新型コロナウイルス影響が拡大している状況を受け、参加者および関係者の健康・安全面を第一に考慮した結果、開催の中止となった「オープンソースカンファレンス 2020 Tokyo/Spring」で2020年2月21日講演予定だった資料
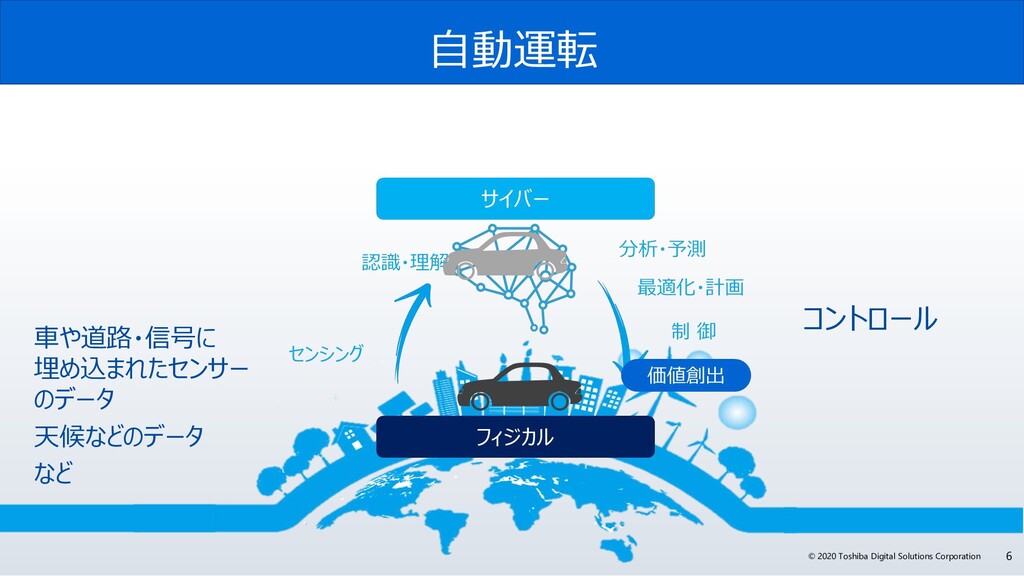
サイバー・フィジカル・システム・・・自動運転、スマートグリッド、スマート工場、スマートビルディング・・・
