Azure Cosmos DB is globally distributed, multimodel SLA based database for throughput, low latency for reads/writes and consistency. The operations of Cosmos DB are breeze as capacity management, performance management and availability management are all taken care by the platform. Right modelling with partition for scale out in mind and right throughput - ensures you do not have to do much.
![Cosmos DB Operations email : [email protected] Twitter - @azurecosmosdb](https://files.speakerdeck.com/presentations/20527e96849745c8abfb9f8c9b830b79/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
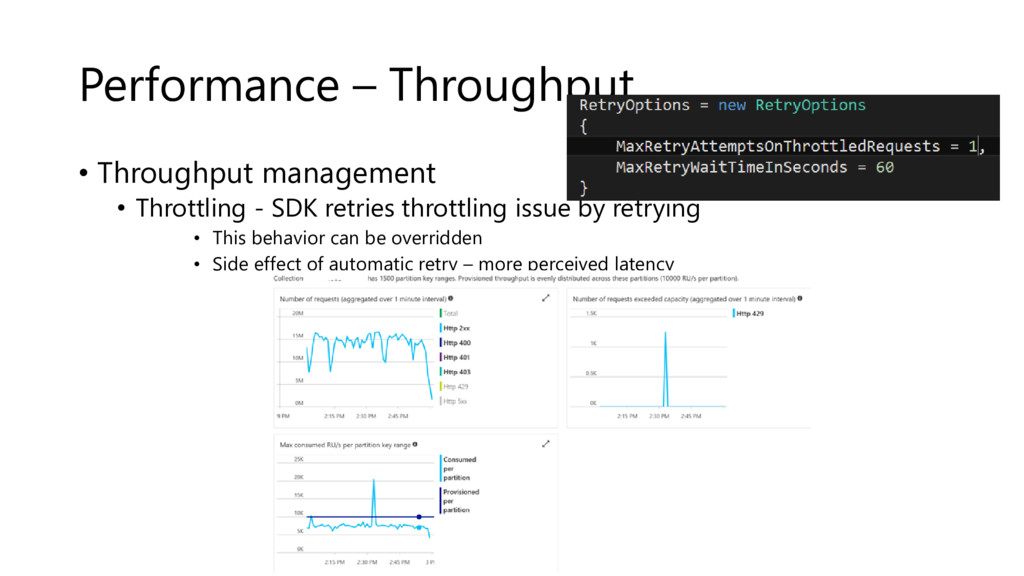{kind=link}
{kind=link}
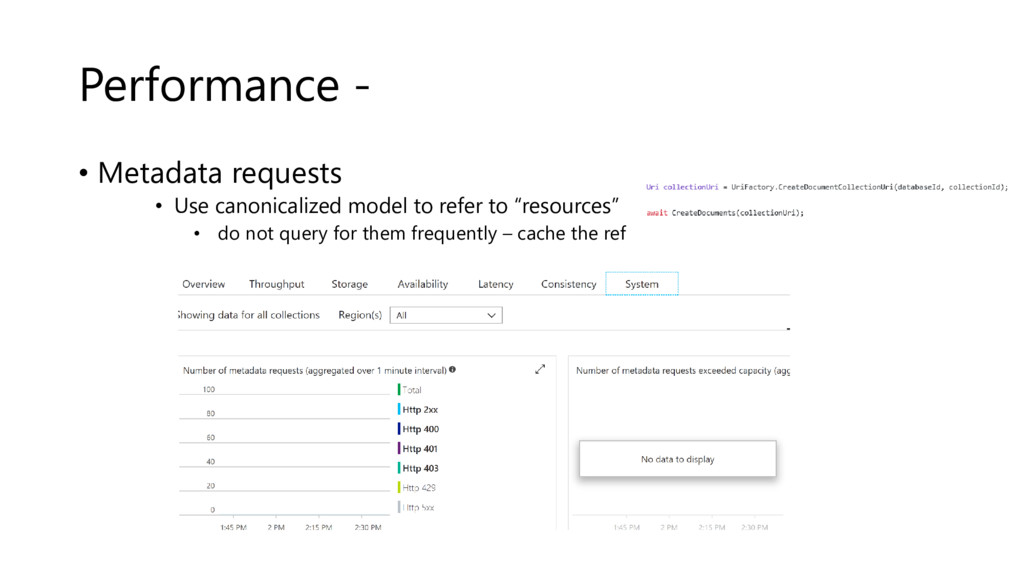{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}