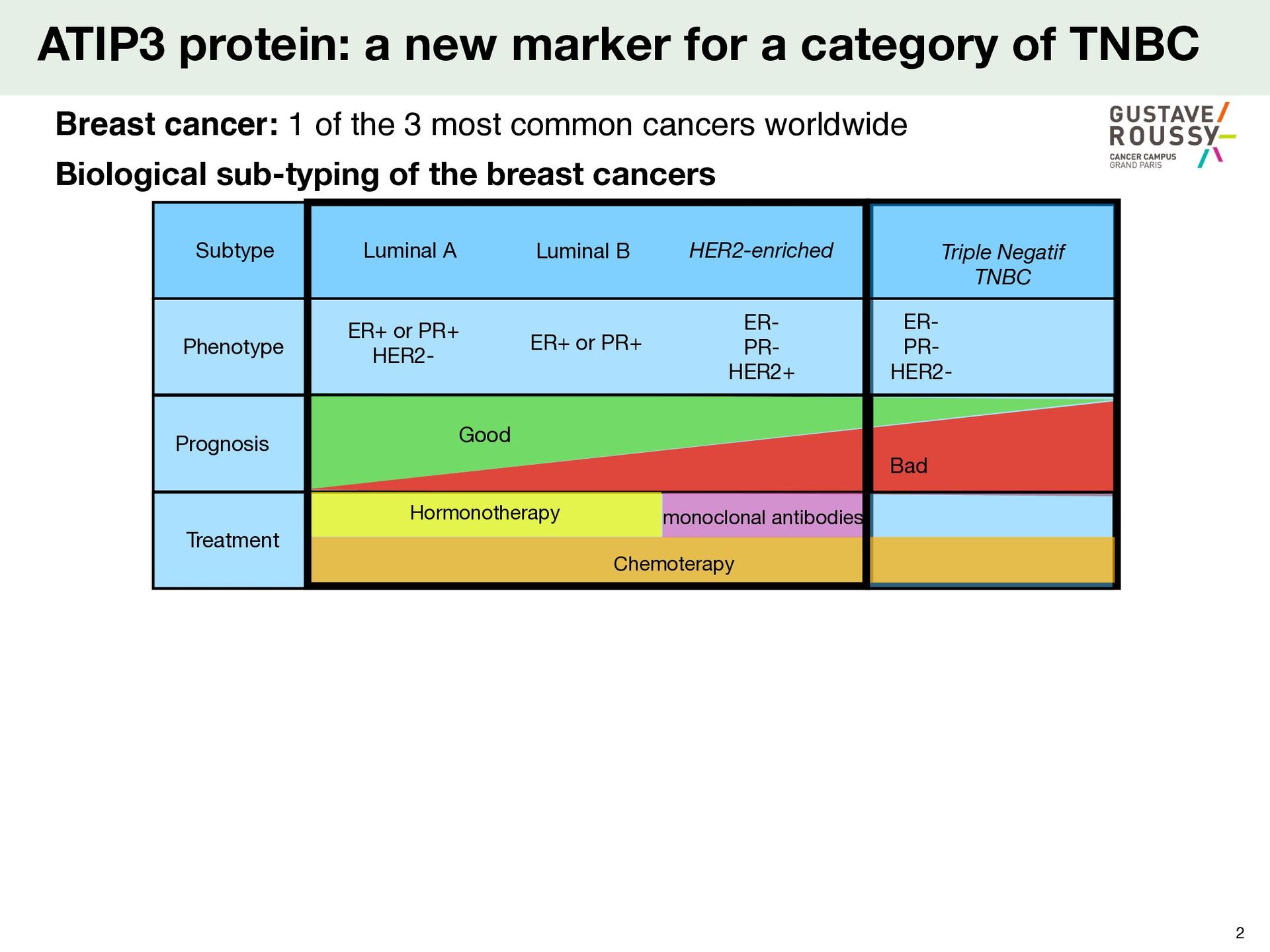
B Triple Negatif TNBC Phenotype Prognosis Treatment ER+ or PR+ HER2- ER+ or PR+ ER- PR- HER2- Good ER- PR- HER2+ ATIP3 protein: a new marker for a category of TNBC 2 Biological sub-typing of the breast cancers Breast cancer: 1 of the 3 most common cancers worldwide
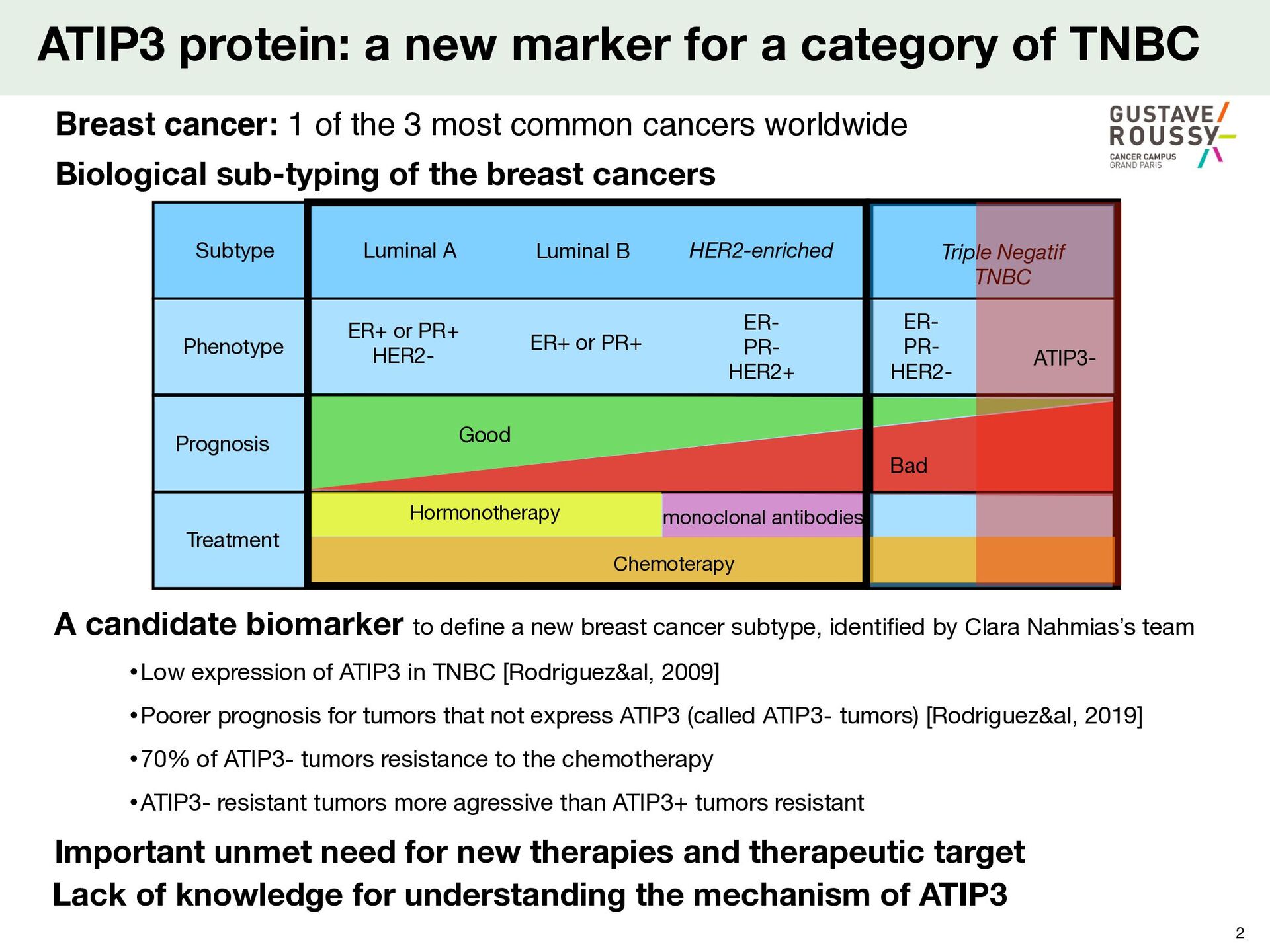
B Triple Negatif TNBC Phenotype Prognosis Treatment ER+ or PR+ HER2- ER+ or PR+ ER- PR- HER2- Good ER- PR- HER2+ ATIP3 protein: a new marker for a category of TNBC 2 Biological sub-typing of the breast cancers Breast cancer: 1 of the 3 most common cancers worldwide A candidate biomarker to de fi ne a new breast cancer subtype, identi fi ed by Clara Nahmias’s team •Low expression of ATIP3 in TNBC [Rodriguez&al, 2009] •Poorer prognosis for tumors that not express ATIP3 (called ATIP3- tumors) [Rodriguez&al, 2019] •70% of ATIP3- tumors resistance to the chemotherapy •ATIP3- resistant tumors more agressive than ATIP3+ tumors resistant Important unmet need for new therapies and therapeutic target Lack of knowledge for understanding the mechanism of ATIP3 ATIP3-
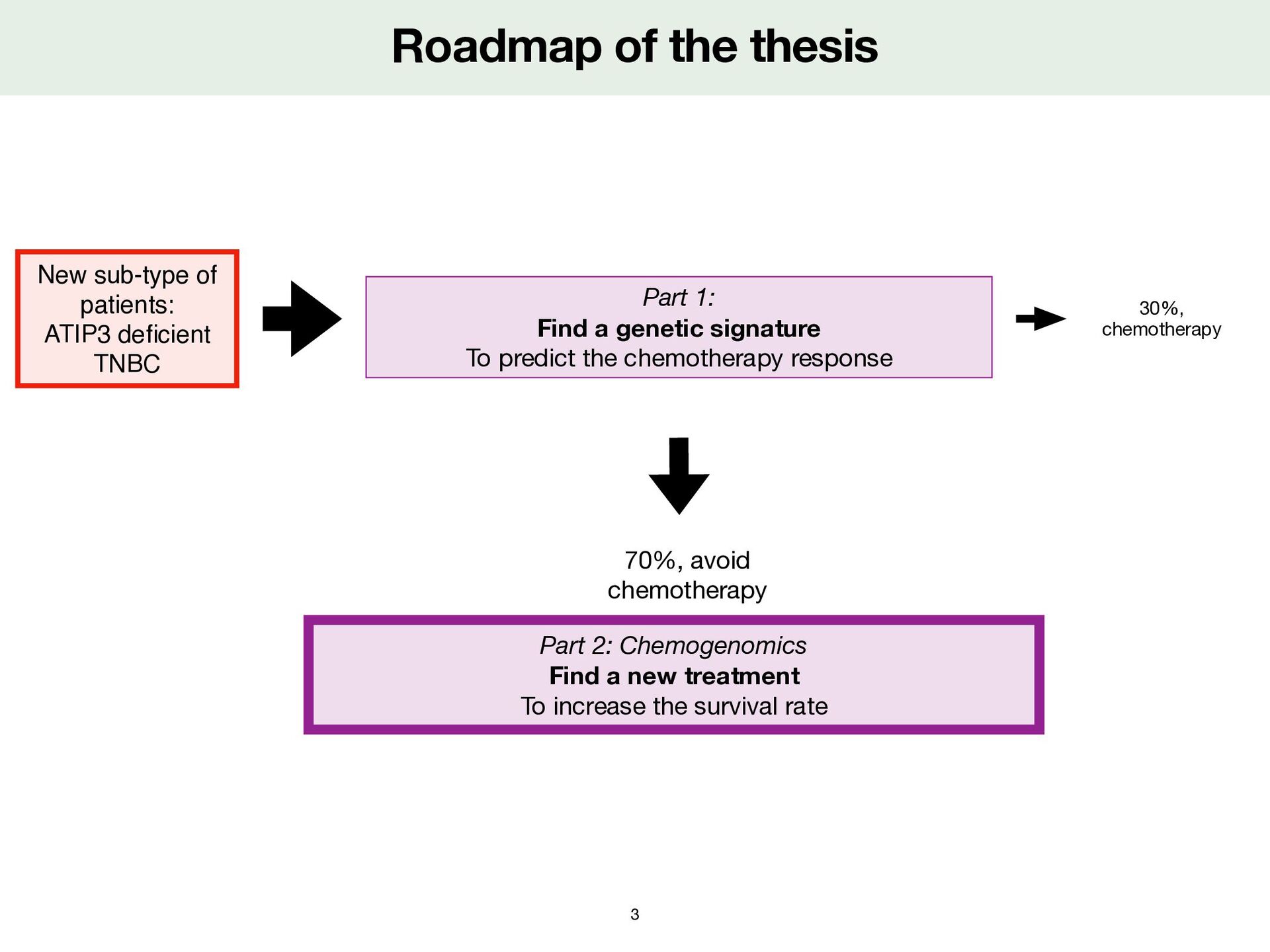
fi cient TNBC Part 1: Find a genetic signature To predict the chemotherapy response Part 2: Chemogenomics Find a new treatment To increase the survival rate 70%, avoid chemotherapy 30%, chemotherapy 3
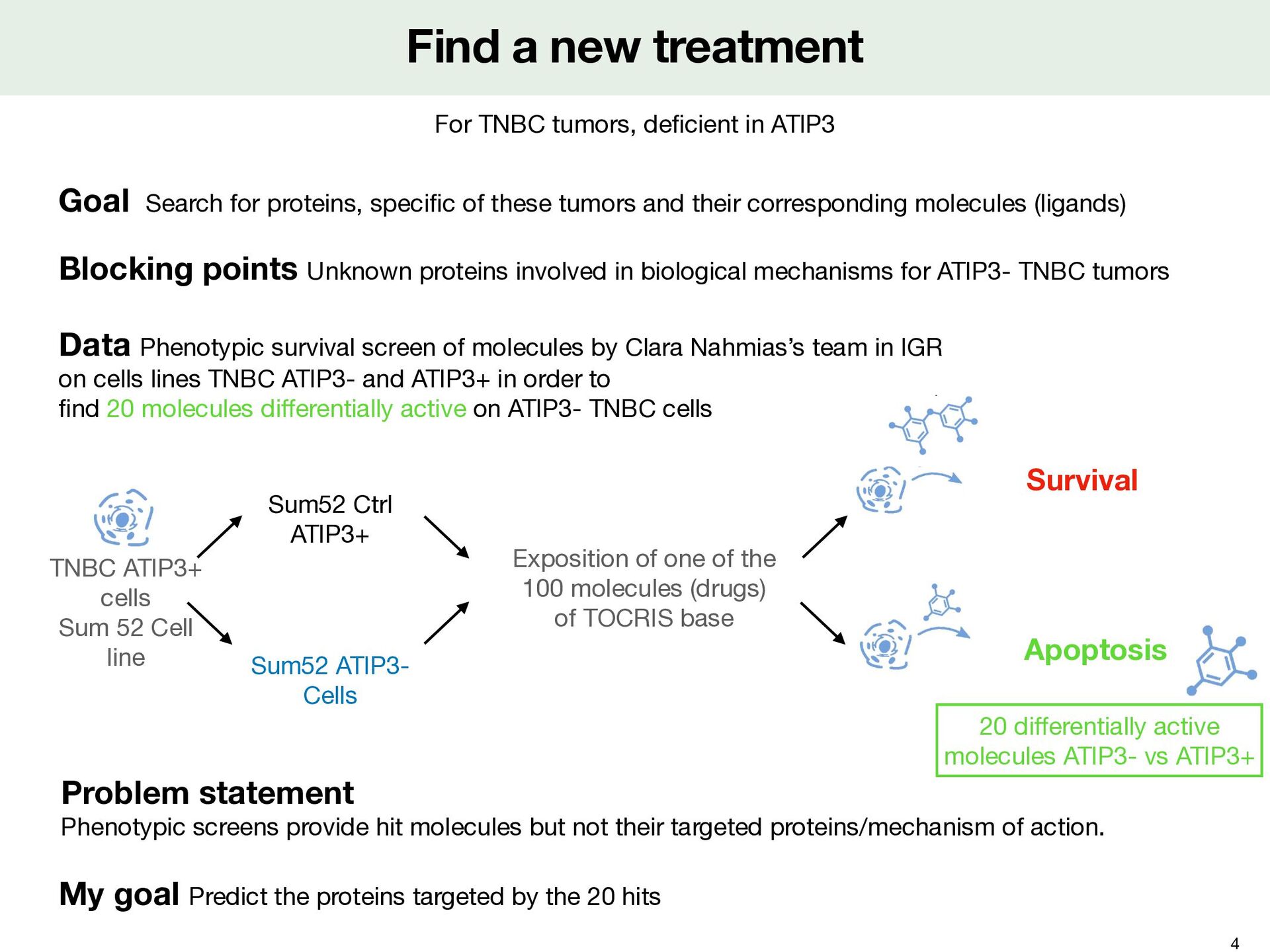
in ATIP3 Blocking points Unknown proteins involved in biological mechanisms for ATIP3- TNBC tumors Goal Search for proteins, speci fi c of these tumors and their corresponding molecules (ligands) 4 Data Phenotypic survival screen of molecules by Clara Nahmias’s team in IGR on cells lines TNBC ATIP3- and ATIP3+ in order to fi nd 20 molecules di ff erentially active on ATIP3- TNBC cells Survival TNBC ATIP3+ cells Sum 52 Cell line Sum52 ATIP3- Cells Sum52 Ctrl ATIP3+ Exposition of one of the 100 molecules (drugs) of TOCRIS base Apoptosis 20 di ff erentially active molecules ATIP3- vs ATIP3+ Problem statement Phenotypic screens provide hit molecules but not their targeted proteins/mechanism of action. My goal Predict the proteins targeted by the 20 hits