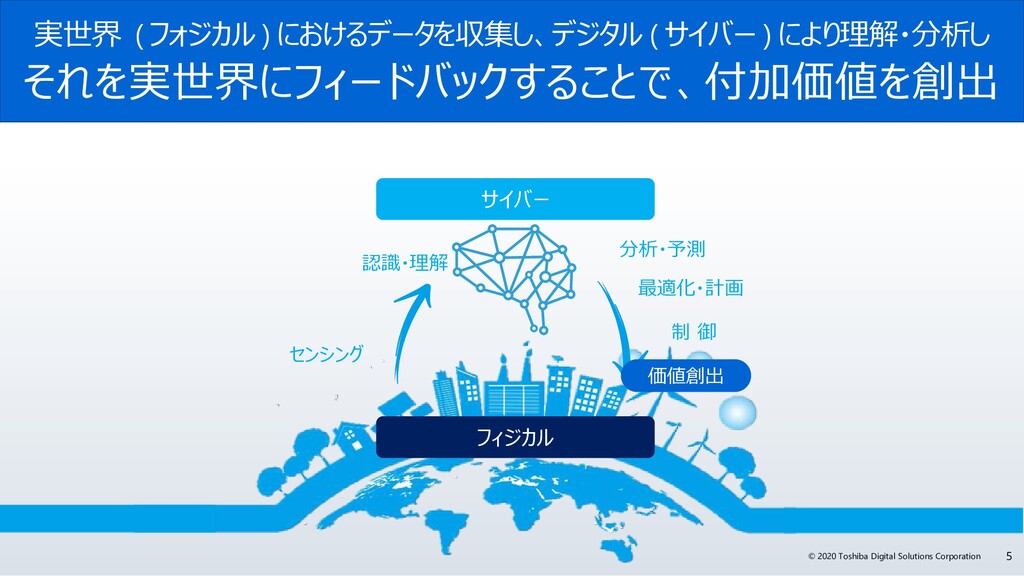
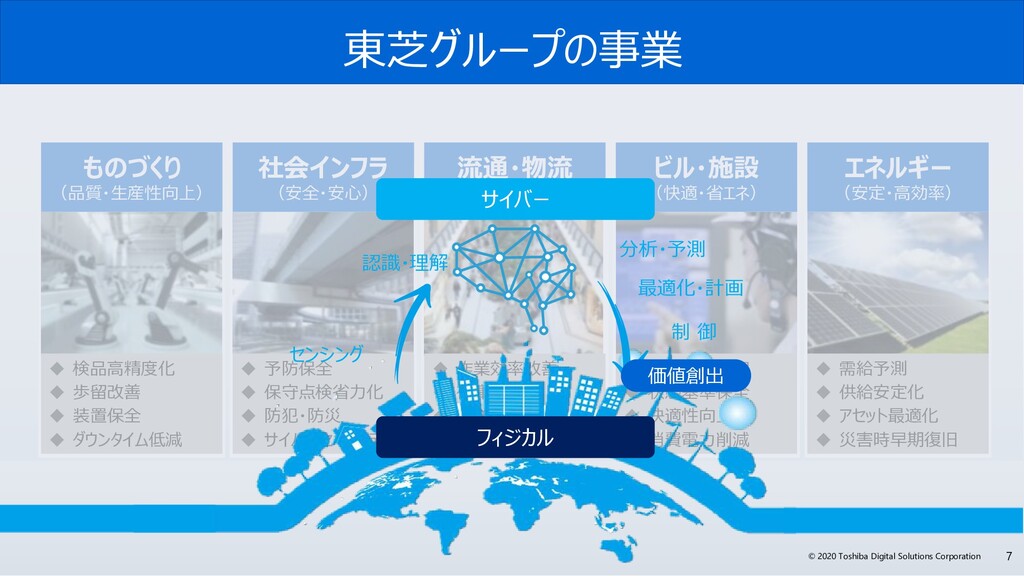
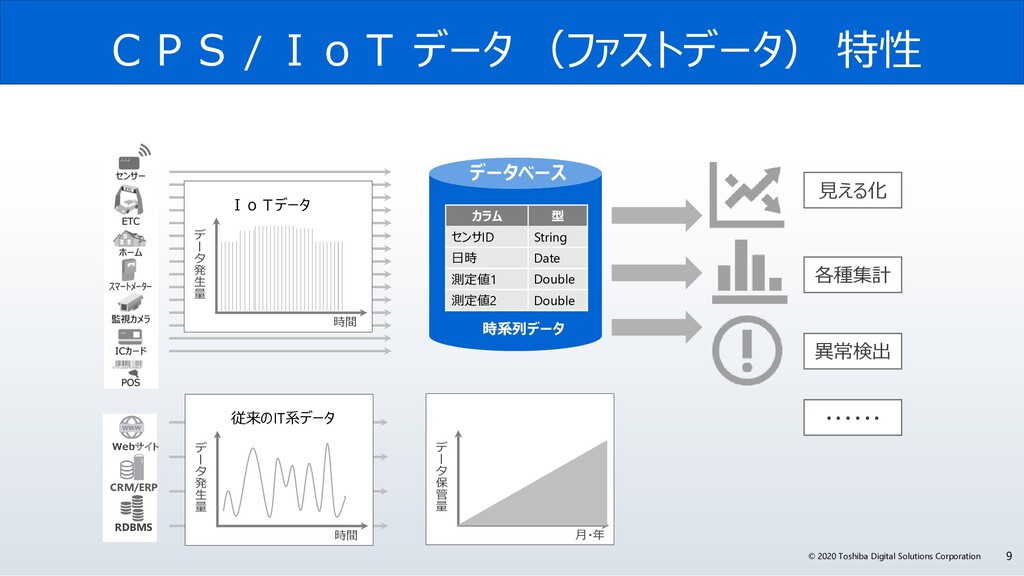
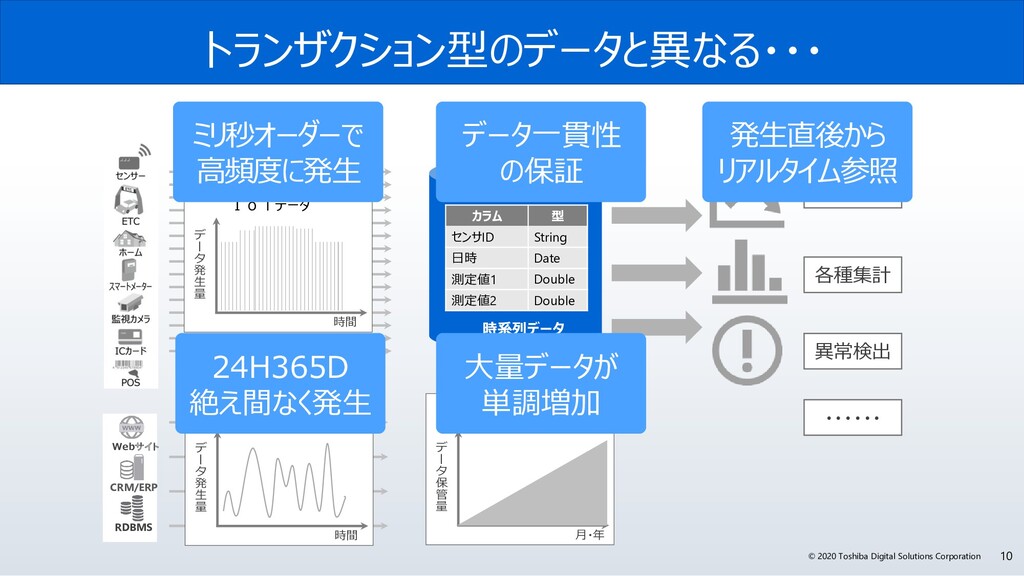
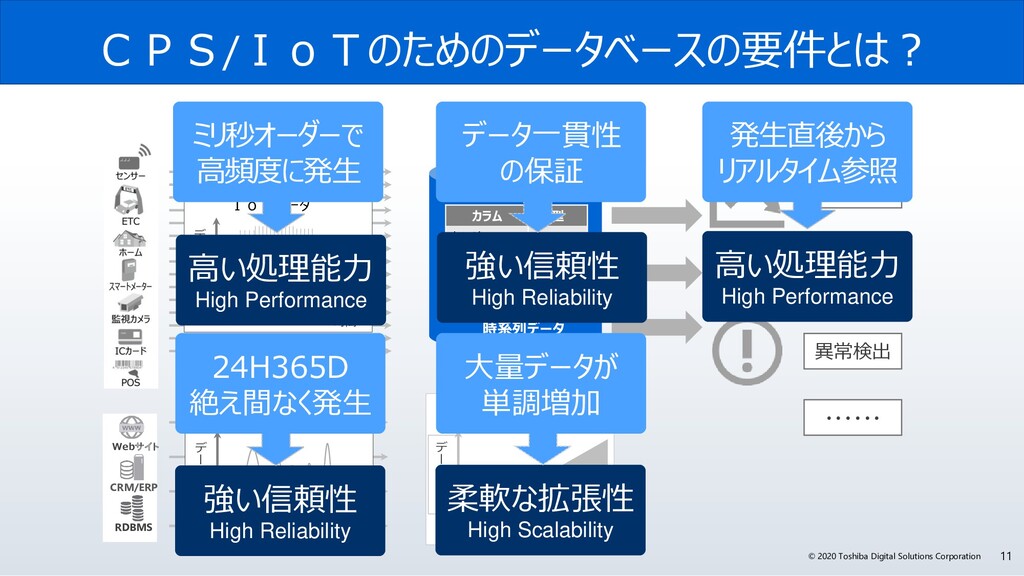
