Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
NN Starterモデルを ベイズNNにして分析してみた
Search
habakan
December 18, 2021
Technology
2.5k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
NN Starterモデルを ベイズNNにして分析してみた
Numerai MeetUp Japan 2021
habakan
December 18, 2021
More Decks by habakan
See All by habakan
Exploratory Data Analysis of the Numerai Signals V1 Dataset
habakan
0
580
Numeraiモデルのポートフォリオ構築の試み
habakan
1
470
Other Decks in Technology
See All in Technology
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
1
560
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
160
Kaggleで成長するために意識したこと
prgckwb
2
420
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
2
420
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
2
670
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
150
発表と総括 / Presentations and Summary
ks91
PRO
0
140
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
410
ガバナンスの「ちょうどいい落とし所」を探れ!開発スピードを妨げない運用判断の勘所 / SRE NEXT 2026
genda
1
260
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
420
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
980
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
3
300
Featured
See All Featured
Side Projects
sachag
455
43k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Building Adaptive Systems
keathley
44
3.1k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
420
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
600
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Google's AI Overviews - The New Search
badams
0
1.1k
Transcript
NN Starterのモデルを ベイズNNにして分析してみた Numerai Meetup JAPAN 2021 12/18 habakan (@habakan_f)
1
自己紹介 2 habakan Jobs ・医療系スタートアップのエンジニア ・機械学習を活用したプロダクトを開発 ・扱うデータは動画像が中心 Account ・Twitter: @habakan_f
・https://numer.ai/habakan ・https://signals.numer.ai/habakan
(1) NumeraiにおけるNNの活用事例とモデル構築の課題 (2) 課題に基づいたベイズNNへのモチベーション (3) ベイズNNの検証 (4) Numeraiにおけるベイズアプローチに関してまとめ 3 Agenda
NN Starterのモデルをベイズ化することで 様々な視点でモデルを評価
ForumでのNNの議論事例 ・ResNetによる特徴量変換[1] ・特徴量の正負反転やノイズ付与などのData Augmentation [1] ・Metric Learningによるera間の分析[2] ・ランキング学習の枠組みでLossを定義して学習[3] ・Denoising Auto
Encoderによるデノイズ[4] ・End2EndではなくNNで事前学習をした特徴量を利用[5] ・Pseudo Labellingを利用した学習[6] 4 NumeraiにおけるNNの活用 アーキテクチャや損失関数などを活用した柔軟なモデル構築 ForumでもNNの利用はいくつか議論されている
NNは学習設定が多く、学習結果の要因が分析しにくい 特徴選択, アーキテクチャ, Loss, ミニバッチ方法, Optimizer, Epoch数, 学習率, 正則化 etc…
Forumでのアイデア共有があっても、設定の違いにより上手くいかないケースがある 初期値のseedを変更するだけパフォーマンスが大きくかわる ・設定した初期化分布からパラメータの初期値をサンプル 再現性を考慮した評価に基づいたモデル選択が必要 ・K-foldや初期値のseed値を変えて複数モデルを構築し、 評価やアンサンブルをすることで安定化 5 NNの評価に課題がある 初期値によって評価が変動し、再現性を担保しにくい 結果的に検証コストが高くなる
モデル選択のために複数モデルを構築し評価・運用 ↓ ベイズの枠組みでパラメータの分布を推定し 複数モデルを構築することで評価ができないか? 6
7 ベイズNNについて 目的変数の生成モデルとして表現 NNのパラメータを確率分布としてモデリング Charles 15 [7] 生成モデル:関数f(x)をNNで表現 事前分布:正規分布とする場合 事後分布の計算(学習)
通常のNN ベイズNN
1. 分布をもとにパラメータを複数サンプルして評価 ・複数パラメータを利用したアンサンブル ・評価指標を分布としてモデルを評価 2. 不確実性を利用したBurn Eraの検出評価 予測分布のstdを活用した、Burn Era検出の評価を比較 3.
targetの生成過程を考慮した確率モデルの構築・評価 複数targetの生成過程などもモデルに考慮して分析 8 検証内容 パラメータの分布を推定して、 分布を活用してモデルを新たな視点で評価できないか?
