Kiyohara, Yusuke Narita, Yuta Saito, Kei Tateno Haruka Kiyohara, Tokyo Institute of Technology https://sites.google.com/view/harukakiyohara February 2023 Policy Adaptive Estimator Selection @ AAAI2023 1
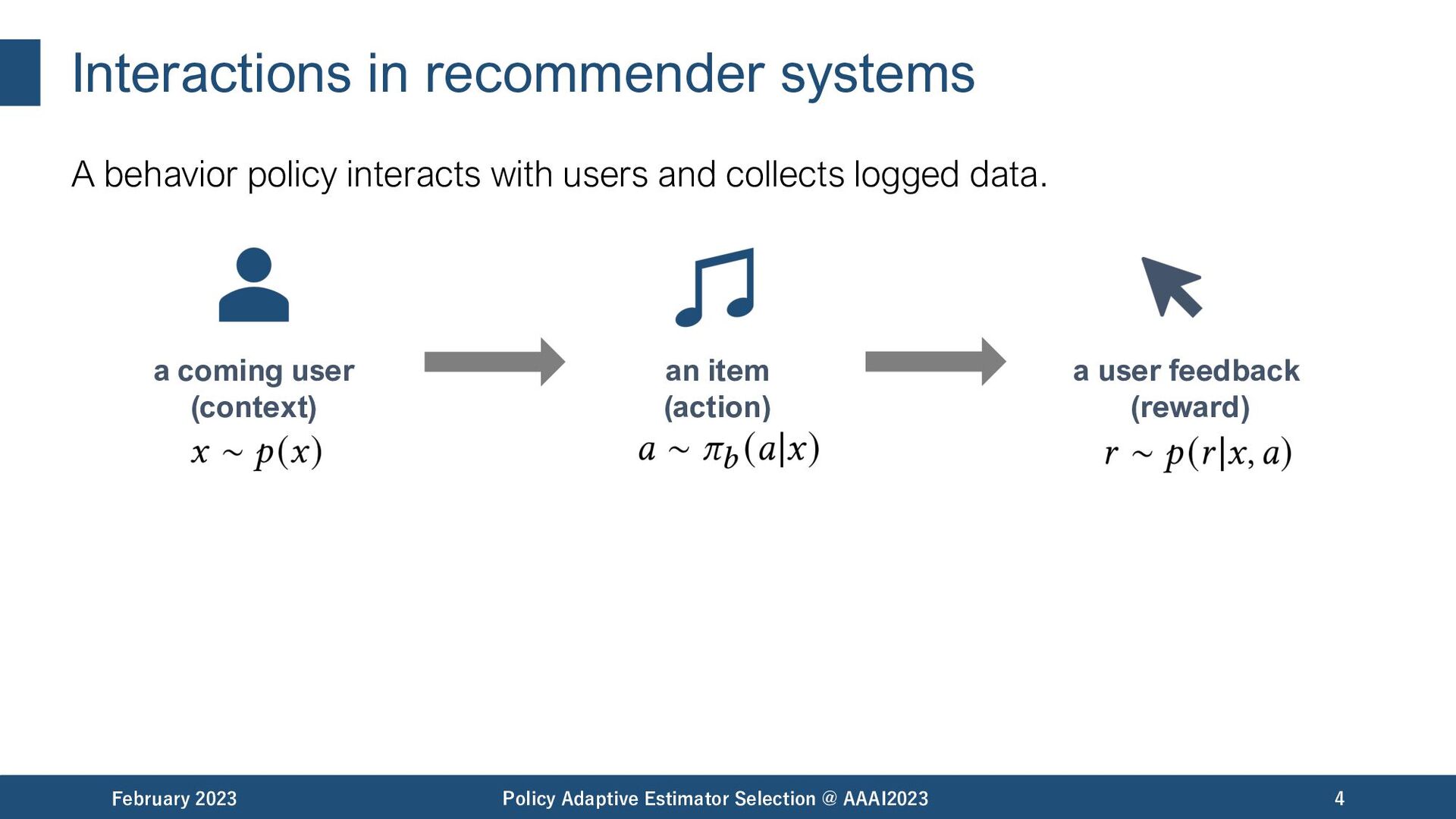
and collects logged data. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 4 a user feedback (reward) a coming user (context) an item (action)