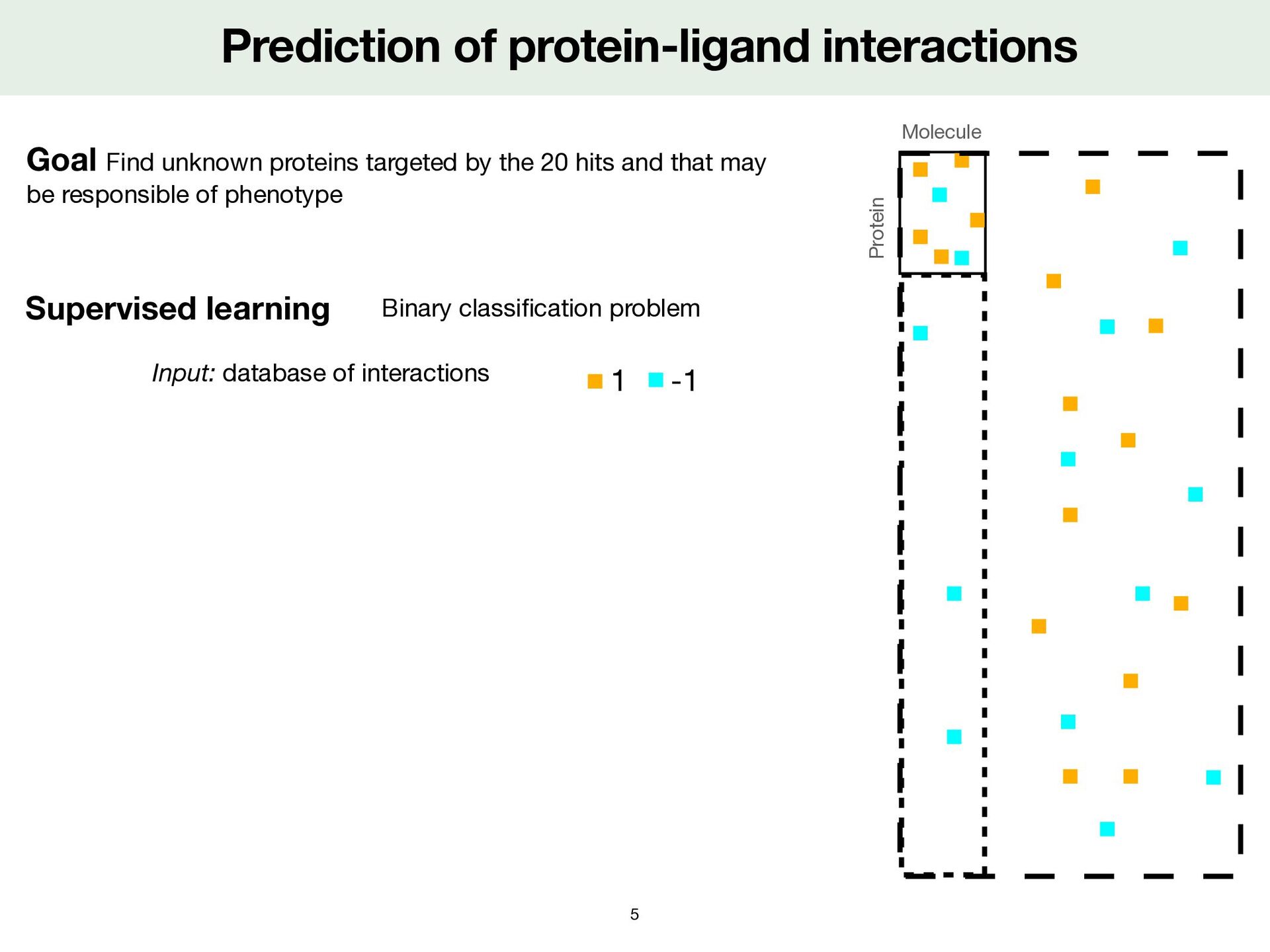
unknown proteins targeted by the 20 hits and that may be responsible of phenotype Supervised learning Input: database of interactions Binary classi fi cation problem 1 -1
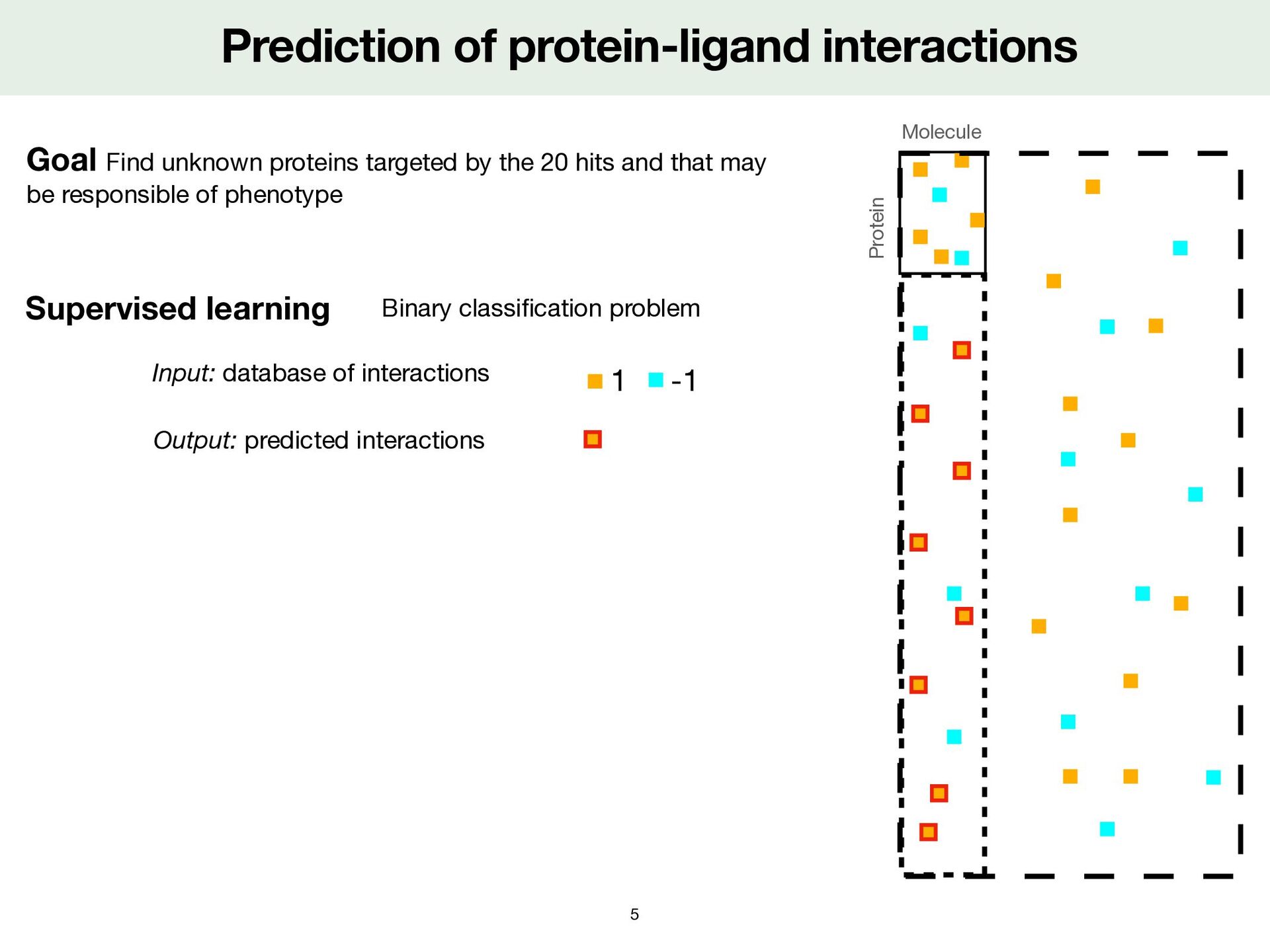
unknown proteins targeted by the 20 hits and that may be responsible of phenotype Output: predicted interactions Supervised learning Input: database of interactions Binary classi fi cation problem 1 -1
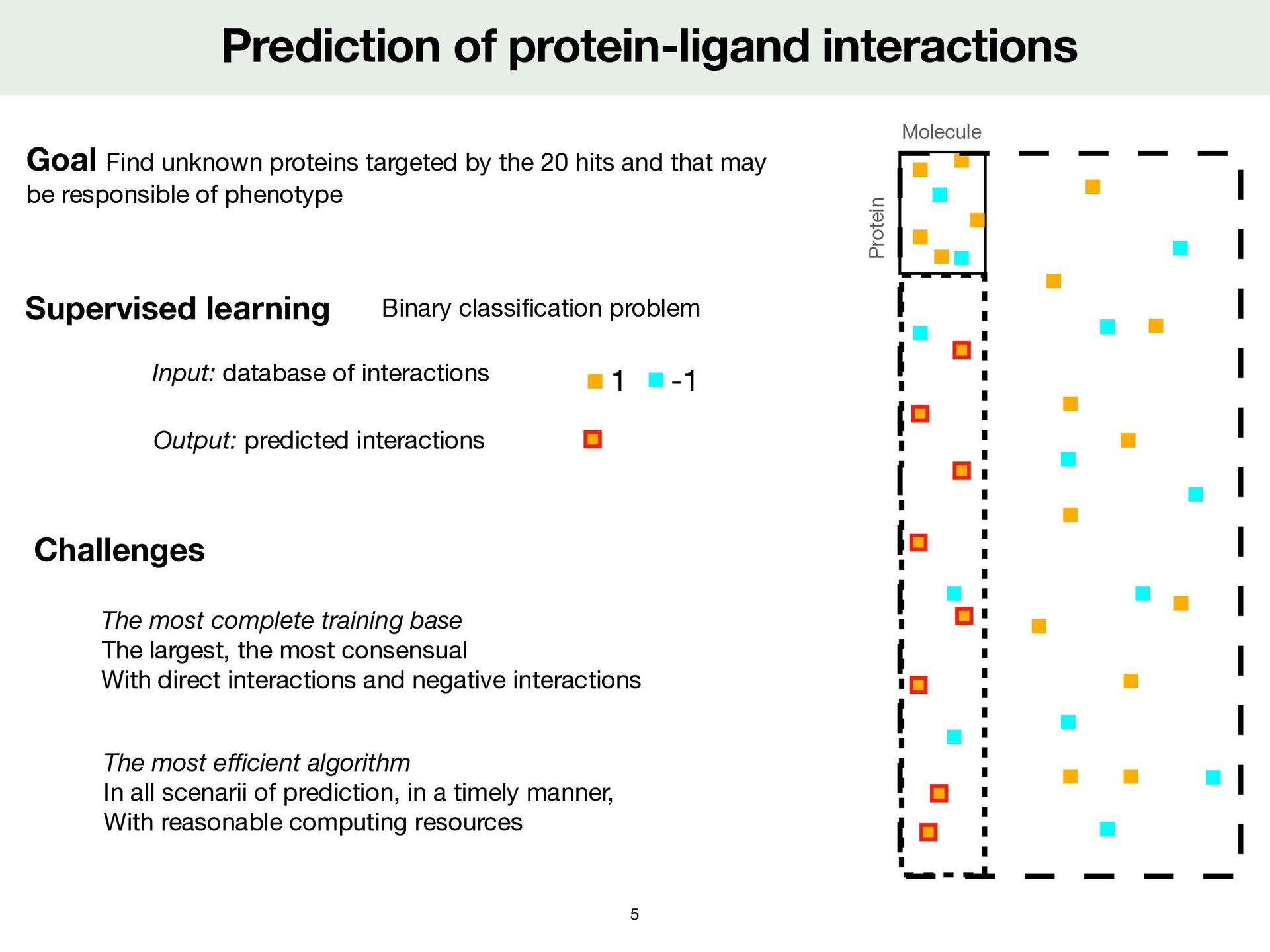
most complete training base The largest, the most consensual With direct interactions and negative interactions The most e ffi cient algorithm In all scenarii of prediction, in a timely manner, With reasonable computing resources Goal Find unknown proteins targeted by the 20 hits and that may be responsible of phenotype Output: predicted interactions Supervised learning Input: database of interactions Binary classi fi cation problem 1 -1
Construction Development of Large-scale kernel method SVM Method From kernel back to features Large-Scale SVM Results Performance in di ff erent prediction situations Comparison to DL
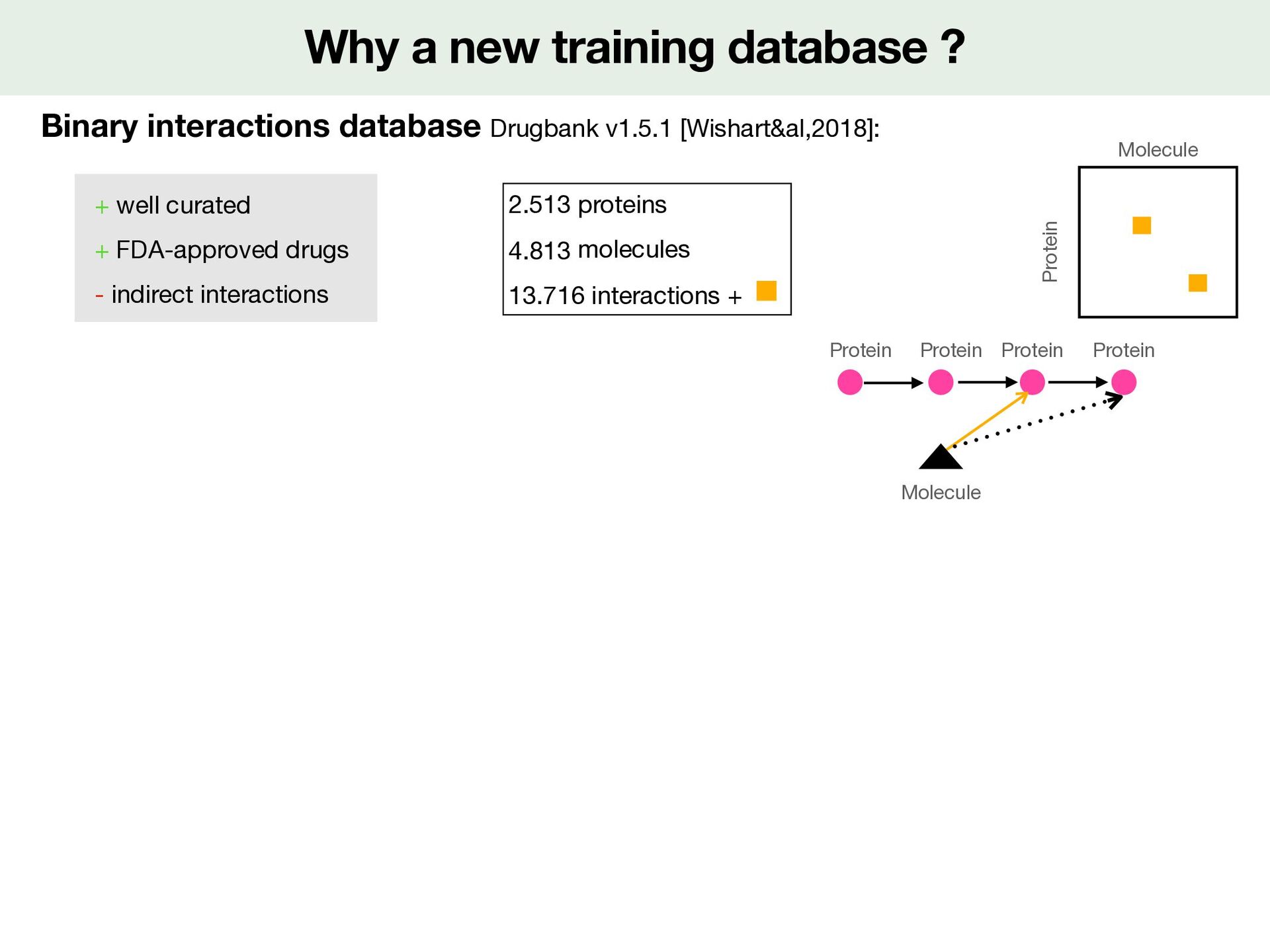
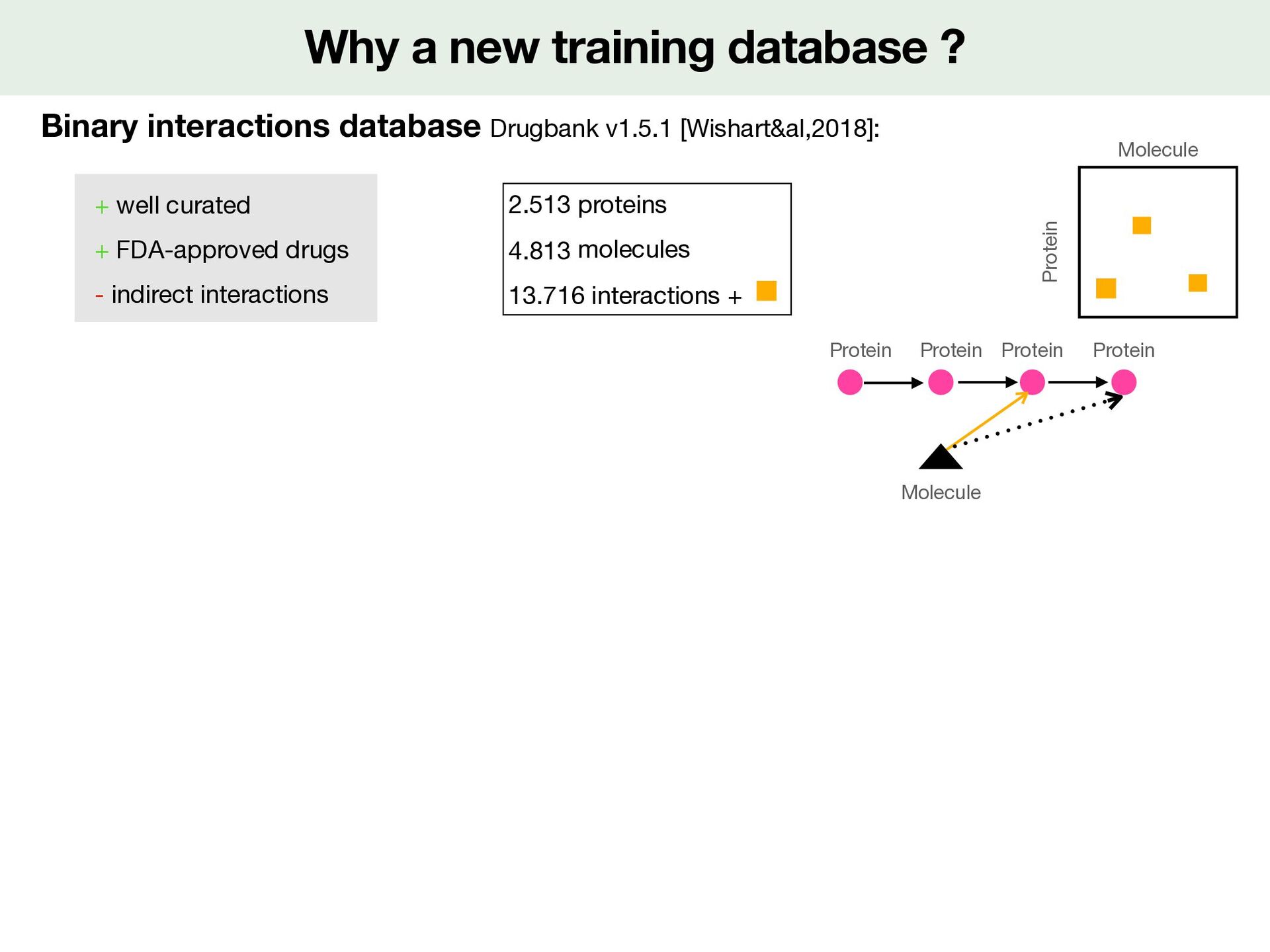
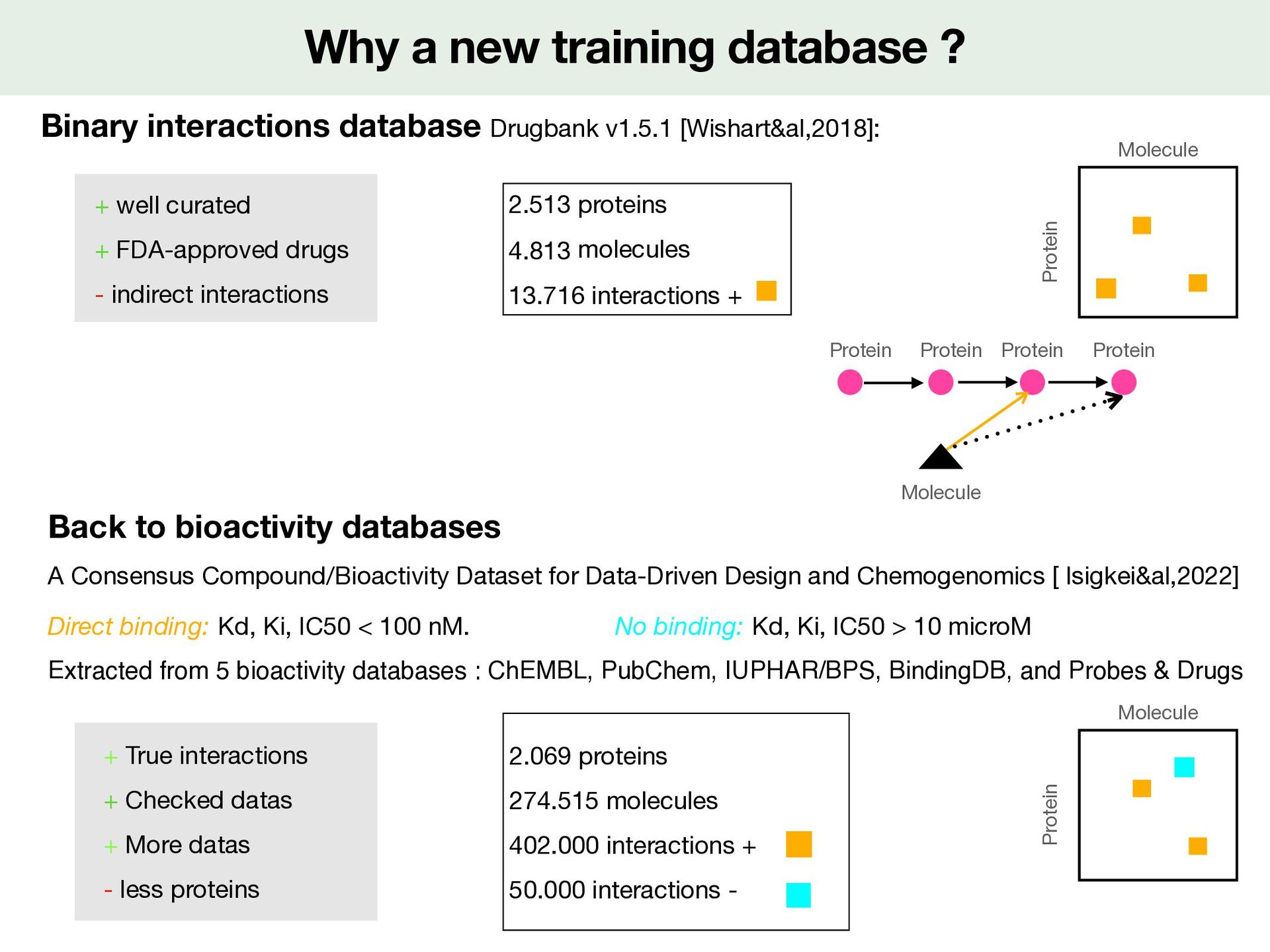
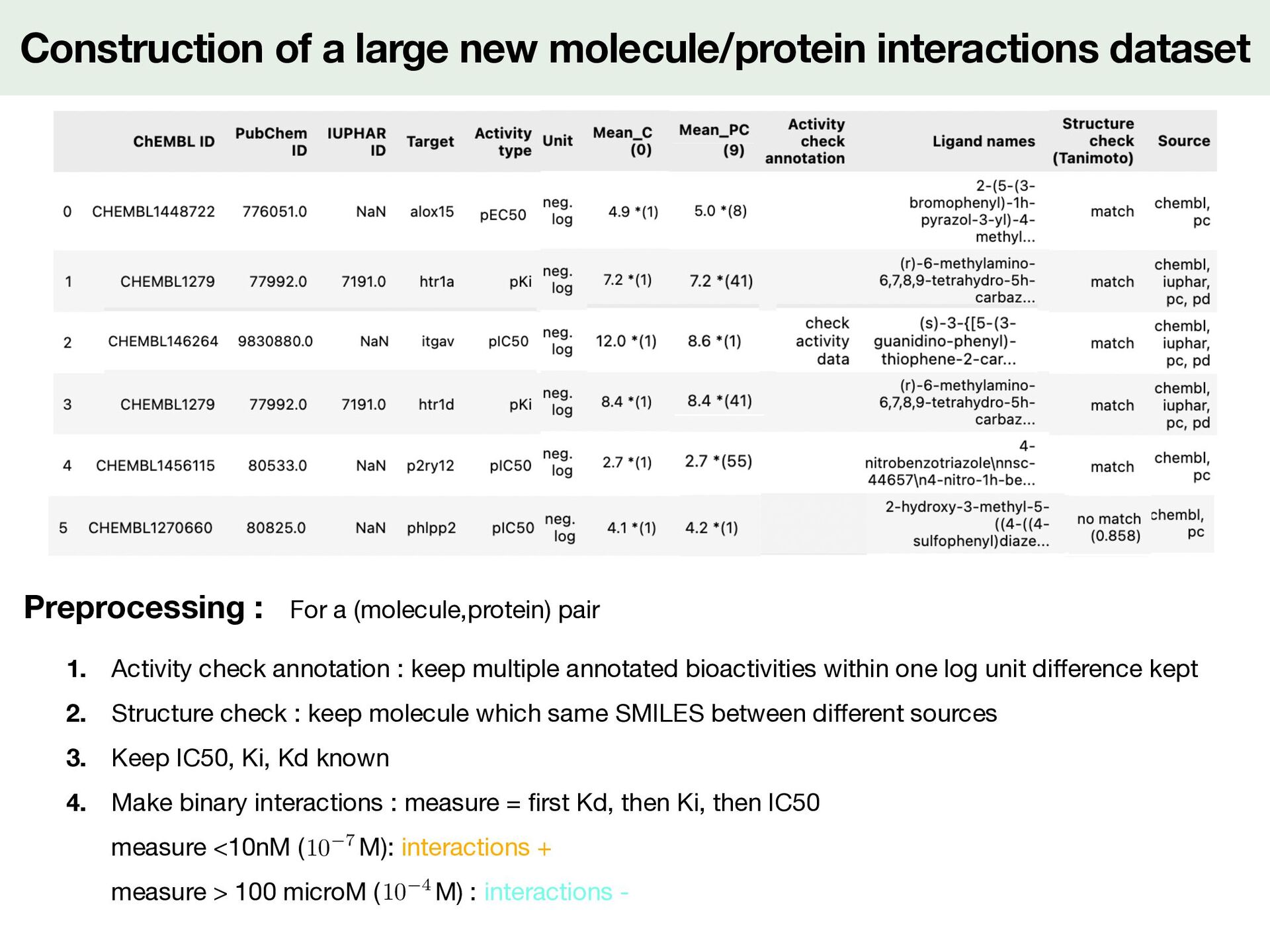
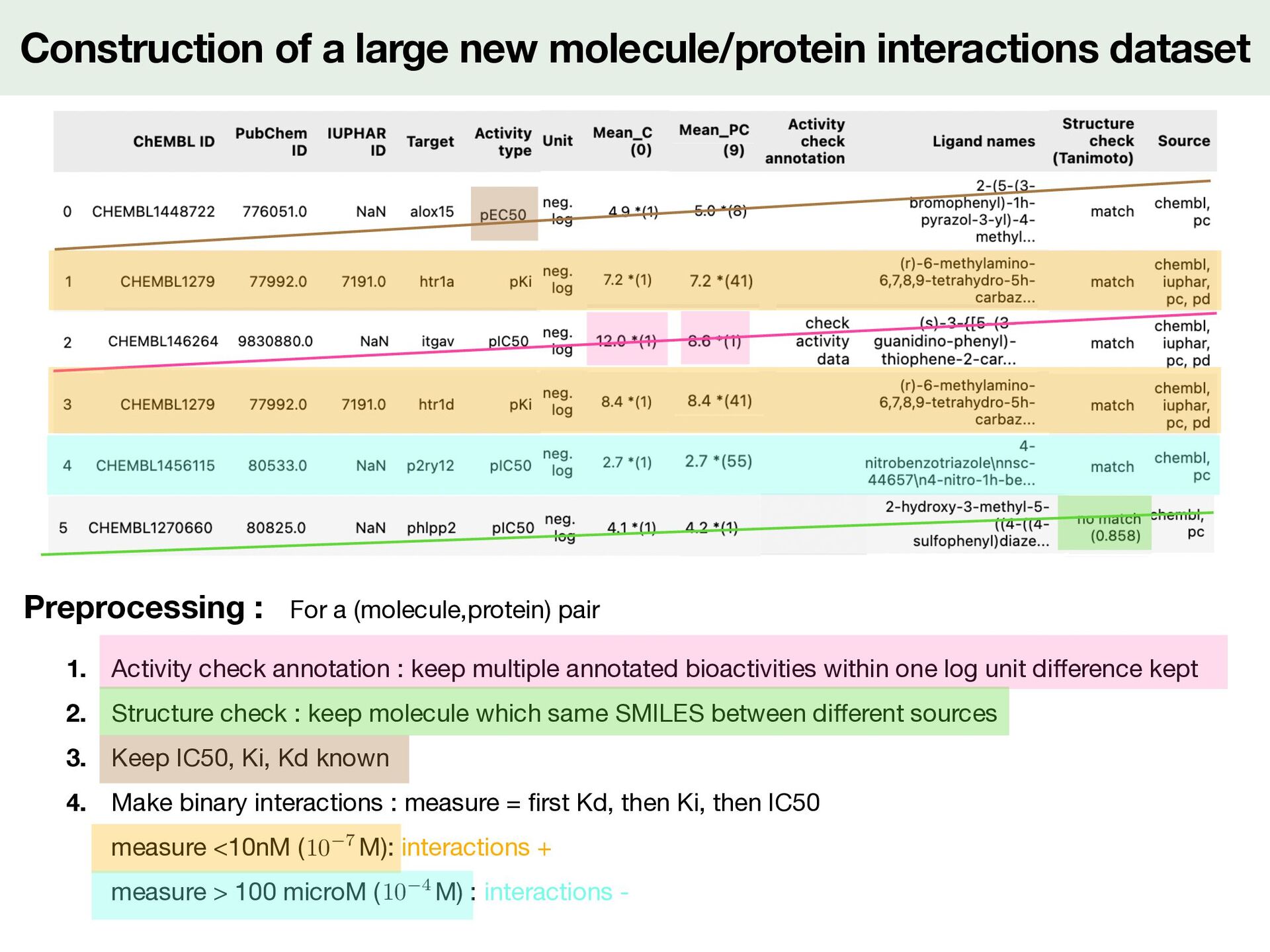
For a (molecule,protein) pair 1. Activity check annotation : keep multiple annotated bioactivities within one log unit di ff erence kept 2. Structure check : keep molecule which same SMILES between di ff erent sources 3. Keep IC50, Ki, Kd known 4. Make binary interactions : measure = fi rst Kd, then Ki, then IC50 measure <10nM ( M): interactions + measure > 100 microM ( M) : interactions - <latexit