Finding the right NoSQL DB for the job - The path to a non-RDBMS solution at Traackr
A walkthrough of Traackr's experience in choosing a NoSQL solution and how we ended up up switching from HBase to MongoDB. This deck goes through some in depth technical aspects, like schema design and our use of secondary indexes.
building full-‐stack web soKware systems with a past focus on e-‐commerce and publishing. Currently responsible for building engineering capability to enable Traackr's growth goals.
exactly which ques>ons you wanted to ask, which drove a very predictable collec>on and storage model. In the new world of data analysis your ques>ons are going to evolve and change over >me and as such you need to be able to collect, store and analyze data without being constrained by resources.” — Werner Vogels, CTO/VP Amazon.com
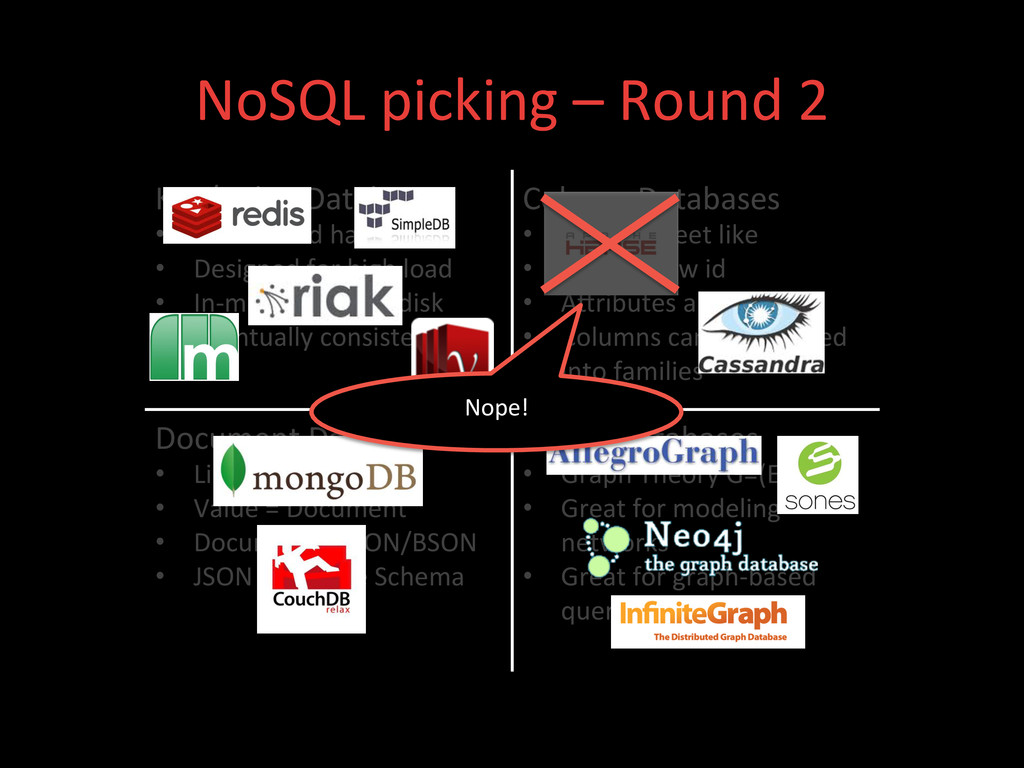
hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms
hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms
• Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Graph Databases: while we can model our domain as a graph we don’t want to pigeonhole ourselves into this structure. We’d rather use these tools for specialized data analysis but not as the main data store.
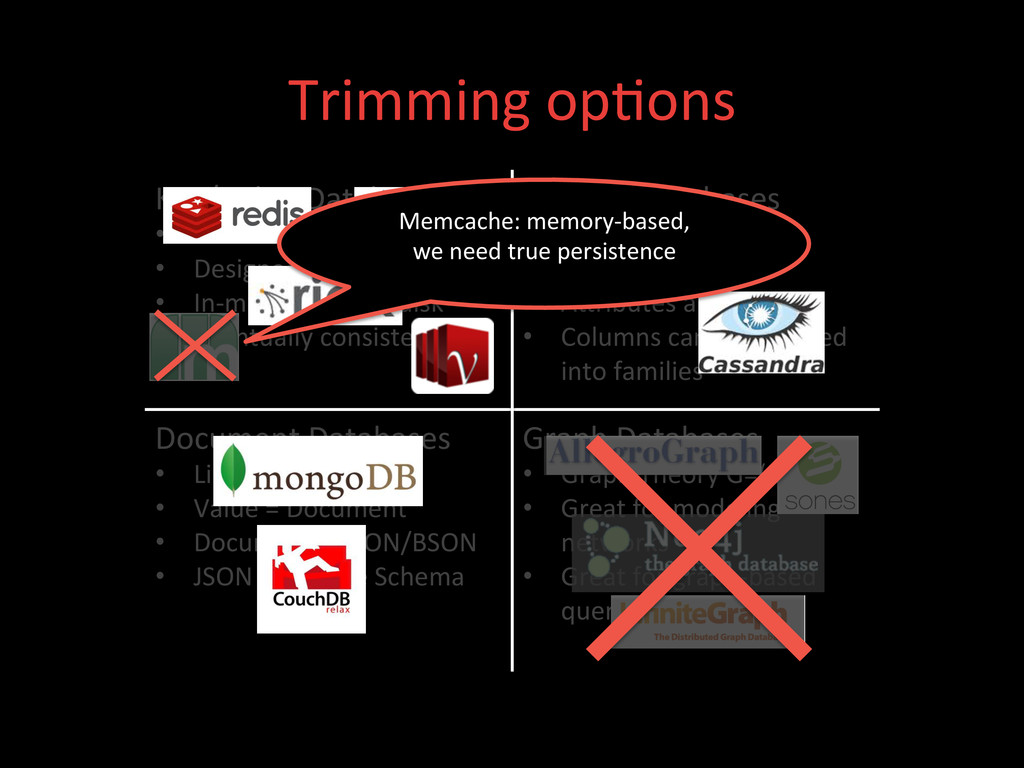
• Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Memcache: memory-‐based, we need true persistence
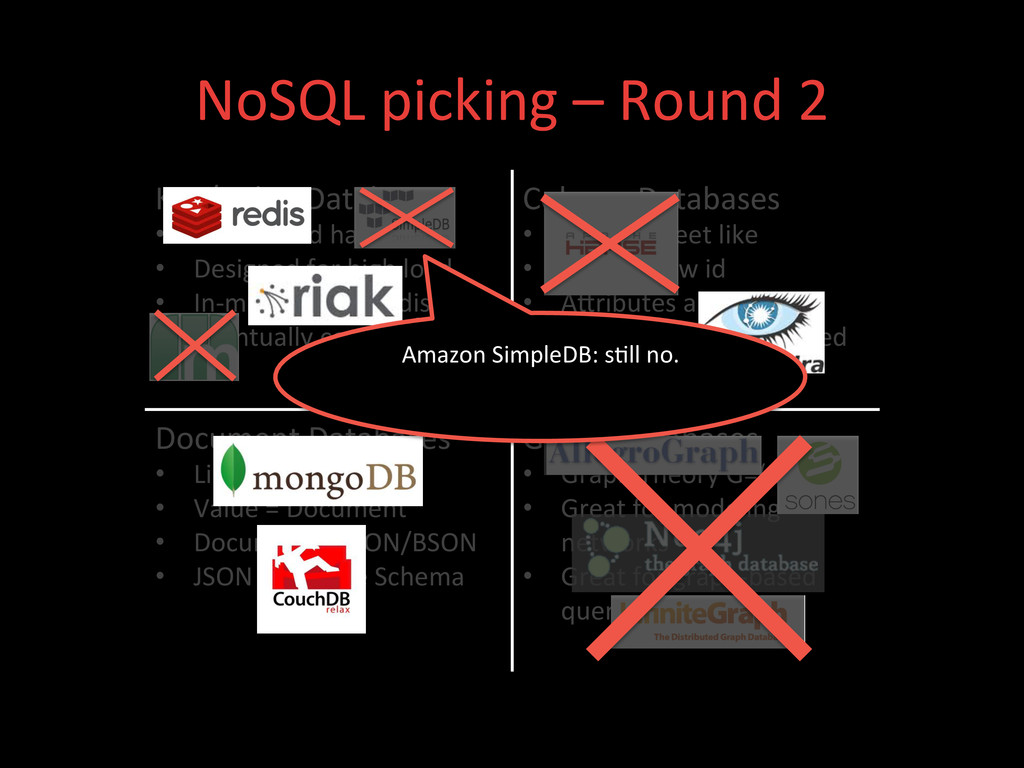
• Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Amazon SimpleDB: not willing to store our data in a proprietary datastore.
