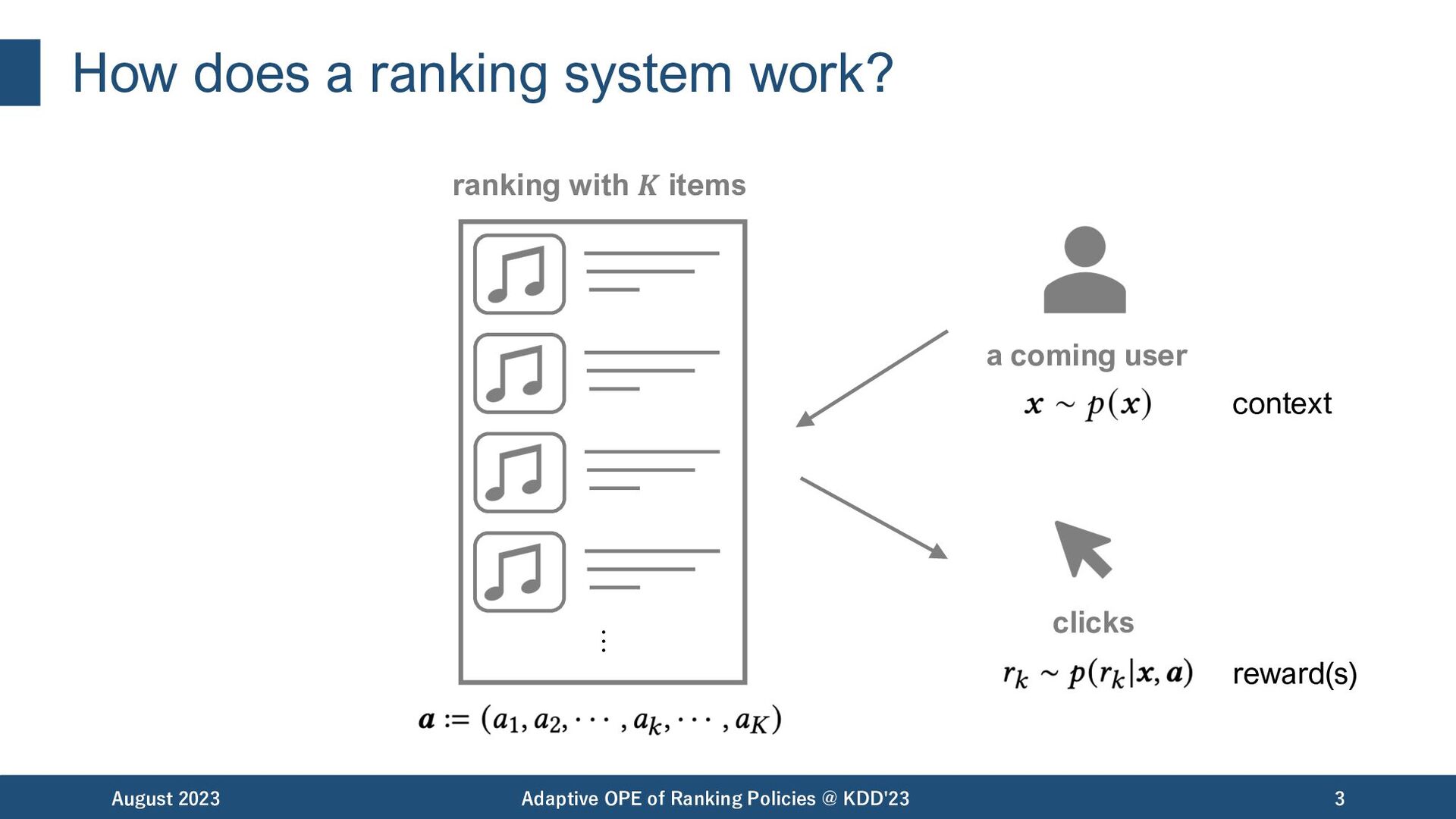
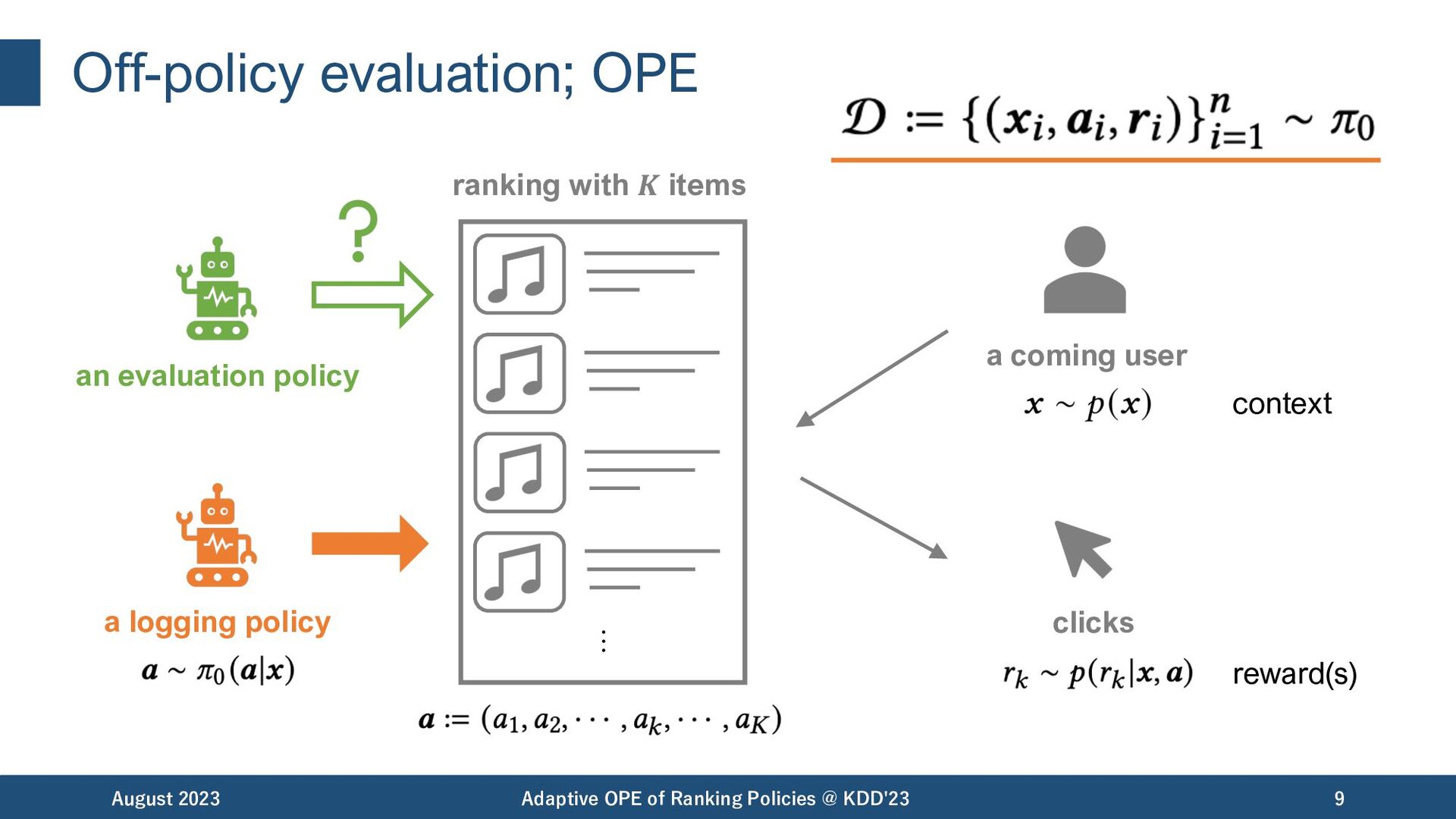
of items August 2023 Adaptive OPE of Ranking Policies @ KDD'23 2 • Search Engine • Music Streaming • E-commerce • News • and more..! Can we evaluate the value of these rankings offline in advance? … …
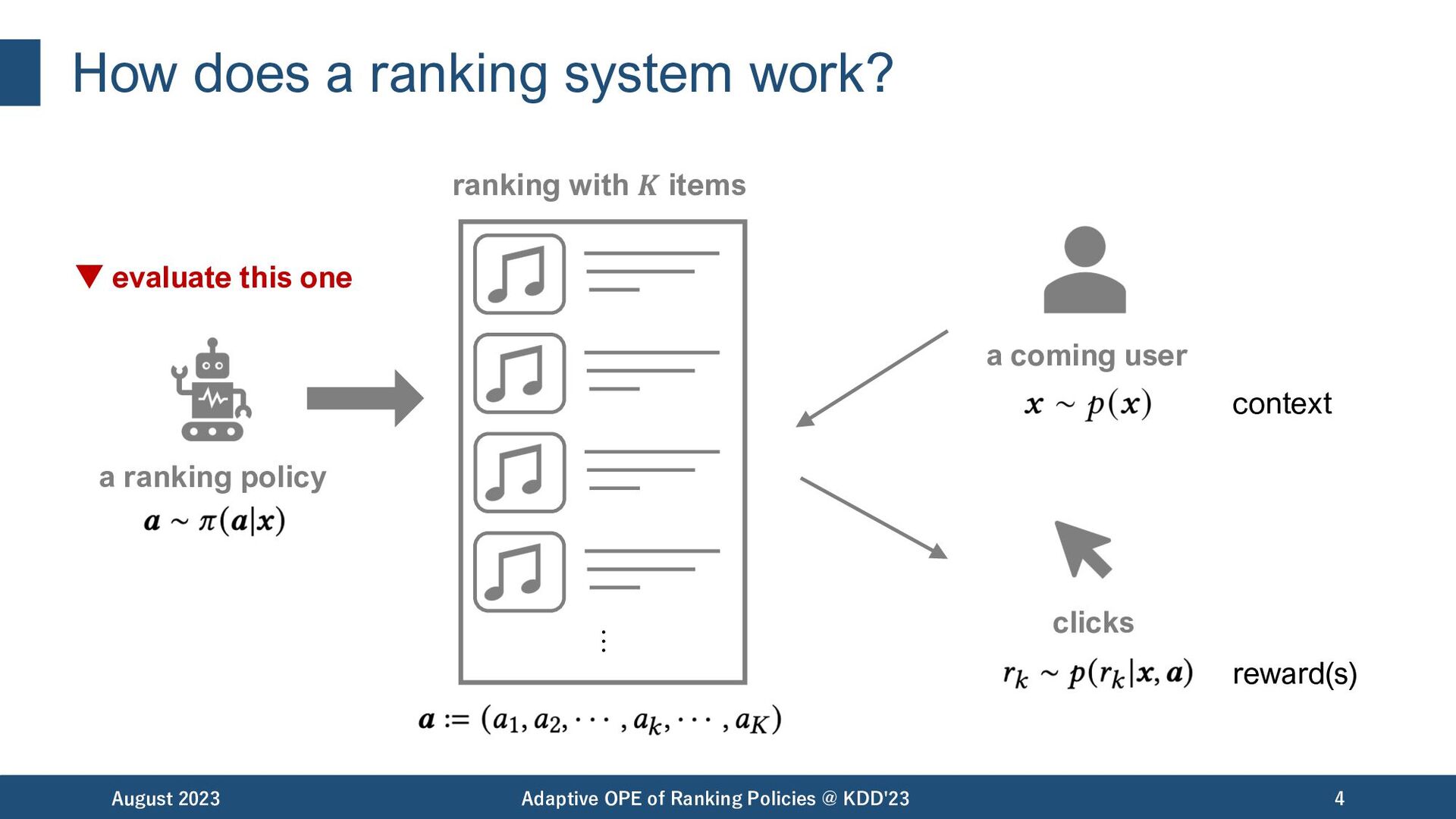
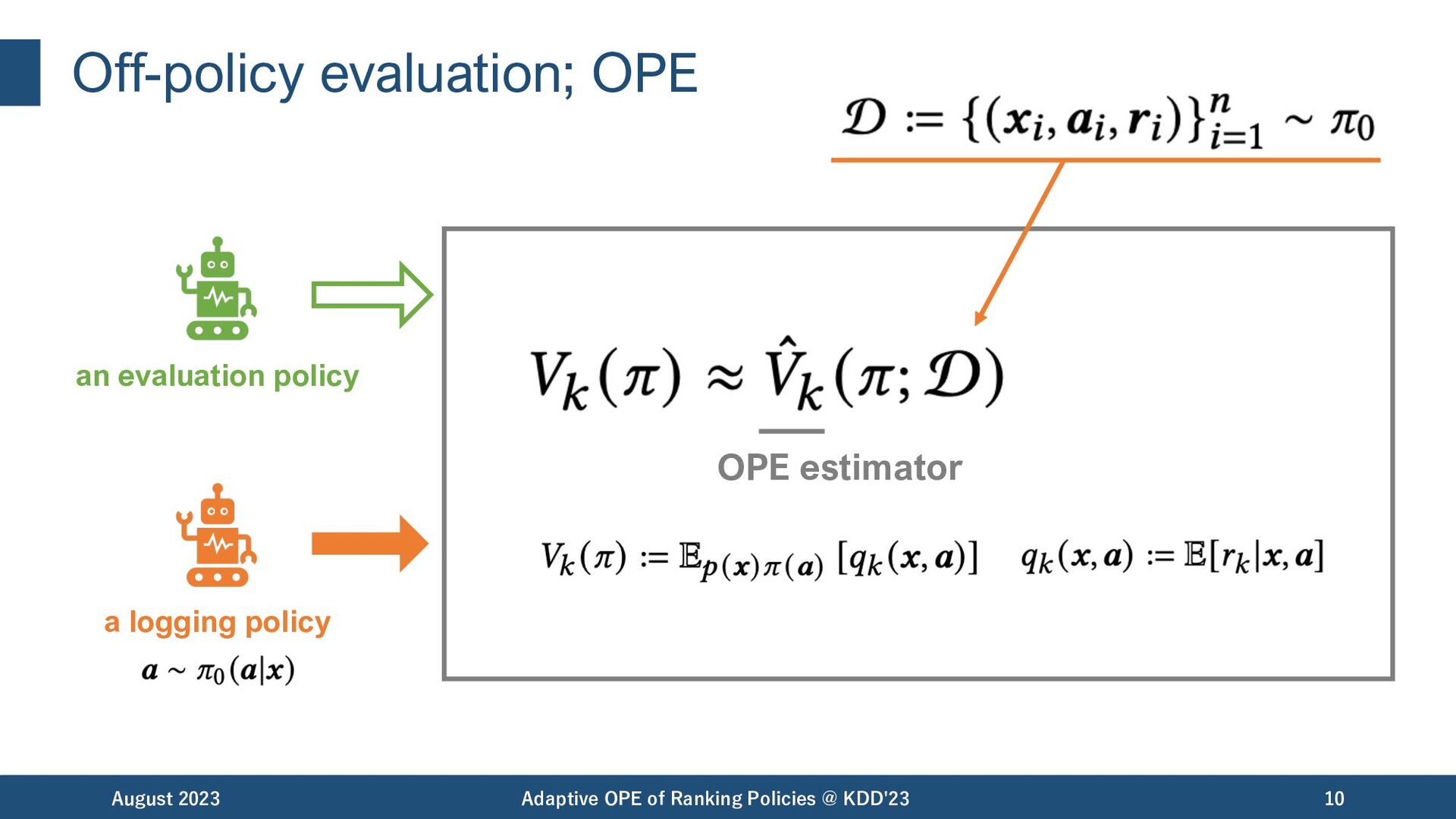
with its expected ranking-wise reward. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 6 position-wise policy value (depends on the whole ranking)
of Ranking Policies @ KDD'23 13 importance weight ・unbiased correcting the distribution shift evaluation logging ranking A ranking B more less less more
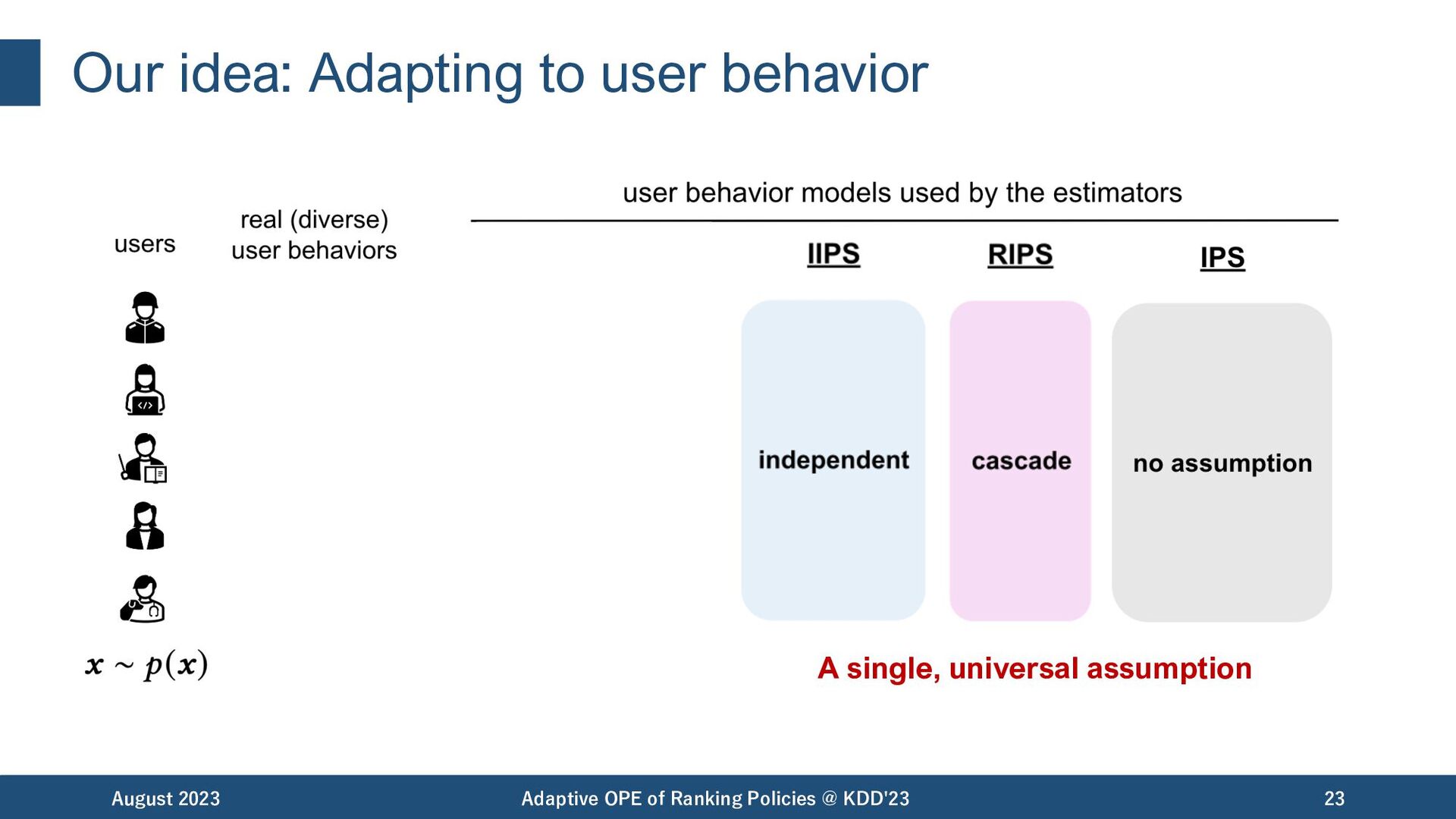
