Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
@cosmeにおけるビッグデータのこれまでとこれから
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
grassy-48
July 31, 2019
Technology
4.5k
1
Share
@cosmeにおけるビッグデータのこれまでとこれから
データ分析基盤
Developers Night #3 発表資料
grassy-48
July 31, 2019
Other Decks in Technology
See All in Technology
AIにフローを作らせようとして挫折した話
hamatsutaichi
0
180
個人の発見を、組織の知恵に 〜生成AI活用を"探索"から"組織の仕組み"へ〜
kintotechdev
2
940
Javaコミュニティをもっと楽しむための9箇条
takasyou
0
1.3k
Ruby::Boxでできること、Refinementsでできること
joker1007
3
390
Chart.js が簡単に使えるようになっていたので OGP 画像生成に使った話
kamekyame
0
160
ITエンジニアを取り巻く環境とキャリアパス / A career path for Japanese IT engineers
takatama
4
1.8k
AIプラットフォームを運用し続けるための可観測性
tanimuyk
4
1.1k
[モダンアプリ勉強会]今更聞けないGit/GitHub入門
tsukuboshi
0
260
新規ゲーム開発におけるAI駆動開発のリアル
202409e2
0
2.5k
JEP 522 Deep Dive - G1 GC同期コスト削減によるスループット向上を徹底検証&解説
tabatad
1
810
Djangoユーザが知っ得なPostgreSQL機能 - 設計の選択肢を増やす / Djang-use-PostgreSQL
soudai
PRO
0
170
正解のないAIプロダクトをどう導くか?dodaが挑む、ユーザーの『本音』を構造化する評価設計と検証のリアル