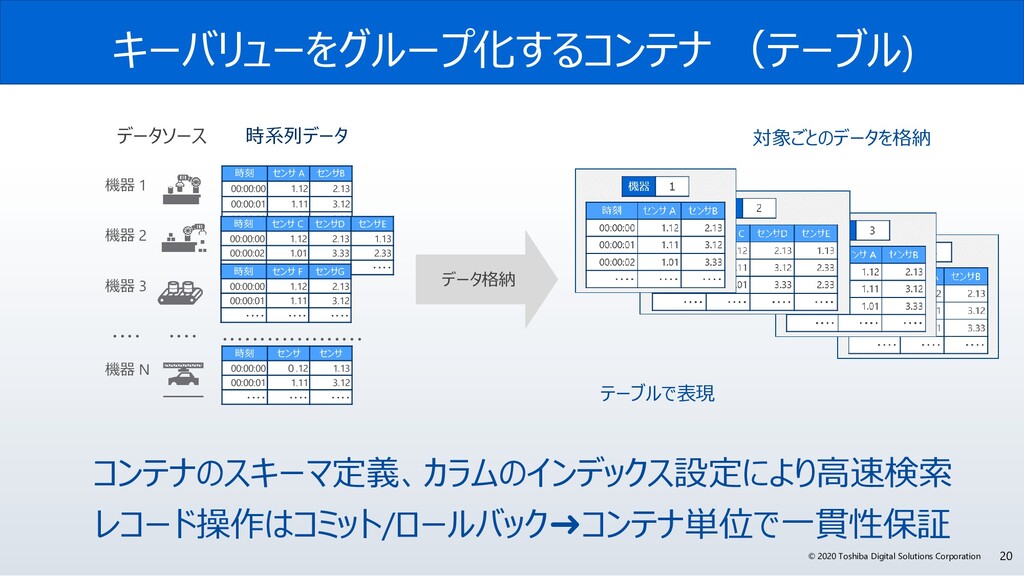
サイバー・フィジカル・システムは、フィジカル空間(実世界)にある多様なデータを収集し、サイバー空間で、大規模データ処理技術を駆使し、分析・知識化を行い、そこで創出した情報・価値によって、これまで「経験と勘」に頼っていた事象を効率化し、産業の活性化や社会問題の解決を図っていきます。