are affected only by some subsets of actions. • Independent IPS [Li+,18] • Reward Interaction IPS [McInerney+,20] August 2023 Adaptive OPE of Ranking Policies @ KDD'23 18
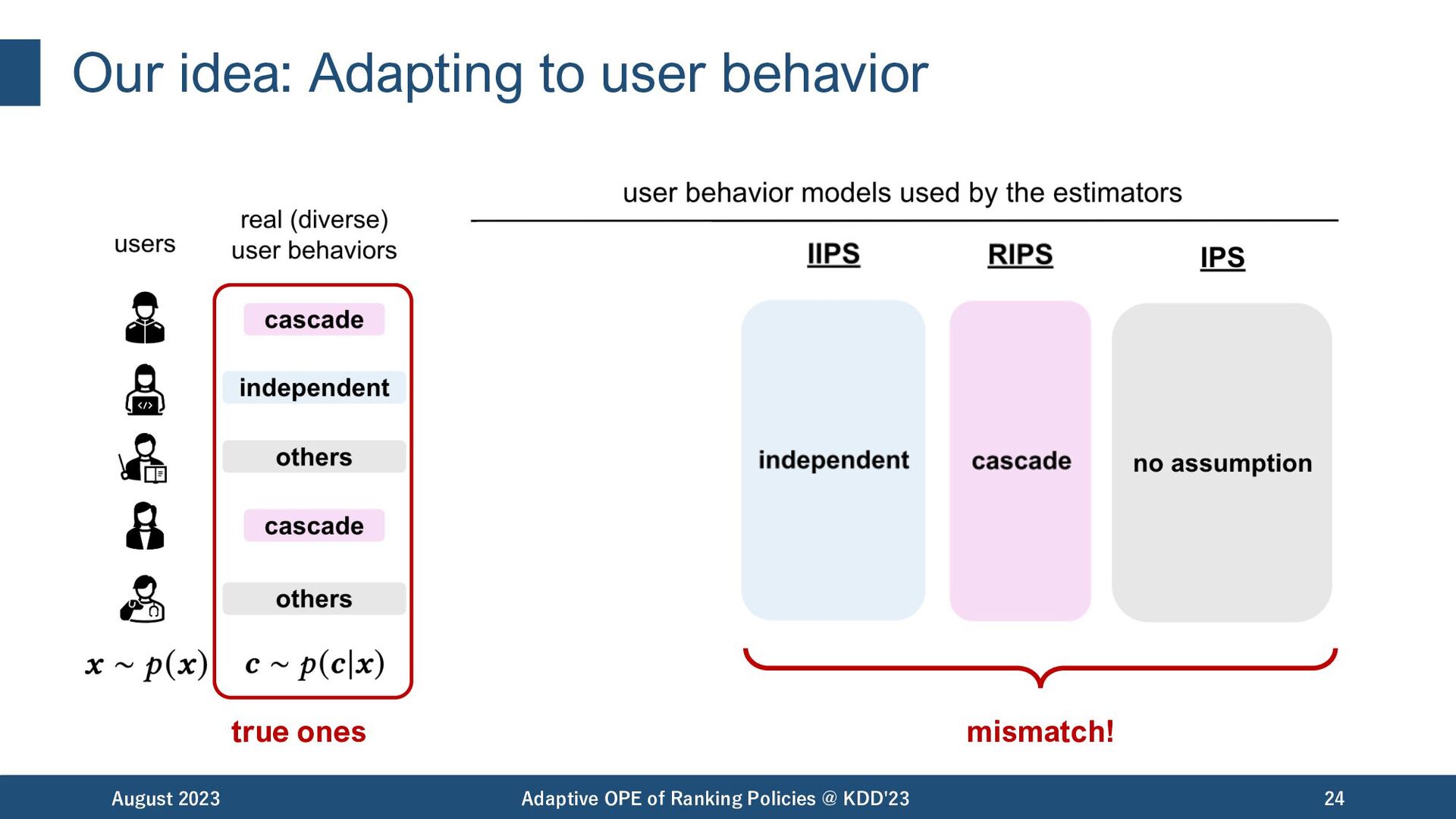
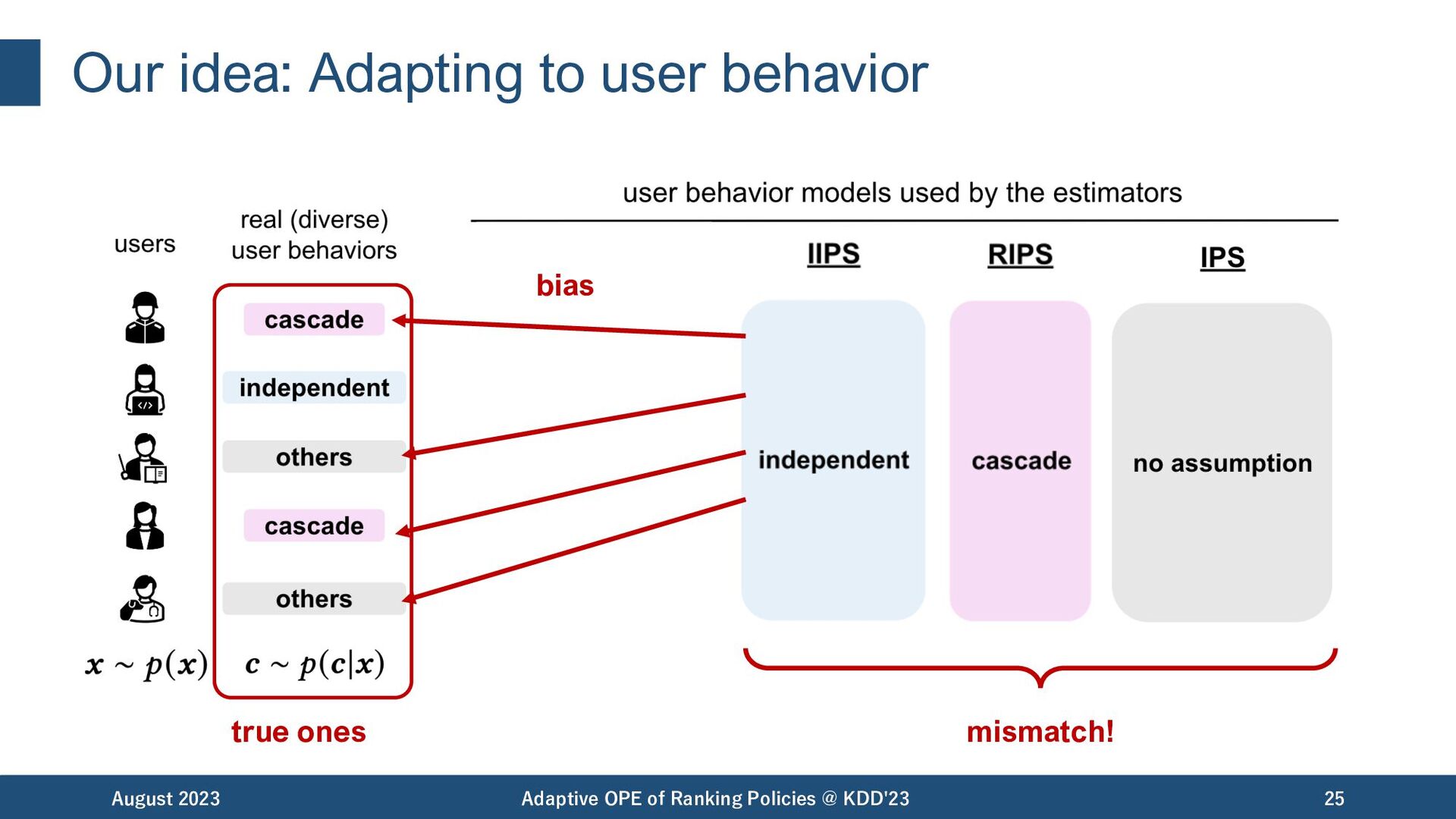
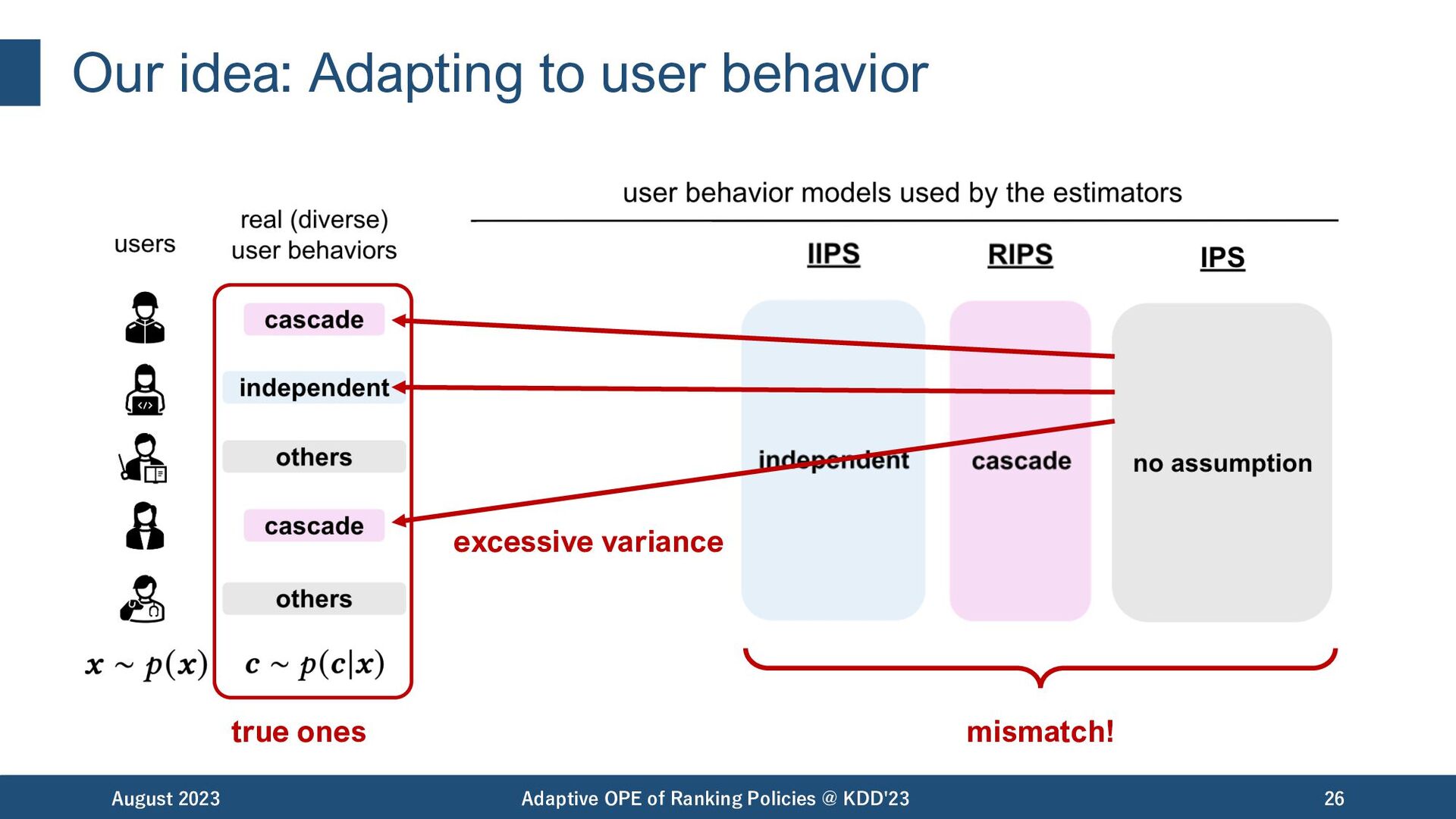
OPE of Ranking Policies @ KDD'23 19 Bias Variance IIPS RIPS IPS independent cascade standard click model IIPS: [Li+,18], RIPS: [McInerney+,20], IPS: [Precup+,00] bias variance tradeoff depending on a single user behavior assumption
OPE of Ranking Policies @ KDD'23 20 Bias Variance IIPS RIPS IPS independent cascade standard click model IIPS: [Li+,18], RIPS: [McInerney+,20], IPS: [Precup+,00] Are they enough to capture real-world user behaviors..? bias variance tradeoff depending on the user behavior assumption
