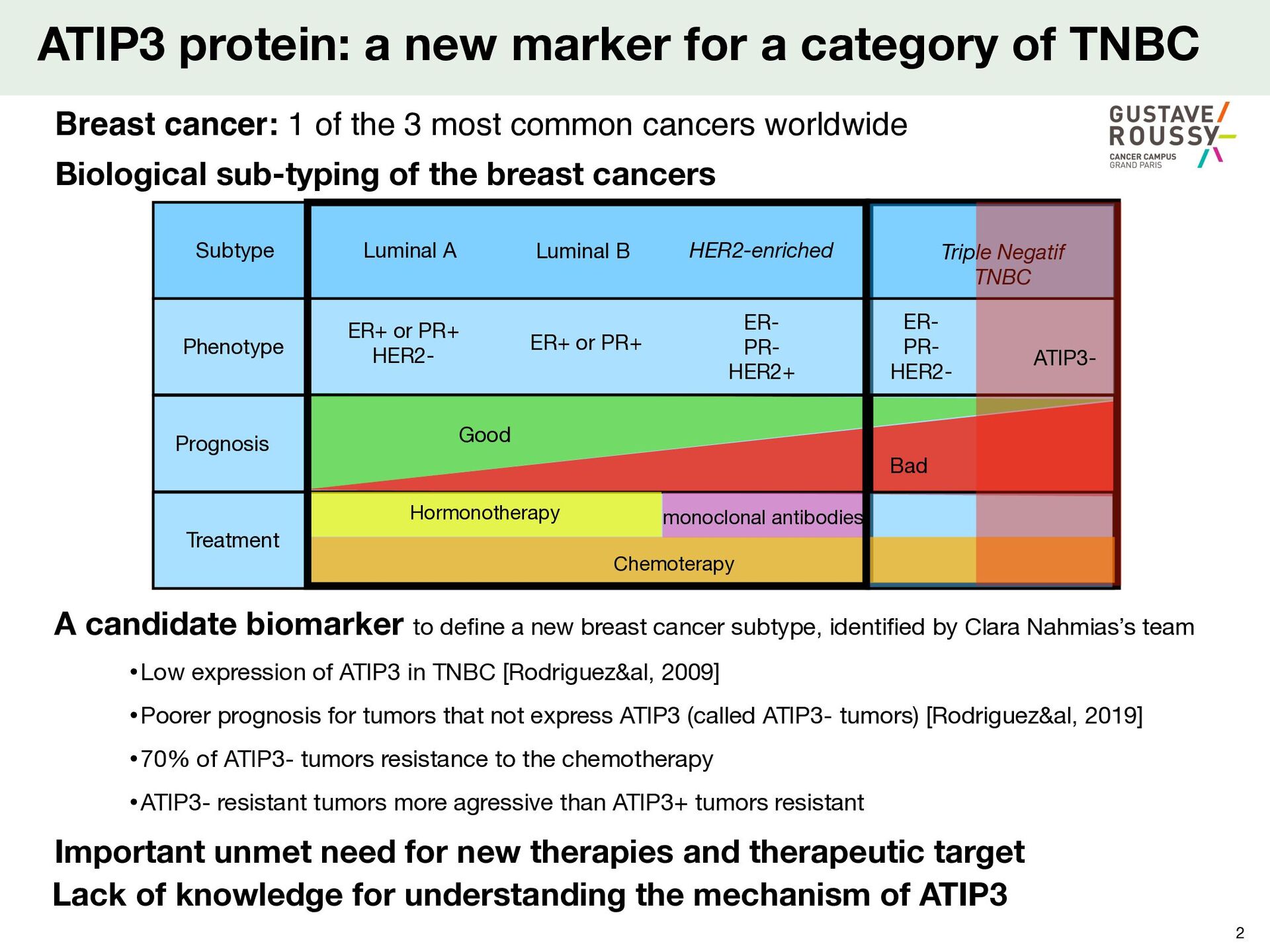
B Triple Negatif TNBC Phenotype Prognosis Treatment ER+ or PR+ HER2- ER+ or PR+ ER- PR- HER2- Good ER- PR- HER2+ ATIP3 protein: a new marker for a category of TNBC 2 Biological sub-typing of the breast cancers Breast cancer: 1 of the 3 most common cancers worldwide A candidate biomarker to de fi ne a new breast cancer subtype, identi fi ed by Clara Nahmias’s team •Low expression of ATIP3 in TNBC [Rodriguez&al, 2009] •Poorer prognosis for tumors that not express ATIP3 (called ATIP3- tumors) [Rodriguez&al, 2019] •70% of ATIP3- tumors resistance to the chemotherapy •ATIP3- resistant tumors more agressive than ATIP3+ tumors resistant Important unmet need for new therapies and therapeutic target Lack of knowledge for understanding the mechanism of ATIP3 ATIP3-
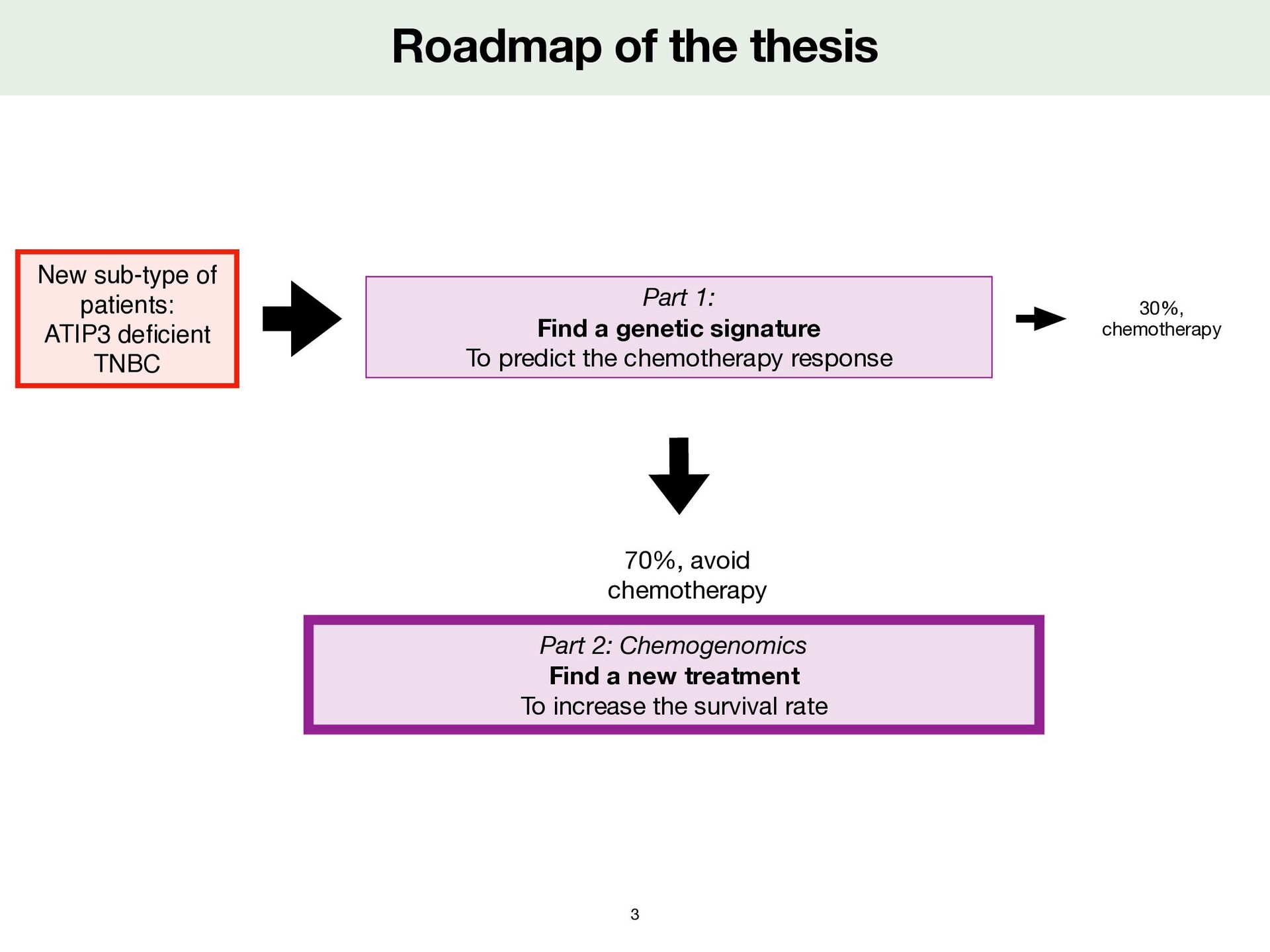