sha1_base64="19OAeTsEV3mWXvQneo58YjqgWMc=">AAACy3icjVHLSsNAFD2Nr1pfVZdugkVwY0lErcuiGzdCBfuAWiVJp3UwLyYTodYu/QG3+l/iH+hfeGdMQS2iE5KcOfecO3PvdWOfJ9KyXnPG1PTM7Fx+vrCwuLS8UlxdayRRKjxW9yI/Ei3XSZjPQ1aXXPqsFQvmBK7Pmu7NsYo3b5lIeBSey0HMOoHTD3mPe44kqmVbl8OdyqhwVSxZZUsvcxLYGSghW7Wo+IILdBHBQ4oADCEkYR8OEnrasGEhJq6DIXGCENdxhhEK5E1JxUjhEHtD3z7t2hkb0l7lTLTbo1N8egU5TWyRJyKdIKxOM3U81ZkV+1vuoc6p7jagv5vlCoiVuCb2L99Y+V+fqkWih0NdA6eaYs2o6rwsS6q7om5ufqlKUoaYOIW7FBeEPe0c99nUnkTXrnrr6PibVipW7b1Mm+Jd3ZIGbP8c5yRo7Jbtg/L+2V6pepSNOo8NbGKb5llBFSeooa7n+IgnPBunRmLcGfefUiOXedbxbRkPH3mckXo=</latexit> 10 7 <latexit sha1_base64="3V19iHXrJMEsQ7O1Yf/AR3qR19A=">AAACy3icjVHLSsNAFD2Nr1pfVZdugkVwY0mkPpZFN26ECvYBtUqSTutgXkwmQq1d+gNu9b/EP9C/8M6YglpEJyQ5c+45d+be68Y+T6RlveaMqemZ2bn8fGFhcWl5pbi61kiiVHis7kV+JFqukzCfh6wuufRZKxbMCVyfNd2bYxVv3jKR8Cg8l4OYdQKnH/Ie9xxJVMu2Loc7lVHhqliyypZe5iSwM1BCtmpR8QUX6CKChxQBGEJIwj4cJPS0YcNCTFwHQ+IEIa7jDCMUyJuSipHCIfaGvn3atTM2pL3KmWi3R6f49ApymtgiT0Q6QVidZup4qjMr9rfcQ51T3W1AfzfLFRArcU3sX76x8r8+VYtED4e6Bk41xZpR1XlZllR3Rd3c/FKVpAwxcQp3KS4Ie9o57rOpPYmuXfXW0fE3rVSs2nuZNsW7uiUN2P45zknQ2C3b++W9s0qpepSNOo8NbGKb5nmAKk5QQ13P8RFPeDZOjcS4M+4/pUYu86zj2zIePgBydpF3</latexit> 10 4
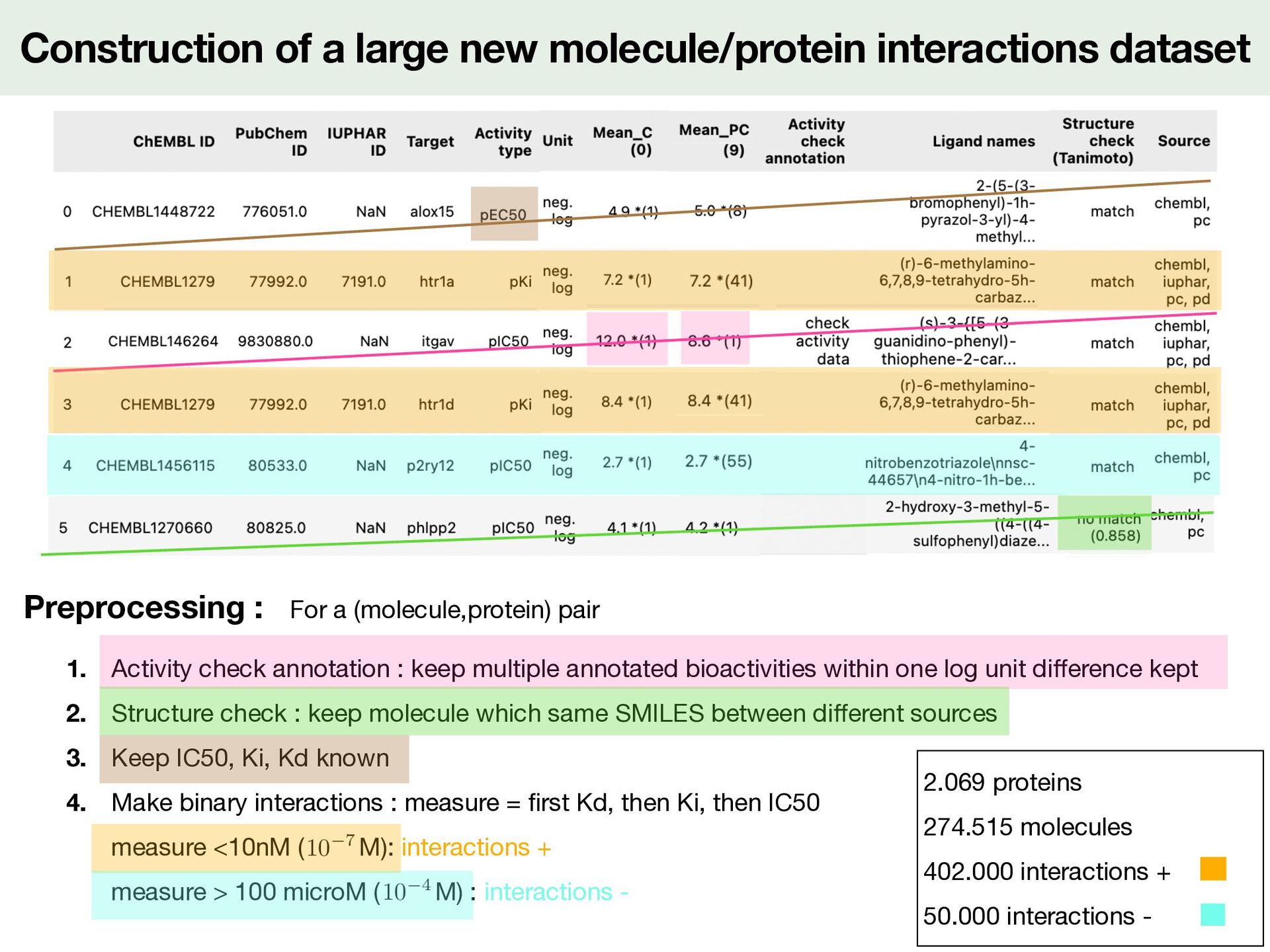
For a (molecule,protein) pair 1. Activity check annotation : keep multiple annotated bioactivities within one log unit di ff erence kept 2. Structure check : keep molecule which same SMILES between di ff erent sources 3. Keep IC50, Ki, Kd known 4. Make binary interactions : measure = fi rst Kd, then Ki, then IC50 measure <10nM ( M): interactions + measure > 100 microM ( M) : interactions - <latexit sha1_base64="19OAeTsEV3mWXvQneo58YjqgWMc=">AAACy3icjVHLSsNAFD2Nr1pfVZdugkVwY0lErcuiGzdCBfuAWiVJp3UwLyYTodYu/QG3+l/iH+hfeGdMQS2iE5KcOfecO3PvdWOfJ9KyXnPG1PTM7Fx+vrCwuLS8UlxdayRRKjxW9yI/Ei3XSZjPQ1aXXPqsFQvmBK7Pmu7NsYo3b5lIeBSey0HMOoHTD3mPe44kqmVbl8OdyqhwVSxZZUsvcxLYGSghW7Wo+IILdBHBQ4oADCEkYR8OEnrasGEhJq6DIXGCENdxhhEK5E1JxUjhEHtD3z7t2hkb0l7lTLTbo1N8egU5TWyRJyKdIKxOM3U81ZkV+1vuoc6p7jagv5vlCoiVuCb2L99Y+V+fqkWih0NdA6eaYs2o6rwsS6q7om5ufqlKUoaYOIW7FBeEPe0c99nUnkTXrnrr6PibVipW7b1Mm+Jd3ZIGbP8c5yRo7Jbtg/L+2V6pepSNOo8NbGKb5llBFSeooa7n+IgnPBunRmLcGfefUiOXedbxbRkPH3mckXo=</latexit> 