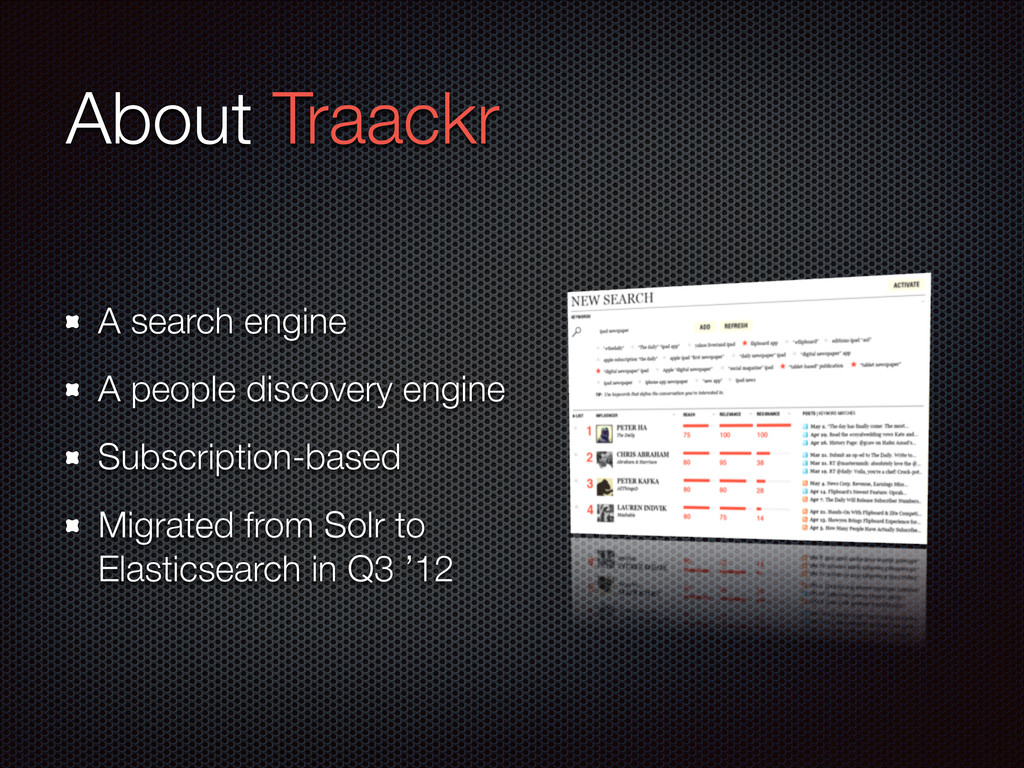
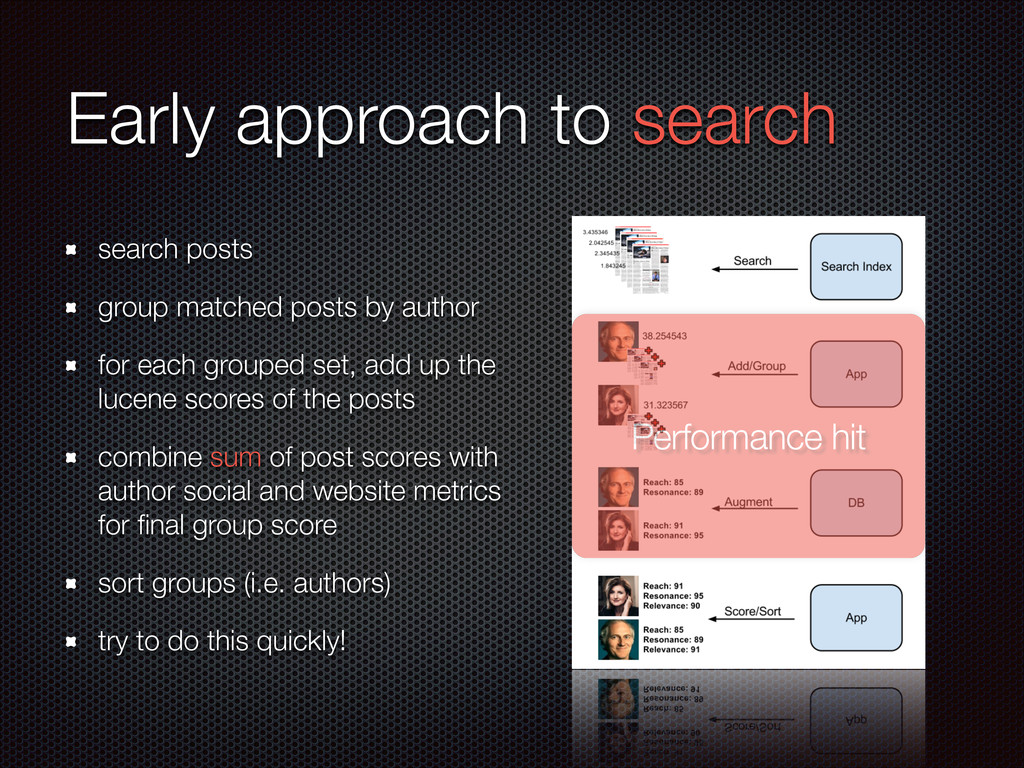
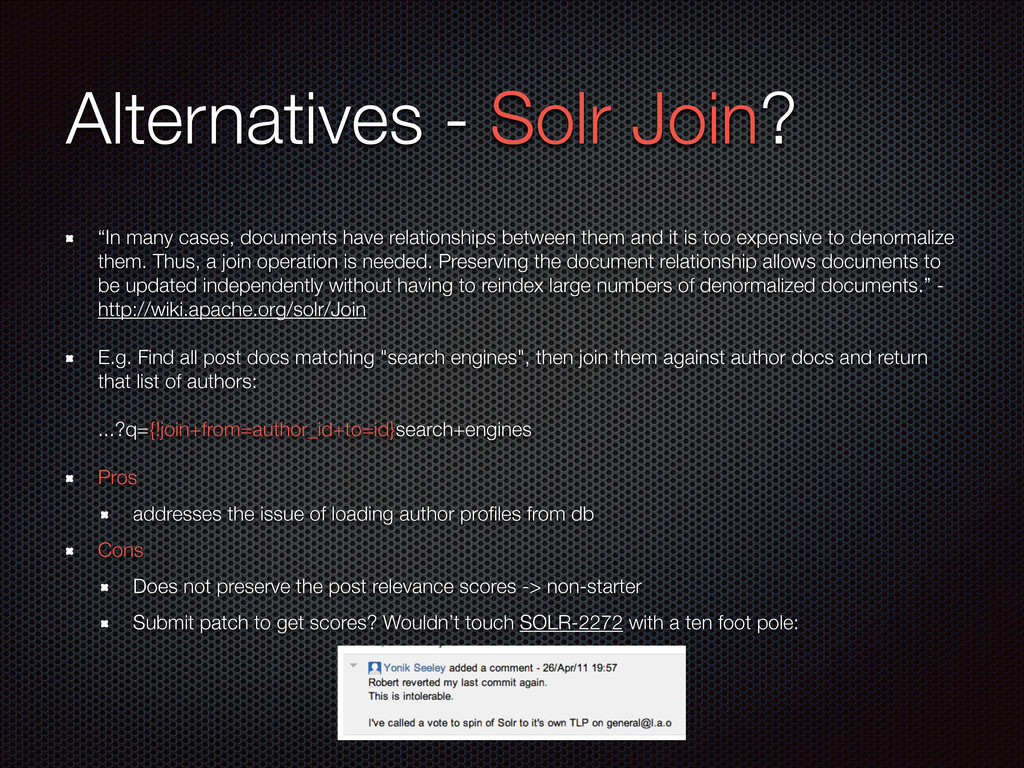
Presented on 10/11/12 at the Boston Elasticsearch meetup held at the Microsoft New England Research & Development Center. This talk gave a very high-level overview of Elasticsearch to newcomers and explained why ES is a good fit for Traackr's use case.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}