katsuさん公開のNN Starter Notebook [8] https://www.kaggle.com/code1110/numerai-nn-baseline-with-new-massive-data ・Borutaで選択した38個の特徴量を入力 ・4層の全結合層で構成 ・Dropout, ガウスノイズによる正則化 ・複数targetを予測
シンプルにしたものをbaselineとして検証 ・Borutaで選択した38個の特徴量を入力 ・4層の全結合層で構成 ・正則化レイヤーなし ・targetは一つのみ予測 9 NN Starterをベースに検証
ベースライン ・損失関数: MSE ・パラメータはHeの初期化 ・学習率: 1e-2 ・バッチサイズ: 4096 ・エポック数: 30
・最適化手法: Adam ・early stoppingなし 10 ベイズNN ・事後分布の計算: SVI(変分推論) ・以下の生成モデルを仮定 ・priorのscaleはHe初期化に準拠 ・学習率: 1e-3 ・バッチサイズ: 4096 ・エポック数: 30 ・最適化手法: Adam ・early stoppingなし 学習方法 training_data.csvを学習に、validation_dataを評価データとして利用 validation_dataを監視したearly stoppingなどはなし 30エポック決め打ちでのvalidation_dataの結果を評価
一様分布 非正則な分布として設定 正規分布 MAP推定の場合、L2正則化(Ridge)に相当 ガウスノイズの追加をパラメータの分布として考える ラプラス分布 MAP推定の場合、L1正則化(Lasso)に相当 全結合層のパラメータがスパースな行列となる 11 事前分布の設定
正則化を考慮し、事前分布を設定して比較 ベイズNNの評価 学習後、1000組のパラメータをサンプルして評価に利用 ・1000組の予測それぞれで評価を計算することで評価の分布を作成 ・1000組の予測を平均して1つの評価を計算
検証1:パラメータを複数サンプルして評価 12
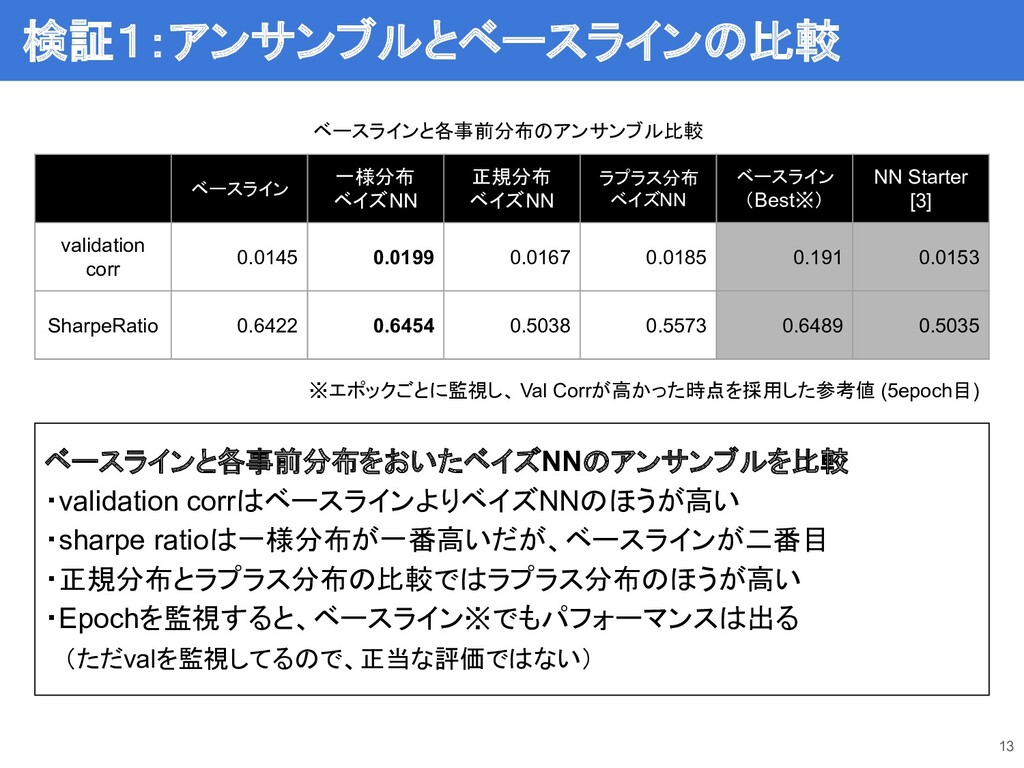
ベースラインと各事前分布をおいたベイズNNのアンサンブルを比較 ・validation corrはベースラインよりベイズNNのほうが高い ・sharpe ratioは一様分布が一番高いだが、ベースラインが二番目 ・正規分布とラプラス分布の比較ではラプラス分布のほうが高い ・Epochを監視すると、ベースライン※でもパフォーマンスは出る (ただvalを監視してるので、正当な評価ではない) 13 ベースラインと各事前分布のアンサンブル比較