10 7 <latexit sha1_base64="3V19iHXrJMEsQ7O1Yf/AR3qR19A=">AAACy3icjVHLSsNAFD2Nr1pfVZdugkVwY0mkPpZFN26ECvYBtUqSTutgXkwmQq1d+gNu9b/EP9C/8M6YglpEJyQ5c+45d+be68Y+T6RlveaMqemZ2bn8fGFhcWl5pbi61kiiVHis7kV+JFqukzCfh6wuufRZKxbMCVyfNd2bYxVv3jKR8Cg8l4OYdQKnH/Ie9xxJVMu2Loc7lVHhqliyypZe5iSwM1BCtmpR8QUX6CKChxQBGEJIwj4cJPS0YcNCTFwHQ+IEIa7jDCMUyJuSipHCIfaGvn3atTM2pL3KmWi3R6f49ApymtgiT0Q6QVidZup4qjMr9rfcQ51T3W1AfzfLFRArcU3sX76x8r8+VYtED4e6Bk41xZpR1XlZllR3Rd3c/FKVpAwxcQp3KS4Ie9o57rOpPYmuXfXW0fE3rVSs2nuZNsW7uiUN2P45zknQ2C3b++W9s0qpepSNOo8NbGKb5nmAKk5QQ13P8RFPeDZOjcS4M+4/pUYu86zj2zIePgBydpF3</latexit> 10 4
For a (molecule,protein) pair 1. Activity check annotation : keep multiple annotated bioactivities within one log unit di ff erence kept 2. Structure check : keep molecule which same SMILES between di ff erent sources 3. Keep IC50, Ki, Kd known 4. Make binary interactions : measure = fi rst Kd, then Ki, then IC50 measure <10nM ( M): interactions + measure > 100 microM ( M) : interactions - <latexit sha1_base64="19OAeTsEV3mWXvQneo58YjqgWMc=">AAACy3icjVHLSsNAFD2Nr1pfVZdugkVwY0lErcuiGzdCBfuAWiVJp3UwLyYTodYu/QG3+l/iH+hfeGdMQS2iE5KcOfecO3PvdWOfJ9KyXnPG1PTM7Fx+vrCwuLS8UlxdayRRKjxW9yI/Ei3XSZjPQ1aXXPqsFQvmBK7Pmu7NsYo3b5lIeBSey0HMOoHTD3mPe44kqmVbl8OdyqhwVSxZZUsvcxLYGSghW7Wo+IILdBHBQ4oADCEkYR8OEnrasGEhJq6DIXGCENdxhhEK5E1JxUjhEHtD3z7t2hkb0l7lTLTbo1N8egU5TWyRJyKdIKxOM3U81ZkV+1vuoc6p7jagv5vlCoiVuCb2L99Y+V+fqkWih0NdA6eaYs2o6rwsS6q7om5ufqlKUoaYOIW7FBeEPe0c99nUnkTXrnrr6PibVipW7b1Mm+Jd3ZIGbP8c5yRo7Jbtg/L+2V6pepSNOo8NbGKb5llBFSeooa7n+IgnPBunRmLcGfefUiOXedbxbRkPH3mckXo=</latexit> 10 7 <latexit