Satinder P. Singh. “Eligibility Traces for Off-Policy Policy Evaluation.” ICML, 2000. https://scholarworks.umass.edu/cgi/viewcontent.cgi?article=1079&context=cs_faculty_pubs [Strehl+, 10] Alex Strehl, John Langford, Sham Kakade, and Lihong Li. “Learning from Logged Implicit Exploration Data.” NeurIPS, 2010. https://arxiv.org/abs/1003.0120 [Li+, 18] Shuai Li, Yasin Abbasi-Yadkori, Branislav Kveton, S. Muthukrishnan, Vishwa Vinay, and Zheng Wen. “Offline Evaluation of Ranking Policies with Click Models.” KDD, 2018. https://arxiv.org/abs/1804.10488 [McInerney+, 20] James McInerney, Brian Brost, Praveen Chandar, Rishabh Mehrotra, and Ben Carterette. “Counterfactual Evaluation of Slate Recommendations with Sequential Reward Interactions.” KDD, 2020. https://arxiv.org/abs/2007.12986 [Dudík+, 14] Miroslav Dudík, Dumitru Erhan, John Langford, and Lihong Li. “Doubly Robust Policy Evaluation and Optimization.” ICML, 2011. https://arxiv.org/abs/1503.02834 [Jiang&Li, 16] Nan Jiang and Lihong Li. “Doubly Robust Off-policy Value Evaluation for Reinforcement Learning.” ICML, 