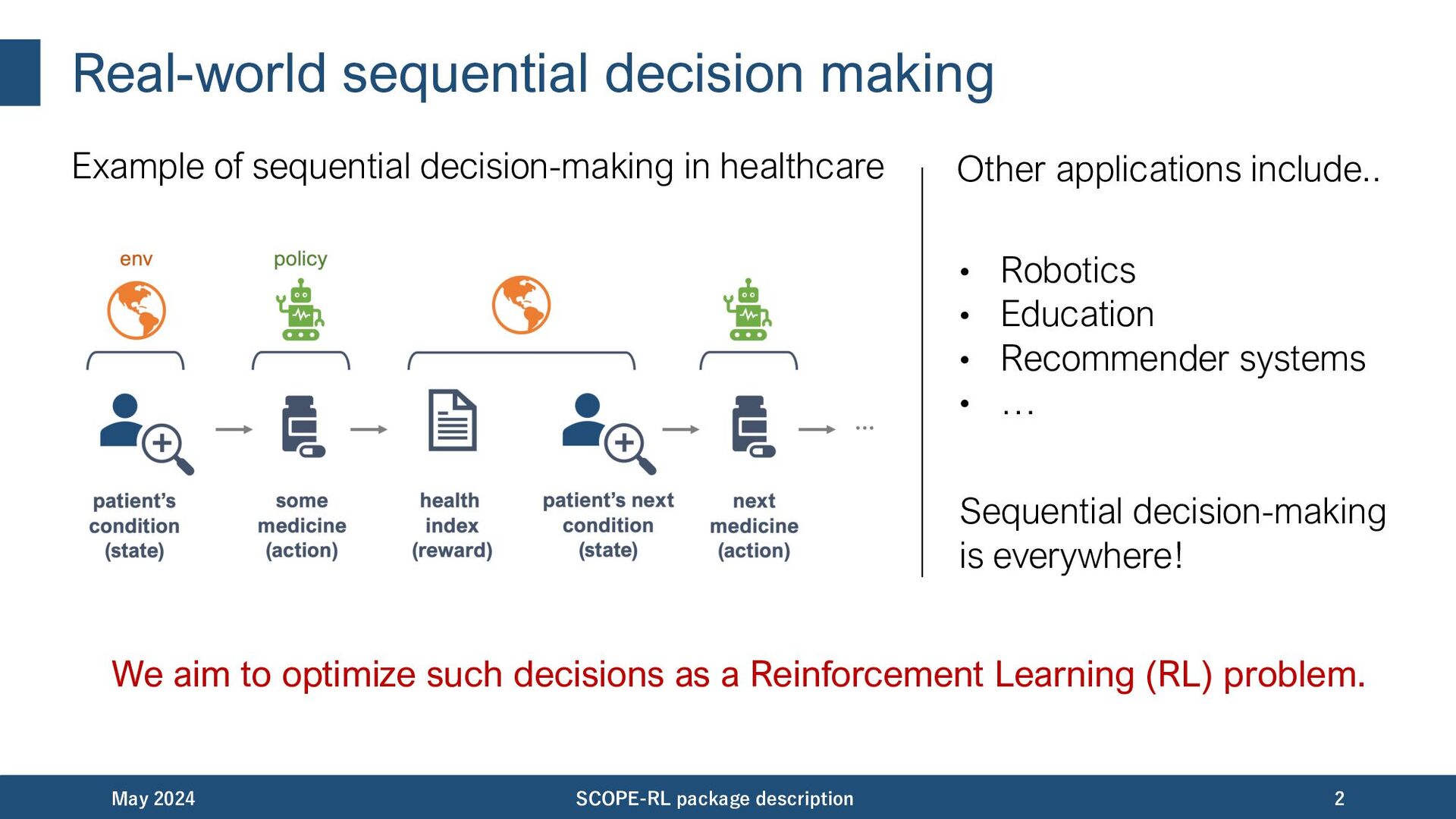
We aim to optimize such decisions as a Reinforcement Learning (RL) problem. May 2024 SCOPE-RL package description 2 Other applications include.. • Robotics • Education • Recommender systems • … Sequential decision-making is everywhere!
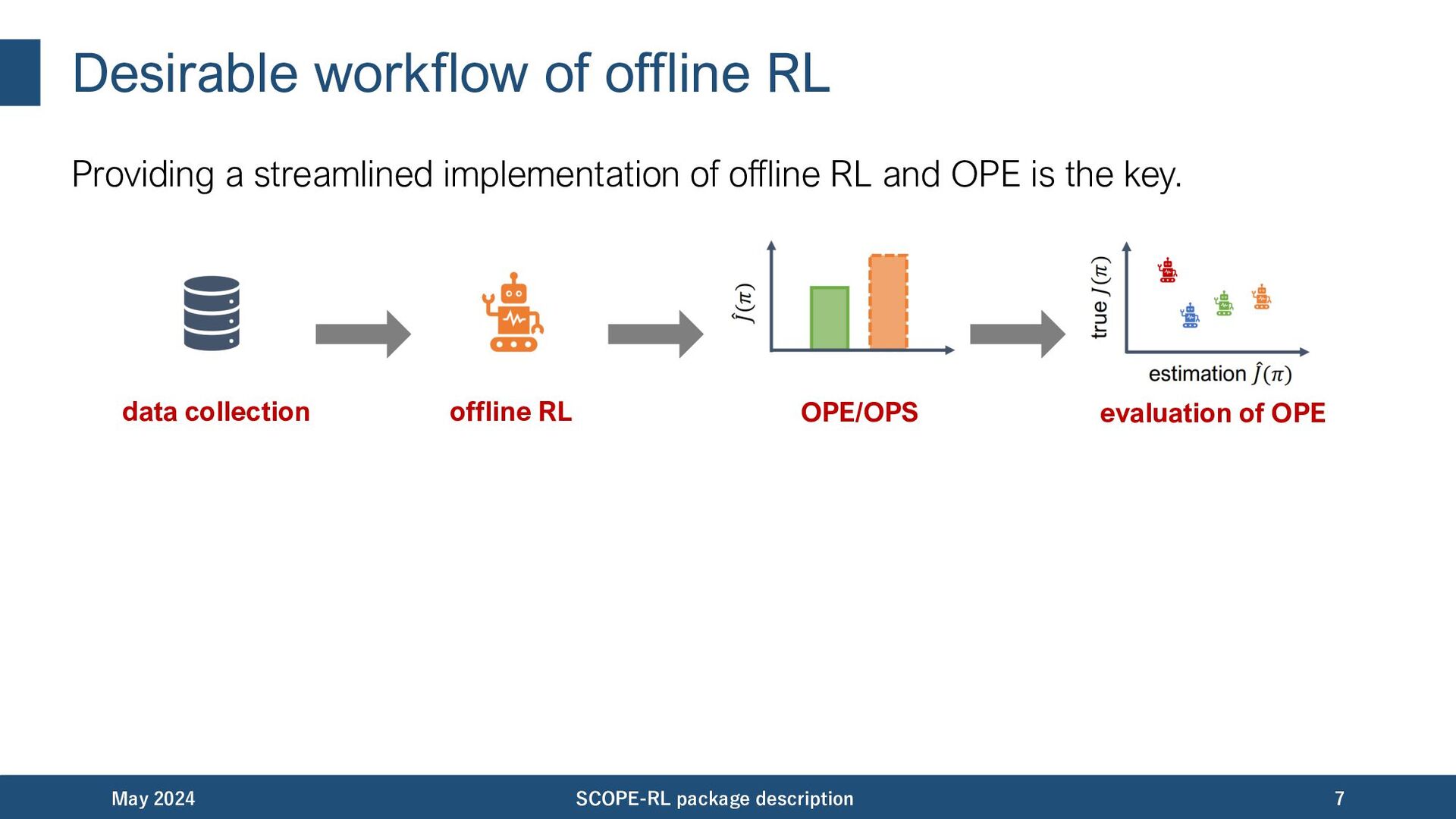
• learns a policy through interaction • may harm the real system with bad action choices • Offline RL – • learns and evaluate a policy solely from offline data • can be a safe alternative for online RL May 2024 SCOPE-RL package description 3 We talk about a library for offline RL and policy evaluation.
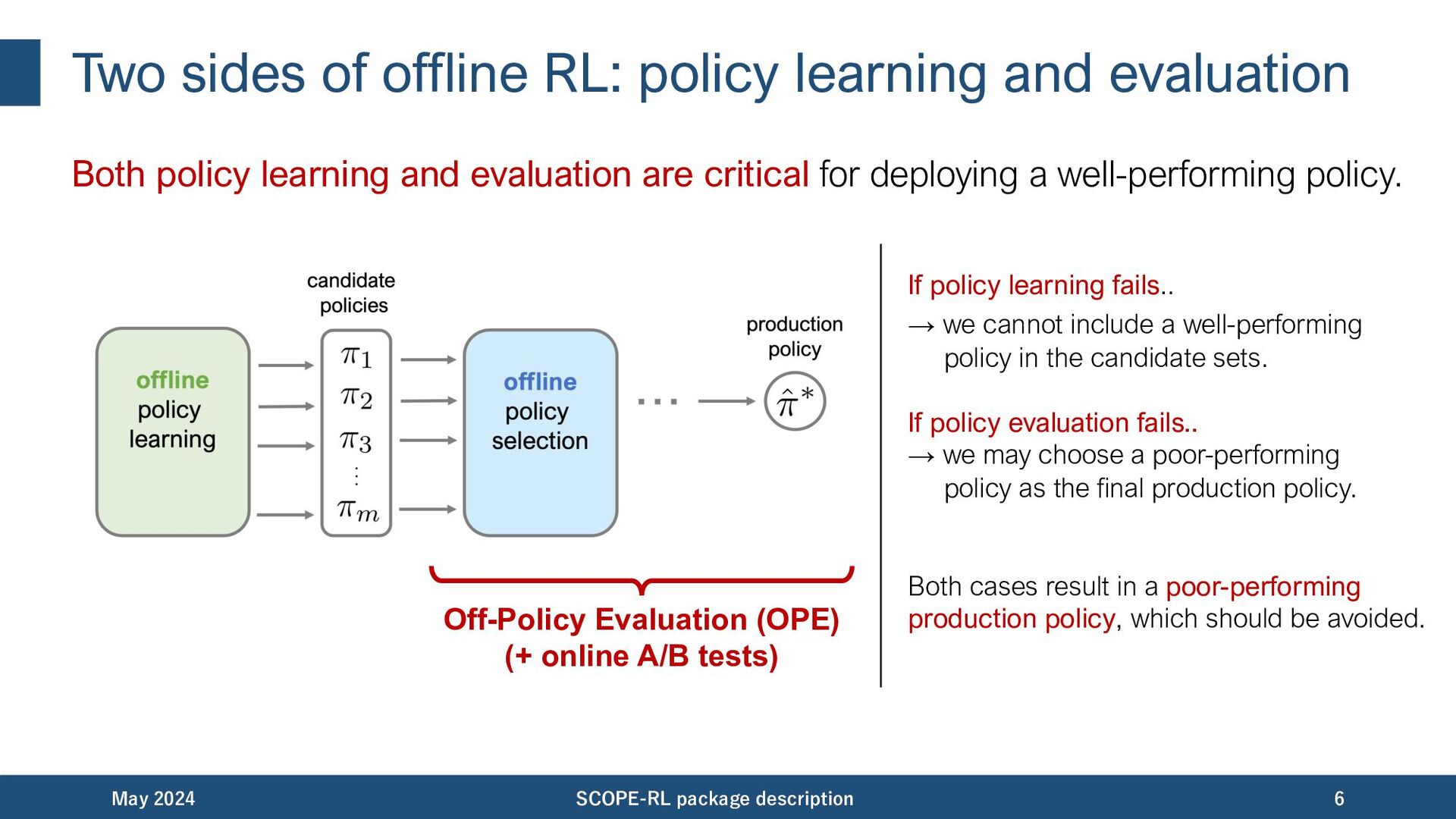
policy learning and evaluation are critical for deploying a well-performing policy. May 2024 SCOPE-RL package description 6 Off-Policy Evaluation (OPE) (+ online A/B tests) If policy learning fails.. → we cannot include a well-performing policy in the candidate sets. If policy evaluation fails.. → we may choose a poor-performing policy as the final production policy. Both cases result in a poor-performing production policy, which should be avoided.