sha1_base64="3V19iHXrJMEsQ7O1Yf/AR3qR19A=">AAACy3icjVHLSsNAFD2Nr1pfVZdugkVwY0mkPpZFN26ECvYBtUqSTutgXkwmQq1d+gNu9b/EP9C/8M6YglpEJyQ5c+45d+be68Y+T6RlveaMqemZ2bn8fGFhcWl5pbi61kiiVHis7kV+JFqukzCfh6wuufRZKxbMCVyfNd2bYxVv3jKR8Cg8l4OYdQKnH/Ie9xxJVMu2Loc7lVHhqliyypZe5iSwM1BCtmpR8QUX6CKChxQBGEJIwj4cJPS0YcNCTFwHQ+IEIa7jDCMUyJuSipHCIfaGvn3atTM2pL3KmWi3R6f49ApymtgiT0Q6QVidZup4qjMr9rfcQ51T3W1AfzfLFRArcU3sX76x8r8+VYtED4e6Bk41xZpR1XlZllR3Rd3c/FKVpAwxcQp3KS4Ie9o57rOpPYmuXfXW0fE3rVSs2nuZNsW7uiUN2P45zknQ2C3b++W9s0qpepSNOo8NbGKb5nmAKk5QQ13P8RFPeDZOjcS4M+4/pUYu86zj2zIePgBydpF3</latexit> 10 4 2.069 proteins 274.515 molecules 402.000 interactions + 50.000 interactions -
Construction Development of Large-scale kernel method Method From kernel back to features Large-Scale SVM Results Performance in di ff erent prediction situations Comparison to DL
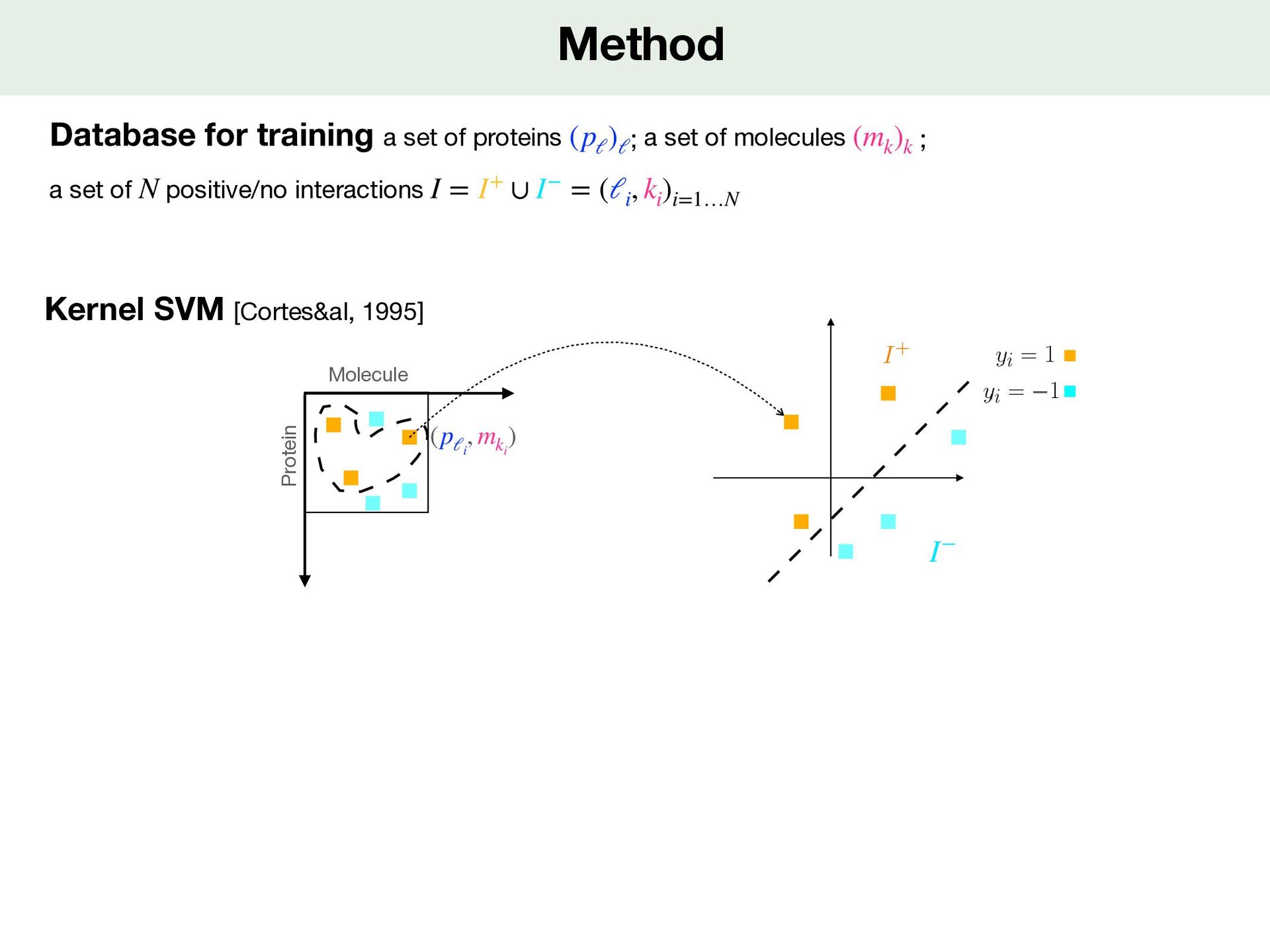
set of molecules ; a set of positive/no interactions (pℓ )ℓ (mk )k N I = I+ ∪ I− = (ℓi , ki )i=1…N Molecule Protein (pℓi , mki ) Kernel SVM [Cortes&al, 1995] <latexit sha1_base64="XatMEnUSih1rJU8Wr6s3x1f1ipM=">AAACxnicjVHLTsJAFD3UF+ILdemmkZiYmDQDAsKO6AZ3GOWRIJq2DNhQ2qadaggx8Qfc6qcZ/0D/wjtjSXRBdJq2d84958zce63AdSLB2HtKW1hcWl5Jr2bW1jc2t7LbO63Ij0ObN23f9cOOZUbcdTzeFI5weScIuTm2XN62Rmcy377nYeT43pWYBLw3NoeeM3BsUxB0eX5zdJvNMaNaZcV8VWdGibFCpUwBOy5USiU9bzC1ckhWw8++4Rp9+LARYwwOD4JiFyYierrIgyEgrIcpYSFFjspzPCJD2phYnBgmoSP6DmnXTVCP9tIzUmqbTnHpDUmp44A0PvFCiuVpusrHylmi87ynylPebUJ/K/EaEypwR+hfuhnzvzpZi8AAFVWDQzUFCpHV2YlLrLoib67/qEqQQ0CYjPuUDym2lXLWZ11pIlW77K2p8h+KKVG5txNujE95SxrwbIr6/KBVMPJlo3RRzNVOk1GnsYd9HNI8T1BDHQ00yXuIZ7zgVatrnhZrD99ULZVodvFraU9fQDOQQQ==</latexit> I+ I−
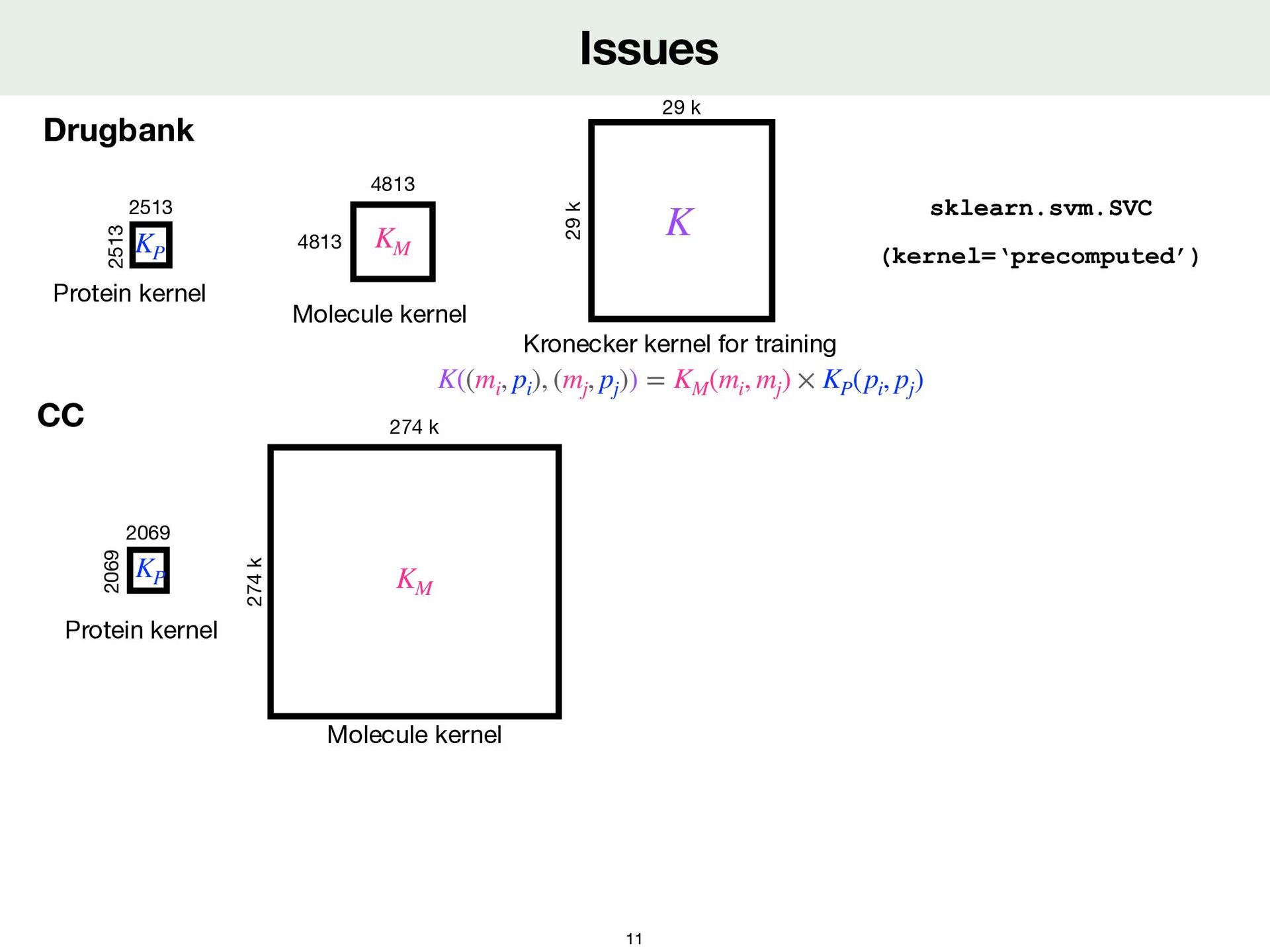
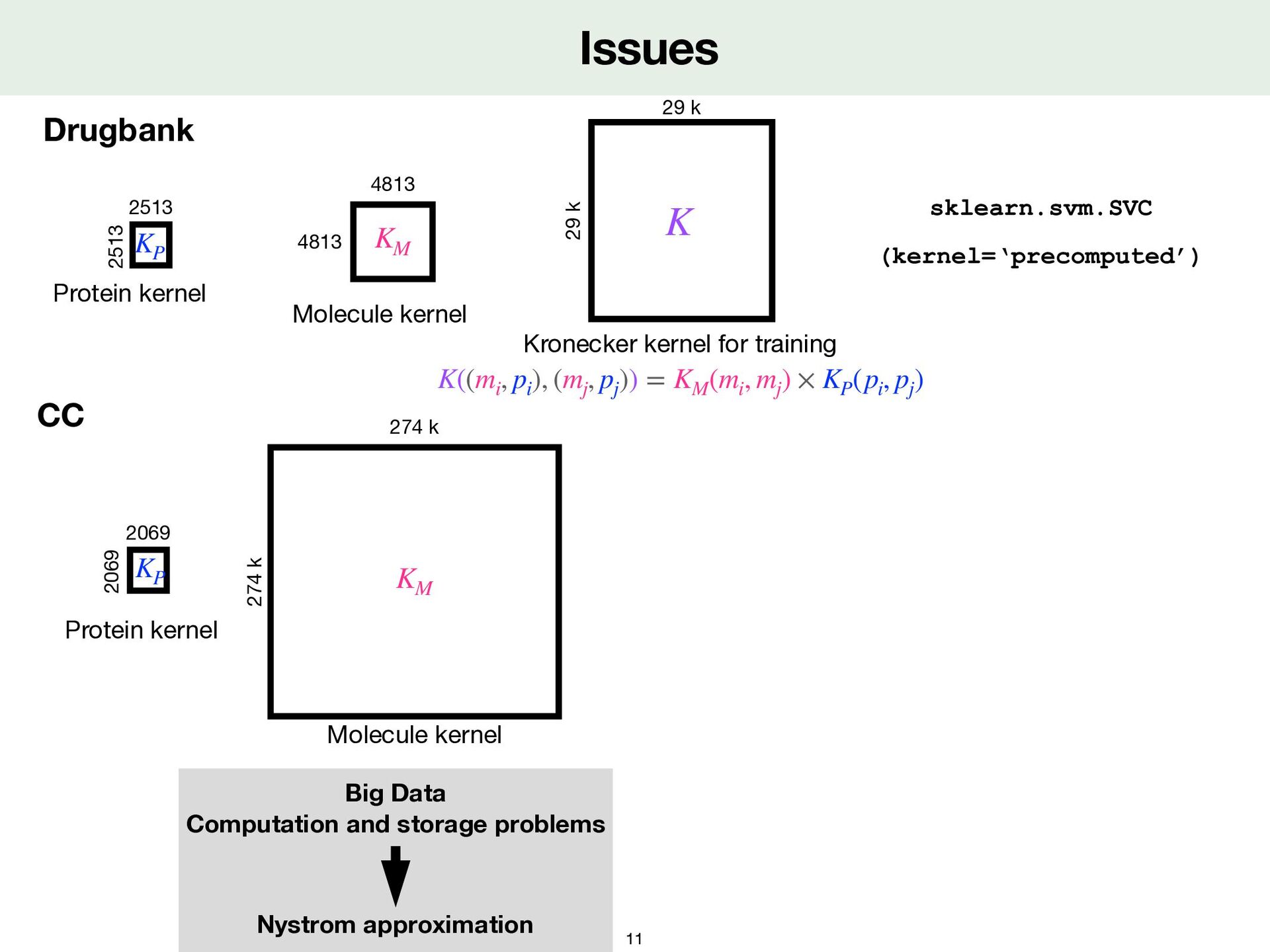
2069 2069 Protein kernel KP 4813 4813 Molecule kernel KM 29 k 29 k K 2513 2513 Protein kernel KP K((mi , pi ), (mj , pj )) = KM (mi , mj ) × KP (pi , pj )
2069 2069 Protein kernel KP 4813 4813 Molecule kernel KM 29 k 29 k K 2513 2513 Protein kernel KP 274 k 274 k Molecule kernel KM K((mi , pi ), (mj , pj )) = KM (mi , mj ) × KP (pi , pj )