fi cient TNBC Part 1: Find a genetic signature To predict the chemotherapy response Part 2: Chemogenomics Find a new treatment To increase the survival rate 70%, avoid chemotherapy 30%, chemotherapy 3
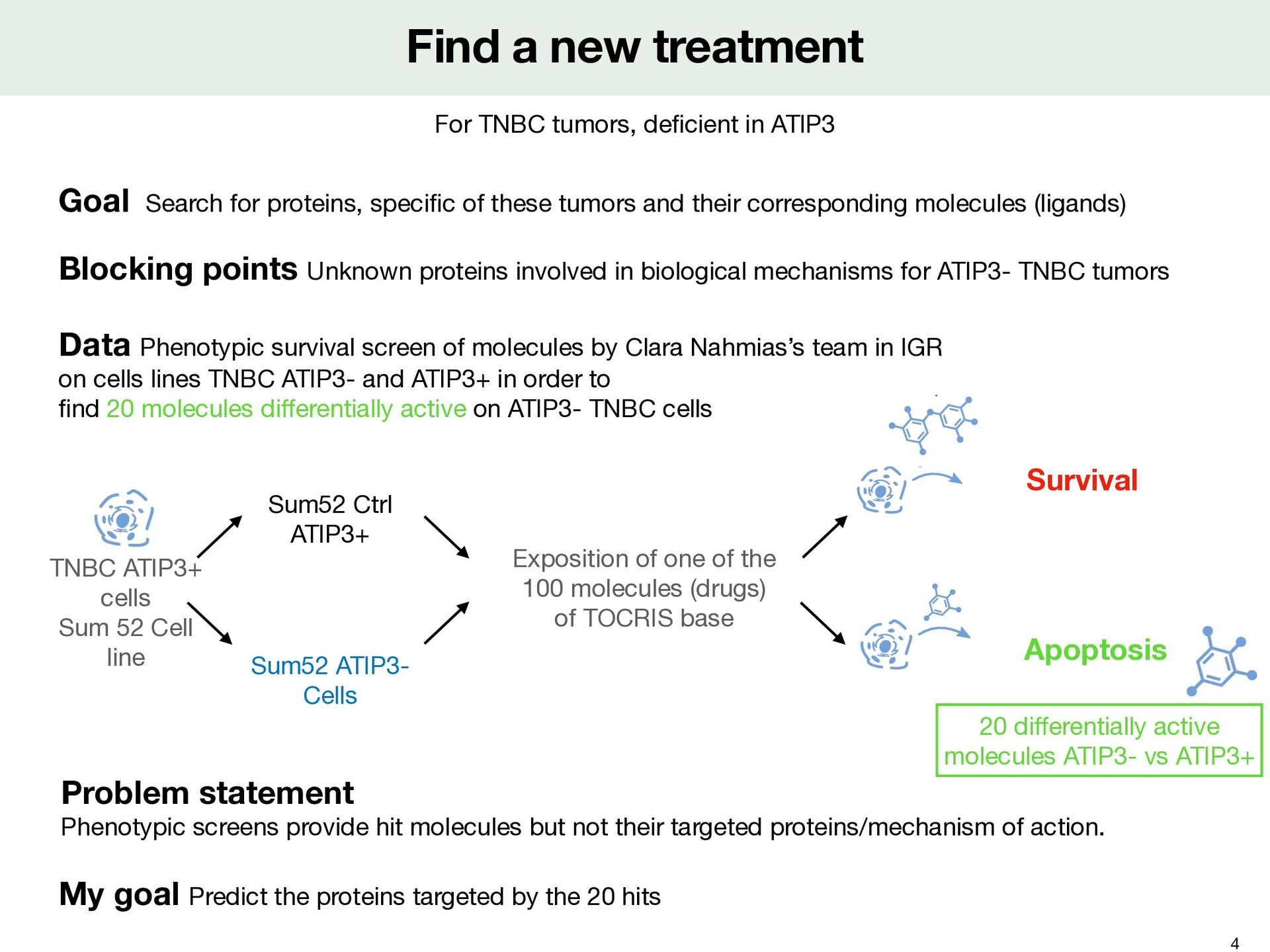
in ATIP3 Blocking points Unknown proteins involved in biological mechanisms for ATIP3- TNBC tumors Goal Search for proteins, speci fi c of these tumors and their corresponding molecules (ligands) 4 Data Phenotypic survival screen of molecules by Clara Nahmias’s team in IGR on cells lines TNBC ATIP3- and ATIP3+ in order to fi nd 20 molecules di ff erentially active on ATIP3- TNBC cells Survival TNBC ATIP3+ cells Sum 52 Cell line Sum52 ATIP3- Cells Sum52 Ctrl ATIP3+ Exposition of one of the 100 molecules (drugs) of TOCRIS base Apoptosis 20 di ff erentially active molecules ATIP3- vs ATIP3+ Problem statement Phenotypic screens provide hit molecules but not their targeted proteins/mechanism of action. My goal Predict the proteins targeted by the 20 hits
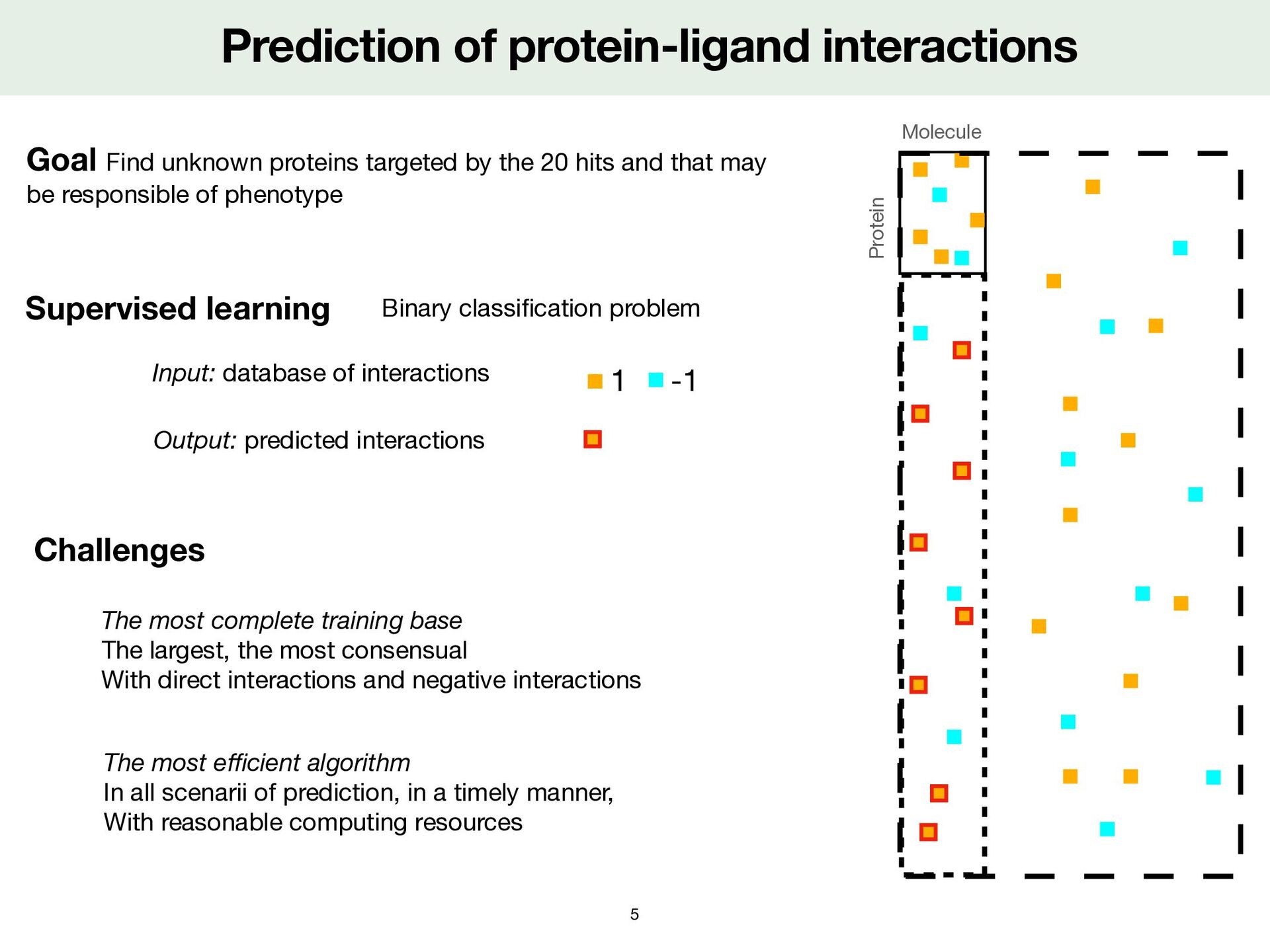