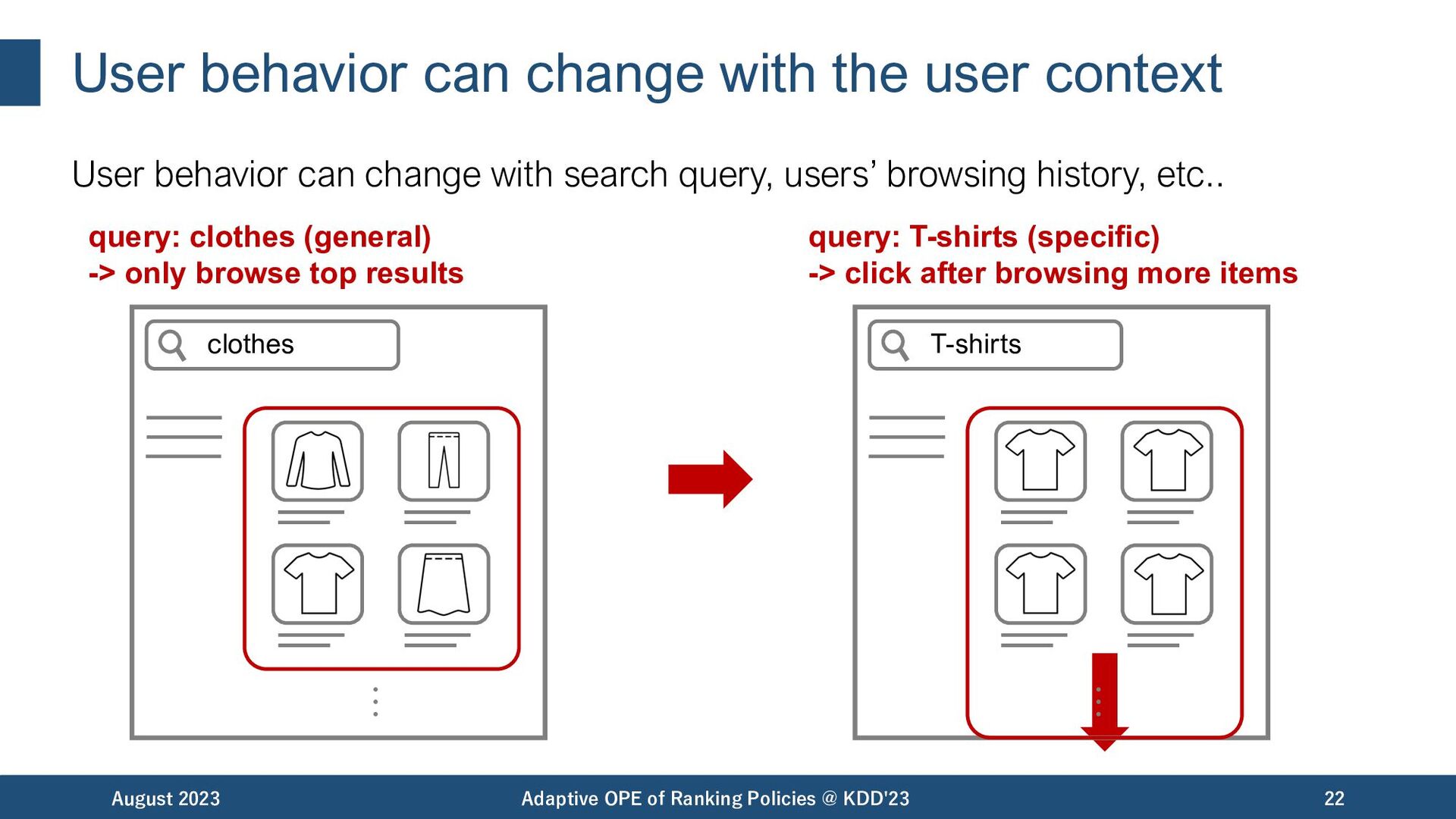
Adaptive OPE of Ranking Policies @ KDD'23 22 query: clothes (general) -> only browse top results query: T-shirts (specific) -> click after browsing more items clothes … T-shirts … User behavior can change with search query, users’ browsing history, etc..
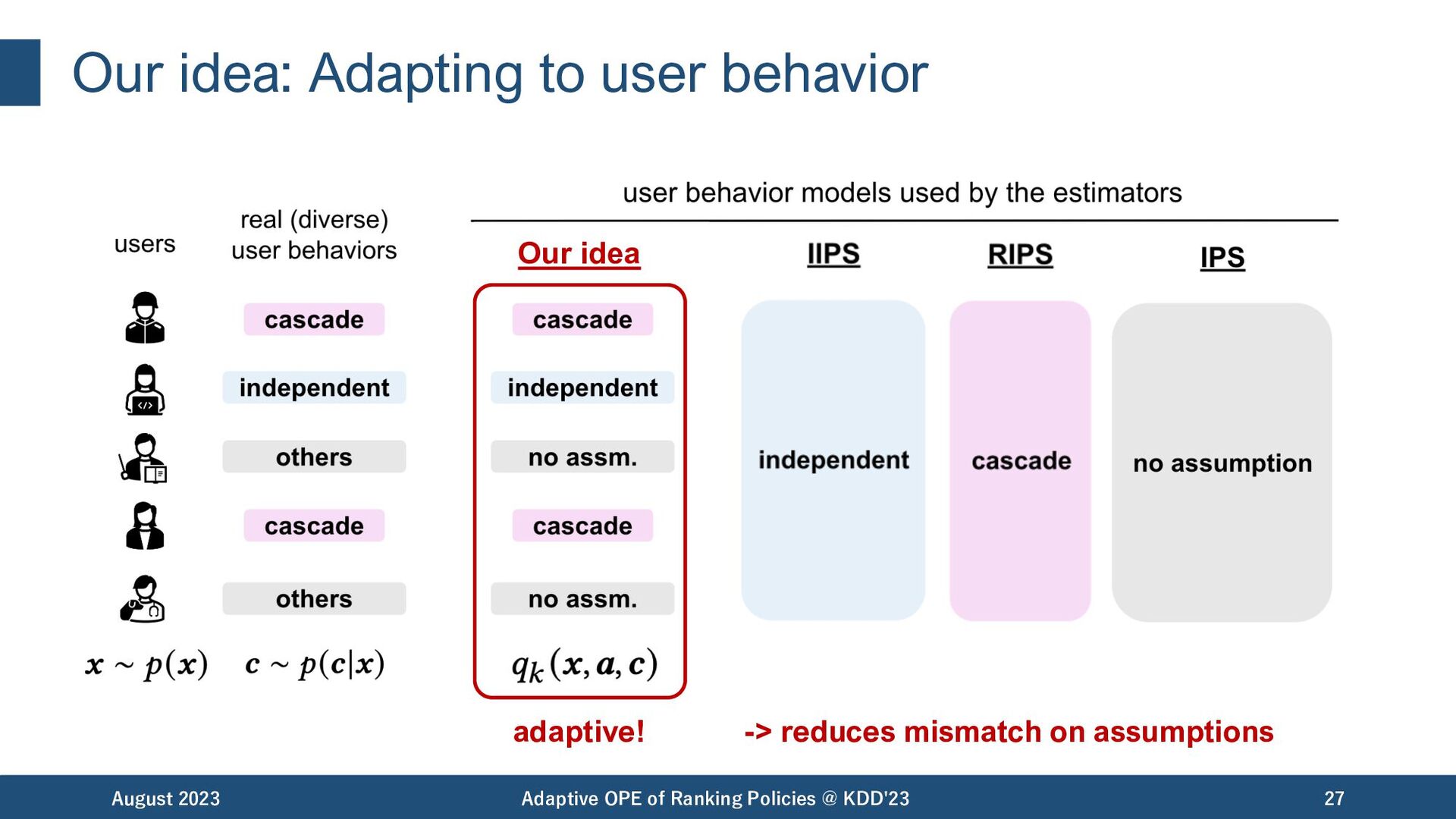
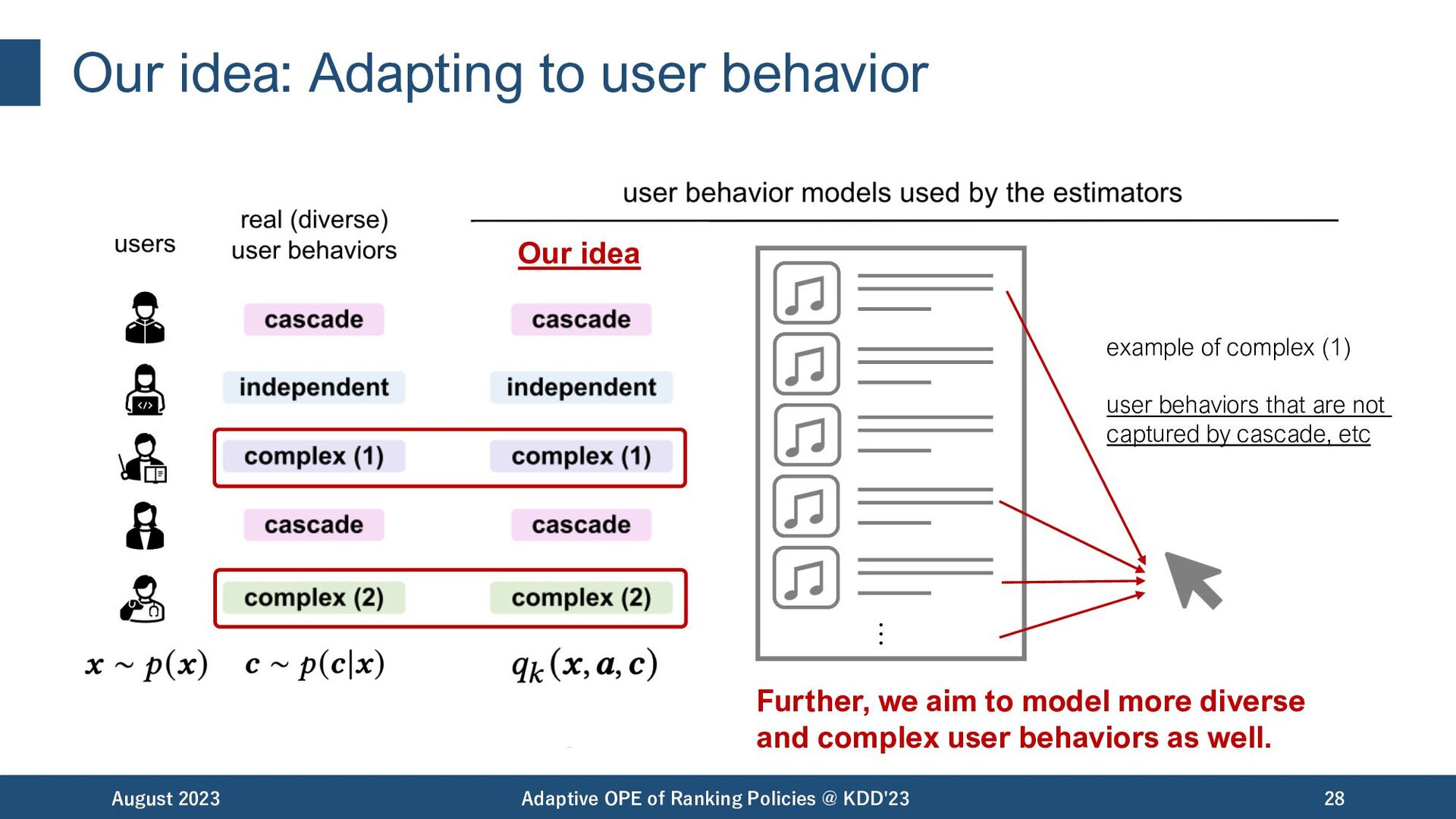
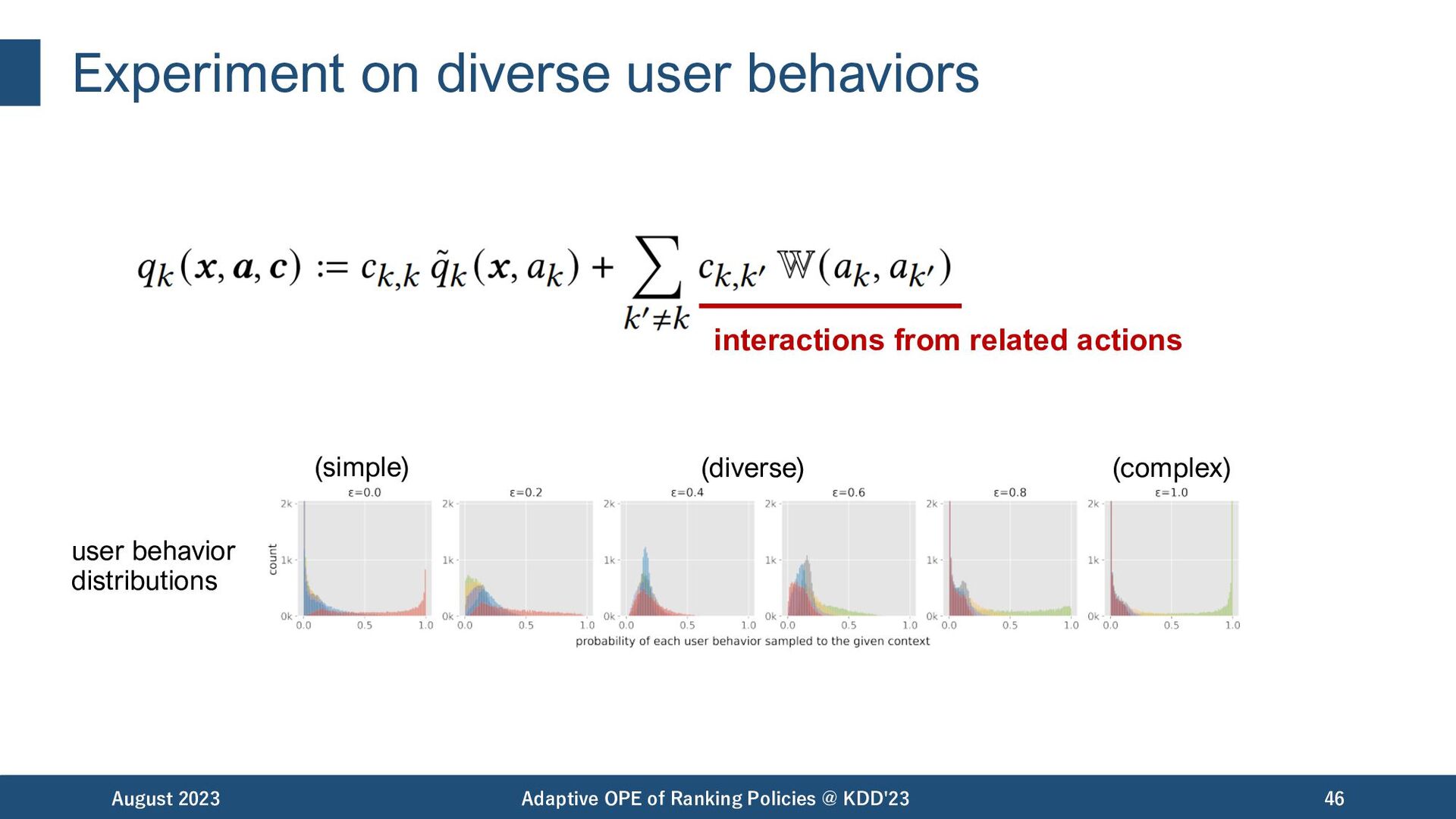
of Ranking Policies @ KDD'23 28 Our idea adaptive! -> reduces mismatch on assumptions Our idea … example of complex (1) user behaviors that are not captured by cascade, etc Further, we aim to model more diverse and complex user behaviors as well.
