TECH in 京都 #2 発表資料です。
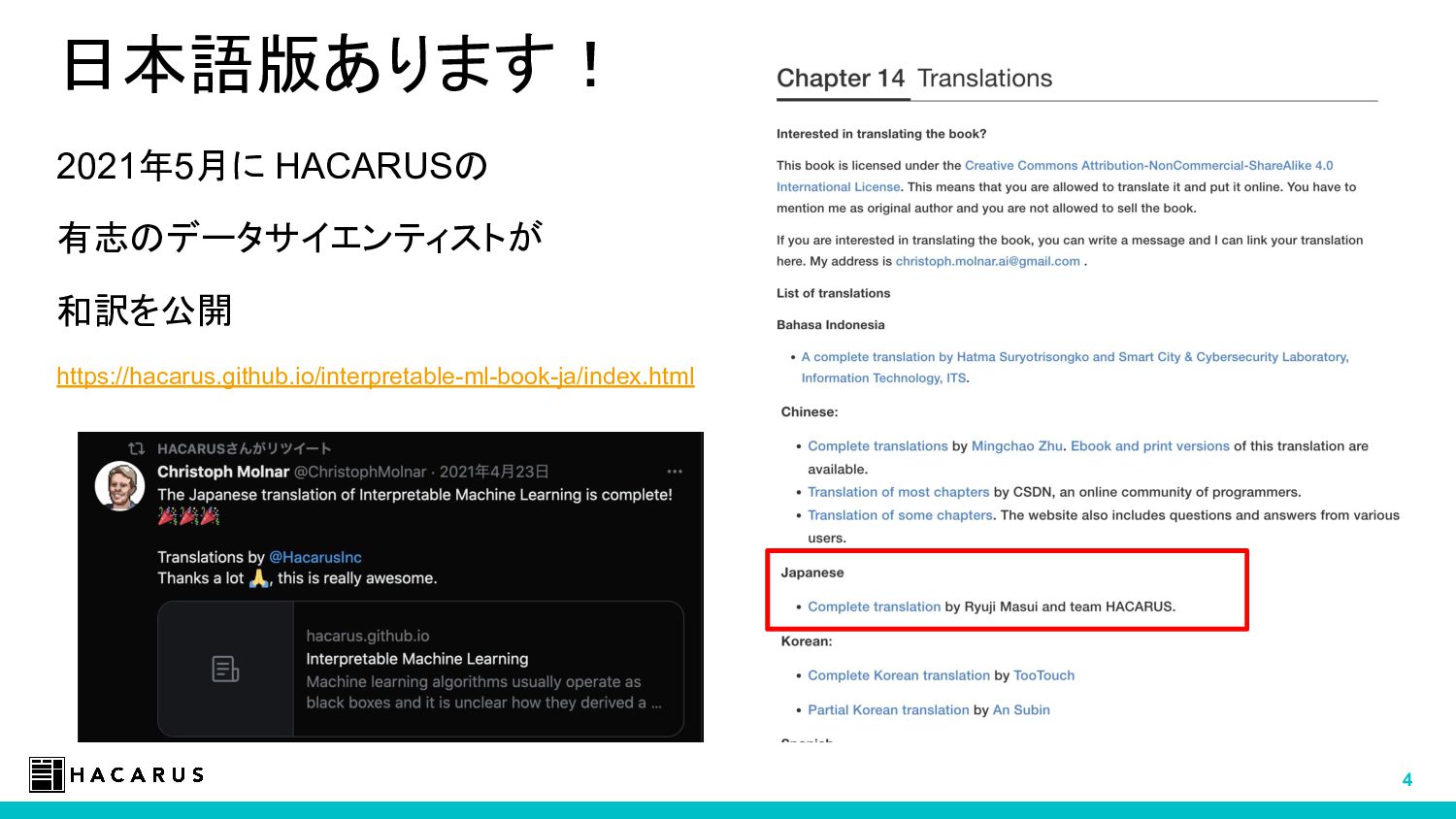
HACARUS の有志のデータサイエンティストによって、Christoph Molnar氏 の Interpretable Machine Learning の和訳を公開しています。 