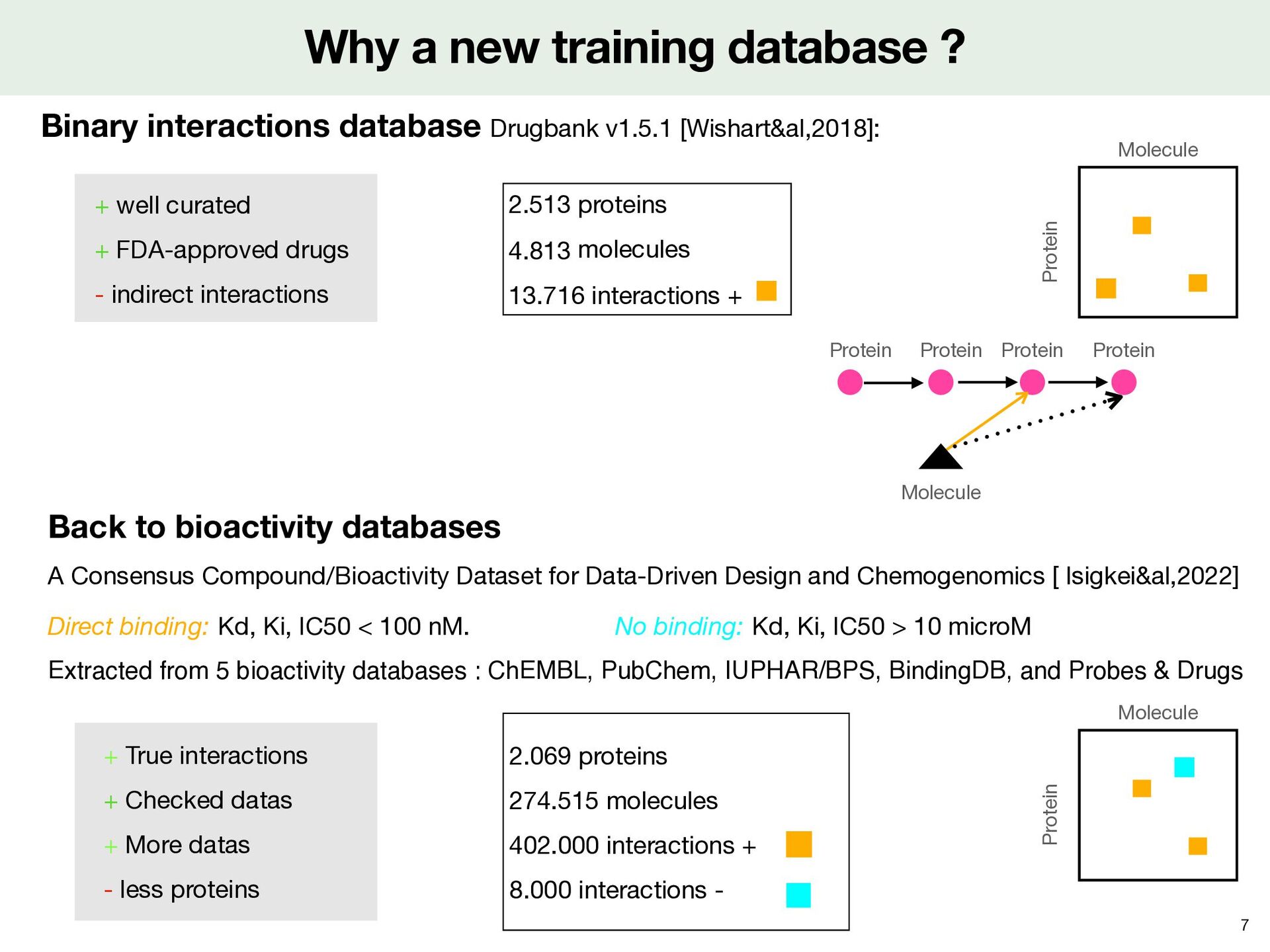
most complete training base The largest, the most consensual With direct interactions and negative interactions The most e ffi cient algorithm In all scenarii of prediction, in a timely manner, With reasonable computing resources Goal Find unknown proteins targeted by the 20 hits and that may be responsible of phenotype Output: predicted interactions Supervised learning Input: database of interactions Binary classi fi cation problem 1 -1
Construction Coverage of the protein and molecule spaces Komet: a Large-scale DTI prediction method Embeddings of proteins and molecules Interaction module DTI classi fi cation Results Parameters set-up of the model Impact of molecule and protein features Comparison of ML algorithms Case Study: A sca ff old hopping problem
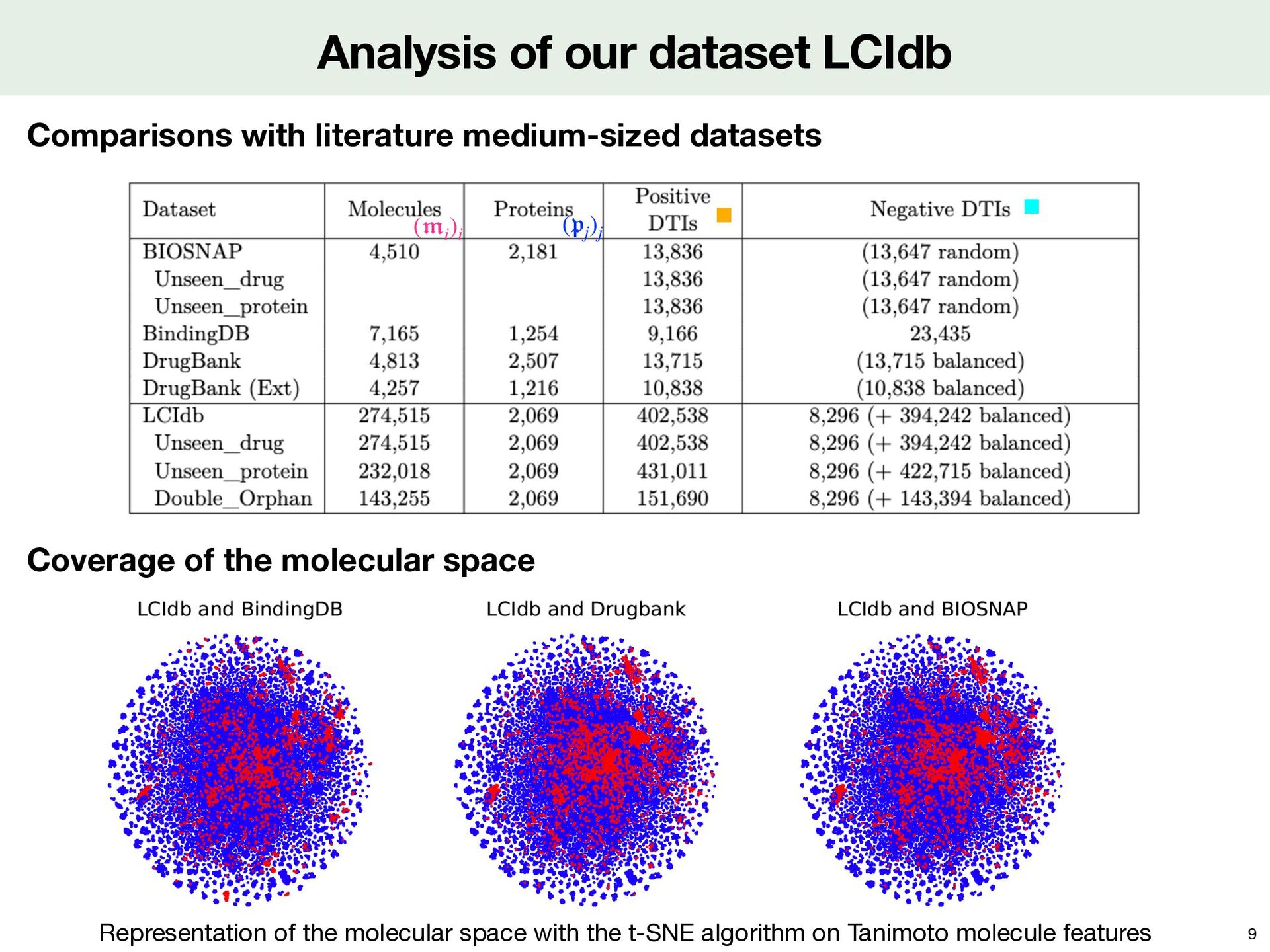
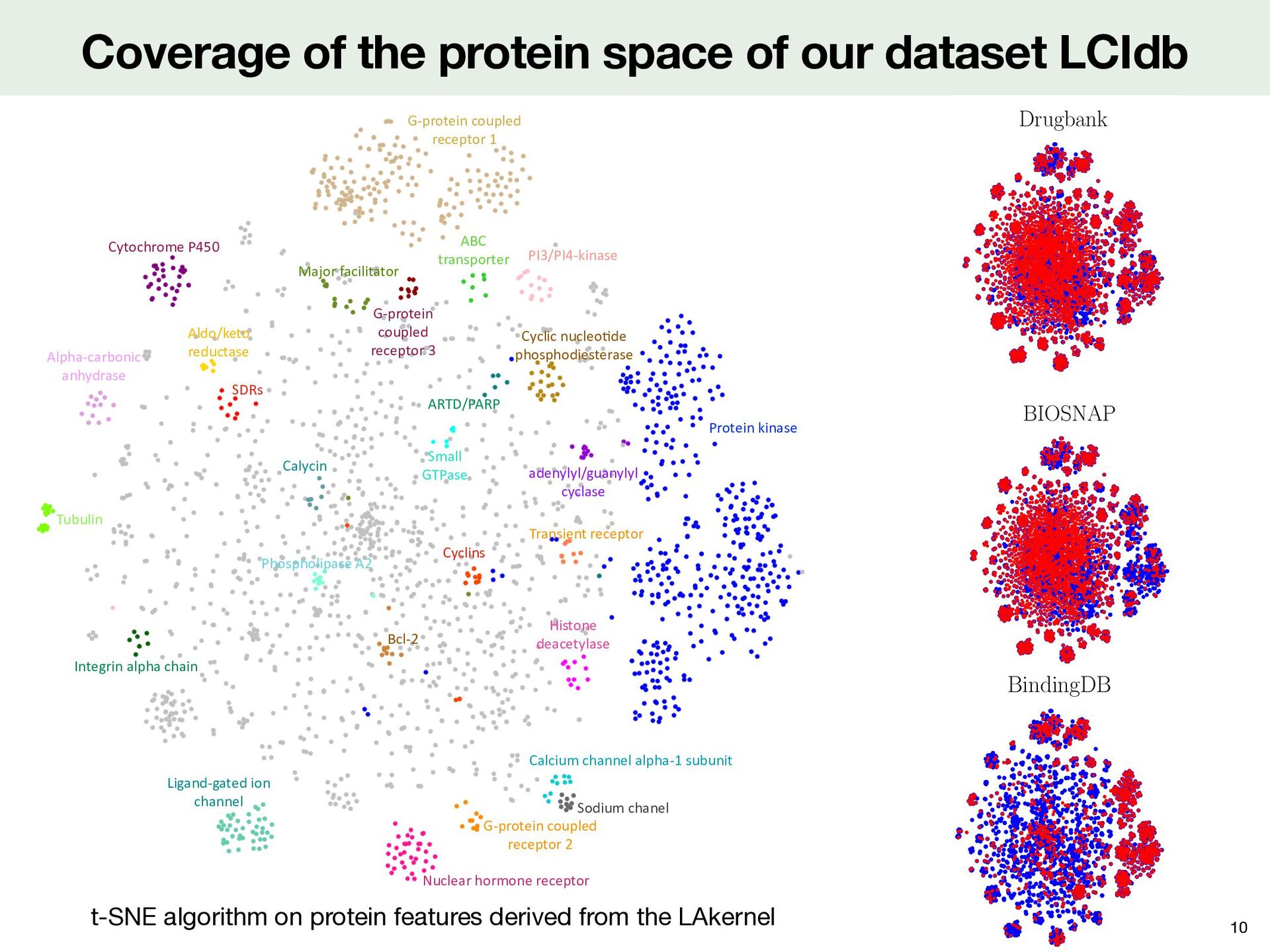