サイバー・フィジカル・システムには、センサーネットワークが生みだす膨大な時系列データをリアルタイムに処理が可能なデータ基盤が必要です。
YouTubeで公開しているショートビデオ「サイバー・フィジカル・システムを支えるスケールアウト型分散データベース GridDB」https://youtu.be/ALK9RReUSpI で述べている通り、GridDBはサイバー・フィジカル・システムの実現に必要な要件を満たしたオープンなデータベースです。
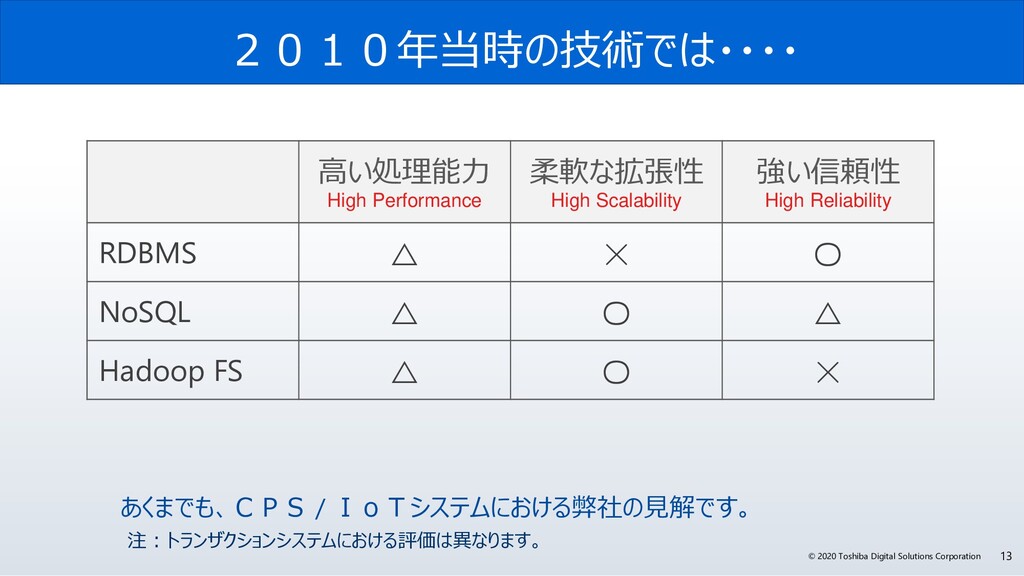
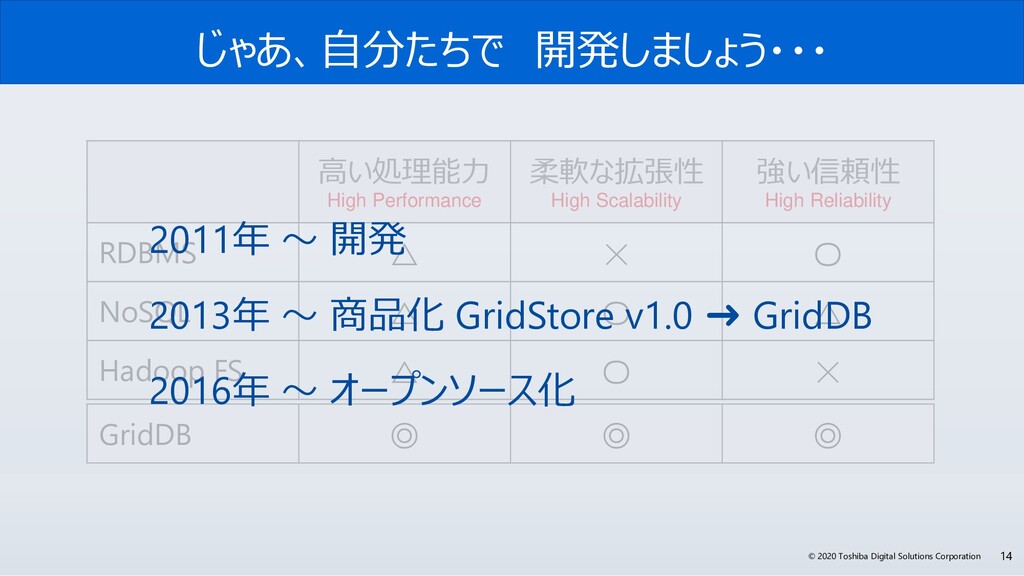
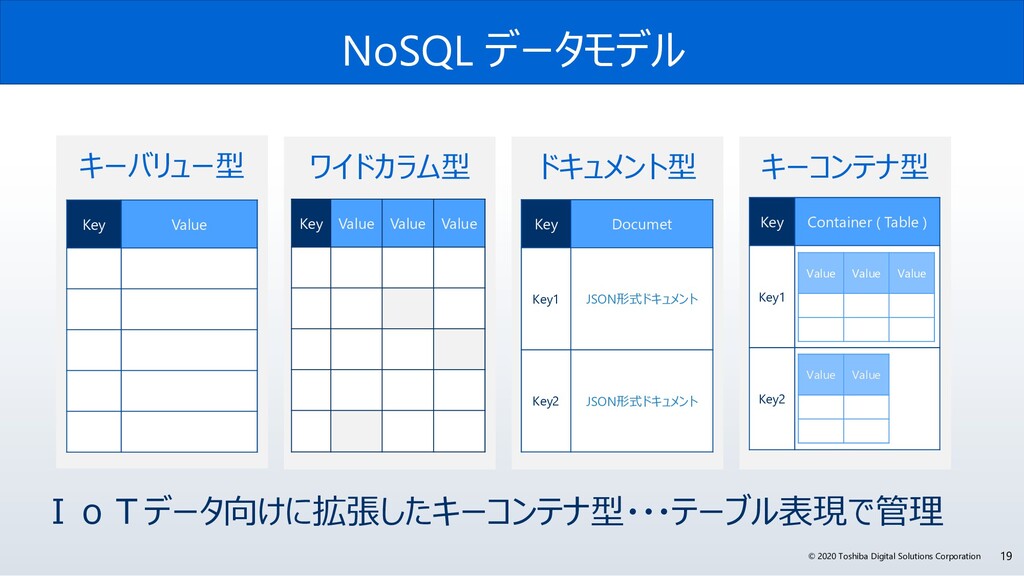
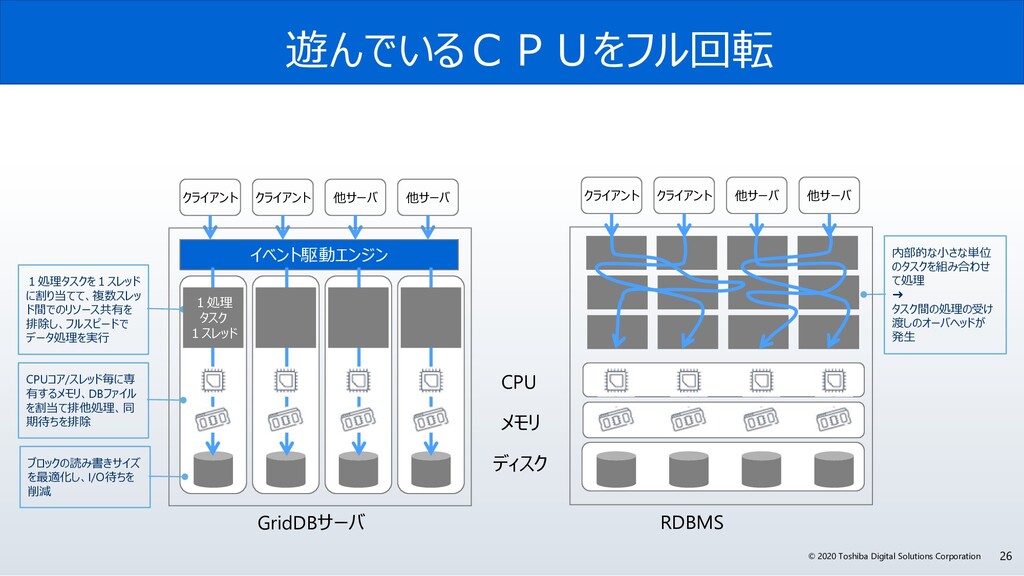
今回、なぜGridDBは、サイバー・フィジカル・システムの実現に必要な要件を