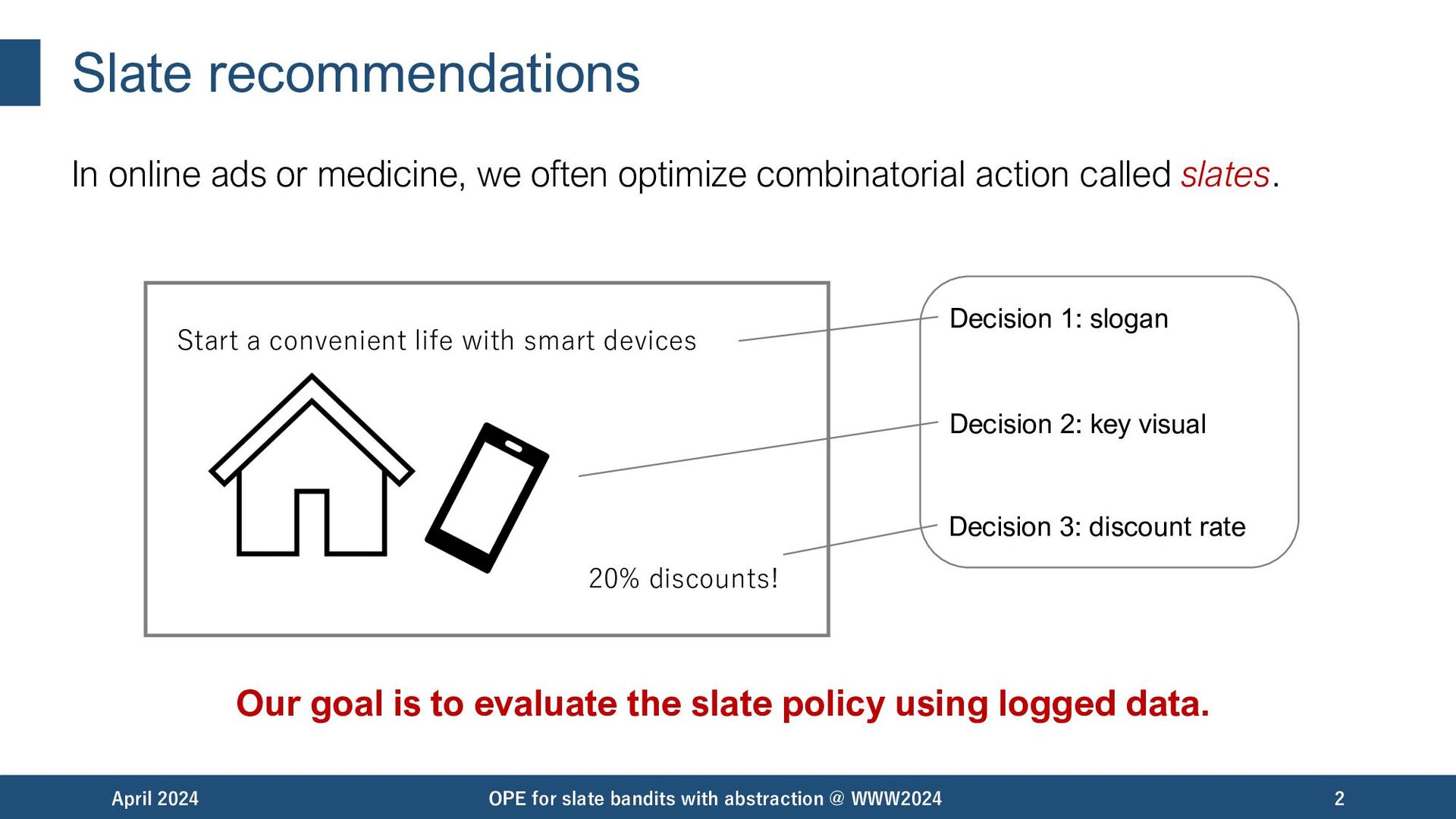
combinatorial action called slates. April 2024 OPE for slate bandits with abstraction @ WWW2024 2 Start a convenient life with smart devices 20% discounts! Decision 1: slogan Decision 2: key visual Decision 3: discount rate Our goal is to evaluate the slate policy using logged data.