ベースライン 一様分布 ベイズNN 正規分布 ベイズNN ラプラス分布 ベイズNN ベースライン (Best※) NN Starter [3] validation corr 0.0145 0.0199 0.0167 0.0185 0.191 0.0153 SharpeRatio 0.6422 0.6454 0.5038 0.5573 0.6489 0.5035 ※エポックごとに監視し、 Val Corrが高かった時点を採用した参考値 (5epoch目) 検証1:アンサンブルとベースラインの比較
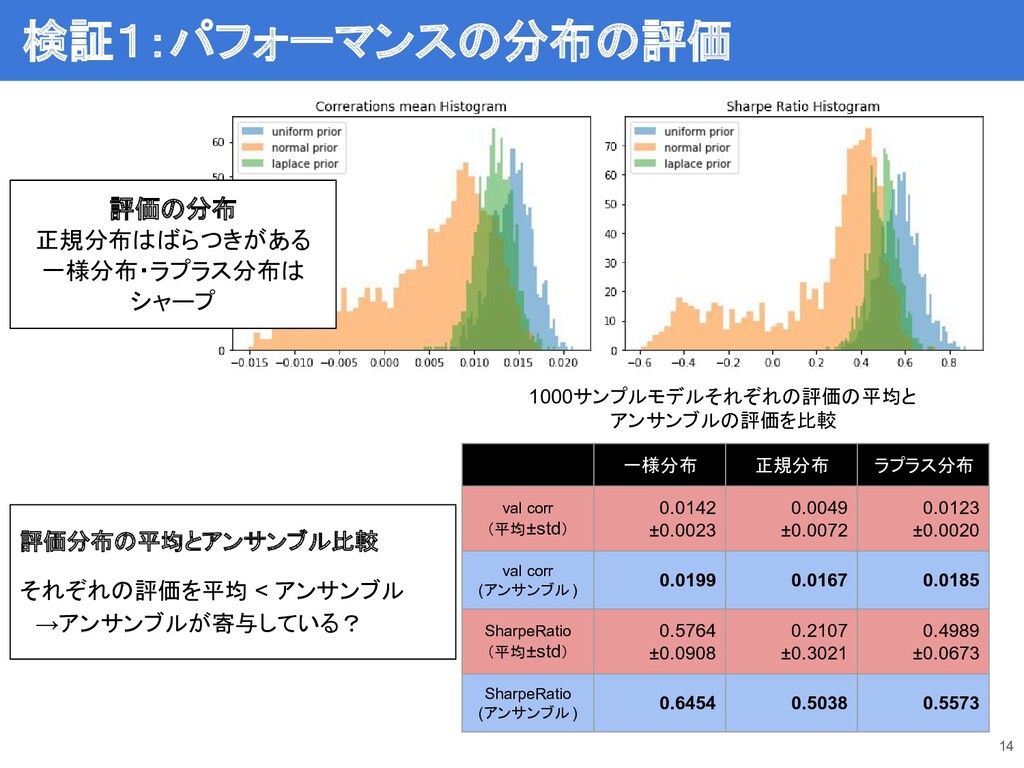
評価分布の平均とアンサンブル比較 それぞれの評価を平均 < アンサンブル →アンサンブルが寄与している? 14 1000サンプルモデルそれぞれの評価の平均と アンサンブルの評価を比較 一様分布 正規分布
ラプラス分布 val corr (平均±std) 0.0142 ±0.0023 0.0049 ±0.0072 0.0123 ±0.0020 val corr (アンサンブル) 0.0199 0.0167 0.0185 SharpeRatio (平均±std) 0.5764 ±0.0908 0.2107 ±0.3021 0.4989 ±0.0673 SharpeRatio (アンサンブル) 0.6454 0.5038 0.5573 検証1:パフォーマンスの分布の評価 評価の分布 正規分布はばらつきがある 一様分布・ラプラス分布は シャープ
検証2:不確実性に利用したBurn Eraの検出評価 15
ベイズNNの予測分布を活用 複数の予測から標準偏差を計算し、予測の不確実性とする 不確実性から、あるEraで自身の予測がBurnするか検出できないか? 平均不確実性によるBurn判定をAUCで計算 Validationの各eraのCorrで負の値になったときをBurn Eraとする 各データの標準偏差をEraごとに平均し、閾値でBurnを検出ことを想定 閾値による実運用も考慮して、相関ではなくAUCで評価した AUCが良いほど標準偏差が機能して事後分布を計算できている Burn検出もそうだが、事後分布も適切かどうかを評価したい