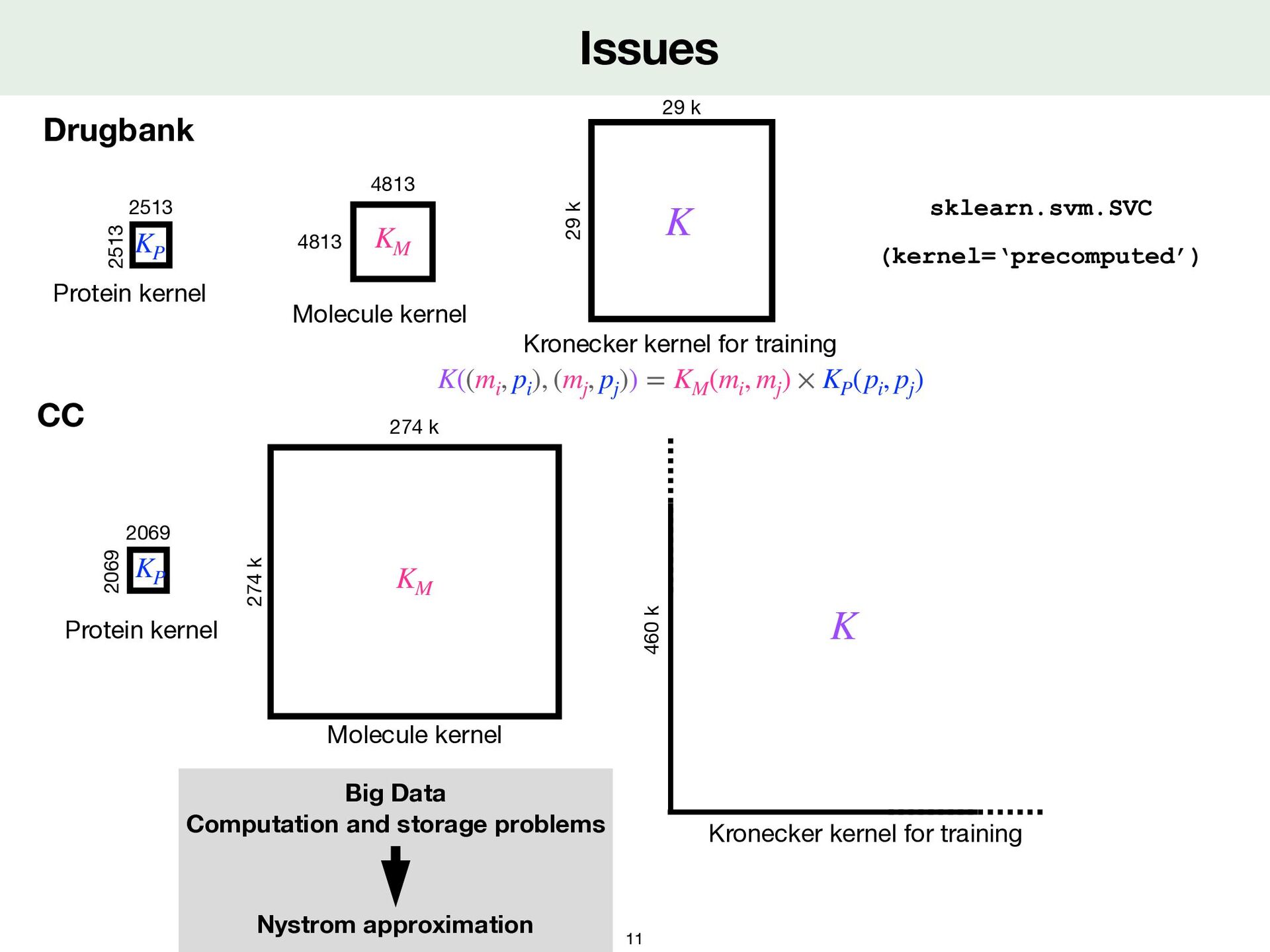
Data Computation and storage problems Nystrom approximation CC 2069 2069 Protein kernel KP 4813 4813 Molecule kernel KM 29 k 29 k K 2513 2513 Protein kernel KP 274 k 274 k Molecule kernel KM K((mi , pi ), (mj , pj )) = KM (mi , mj ) × KP (pi , pj )
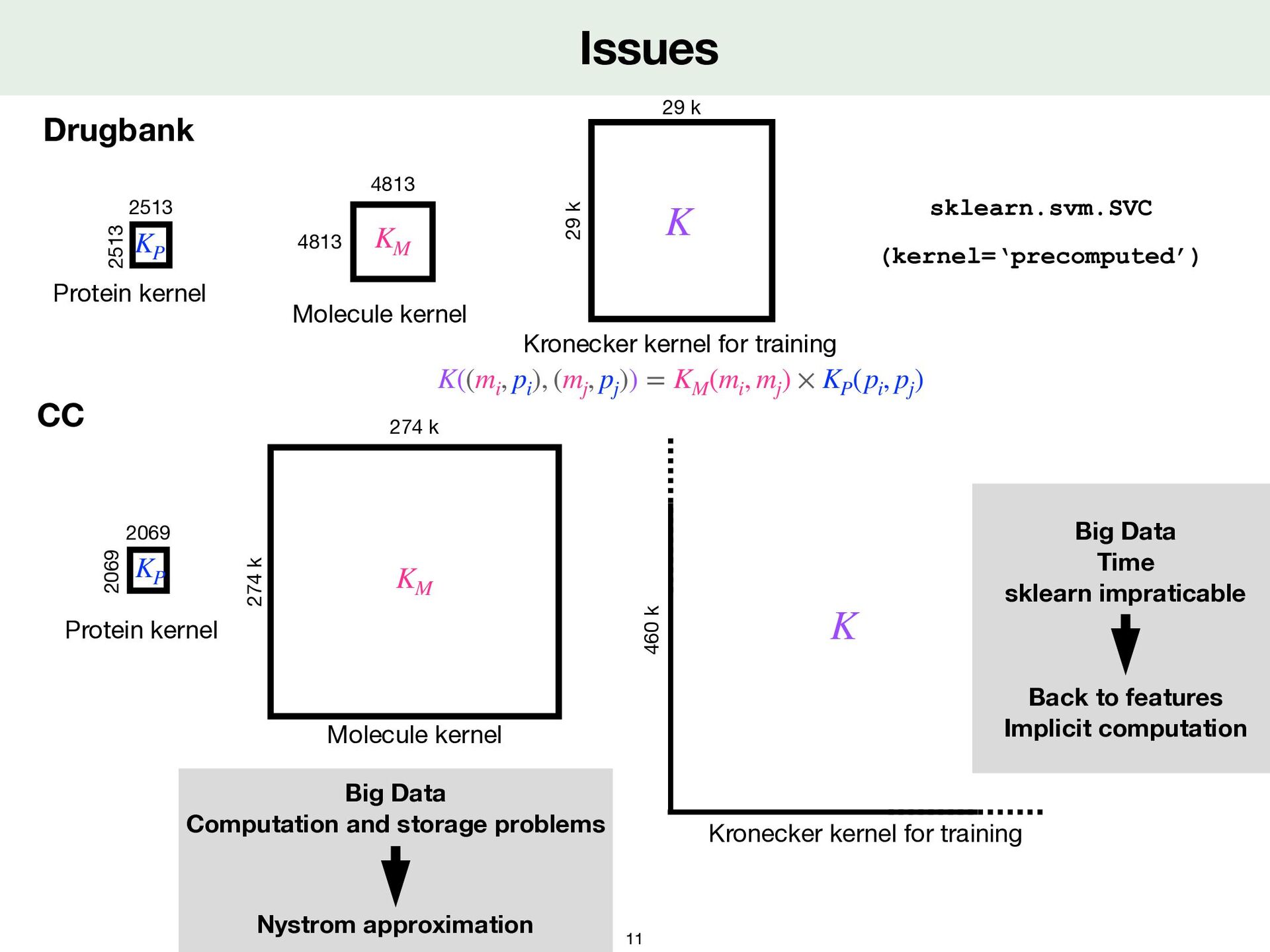
Data Computation and storage problems Nystrom approximation CC 2069 2069 Protein kernel KP 4813 4813 Molecule kernel KM 29 k 29 k K 2513 2513 Protein kernel KP 274 k 274 k Molecule kernel KM 460 k Kronecker kernel for training K K((mi , pi ), (mj , pj )) = KM (mi , mj ) × KP (pi , pj )
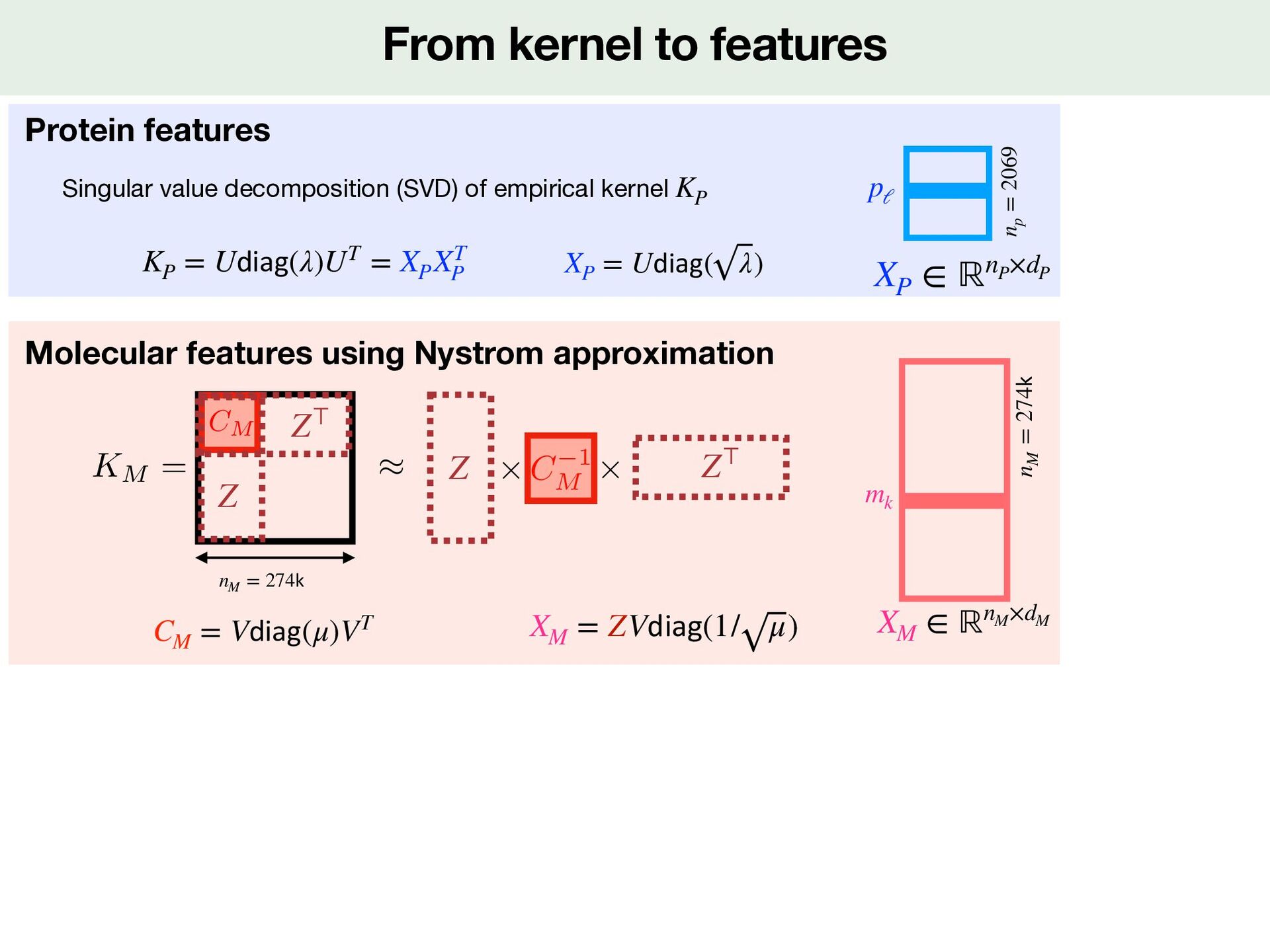
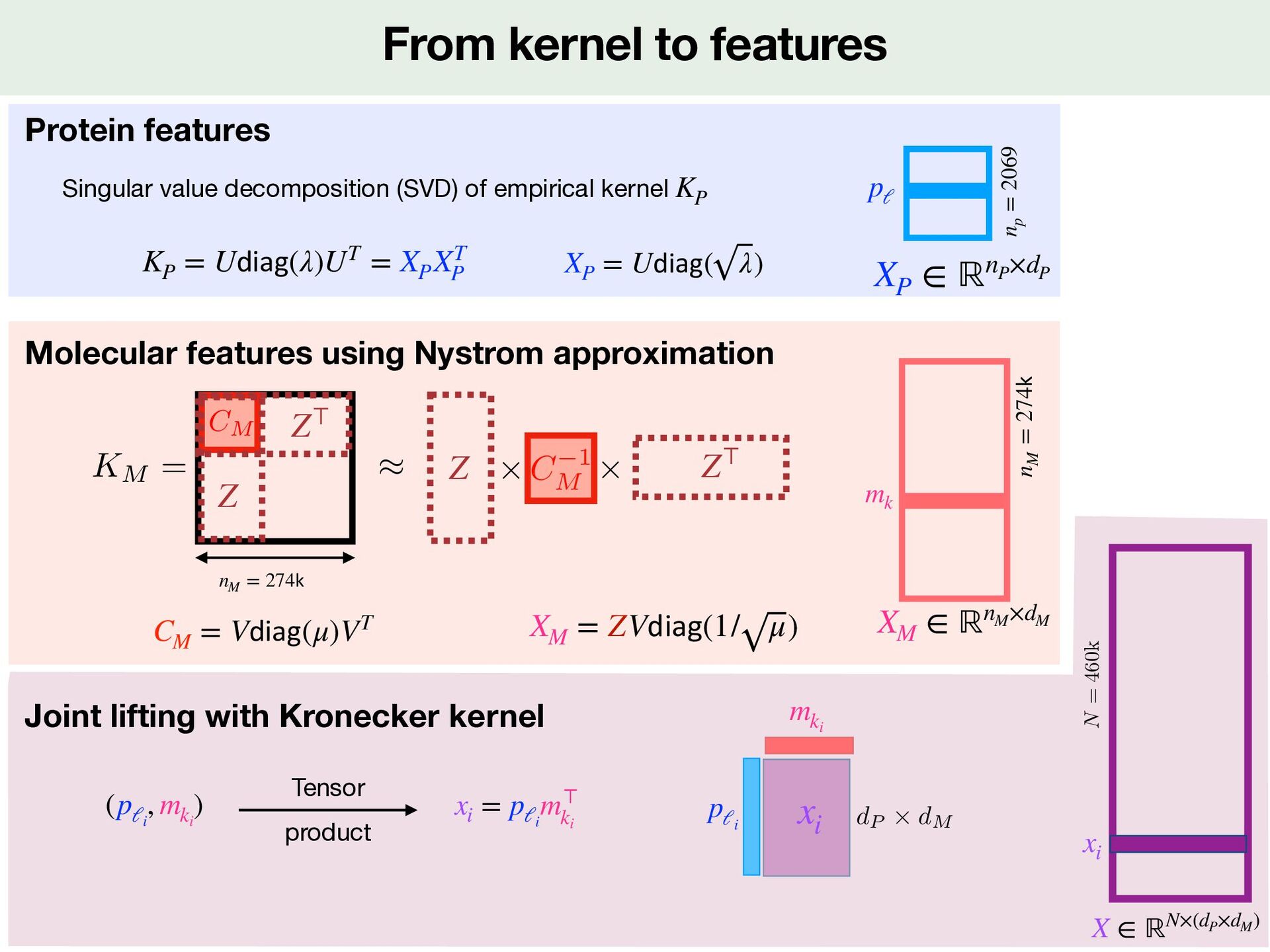
Data Computation and storage problems Nystrom approximation CC 2069 2069 Protein kernel KP 4813 4813 Molecule kernel KM 29 k 29 k K Big Data Time sklearn impraticable Back to features Implicit computation 2513 2513 Protein kernel KP 274 k 274 k Molecule kernel KM 460 k Kronecker kernel for training K K((mi , pi ), (mj , pj )) = KM (mi , mj ) × KP (pi , pj )
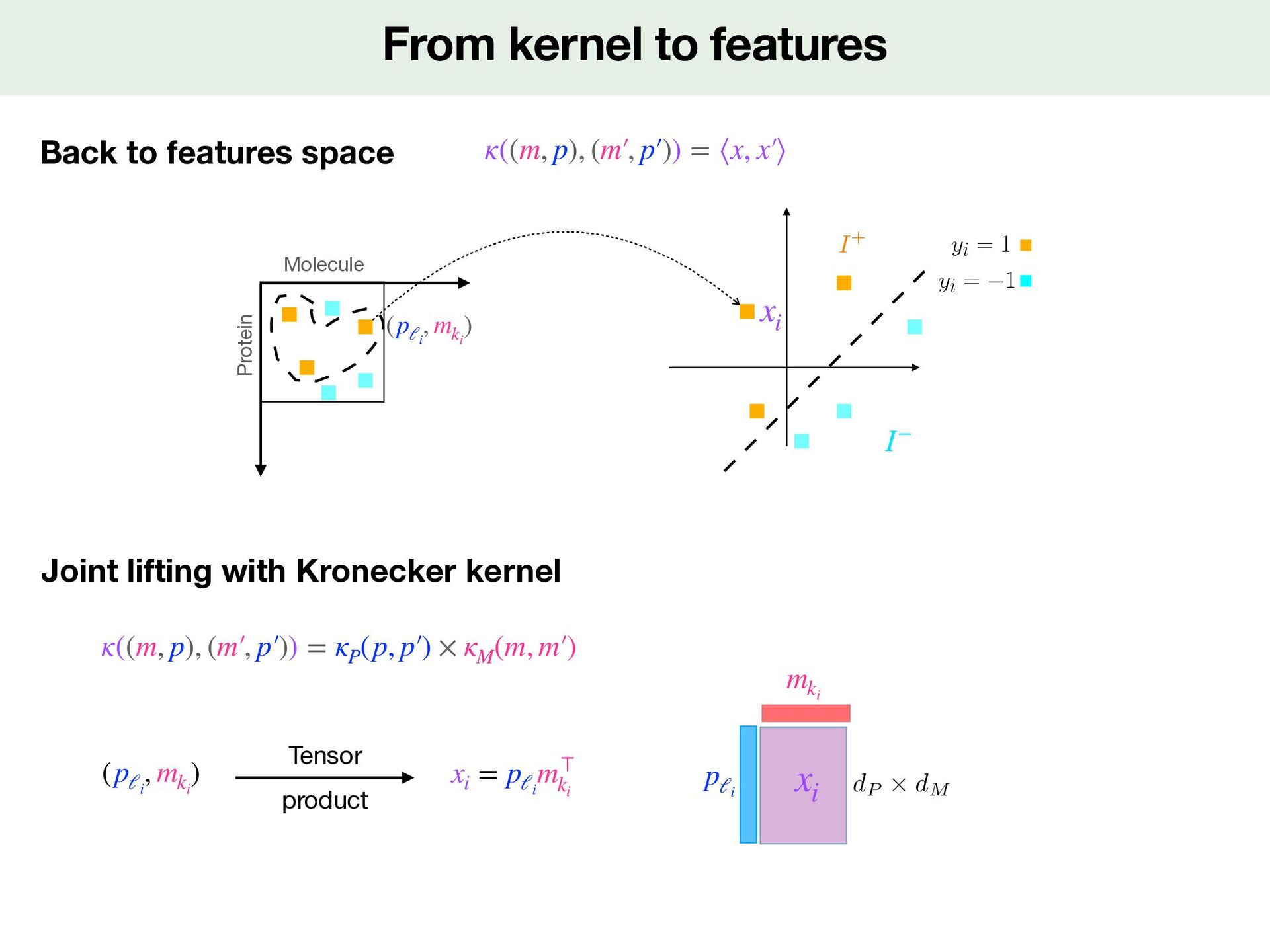
∥w∥2 SVM in feature space <latexit sha1_base64="XatMEnUSih1rJU8Wr6s3x1f1ipM=">AAACxnicjVHLTsJAFD3UF+ILdemmkZiYmDQDAsKO6AZ3GOWRIJq2DNhQ2qadaggx8Qfc6qcZ/0D/wjtjSXRBdJq2d84958zce63AdSLB2HtKW1hcWl5Jr2bW1jc2t7LbO63Ij0ObN23f9cOOZUbcdTzeFI5weScIuTm2XN62Rmcy377nYeT43pWYBLw3NoeeM3BsUxB0eX5zdJvNMaNaZcV8VWdGibFCpUwBOy5USiU9bzC1ckhWw8++4Rp9+LARYwwOD4JiFyYierrIgyEgrIcpYSFFjspzPCJD2phYnBgmoSP6DmnXTVCP9tIzUmqbTnHpDUmp44A0PvFCiuVpusrHylmi87ynylPebUJ/K/EaEypwR+hfuhnzvzpZi8AAFVWDQzUFCpHV2YlLrLoib67/qEqQQ0CYjPuUDym2lXLWZ11pIlW77K2p8h+KKVG5txNujE95SxrwbIr6/KBVMPJlo3RRzNVOk1GnsYd9HNI8T1BDHQ00yXuIZ7zgVatrnhZrD99ULZVodvFraU9fQDOQQQ==</latexit> I+ I− xi w