• users’ demographic profile • slate 𝑠 = 𝑎1 , 𝑎2 , ⋯ , 𝑎𝐿 ∈ 𝑆 = ∑!∈[$] 𝐴𝑙 • slot action 𝑎𝑙 ∈ 𝐴𝑙 • e.g., in an email promotion, 𝐴1 can be a set of subject lines, 𝐴2 can be candidate visuals. • reward 𝑟 • click or purchase April 2024 OPE for slate bandits with abstraction @ WWW2024 3
• users’ demographic profile • slate 𝑠 = 𝑎1 , 𝑎2 , ⋯ , 𝑎𝐿 ∈ 𝑆 = ∑!∈[$] 𝐴𝑙 • slot action 𝑎𝑙 ∈ 𝐴𝑙 • e.g., in an email promotion, 𝐴1 can be a set of subject lines, 𝐴2 can be candidate visuals. • reward 𝑟 • click or purchase April 2024 OPE for slate bandits with abstraction @ WWW2024 4 The goal of Off-Policy Evaluation (OPE) is to accurately estimate the policy value: , using the logged data collected by a logging policy 𝜋0 .
is different, we need to address distribution shift. April 2024 OPE for slate bandits with abstraction @ WWW2024 5 evaluation logging ranking A ranking B more less less more
is different, we need to address distribution shift. April 2024 OPE for slate bandits with abstraction @ WWW2024 6 evaluation logging ranking A ranking B more less less more ・unbiased
is different, we need to address distribution shift. April 2024 OPE for slate bandits with abstraction @ WWW2024 7 evaluation logging ranking A more less ・unbiased ・variance
variance issue, PI considers the following linearity assumption. April 2024 OPE for slate bandits with abstraction @ WWW2024 8 expected reward of an email = value of title + value of coupon + value of visual + …
variance issue, PI considers the following linearity assumption. Then, PI estimates the policy value as follows. April 2024 OPE for slate bandits with abstraction @ WWW2024 9 importance weight (iw) is no longer the product but is instead the sum of slot-wise iw.
