you are interested in will be a cartoon model, and you will see a cartoon version of the world through the agent's eyes. It is therefore a self-reinforcing model. This will recreate the lowest-common-denominator approach to content that plagues TV - Jaron Lanier (1995)
one dimension • A spreadsheet: two dimensions • Add another axis and we have 3d (Euclidian) space • Defining a space: distance metric, inner product • Moving between spaces with simple operations • E.g. Matrix multiplication • Input spaces, weight space, loss surfaces
an input space, • X, Y coordinates of a still image, and the pixel intensity/RGB value, hence a 3d-matrix • This space is defined in such a way that we can perform operations on it, like multiplication and addition (of the elements in our 3d-matrix) • These operations induce a common feature representation of the input image we want, and then a categorical prediction of label ‘cat’
cat1.jpg, cat2.jpg, cat3.jpg. They embed in the space of animals*.jpg. • While we may not be able to make a prediction of label ‘cat’ we can make identify ‘clusters’ of features common to cat*.jpg, as distinct from dog*.jpg and goat*.jpg.
cat.jpg to ‘cat’, or identifying cat-ness in the space of animals*.jpg, we can think of a cat as a self- directed agent, exploring a world in search of tasty mice. • The cat finds a mouse, great success • Cat learns that looking in that corner of the basement is a good place to find mice • Repeat until all roads lead to mice Markov the happy cat à
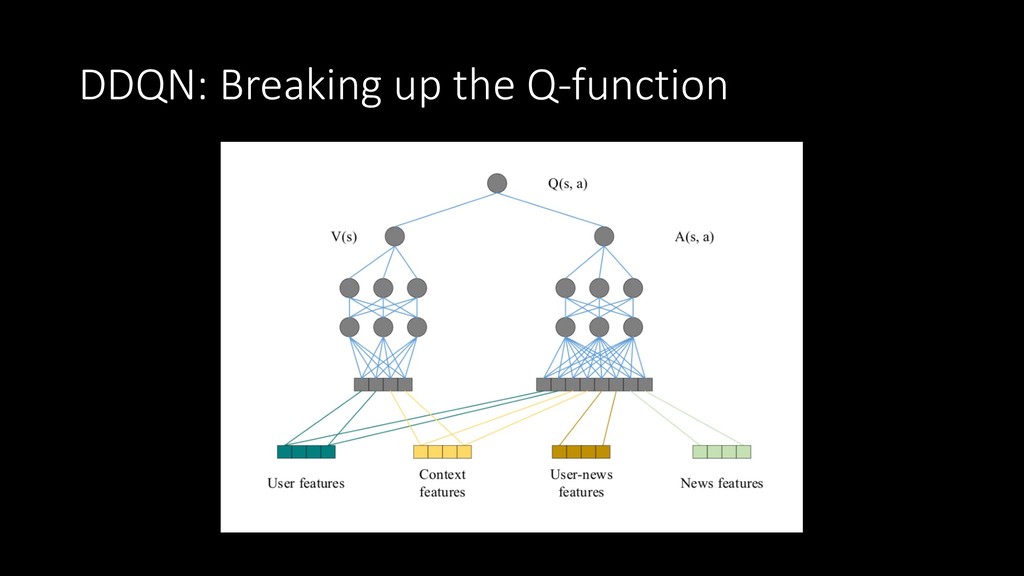
paper – a blank slate! • Easy training at scale, minimal dependencies/container fun • Have written a DQN recently for a book • Want to integrate with existing ABC Recommendations platform & API • Curiosity!
of data science applications • ‘lib/pq’ just works • Integrate query into pipeline, enabling: • Offline training on ~6 months of 10k sampled users • Online training of recent content interactions • Data pipeline is 71% total LOC pls no
metric! • Measuring co-sine similarity of each recommended item • A single dial for controlling tradeoff between novelty/relevance • Simulation! The original DRN system was run in a live environment • We don’t have that luxury, we are developing a simulator based on real data • This ensures that we are only presenting our audience with a finished system • We then have high confidence in the quality of recommendations • Keeping in-line with editorial standards • ‘Oh these recs are terrible, guess the system is still learning’ = NOPE • Must retain audience trust!