2016. https://arxiv.org/abs/1511.03722 February 2022 Cascade Doubly Robust Off-Policy Evaluation @ WSDM2022 87
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
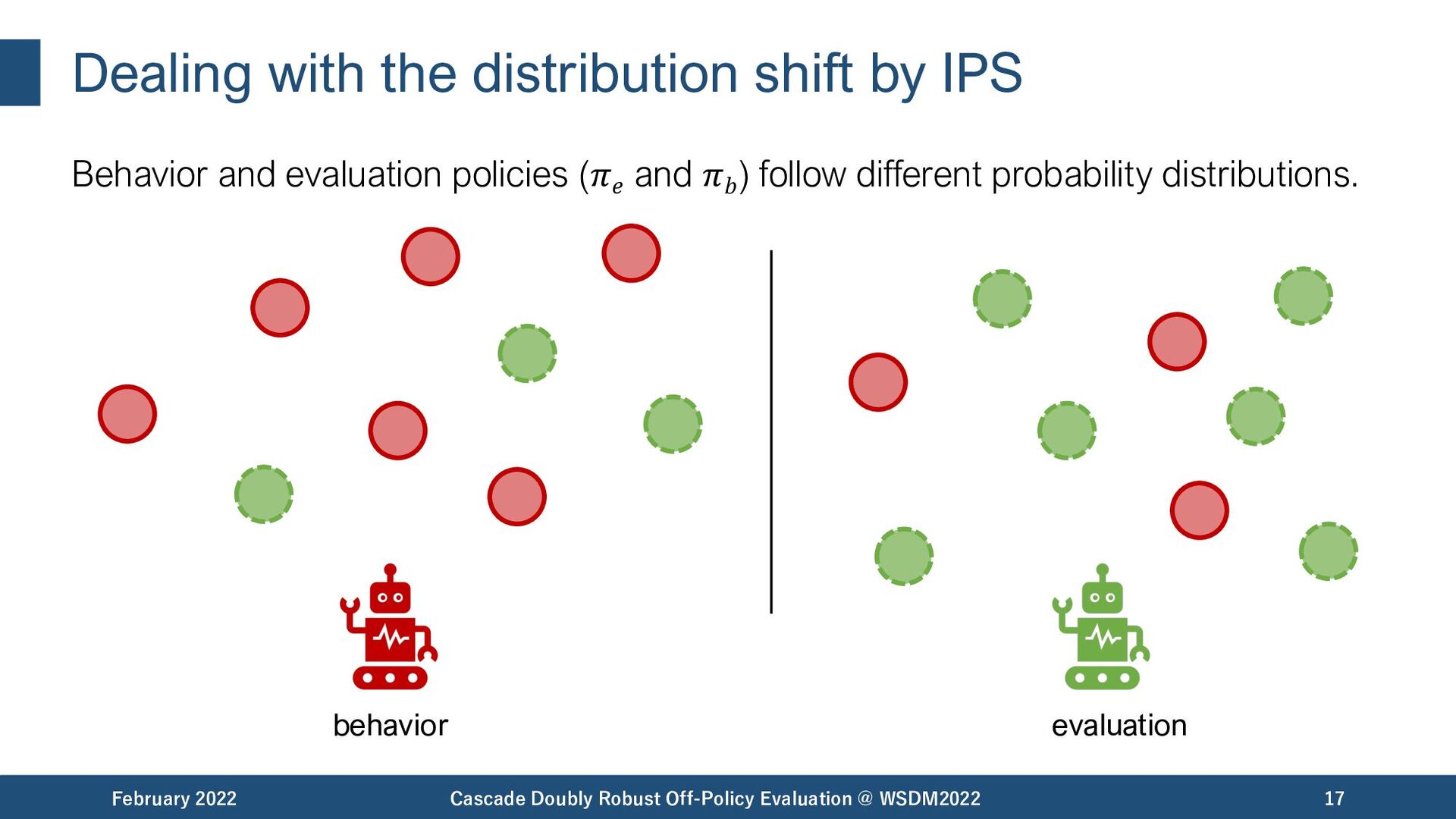
![Inverse Propensity Scoring (IPS) [Precup+, 00] [Strehl+, 10] IPS corrects](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
![Inverse Propensity Scoring (IPS) [Precup+, 00] [Strehl+, 10] IPS corrects](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_18.jpg){kind=link}