16 検証2:不確実性による自身のBurn Eraの検出
Val Corr・Sharpe Ratioの高かった一様分布はチャンスレート以下 不確実性という意味では正則化をおいたほうが良さそう 精度のみの比較では一様分布だが、 今回の評価も加味するとラプラス分布もモデル候補として上がる 17 検証2:不確実性による自身のBurn Eraの検出 事前分布によってはチャンスレート(0.5)を超えている
分布比較ではラプラス分布が一番良かった 事前分布 AUC Burn Era数 一様分布 0.4679 28 正規分布 0.6010 33 ラプラス分布 0.6245 31
検証3:複数targetの確率モデルの構築・評価 18
種類の異なるtargetの利用 ・target_nomi ・target_janet ・target_george 19 検証3:targetの確率モデルの構築 モデル出力を複数targetにして事後分布を計算することで、 target_nomiの予測精度がどうなるか比較 上記に異なる仮定をおいた確率モデルを構築し比較 予測期間の異なるtargetの利用
・target_nomi (20d) ・target_nomi_60d
20 検証3:targetの確率モデルの構築 μ target nomi target janet target george μ
target nomi target janet target george μ μ 複数種類のtargetを複数生成するモデルを構築 生成過程の仮説を元に設計して検証 仮説1 targetは同じ分布からサンプル 仮説2 (NN Starter) 分布は異なるがμは同じ潜在変数から変換
21 検証3:targetの確率モデルの構築 一様分布 正規分布 ラプラス分布 仮説1 0.0151(0.5794) 0.0110(0.3735) 0.0122(0.4161) 仮説2
0.0171(0.5891) 0.0080(0.3236) 0.0075(0.3040) 検証1の ベイズNN 0.0199(0.6454) 0.0167(0.5038) 0.0185(0.5573) 仮説1・2の検証結果 target1つのみのベイズNNと比較すると評価が劣後 ・仮説1の同一分布の仮定は厳しそう ・仮説2ではないなら共通する潜在変数は一部 or 存在しない? ・ただ、正規分布, ラプラス分布が大きく劣後している →パラメータ増加によって事後分布の計算が影響していないか?