no assumption • (pros) unbiased without any assumption on the reward • (cons) extremely high variance (due to large action space) • PseudoInverse (PI) • linearity assumption • (pros) reduces variance compared to IPS • (cons) induces bias when the linearity does not hold Can we reduce the variance of IPS while not using a restrictive assumption? April 2024 OPE for slate bandits with abstraction @ WWW2024 10
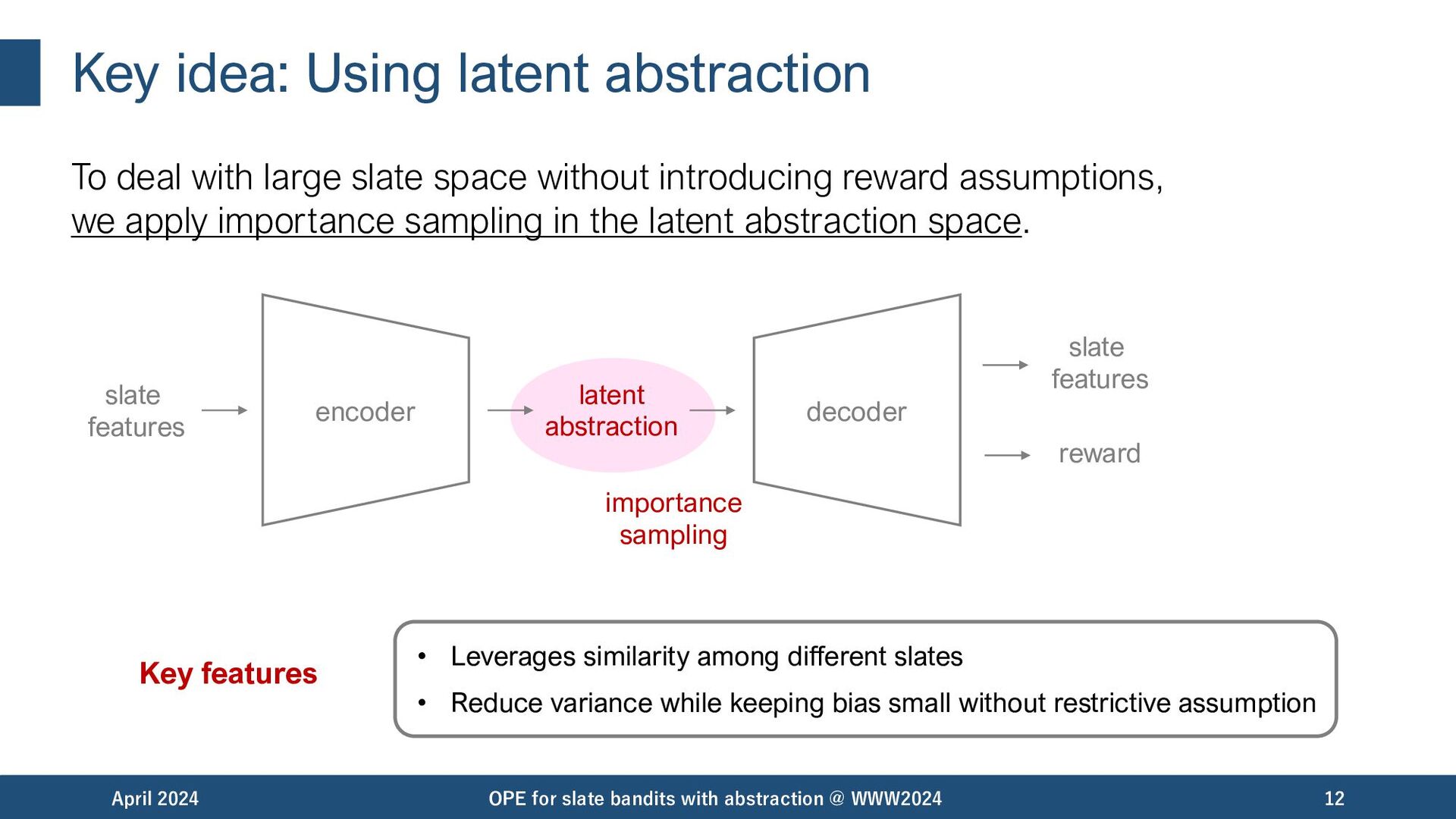
space without introducing reward assumptions, we apply importance sampling in the latent abstraction space. April 2024 OPE for slate bandits with abstraction @ WWW2024 12 • Leverages similarity among different slates • Reduce variance while keeping bias small without restrictive assumption Key features encoder decoder slate features slate features reward latent abstraction importance sampling
𝜙: 𝑆 ⟶ 𝑍 , we difine Latent IPS as follows. Generalizing this to context-dependent and stochastic clustering, we also have, April 2024 OPE for slate bandits with abstraction @ WWW2024 14 importance weight on the latent abstraction
the following condition of the sufficient slate abstraction. (Sufficient slate abstraction) A slate abstraction function 𝜙𝜃 is said to be “sufficient” if it satisfies 𝑞 𝑥, 𝑠 = 𝑞(𝑥, 𝑠′), for all 𝑥 ∈ 𝑋, 𝑠 ∈ 𝑆, and 𝑠' ∈ 𝑠'' ∈ 𝑆 𝜙𝜃 𝑠 = 𝜙𝜃 (𝑠′′)} (e.g., one-hot embedding of the original slate is a saficient slate abstraction) April 2024 OPE for slate bandits with abstraction @ WWW2024 15
does not hold, the bias of LIPS is derived as follows. April 2024 OPE for slate bandits with abstraction @ WWW2024 17 ① ② ③ ① identifiability of the slates from their abstractions ② difference in the expected rewards between a pair of slates ③ difference in the slate-wise importance weights between a pair of slates Bias can be small with a fine-grained abstraction.