Policies @ KDD'23 29 Statistical benefits • Unbiased under any given user behavior model. • Minimum variance among other IPS-based unbiased estimators. importance weight of only actions that matters
practice, user behavior 𝑐 is often unobservable, thus consider ̂ 𝑐 instead. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 32 overlap matters small bias large bias source of bias
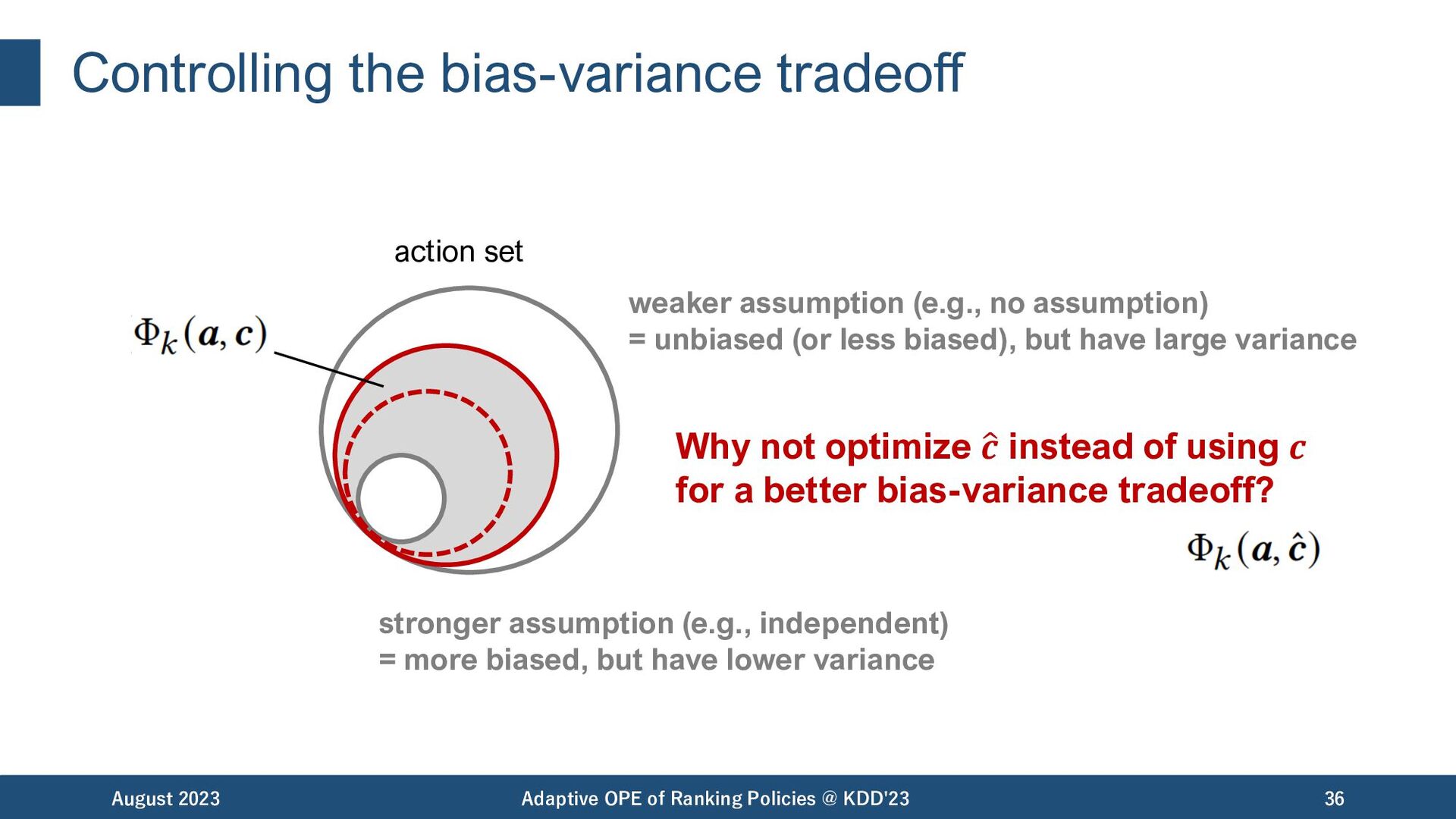
Policies @ KDD'23 35 stronger assumption (e.g., independent) = more biased, but have lower variance action set weaker assumption (e.g., no assumption) = unbiased (or less biased), but have large variance
Policies @ KDD'23 36 stronger assumption (e.g., independent) = more biased, but have lower variance action set weaker assumption (e.g., no assumption) = unbiased (or less biased), but have large variance Why not optimize # 𝒄 instead of using 𝒄 for a better bias-variance tradeoff?
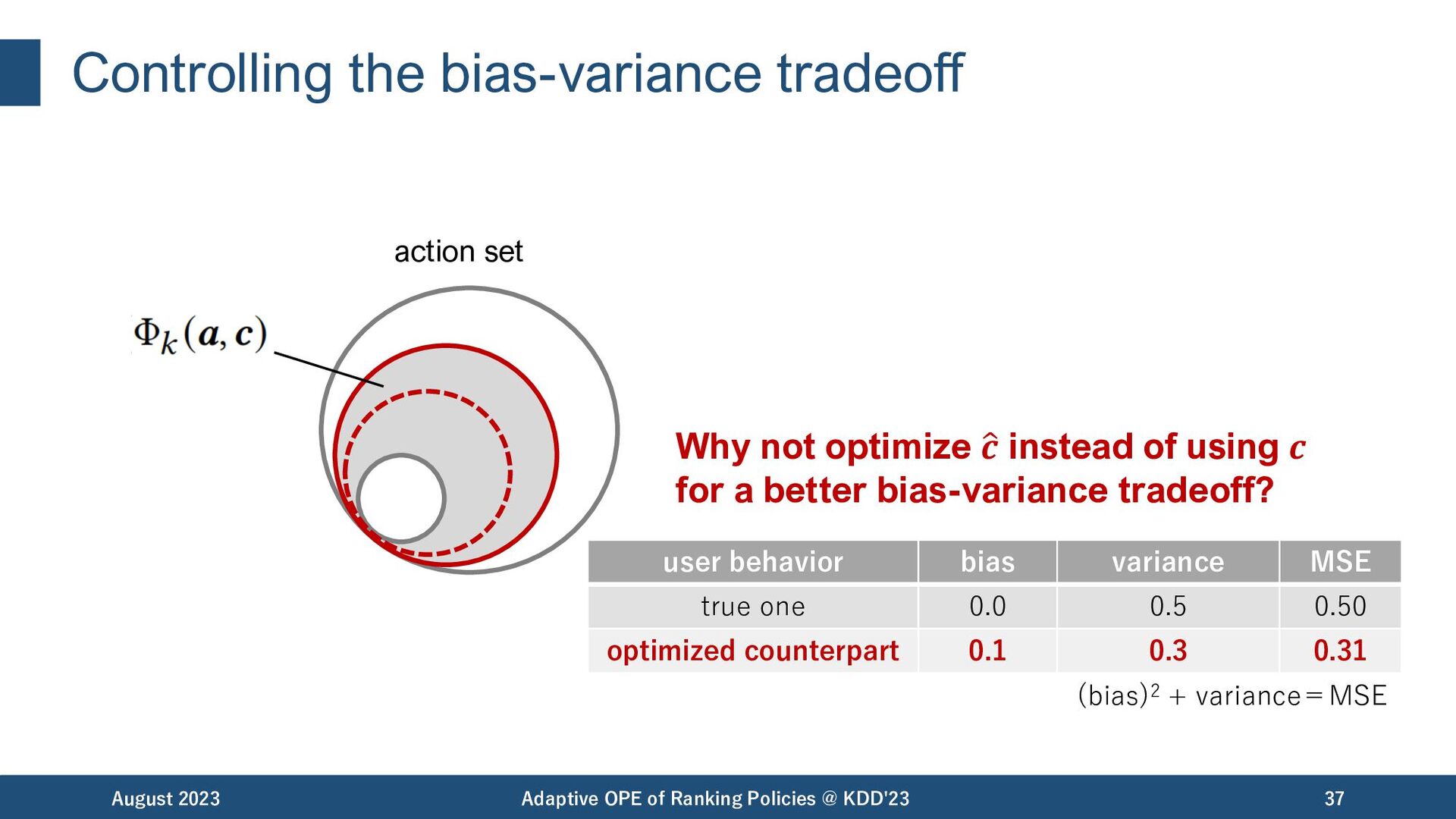
Policies @ KDD'23 37 action set Why not optimize # 𝒄 instead of using 𝒄 for a better bias-variance tradeoff? user behavior bias variance MSE true one 0.0 0.5 0.50 optimized counterpart 0.1 0.3 0.31 (bias)2 + variance=MSE
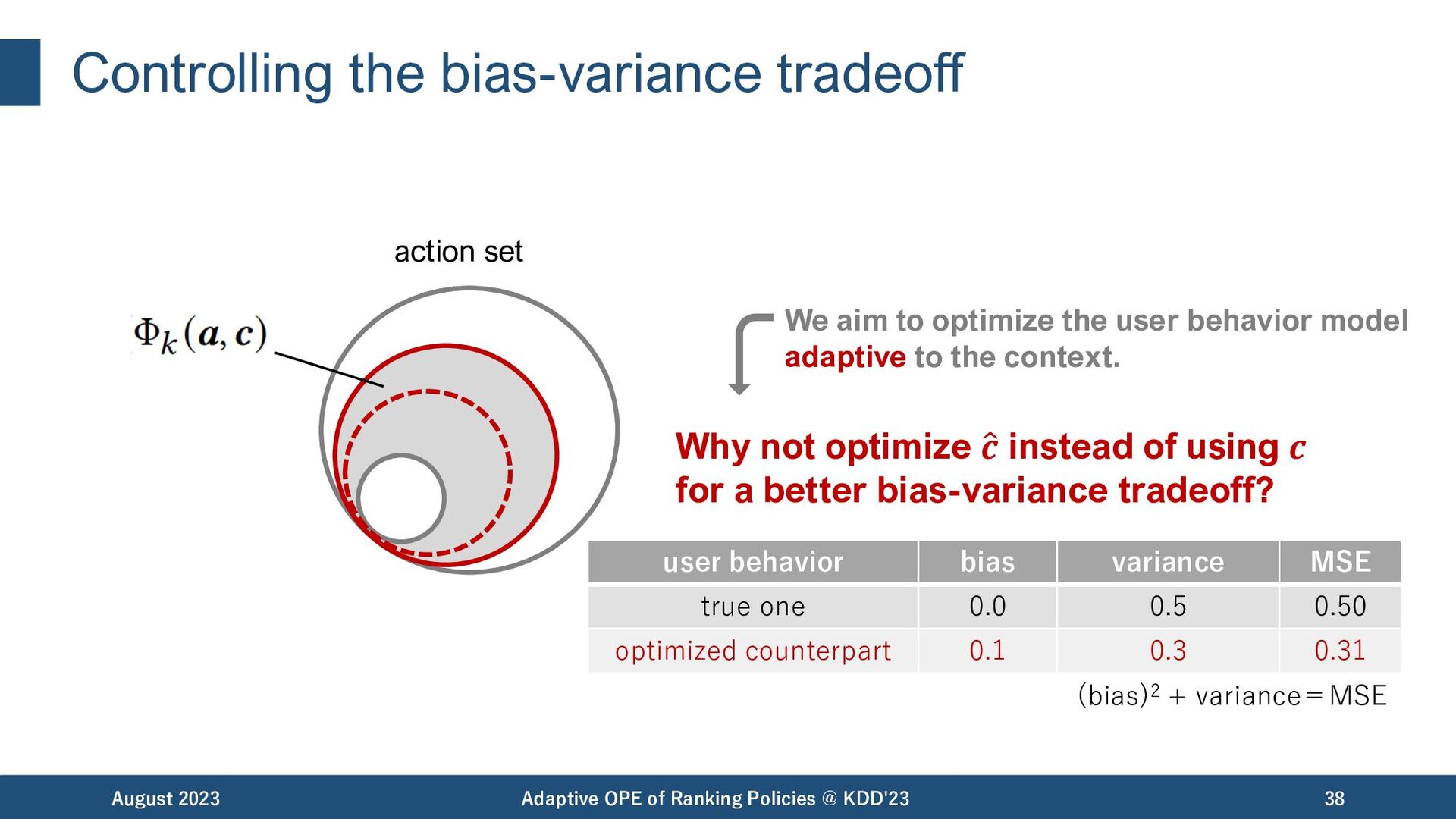
Policies @ KDD'23 38 action set Why not optimize # 𝒄 instead of using 𝒄 for a better bias-variance tradeoff? user behavior bias variance MSE true one 0.0 0.5 0.50 optimized counterpart 0.1 0.3 0.31 (bias)2 + variance=MSE We aim to optimize the user behavior model adaptive to the context.