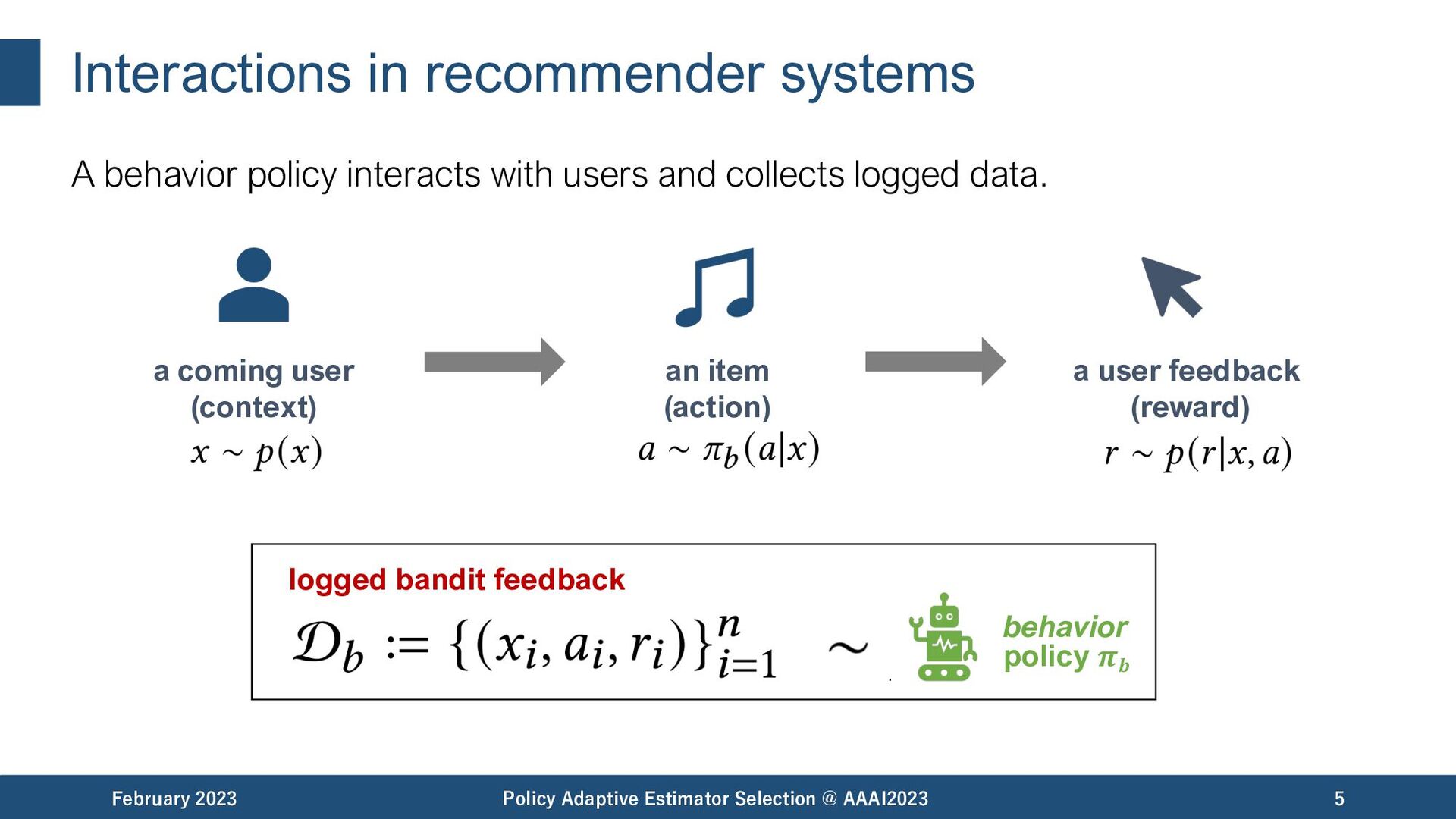
and collects logged data. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 5 a user feedback (reward) a coming user (context) an item (action) logged bandit feedback behavior policy 𝝅𝒃
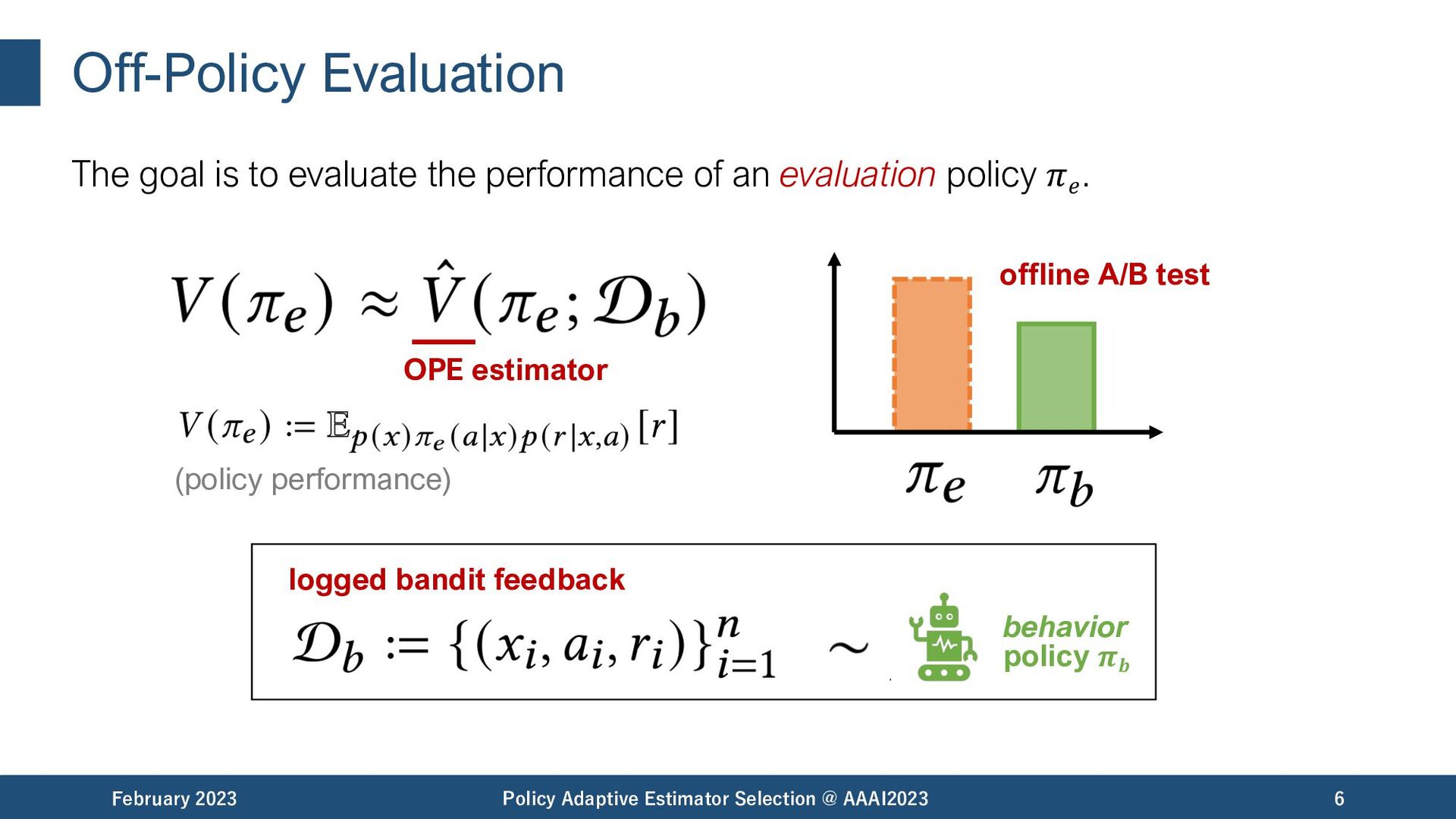
variance to enable an accurate OPE. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 7 ✓ ✓ ✓ ✓ ✓ model-based importance sampling-based bias variance