![Inverse Propensity Scoring (IPS) [Precup+, 00] [Strehl+, 10] IPS corrects](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Reward interaction IPS (RIPS) [McInerney+, 20] RIPS assumes that users](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_27.jpg){kind=link}
![Reward interaction IPS (RIPS) [McInerney+, 20] RIPS assumes that users](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_28.jpg){kind=link}
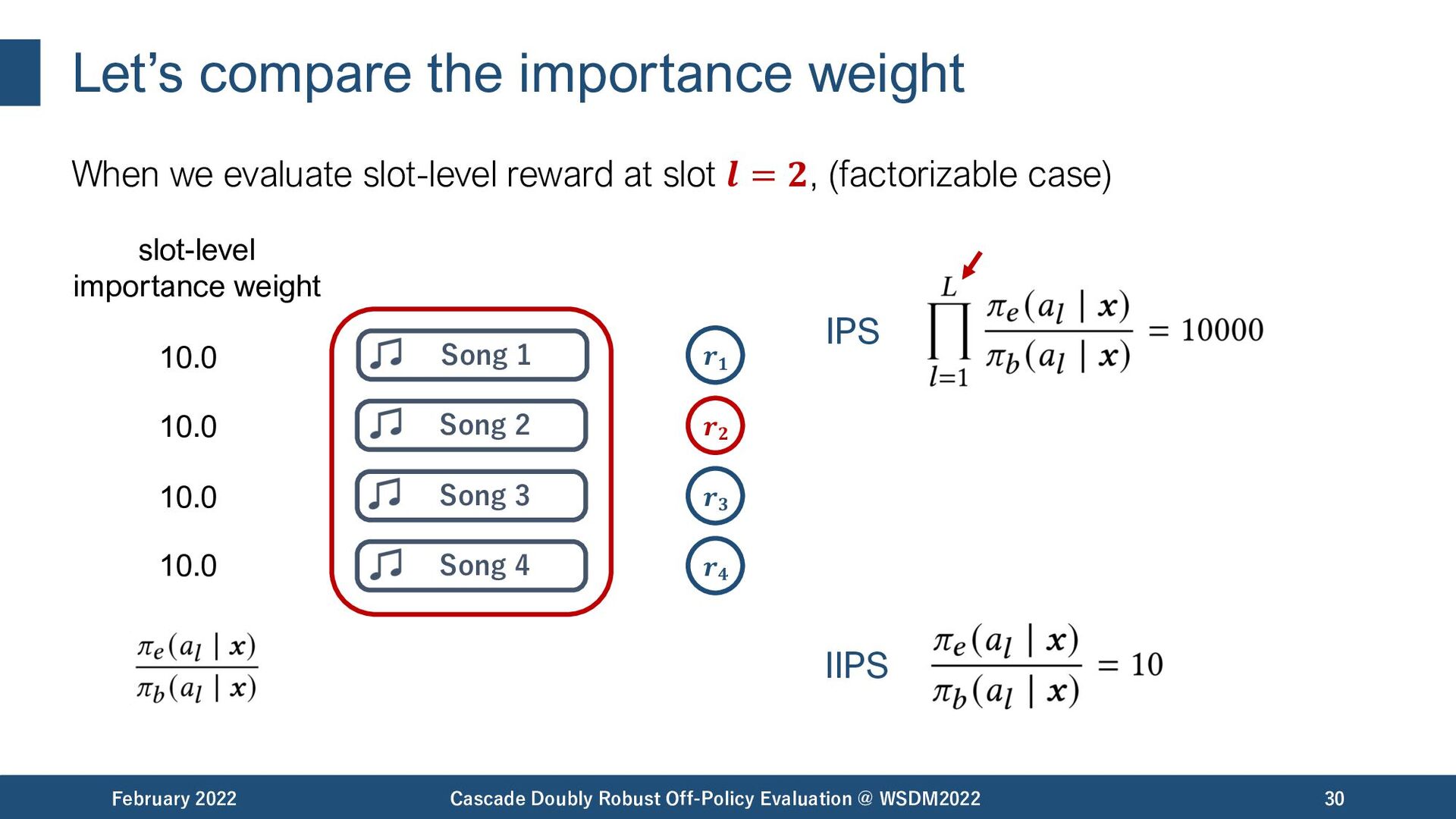{kind=link}
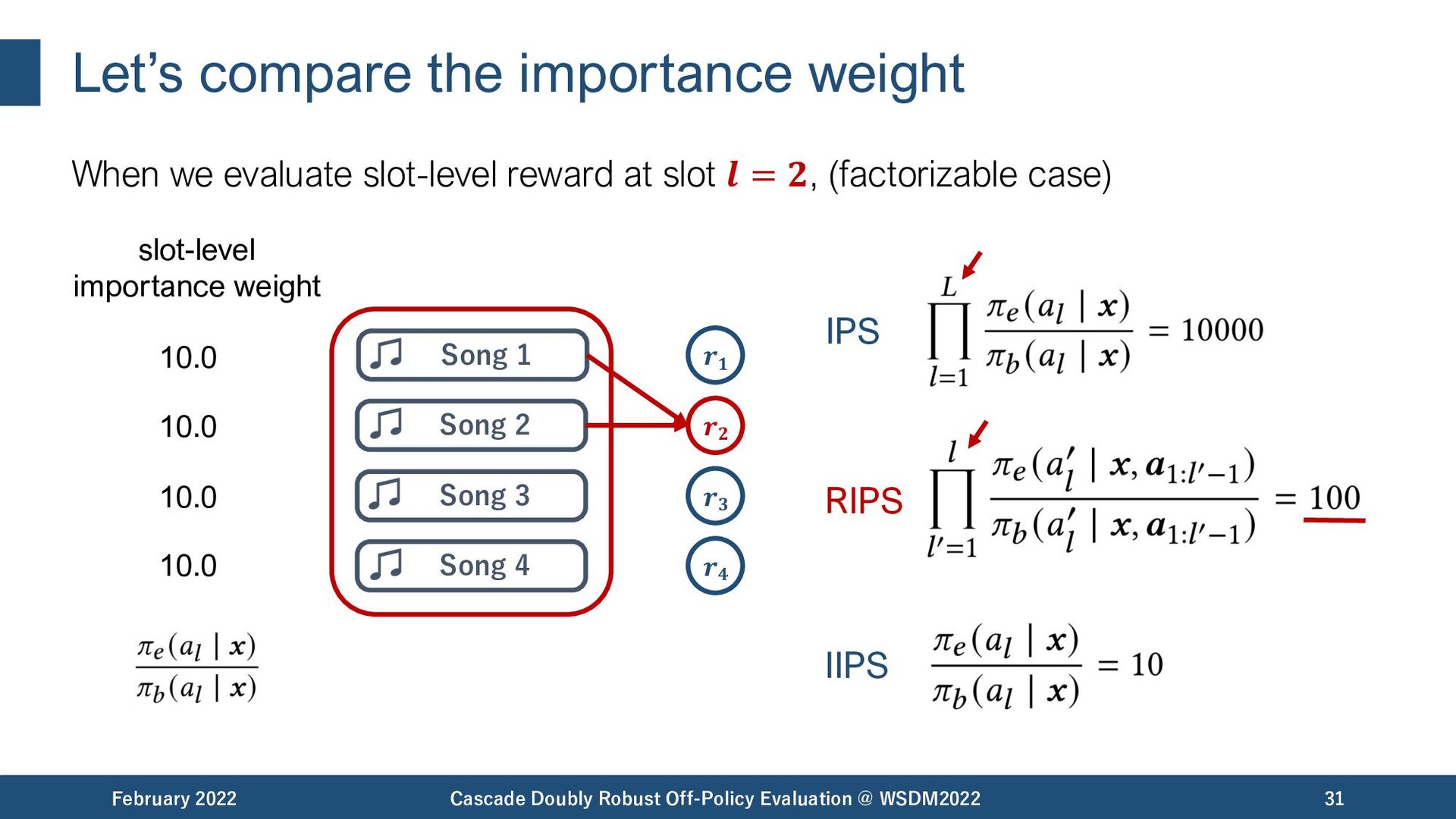{kind=link}
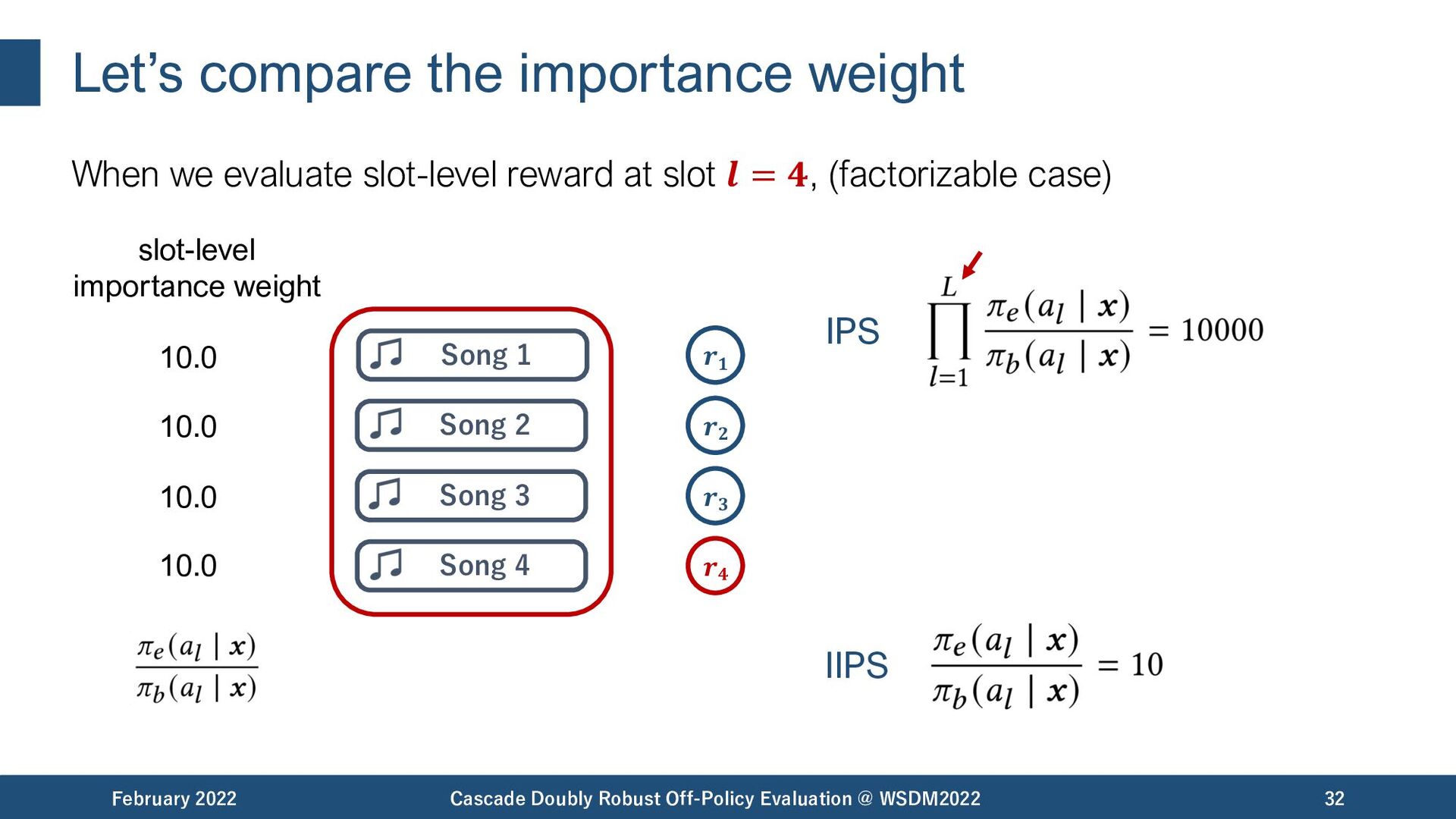{kind=link}
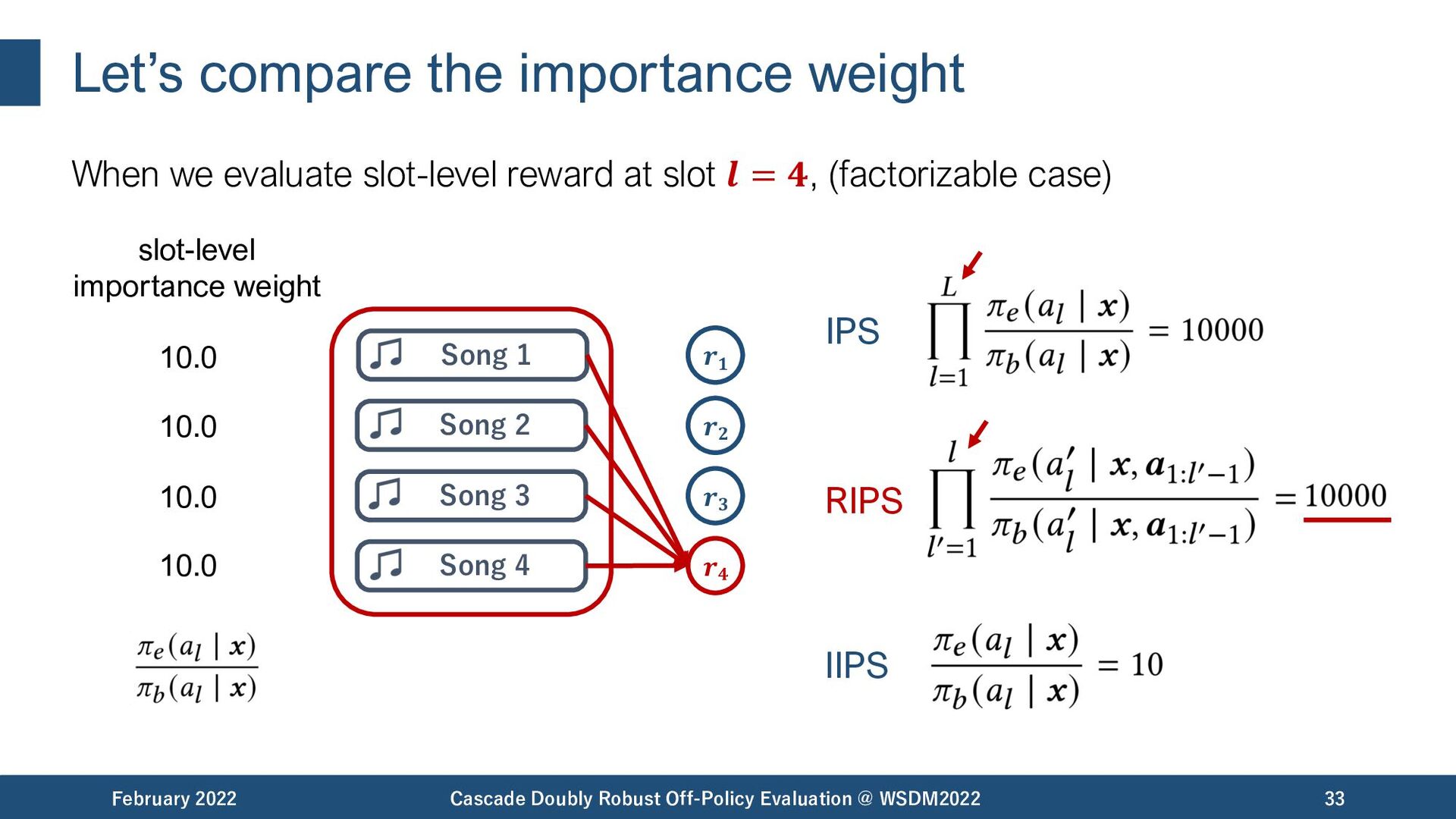{kind=link}