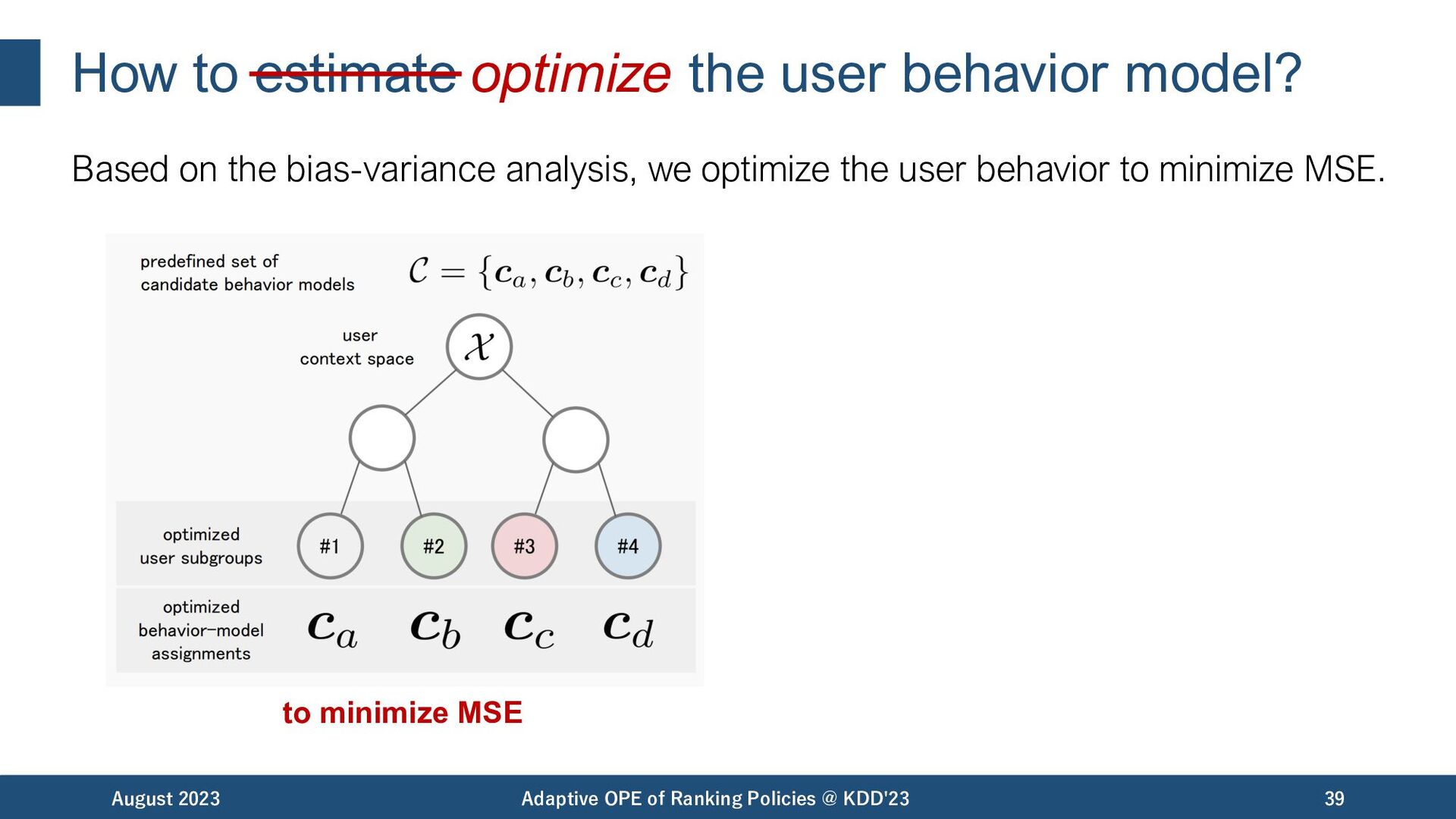
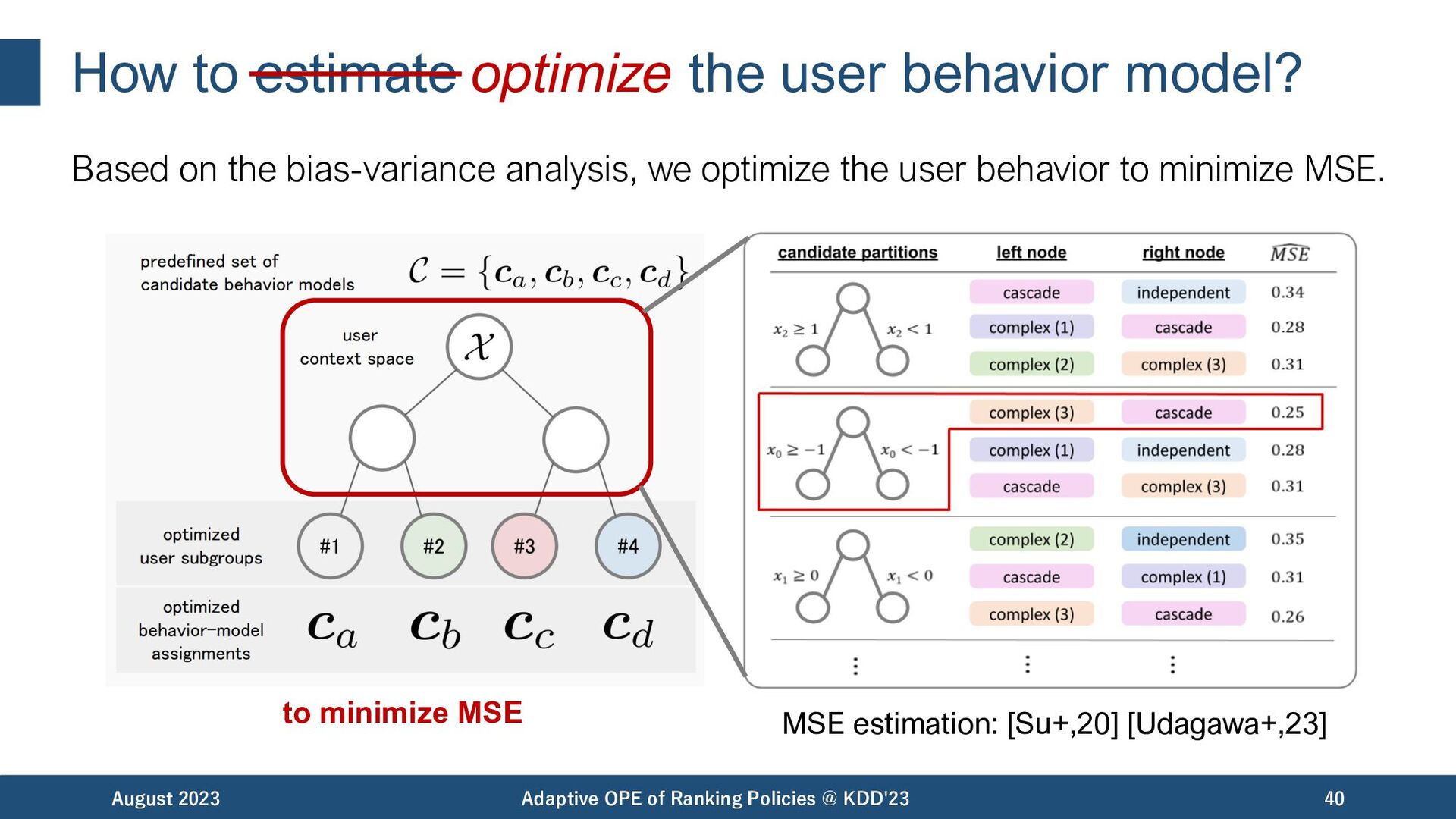
the bias-variance analysis, we optimize the user behavior to minimize MSE. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 40 MSE estimation: [Su+,20] [Udagawa+,23] to minimize MSE
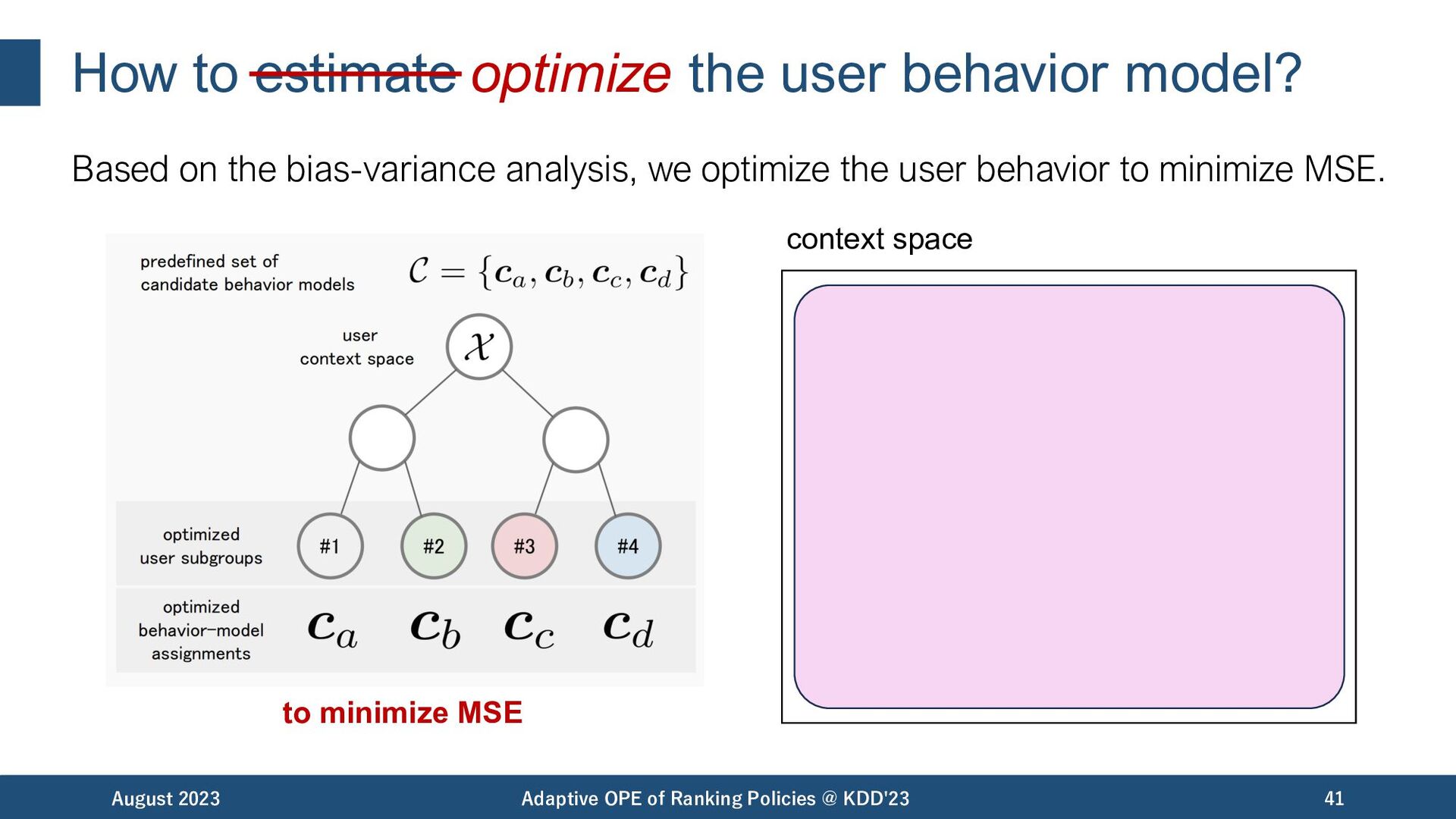
the bias-variance analysis, we optimize the user behavior to minimize MSE. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 41 context space to minimize MSE
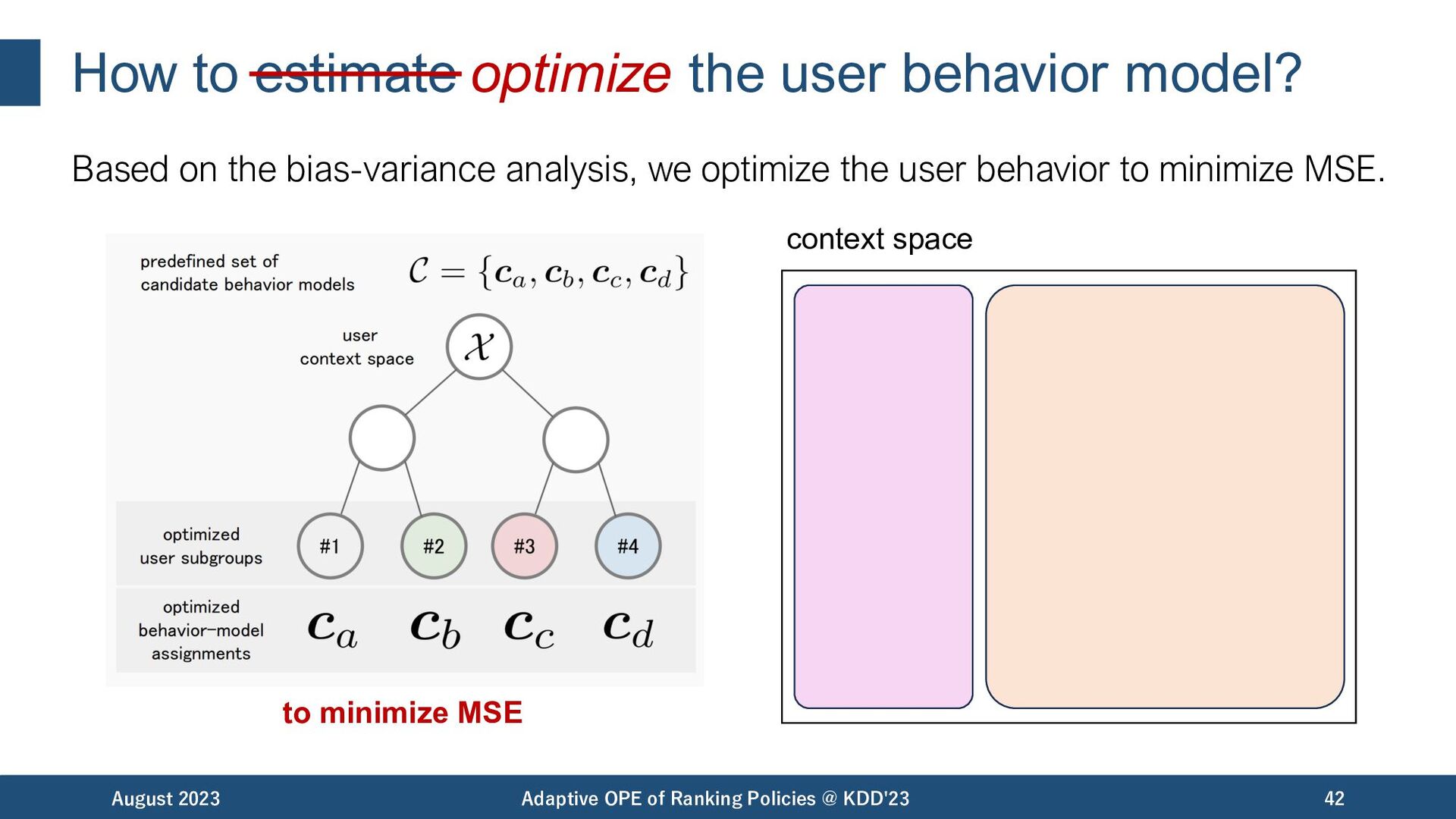
the bias-variance analysis, we optimize the user behavior to minimize MSE. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 42 context space to minimize MSE
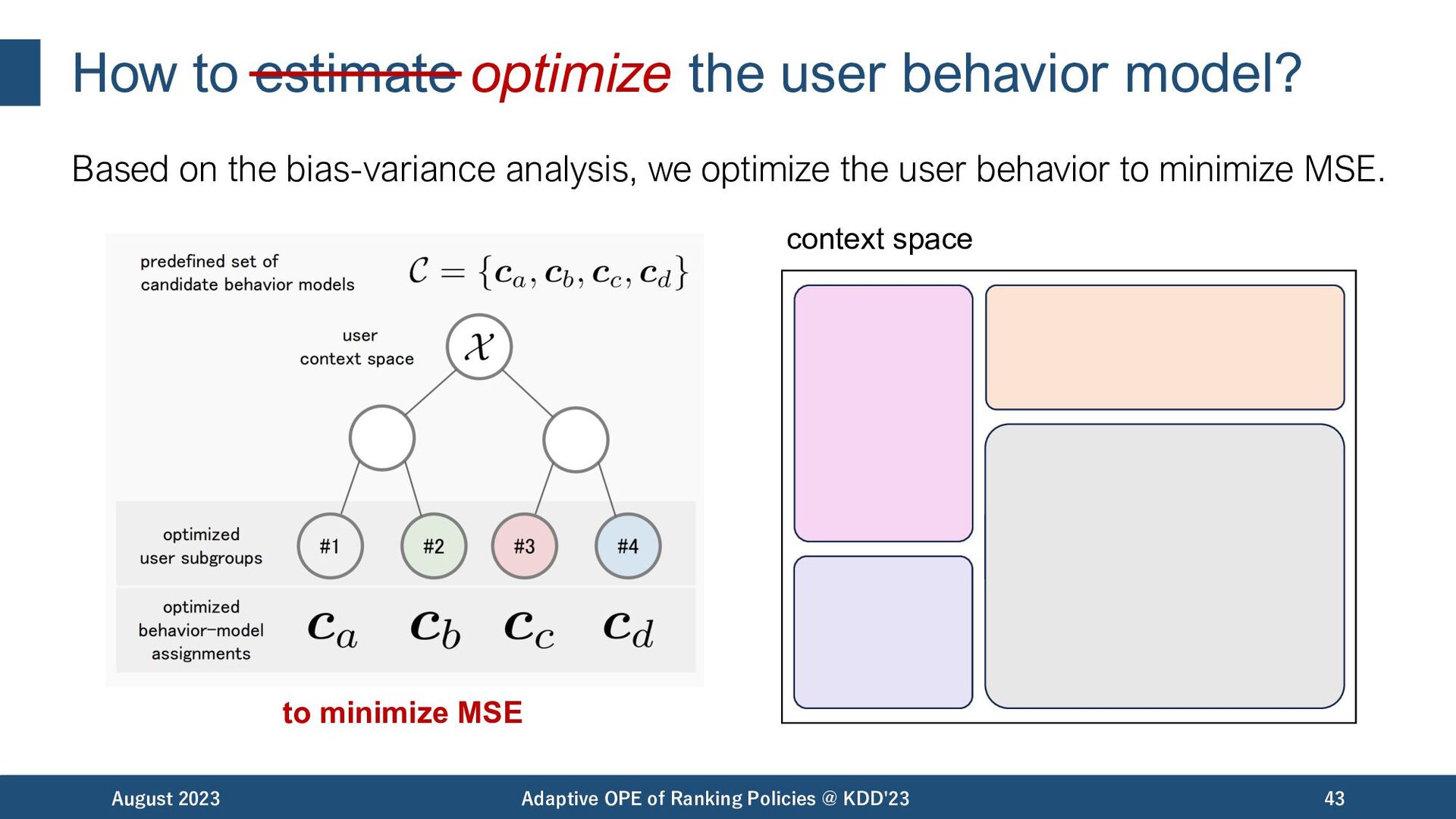
the bias-variance analysis, we optimize the user behavior to minimize MSE. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 43 to minimize MSE context space
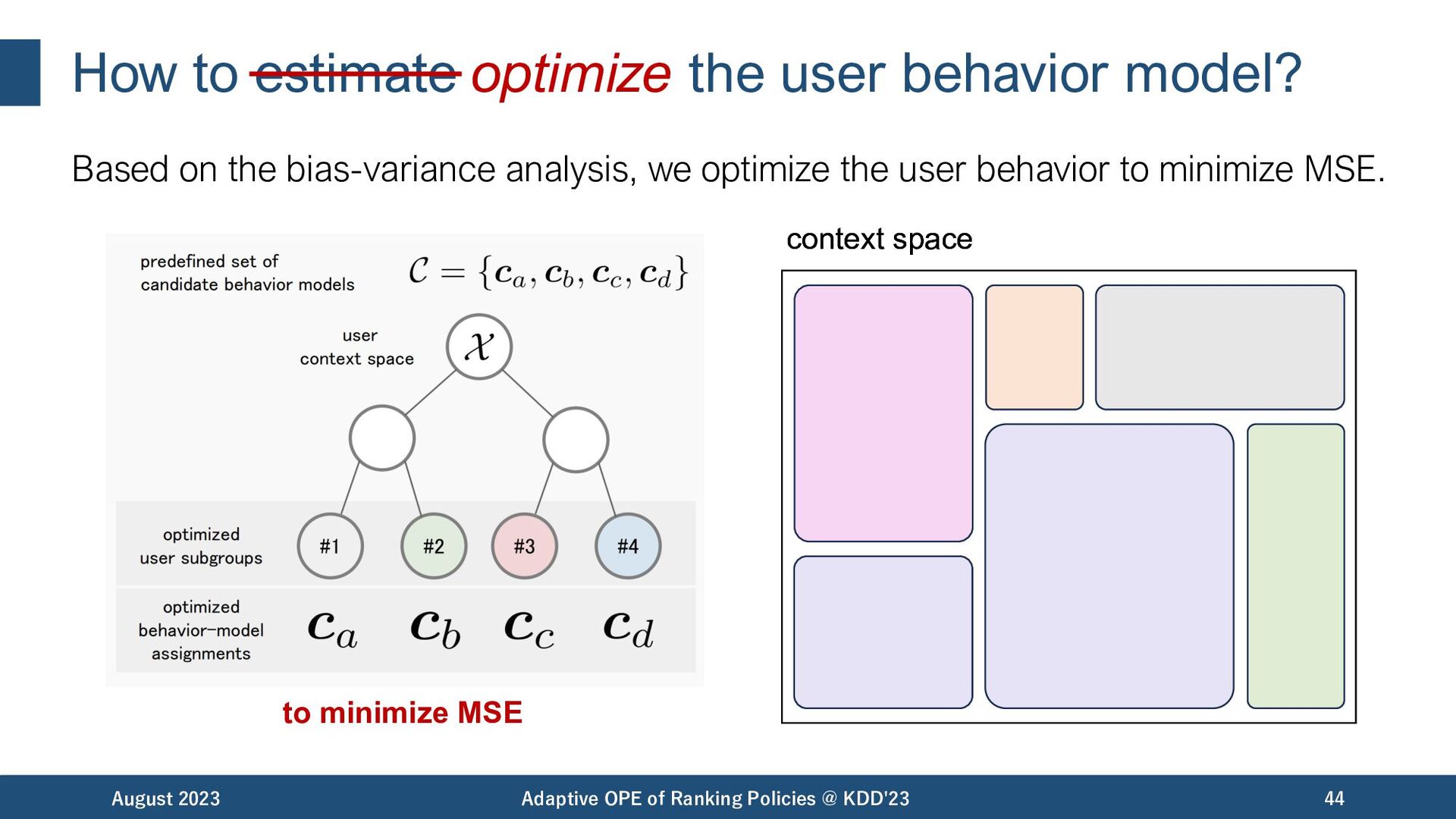
the bias-variance analysis, we optimize the user behavior to minimize MSE. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 44 context space to minimize MSE context space
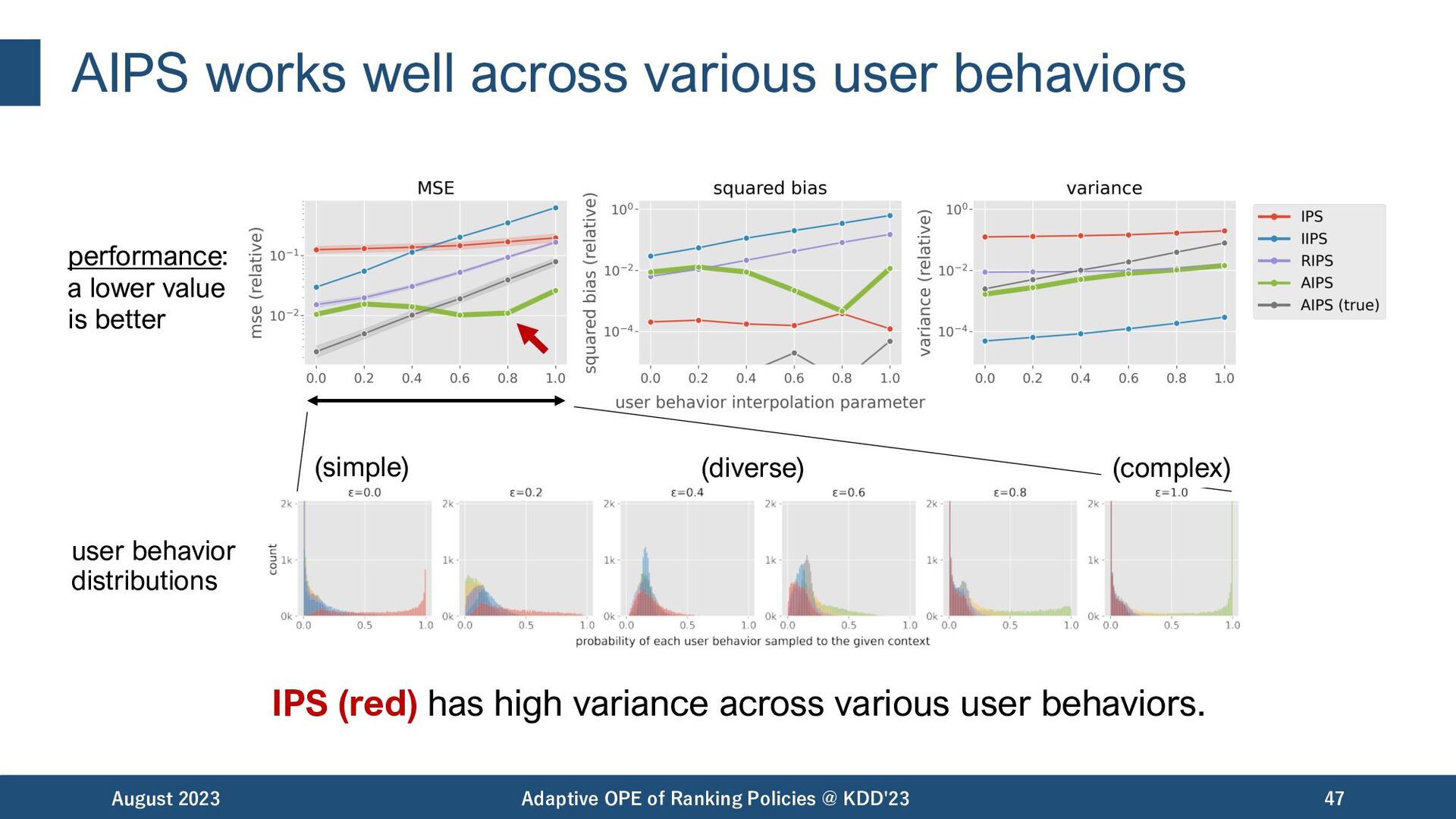
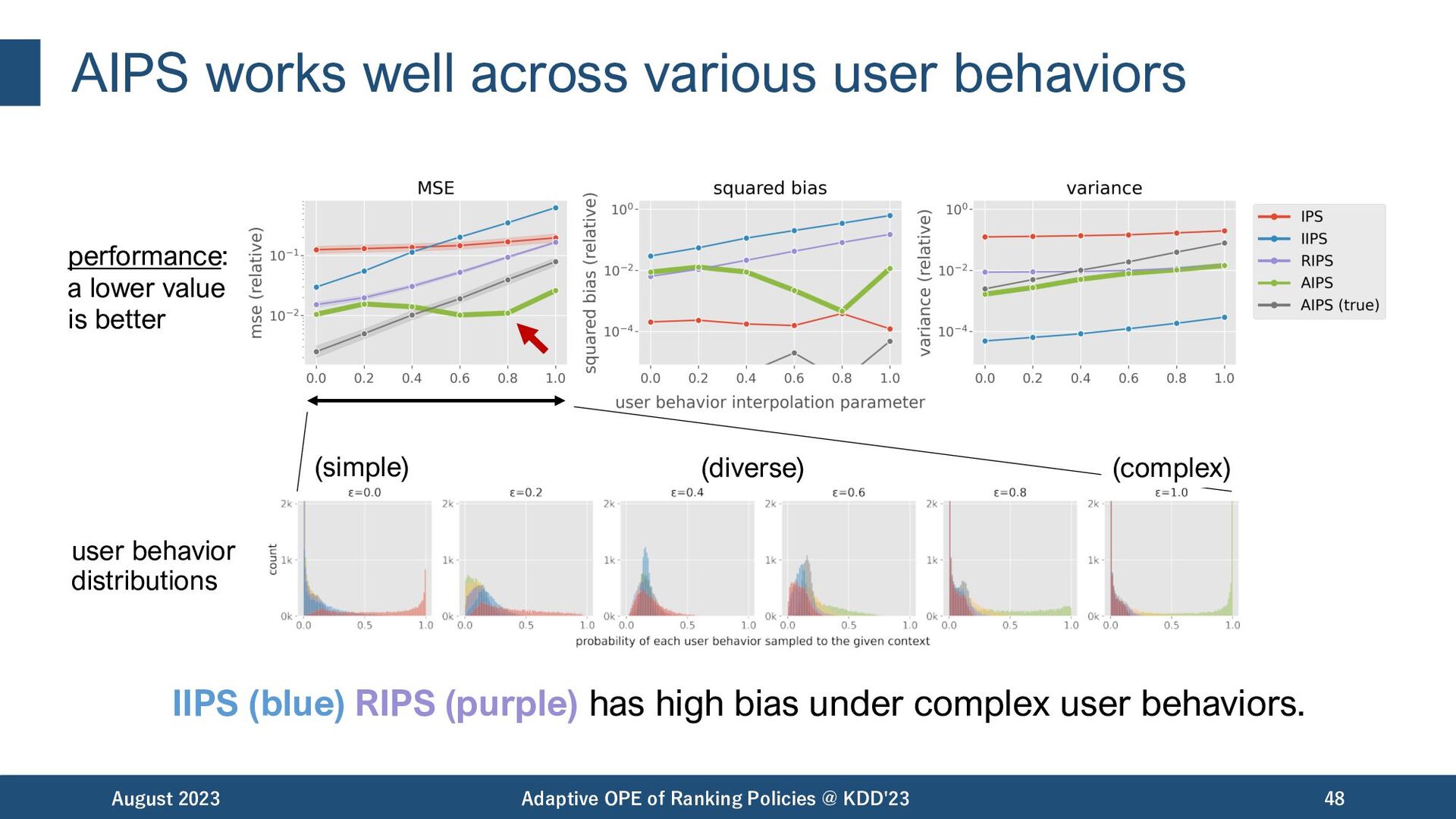
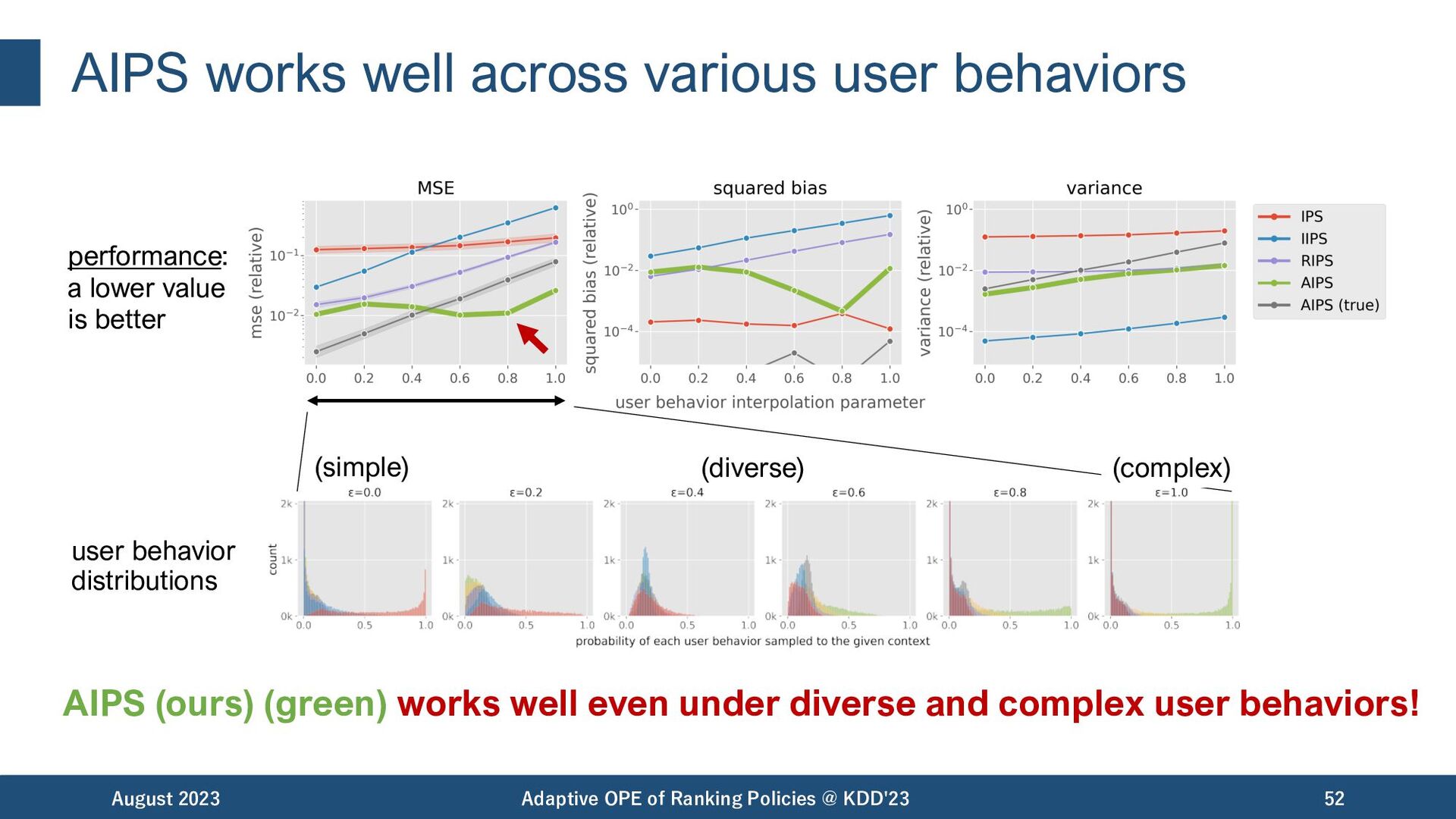
high variance across various user behaviors. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 47 performance: a lower value is better (simple) (diverse) (complex) user behavior distributions