Direct Method (DM) [Beygelzimer&Langford,09] --- high low Inverse Propensity Scoring (IPS) [Precup+,00] [Strehl+,10] --- unbiased very high Doubly Robust (DR) [Dudík+,14] unbiased lower than IPS, but still high (reward predictor) (importance weight)
variance to enable an accurate OPE. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 8 ✓ ✓ ✓ ✓ ✓ model-based importance sampling-based bias variance Direct Method (DM) [Beygelzimer&Langford,09] --- high low Inverse Propensity Scoring (IPS) [Precup+,00] [Strehl+,10] --- unbiased very high Doubly Robust (DR) [Dudík+,14] unbiased lower than IPS, but still high ✓ reward predictor
variance to enable an accurate OPE. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 9 ✓ ✓ ✓ ✓ ✓ model-based importance sampling-based bias variance Direct Method (DM) [Beygelzimer&Langford,09] --- high low Inverse Propensity Scoring (IPS) [Precup+,00] [Strehl+,10] --- unbiased very high Doubly Robust (DR) [Dudík+,14] unbiased lower than IPS, but still high importance weight
variance to enable an accurate OPE. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 10 ✓ ✓ ✓ ✓ ✓ model-based importance sampling-based bias variance Direct Method (DM) [Beygelzimer&Langford,09] --- high