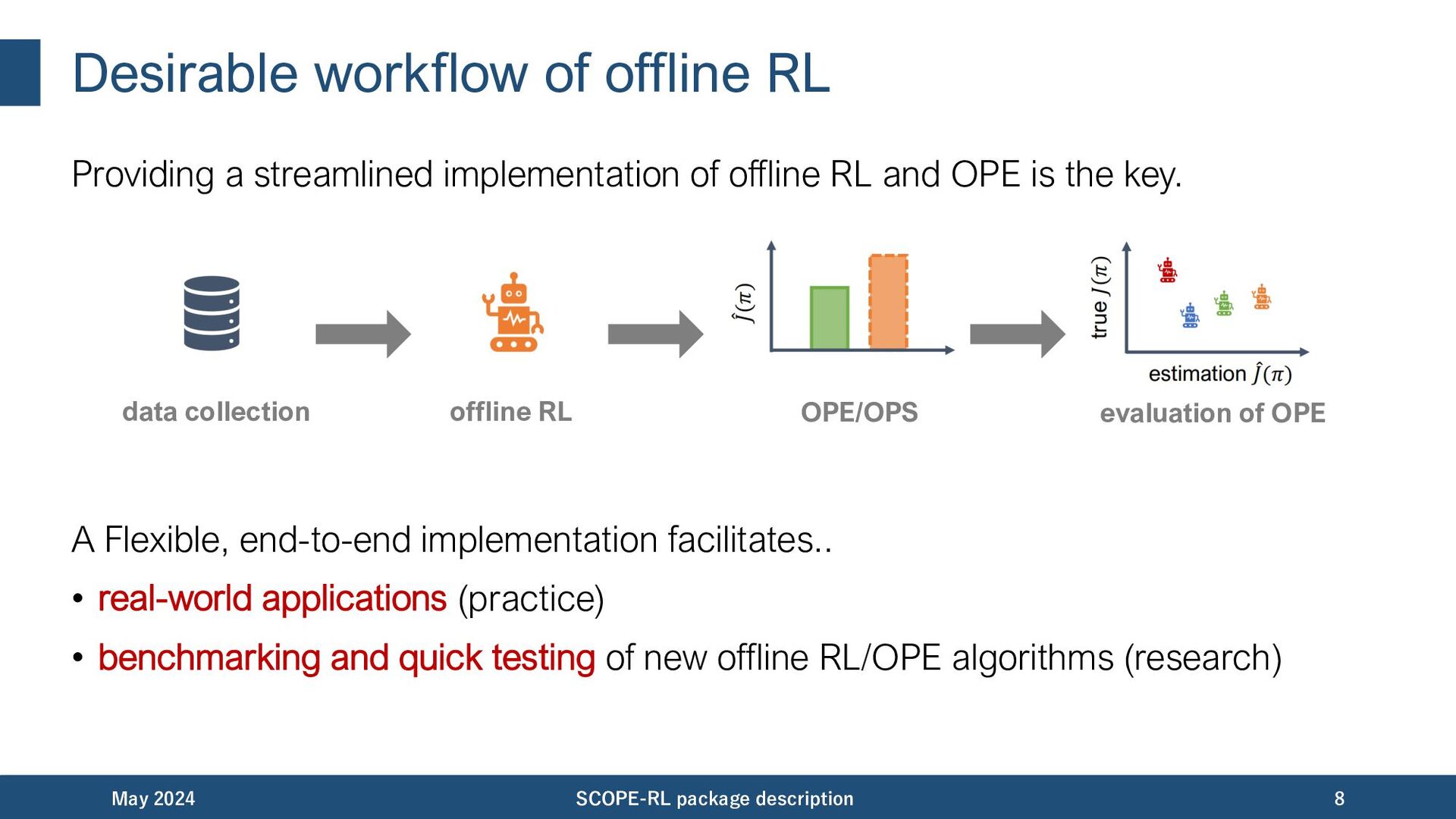
offline RL and OPE is the key. A Flexible, end-to-end implementation facilitates.. • real-world applications (practice) • benchmarking and quick testing of new offline RL/OPE algorithms (research) May 2024 SCOPE-RL package description 8 data collection offline RL OPE/OPS evaluation of OPE
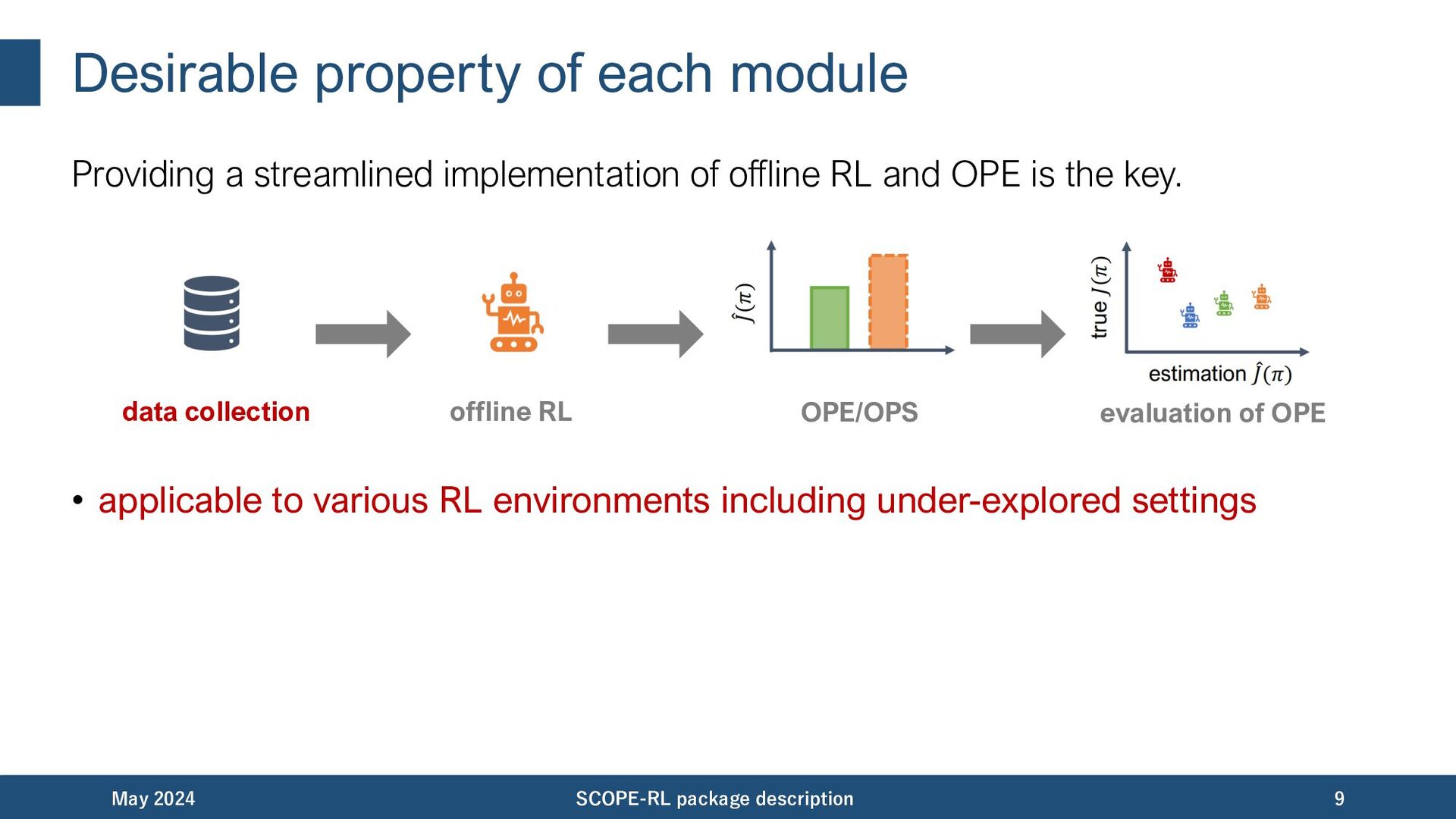
offline RL and OPE is the key. • applicable to various RL environments including under-explored settings May 2024 SCOPE-RL package description 9 data collection offline RL OPE/OPS evaluation of OPE
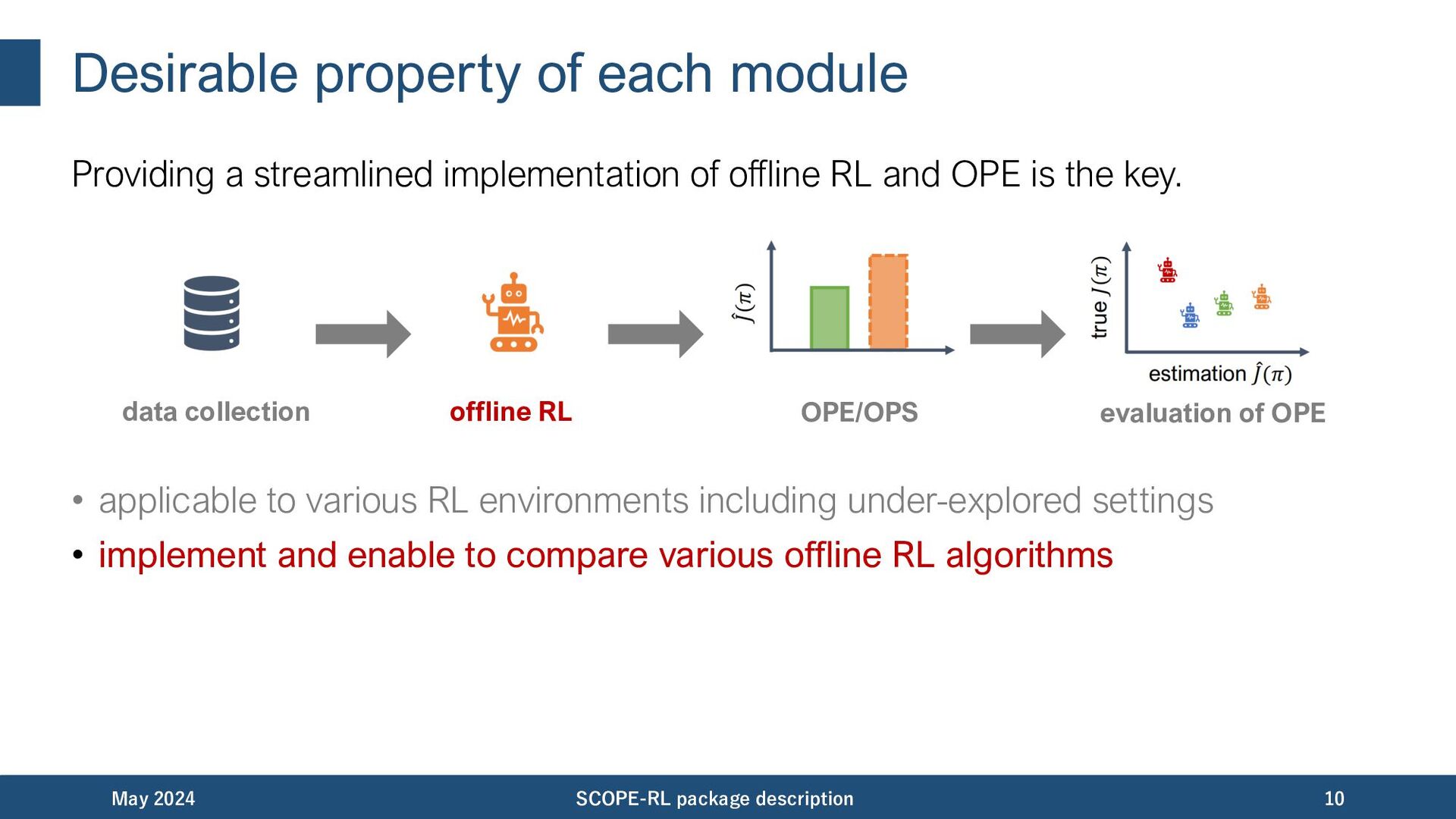
offline RL and OPE is the key. • applicable to various RL environments including under-explored settings • implement and enable to compare various offline RL algorithms May 2024 SCOPE-RL package description 10 data collection offline RL OPE/OPS evaluation of OPE
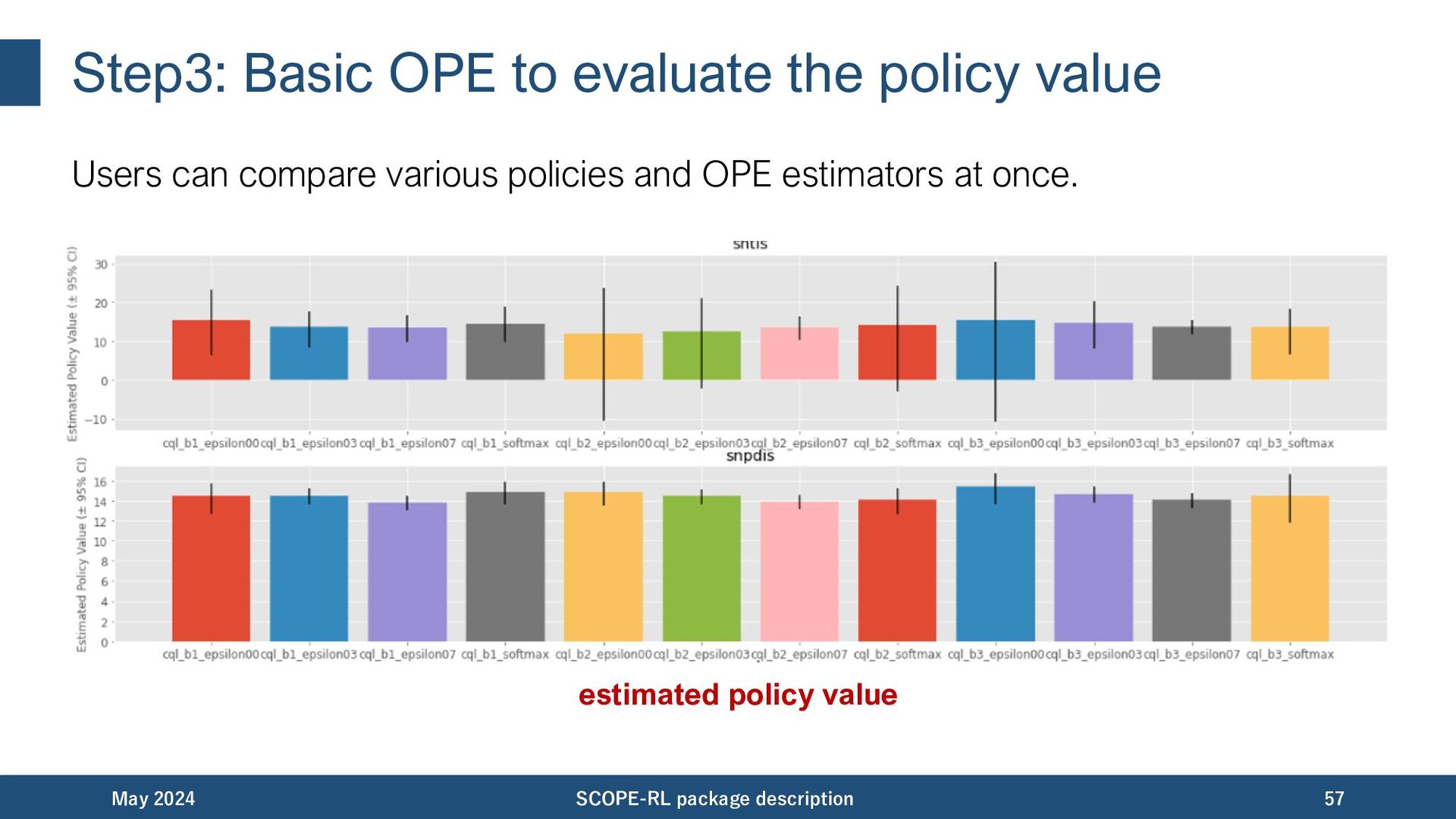
offline RL and OPE is the key. • applicable to various RL environments including under-explored settings • implement and enable to compare various offline RL algorithms • able to evaluate various policies with various OPE estimators May 2024 SCOPE-RL package description 11 data collection offline RL OPE/OPS evaluation of OPE
offline RL and OPE is the key. • applicable to various RL environments including under-explored settings • implement and enable to compare various offline RL algorithms • able to evaluate various policies with various OPE estimators • validate the reliability of OPE and downstream policy selection methods May 2024 SCOPE-RL package description 12 data collection offline RL OPE/OPS evaluation of OPE
a streamlined implementation of offline RL and OPE is the key. May 2024 SCOPE-RL package description 13 data collection offline RL OPE/OPS evaluation of OPE Unfortunately, most of the existing platforms / benchmark suites are insufficient to enable an end-to-end implementation..