variance reduction compared to naive IPS. Given a slate abstraction function 𝜙𝜃 , April 2024 OPE for slate bandits with abstraction @ WWW2024 18 ① ② ① variance of reward conditioned by the slate abstraction ② variance of slate-wise iw regarding the conditional distribution 𝜋0 (𝑠|𝑥, 𝜙𝜃(𝑠)) Variance can be small with a coarse-grained abstraction.
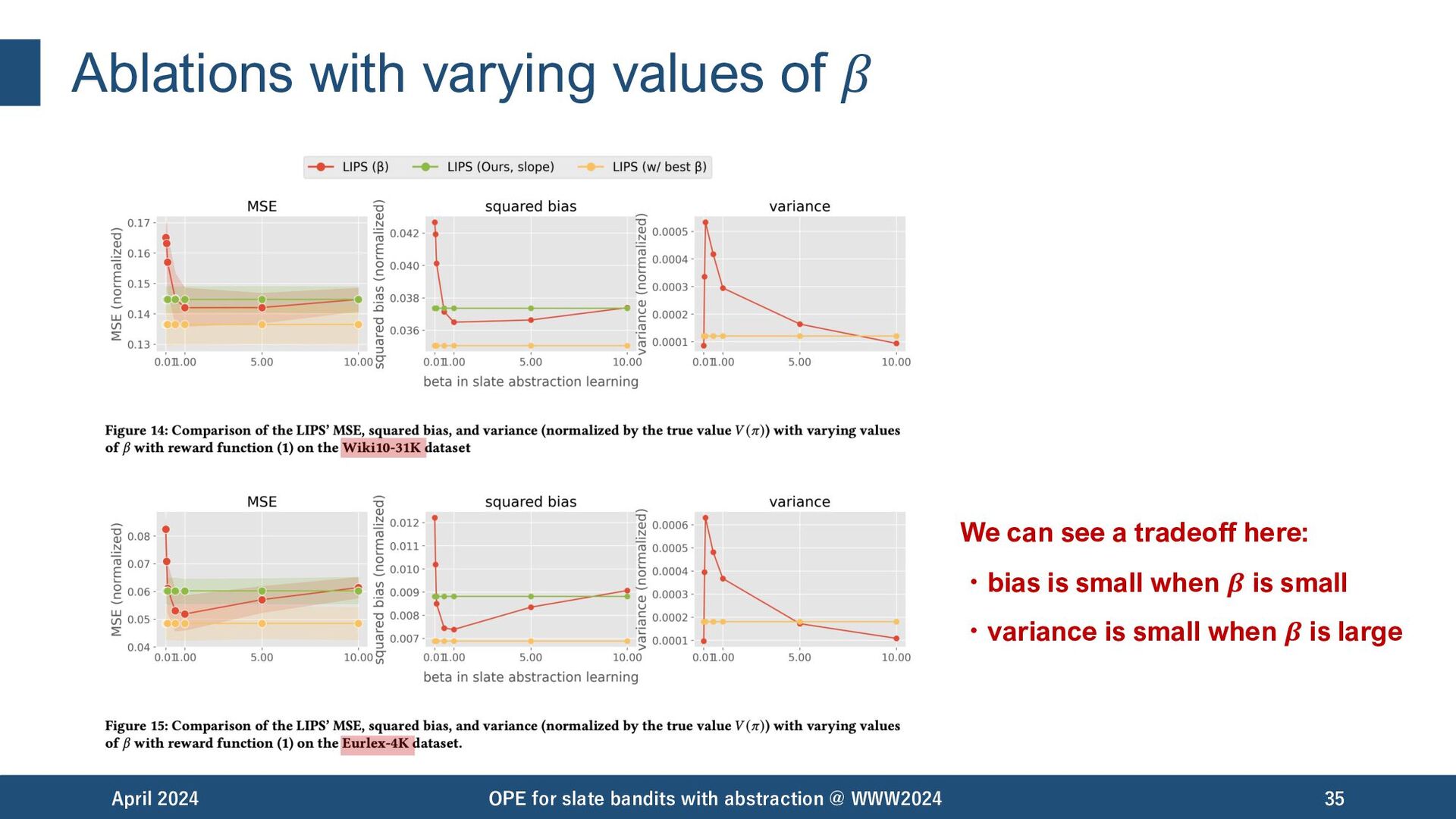
for the bias-variance tradeoff. April 2024 OPE for slate bandits with abstraction @ WWW2024 19 coarse-grained abstraction fine-grained abstraction bias variance
for the bias-variance tradeoff. Thus, we can minimize the mean-squared error (MSE) by optimizing the abstraction: April 2024 OPE for slate bandits with abstraction @ WWW2024 20 coarse-grained abstraction fine-grained abstraction bias variance
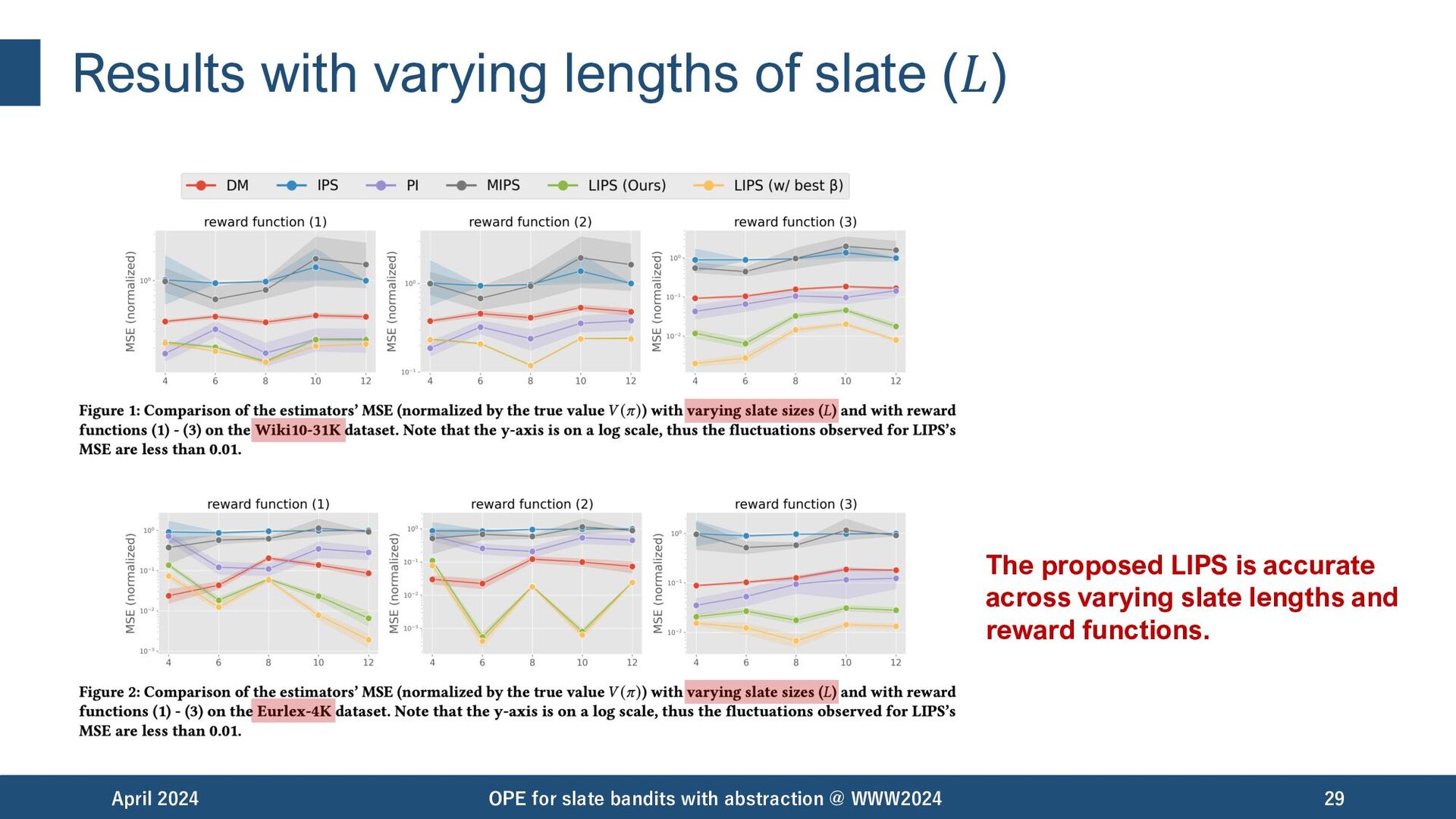
across the varying configurations. • data sizes (𝑛): {1000, 2000, 4000, 8000, 16000} • lengths of slate (𝐿): {4, 6, 8, 10, 12} April 2024 OPE for slate bandits with abstraction @ WWW2024 27 (estimated by logged data generated with 50 different random seeds) value: default value
