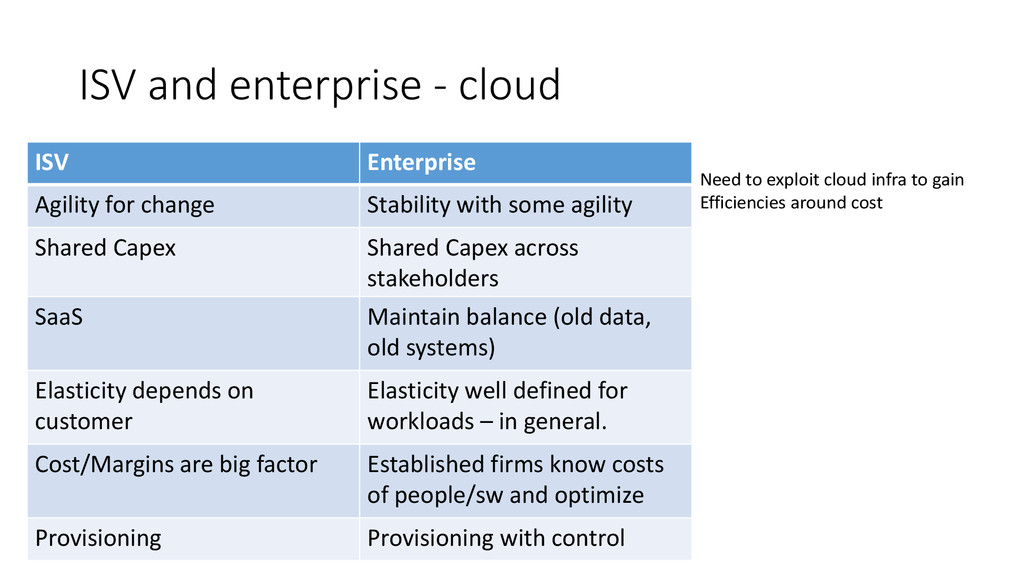
Following is gist of learnings focused on Azure adoption by ISVs and Enterprises. goal of this session is to ensure customers walk away knowing lot of issues they will face. ISVs and enterprises generally have different goal on price, elasticity, cost savings and agility. Generally issues are around availability, performance and security. Azure as a platform is evolving very fast to meet needs of customer.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}