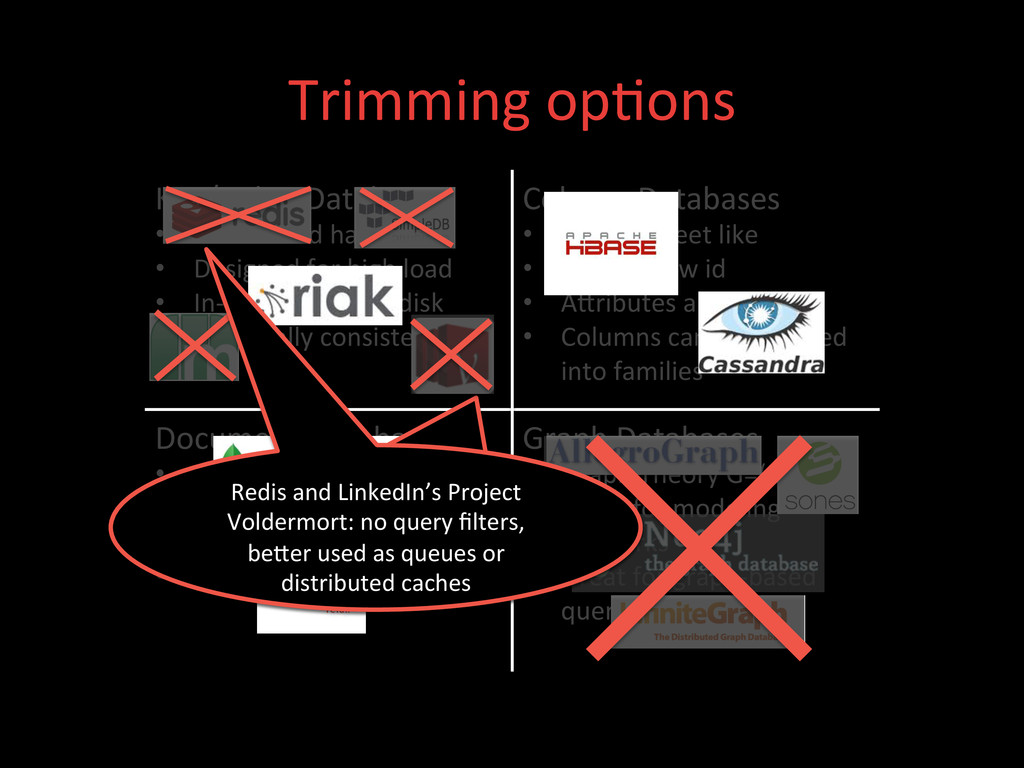
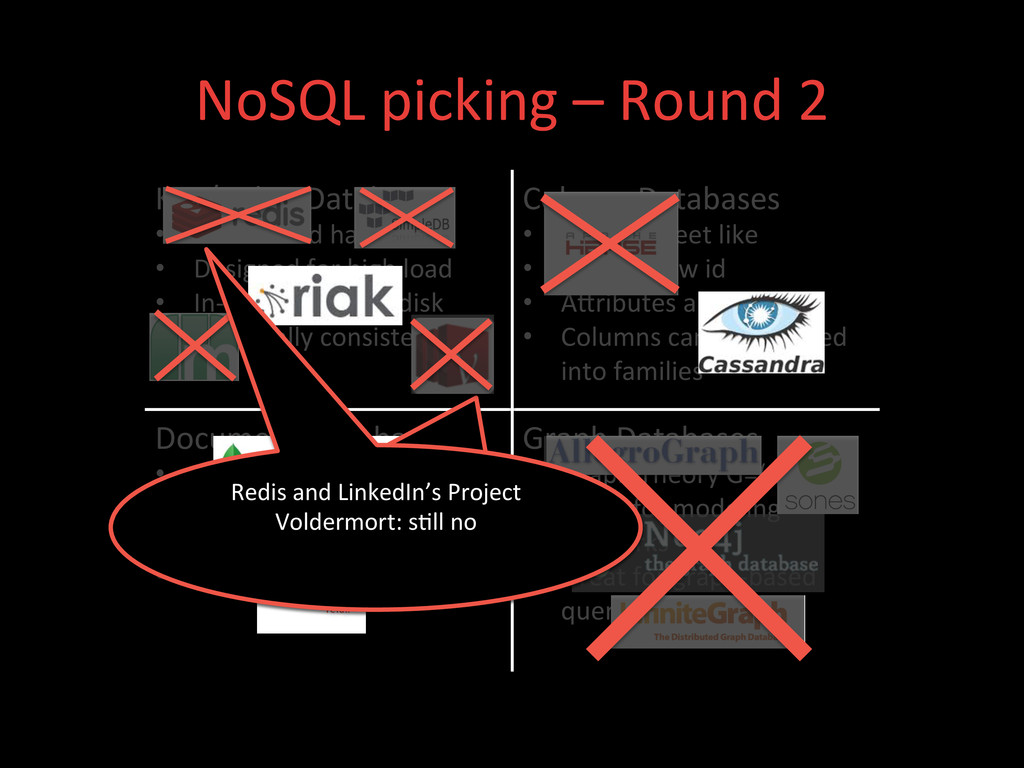
• Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Not willing to store our data in a proprietary datastore. Redis and LinkedIn’s Project Voldermort: no query filters, beXer used as queues or distributed caches
• Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms CouchDB: no ad-‐hoc queries; maturity in early 2010 made us shy away although we did try early prototypes.
• Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Cassandra: in early 2010, maturity ques>ons, no secondary indexes and no batch processing op>ons (came later on).
• Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms MongoDB: in early 2010, maturity ques>ons, adop>on ques>ons and no batch processing op>ons.
• Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Riak: very close but in early 2010, we had adop>on ques>ons.
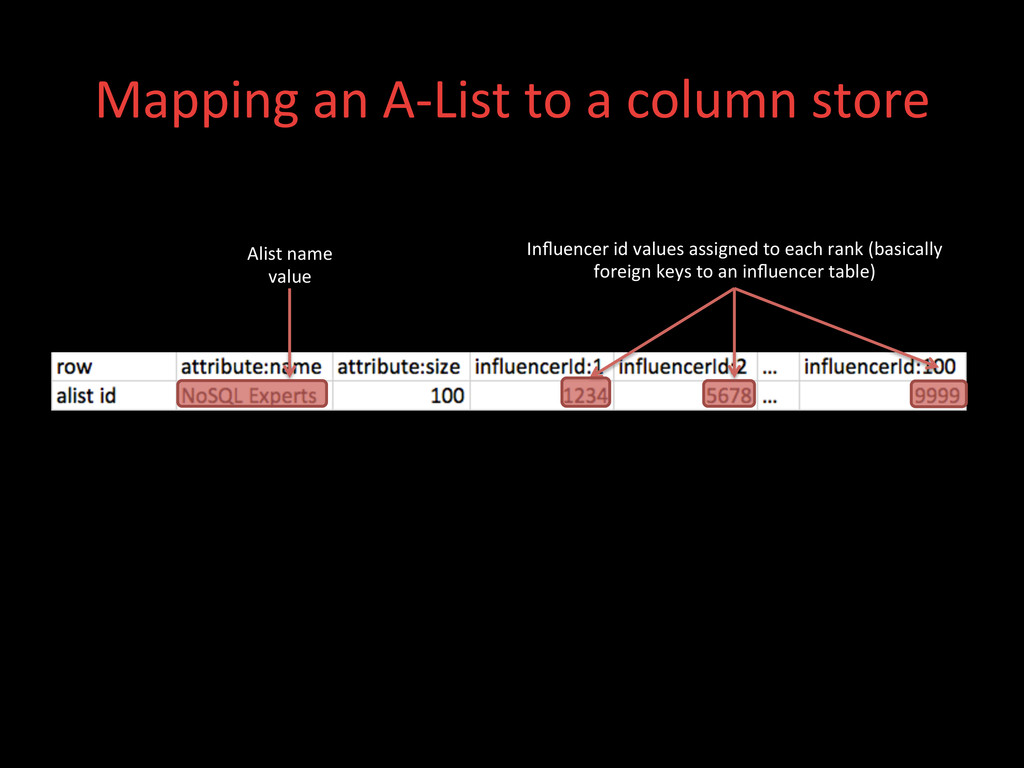
• Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms HBase: came across as the most mature at the >me, with several deployments, a healthy community, "out-‐of-‐the box" secondary indexes through a contrib and support for batch processing using Hadoop/MR .
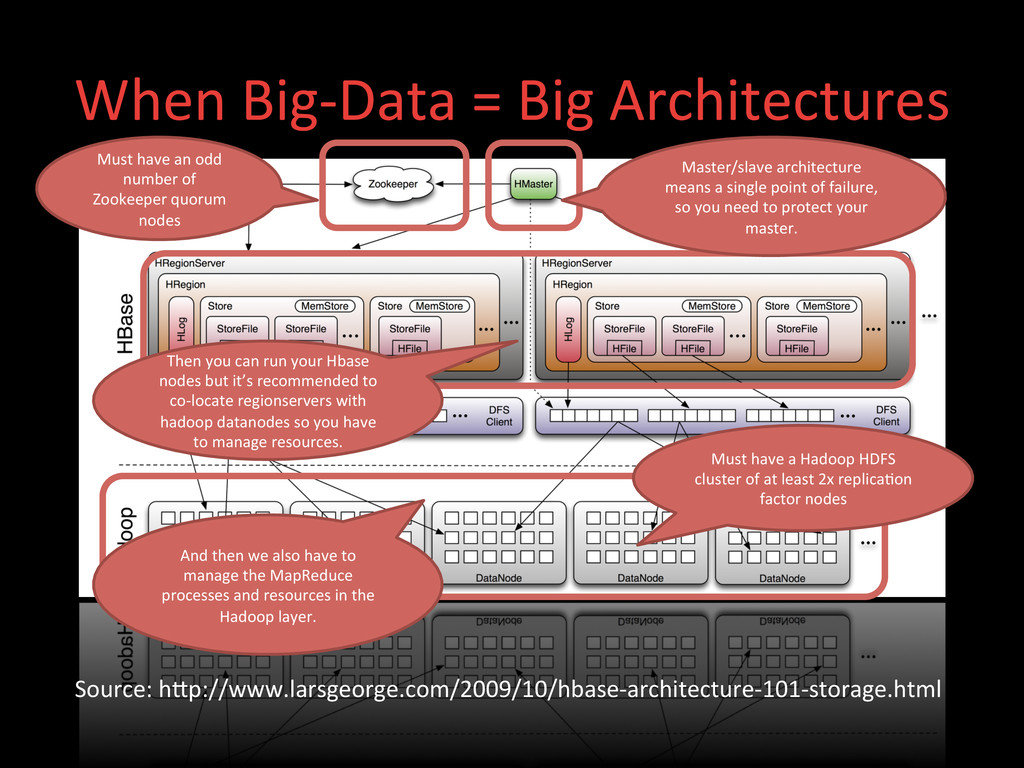
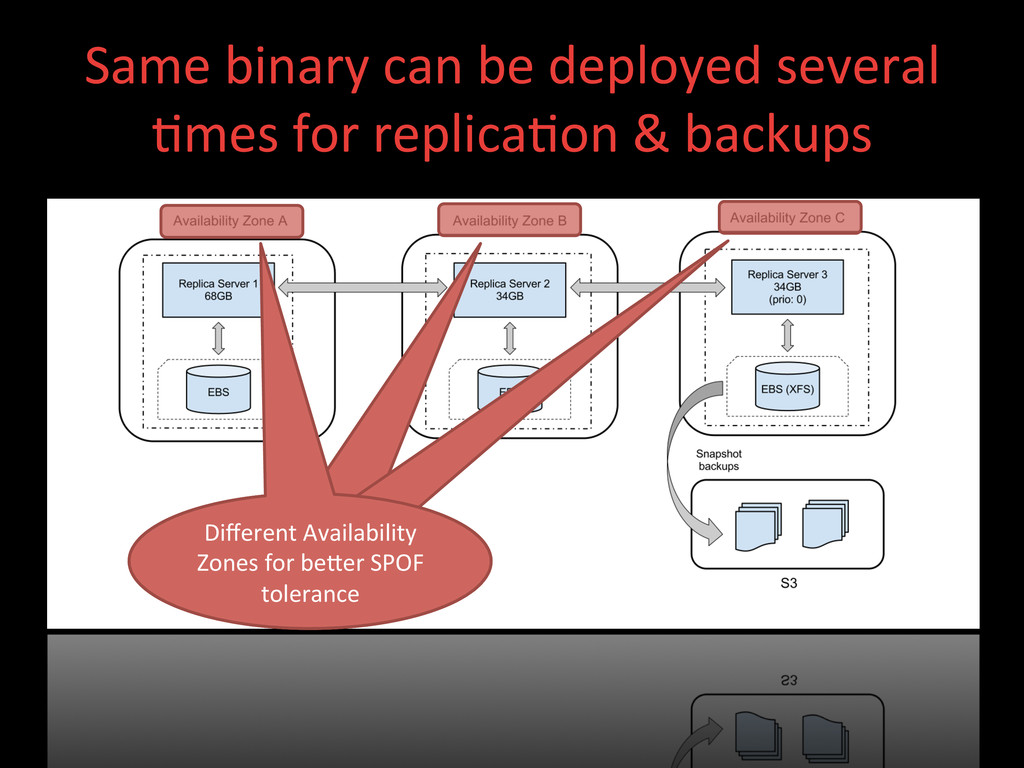
have a Hadoop HDFS cluster of at least 2x replica>on factor nodes Must have an odd number of Zookeeper quorum nodes Then you can run your Hbase nodes but it’s recommended to co-‐locate regionservers with hadoop datanodes so you have to manage resources. Master/slave architecture means a single point of failure, so you need to protect your master. And then we also have to manage the MapReduce processes and resources in the Hadoop layer.
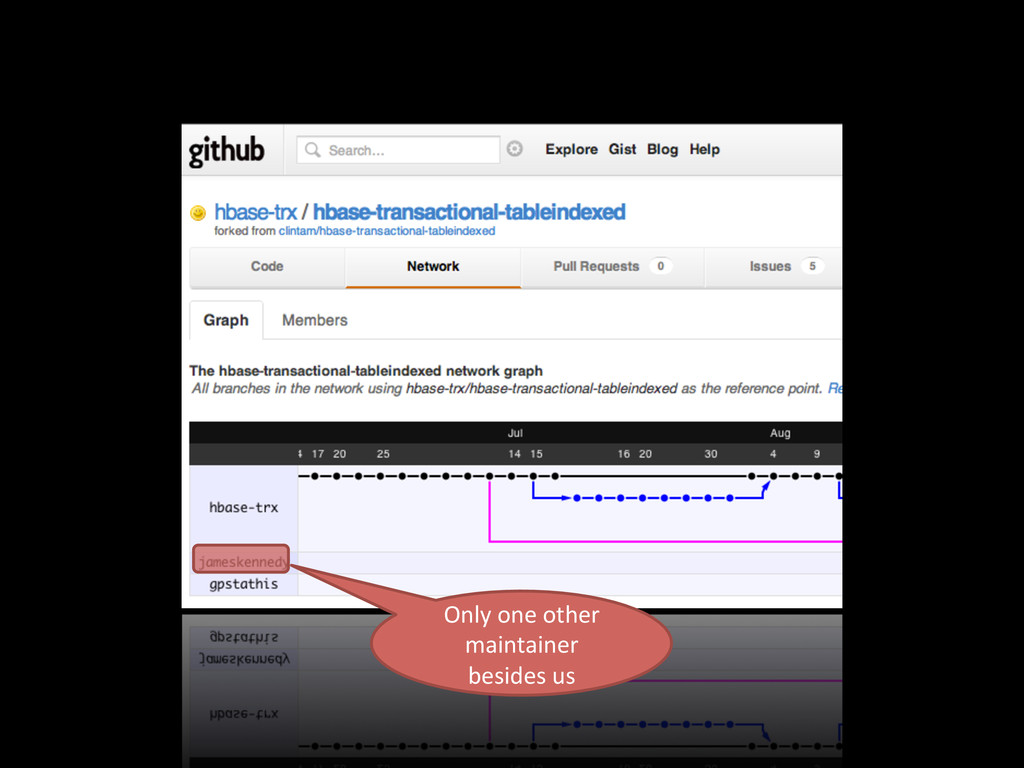