involves combinatorial actions. • Baseline estimators suffer either from variance caused by large action space or bias caused by a restrictive assumption of linearity. • We proposed to apply importance weight on latent abstraction space, with a way to learn an abstraction that reduces both bias and variance. • Semi-synthetic experiments demonstrates that the proposed LIPS performs well across various data sizes and lengths of slate. April 2024 OPE for slate bandits with abstraction @ WWW2024 30
importance sampling and regression. April 2024 OPE for slate bandits with abstraction @ WWW2024 32 control variate [Dudík+,14] [Vlassis+,21] [Saito+,23]
Li. “Learning from Logged Implicit Exploration Data.” NeurIPS, 2010. https://arxiv.org/abs/1003.0120 [Swamminathan+,17] Adith Swaminathan, Akshay Krishnamurthy, Alekh Agarwal, Miroslav Dudík, John Langford, Damien Jose, Imed Zitouni. “Off-policy evaluation for slate recommendation.” NeurIPS, 2017. https://arxiv.org/abs/1605.04812 [Beygelzimer&Langford,09] Alina Beygelzimer, John Langford. “The Offset Tree for Learning with Partial Labels.” KDD, 2009. https://arxiv.org/abs/0812.4044 [Saito&Joachims,22] Yuta Saito, Thorsten Joachims. “Off-Policy Evaluation for Large Action Spaces via Embeddings.” ICML, 2022. https://arxiv.org/abs/2202.06317 [Dudík+,14] Miroslav Dudík, Dumitru Erhan, John Langford, and Lihong Li. “Doubly Robust Policy Evaluation and Optimization.” ICML, 2011. https://arxiv.org/abs/1503.02834 April 2024 OPE for slate bandits with abstraction @ WWW2024 37
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Distribution shift and importance sampling [Strehl+,10] Because 𝜋0 and 𝜋](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_4.jpg){kind=link}
![Distribution shift and importance sampling [Strehl+,10] Because 𝜋0 and 𝜋](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_5.jpg){kind=link}
![Distribution shift and importance sampling [Strehl+,10] Because 𝜋0 and 𝜋](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_6.jpg){kind=link}
![Linearity assum. and PseudoInverse (PI) [Swamminathan+,17] To deal with the](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_7.jpg){kind=link}
![Linearity assum. and PseudoInverse (PI) [Swamminathan+,17] To deal with the](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References (1/2) [Strehl+,10] Alex Strehl, John Langford, Sham Kakade, Lihong](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_36.jpg){kind=link}
![References (2/2) [Vlassis+,21] Nikos Vlassis, Ashok Chandrashekar, Fernando Amat Gil,](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_37.jpg){kind=link}