techtekt
PRO
0
180
Featured
See All Featured
Paper Plane (Part 1)
katiecoart
PRO
0
8.5k
Accessibility Awareness
sabderemane
1
130
Docker and Python
trallard
47
3.9k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Amusing Abliteration
ianozsvald
1
200
WCS-LA-2024
lcolladotor
0
620
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
460
Joys of Absence: A Defence of Solitary Play
codingconduct
1
390
Building Applications with DynamoDB
mza
96
7.1k
Done Done
chrislema
186
16k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
570
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Transcript
株式会社アイスタイル @cosmeにおけるビッグデータの これまでとこれから テクノロジー本部 R&D部 芝 星帆
自己紹介 芝 星帆(SHIBA SEIHO) 株式会社アイスタイル テクノロジー本部 R&D部 技術開発グループ所属 @cosmeアプリのバックエンドAPIの開発 スマホ版@cosmeの速度改善プロジェクト 今後のビッグデータ統括に向け収集基盤の開発 言語 Go/PHP/Scala
アジェンダ • istyleとは • istyleにおけるビッグデータ基盤 • istyleにおけるビッグデータ活用例 • これからのビッグデータ活用
• istyleとは • istyleにおけるビッグデータ基盤 • istyleにおけるビッグデータ活用例 • これからのビッグデータ活用