https://hacarus.github.io/interpretable-ml-book-ja/index.html
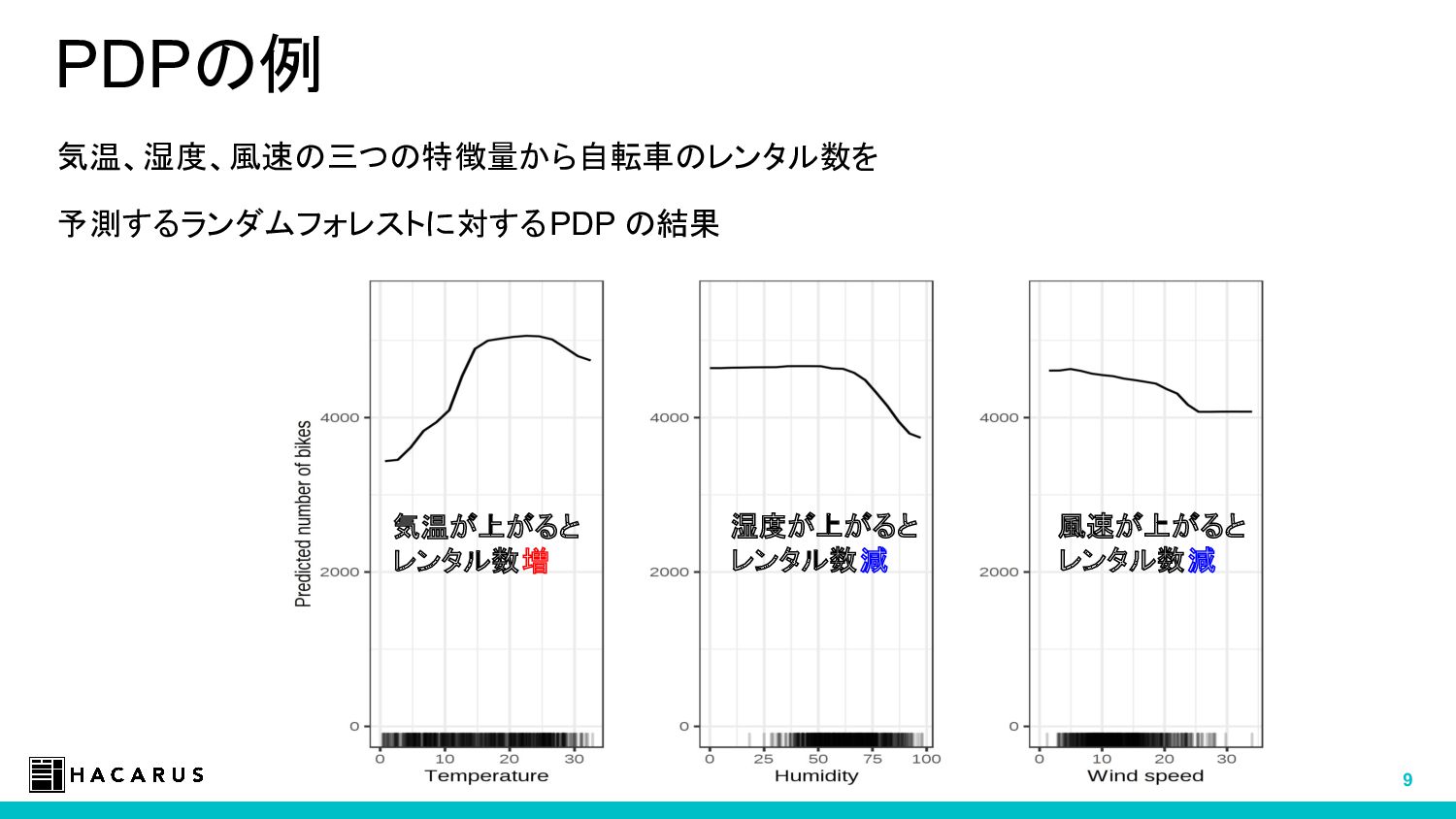
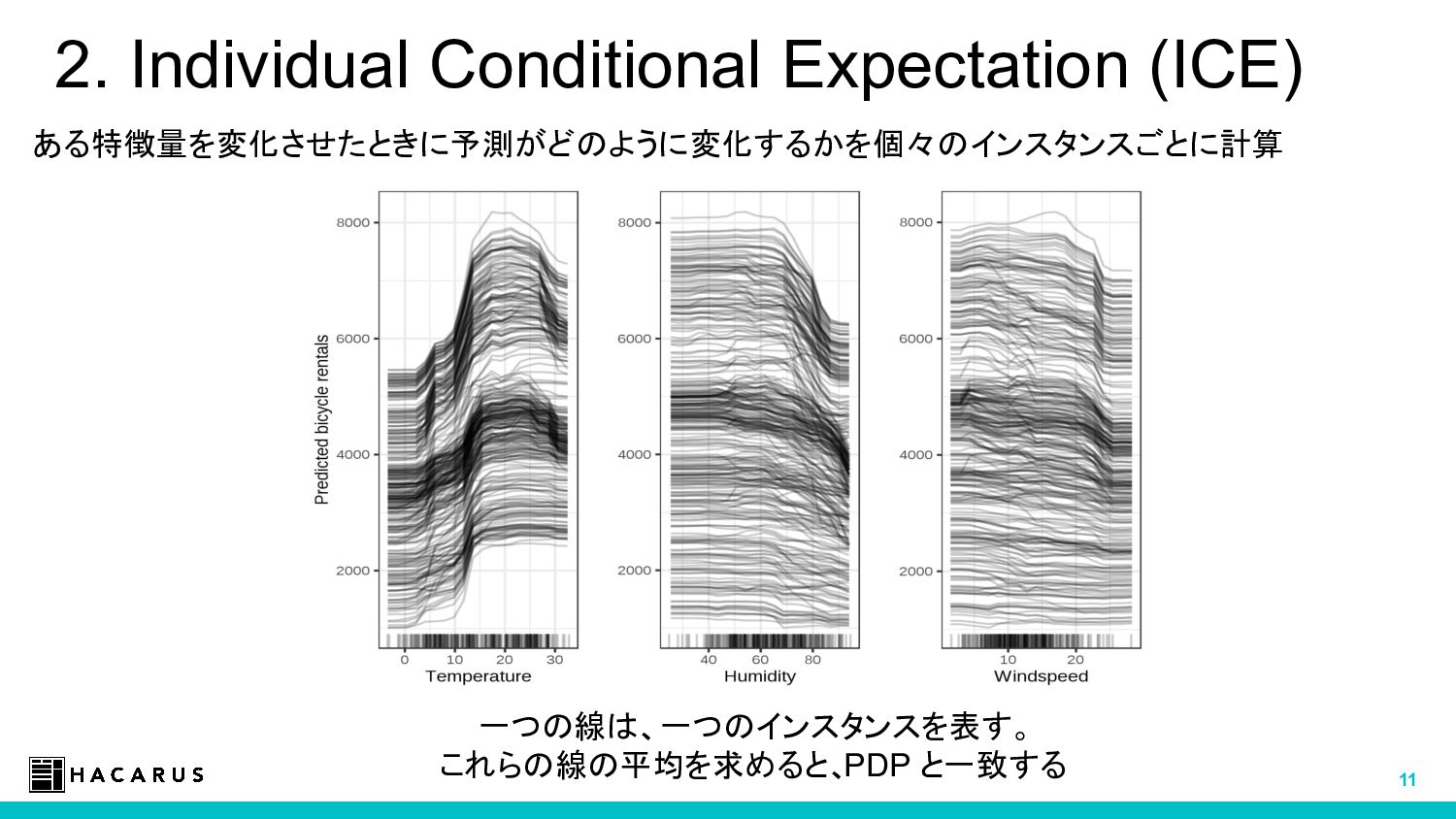
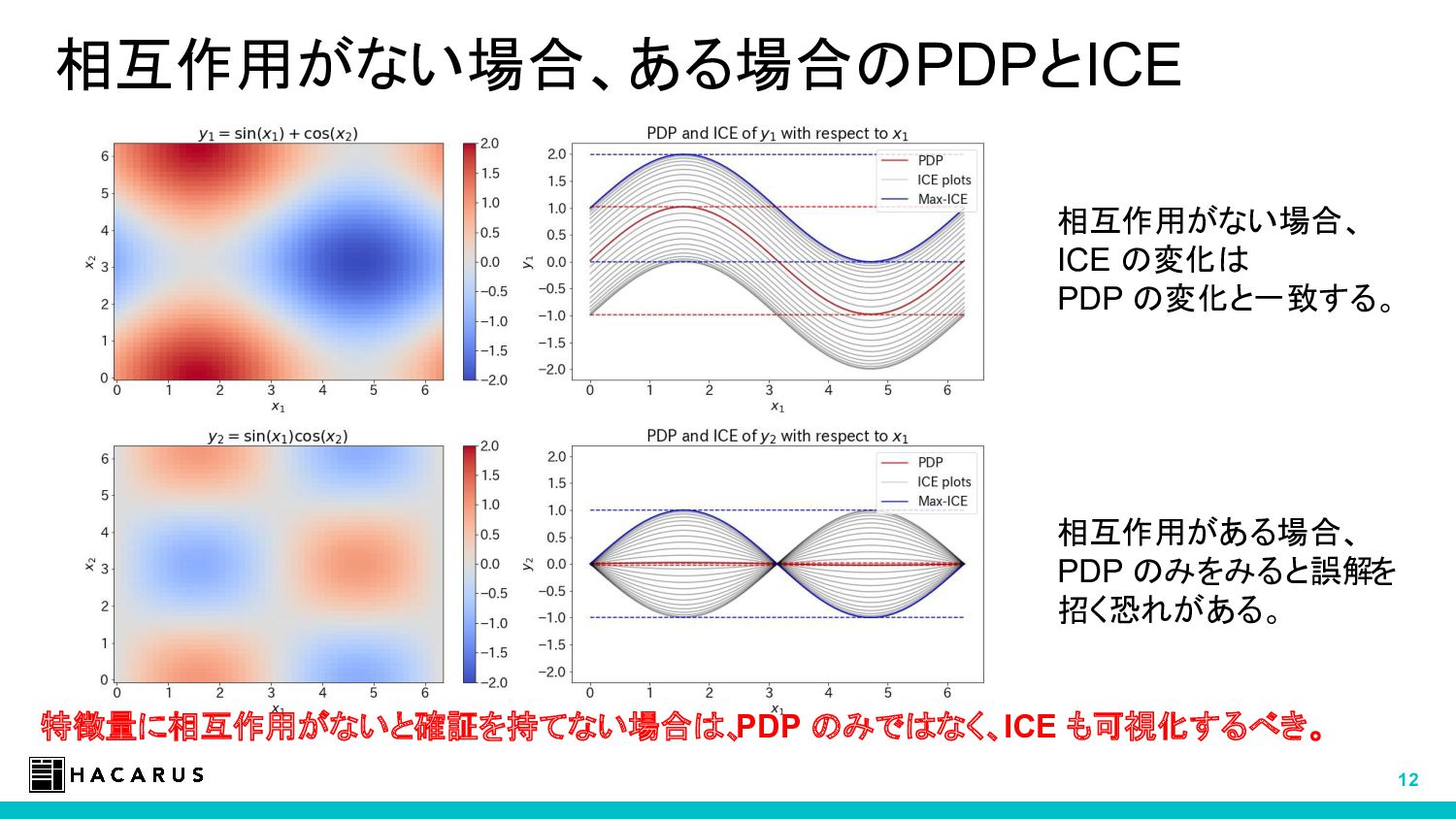
