plates • User oriented • App development • Product delivery • Model accuracy • Visualization of data • Notebooks • Data-driven • Mathematical computations
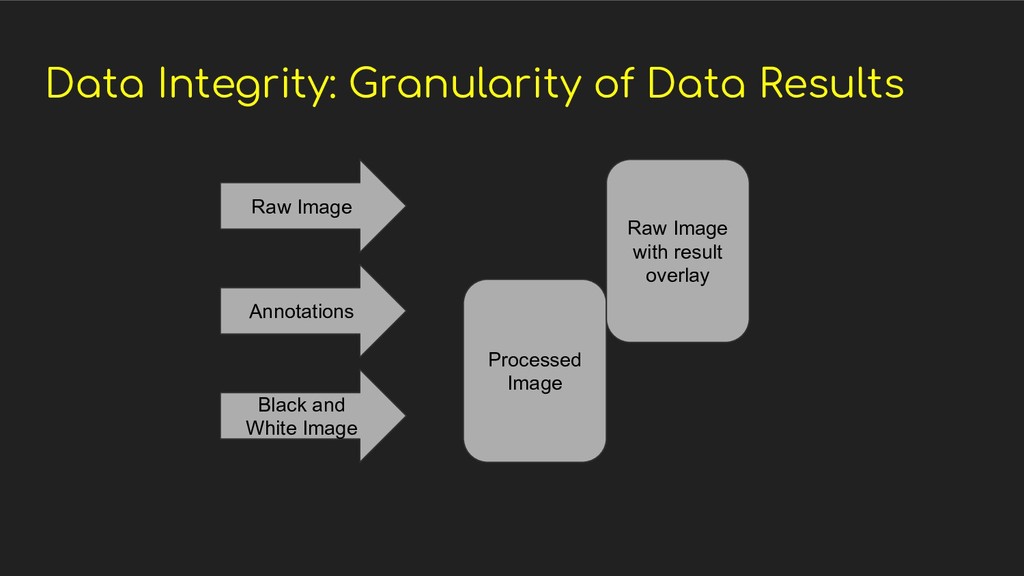
- Resource limitations - Code quality - Error handling - Data integrity for both input and results - Proper feedback loop for data scientists and developers
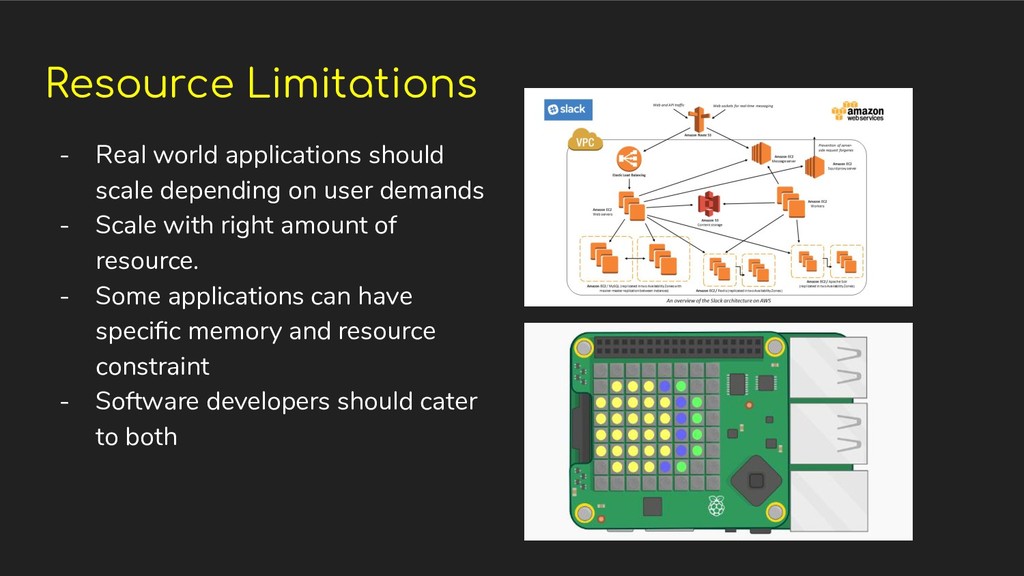
user demands - Scale with right amount of resource. - Some applications can have specific memory and resource constraint - Software developers should cater to both
expected inputs and outputs - Making sure the right results are displayed on the application side - Making sure the right data is passed to the machine learning side
- Agree on implementation key points such as - Release versions and deployment - Data pipelines - Validation, etc - Regular meetings with data science team is a must!
for training - Memory needed for model storage - Consider the kind of algorithm the model uses - Sparse modeling usually performs well in smaller resource setup
linters and automatic code formatting tools. - Agree on conventions on function definitions and interfaces. - Code reviews - Use Type Hints and other tools that IDEs utilize
"""Version mismatch for algorithm""" class NotFittedException(Exception): """Model is not fitted""" class DataSizeException(Exception): """Invalid data size for training""" class NoTrainDataException(Exception): """No training data""" - Errors are clear and descriptive - Case to case basis
Challenge - Software engineers doing ML exercises with data scientists and vice versa. - Solves online challenges, etc. - Makes it easier to align with ML team.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}