with the t-SNE algorithm on Tanimoto molecule features ( 𝔭 j )j ( 𝔪 i )i Comparisons with literature medium-sized datasets Coverage of the molecular space 9
Construction Coverage of the protein and molecule spaces Komet: a Large-scale DTI prediction method Embeddings of proteins and molecules Interaction module DTI classi fi cation Results Parameters set-up of the model Impact of molecule and protein features Comparison of ML algorithms Case Study: A sca ff old hopping problem
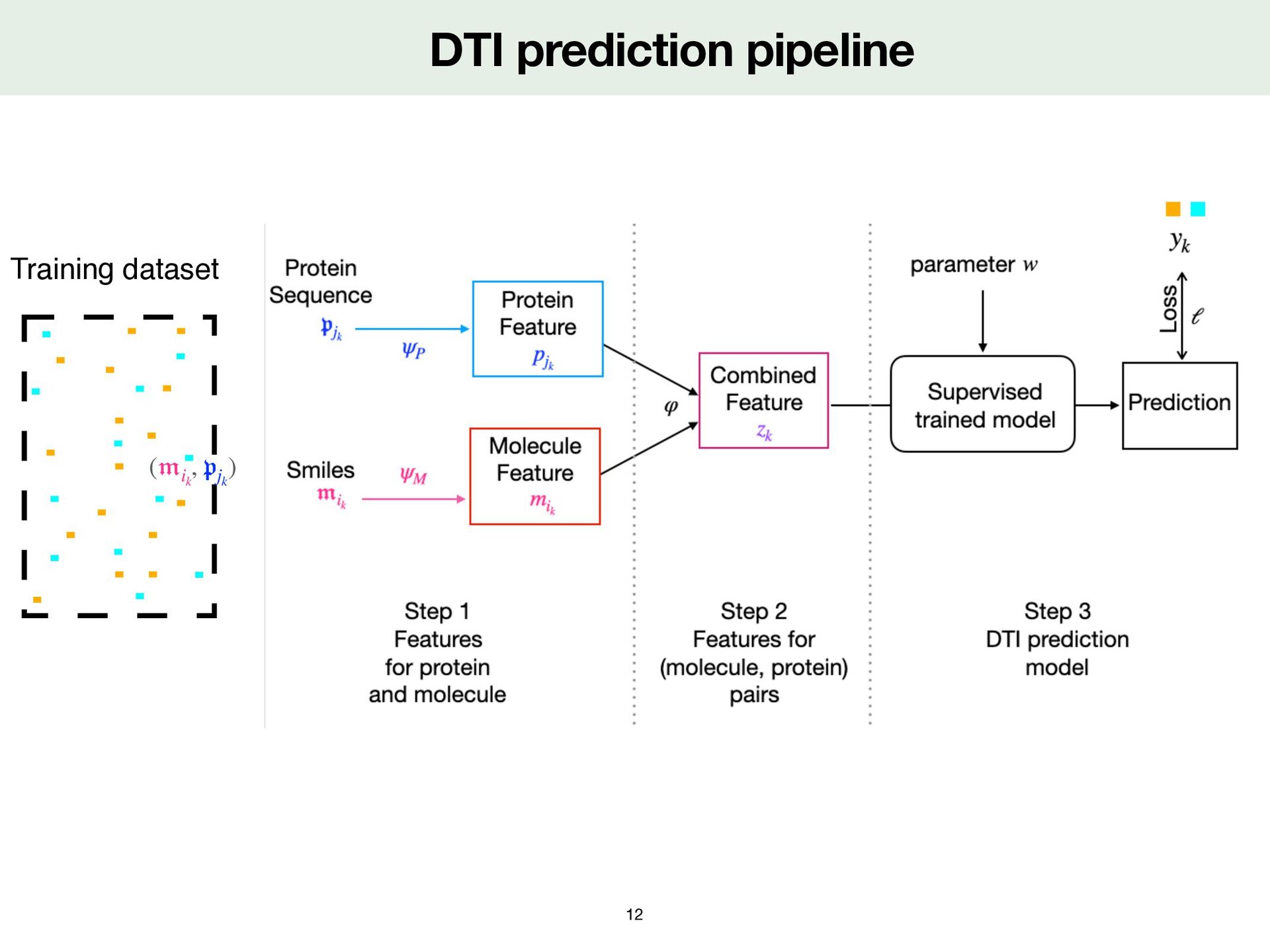
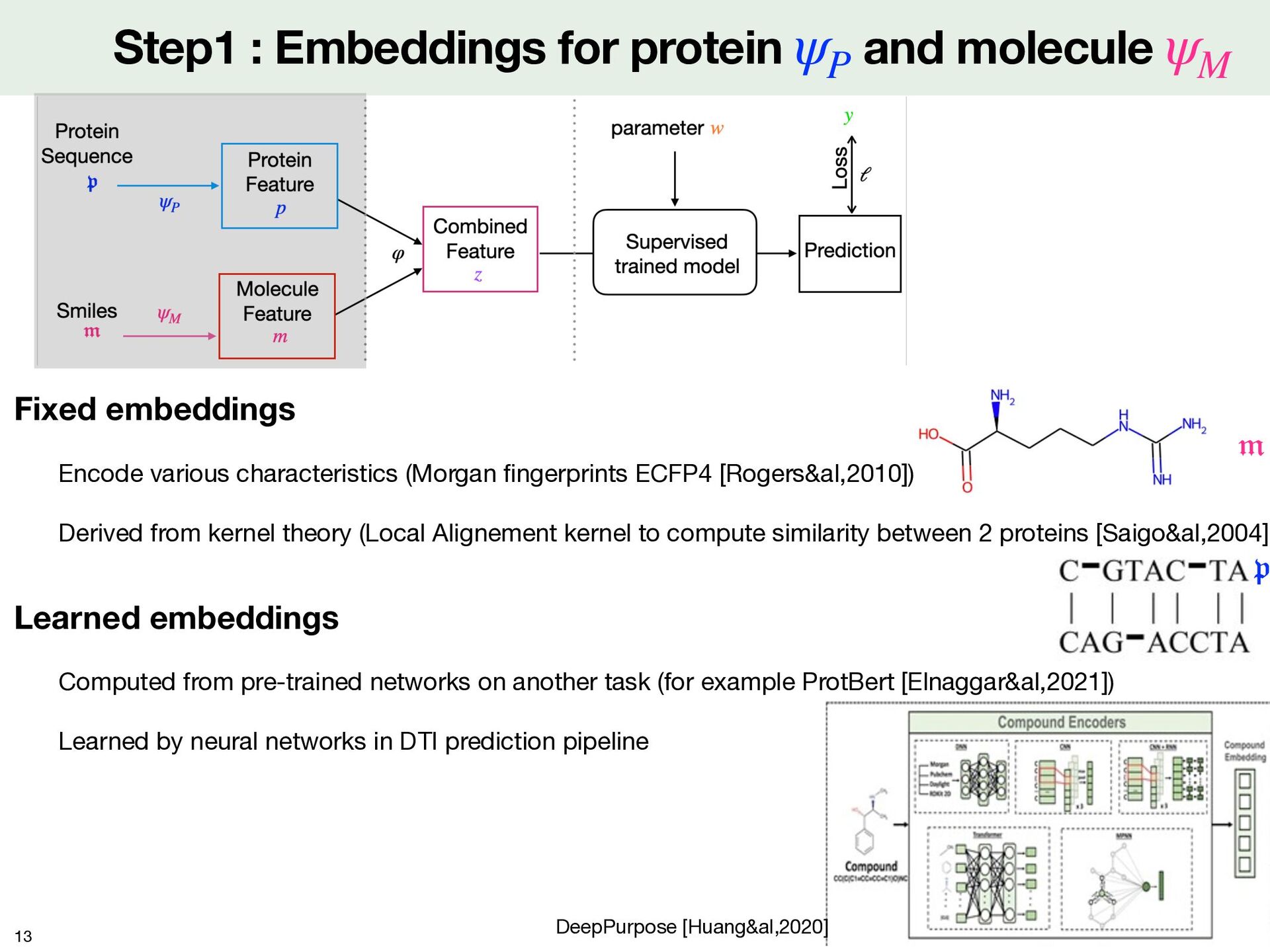
Fixed embeddings Encode various characteristics (Morgan fi ngerprints ECFP4 [Rogers&al,2010]) Derived from kernel theory (Local Alignement kernel to compute similarity between 2 proteins [Saigo&al,2004] Learned embeddings Computed from pre-trained networks on another task (for example ProtBert [Elnaggar&al,2021]) Learned by neural networks in DTI prediction pipeline DeepPurpose [Huang&al,2020] 𝔭 𝔪