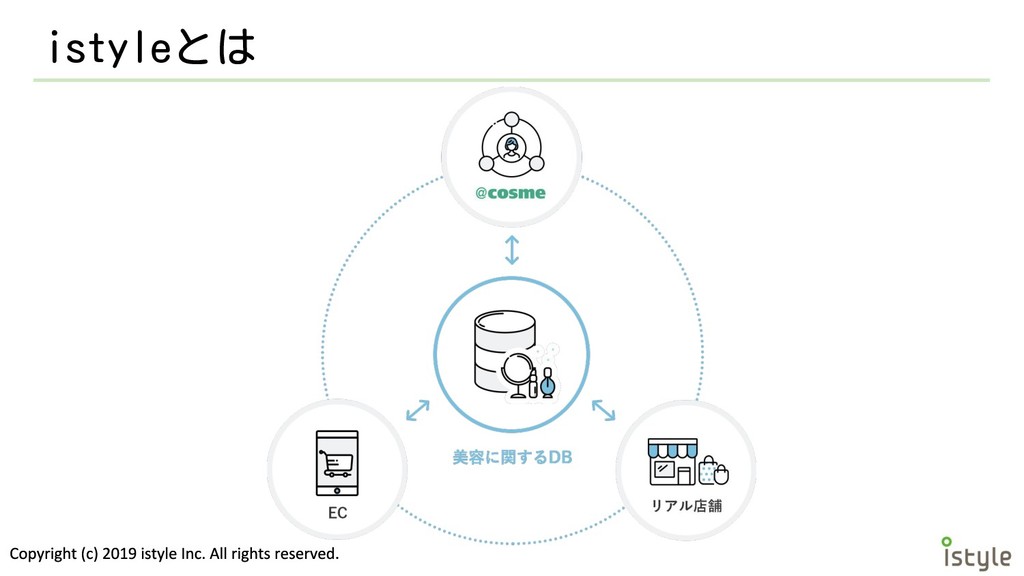
istyleとは • @cosme(コスメ・美容総合サイト)や 関連する他サービスの運営
istyleとは • @cosme以外にもこんなことをやっています ◦ ECサイト(@cosme shopping)運営 ◦ 全国の小売店(@cosme store)や プライベートブランドの展開
◦ 海外の化粧品サイトとの連携 ◦ 海外への小売店の展開
istyleとは
istyleが持っているデータ
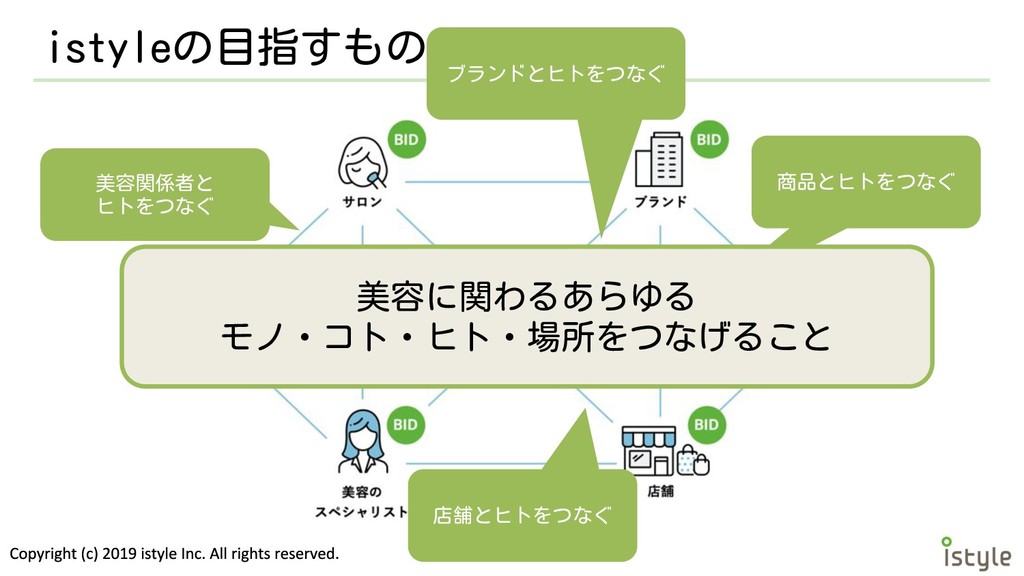
istyleの目指すもの 商品とヒトをつなぐ ブランドとヒトをつなぐ 店舗とヒトをつなぐ 美容関係者と ヒトをつなぐ 美容に関わるあらゆる モノ・コト・ヒト・場所をつなげること
istyleだから出来ること 20年蓄積した情報 20年培ったつながり ビッグデータを活用したビジネスへの進化
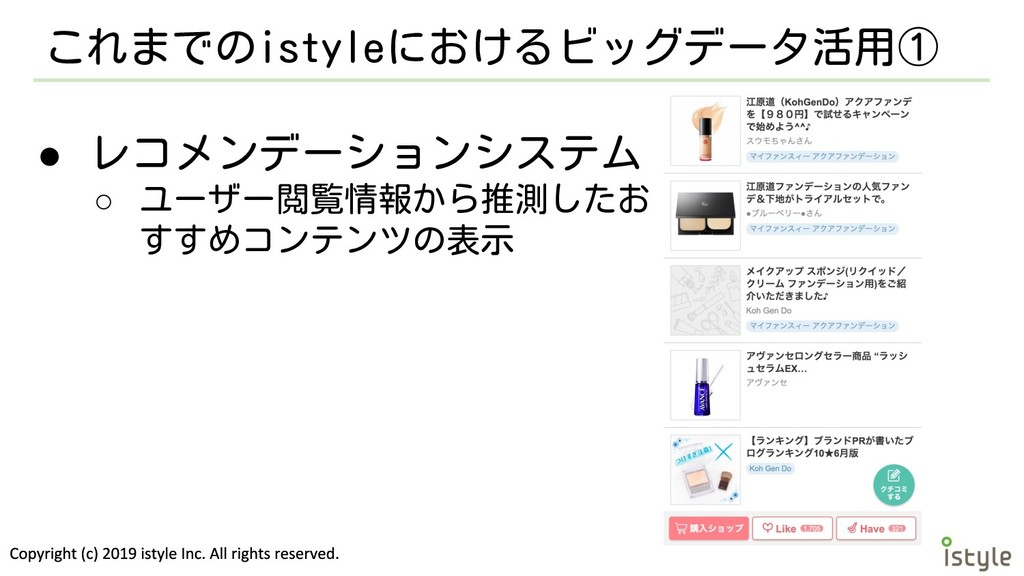
これまでのistyleにおけるビッグデータ活用① • レコメンデーションシステム ◦ ユーザー閲覧情報から推測したお すすめコンテンツの表示
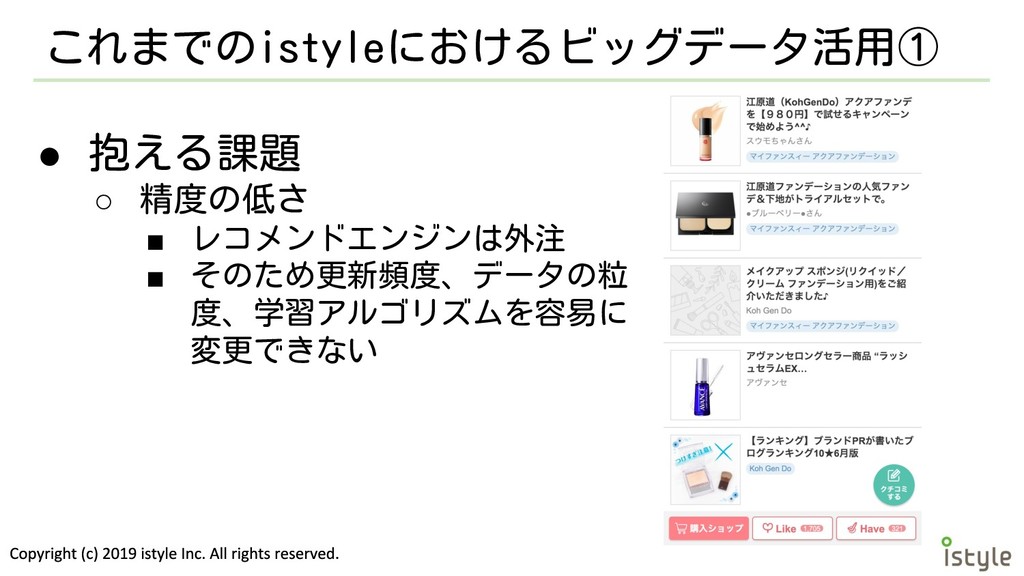
これまでのistyleにおけるビッグデータ活用① • 抱える課題 ◦ 精度の低さ ▪ レコメンドエンジンは外注 ▪ そのため更新頻度、データの粒 度、学習アルゴリズムを容易に
変更できない
これまでのistyleにおけるビッグデータ活用② • ブランド向けユーザーデータ解析ツールの展開 ◦ ALCOS ▪ Analyzer for Cosmetics の略。@cosmeのデータ
とソーシャルメディア情報を連携した、美容特化のASP 型の⾏活者⾏動分析ツール
これまでのistyleにおけるビッグデータ活用② • 抱える課題 ◦ データの取得範囲 ▪ 今まではSNSへの連携・投稿と、アクセス行動から割り 出せる範囲でのユーザーデータ分析 ▪ 期間・コンテンツも限定的
ユーザーとブランドやメーカーとのつながりを強めるには より多くのデータと、より多彩な分析が必要!