![Reward interaction IPS (RIPS) [McInerney+, 20] RIPS assumes that users](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_33.jpg){kind=link}
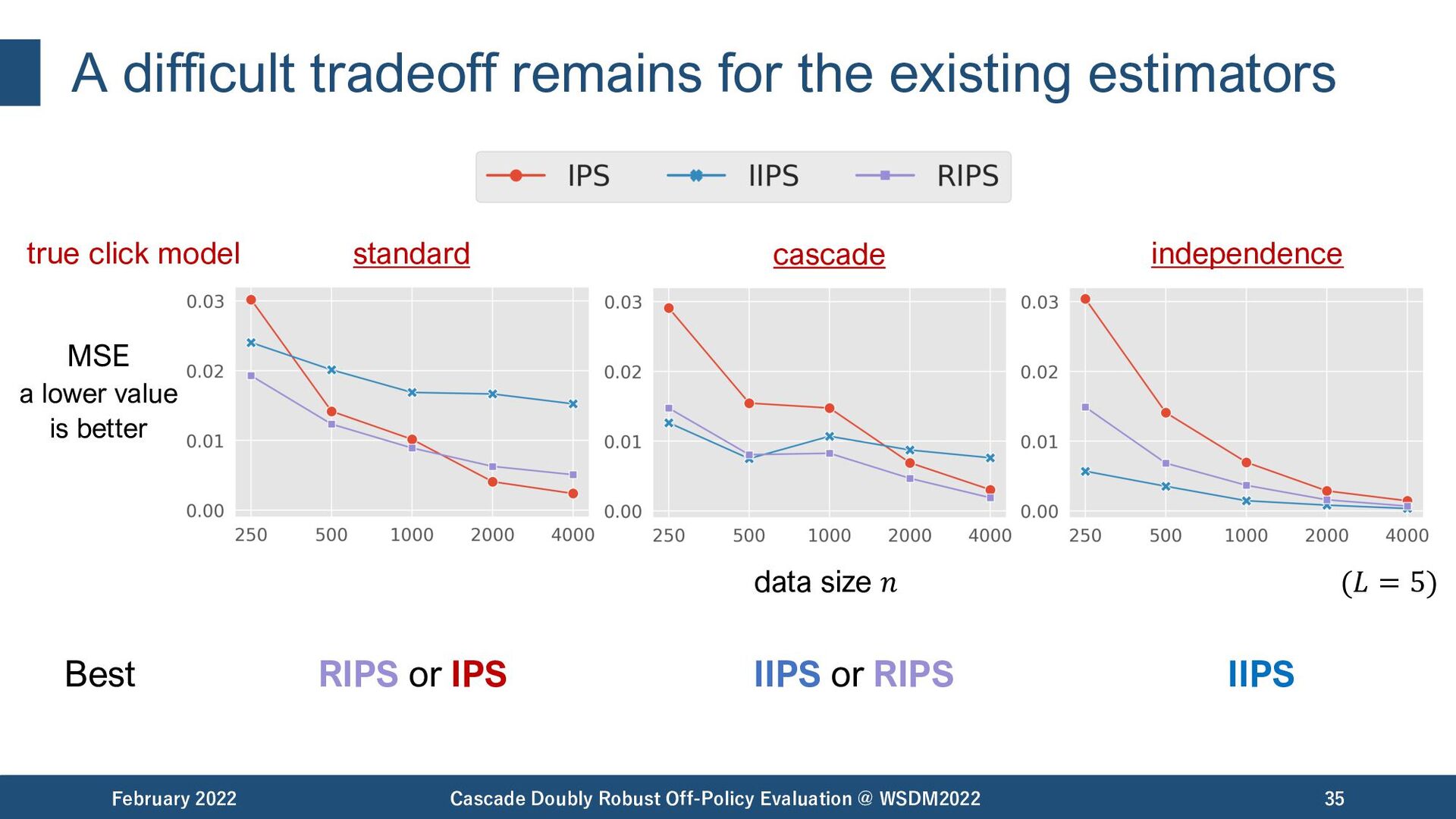{kind=link}
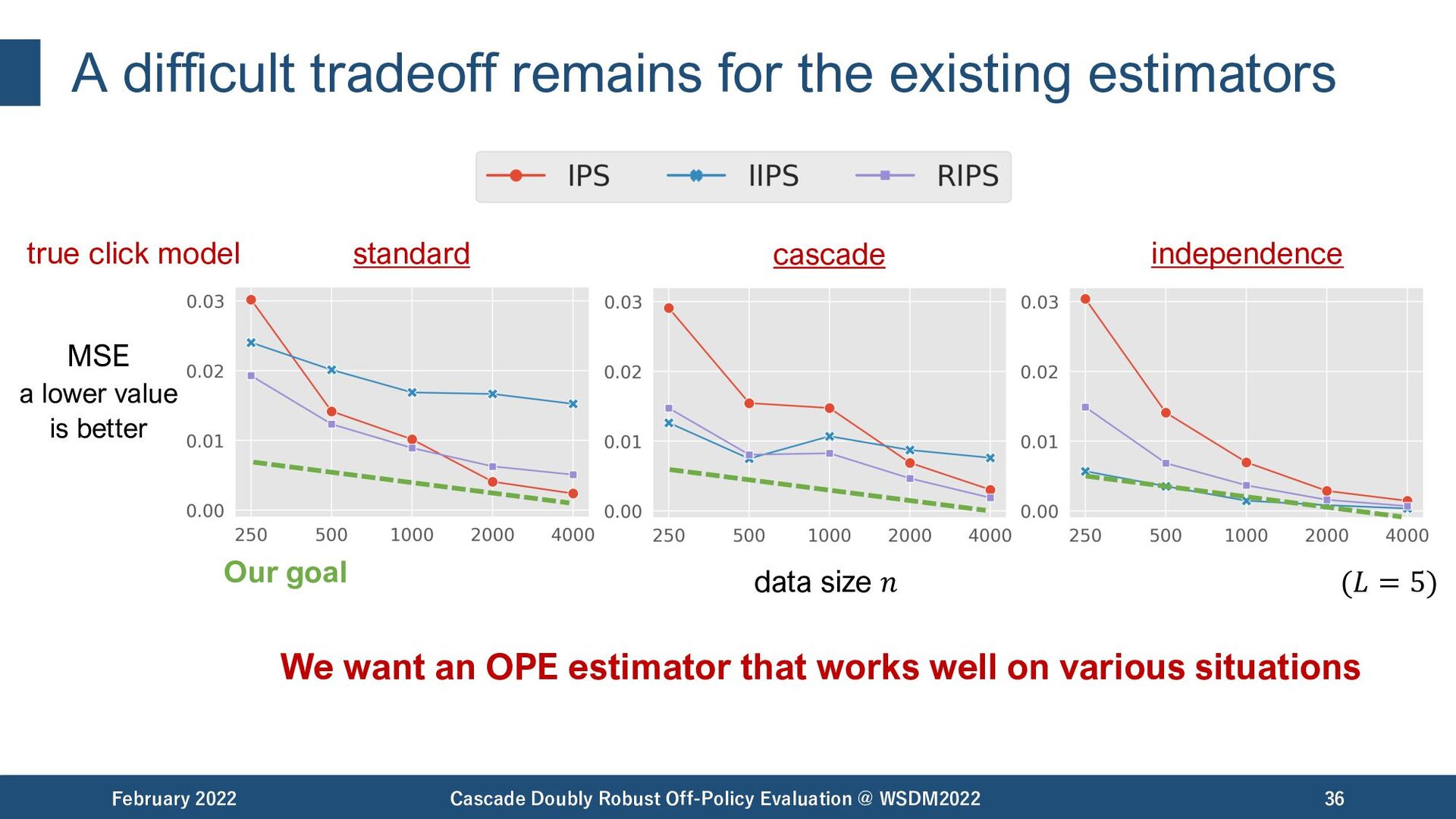{kind=link}
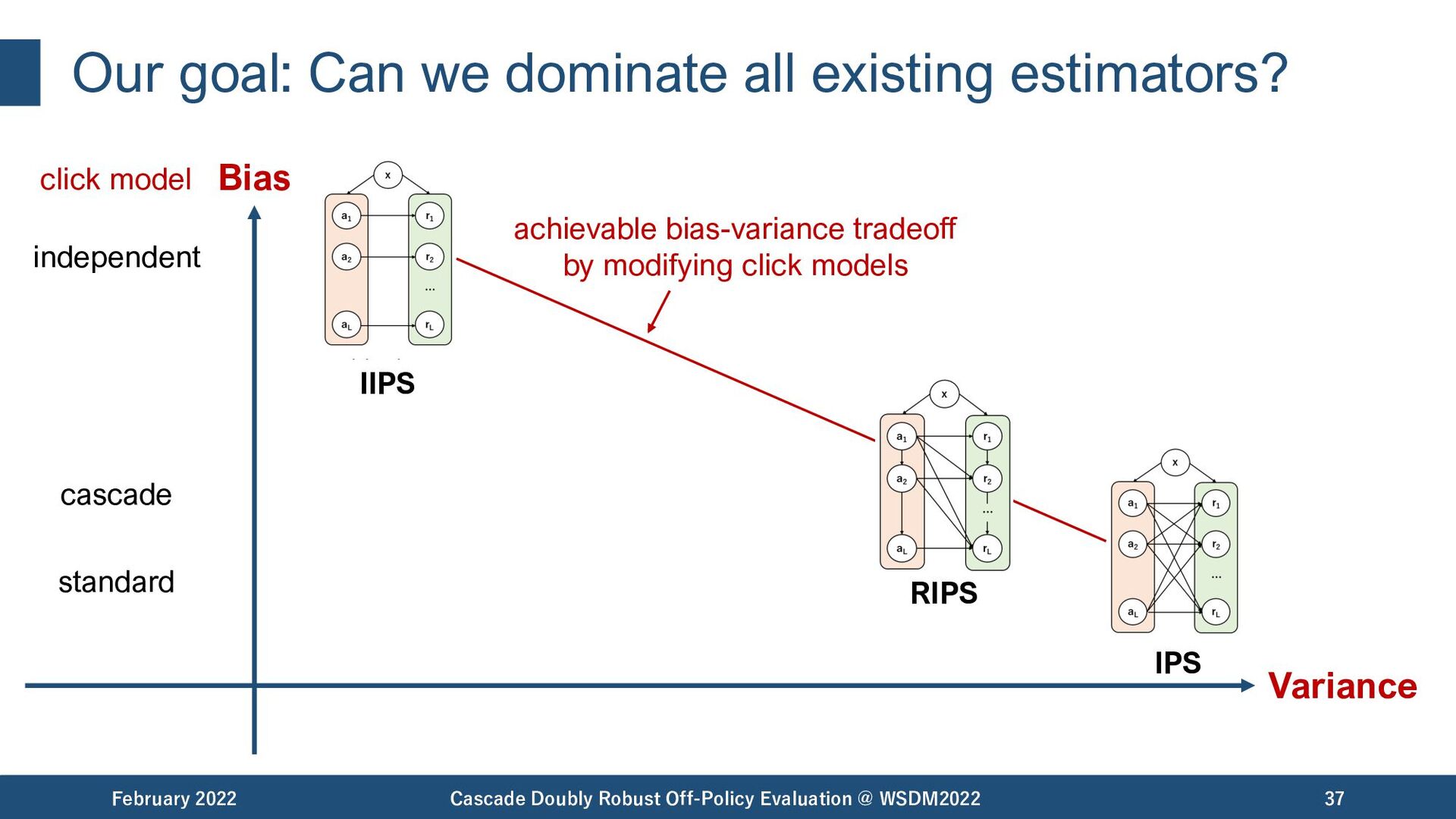{kind=link}
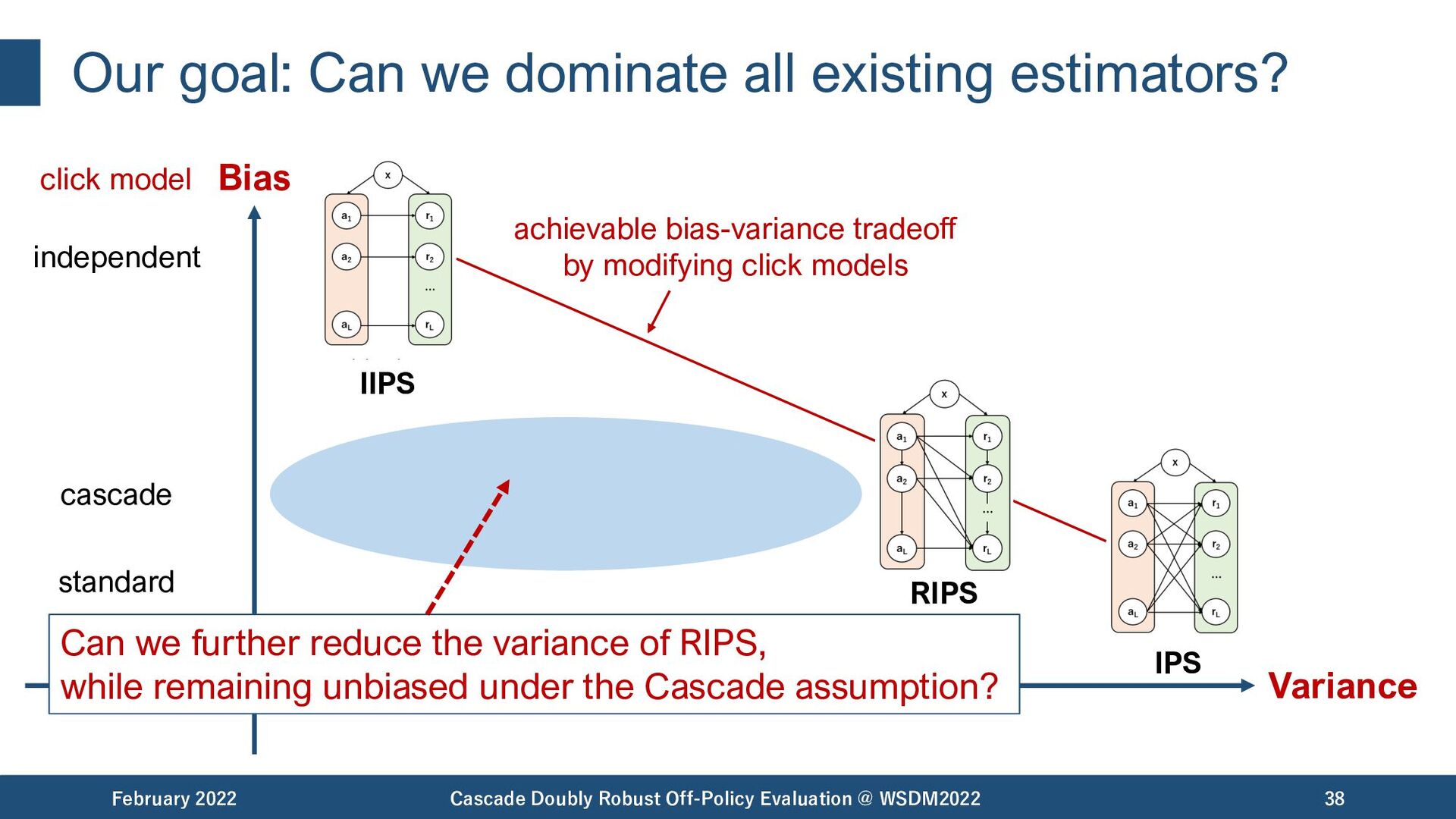{kind=link}
{kind=link}
![From IPS to Doubly Robust (DR) [Dudík+, 14] In a](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_39.jpg){kind=link}