and computation of X Xw min w∈ℝdP×dM LHinge(y, Xw) + λ 2 ∥w∥2 SVM in feature space <latexit sha1_base64="XatMEnUSih1rJU8Wr6s3x1f1ipM=">AAACxnicjVHLTsJAFD3UF+ILdemmkZiYmDQDAsKO6AZ3GOWRIJq2DNhQ2qadaggx8Qfc6qcZ/0D/wjtjSXRBdJq2d84958zce63AdSLB2HtKW1hcWl5Jr2bW1jc2t7LbO63Ij0ObN23f9cOOZUbcdTzeFI5weScIuTm2XN62Rmcy377nYeT43pWYBLw3NoeeM3BsUxB0eX5zdJvNMaNaZcV8VWdGibFCpUwBOy5USiU9bzC1ckhWw8++4Rp9+LARYwwOD4JiFyYierrIgyEgrIcpYSFFjspzPCJD2phYnBgmoSP6DmnXTVCP9tIzUmqbTnHpDUmp44A0PvFCiuVpusrHylmi87ynylPebUJ/K/EaEypwR+hfuhnzvzpZi8AAFVWDQzUFCpHV2YlLrLoib67/qEqQQ0CYjPuUDym2lXLWZ11pIlW77K2p8h+KKVG5txNujE95SxrwbIr6/KBVMPJlo3RRzNVOk1GnsYd9HNI8T1BDHQ00yXuIZ7zgVatrnhZrD99ULZVodvFraU9fQDOQQQ==</latexit> I+ I− xi w
and computation of X Xw min w∈ℝdP×dM LHinge(y, Xw) + λ 2 ∥w∥2 Optimization problem solved with matrix/vector implicit computation Key idea (Xw)i = ⟨pℓi m⊤ ki , w⟩ = ⟨pℓi , wmki ⟩ Time Space Explicit Xw Implicit with XM and XP N × (dP × dM ) N × (dP × dM ) N × dM np × dP + nM × dM SVM in feature space <latexit sha1_base64="XatMEnUSih1rJU8Wr6s3x1f1ipM=">AAACxnicjVHLTsJAFD3UF+ILdemmkZiYmDQDAsKO6AZ3GOWRIJq2DNhQ2qadaggx8Qfc6qcZ/0D/wjtjSXRBdJq2d84958zce63AdSLB2HtKW1hcWl5Jr2bW1jc2t7LbO63Ij0ObN23f9cOOZUbcdTzeFI5weScIuTm2XN62Rmcy377nYeT43pWYBLw3NoeeM3BsUxB0eX5zdJvNMaNaZcV8VWdGibFCpUwBOy5USiU9bzC1ckhWw8++4Rp9+LARYwwOD4JiFyYierrIgyEgrIcpYSFFjspzPCJD2phYnBgmoSP6DmnXTVCP9tIzUmqbTnHpDUmp44A0PvFCiuVpusrHylmi87ynylPebUJ/K/EaEypwR+hfuhnzvzpZi8AAFVWDQzUFCpHV2YlLrLoib67/qEqQQ0CYjPuUDym2lXLWZ11pIlW77K2p8h+KKVG5txNujE95SxrwbIr6/KBVMPJlo3RRzNVOk1GnsYd9HNI8T1BDHQ00yXuIZ7zgVatrnhZrD99ULZVodvFraU9fQDOQQQ==</latexit> I+ I− xi w
is too big for both storage and computation of X Xw min w∈ℝdP×dM LHinge(y, Xw) + λ 2 ∥w∥2 Optimization problem solved with matrix/vector implicit computation Key idea (Xw)i = ⟨pℓi m⊤ ki , w⟩ = ⟨pℓi , wmki ⟩ Time Space Explicit Xw Implicit with XM and XP N × (dP × dM ) N × (dP × dM ) N × dM np × dP + nM × dM SVM in feature space <latexit