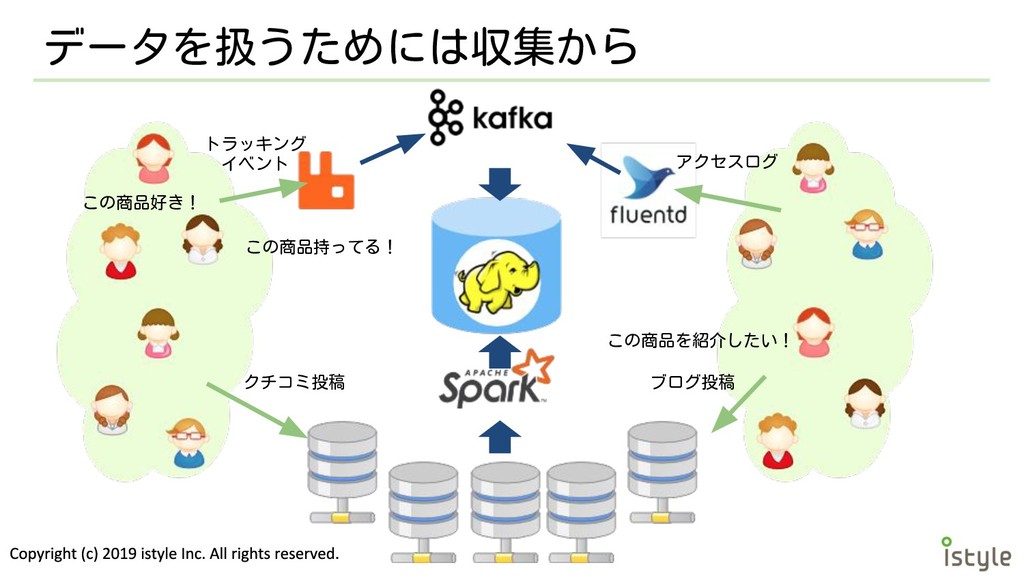
課題を解決するために • 社内でもビッグデータ収集が開始 ◦ サービスを超えたログデータ収集基盤の構築 ◦ ユーザー行動トラッキングデータの収集 ▪ アクセス数から算出されるフィードの表示数が理論値で は100億を超える。そのためGoogleAnalyticsは使用でき
ず、独自イベントでの計測を行う
• istyleとは • istyleにおけるビッグデータ基盤 • istyleにおけるビッグデータ活用例 • これからのビッグデータ活用
社内ビッグデータ環境の変遷 2017年1月:データ基盤構想が開始(Hadoop環境の構築) 2017年同月:自社トラッキングシステムから、インプレッションの収集を開始 2018年6月:アクセスログ収集開始 2019年3月:機械学習プロジェクト開始 新しく一部のログ基盤とアクション基盤を作り変える 集積データの活用を開始 2019年4月:トラッキングデータの一部を解析に利用開始
データを扱うためには収集から この商品好き! この商品持ってる! アクセスログ クチコミ投稿 ブログ投稿 この商品を紹介したい! トラッキング イベント
使った技術 • Spark ◦ 巨大なデータに対して高速に分散処理を行う ためのフレームワーク ◦ Resilient Distributed Datasetsによって分
散共有メモリを実現し、インメモリでデータ にアクセスする ◦ Hadoop上のYARNによってSparkのリソースを 管理している
使った技術 • Apache Kafka ◦ 分散メッセージキューを行うミドル ウェア ◦ リアルタイムアプリケーションとマ イクロサービスを実現する
◦ スケーラブルでユースケース規模に よらず高い耐障害性で利用可能 ◦ 個別の処理用クラスタが不要 ◦ Java、Scalaアプリケーションの作成 ができれば誰でも使える