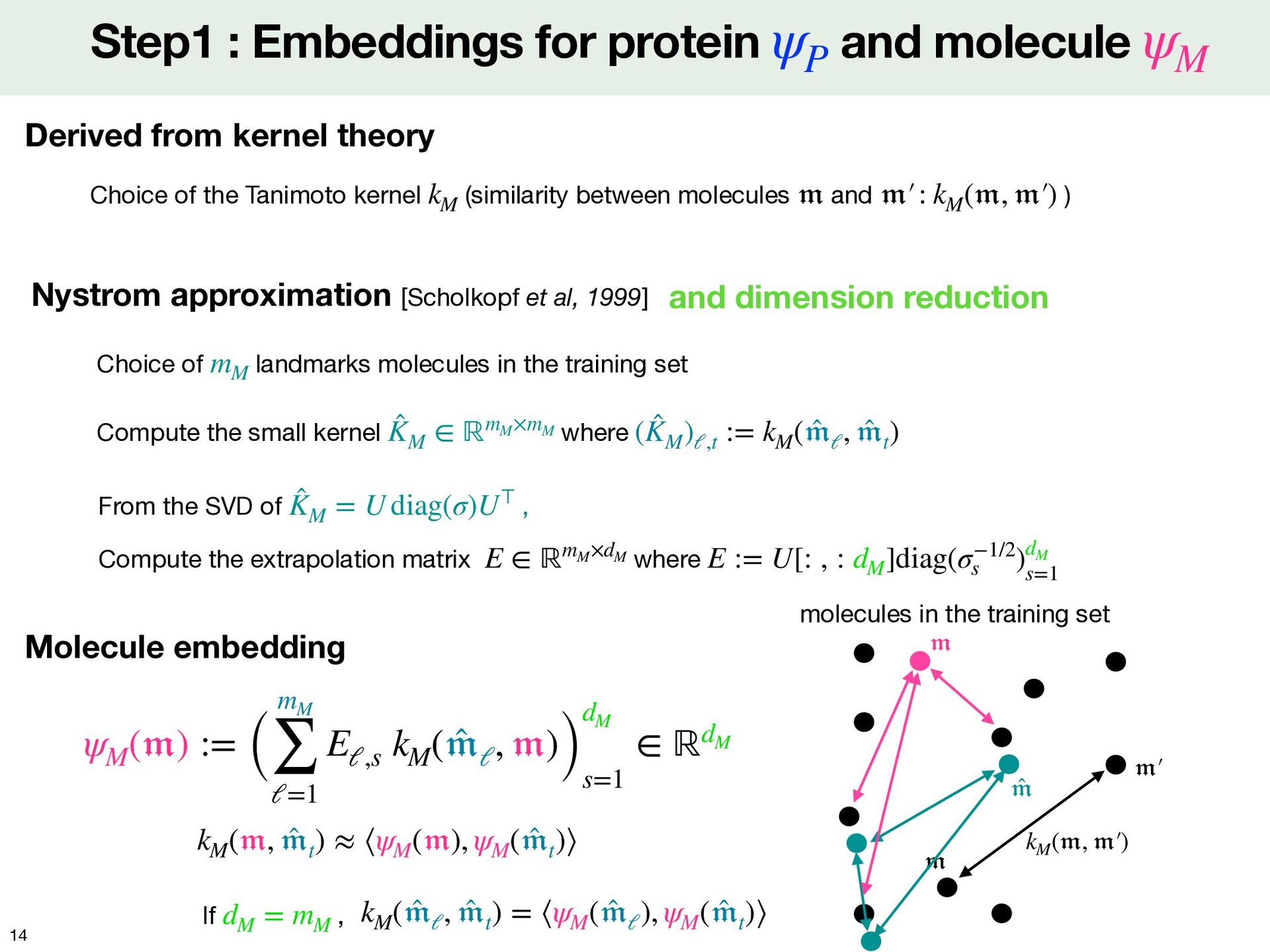
: ) kM 𝔪 𝔪 ′  kM ( 𝔪 , 𝔪 ′  ) Step1 : Embeddings for protein and molecule ψP ψM Derived from kernel theory kM ( 𝔪 , 𝔪 ′  ) molecules in the training set 𝔪 𝔪 ′  Nystrom approximation [Scholkopf et al, 1999] Choice of landmarks molecules in the training set mM ̂ 𝔪 Compute the small kernel where ̂ KM ∈ ℝmM ×mM ( ̂ KM )ℓ,t := kM ( ̂ 𝔪 ℓ , ̂ 𝔪 t ) From the SVD of , Compute the extrapolation matrix where ̂ KM = U diag(σ)U⊤ E ∈ ℝmM ×dM E := U[: , : dM ]diag(σ−1/2 s )dM s=1 and dimension reduction ψM ( 𝔪 ) := ( mM ∑ ℓ=1 Eℓ,s kM ( ̂ 𝔪 ℓ , 𝔪 )) dM s=1 ∈ ℝdM 𝔪 Molecule embedding kM ( ̂ 𝔪 ℓ , ̂ 𝔪 t ) = ⟨ψM ( ̂ 𝔪 ℓ ), ψM ( ̂ 𝔪 t )⟩ kM ( 𝔪 , ̂ 𝔪 t ) ≈ ⟨ψM ( 𝔪 ), ψM ( ̂ 𝔪 t )⟩ If , dM = mM
( 𝔪 ) := m ψP ( 𝔭 ) := p z Mixing of molecule and protein embeddings z = mp⊤ m p z dZ = dM × dP Using a tensor product Linear mixing Concatenation of the embeddings z Non linear mixing Using a neural network