![From IPS to Doubly Robust (DR) [Dudík+, 14] In a](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
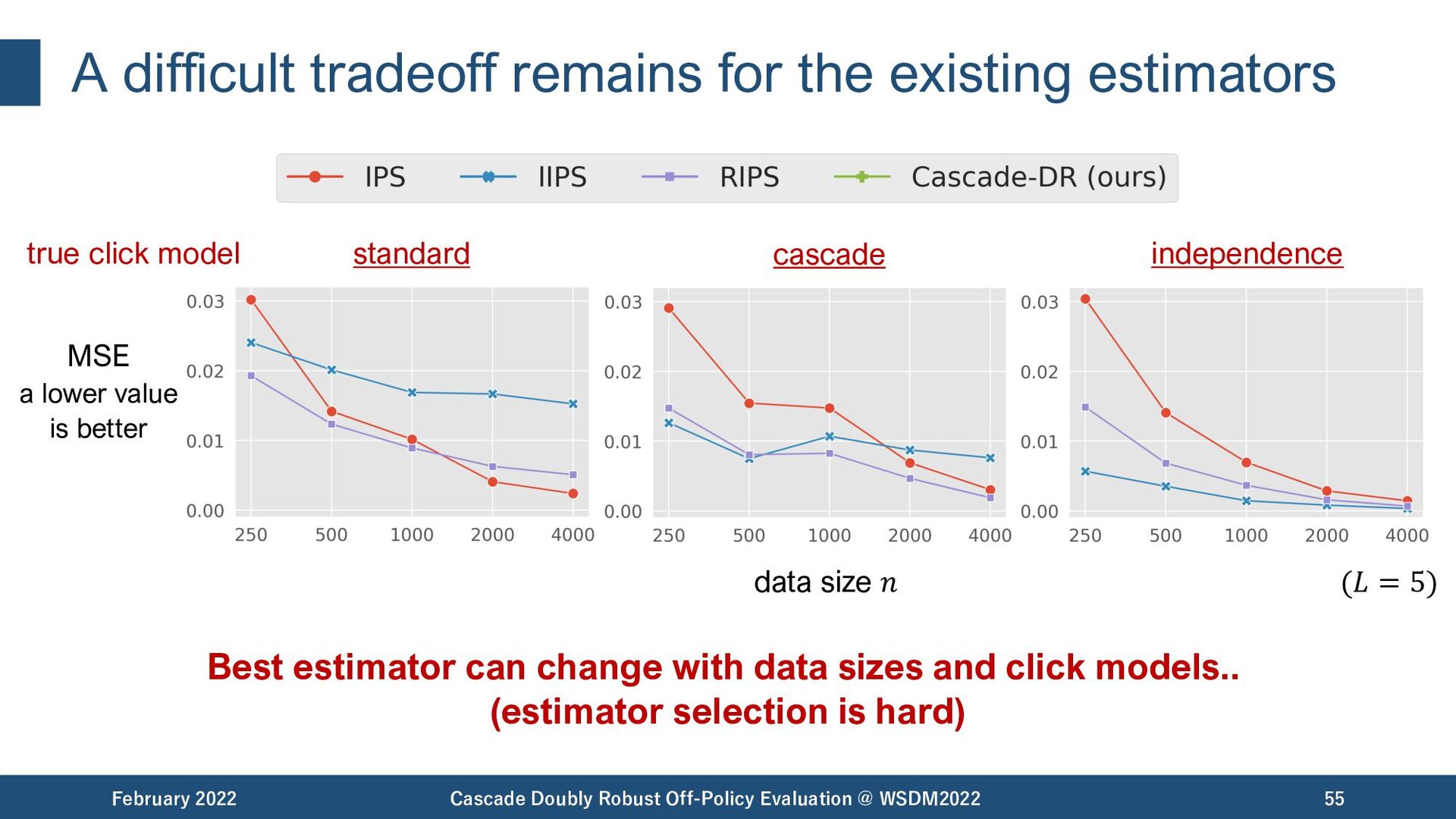{kind=link}
{kind=link}
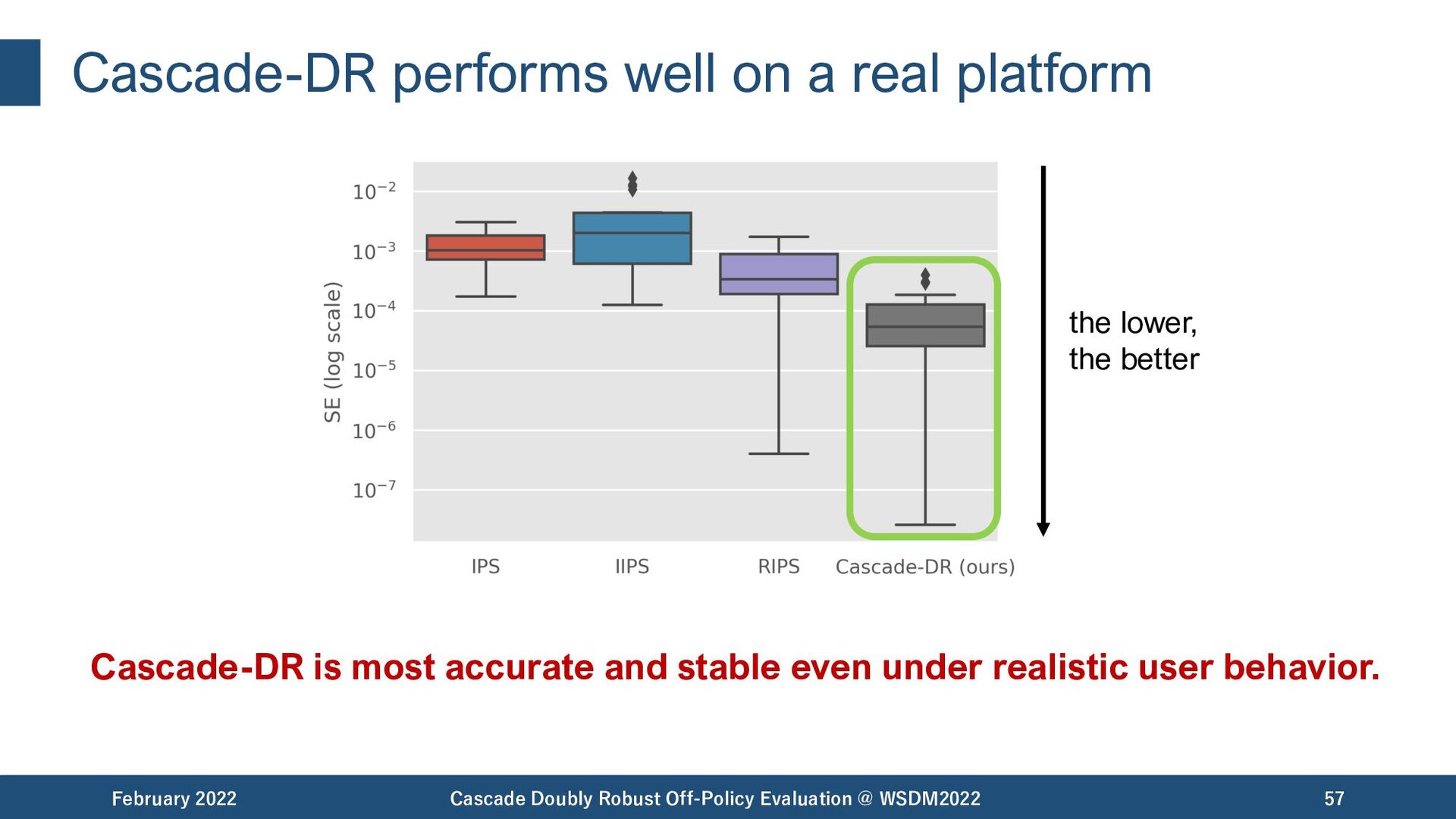{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
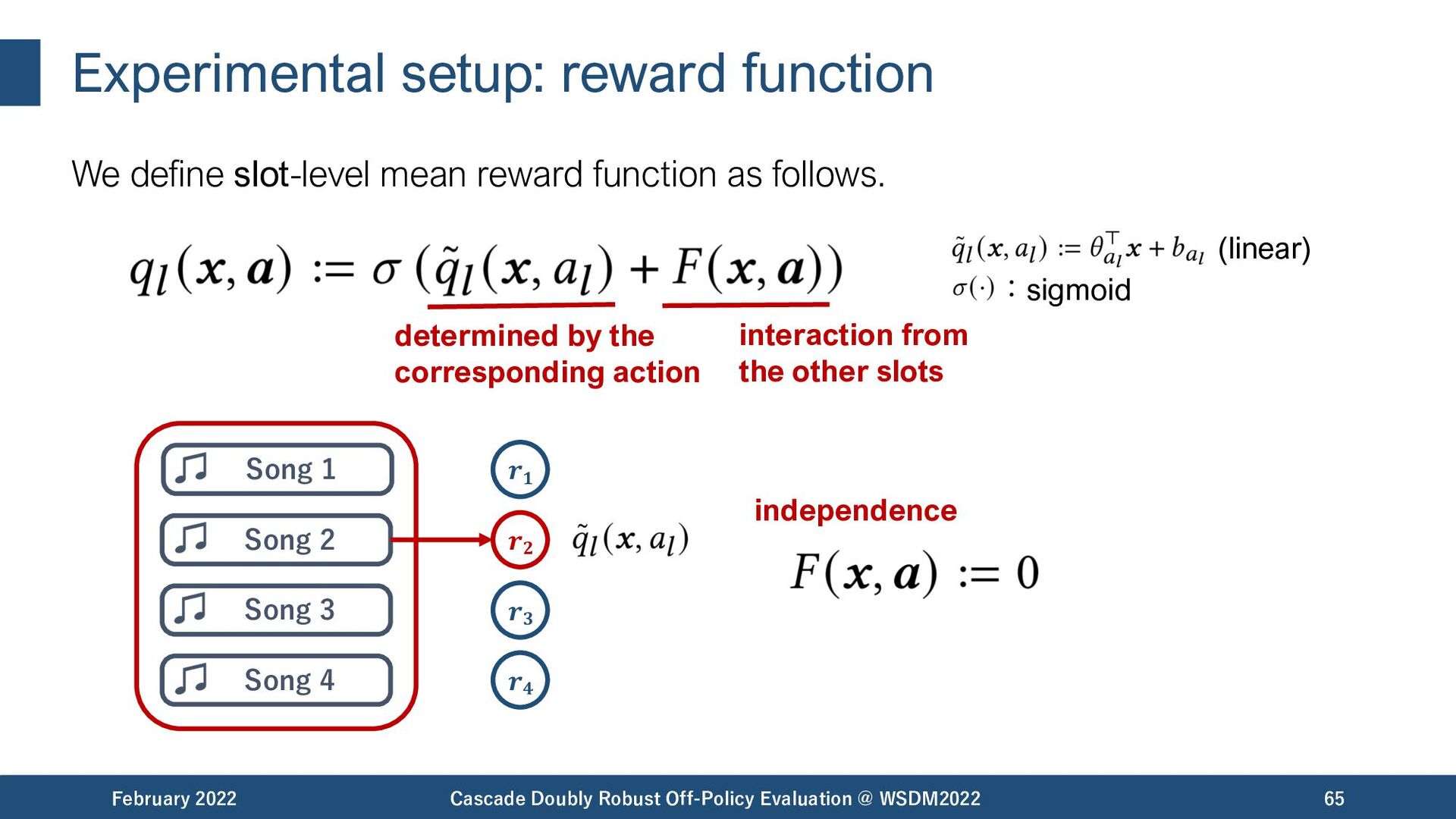{kind=link}
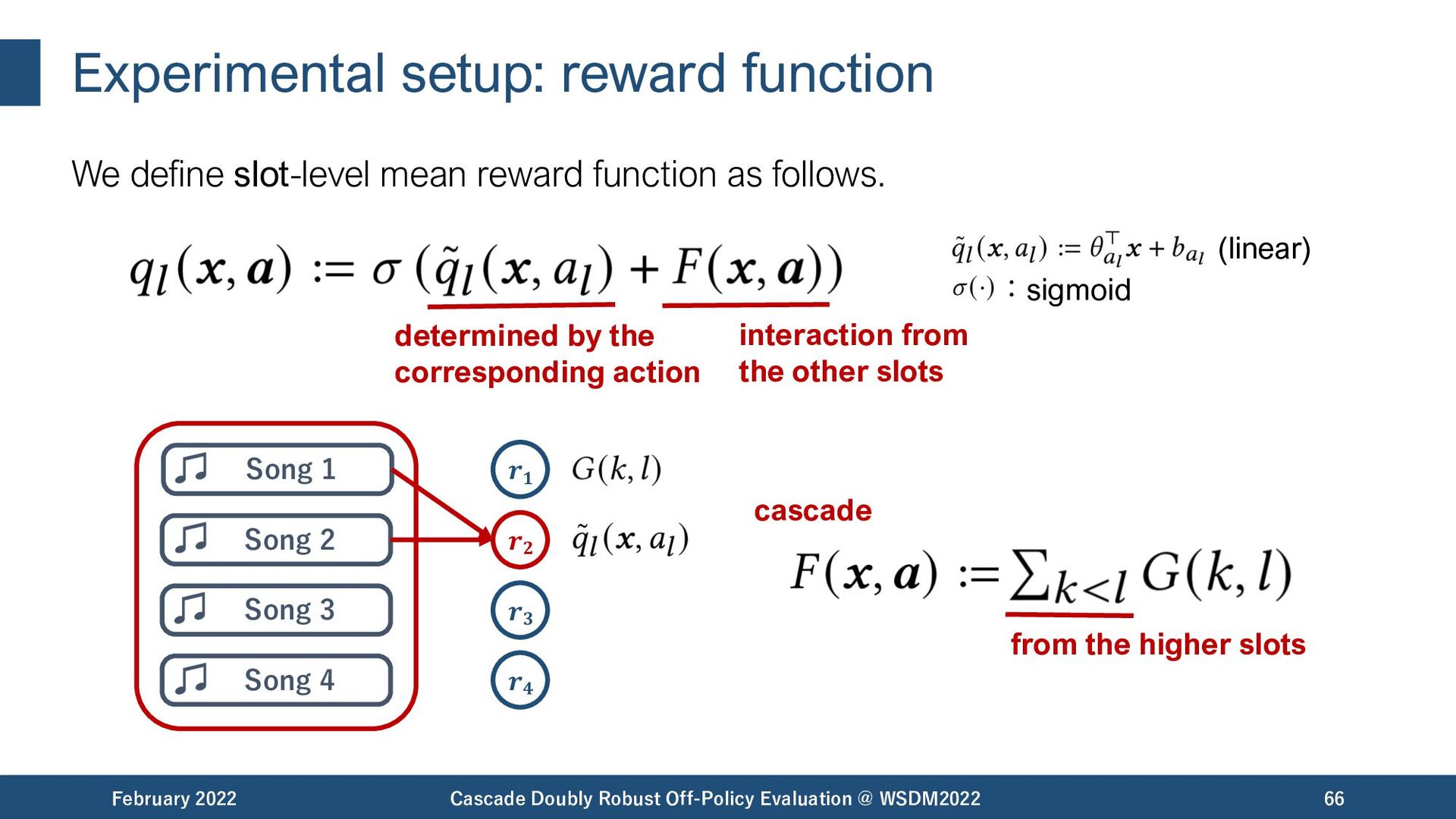{kind=link}
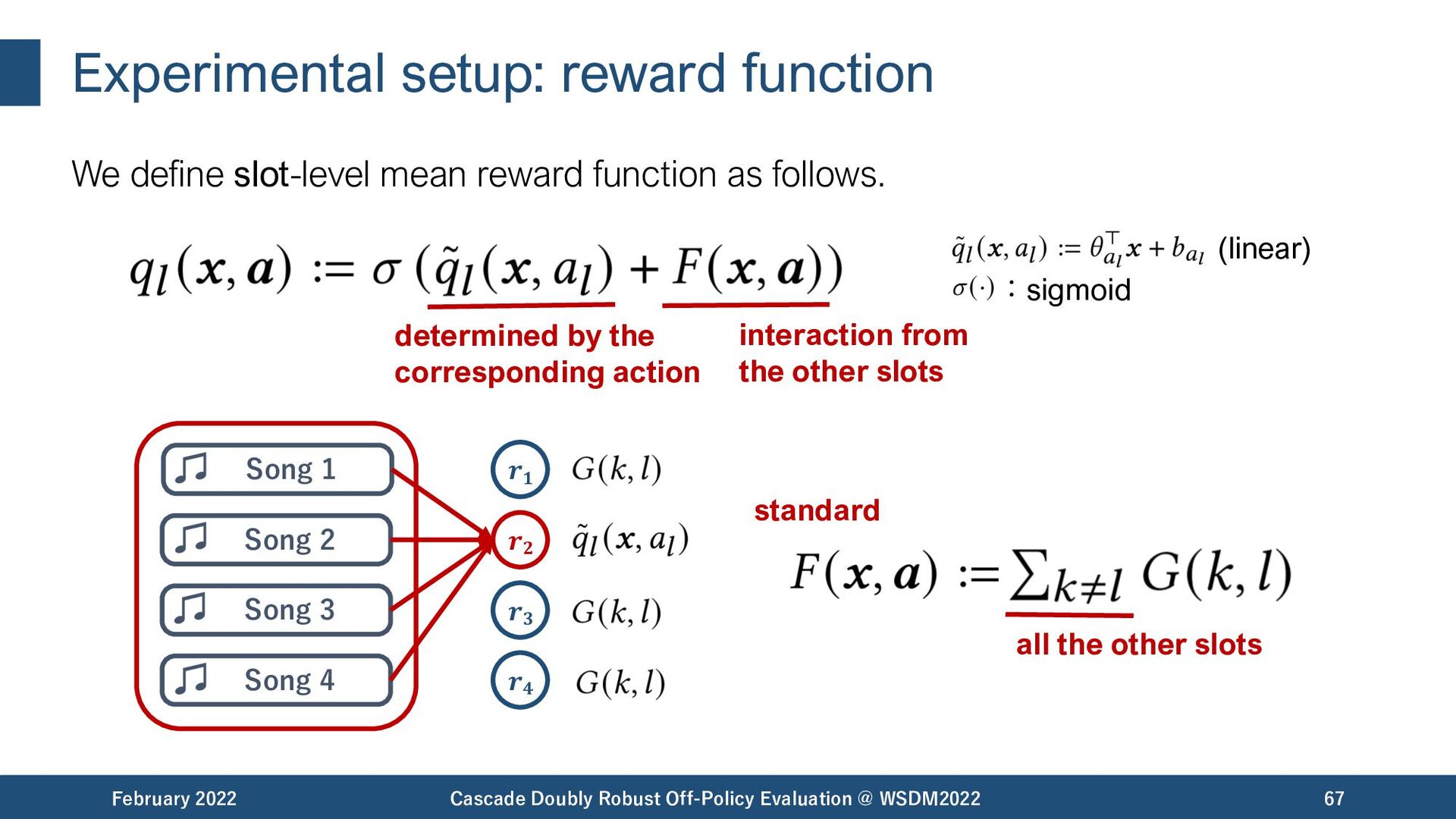{kind=link}
{kind=link}
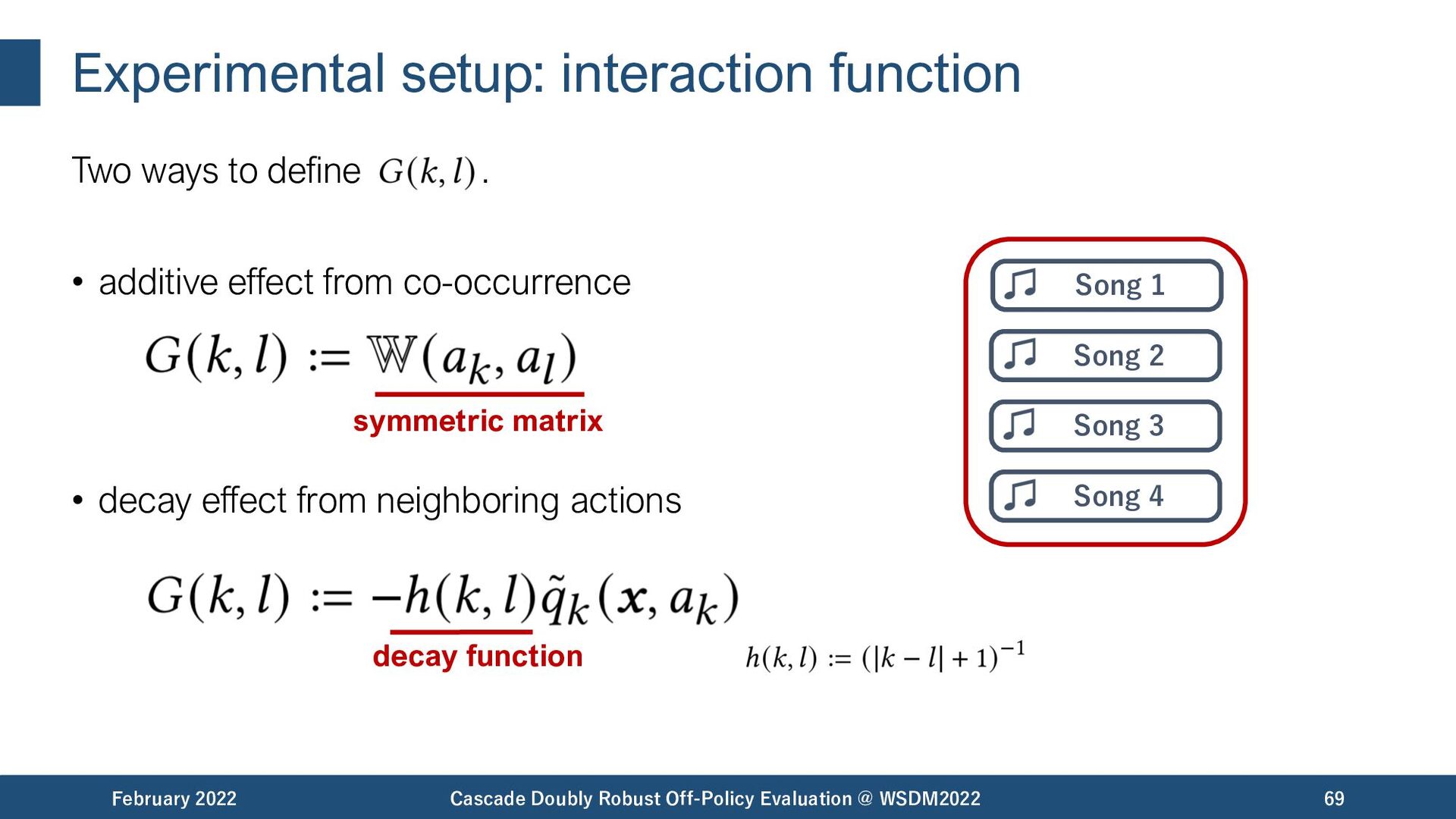{kind=link}
{kind=link}
{kind=link}