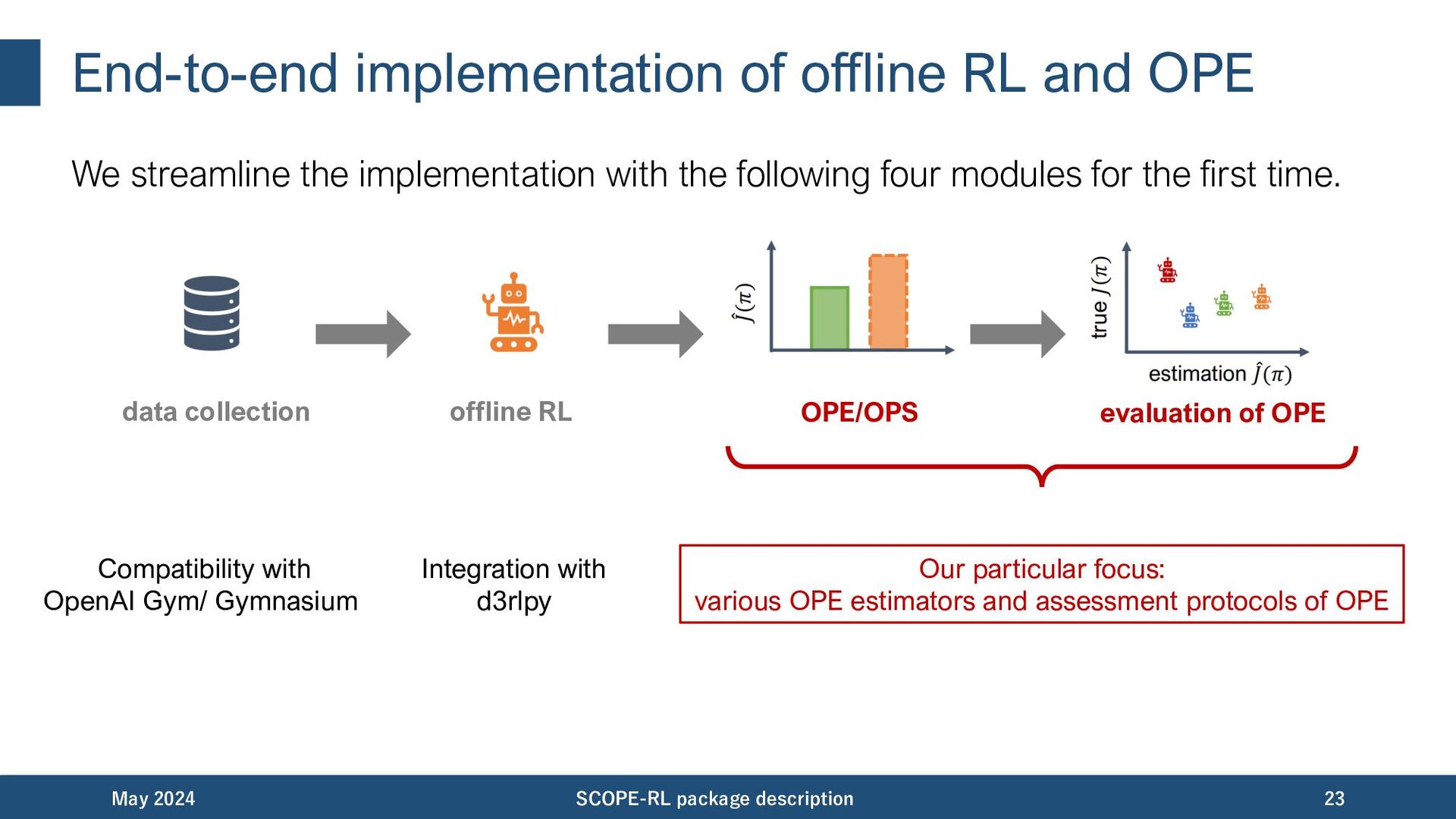
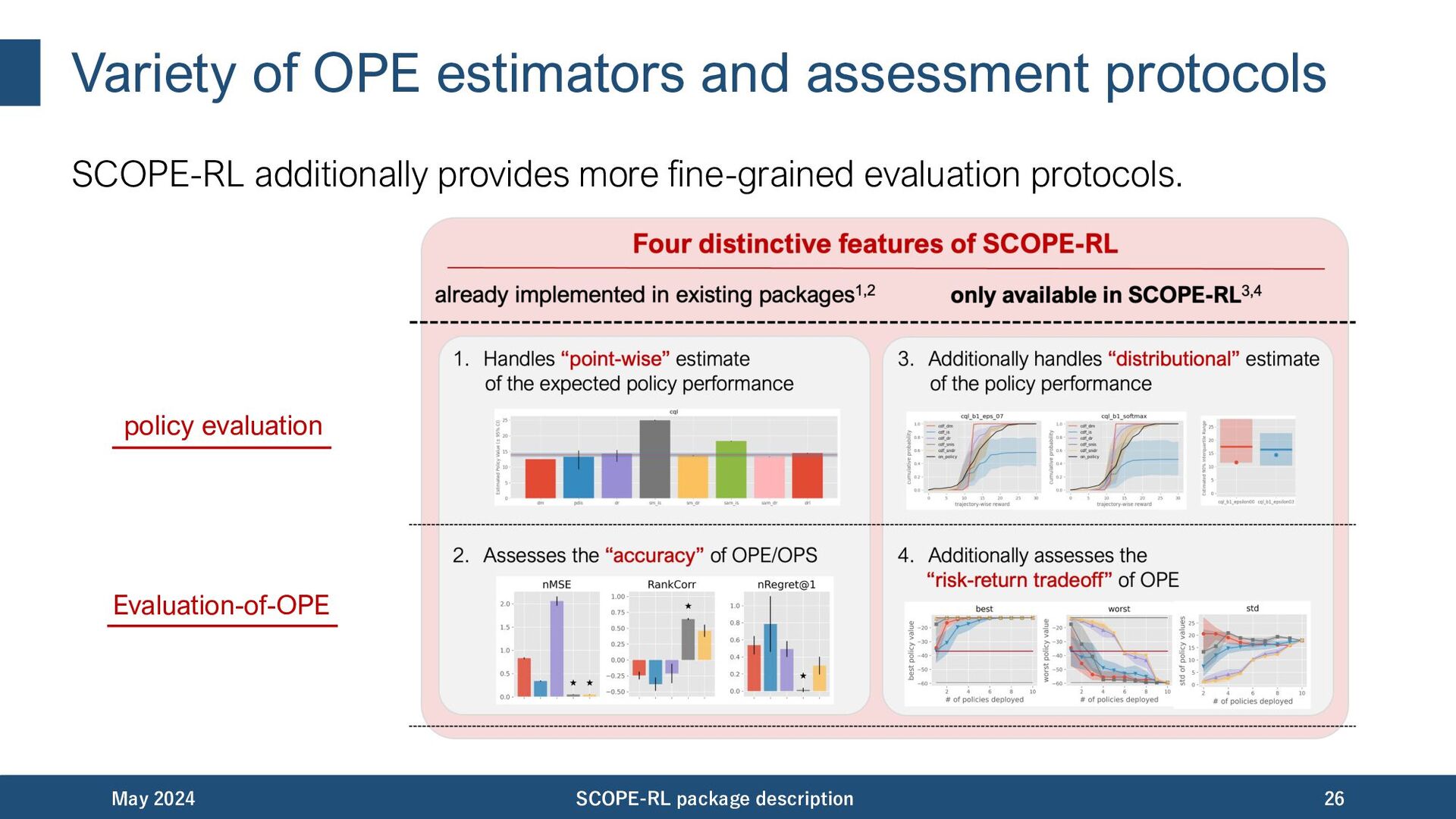
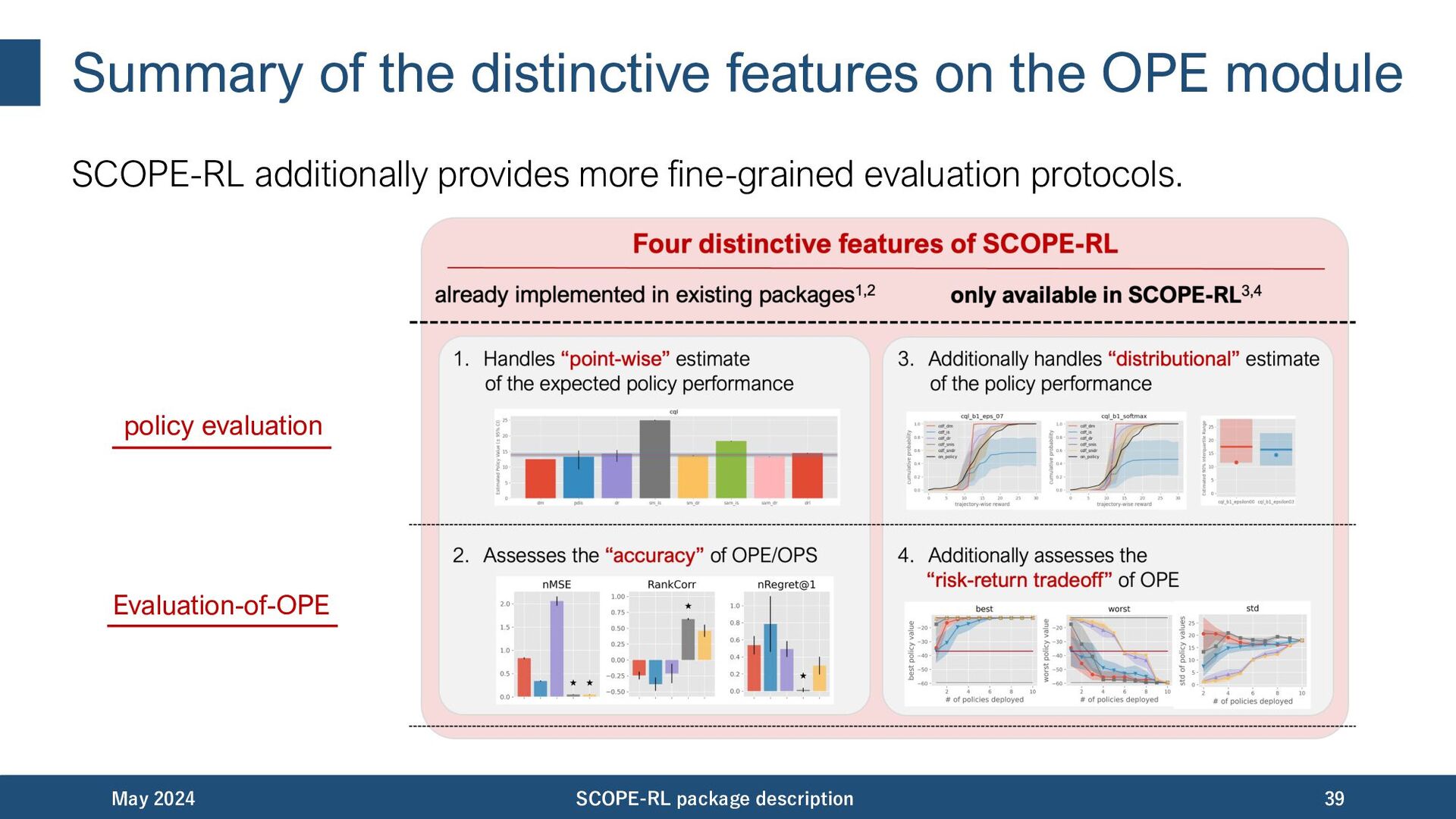
discuss each features one by one: • End-to-end implementation of offline RL and OPE • Variety of OPE estimators and assessment protocols • Cumulative distribution OPE for risk function estimation • Risk-return assessments of OPE and the downstream policy selection • User friendly APIs, visualization tools, and documentation May 2024 SCOPE-RL package description 22
implementation with the following four modules for the first time. May 2024 SCOPE-RL package description 23 data collection offline RL OPE/OPS evaluation of OPE Compatibility with OpenAI Gym/ Gymnasium Integration with d3rlpy Our particular focus: various OPE estimators and assessment protocols of OPE
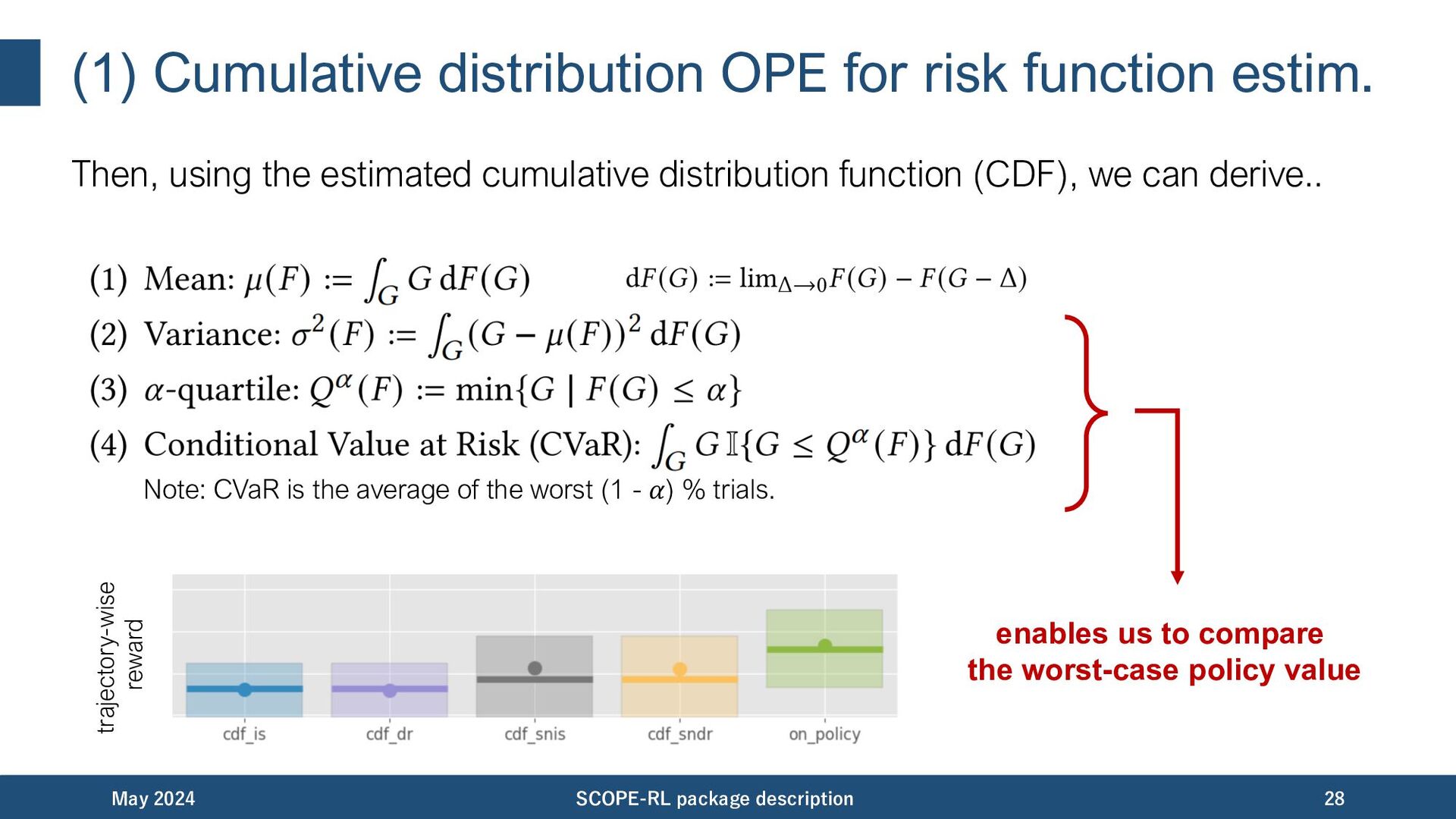
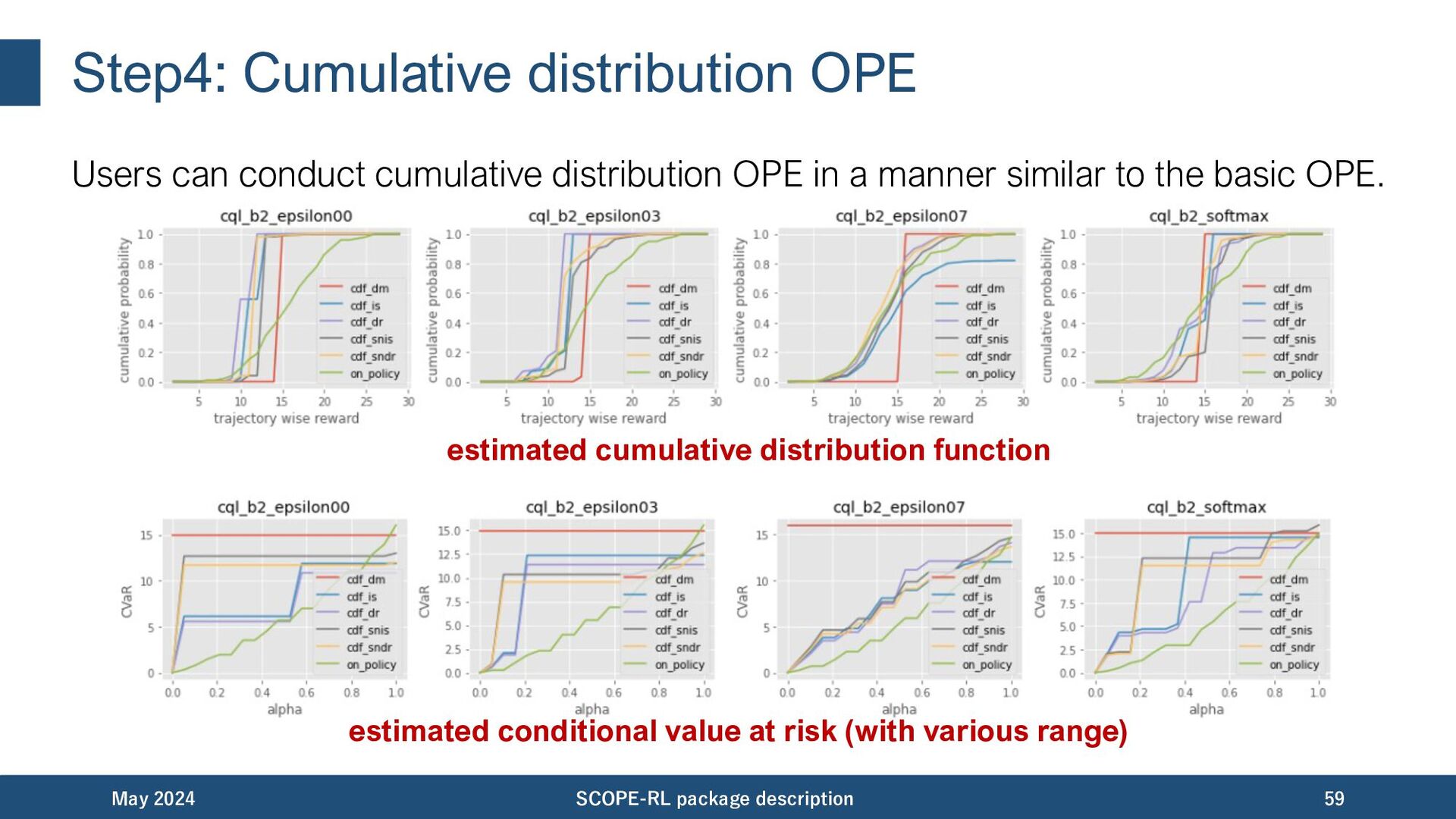