et al, 2019] Network-based inference approaches [Cheng et al, 2012] Linear model min w∈ℝ(dP×dM) nZ ∑ k=1 ℓ(⟨w, zk ⟩, yk ) + λ 2 ∥w∥2 SVM with Hinge loss : ℓ(y′  , y) = max(0,1 − yy′  ) Logistic loss zk yk [MolTrans, Huang et al, 2021] w ( 𝔪 ik , 𝔭 jk ) Training dataset 16
k=1 ℓ(⟨w, zk ⟩, yk ) + λ 2 ∥w∥2 Optimization problem (Zw)k = ⟨w, zk ⟩ℝdZ = ⟨w, mik p⊤ jk ⟩ℝdP×dM = ⟨Wpjk , mik ⟩ℝdM E ffi cient computation [Airola&Pahikkala,2017] Problem is too big for both storage and computation of Z Zw can be computed in only operations (qj )nP j=1 nP × dZ ⏟ qjk Complexity Explicit Zw Implicit computation nZ × dZ nP × dZ + nZ × dM Z ∈ ℝnZ ×dZ zk nZ = 460k dZ = dM × dP Code in PyTorch running on GPU https://komet.readthedocs.io Full batch BFGS method to solve the optimization problem
Construction Coverage of the protein and molecule spaces Komet: a Large-scale DTI prediction method Embeddings of proteins and molecules Interaction module DTI classi