![Experimental procedure [Saito+, 21b] • We first randomly sample configurations](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_71.jpg){kind=link}
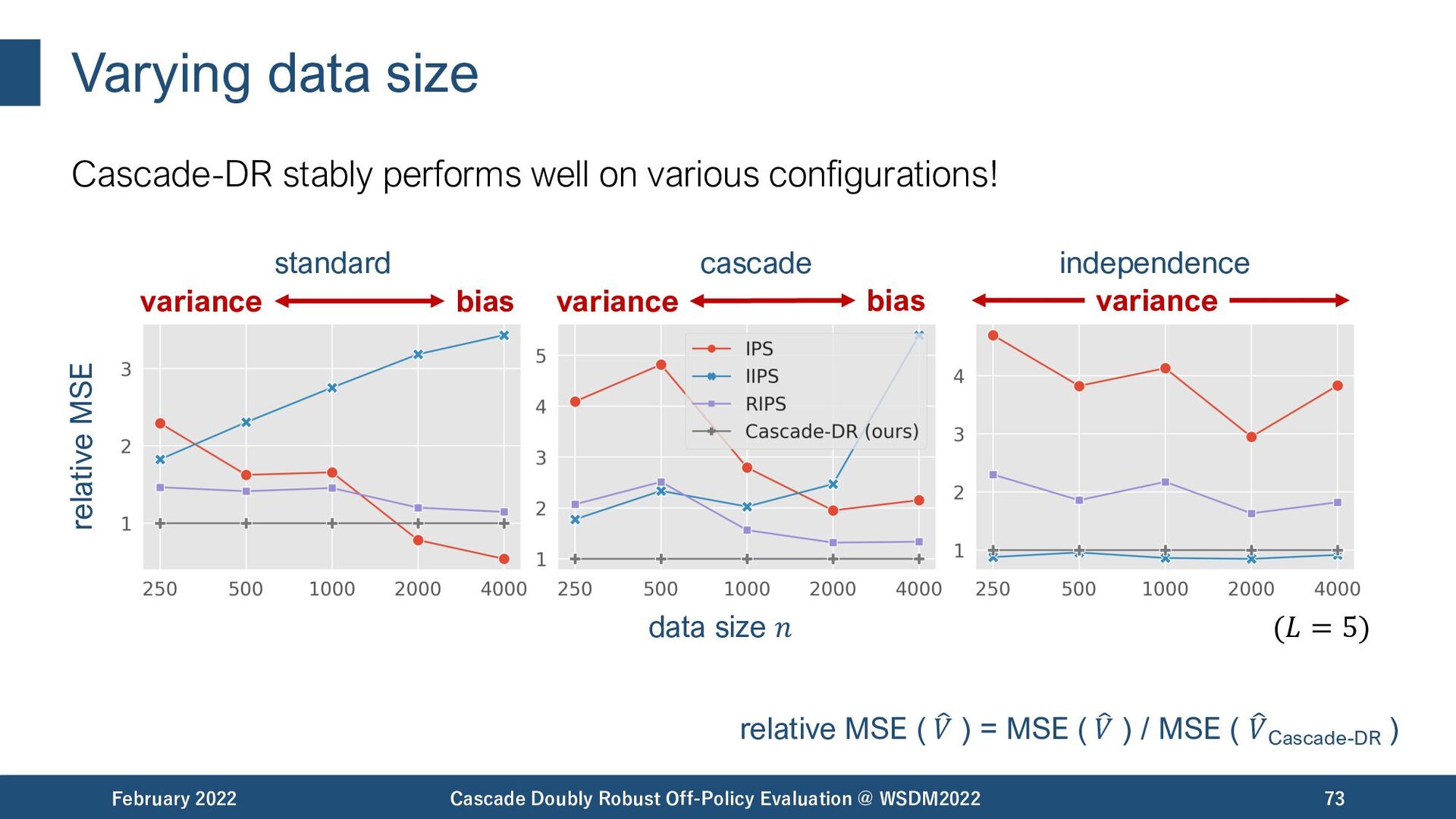{kind=link}
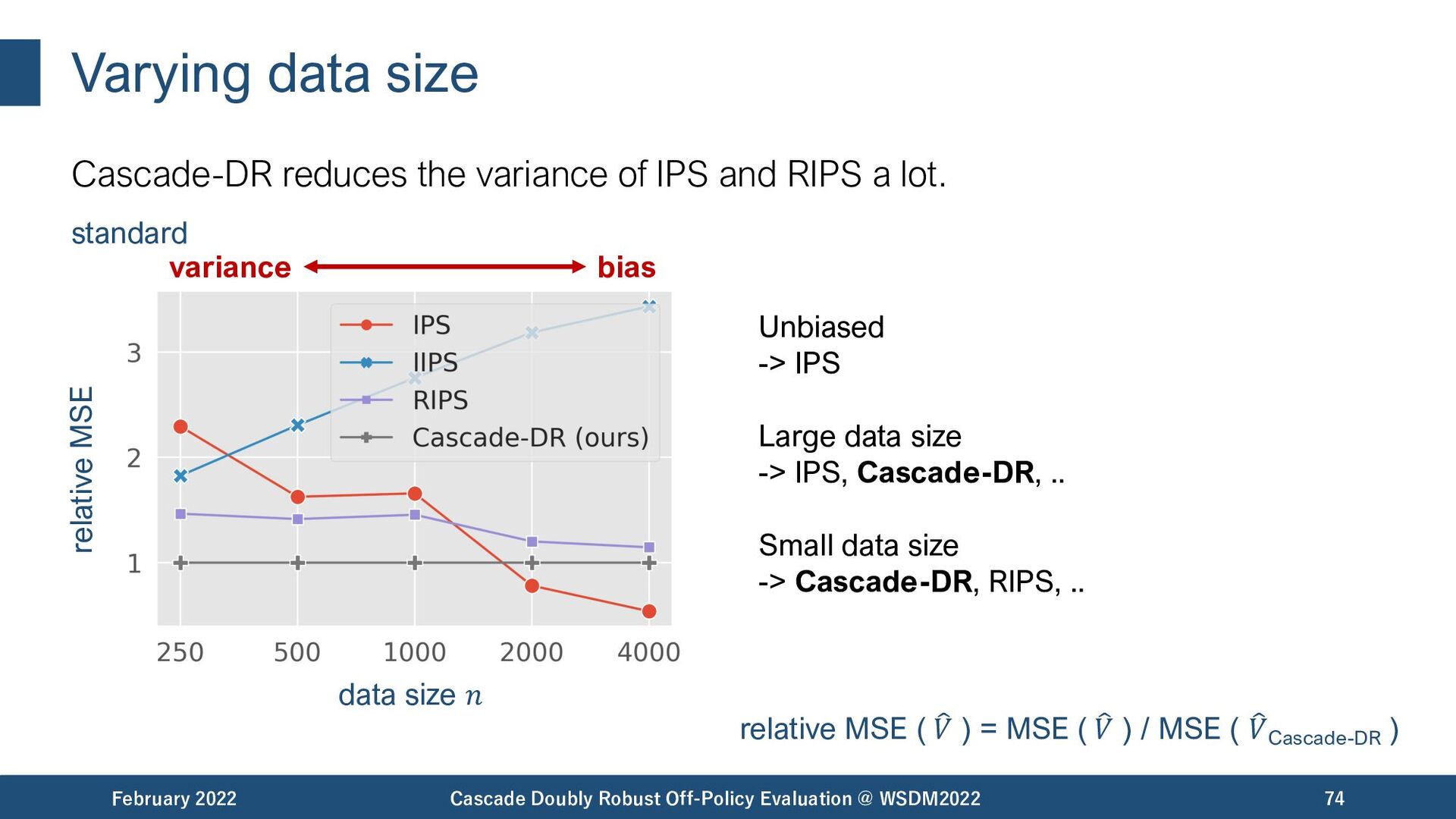{kind=link}
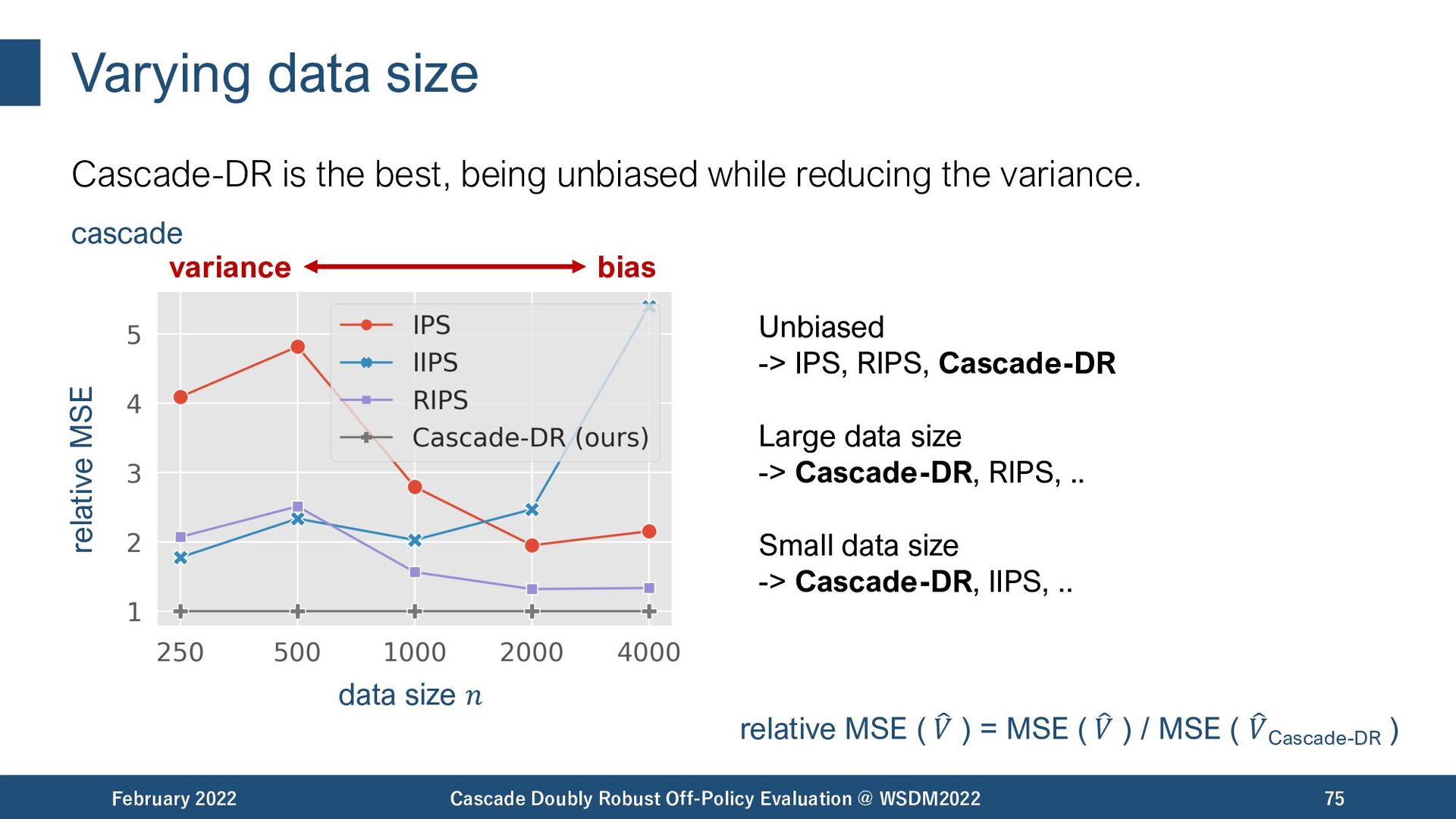{kind=link}
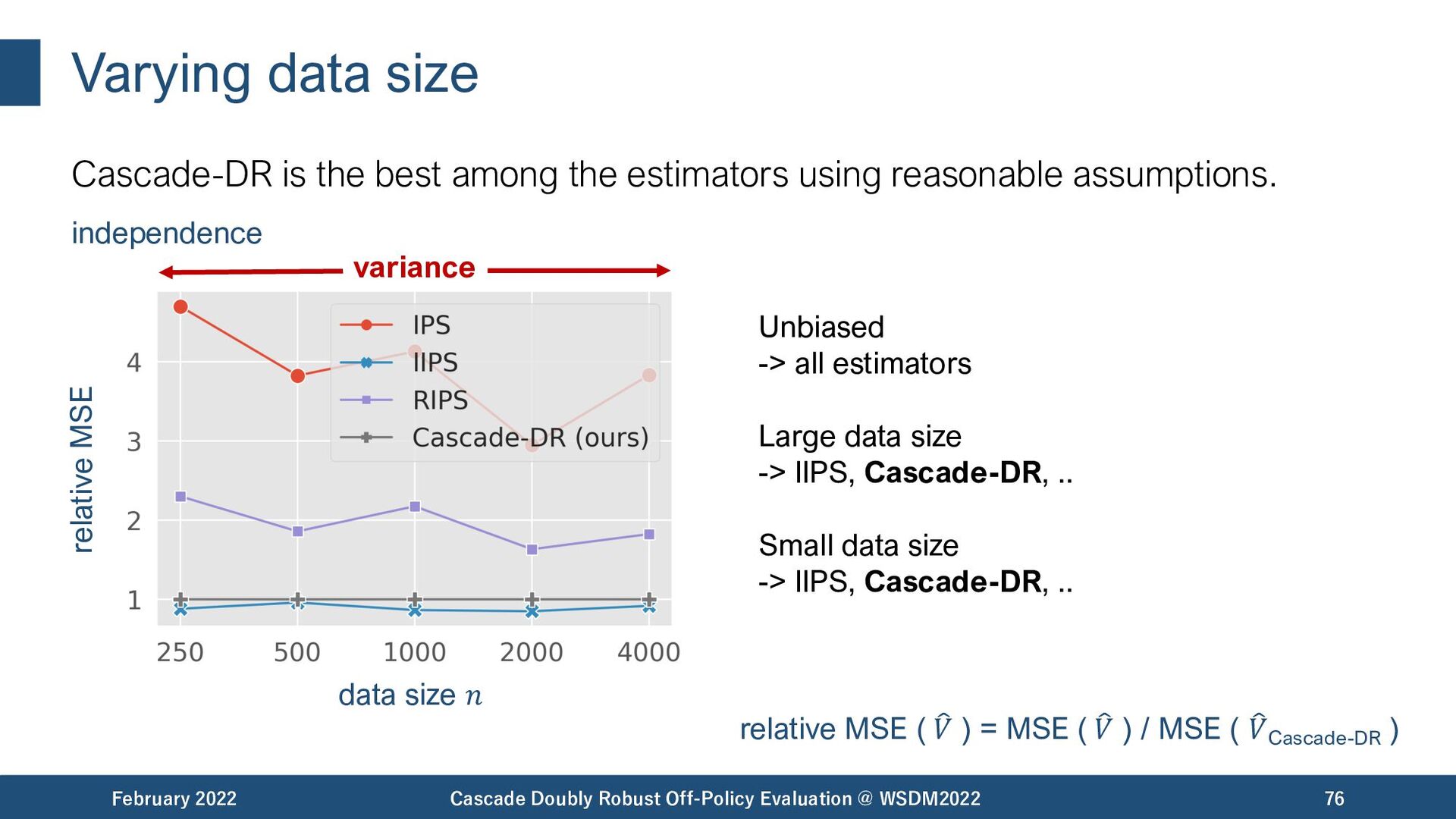{kind=link}
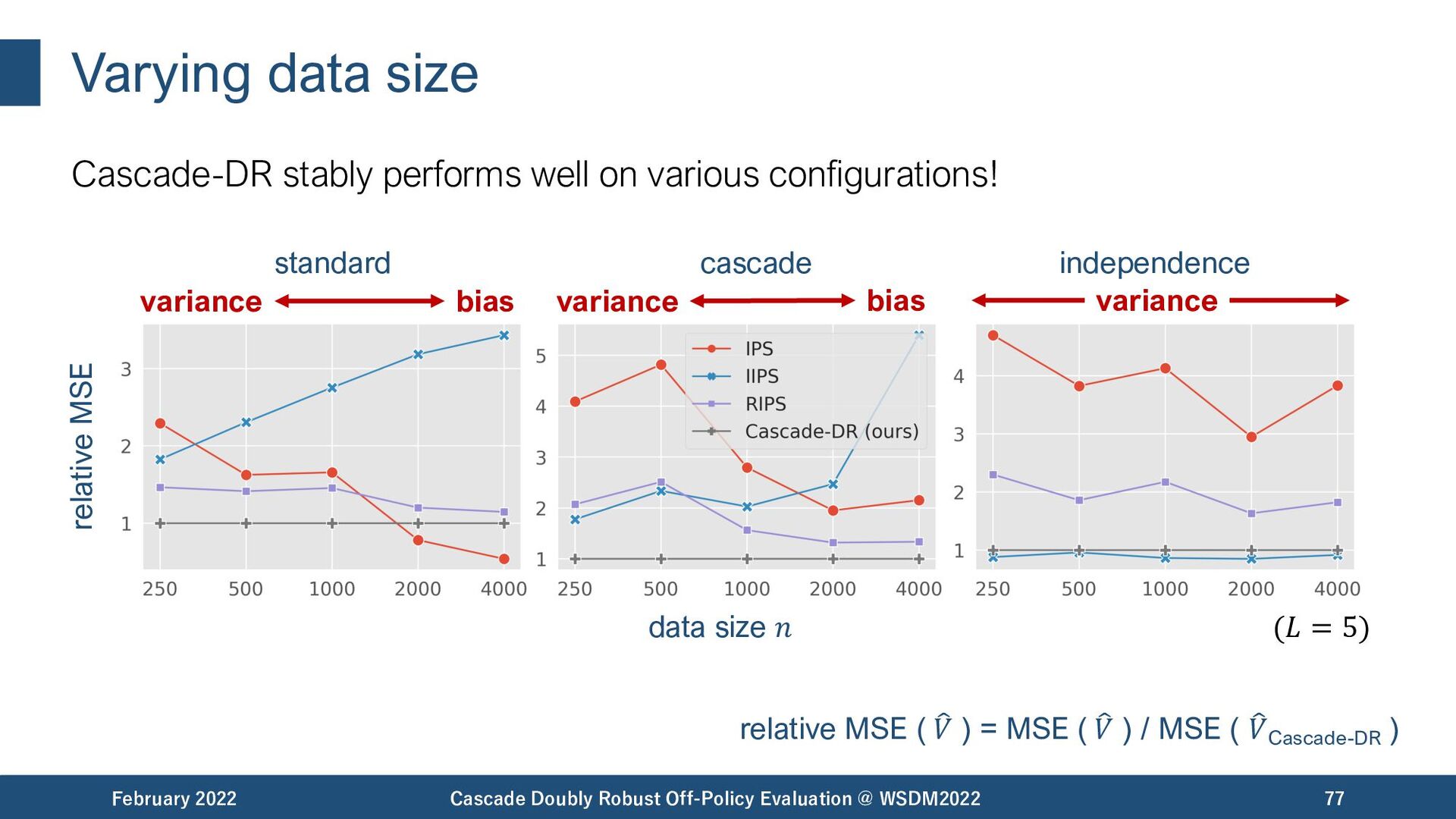{kind=link}
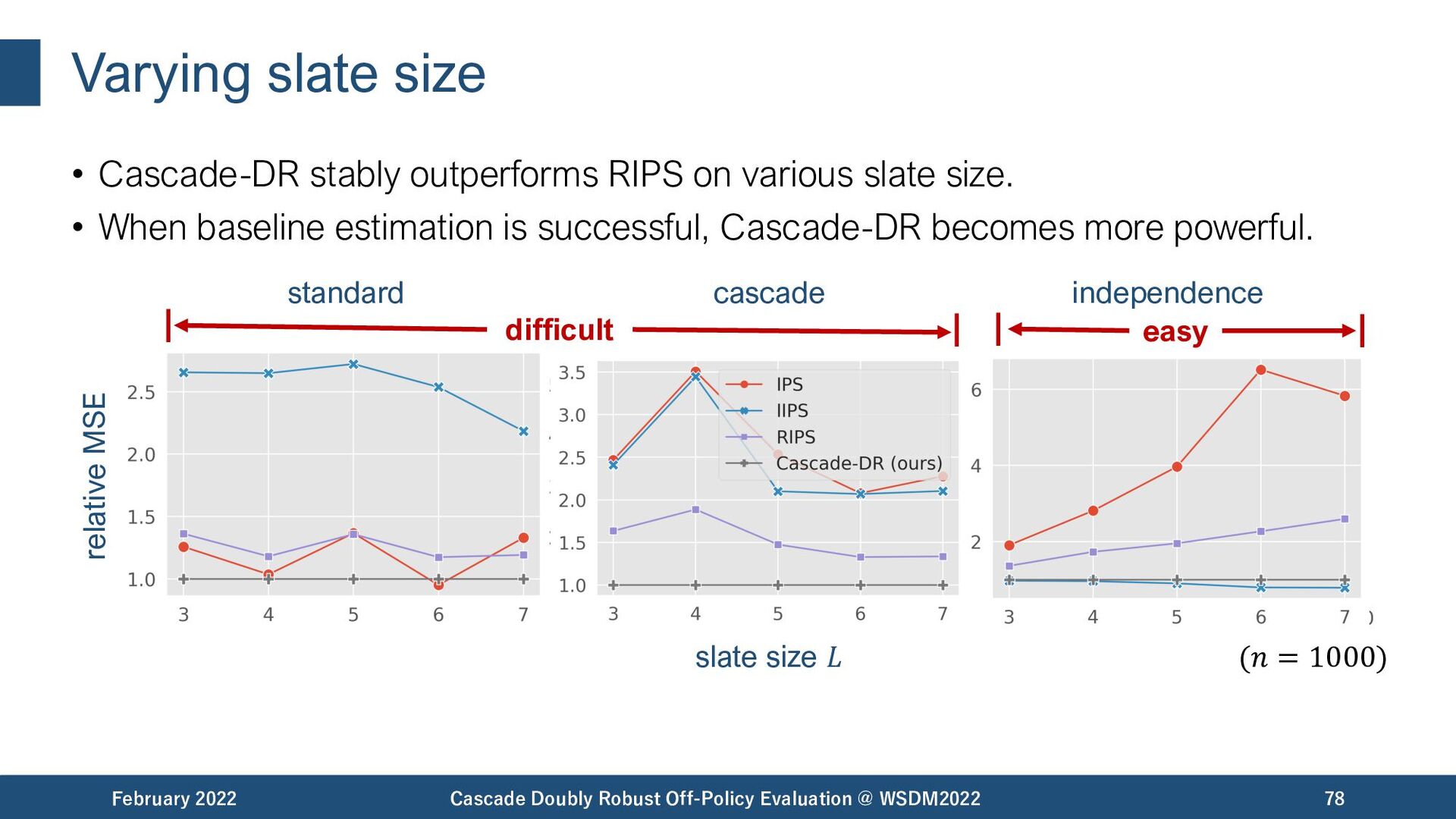{kind=link}
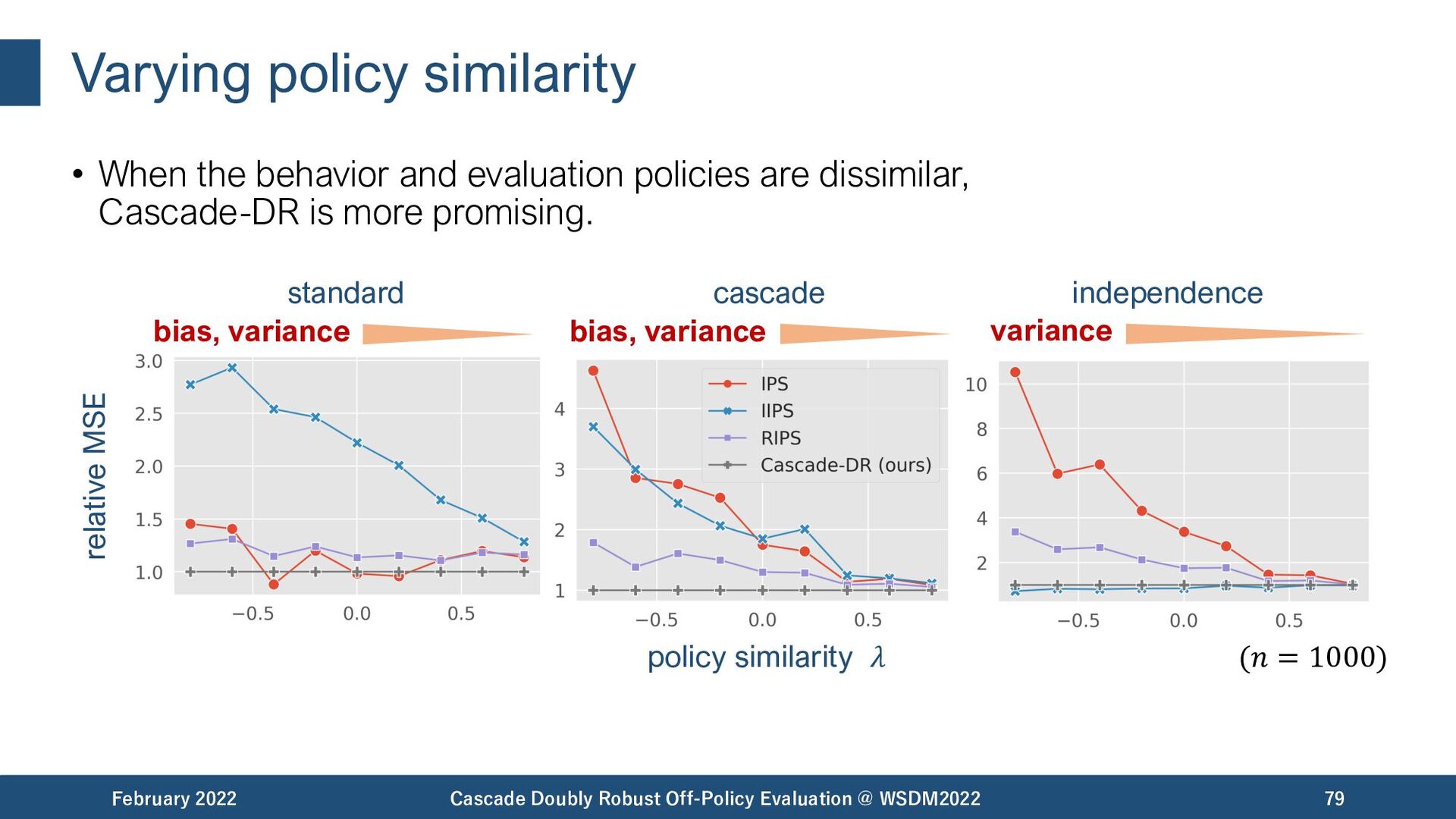{kind=link}
{kind=link}
{kind=link}
{kind=link}
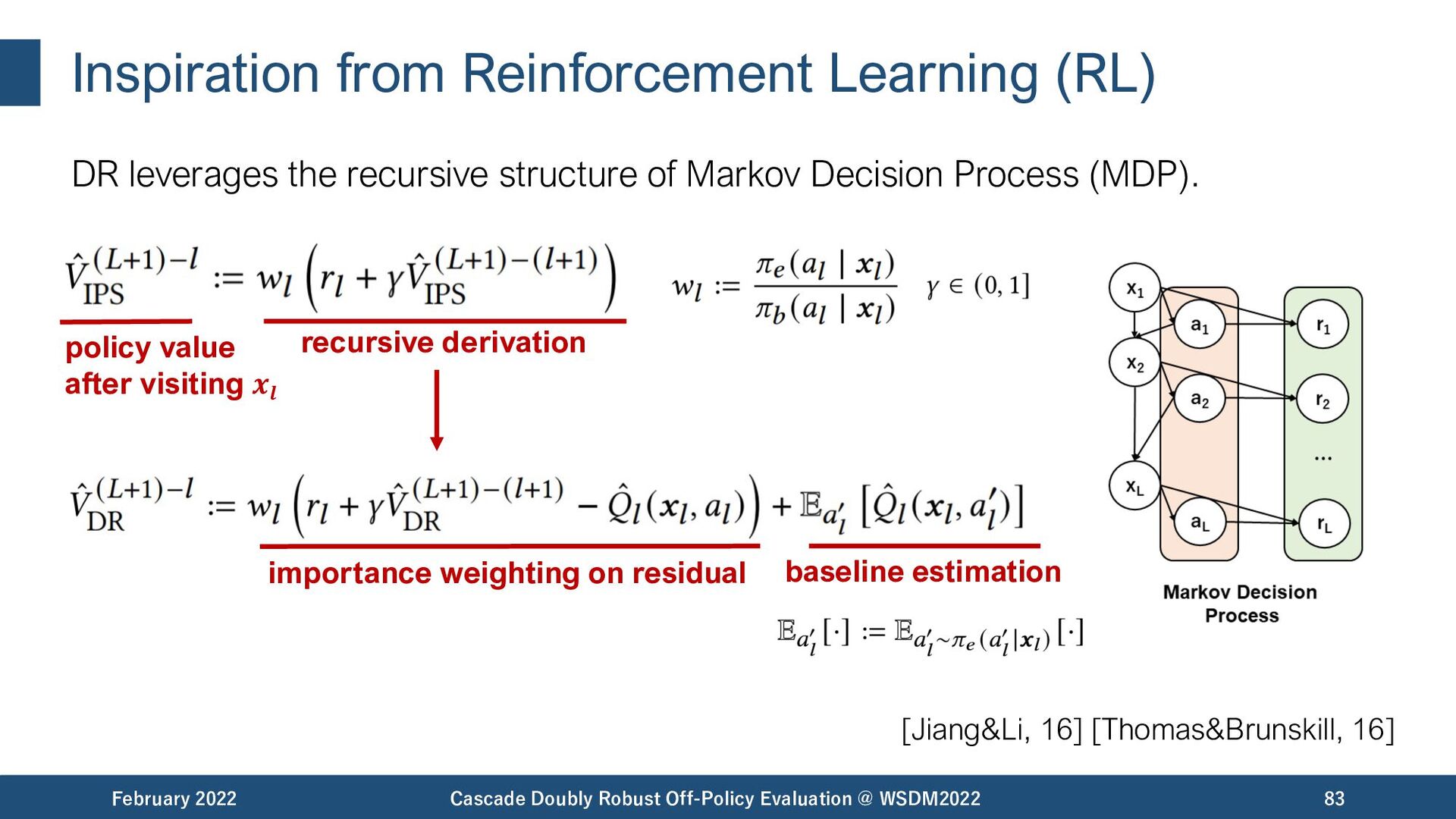{kind=link}