the estimated cumulative distribution function (CDF), we can derive.. May 2024 SCOPE-RL package description 28 enables us to compare the worst-case policy value trajectory-wise reward Note: CVaR is the average of the worst (1 - 𝛼) % trials.
will move on to the assessment of OPE. • applicable to various RL environments including under-explored settings • implement and enable to compare various offline RL algorithms • able to evaluate various policies with various OPE estimators • validate the reliability of OPE and downstream policy selection methods May 2024 SCOPE-RL package description 29 data collection offline RL OPE/OPS evaluation of OPE
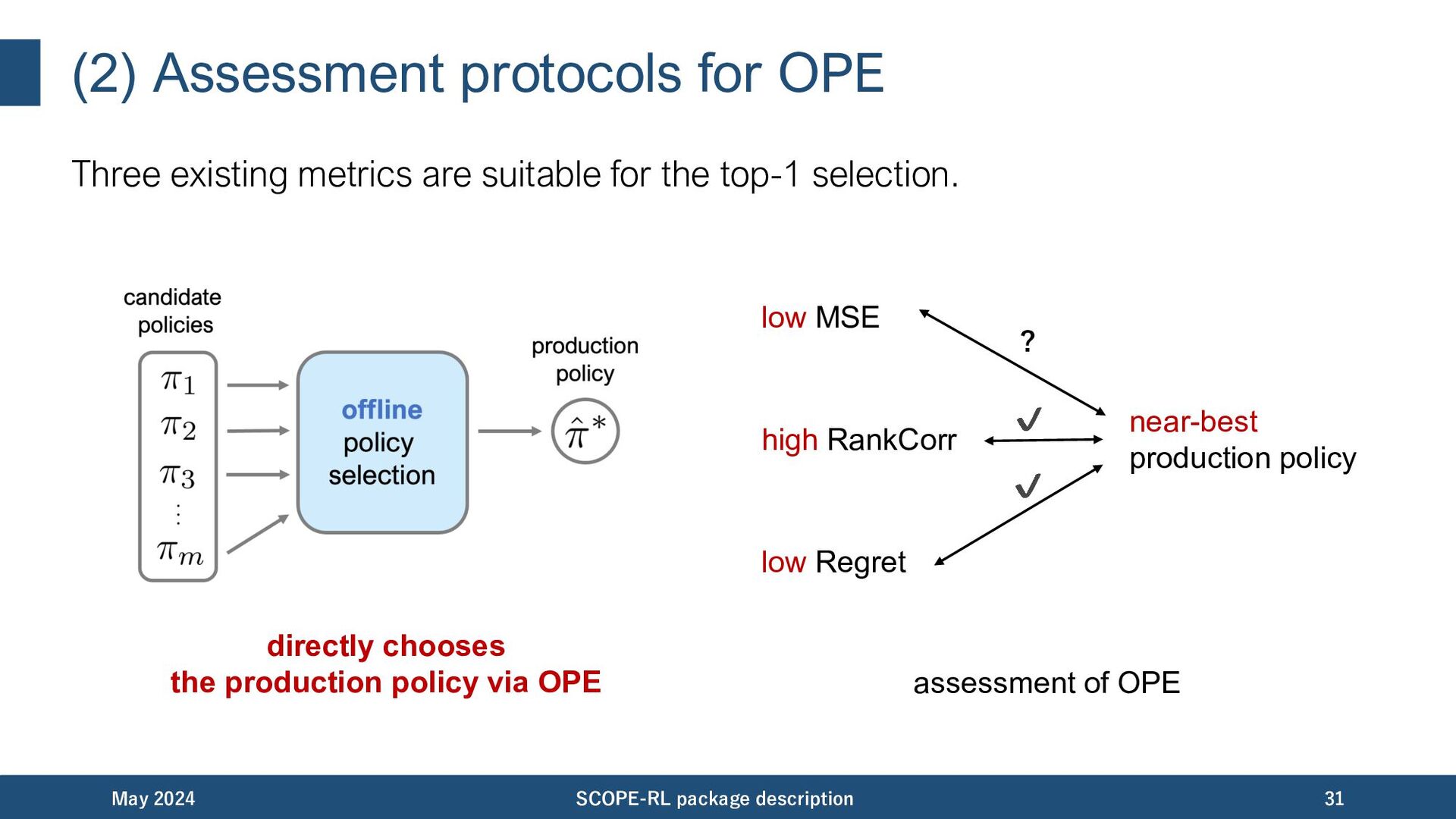
metrics. • Mean squared error (MSE) – “accuracy” of policy evaluation • Rank correlation (RankCorr) – “accuracy” of policy alignment • Regret – “accuracy” of the downstream policy selection May 2024 SCOPE-RL package description 30 See Appendix for the definitions.
