Роман Нікітченко, Research engineer at V.I.tech
Технології Big Data та інфраструктура Apache Hadoop
Обсяги даних в сучасних інформаційних рішеннях стримко зростають і це приводить до виникнення як нових проблем, так і нових можливостей. De-facto перша в світі операційна система для обробки даних (data OS) Apache Hadoop надає дуже широкі можливості як для зберігання, так і для обробки великих обсягів інформації. Які саме і як це може вплинути найближчим часом на обличчя індустрії Big Data?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
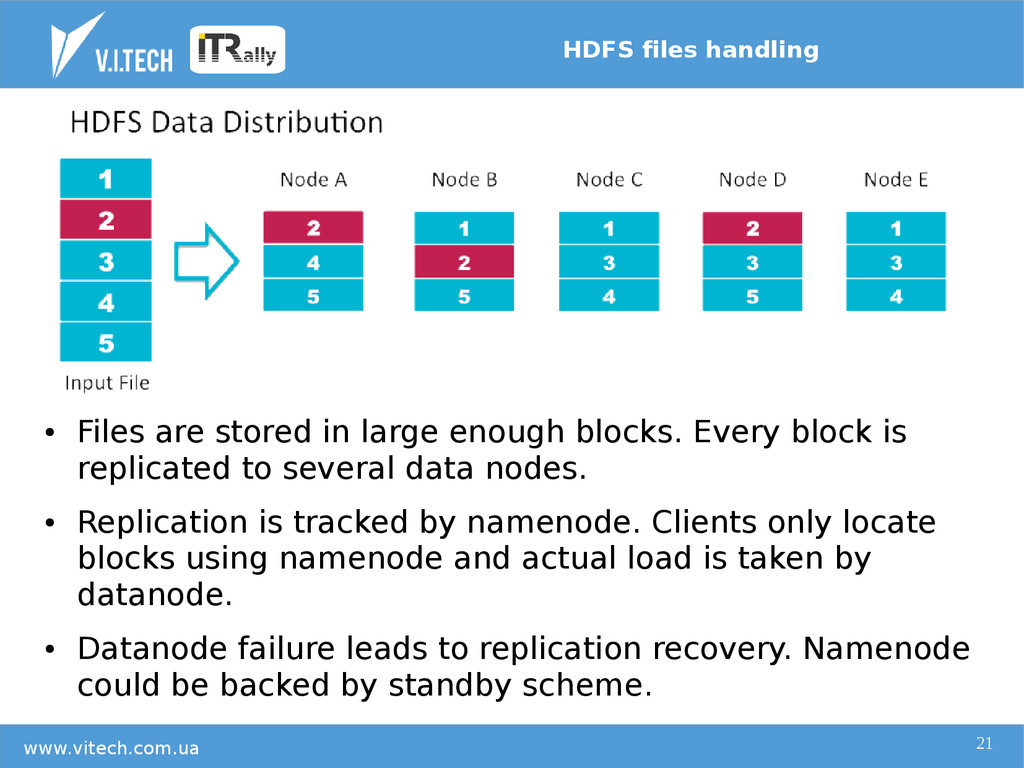{kind=link}
{kind=link}
{kind=link}
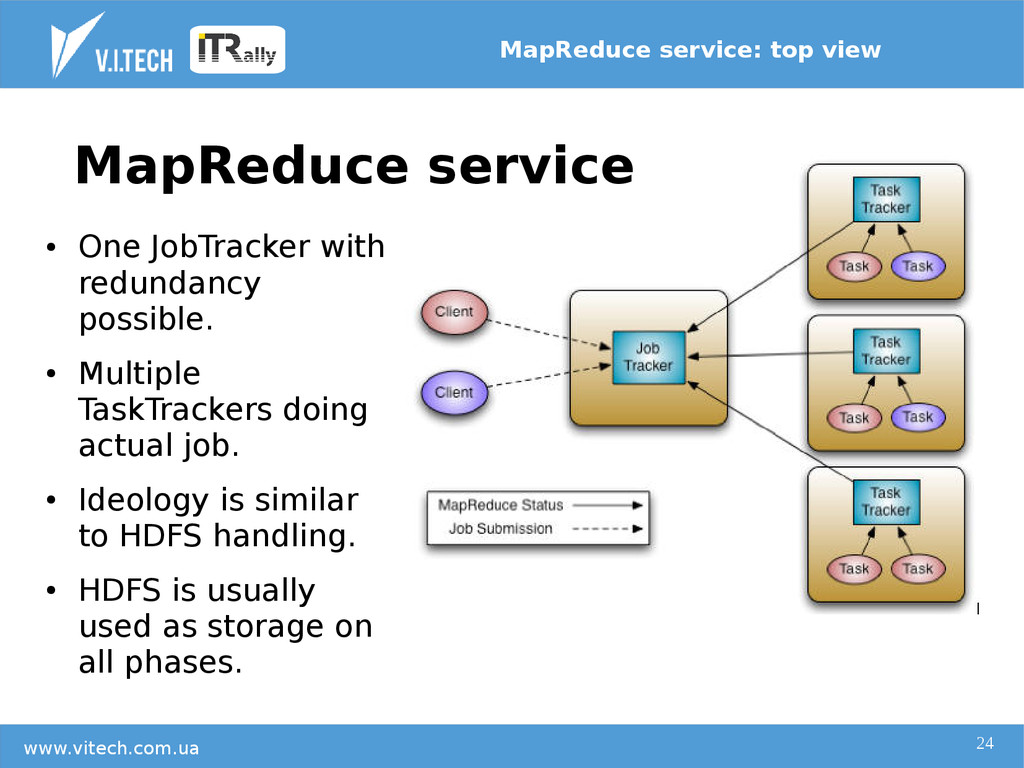{kind=link}
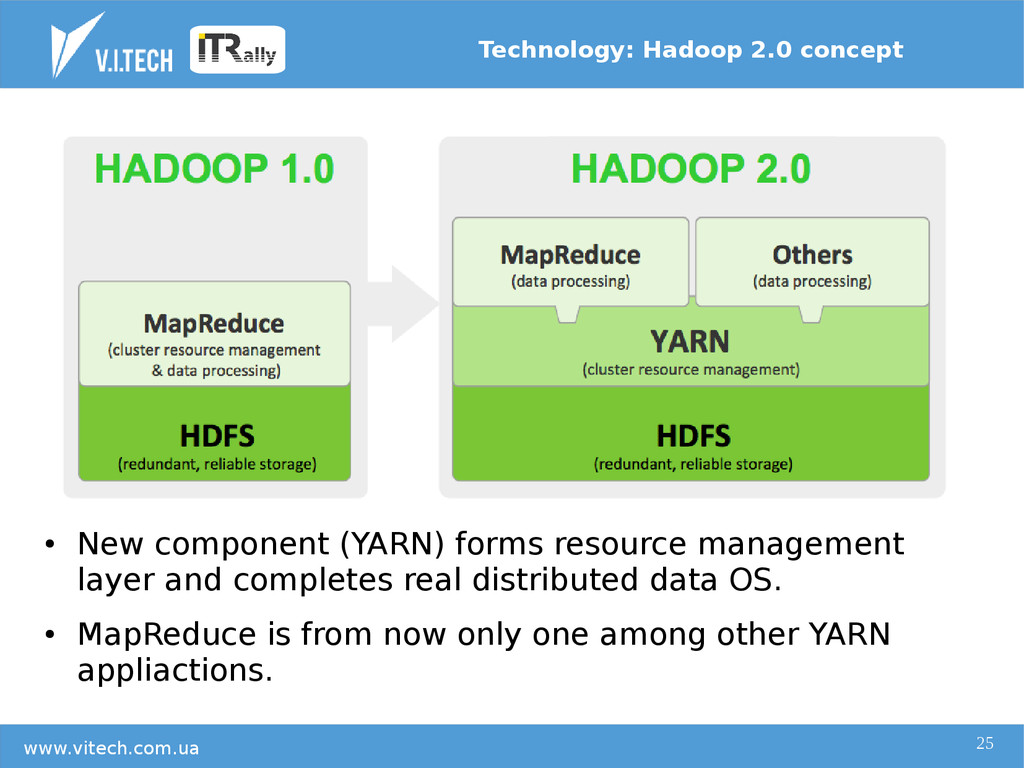{kind=link}
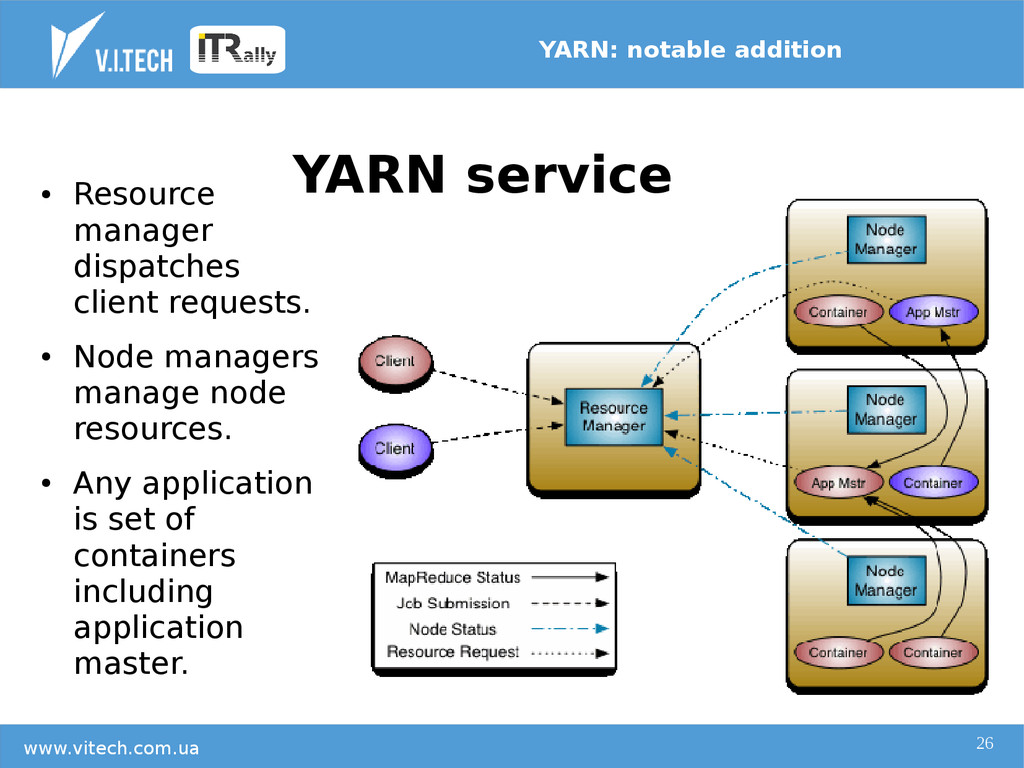{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}