満たしているのか? GridDBの概要と特長、特に、「データモデル」、「高速性」、「拡張性」、そして「可用性」にこだわる理由とその実現方法のポイントついて解説します。また、活用事例やオープンイノベーション活動などについても紹介します。
https://event.ospn.jp/osc2020-spring/session/22110
https://www.ospn.jp/osc2020-spring/modules/eguide/event.php?eid=15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
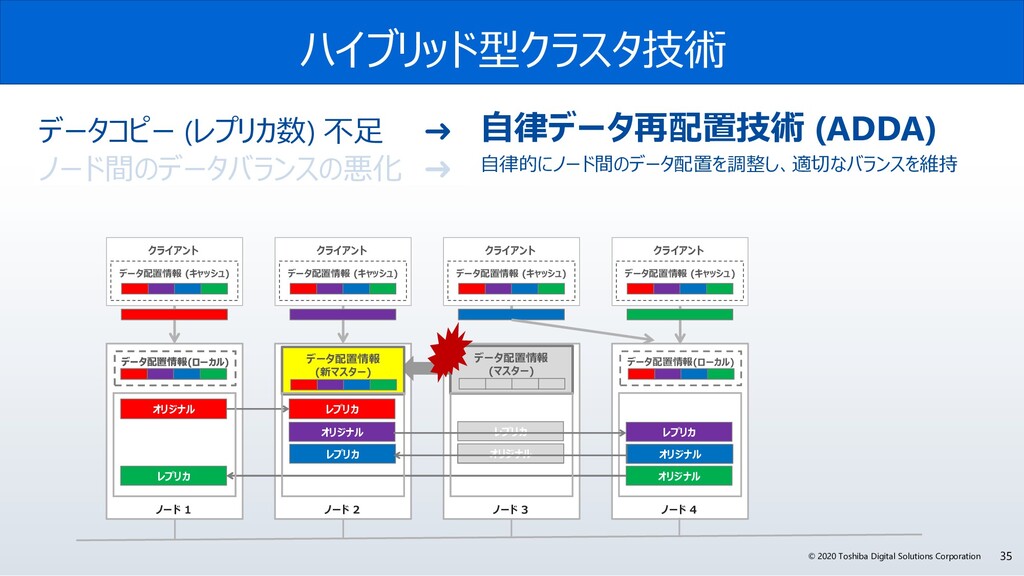{kind=link}
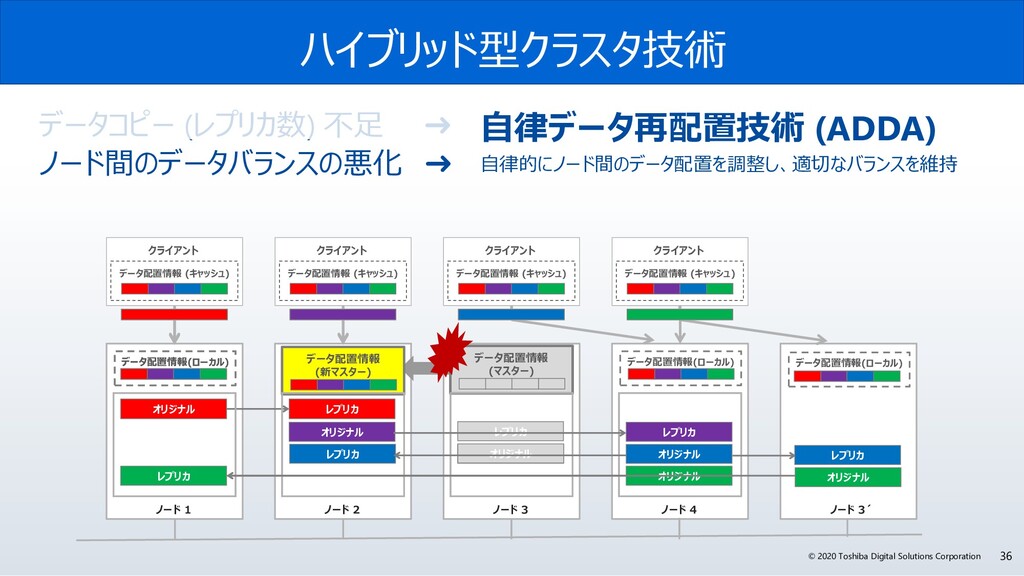{kind=link}
{kind=link}