データ集約からデータ活用のフェーズへ • Hadoop上にログ基盤、ユーザーアクション データ基盤を構築 • 4ヶ月で集約したデータサイズ:11TB程度 • データ活用のフェーズへと移行
• istyleとは • istyleにおけるビッグデータ基盤 • istyleにおけるビッグデータ活用例 • これからのビッグデータ活用
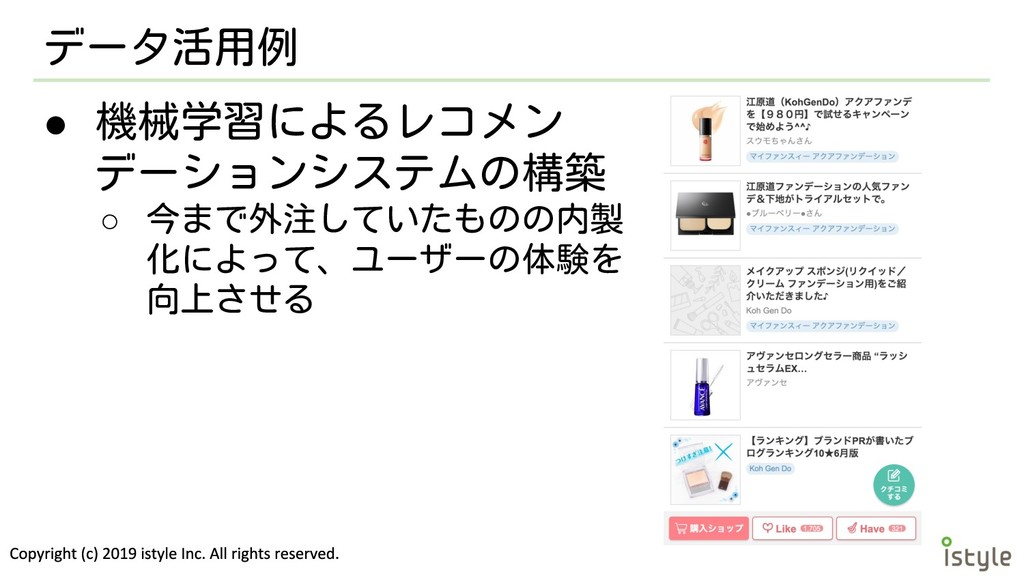
データ活用例 • 機械学習によるレコメン デーションシステムの構築 ◦ 今まで外注していたものの内製 化によって、ユーザーの体験を 向上させる
レコメンデーションの改善 • 内製化することで得られるメリット ◦ 学習に扱えるデータの多様性が増す ◦ パラメータ調整やアルゴリズム検証が容易となる ◦ データ更新頻度を上げることができる
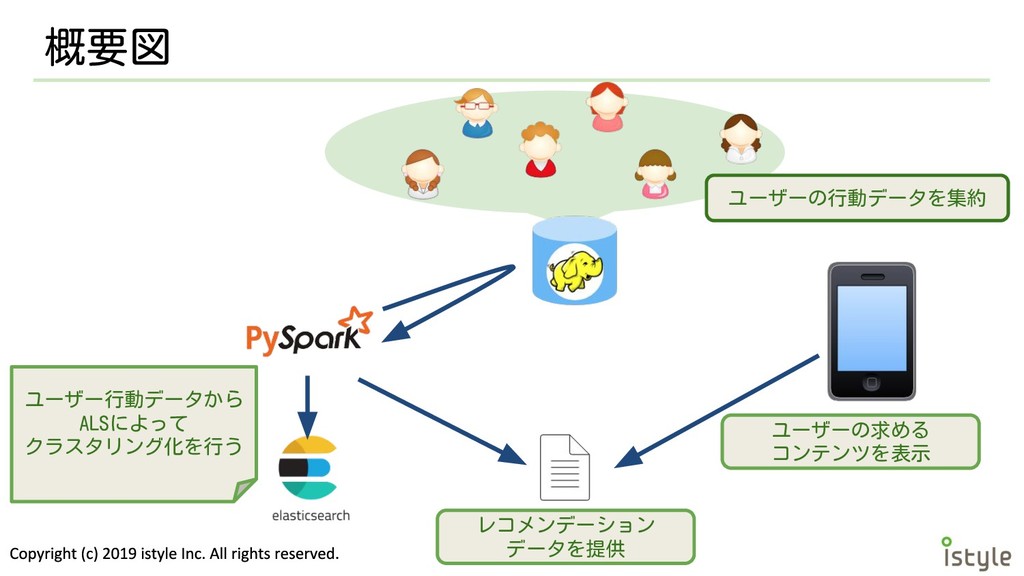
概要図 ユーザーの行動データを集約 ユーザー行動データから ALSによって クラスタリング化を行う レコメンデーション データを提供 ユーザーの求める コンテンツを表示
使った技術 • PySpark ◦ Sparkを実行するためのPythonAPI ◦ ワーカーノードでの処理をPythonプロセス で実行する ◦ PyDataのライブラリと組み合わせて実行で
きる ◦ MLのライブラリもほぼ使用できる
得られた効果 • 飛躍的な効果はまだ見られない ◦ クリック率向上 → × ◦ 回遊率の向上 → × • 原因として考えられる内容 ◦
コンテンツの表示方法? ◦ 表示件数? ◦ レコメンデーションとしての精度の低さ 今後の課題となる POINT
レコメンデーション精度の向上にむけて • 学習データの拡充 ◦ 内製化によって扱うデータの多様化 ◦ データの変更や調整が容易 ◦ これまで週次だった学習モデル化を日次で行えるよう になりユーザーへの反映頻度が向上
• 学習データの調整 ◦ 都度数字の動向をみてパラメータ調整を行える ◦ 各種アルゴリズムの適応や検証が可能に