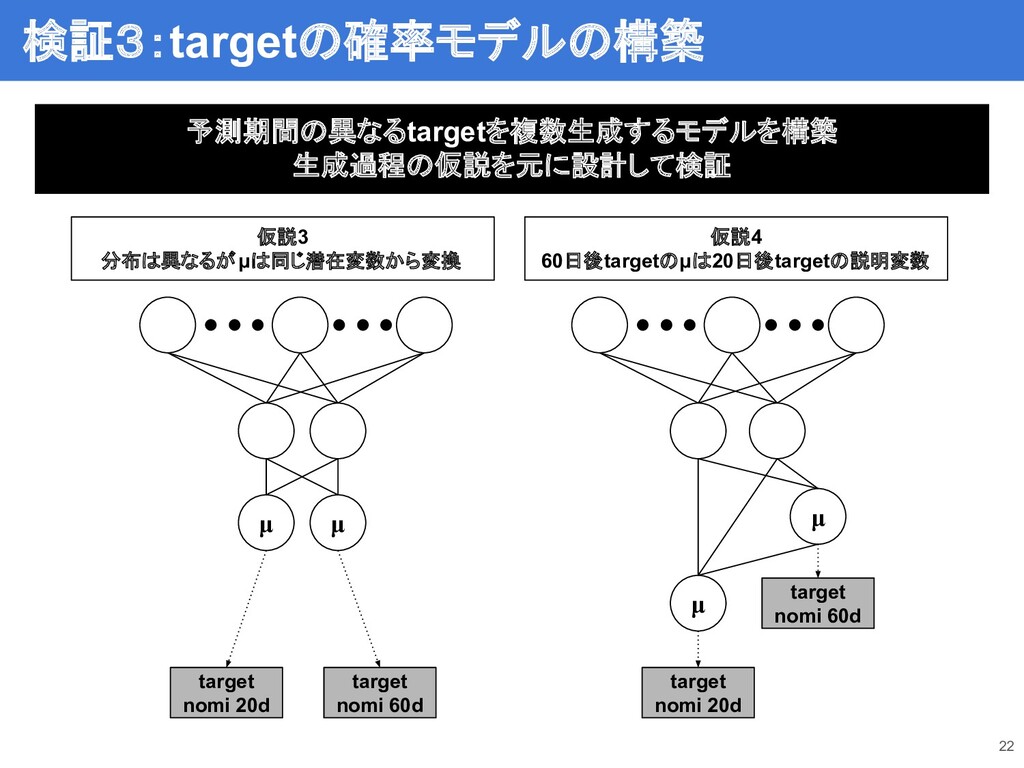
22 検証3:targetの確率モデルの構築 target nomi 20d target nomi 60d μ μ
target nomi 20d target nomi 60d μ μ 予測期間の異なるtargetを複数生成するモデルを構築 生成過程の仮説を元に設計して検証 仮説3 分布は異なるがμは同じ潜在変数から変換 仮説4 60日後targetのμは20日後targetの説明変数
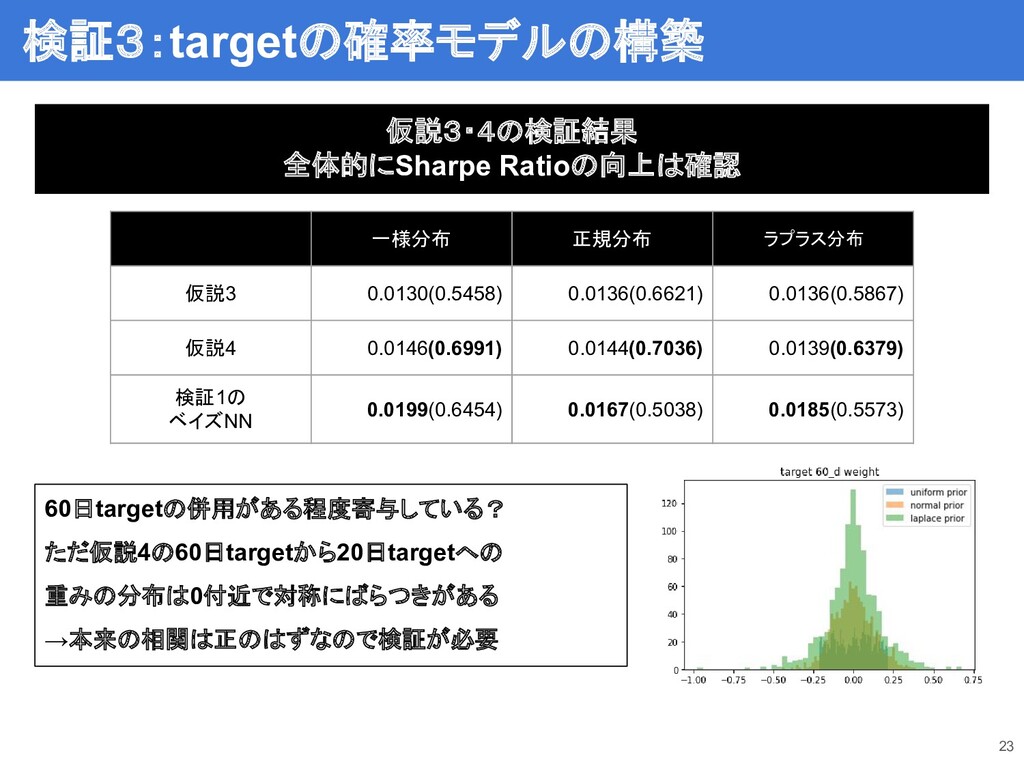
23 検証3:targetの確率モデルの構築 一様分布 正規分布 ラプラス分布 仮説3 0.0130(0.5458) 0.0136(0.6621) 0.0136(0.5867) 仮説4
0.0146(0.6991) 0.0144(0.7036) 0.0139(0.6379) 検証1の ベイズNN 0.0199(0.6454) 0.0167(0.5038) 0.0185(0.5573) 仮説3・4の検証結果 全体的にSharpe Ratioの向上は確認 60日targetの併用がある程度寄与している? ただ仮説4の60日targetから20日targetへの 重みの分布は0付近で対称にばらつきがある →本来の相関は正のはずなので検証が必要
まとめ 24
評価の分布による分析とアンサンブル予測 ・アンサンブル評価は似ているが、評価の分布にばらつきがある ・評価の分布の期待値 < アンサンブルの評価 →NNにおいてもアンサンブルが寄与している 不確実性によるBurn Era、事後分布の評価 Validationの評価だと、一様分布が良かったが Burn Era検出の不確実性の評価だとラプラス分布などが良かった 複数targetの生成過程をモデリングにいれる
・nomi, janet, georgeは同一分布ではなさそう ・target_60dを含めると良さそうだが、さらなる検証が必要 25 今回のベイズNNでの検証まとめ
モデルの情報量が増えたことで、様々な角度で分析が可能に 今回の分析において、ベイズアプローチの本質的な価値は モデルのパラメータ・予測を期待値ではなく分布で取得できるという点 分析情報量が増えることで、Numerai特有の課題を理解しやすくなるかも 長期的モデル選択・難読化データ・回帰タスクとして難しい・Valを妄信できない 既存モデルをベイズ化しただけで、良いモデルが作れるわけではない 単純にベイズ化して精度向上できるかはわからない データを理解をして、良いモデルを構築するための一つの分析手法 従来と同様にベイズモデリングでも上流工程に依存 ・Signals:データの用意