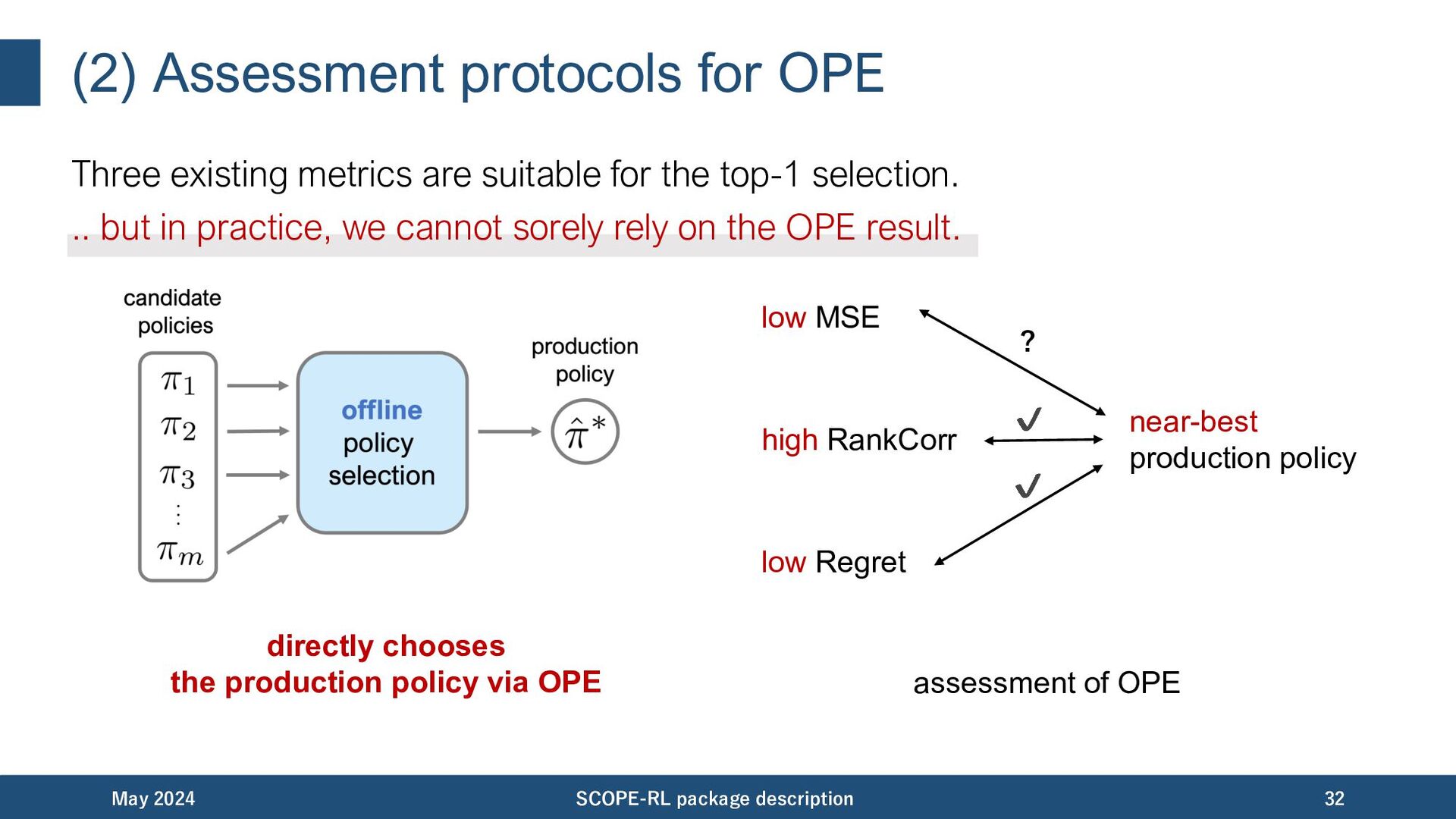
for the top-1 selection. May 2024 SCOPE-RL package description 31 directly chooses the production policy via OPE low MSE high RankCorr low Regret near-best production policy ? ✔ ✔ assessment of OPE
for the top-1 selection. .. but in practice, we cannot sorely rely on the OPE result. May 2024 SCOPE-RL package description 32 directly chooses the production policy via OPE low MSE high RankCorr low Regret near-best production policy ? ✔ ✔ assessment of OPE
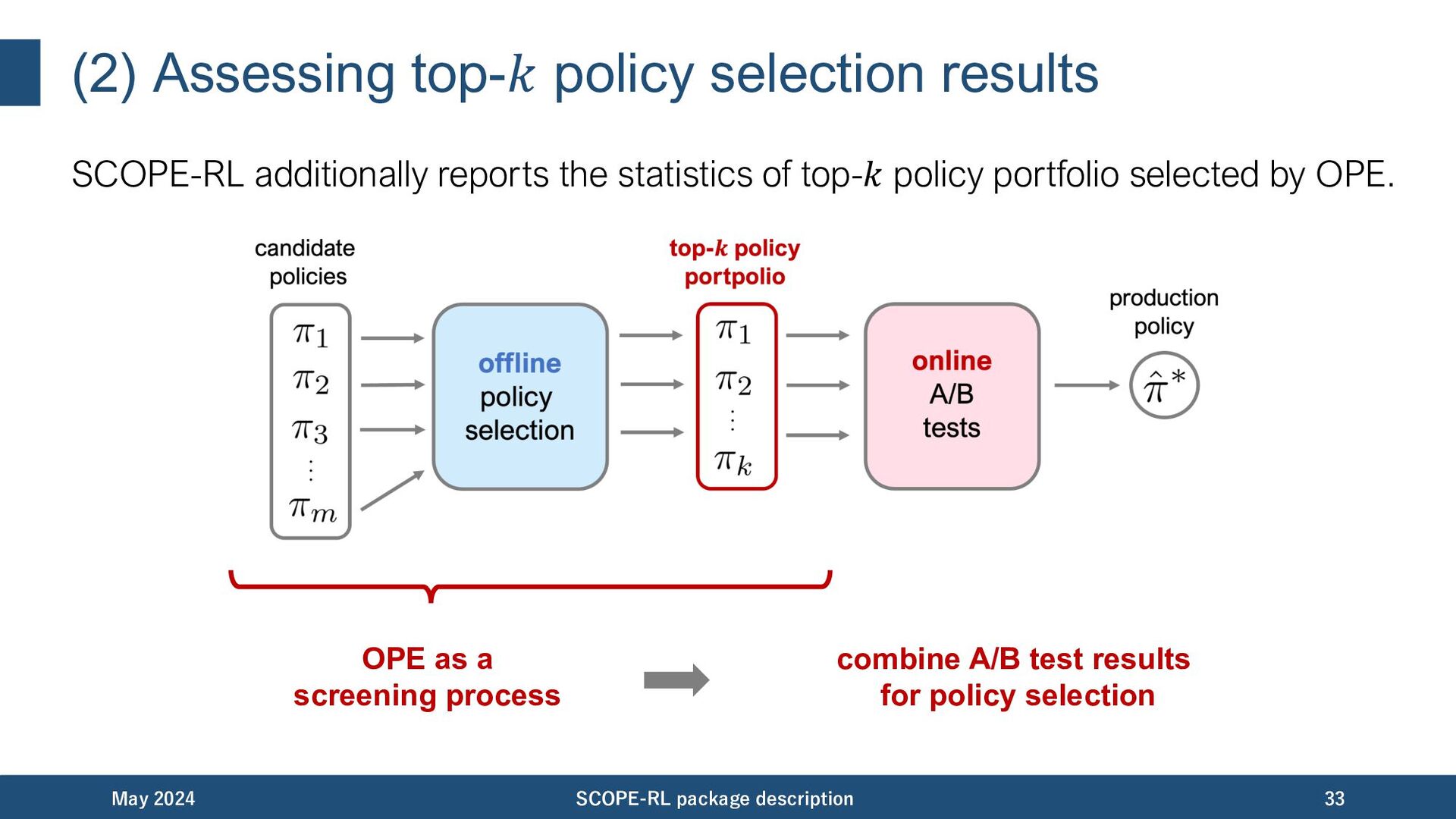
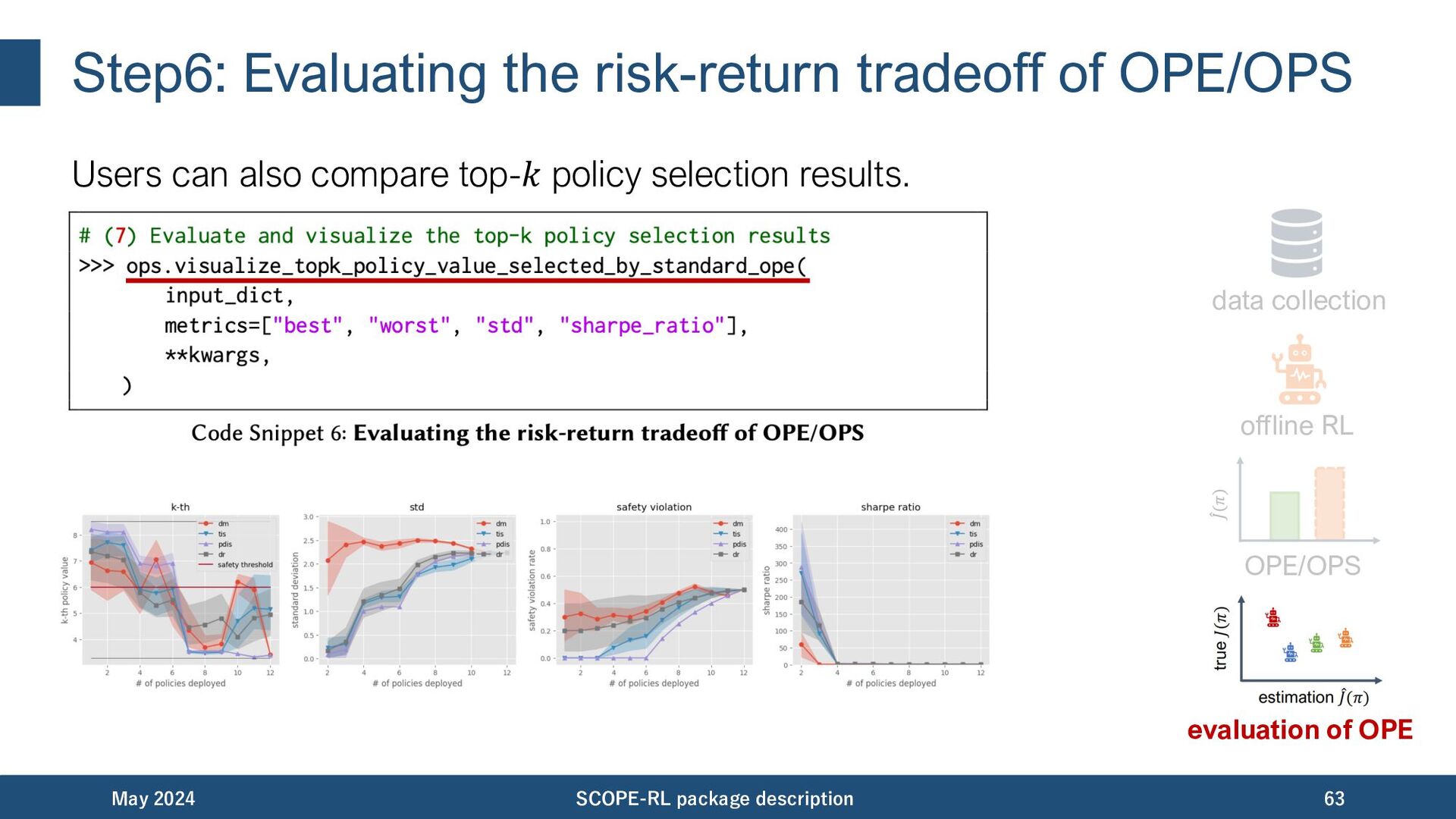
statistics of top-𝑘 policy portfolio selected by OPE. May 2024 SCOPE-RL package description 33 OPE as a screening process combine A/B test results for policy selection