この中から、モデルに依存しない説明手法 (PDP, LIME, SHAP など) について紹介し、実際に使う上での勘所などを紹介します。
勉強会名の TECH は Technology Enhancement Community by HACARUS の略で、技術好きの方々がラフに集って学べる場をつくり、京都から面白いことを生み出していこうという試みで、HACARUS主導で開催しております。 HACARUS は人工知能を使ったデータ解析サービス・プロダクトを開発・提供する京都発のAIカンパニーです。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
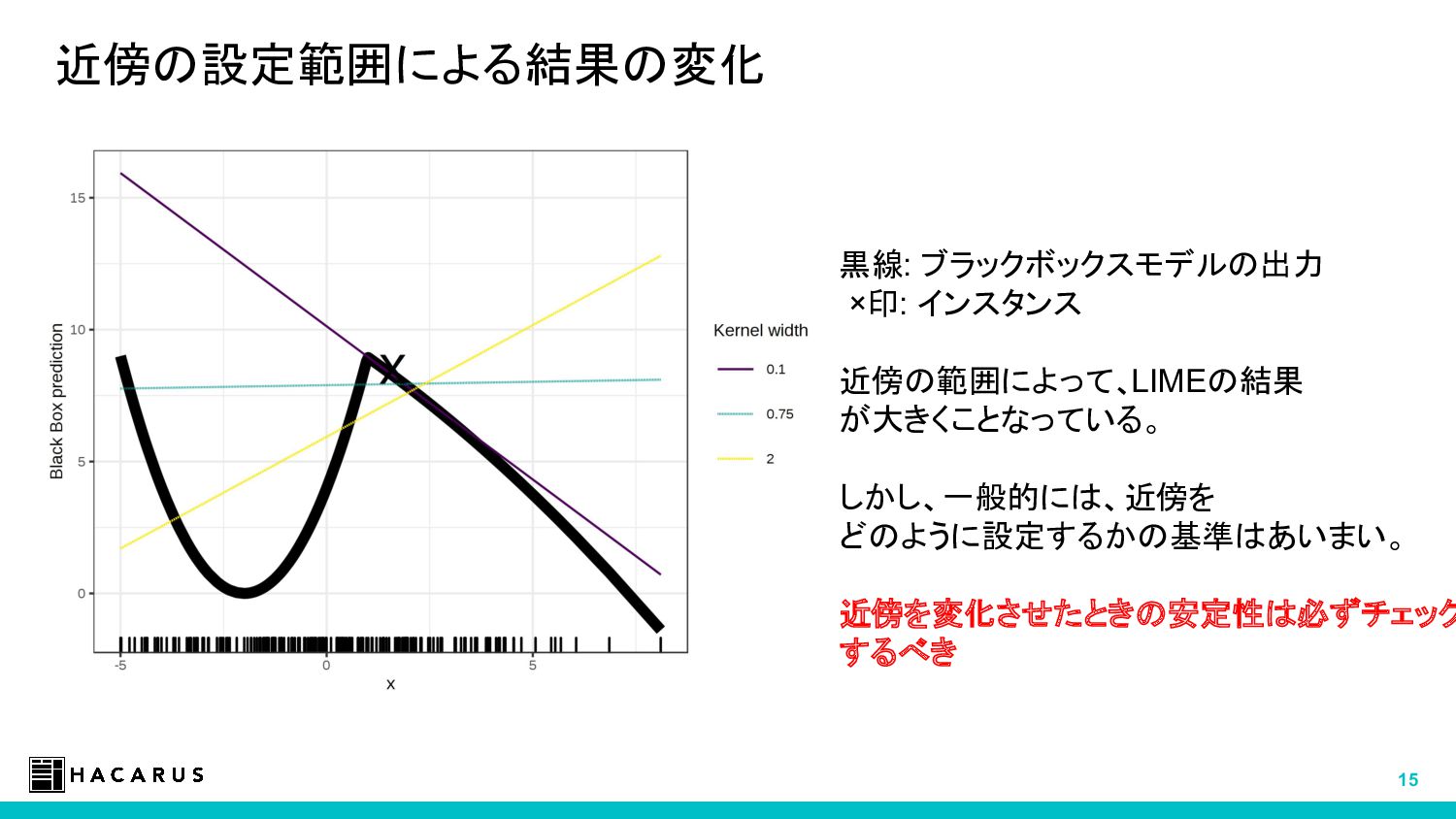{