・特徴量の設計・選択 ご利用は計画的に 26 Numeraiにとってのベイズアプローチ
ご清聴ありがとうございました。 27
Appendix 28
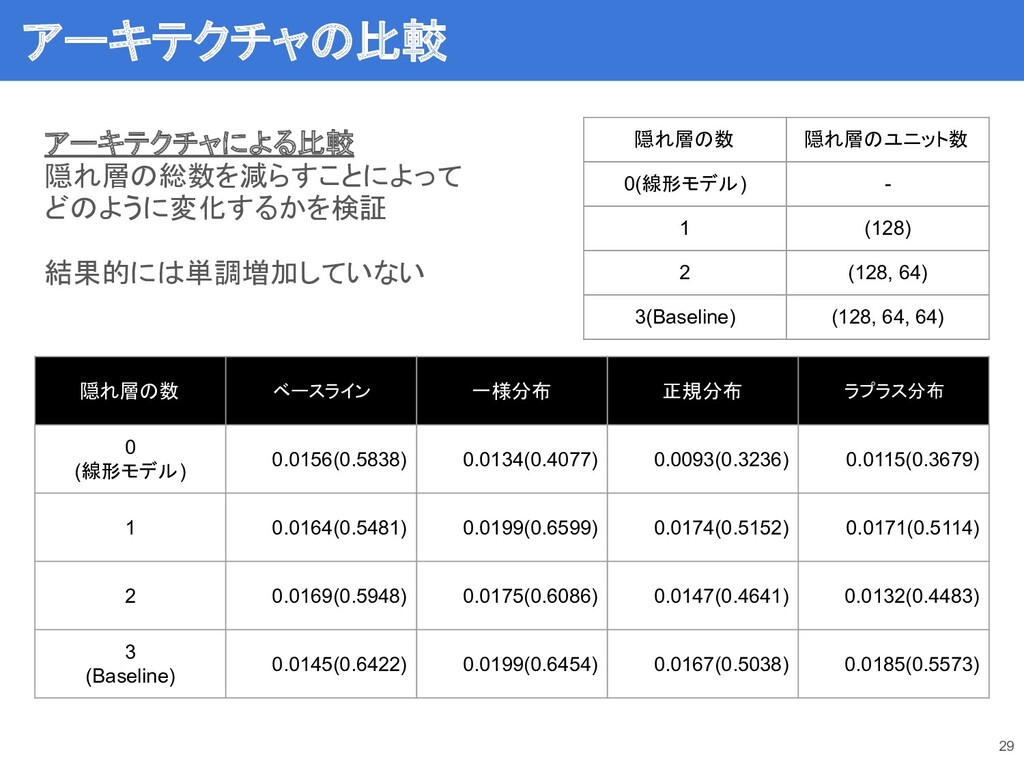
アーキテクチャによる比較 隠れ層の総数を減らすことによって どのように変化するかを検証 結果的には単調増加していない 29 隠れ層の数 ベースライン 一様分布 正規分布 ラプラス分布
0 (線形モデル) 0.0156(0.5838) 0.0134(0.4077) 0.0093(0.3236) 0.0115(0.3679) 1 0.0164(0.5481) 0.0199(0.6599) 0.0174(0.5152) 0.0171(0.5114) 2 0.0169(0.5948) 0.0175(0.6086) 0.0147(0.4641) 0.0132(0.4483) 3 (Baseline) 0.0145(0.6422) 0.0199(0.6454) 0.0167(0.5038) 0.0185(0.5573) アーキテクチャの比較 隠れ層の数 隠れ層のユニット数 0(線形モデル) - 1 (128) 2 (128, 64) 3(Baseline) (128, 64, 64)
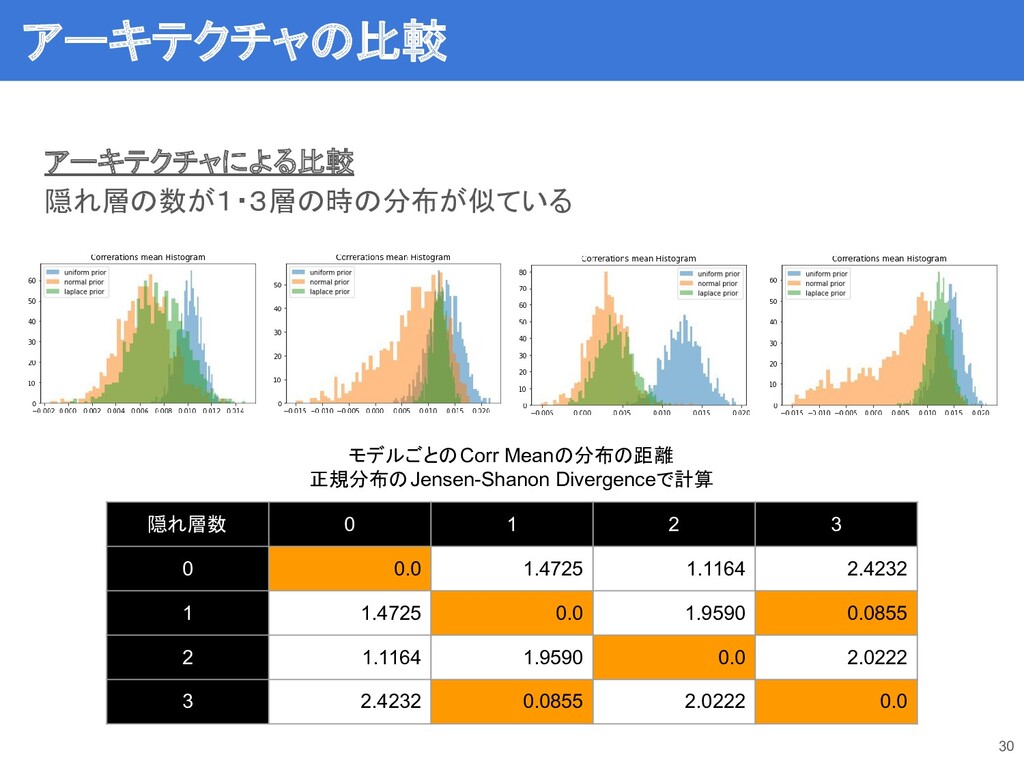
アーキテクチャによる比較 隠れ層の数が1・3層の時の分布が似ている 30 隠れ層数 0 1 2 3 0 0.0
1.4725 1.1164 2.4232 1 1.4725 0.0 1.9590 0.0855 2 1.1164 1.9590 0.0 2.0222 3 2.4232 0.0855 2.0222 0.0 モデルごとのCorr Meanの分布の距離 正規分布のJensen-Shanon Divergenceで計算 アーキテクチャの比較
損失関数を自由に設計することが難しい 設計するのは損失関数ではなく、予測分布になった 回帰問題であれば正規分布、分類問題ではカテゴリカル分布で良いが ランキング学習はどのような分布か考える必要あり ライブラリが整備されたとはいえ、手軽に試せる手法ではなさそう モデルの設計も含めて、ベイズモデリングの知識が必要 アウトプットも悪く言えば、通常評価に+αが追加された形 それが重要かどうかは分析タスクと分析者の方針次第 分析要素として低Priorityならオーバースペックになると個人的に思う 31