statistics of top-𝑘 policy portfolio selected by OPE. May 2024 SCOPE-RL package description 34 OPE as a screening process Assess risk-returns of online A/B tests via statistics of policy portfolio
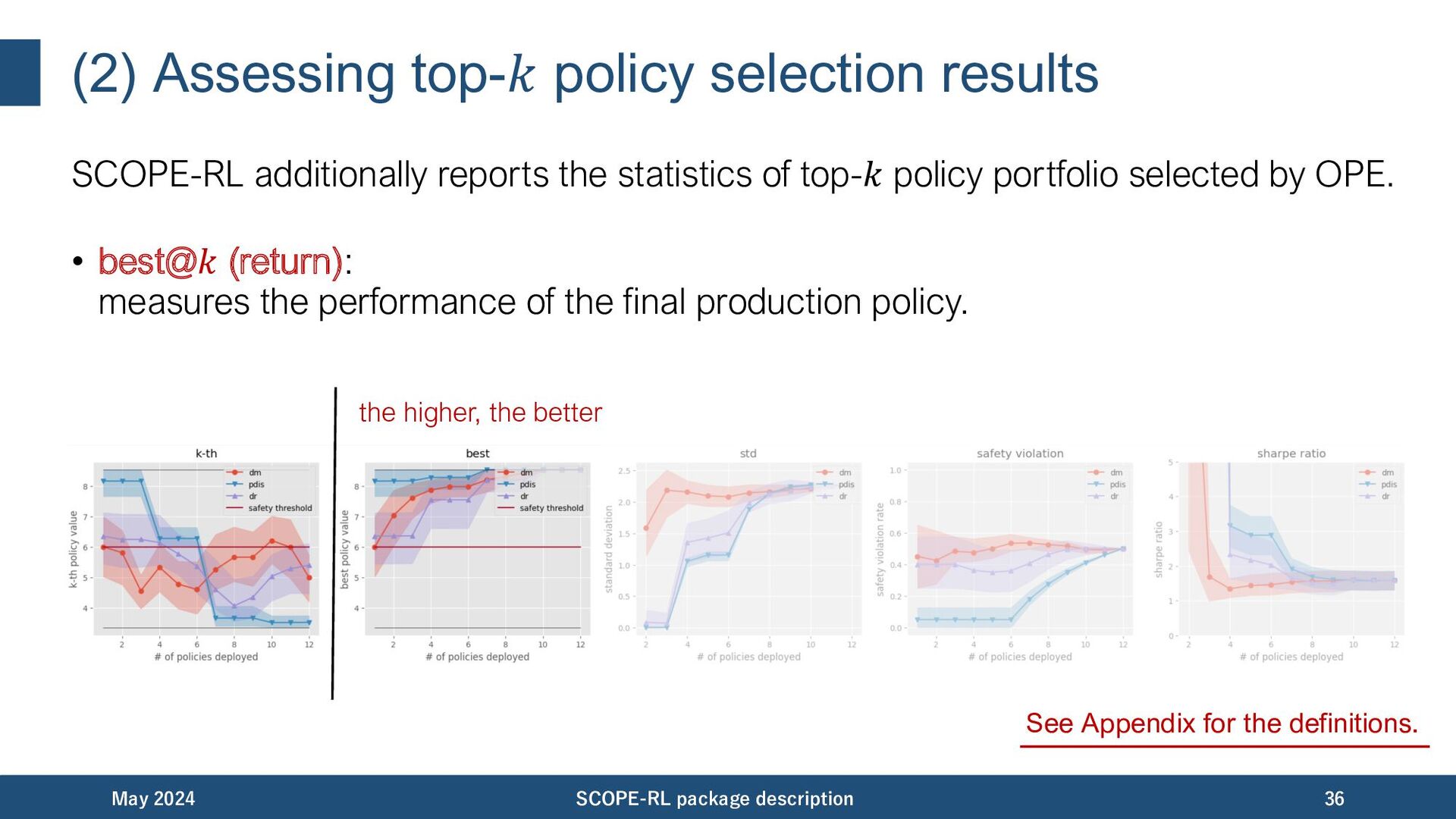
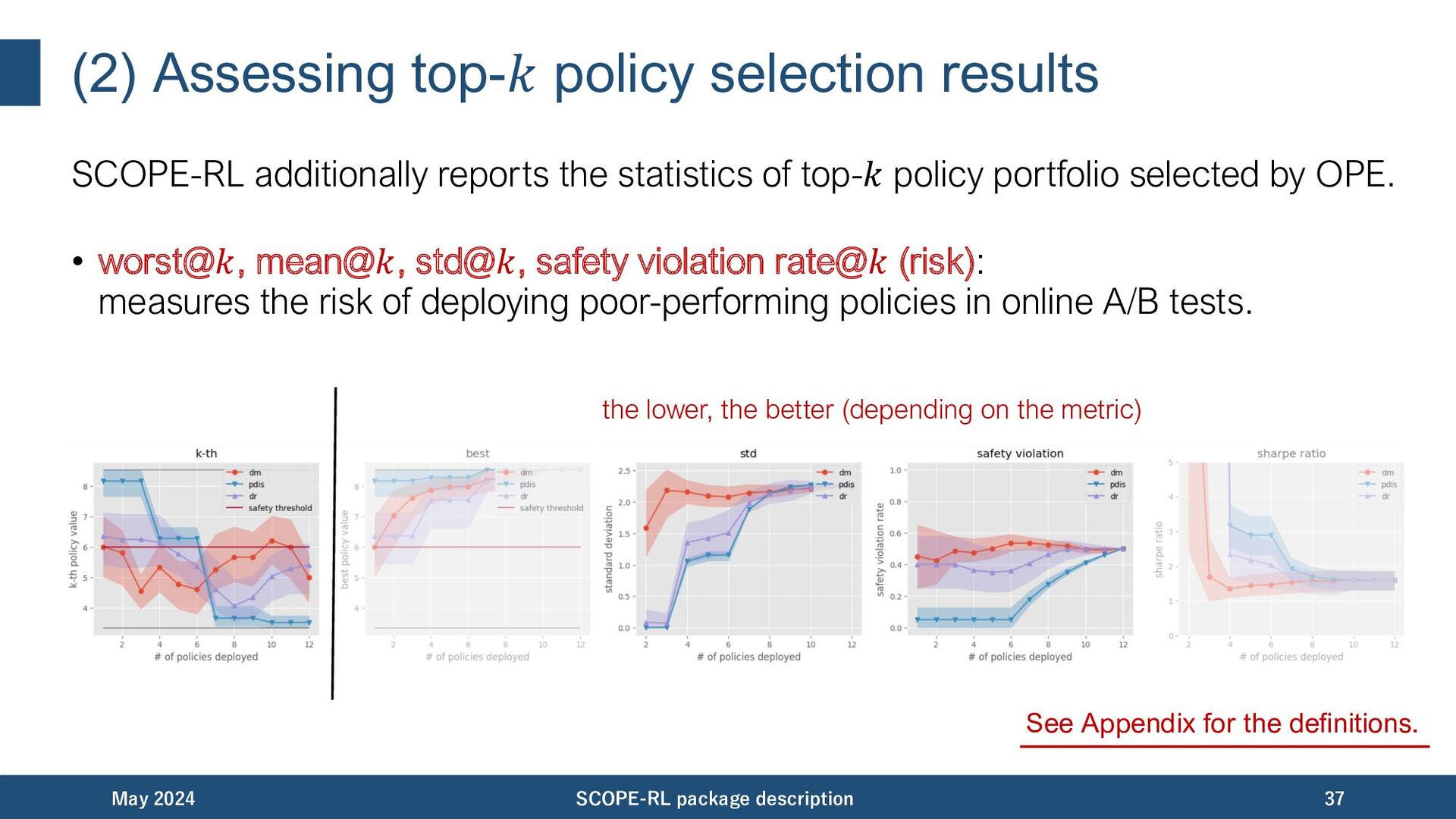
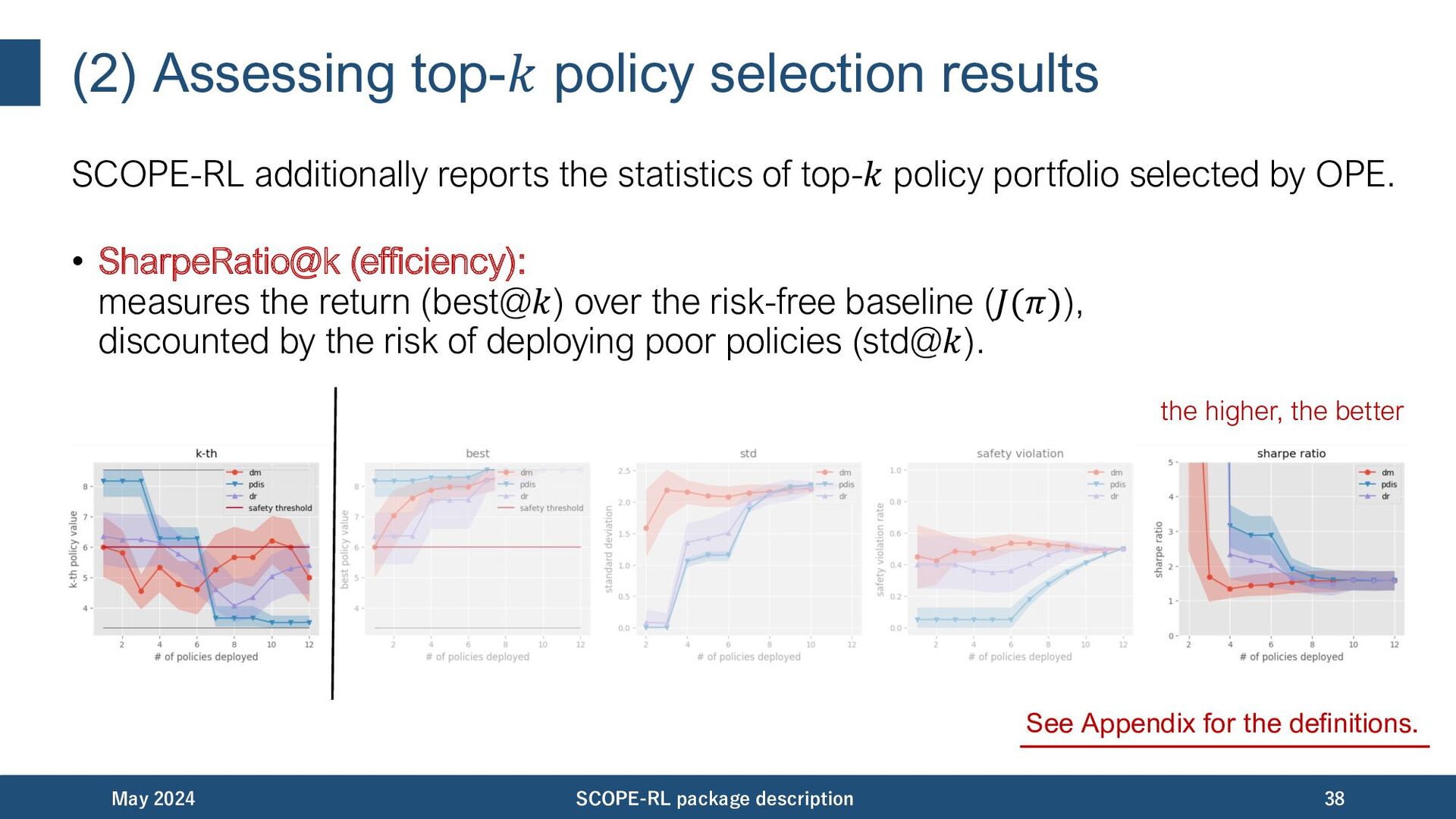
statistics of top-𝑘 policy portfolio selected by OPE. • best@𝑘 (return): measures the performance of the Lnal production policy. • worst@𝑘, mean@𝑘, std@𝑘, safety violation rate@𝑘 (risk): measures the risk of deploying poor-performing policies in online A/B tests. • SharpeRatio@k (ef]ciency): measures the return (best@𝑘) over the risk-free baseline (𝐽(𝜋𝑏 )), discounted by the risk of deploying poor policies (std@𝑘). May 2024 SCOPE-RL package description 35 See Appendix for the definitions.