{kind=link}
{kind=link}
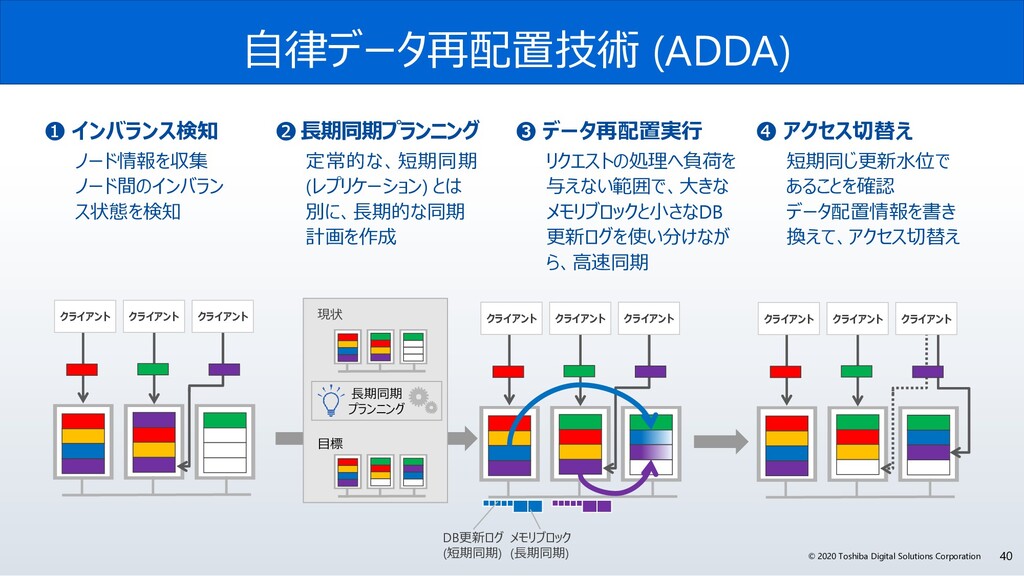{kind=link}
{kind=link}
{kind=link}
{kind=link}
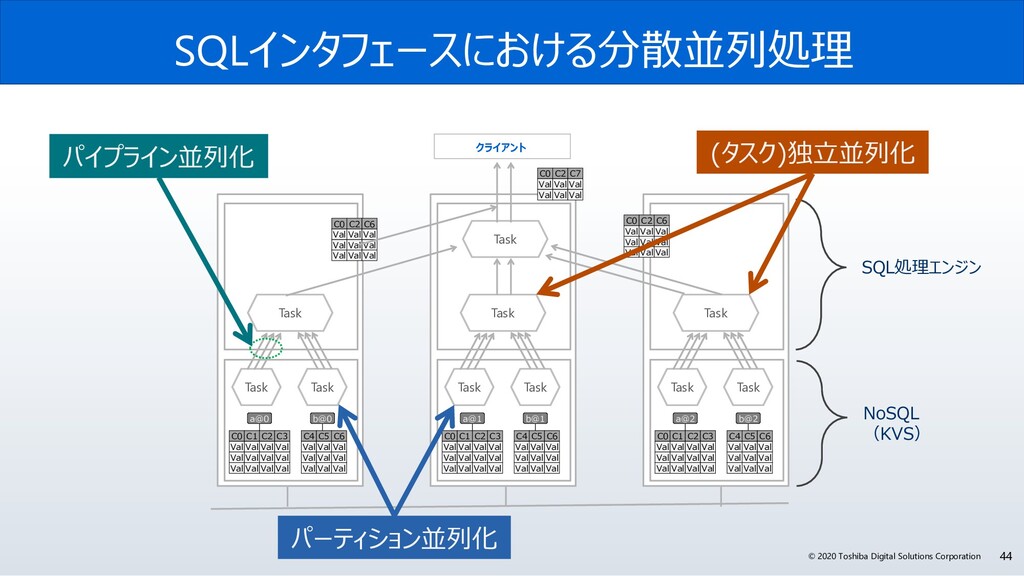{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}