運用を開始して… • ファイルフォーマットの変更 ◦ 開発初期はログフォーマットとしてAvroを採用 ▪ 理由 • スキーマ定義が必要だったためJSONは除外 •
ORCも使えるソフトウェアが限られるため除外 • kafka streamsとの高い互換性によってAvroを採用 ◦ 中盤で標準をParquetに変更 ▪ 理由 • Spark2.2ではAvroの読み込みにパッケージインポートが必要で あり保守が困難であった • 今後追加されていく予定の大量なデータを見据えてカラムナ フォーマットに変更したかった
運用を開始して… • ログ収集が一時停止した ◦ 原因 ▪ 設定変更の反映のためHDFS再起動が必要となった ▪ Kafka connectorを停止せずに再起動したため、
connectorのログファイルが破損 ▪ Kafka側エラーが発生しログの取得が停止 ◦ 解決方法 ▪ HDFS再起動時は接続するKafka connectorの停止をして から実施
実現までに苦労したこと • 学習コスト ◦ 開発開始時、ほぼ全員ビッグデータ運用未経験 • 初期基盤構築 ◦ 構築時の情報が社内ナレッジに残されていない ◦
物はあるのに使えない状態からのスタート それぞれが学んだ内容をレビューや ディスカッションで共有していく 知識の定着もかねてナレッジへの文書化
実現までに苦労したこと • 適切な設定値が分からない ◦ リソースの割当 ◦ 実行メモリ ◦ パーティション設定 •
ファイルブロック数の肥大化 調査しながらトライ・アンド・エラーで 設定していく ファイル作成頻度の見直し・ 定期的なコンパクションの実行
• istyleとは • istyleにおけるビッグデータ基盤 • istyleにおけるビッグデータ活用例 • これからのビッグデータ活用