statistics of top-𝑘 policy portfolio selected by OPE. • best@𝑘 (return): measures the performance of the ]nal production policy. May 2024 SCOPE-RL package description 36 See Appendix for the definitions. the higher, the better
statistics of top-𝑘 policy portfolio selected by OPE. • worst@𝑘, mean@𝑘, std@𝑘, safety violation rate@𝑘 (risk): measures the risk of deploying poor-performing policies in online A/B tests. May 2024 SCOPE-RL package description 37 See Appendix for the dePnitions. the lower, the better (depending on the metric)
statistics of top-𝑘 policy portfolio selected by OPE. • SharpeRatio@k (efficiency): measures the return (best@𝑘) over the risk-free baseline (𝐽(𝜋)), discounted by the risk of deploying poor policies (std@𝑘). May 2024 SCOPE-RL package description 38 See Appendix for the dePnitions. the higher, the better
first end-to-end open-source platfom for offline RL and OPE. • Unlike most existing offline RL libraries, SCOPE-RL puts weight on the OPE module. • .. implements a variety of OPE estimators. • .. supports cumulative distribution OPE for the first time. • .. handles assessments of OPE estimators. SCOPE-RL can be used for a quick testbed for OPE estimators! May 2024 SCOPE-RL package description 40
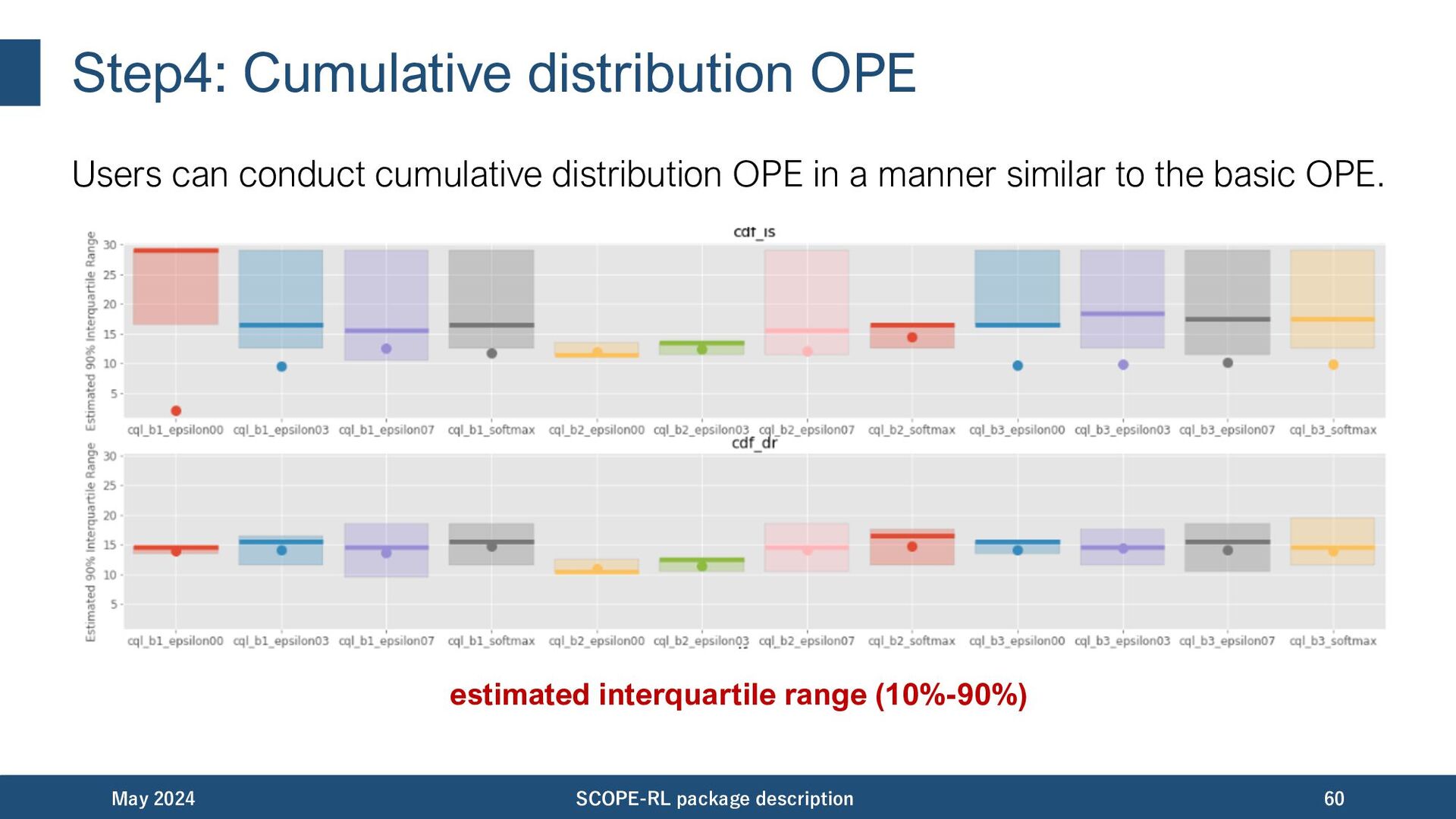
in a manner similar to the basic OPE. May 2024 SCOPE-RL package description 59 estimated cumulative distribution function estimated conditional value at risk (with various range)
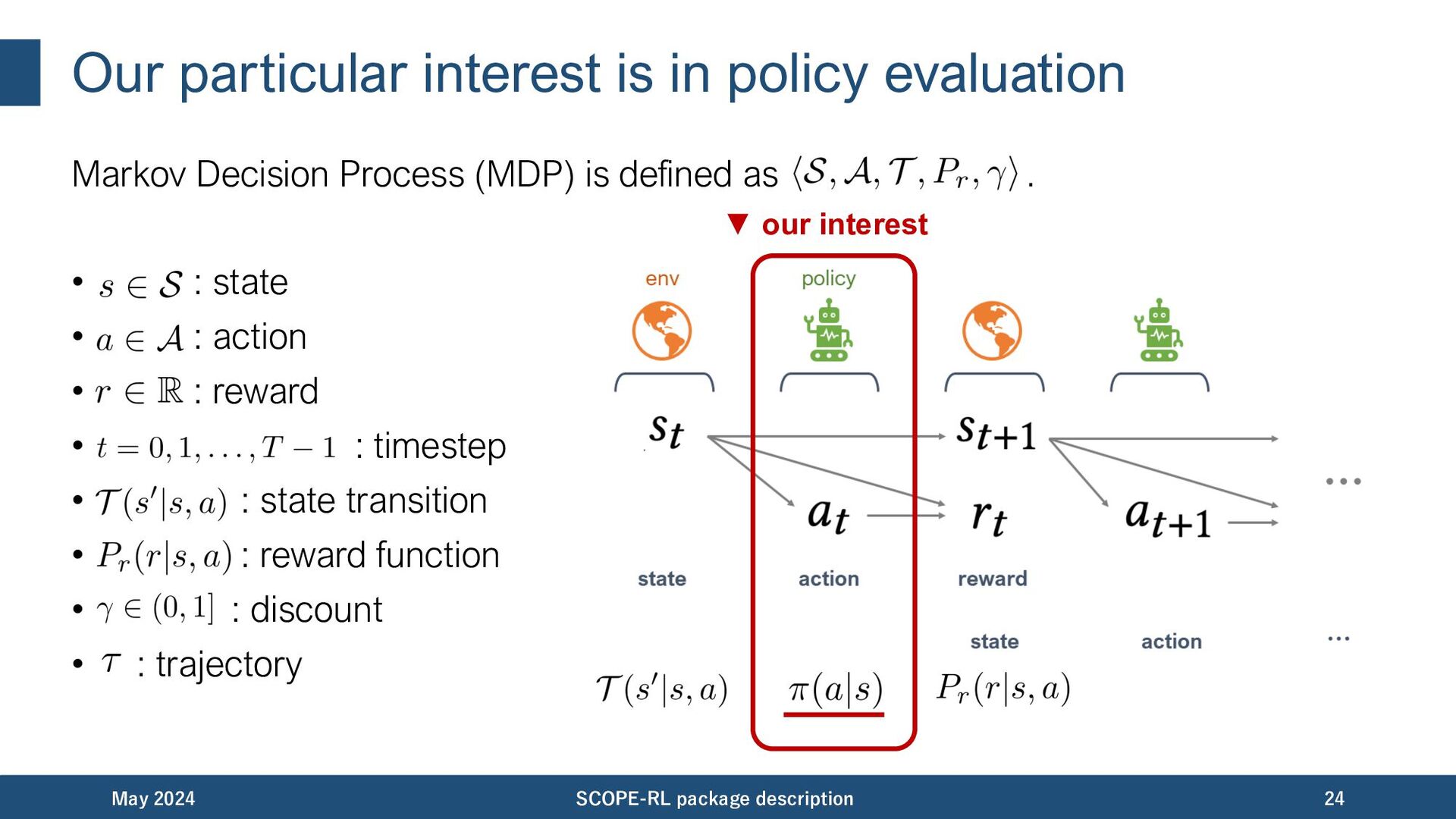
implement both OPS and evaluation of OPE/OPS. May 2024 SCOPE-RL package description 62 comparing the true (x) and estimated (y) variance evaluating the quality of OPS results
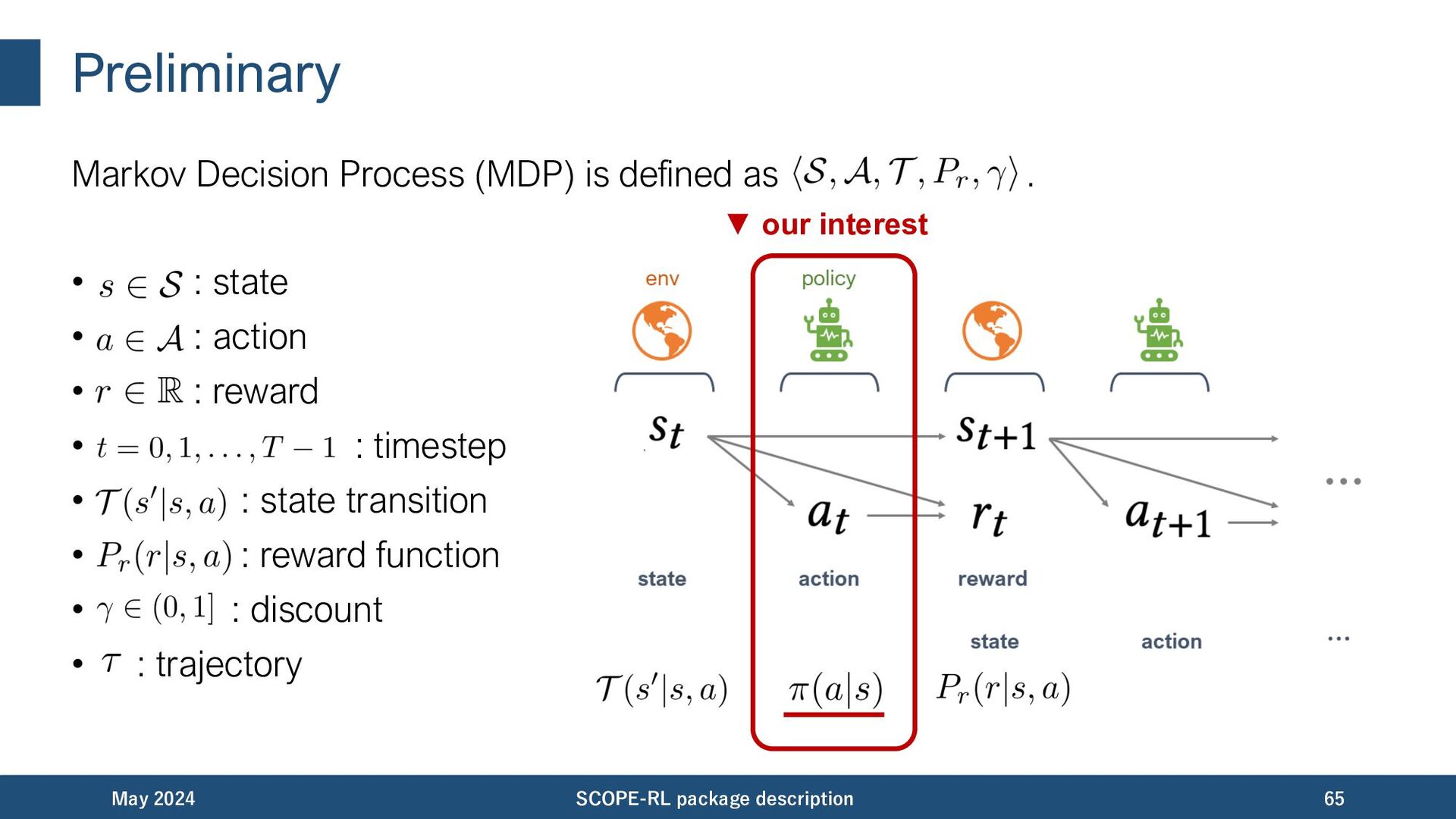
expected trajectory-wise reward (i.e., policy value): May 2024 SCOPE-RL package description 66 OPE estimator logged data collected by a past (behavior) policy counterfactuals & distribution shift behavior policy
estimates the policy value from the prediction. Pros: variance is small. Cons: bias can be large when & 𝑄 is inaccurate. May 2024 SCOPE-RL package description 67 value prediction estimating expected reward at future timesteps empirical average (𝑛 is the data size and 𝑖 is the index)
correct the distribution shift. Pros: unbiased (under the common support assumption: ). Cons: variance can be exponentially large as 𝑡 grows. May 2024 SCOPE-RL package description 68 importance weight = product of step-wise iimportance weights
DM and IPS, which apply importance sampling only on the residual. May 2024 SCOPE-RL package description 69 (recursive form) importance weight is multiplied on the residual value after timestep 𝒕
DM and IPS, which apply importance sampling only on the residual. Pros: unbiased and often reduce variance compared to PDIS. Cons: can still suffer from high variance when 𝑡 is large. May 2024 SCOPE-RL package description 70
IS on the (state-action) marginal distribution. Pros: unbiased when ) 𝜌 is correct and reduces variance compared to PDIS. Cons: accurate estimation of ) 𝜌 is often challenging, resulting in some bias. May 2024 SCOPE-RL package description 71 (estimated) marginal importance weight state-action visitation probability
that leverages the (state-action) marginal distribution. Pros: unbiased when ) 𝜌 or & 𝑄 is accurate and reduces variance compared to DR. Cons: accurate estimation of ) 𝜌 is often challenging, resulting in some bias. May 2024 SCOPE-RL package description 72 marginal importance weight is multiplied on the residual
the (state) marginal importance weights. where is the (estimated) state marginal importance weight. is the step-wise importance weight at timestep 𝑡. May 2024 SCOPE-RL package description 73
among unbiased estimators. DRL also uses cross-]tting, which estimate ) 𝜌 and & 𝑄 on 𝐷\𝐷𝑘 and estimate - 𝐽 on 𝐷𝑘 (i.e., different subsets of data), to alleviate potential bias in estimation. May 2024 SCOPE-RL package description 76 (reference) cross-fitting
weight rejects almost all actions , we exploit similarity between actions using a kernel. May 2024 SCOPE-RL package description 79 kernel function (e.g., Gaussian kernel)
estimates the whole performance distribution. May 2024 SCOPE-RL package description 81 𝐹(𝜋) enable us to compare the worst-case policy value reward threshold
the cumulative distribution function (CDF). As the probability may exceed 1 due to large importance weight, we apply clipping. May 2024 SCOPE-RL package description 84 trajectory-wise importance weight
assess the accuracy of OPE. • Mean squared error (MSE) – “accuracy” of policy evaluation • Rank correlation (RankCorr) – “accuracy” of policy alignment • Regret – “accuracy” of policy selection • Type I and Type II error rates – “accuracy” of safety validation May 2024 SCOPE-RL package description 87
to assess the accuracy of OPE and policy selection. • Mean squared error (MSE) – “accuracy” of policy evaluation [Voloshin+,21] May 2024 SCOPE-RL package description 88 estimation true value the lower, the better
to assess the accuracy of OPE/OPS. • Regret – “accuracy” of policy selection [Doroudi+,18] May 2024 SCOPE-RL package description 90 performance of the true best policy performance of the estimated best policy the lower, the better
to assess the accuracy of OPE/OPS. • Type I and Type II error rates – “accuracy” of safety validation May 2024 SCOPE-RL package description 91 false positive true negative ̅ 𝐽: safety threshold (true negative / true) (false positive / false) the lower, the better
top-𝑘 policy portfolio selected by OPE. • best@𝑘 (return): measures the performance of the final production policy. • worst@𝑘, mean@𝑘, std@𝑘, safety violation rate@𝑘 (risk): measures the risk of deploying poor-performing policies in online A/B tests. • SharpeRatio@k (efficiency): measures the return (best@𝑘) over the risk-free baseline (𝐽(𝜋)), discounted by the risk of deploying poor policies (std@𝑘). May 2024 SCOPE-RL package description 92
top-𝑘 policy portfolio selected by OPE. • best@𝑘 (return; the higher, the better): measures the performance of the ]nal production policy. May 2024 SCOPE-RL package description 93
top-𝑘 policy portfolio selected by OPE. • worst@𝑘, mean@𝑘 (risk; the higher, the better): measures the risk of deploying poor-performing policies in online A/B tests. May 2024 SCOPE-RL package description 94
top-𝑘 policy portfolio selected by OPE. • std@𝑘 (risk; the lower, the better): measures the risk of deploying poor-performing policies in online A/B tests. May 2024 SCOPE-RL package description 95
top-𝑘 policy portfolio selected by OPE. • SharpeRatio@k (ef]ciency; the higher, the better): [Kiyohara+,23] measures the return (best@𝑘) over the risk-free baseline (𝐽(𝜋)), discounted by the risk of deploying poor policies (std@𝑘). May 2024 SCOPE-RL package description 97
An Offline Deep Reinforcement Learning Library.” JMLR, 2022. https://arxiv.org/abs/2111.03788 [Gauci+,18 (Horizon)] Jason Gauci, Edoardo Conti, Yitao Liang, Kittipat Virochsiri, Yuchen He, Zachary Kaden, Vivek Narayanan, Xiaohui Ye, Zhengxing Chen, and Scott Fujimoto. “Horizon: Facebook's Open Source Applied Reinforcement Learning Platform.” 2018. https://arxiv.org/abs/1811.00260 [Liang+,18 (RLlib)] Eric Liang, Richard Liaw, Philipp Moritz, Robert Nishihara, Roy Fox, Ken Goldberg, Joseph E. Gonzalez, Michael I. Jordan, and Ion Stoica. “RLlib: Abstractions for Distributed Reinforcement Learning.” ICML, 2018. https://arxiv.org/abs/1712.09381 May 2024 SCOPE-RL package description 99