with secondary indexing out-‐of-‐the-‐box • It’s been moved out of the trunk to GitHub • Where only one other company besides us seems to care about it
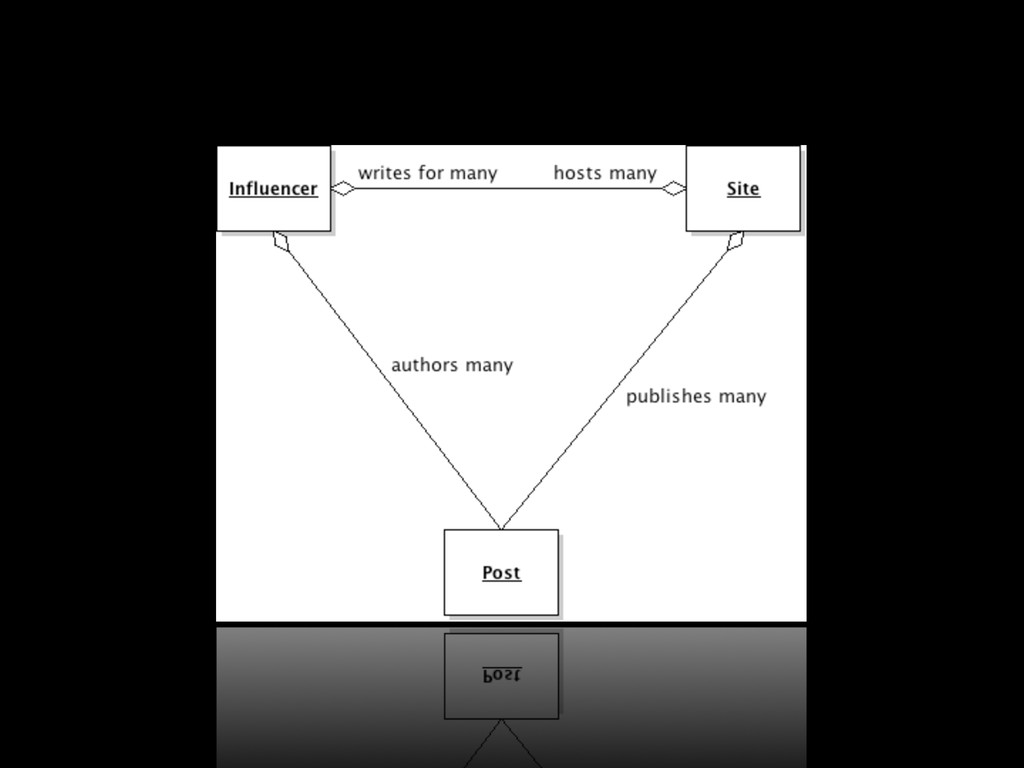
hXp://www.huffingtonpost.com/arianna-‐huffington/post_1.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_2.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_3.html hXp://www.huffingtonpost.com/shaun-‐donovan/post1.html hXp://www.huffingtonpost.com/shaun-‐donovan/post2.html hXp://www.huffingtonpost.com/shaun-‐donovan/post3.html writes for authored by published under writes for authored by published under
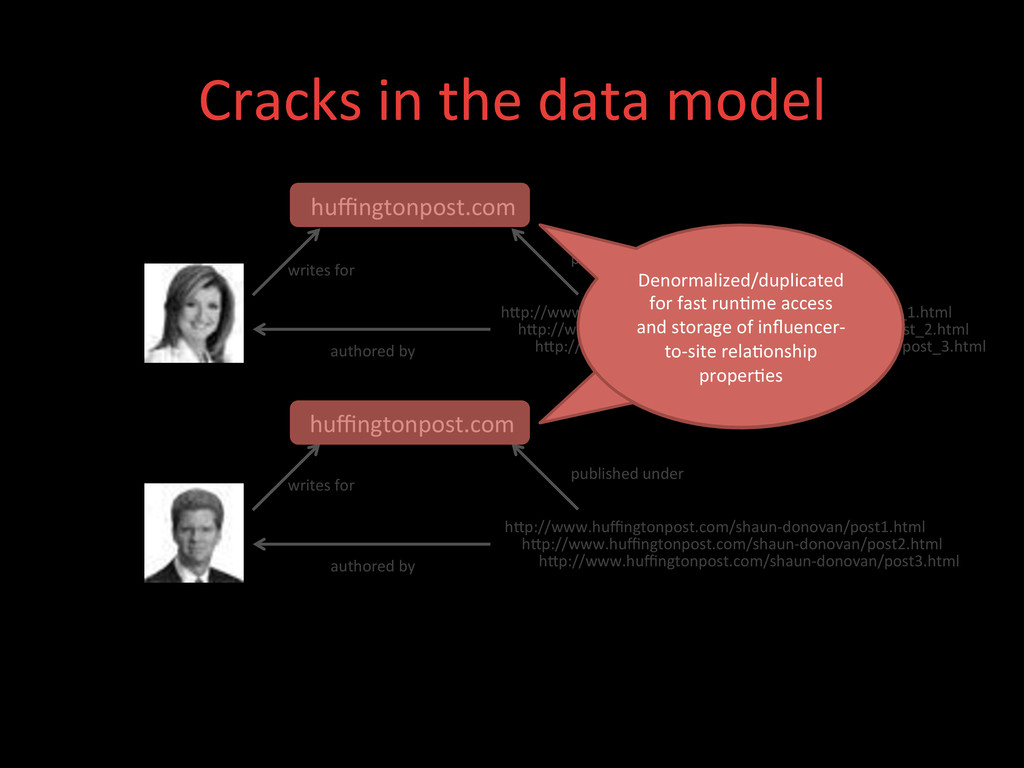
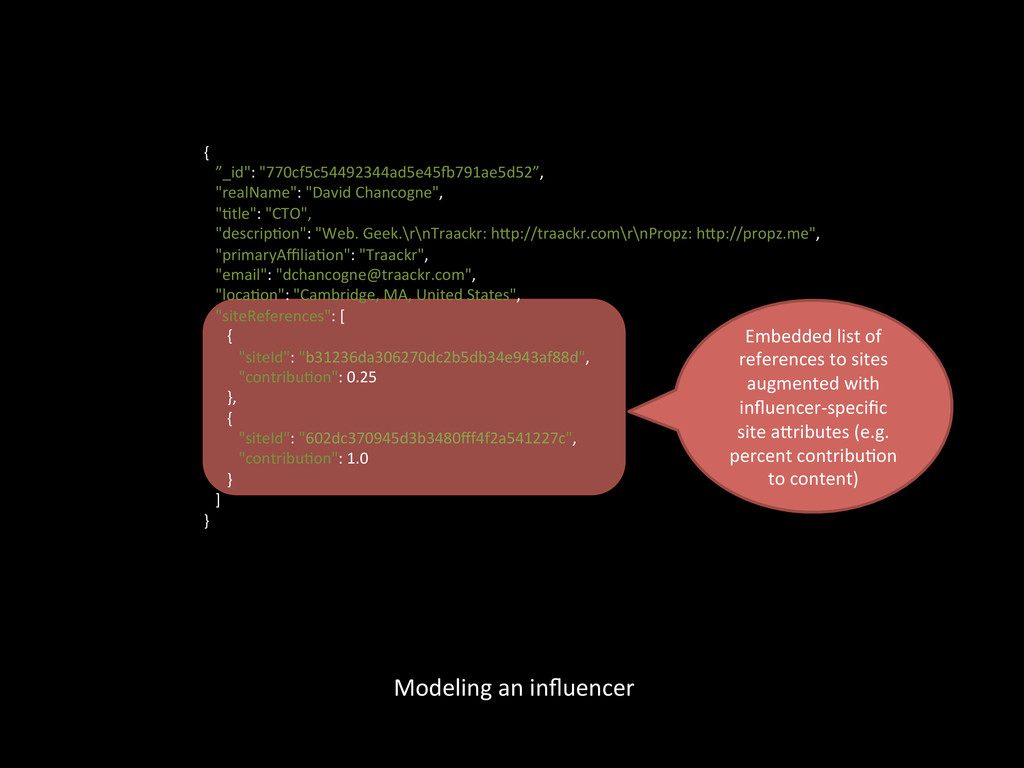
hXp://www.huffingtonpost.com/arianna-‐huffington/post_1.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_2.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_3.html hXp://www.huffingtonpost.com/shaun-‐donovan/post1.html hXp://www.huffingtonpost.com/shaun-‐donovan/post2.html hXp://www.huffingtonpost.com/shaun-‐donovan/post3.html writes for authored by published under writes for authored by published under Denormalized/duplicated for fast run>me access and storage of influencer-‐ to-‐site rela>onship proper>es
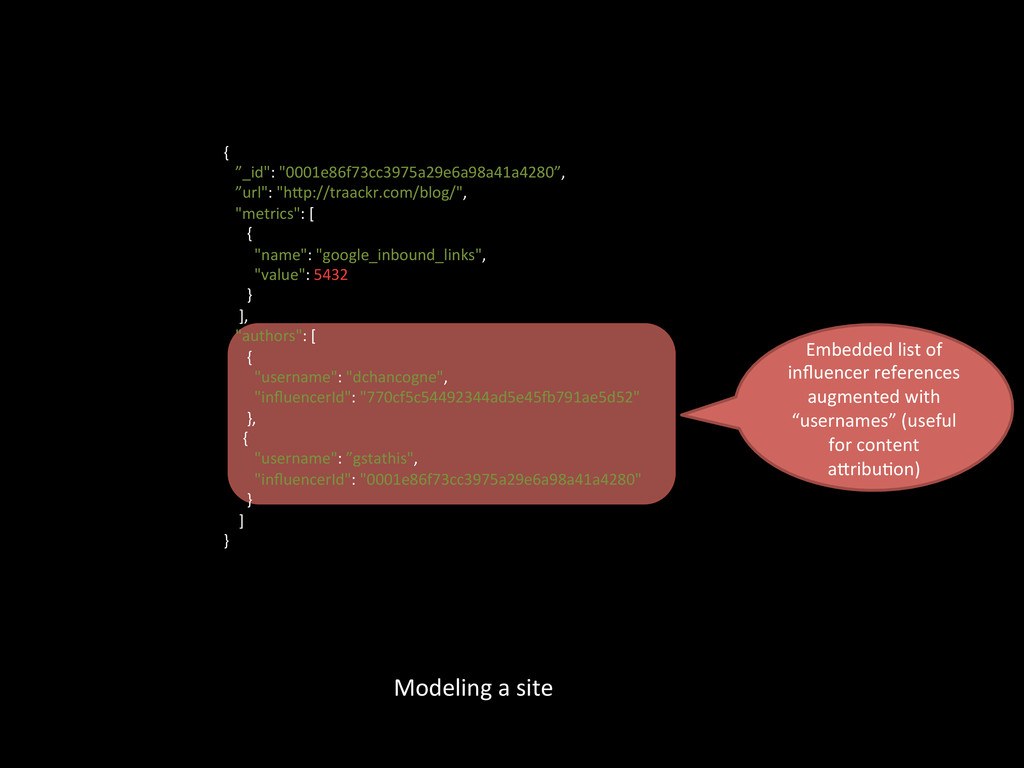