fi cation Results Parameters set-up of the model Impact of molecule and protein features Comparison of ML algorithms Case Study: A sca ff old hopping problem
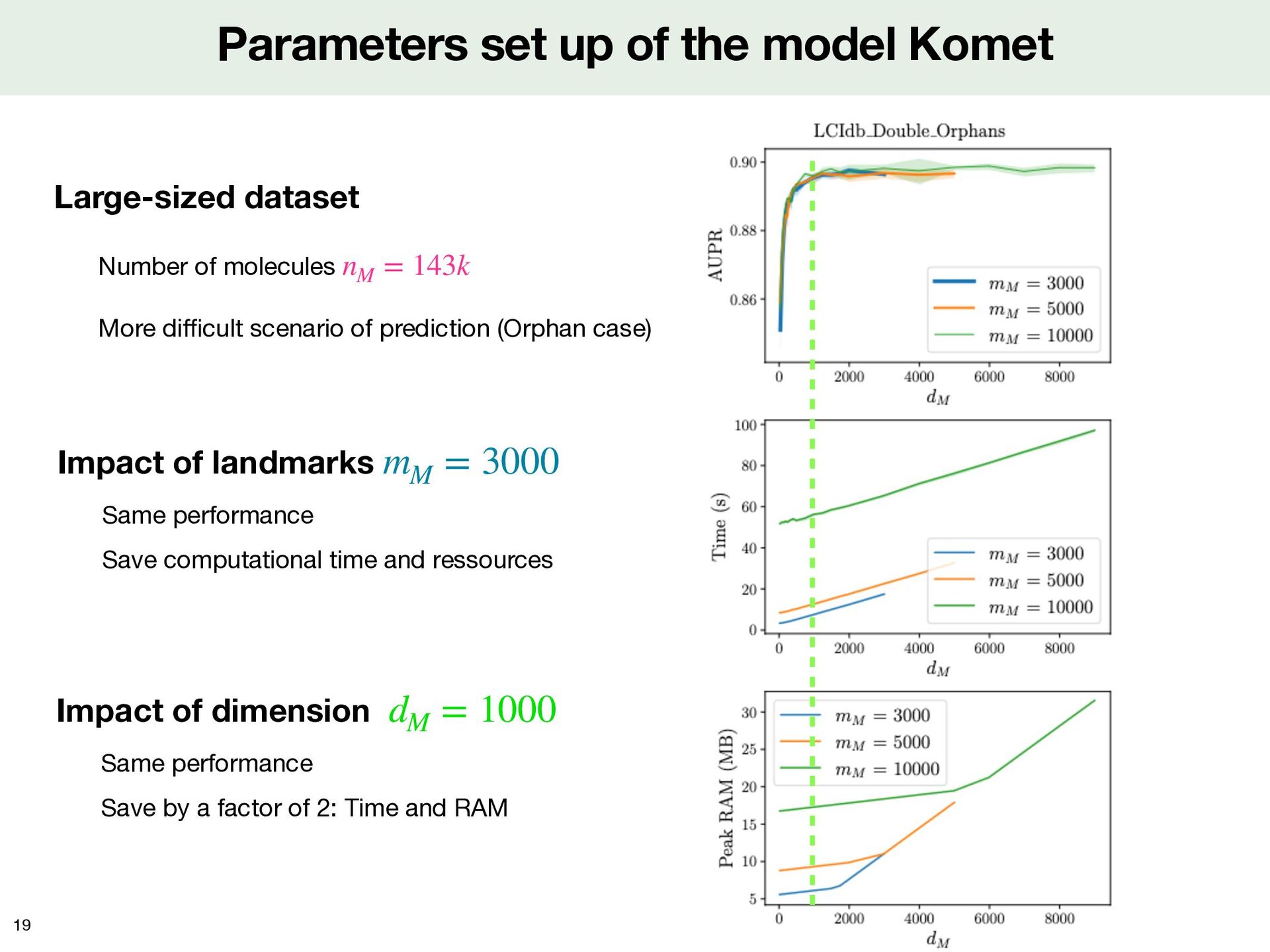
of molecules More di ffi cult scenario of prediction (Orphan case) nM = 143k 19 Impact of landmarks Same performance Save computational time and ressources mM = 3000 Impact of dimension Same performance Save by a factor of 2: Time and RAM dM = 1000
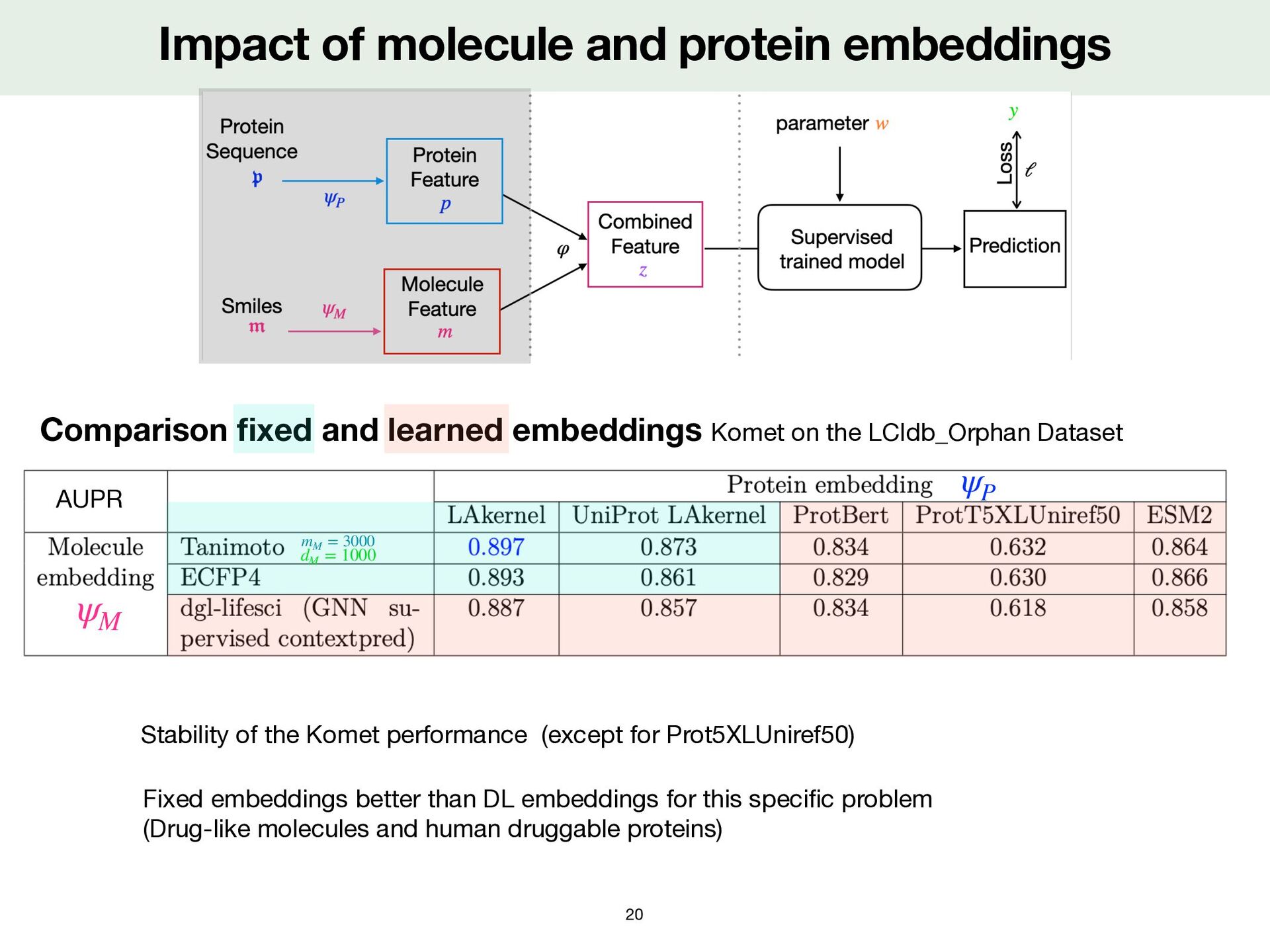
learned embeddings Komet on the LCIdb_Orphan Dataset Fixed embeddings better than DL embeddings for this speci fi c problem (Drug-like molecules and human druggable proteins) 20 ψP ψM dM = 1000 mM = 3000 AUPR Stability of the Komet performance (except for Prot5XLUniref50)
model [Huang, 2021] 21 Almost same structure pipeline in 3 steps Optimization algorithm SGD less precise, less stable and quick than BFGS Everything trained vs fi xed features