George Tucker, Ziyu Wang, Alexander Novikov, Mengjiao Yang, Michael R. Zhang, Yutian Chen, Aviral Kumar, Cosmin Paduraru, Sergey Levine, and Tom Le Paine. “Benchmarks for Deep Off-Policy Evaluation.” ICLR, 2021. https://arxiv.org/abs/2103.16596 [Voloshin+,21 (COBS)] Cameron Voloshin, Hoang M. Le, Nan Jiang, and Yisong Yue. “Empirical Study of Off-Policy Policy Evaluation for Reinforcement Learning.” NeurIPS dataset&benchmark, 2021. https://arxiv.org/abs/1911.06854 [Rohde+,18 (RecoGym)] David Rohde, Stephen Bonner, Travis Dunlop, Flavian Vasile, and Alexandros Karatzoglou “RecoGym: A Reinforcement Learning Environment for the problem of Product Recommendation in Online Advertising.” 2018. https://arxiv.org/abs/1808.00720 May 2024 SCOPE-RL package description 100
Saito. “Accelerating Offline Reinforcement Learning Application in Real-Time Bidding and Recommendation: Potential Use of Simulation.” 2021. https://arxiv.org/abs/2109.08331 [Chandak+,21 (CD-OPE)] Yash Chandak, Scott Niekum, Bruno Castro da Silva, Erik Learned-Miller, Emma Brunskill, and Philip S. Thomas. “Universal Off-Policy Evaluation.” NeurIPS, 2021. https://arxiv.org/abs/2104.12820 [Huang+,21 (CD-OPE)] Audrey Huang, Liu Leqi, Zachary C. Lipton, and Kamyar Azizzadenesheli. “Off-Policy Risk Assessment in Contextual Bandits.” NeurIPS, 2021. https://arxiv.org/abs/2104.12820 May 2024 SCOPE-RL package description 102
Satinder P. Singh. “Eligibility Traces for Off-Policy Policy Evaluation.” ICML, 2000. https://scholarworks.umass.edu/cgi/viewcontent.cgi?article=1079&context=cs_facult y_pubs [Jiang&Li,16 (DR)] Nan Jiang and Lihong Li. “Doubly Robust Off-policy Value Evaluation for Reinforcement Learning.” ICML, 2016. https://arxiv.org/abs/1511.03722 [Thomas&Brunskill,16 (DR)] Philip S. Thomas and Emma Brunskill. “Data-Ef]cient Off-Policy Policy Evaluation for Reinforcement Learning.” ICML, 2016. https://arxiv.org/abs/1604.00923 [Uehara+,20 (SAM-IS/DR)] Masatoshi Uehara, Jiawei Huang, Nan Jiang. “Minimax Weight and Q-Function Learning for Off-Policy Evaluation.” ICML, 2020. https://arxiv.org/abs/1910.12809 May 2024 SCOPE-RL package description 104
Zhou. “Policy Evaluation and Optimization with Continuous Treatments.” AISTATS, 2018. https://arxiv.org/abs/1802.06037 [Thomas+,15 (high-confidence OPE)] Philip S. Thomas, Georgios Theocharous, Mohammad Ghavamzadeh. “High Confidence Off-Policy Evaluation.” AAAI, 2015. https://people.cs.umass.edu/~pthomas/papers/Thomas2015.pdf [Thomas+,15 (high-confidence OPE)] Philip S. Thomas, Georgios Theocharous, Mohammad Ghavamzadeh. “High Confidence Policy Improvement.” ICML, 2015. https://people.cs.umass.edu/~pthomas/papers/Thomas2015b.pdf [Voloshin+,21 (MSE)] Cameron Voloshin, Hoang M. Le, Nan Jiang, Yisong Yue. “Empirical Study of Off-Policy Policy Evaluation for Reinforcement Learning.” NeurIPS datasets&benchmarks, 2021. https://arxiv.org/abs/1911.06854 May 2024 SCOPE-RL package description 106
George Tucker, Ziyu Wang, Alexander Novikov, Mengjiao Yang, Michael R. Zhang, Yutian Chen, Aviral Kumar, Cosmin Paduraru, Sergey Levine, Tom Le Paine. “Benchmarks for Deep Off- Policy Evaluation.” ICLR, 2021. https://arxiv.org/abs/2103.16596 [Doroudi+,18 (Regret)] Shayan Doroudi, Philip S. Thomas, Emma Brunskill. “Importance Sampling for Fair Policy Selection.” IJCAI, 2018. https://people.cs.umass.edu/~pthomas/papers/Daroudi2017.pdf [Kiyohara+,23 (SharpeRatio@k)] Haruka Kiyohara, Ren Kishimoto, Kosuke Kawakami, Ken Kobayashi, Kazuhide Nakata, Yuta Saito. “Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation in Reinforcement Learning.” 2023. May 2024 SCOPE-RL package description 107
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you for listening! contact: [email protected] May 2024 SCOPE-RL package](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Direct Method (DM) [Le+,19] DM trains a value predictor and](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_66.jpg){kind=link}
![Per-Decision Importance Sampling (PDIS) [Precup+,00] PDIS applies importance sampling to](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_67.jpg){kind=link}
![Doubly Robust (DR) [Jiang&Li,16] [Thomas&Brunskill,16] DR is a hydrid of](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_68.jpg){kind=link}
![Doubly Robust (DR) [Jiang&Li,16] [Thomas&Brunskill,16] DR is a hydrid of](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_69.jpg){kind=link}
![State-action Marginal IS (SAM-IS) [Uehara+,20] To alleviate variance, SAM-IS considers](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_70.jpg){kind=link}
![State-action Marginal DR (SAM-DR) [Uehara+,20] SAM-DR is a DR variant](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_71.jpg){kind=link}
![State Marginal estimators (SM-IS/DR) [Liu+,18] Likewise, state marginal estimators uses](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_72.jpg){kind=link}
![Spectrum of Off-Policy Evaluation (SOPE) [Yuan+,21] SOPE interpolates between marginal](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_73.jpg){kind=link}
![Spectrum of Off-Policy Evaluation (SOPE) [Yuan+,21] For example, SAM-IS/DR w/](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_74.jpg){kind=link}
![Double Reinforcement Learning (DRL) [Kallus&Uehara,20] DRL achieves the lowerest variance](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_75.jpg){kind=link}
![Self-normalized estimators [Kallus&Uehara,19] Self-normalized estimators alleviate variance by modifying the](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_76.jpg){kind=link}
![Self-normalized estimators [Kallus&Uehara,19] Self-normalized estimators alleviate variance by modifying the](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_77.jpg){kind=link}
![Extension to continuous action spaces [Kallus&Zhou,18] As the naive importance](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_78.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References (1/9) [Seno&Imai,22 (d3rlpy)] Takuma Seno and Michita Imai. “d3rlpy:](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_98.jpg){kind=link}
![References (2/9) [Fu+,21 (DOPE)] Justin Fu, Mohammad Norouzi, Ofir Nachum,](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_99.jpg){kind=link}
![References (3/9) [Wang+,21 (RL4RS)] Kai Wang, Zhene Zou, Yue Shang,](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_100.jpg){kind=link}
![References (4/9) [Kiyohara+,21 (RTBGym)] Haruka Kiyohara, Kosuke Kawakami, and Yuta](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_101.jpg){kind=link}
![References (5/9) [Huang+,22 (CD-OPE)] Audrey Huang, Liu Leqi, Zachary C.](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_102.jpg){kind=link}
![References (6/9) [Precup+,00 (IPS)] Doina Precup, Richard S. Sutton, and](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_103.jpg){kind=link}
![References (7/9) [Liu+,18 (SM-IS/DR)] Qiang Liu, Lihong Li, Ziyang Tang,](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_104.jpg){kind=link}
![References (8/9) [Kallus&Zhou,18 (extension to continuous actions)] Nathan Kallus, Angela](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_105.jpg){kind=link}
![References (9/9) [Fu+,21 (RankCorr)] Justin Fu, Mohammad Norouzi, O]r Nachum,](https://files.speakerdeck.com/presentations/850efe7156b742678e050aeb65058281/slide_106.jpg){kind=link}