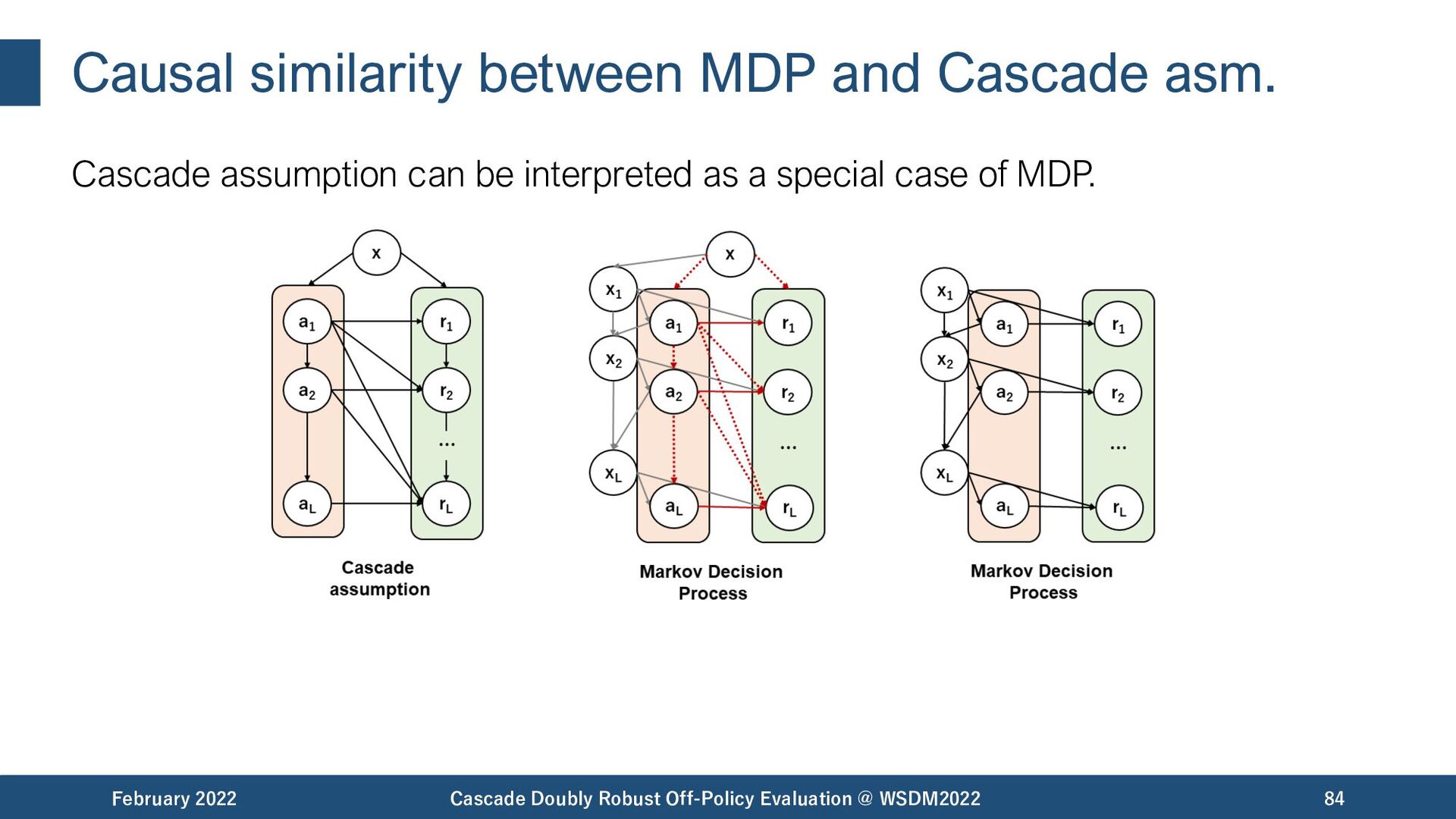{kind=link}
![PseudoInverse (PI) [Swaminathan+, 17] • Designed for the situation where](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_84.jpg){kind=link}
{kind=link}
![References (1/2) [Precup+, 00] Doina Precup, Richard S. Sutton, and](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_86.jpg){kind=link}
![References (2/2) [Thomas&Brunskill, 16] Philip S. Thomas and Emma Brunskill.](https://files.speakerdeck.com/presentations/7e71907b215a42f6b0b871a052a9c47c/slide_87.jpg){kind=link}