proteins Perspectives: Analysis of the target proteins predicted for the 20 di ff erentially active molecules Initial problem understanding biological mechanisms associated to a set of 20 di ff erentially active molecules found by Phenotypic survival screen Contributions: A large new molecule/protein interactions dataset Komet: Fast & State of the Art https://komet.readthedocs.io
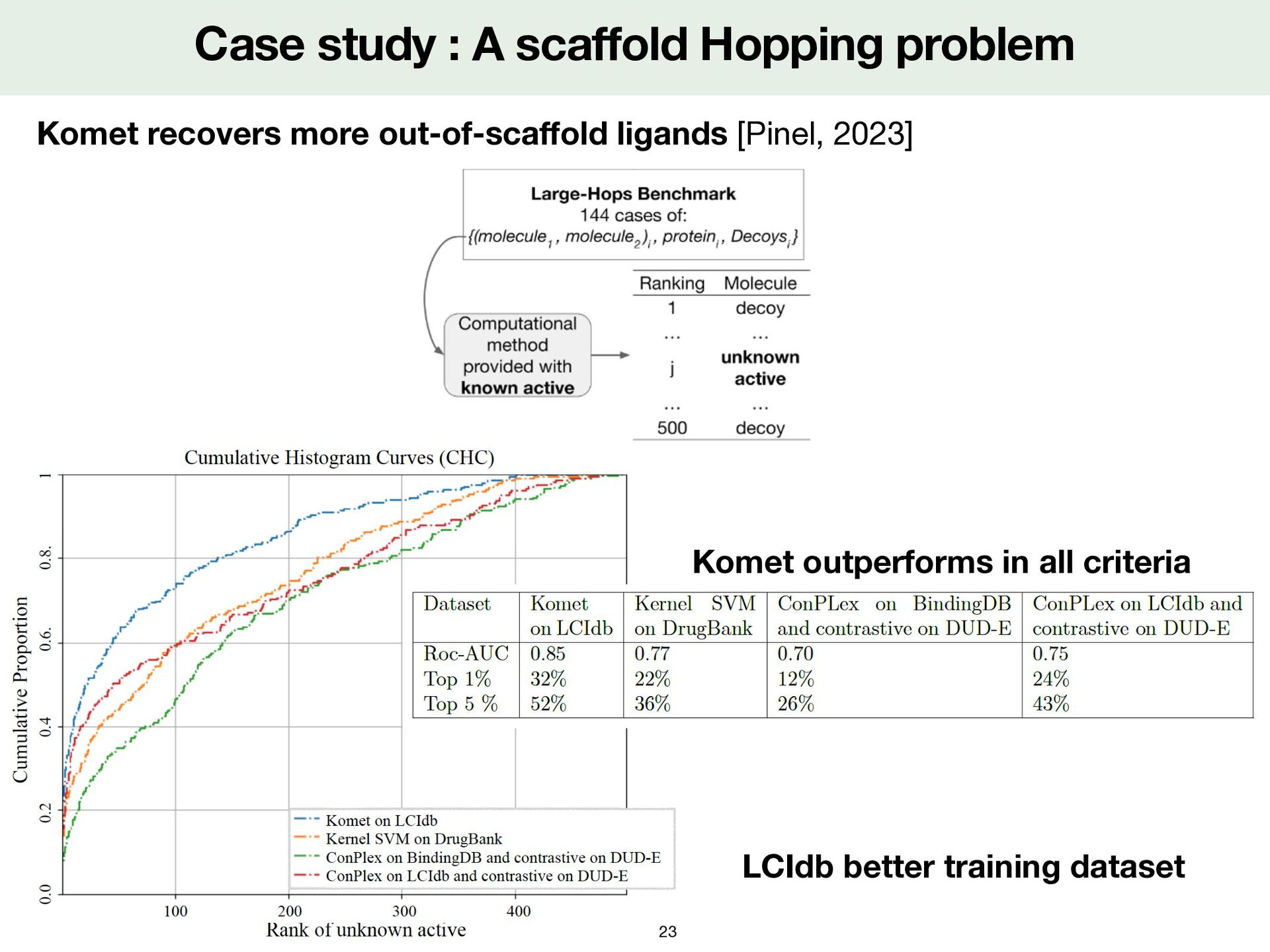
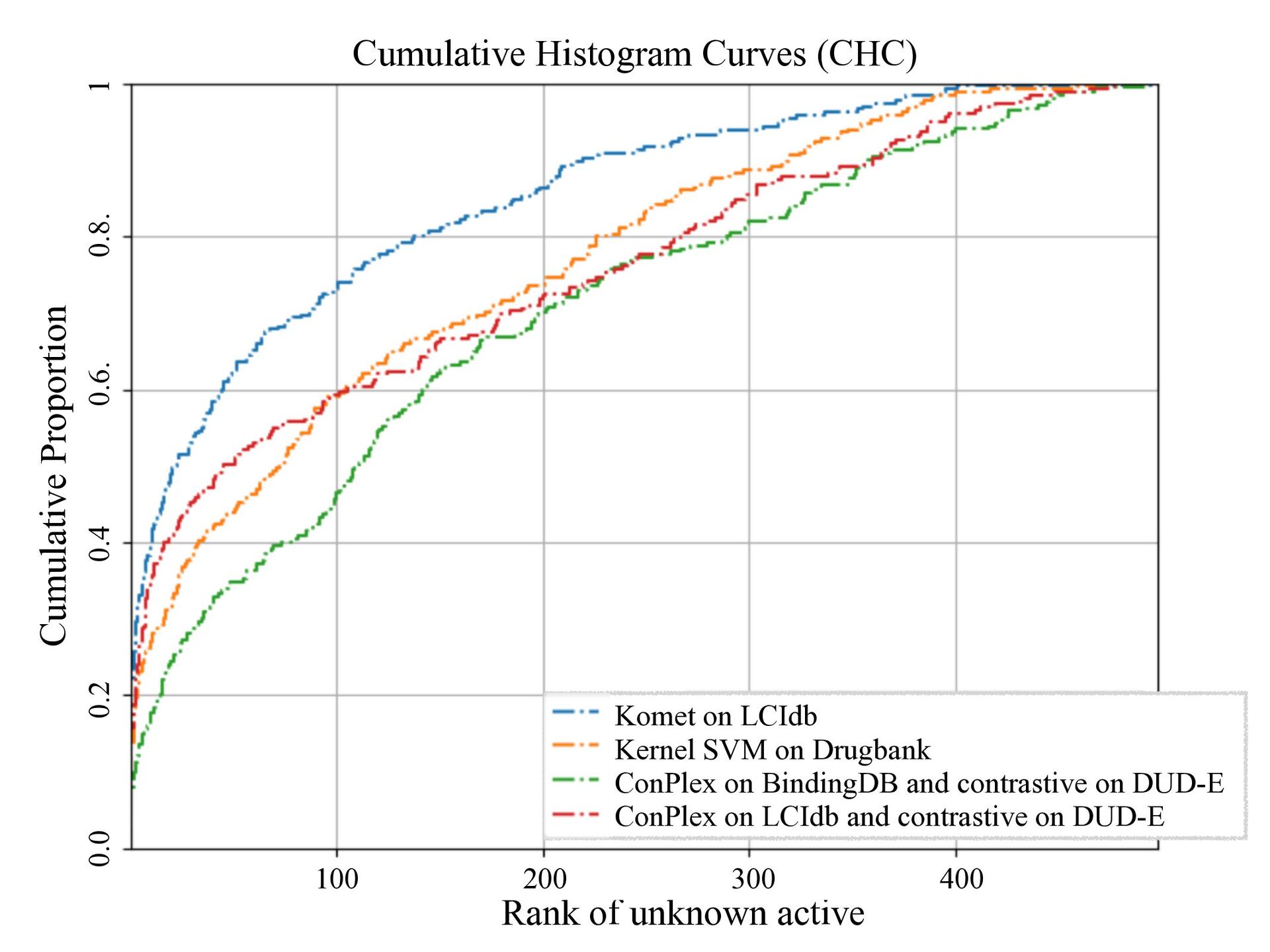
Komet on LCIdb Kernel SVM on Drugbank ConPlex on BindingDB and contrastive on DUD-E ConPlex on LCIdb and contrastive on DUD-E 100 200 300 400 0.0 0.2 0.4 0.6. 0.8. 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
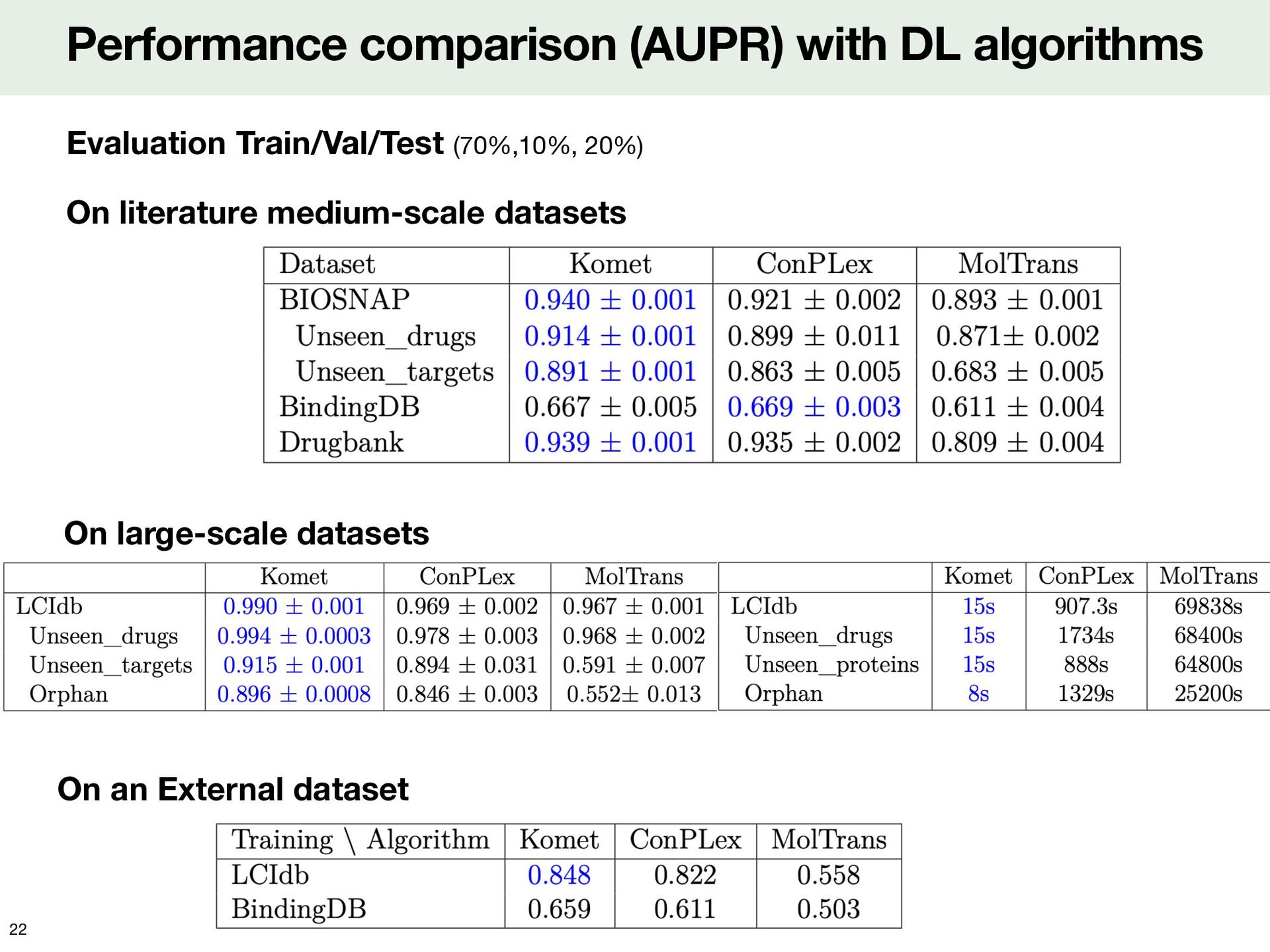
![Comparison to Deep Learning algorithms ConPlex model [Singh, 2023] MolTrans](https://files.speakerdeck.com/presentations/94c56b4fda6244a6aa8732de8ab67977/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}