(purple) has high bias under complex user behaviors. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 48 performance: a lower value is better (simple) (diverse) (complex) user behavior distributions
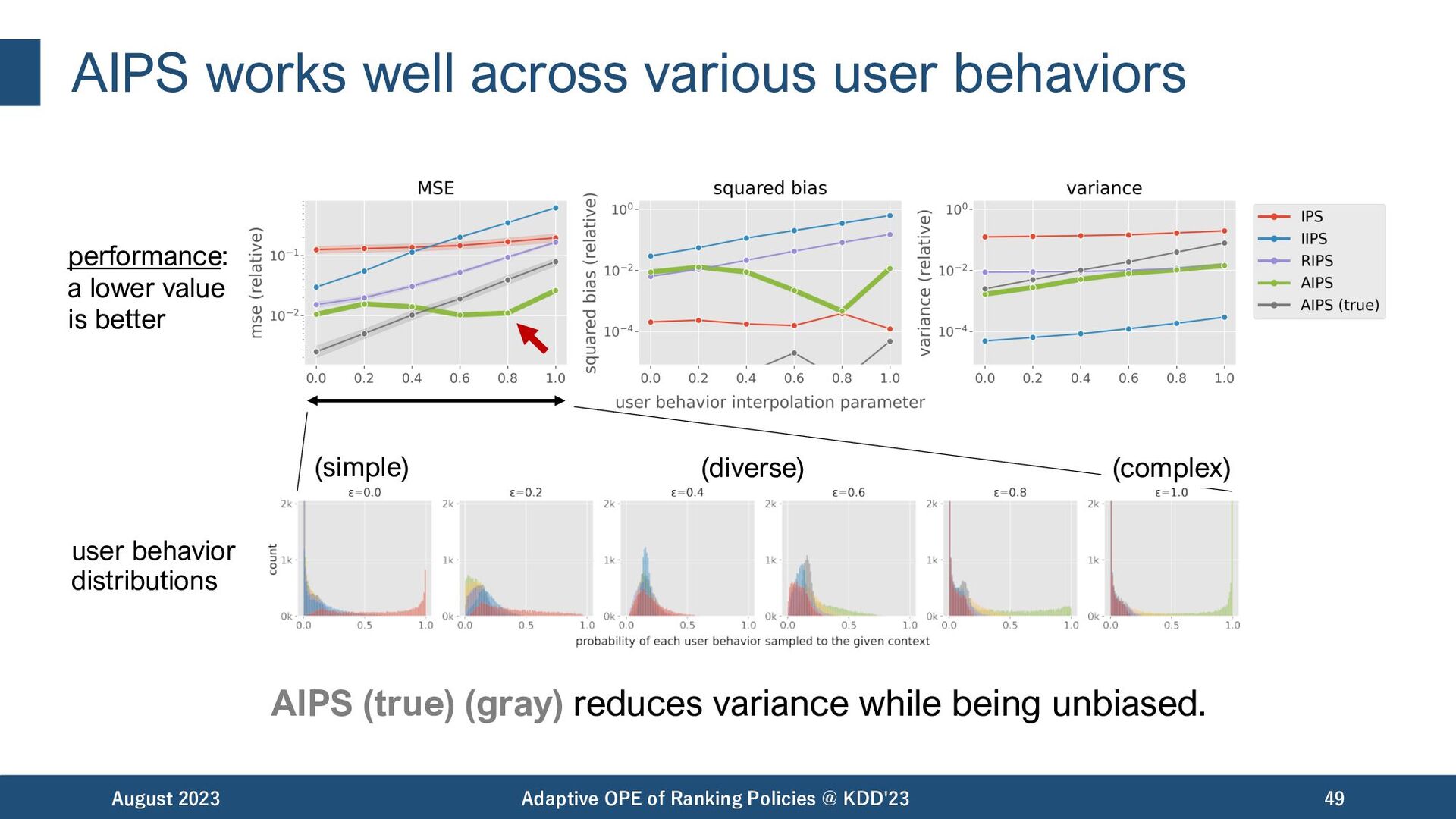
reduces variance while being unbiased. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 49 performance: a lower value is better (simple) (diverse) (complex) user behavior distributions
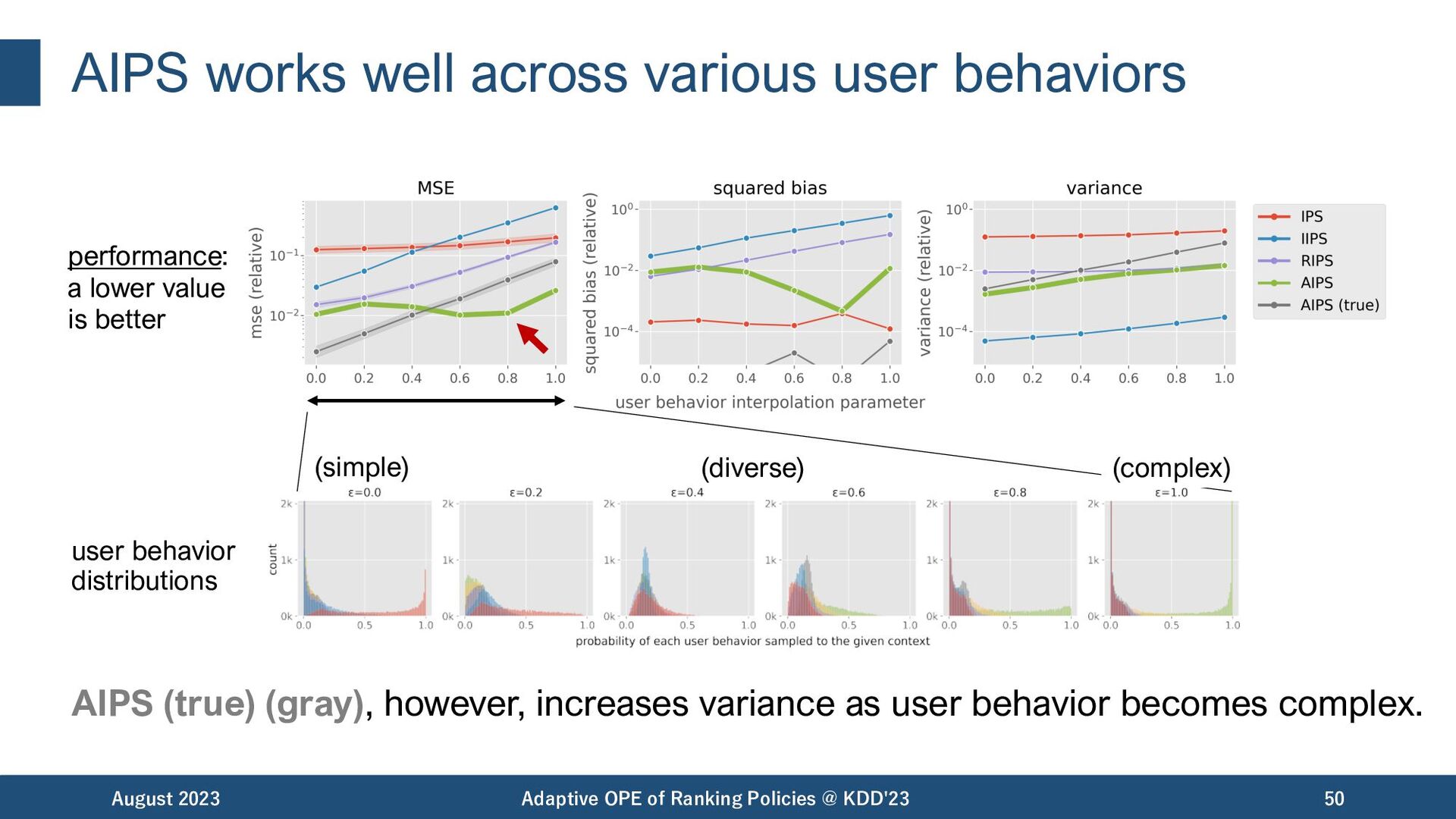
however, increases variance as user behavior becomes complex. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 50 performance: a lower value is better (simple) (diverse) (complex) user behavior distributions
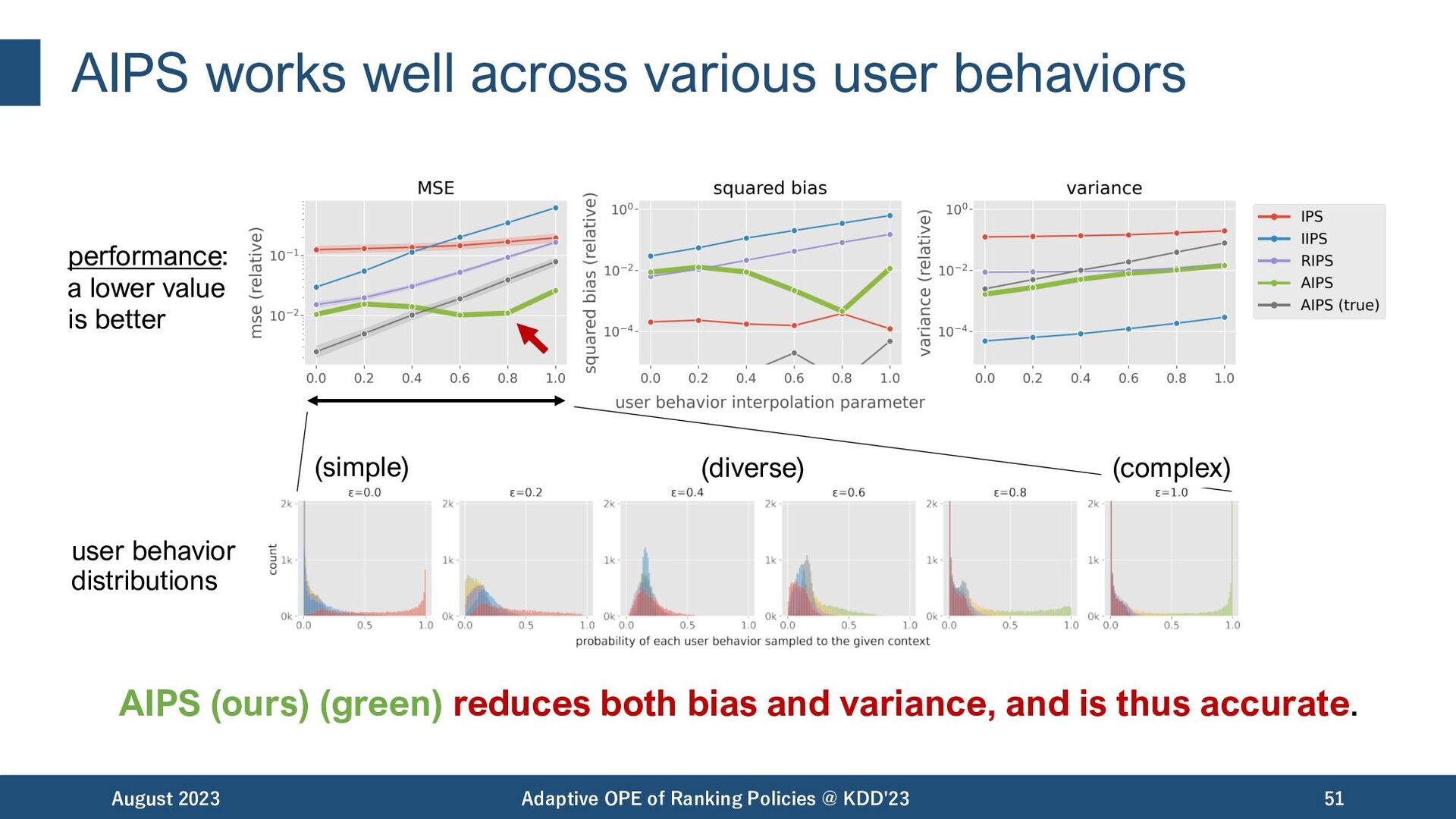
reduces both bias and variance, and is thus accurate. August 2023 Adaptive OPE of Ranking Policies @ KDD'23 51 performance: a lower value is better (simple) (diverse) (complex) user behavior distributions
works well even under diverse and complex user behaviors! August 2023 Adaptive OPE of Ranking Policies @ KDD'23 52 performance: a lower value is better (simple) (diverse) (complex) user behavior distributions
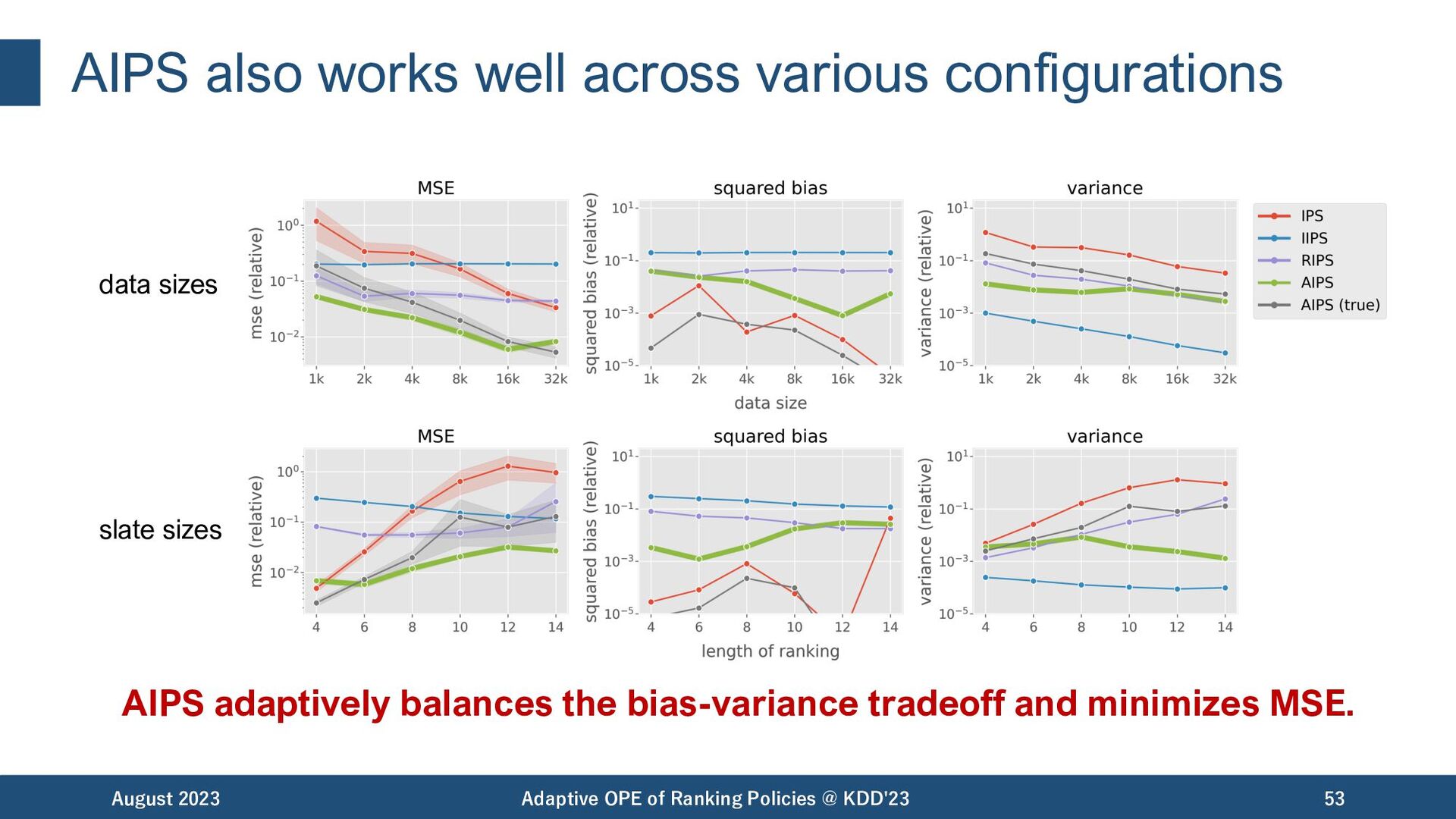
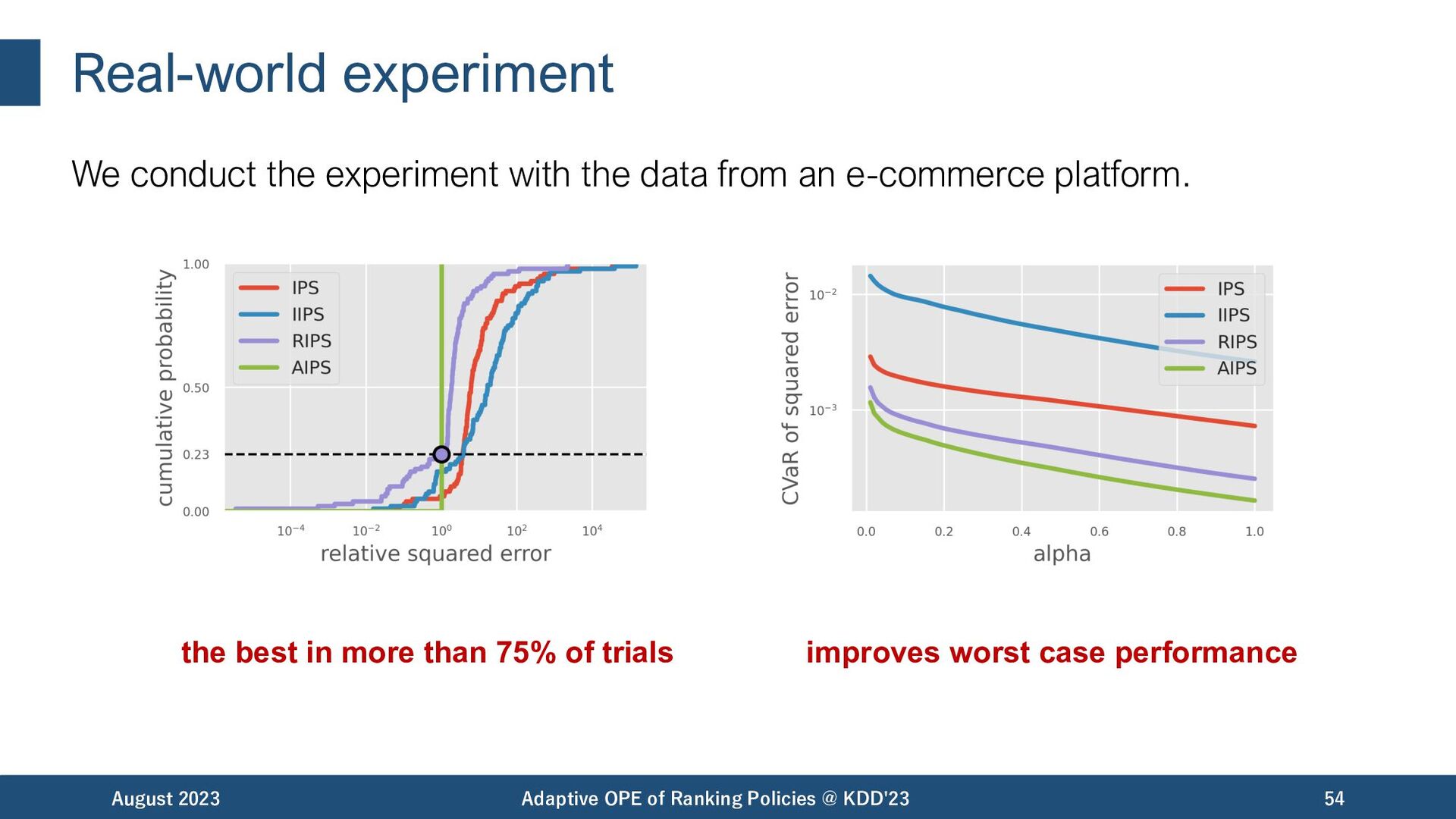
in OPE of ranking policies. • However, existing estimators apply a single user behavior, arising both excessive bias and variance in the presence of diverse user behaviors. • In response, we propose Adaptive IPS, which switches importance weight to minimize the estimation error depending on the user context. AIPS enables an accurate OPE estimation under diverse user behaviors! August 2023 Adaptive OPE of Ranking Policies @ KDD'23 55