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
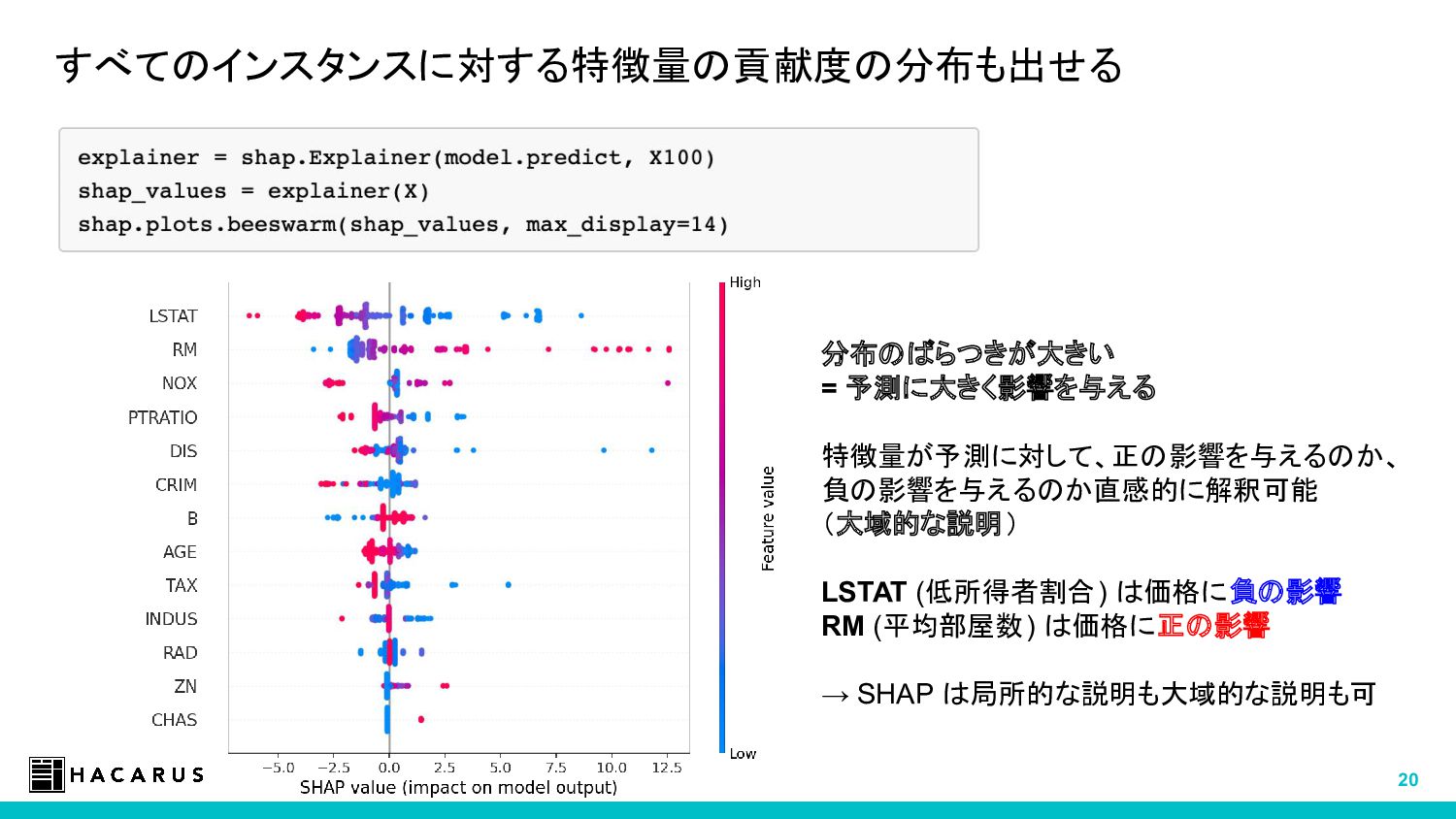{kind=link}
{kind=link}
{kind=link}
![23 [参考文献] Interpretable Machine Learning 原文 • https://christophm.github.io/interpretable-ml-book/ Interpretable Machine](https://files.speakerdeck.com/presentations/2c8a5cacffa1436c84e560b907d99cc9/slide_22.jpg){kind=link}