これからのデータ活用方法 • ユーザーに対しておすすめできるのはコンテ ンツだけではない ◦ 肌質や髪質、年代といったユーザー固有の情報から より高精度な商品とのマッチング ◦ ユーザーの行動からリアルタイムなデータの活用に よってサロンや美容スペシャリストとのデータ連携
◦ つながりを活かしてその瞬間ユーザーが求めている情 報を提供する
これからのデータ活用方法 • ビジネスパートナーへの展開 ◦ @cosmeに集まるデータをビジネスパートナーの ニーズに合わせて集約 ◦ これまでのデータ解析ツールでは実現しなかった情報 を分析できるようにする ◦
そのためにはより多くの情報を集積や、分析方法の確 立をおこなう
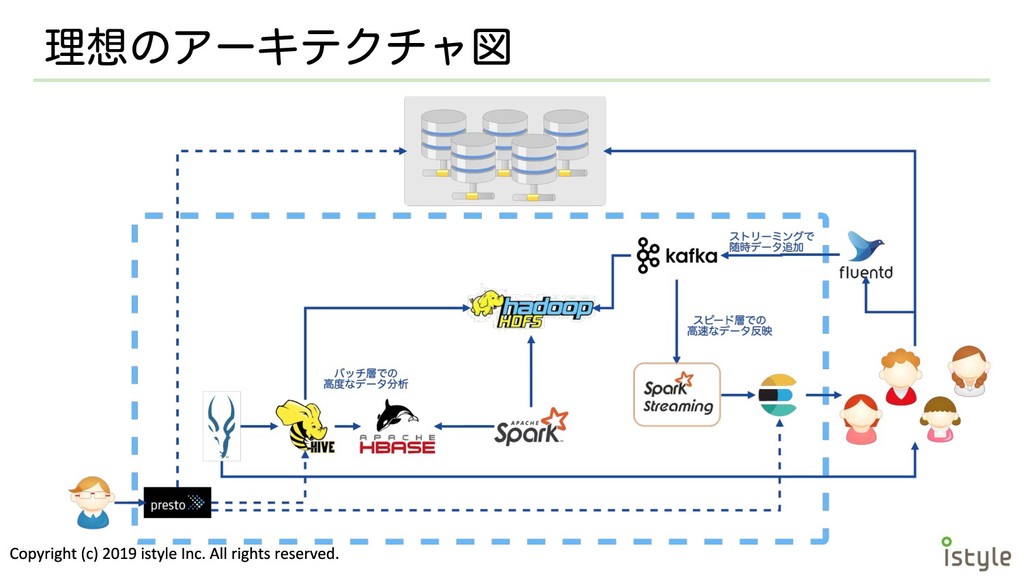
目指すところ • 社内でバラバラに存在しているデータを集約 して一元化されたデータレイクを構築 • サービス内でどんな変化があったかをリアル タイムに蓄積し続ける • より多彩な分析・解析や機械学習を行うため の基盤となる
理想のアーキテクチャ図
理想の実現に向けての課題 • 取得データの多様化 ◦ 既存サービスとの連携 ◦ これまでの過去のデータの発掘 ◦ 今後必要となるデータの選別 •
リソース ◦ 人・時間・サーバーの十分な確保 • ナレッジの充足 ◦ 技術知識の吸収と社内エンジニアへの展開
今日お話したこと • istyleとは ◦ 事業紹介、これまでのistyleについて • istyleにおけるビッグデータ基盤 ◦ データ集約基盤と使った技術について •
istyleにおけるビッグデータ活用例 ◦ レコメンデーションシステムのための機械学習による データ活用について • これからのビッグデータ活用 ◦ 今後のVisionについて
istyleでは下記のような方を募集しています! これからのビッグデータ基盤を支えたい! ビッグデータ基盤を一緒に作り上げたい! ビッグデータについて新しく学びたい!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}