Yusuke Narita. “Open Bandit Dataset and Pipeline: Towards Realistic and Reproducible Off-Policy Evaluation.” NeurIPS dataset&benchmark, 2021. https://arxiv.org/abs/2008.07146 [Li+,18] Shuai Li, Yasin Abbasi-Yadkori, Branislav Kveton, S. Muthukrishnan, Vishwa Vinay, and Zheng Wen. “Offline Evaluation of Ranking Policies with Click Models.” KDD, 2018. https://arxiv.org/abs/1804.10488 [McInerney+,20] James McInerney, Brian Brost, Praveen Chandar, Rishabh Mehrotra, and Ben Carterette. “Counterfactual Evaluation of Slate Recommendations with Sequential Reward Interactions.” KDD, 2020. https://arxiv.org/abs/2007.12986 [Strehl+,10] Alex Strehl, John Langford, Sham Kakade, and Lihong Li. “Learning from Logged Implicit Exploration Data.” NeurIPS, 2010. https://arxiv.org/abs/1003.0120 [Athey&Imbens,16] Susan Athey and Guido Imbens. “Recursive Partitioning for Heterogeneous Causal Effects.” PNAS, 2016. https://arxiv.org/abs/1504.01132 August 2023 Adaptive OPE of Ranking Policies @ KDD'23 58
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![De-facto approach: Inverse Propensity Scoring [Strehl+,10] August 2023 Adaptive OPE](https://files.speakerdeck.com/presentations/568c932c44c24785b1829b7eb7dd4233/slide_10.jpg){kind=link}