hXp://www.huffingtonpost.com/arianna-‐huffington/post_1.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_2.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_3.html hXp://www.huffingtonpost.com/shaun-‐donovan/post1.html hXp://www.huffingtonpost.com/shaun-‐donovan/post2.html hXp://www.huffingtonpost.com/shaun-‐donovan/post3.html writes for authored by published under writes for authored by published under Content aXribu>on logic could some>mes mis-‐aXribute posts because of the duplicated data.
hXp://www.huffingtonpost.com/arianna-‐huffington/post_1.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_2.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_3.html hXp://www.huffingtonpost.com/shaun-‐donovan/post1.html hXp://www.huffingtonpost.com/shaun-‐donovan/post2.html hXp://www.huffingtonpost.com/shaun-‐donovan/post3.html writes for authored by published under writes for authored by published under Exacerbated when we started tracking people’s content on a daily basis in mid-‐2011
hXp://www.huffingtonpost.com/arianna-‐huffington/post_1.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_2.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_3.html hXp://www.huffingtonpost.com/shaun-‐donovan/post1.html hXp://www.huffingtonpost.com/shaun-‐donovan/post2.html hXp://www.huffingtonpost.com/shaun-‐donovan/post3.html writes for authored by published under writes for authored by published under
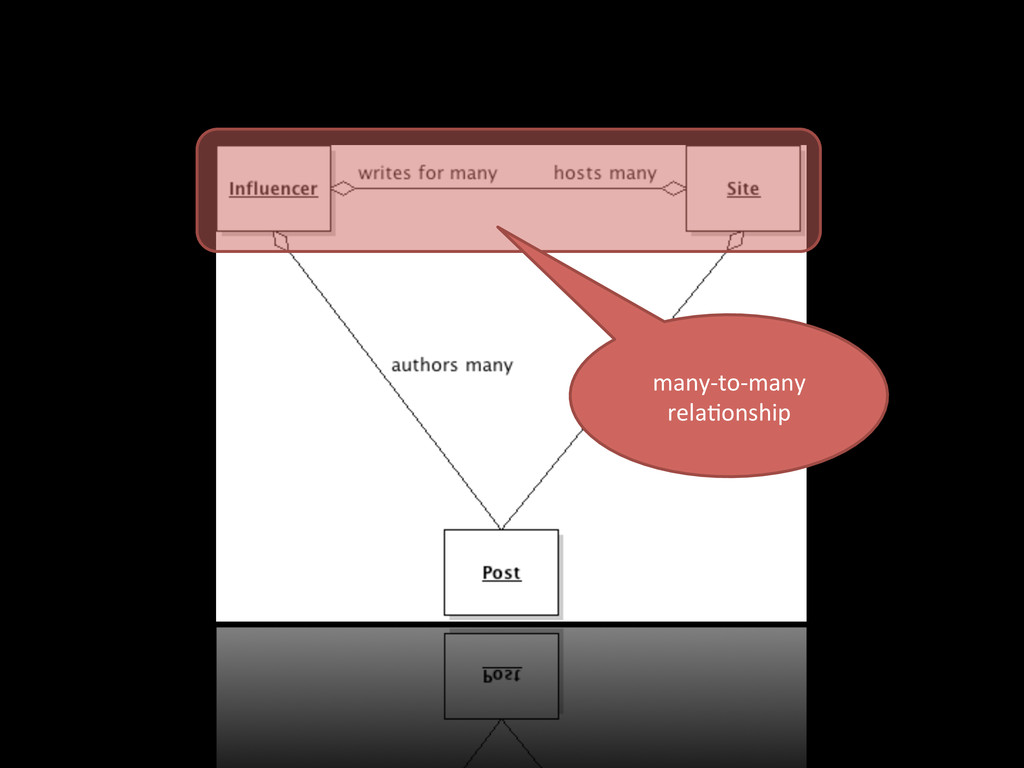