to avoid feedback loops • Successful searches that indicate novel content preferences • Adding textual features to our News vectors • Performance metrics and evaluation against current recommendations system • More generally, a greater push for a personalized experience in 2020 and beyond! • New MD has the mandate to “engage new audiences online and creating a personalised and connected online network”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
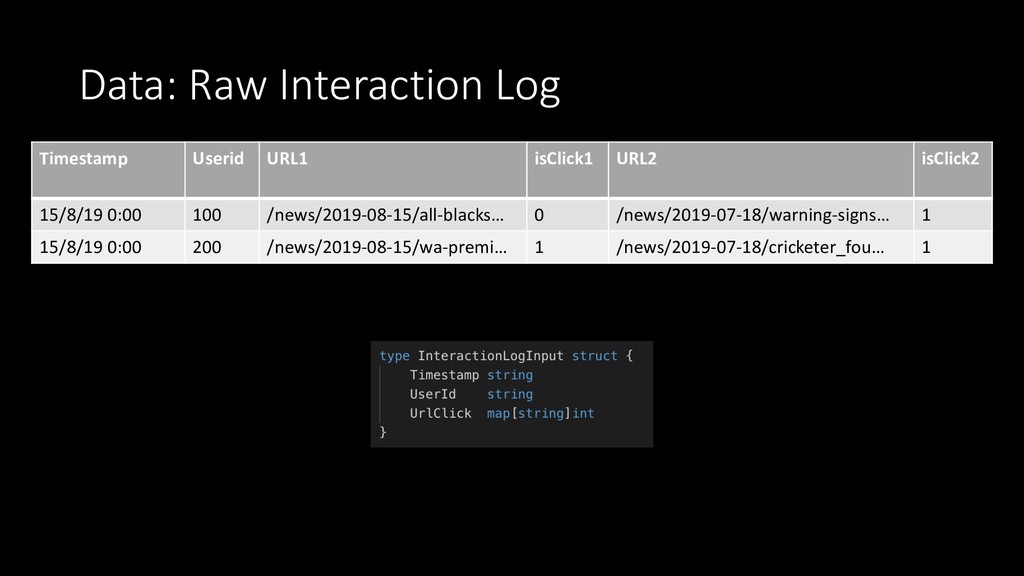{kind=link}
{kind=link}
{kind=link}
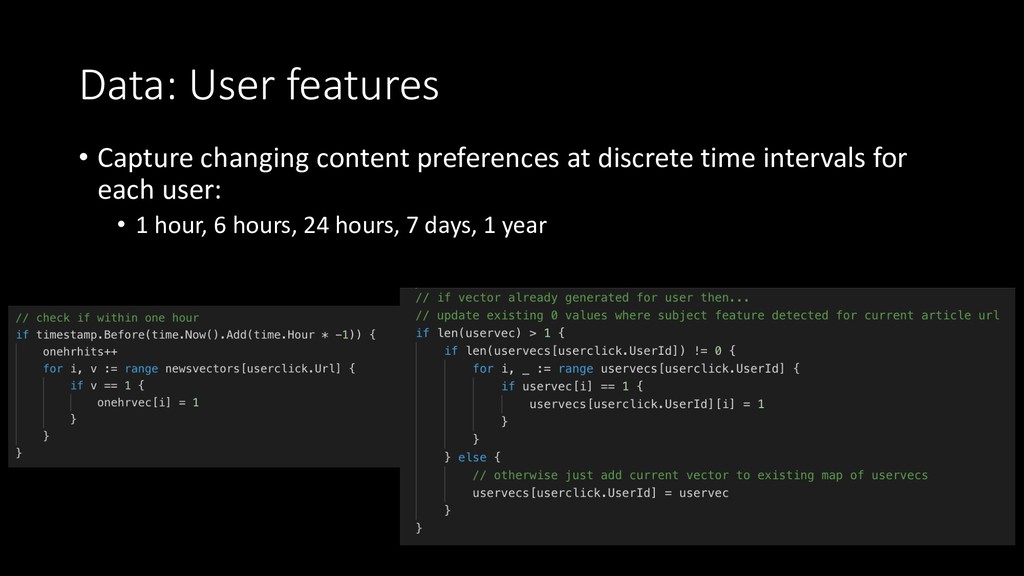{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
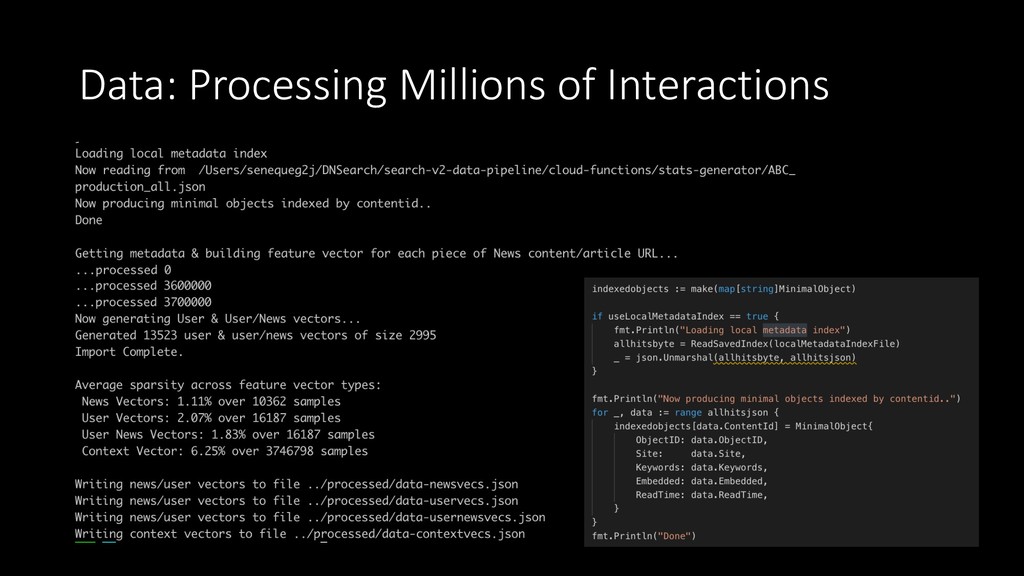{kind=link}
{kind=link}
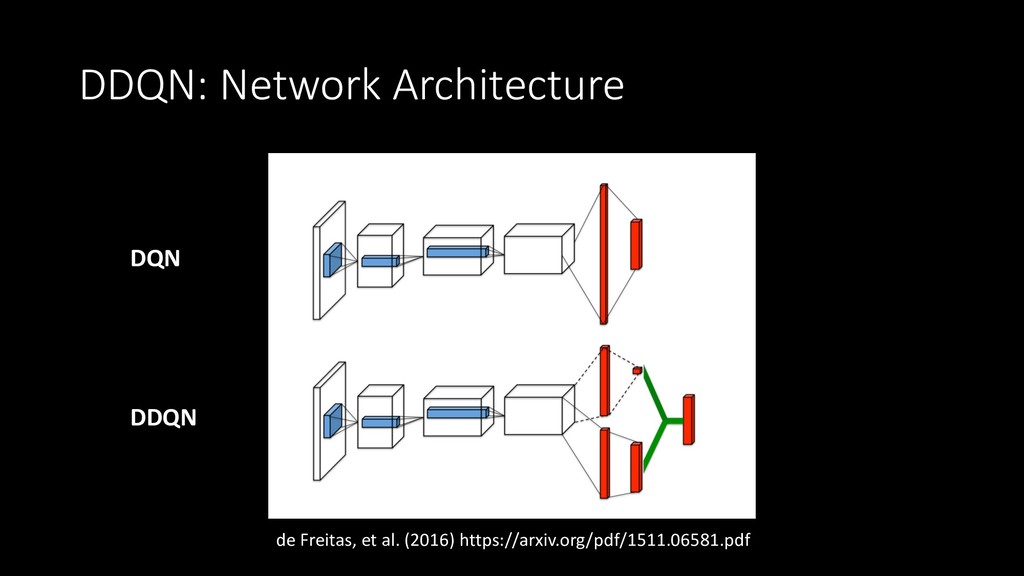{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}