ベイズモデリングの課題
[1]https://forum.numer.ai/t/feature-reversing-input-noise/1416 [2]https://forum.numer.ai/t/deep-metric-learning-to-find-a-close-era-to-live/ 1268 [3]https://forum.numer.ai/t/differentiable-spearman-in-pytorch-optimize-for- corr-directly/2287 [4]https://forum.numer.ai/t/autoencoder-and-multitask-mlp-on-new-dataset -from-kaggle-jane-street/4338/11 [5]https://forum.numer.ai/t/nn-architecture-for-0-03-corr-on-validation-set/3 145 [6]https://forum.numer.ai/t/self-supervised-learning-on-pseudo-labels/3371
[7]https://www.kaggle.com/code1110/numerai-nn-baseline-with-new-mass ive-data [8]Weight Uncertainty in Neural Networks 32 参考文献
{kind=link}
{kind=link}
{kind=link}
![ForumでのNNの議論事例 ・ResNetによる特徴量変換[1] ・特徴量の正負反転やノイズ付与などのData Augmentation [1] ・Metric Learningによるera間の分析[2] ・ランキング学習の枠組みでLossを定義して学習[3] ・Denoising Auto](https://files.speakerdeck.com/presentations/cb19a356bec445978e5b81adb4bf7940/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