hXp://www.huffingtonpost.com/arianna-‐huffington/post_1.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_2.html hXp://www.huffingtonpost.com/arianna-‐huffington/post_3.html hXp://www.huffingtonpost.com/shaun-‐donovan/post1.html hXp://www.huffingtonpost.com/shaun-‐donovan/post2.html hXp://www.huffingtonpost.com/shaun-‐donovan/post3.html writes for authored by published under writes for authored by published under Normalize the sites
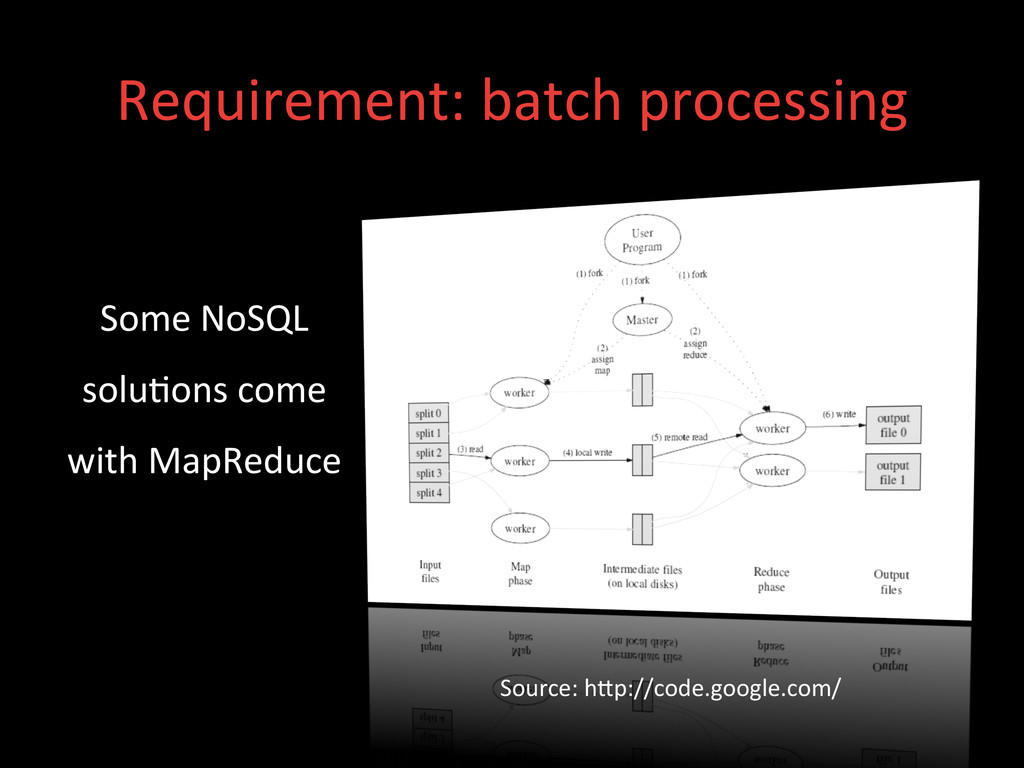
• Good at storing lots of variable length text • Batch processing op>ons (maybe) • Out-‐of-‐the-‐box SECONDARY INDEX support! • Simple to use and administer
Distributed hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms
Distributed hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Nope!
Distributed hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Graph Databases: we looked at Neo4J a bit closer but passed again for the same reasons as before.
Distributed hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Memcache: s>ll no
Distributed hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Amazon SimpleDB: s>ll no.
Distributed hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Not willing to store our data in a proprietary datastore. Redis and LinkedIn’s Project Voldermort: s>ll no
Distributed hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms CouchDB: more mature but s>ll no ad-‐hoc queries.