sha1_base64="XatMEnUSih1rJU8Wr6s3x1f1ipM=">AAACxnicjVHLTsJAFD3UF+ILdemmkZiYmDQDAsKO6AZ3GOWRIJq2DNhQ2qadaggx8Qfc6qcZ/0D/wjtjSXRBdJq2d84958zce63AdSLB2HtKW1hcWl5Jr2bW1jc2t7LbO63Ij0ObN23f9cOOZUbcdTzeFI5weScIuTm2XN62Rmcy377nYeT43pWYBLw3NoeeM3BsUxB0eX5zdJvNMaNaZcV8VWdGibFCpUwBOy5USiU9bzC1ckhWw8++4Rp9+LARYwwOD4JiFyYierrIgyEgrIcpYSFFjspzPCJD2phYnBgmoSP6DmnXTVCP9tIzUmqbTnHpDUmp44A0PvFCiuVpusrHylmi87ynylPebUJ/K/EaEypwR+hfuhnzvzpZi8AAFVWDQzUFCpHV2YlLrLoib67/qEqQQ0CYjPuUDym2lXLWZ11pIlW77K2p8h+KKVG5txNujE95SxrwbIr6/KBVMPJlo3RRzNVOk1GnsYd9HNI8T1BDHQ00yXuIZ7zgVatrnhZrD99ULZVodvFraU9fQDOQQQ==</latexit> I+ I− xi w
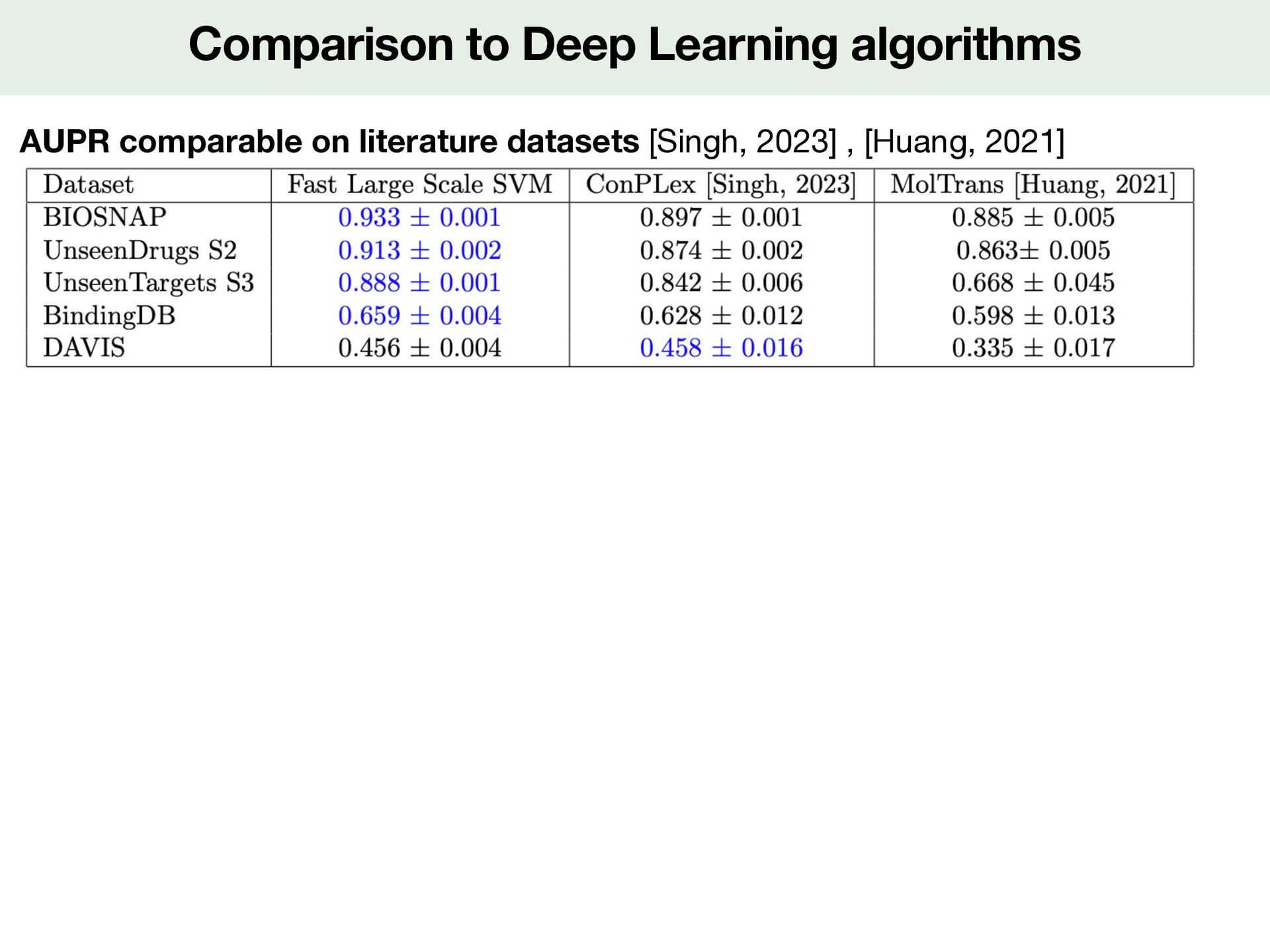
Construction Development of Large-scale kernel method Method From kernel back to features Results Performance in di ff erent prediction situations Comparison to Deep Learning
proteins Initial problem understanding biological mechanisms associated to a set of 20 di ff erentially active molecules found by Phenotypic survival screen
proteins Initial problem understanding biological mechanisms associated to a set of 20 di ff erentially active molecules found by Phenotypic survival screen Contributions: A large new molecule/protein interactions dataset Large-scale kernel method : Fast & State of the Art
proteins Perspectives: Analysis of the target proteins predicted for the 20 di ff erentially active molecules Initial problem understanding biological mechanisms associated to a set of 20 di ff erentially active molecules found by Phenotypic survival screen Contributions: A large new molecule/protein interactions dataset Large-scale kernel method : Fast & State of the Art
the “DIM AI4IDF” Sylvie RODRIGUES-FERREIRA Clara NAHMIAS Véronique STOVEN Chloé AZENCOTT Thanks to CBIO and U900 teams Thanks for your attention! Olivier COLLIER
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
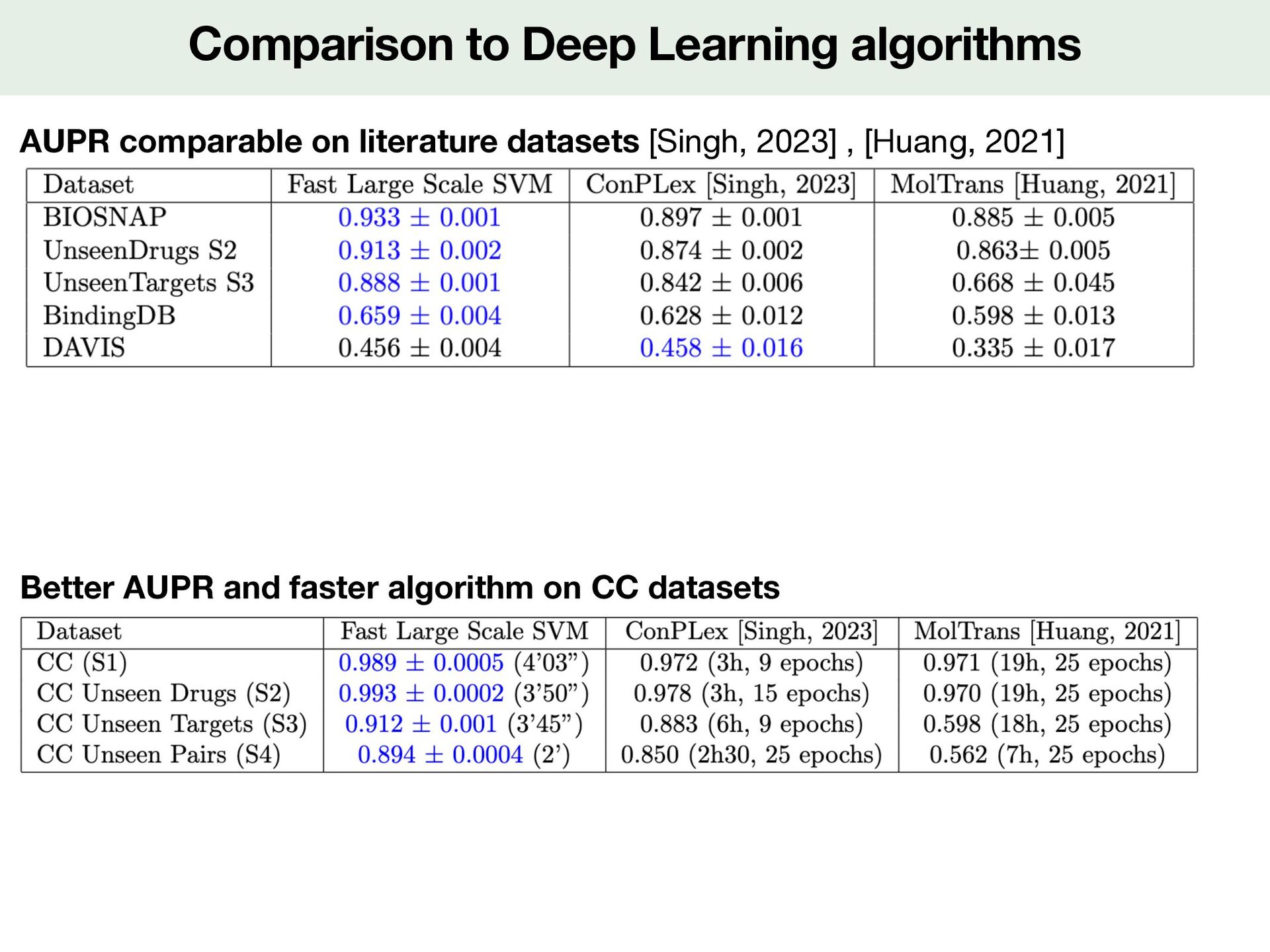
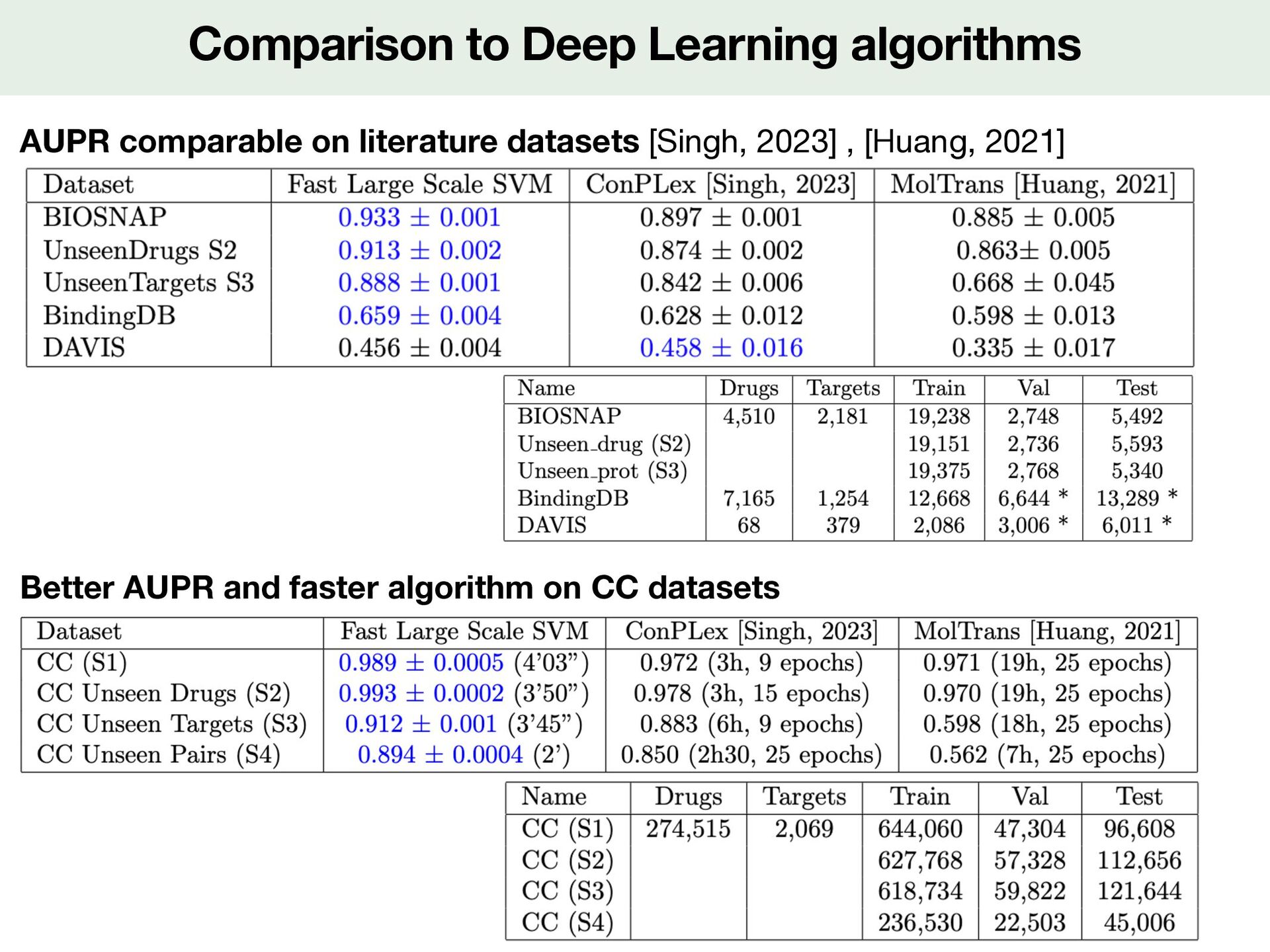
![Performance in different prediction situations 4 prediction scenarii [Playe, 2018]](https://files.speakerdeck.com/presentations/09e5f5ac1dc1438a8c4668167189e384/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}