![7 ベイズNNについて 目的変数の生成モデルとして表現 NNのパラメータを確率分布としてモデリング Charles 15 [7] 生成モデル:関数f(x)をNNで表現 事前分布:正規分布とする場合 事後分布の計算(学習)](https://files.speakerdeck.com/presentations/cb19a356bec445978e5b81adb4bf7940/slide_6.jpg){kind=link}
{kind=link}
![katsuさん公開のNN Starter Notebook [8] https://www.kaggle.com/code1110/numerai-nn-baseline-with-new-massive-data ・Borutaで選択した38個の特徴量を入力 ・4層の全結合層で構成 ・Dropout, ガウスノイズによる正則化 ・複数targetを予測](https://files.speakerdeck.com/presentations/cb19a356bec445978e5b81adb4bf7940/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[1]https://forum.numer.ai/t/feature-reversing-input-noise/1416 [2]https://forum.numer.ai/t/deep-metric-learning-to-find-a-close-era-to-live/ 1268 [3]https://forum.numer.ai/t/differentiable-spearman-in-pytorch-optimize-for- corr-directly/2287 [4]https://forum.numer.ai/t/autoencoder-and-multitask-mlp-on-new-dataset -from-kaggle-jane-street/4338/11 [5]https://forum.numer.ai/t/nn-architecture-for-0-03-corr-on-validation-set/3 145 [6]https://forum.numer.ai/t/self-supervised-learning-on-pseudo-labels/3371](https://files.speakerdeck.com/presentations/cb19a356bec445978e5b81adb4bf7940/slide_31.jpg){kind=link}