Distributed hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Cassandra: matured quite a bit, added secondary indexes and batch processing op>ons but more restric>ve in its’ use than other solu>ons. AKer the Hbase lesson, simplicity of use was now more important.
Distributed hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms Riak: strong contender s>ll but adop>on ques>ons remained.
Distributed hashtables • Designed for high load • In-‐memory or on-‐disk • Eventually consistent Column Databases • Spread sheet like • Key is a row id • AXributes are columns • Columns can be grouped into families Document Databases • Like Key/Value • Value = Document • Document = JSON/BSON • JSON = Flexible Schema Graph Databases • Graph Theory G=(E,V) • Great for modeling networks • Great for graph-‐based query algorithms MongoDB: matured by leaps and bounds, increased adop>on, support from 10gen, advanced indexing out-‐of-‐the-‐box as well as some batch processing op>ons, breeze to use, well documented and fit into our exis>ng code base very nicely.
easier to write with JavaScript: no need for a Java developer to write map reduce code to extract the data in a usable form like it was needed with Hbase.
Purpose: report the count of twitter URLs for which we have! // computed the the number of total retweets! print( "NUMBER OF TWITTER URLS where retweetTotal IS SET:" );! print( db.sites.find( { platformName: "twitter.com", ! retweetTotal: { $exists: true } } ).count() );! ! • Easy to execute JS report script remotely: ! > mongo <hostname>:<port>/traackr --quiet retweetTotal.js! ! • Run as a cron job, pipe the output to a file and email it out • Also, more complex MR-‐based reports are easily accessible to someone with some JavaScript knowledge
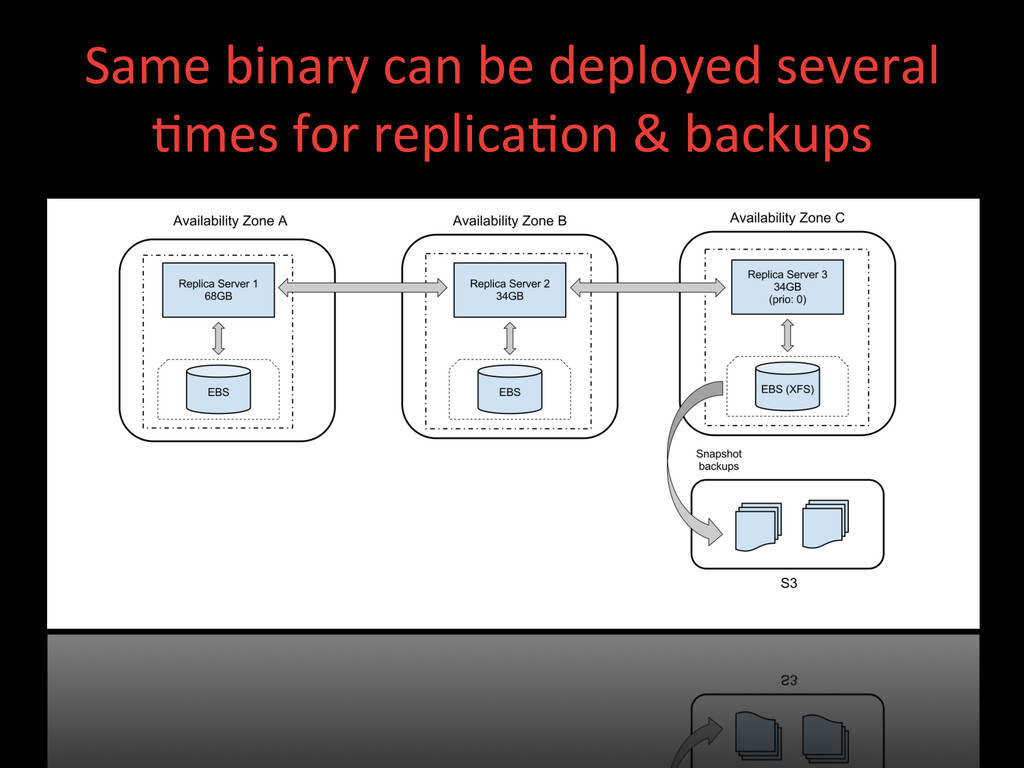
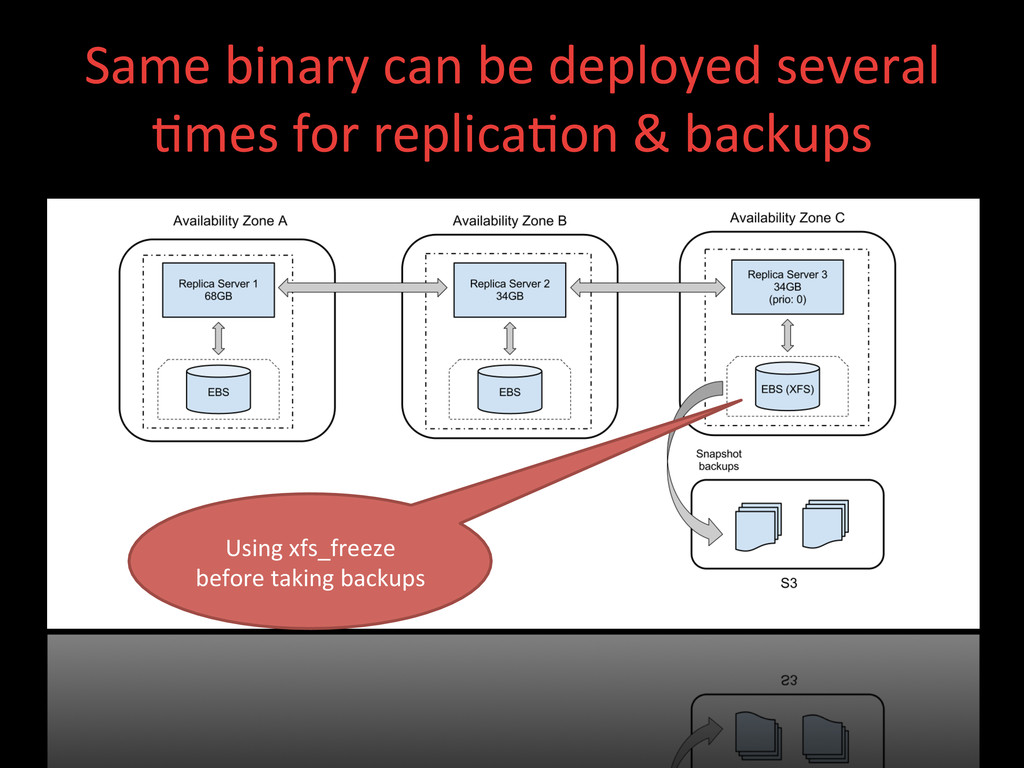
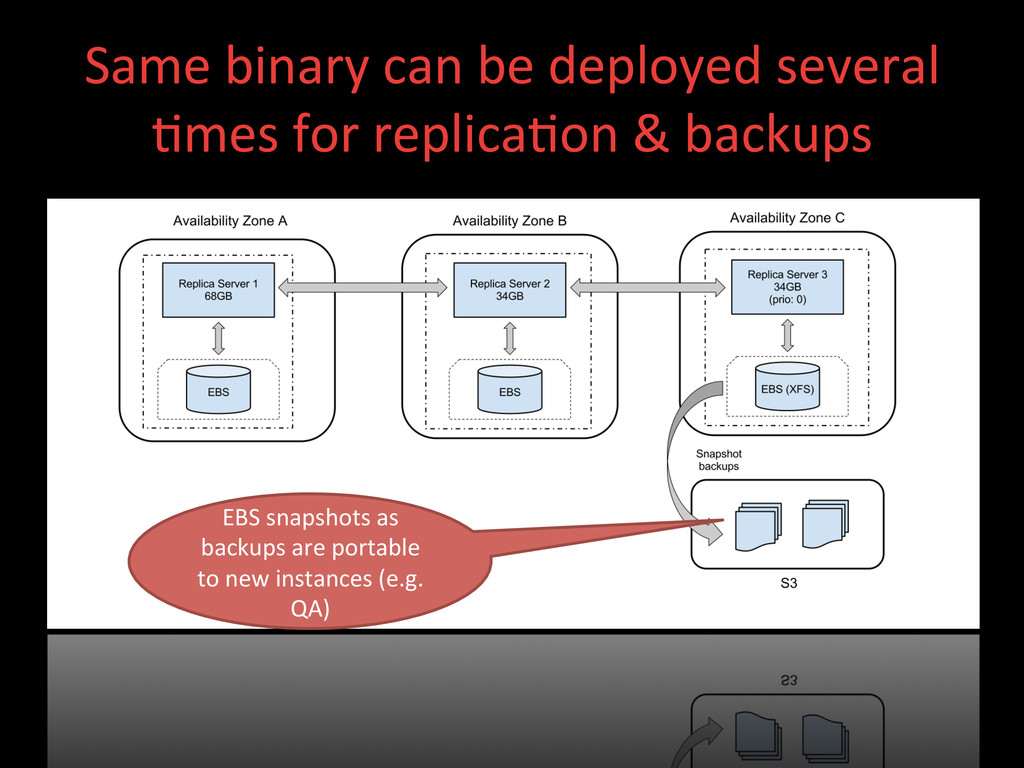
became easier to write with JavaScript: no need for a Java developer to write map reduce code to extract the data in a usable form like it was needed with Hbase. • Simpler backups: Hbase mostly relied on HDFS redundancy; intra-‐ cluster replica>on is available but experimental and a lot more involved to setup.
became easier to write with JavaScript: no need for a Java developer to write map reduce code to extract the data in a usable form like it was needed with Hbase. • Simpler backups: Hbase mostly relied on HDFS redundancy; intra-‐ cluster replica>on is available but experimental and a lot more involved to setup. • Great documenta>on • Great adop>on and community
enough for our data size to be able to serially score the DB faster than the MapReduce jobs did in parallel. • When we grow larger, MapReduce is s>ll available as an op>on
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}