![De-facto approach: Inverse Propensity Scoring [Strehl+,10] August 2023 Adaptive OPE](https://files.speakerdeck.com/presentations/568c932c44c24785b1829b7eb7dd4233/slide_11.jpg){kind=link}
![De-facto approach: Inverse Propensity Scoring [Strehl+,10] August 2023 Adaptive OPE](https://files.speakerdeck.com/presentations/568c932c44c24785b1829b7eb7dd4233/slide_12.jpg){kind=link}
![De-facto approach: Inverse Propensity Scoring [Strehl+,10] August 2023 Adaptive OPE](https://files.speakerdeck.com/presentations/568c932c44c24785b1829b7eb7dd4233/slide_13.jpg){kind=link}
![De-facto approach: Inverse Propensity Scoring [Strehl+,10] August 2023 Adaptive OPE](https://files.speakerdeck.com/presentations/568c932c44c24785b1829b7eb7dd4233/slide_14.jpg){kind=link}
![De-facto approach: Inverse Propensity Scoring [Strehl+,10] August 2023 Adaptive OPE](https://files.speakerdeck.com/presentations/568c932c44c24785b1829b7eb7dd4233/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you for listening! contact: [email protected] August 2023 Adaptive OPE](https://files.speakerdeck.com/presentations/568c932c44c24785b1829b7eb7dd4233/slide_55.jpg){kind=link}
{kind=link}
![References (1/2) [Saito+,21] Yuta Saito, Shunsuke Aihara, Megumi Matsutani, and](https://files.speakerdeck.com/presentations/568c932c44c24785b1829b7eb7dd4233/slide_57.jpg){kind=link}
![References (2/2) [Kiyohara+,22] Haruka Kiyohara, Yuta Saito, Tatsuya Matsuhiro, Yusuke](https://files.speakerdeck.com/presentations/568c932c44c24785b1829b7eb7dd4233/slide_58.jpg){kind=link}