low Inverse Propensity Scoring (IPS) [Precup+,00] [Strehl+,10] --- unbiased very high Doubly Robust (DR) [Dudík+,14] unbiased lower than IPS, but still high importance weight evaluation behavior
variance to enable an accurate OPE. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 11 ✓ ✓ ✓ ✓ ✓ model-based importance sampling-based bias variance Direct Method (DM) [Beygelzimer&Langford,09] --- high low Inverse Propensity Scoring (IPS) [Precup+,00] [Strehl+,10] --- unbiased very high Doubly Robust (DR) [Dudík+,14] unbiased lower than IPS, but still high importance weight evaluation behavior
variance to enable an accurate OPE. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 12 ✓ ✓ ✓ ✓ ✓ model-based importance sampling-based bias variance Direct Method (DM) [Beygelzimer&Langford,09] --- high low Inverse Propensity Scoring (IPS) [Precup+,00] [Strehl+,10] --- unbiased very high Doubly Robust (DR) [Dudík+,14] unbiased lower than IPS, but still high control variate
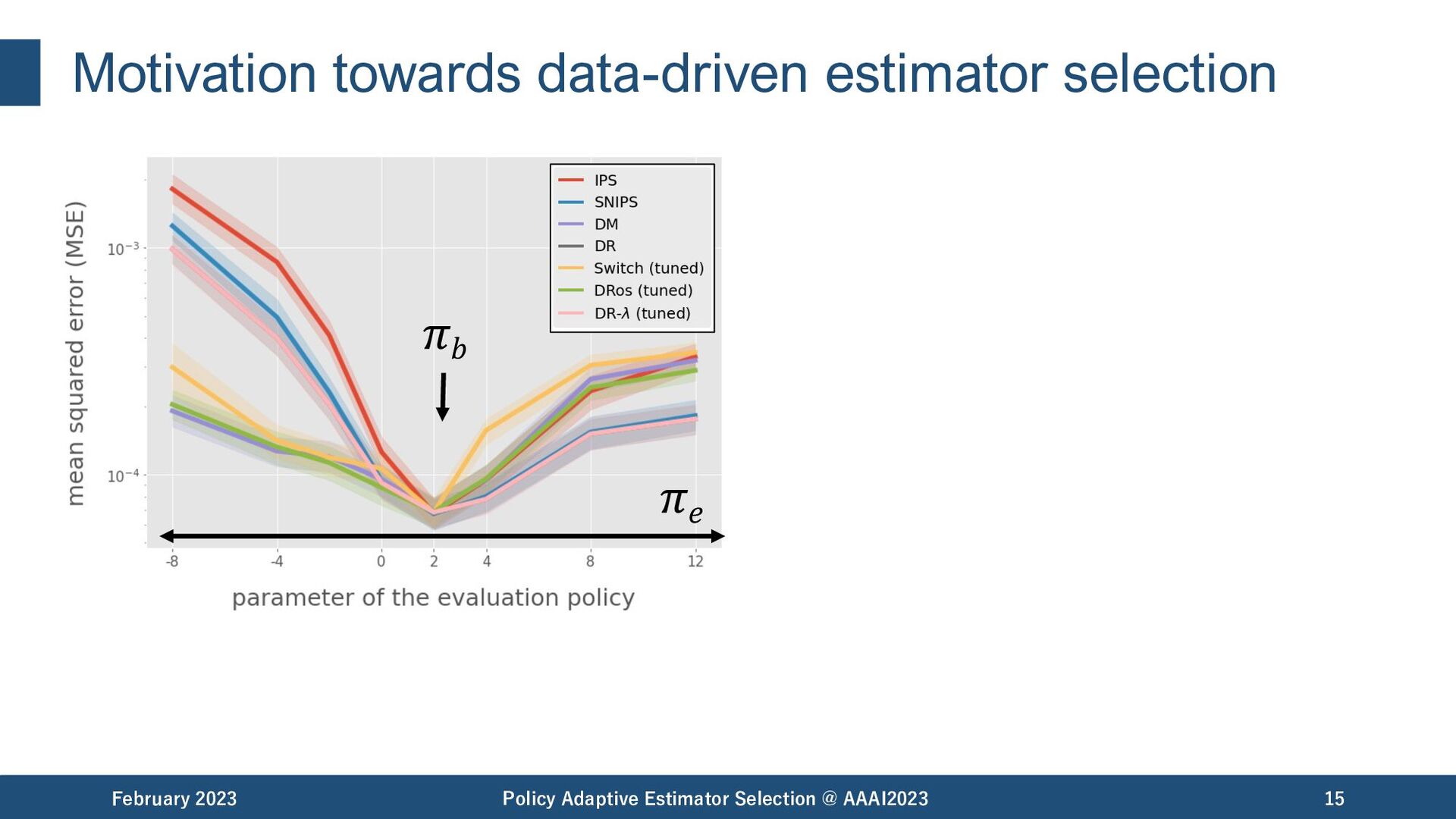
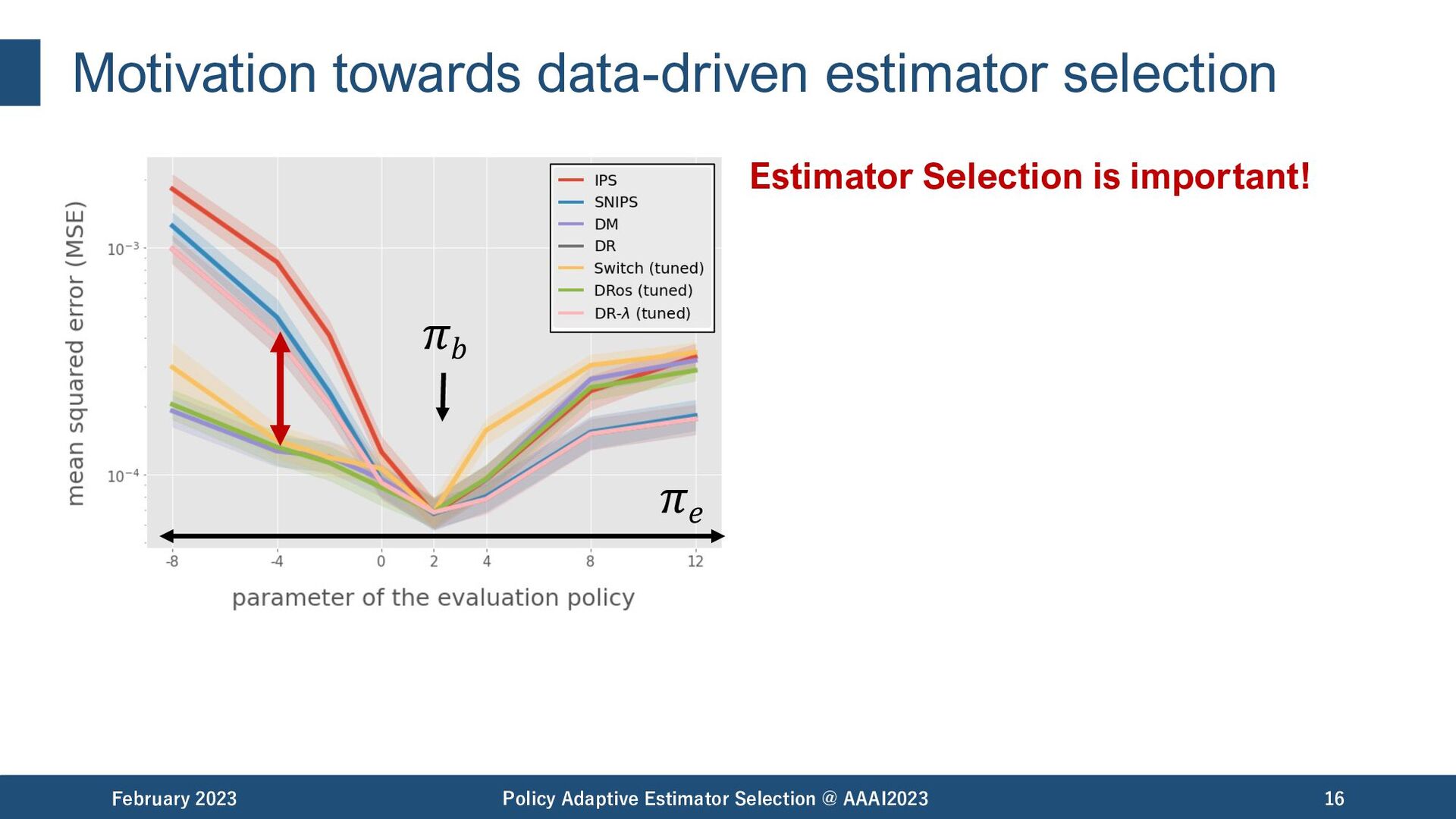
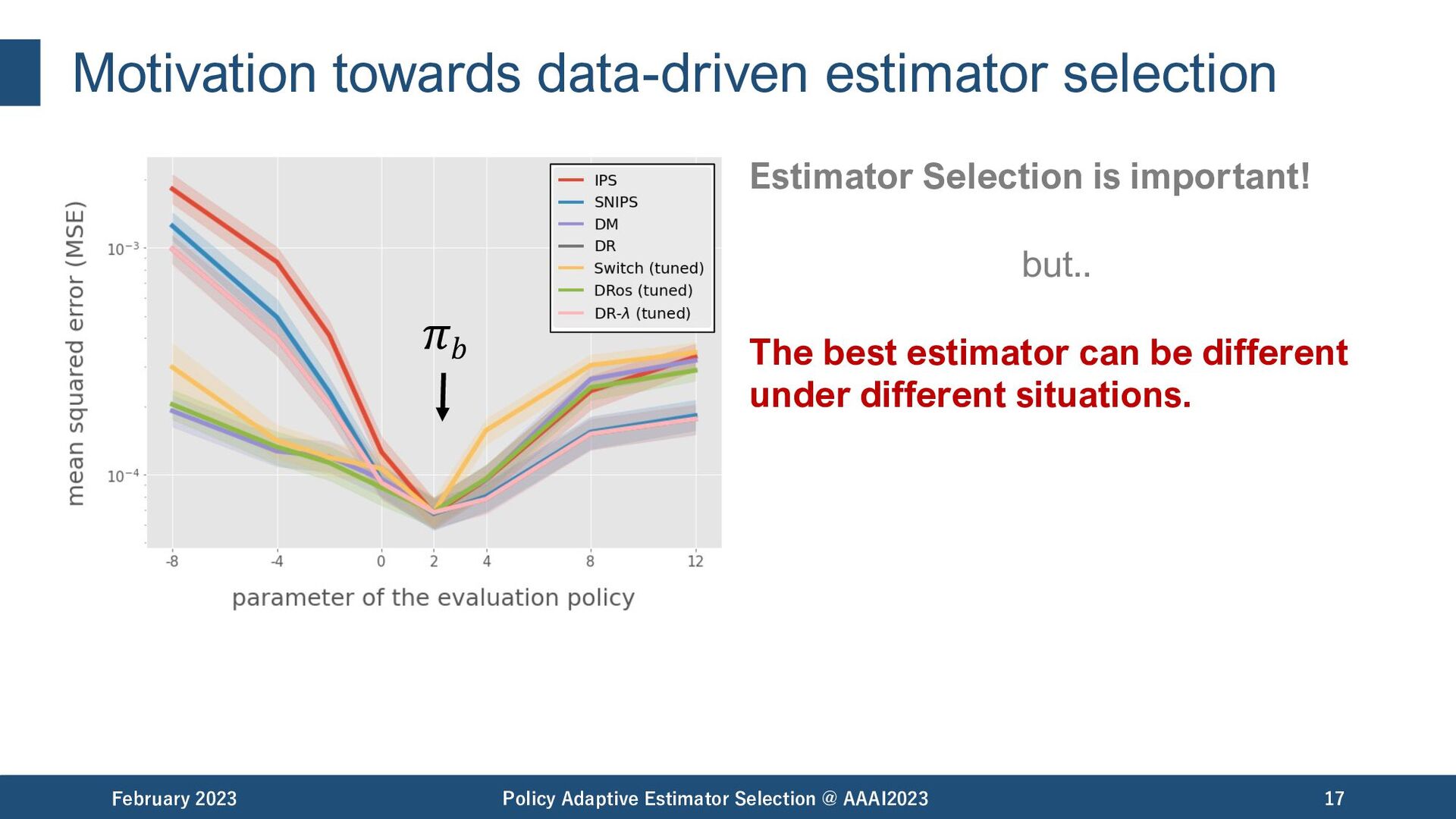
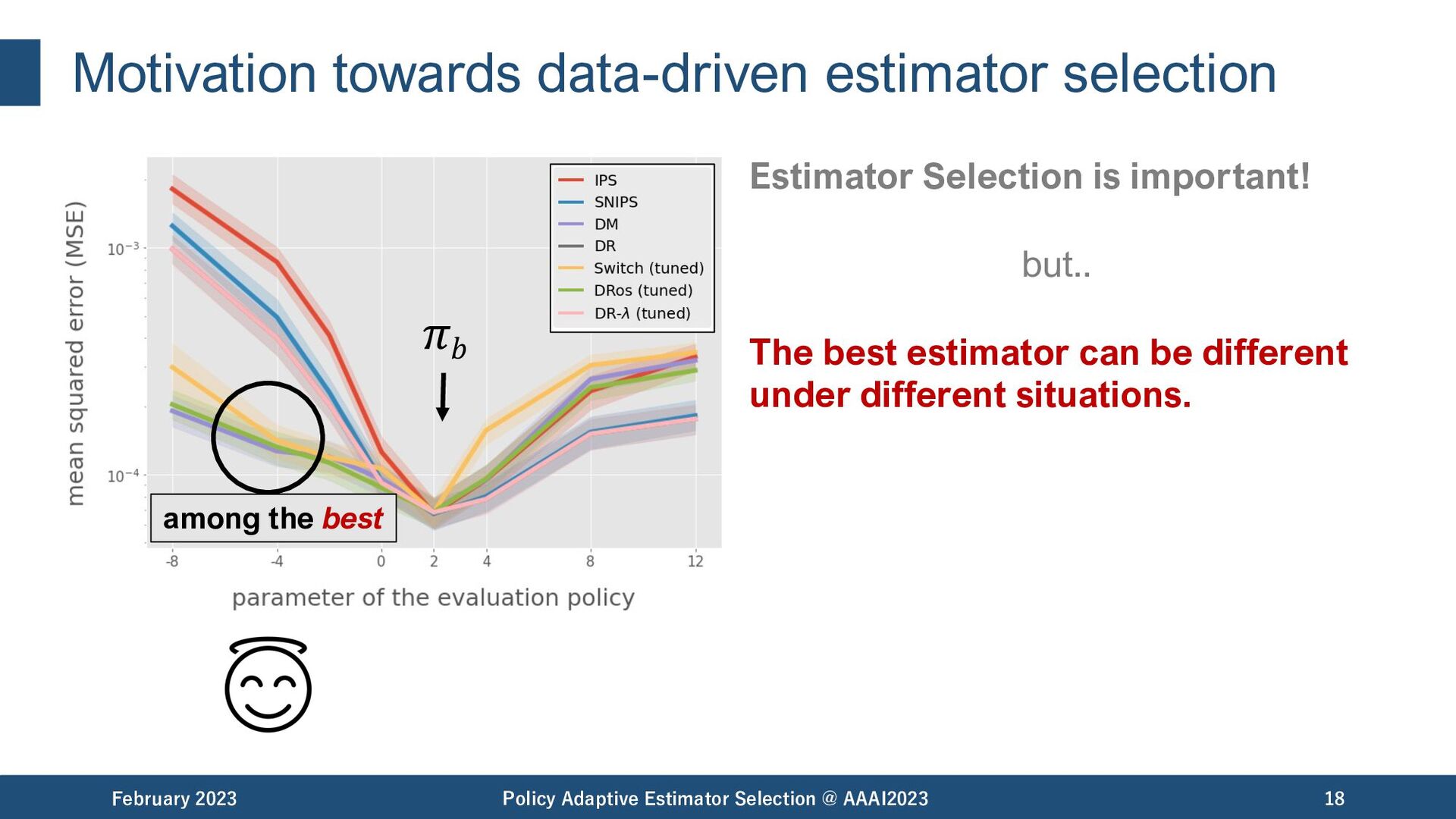
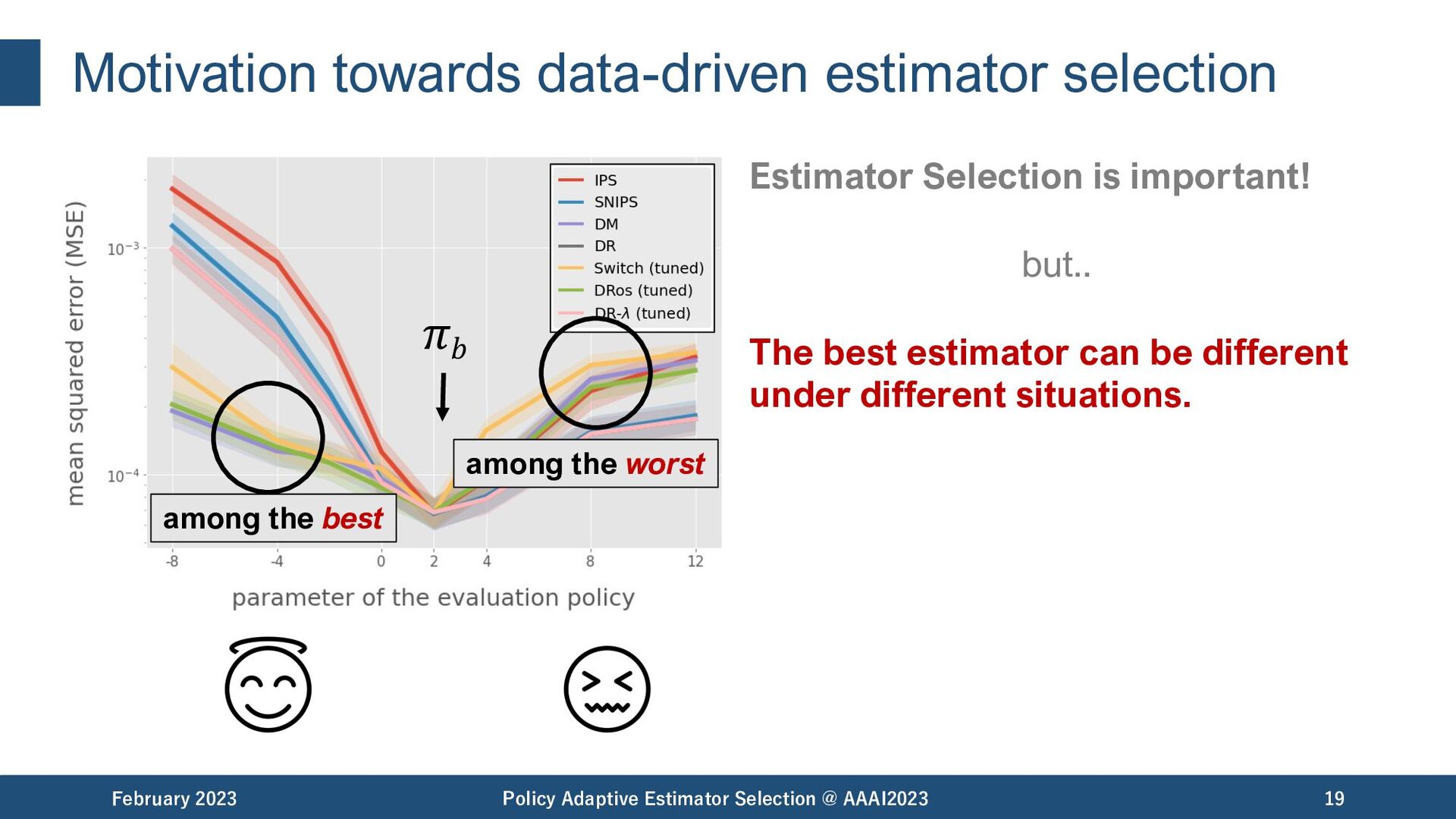
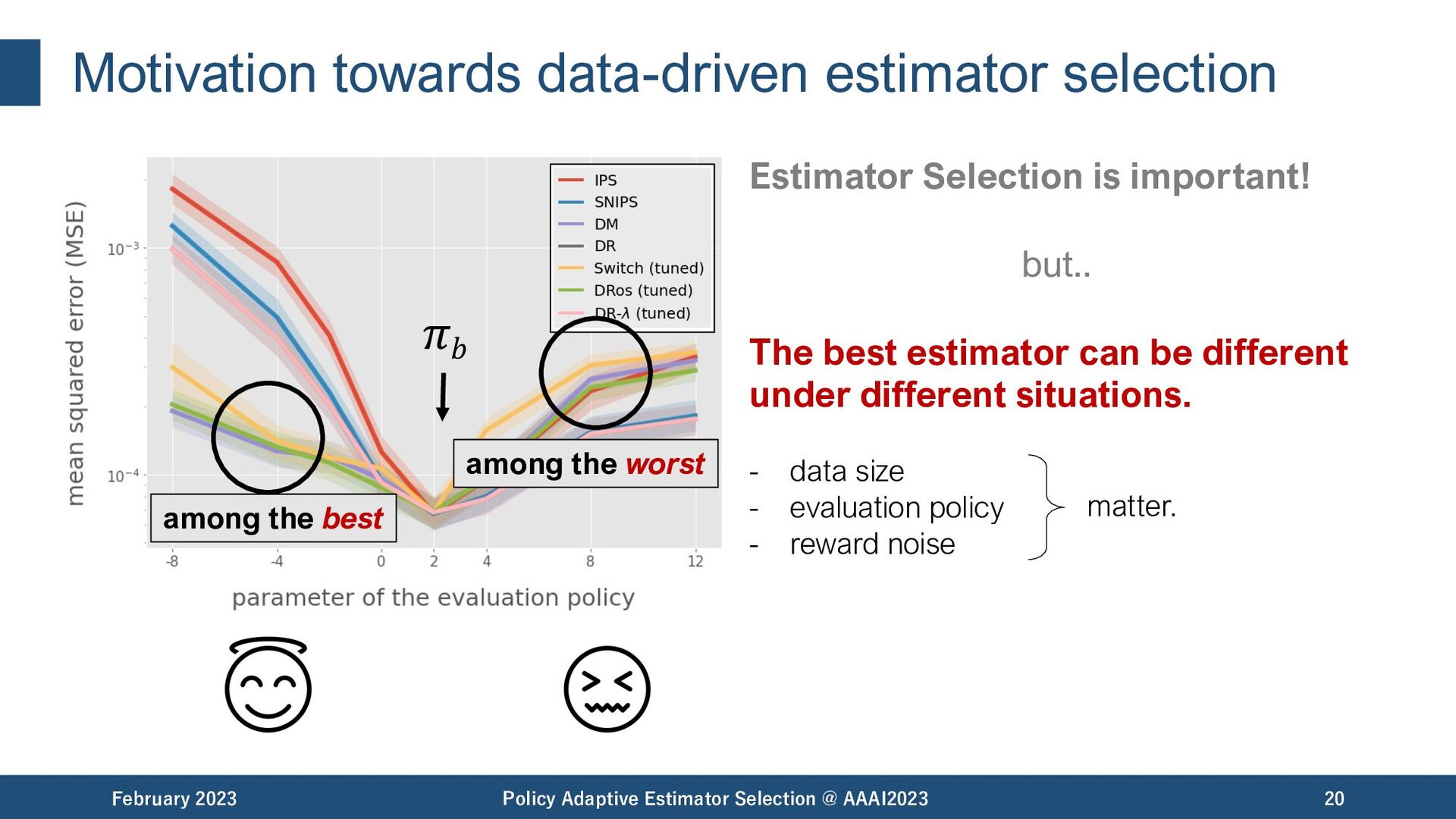
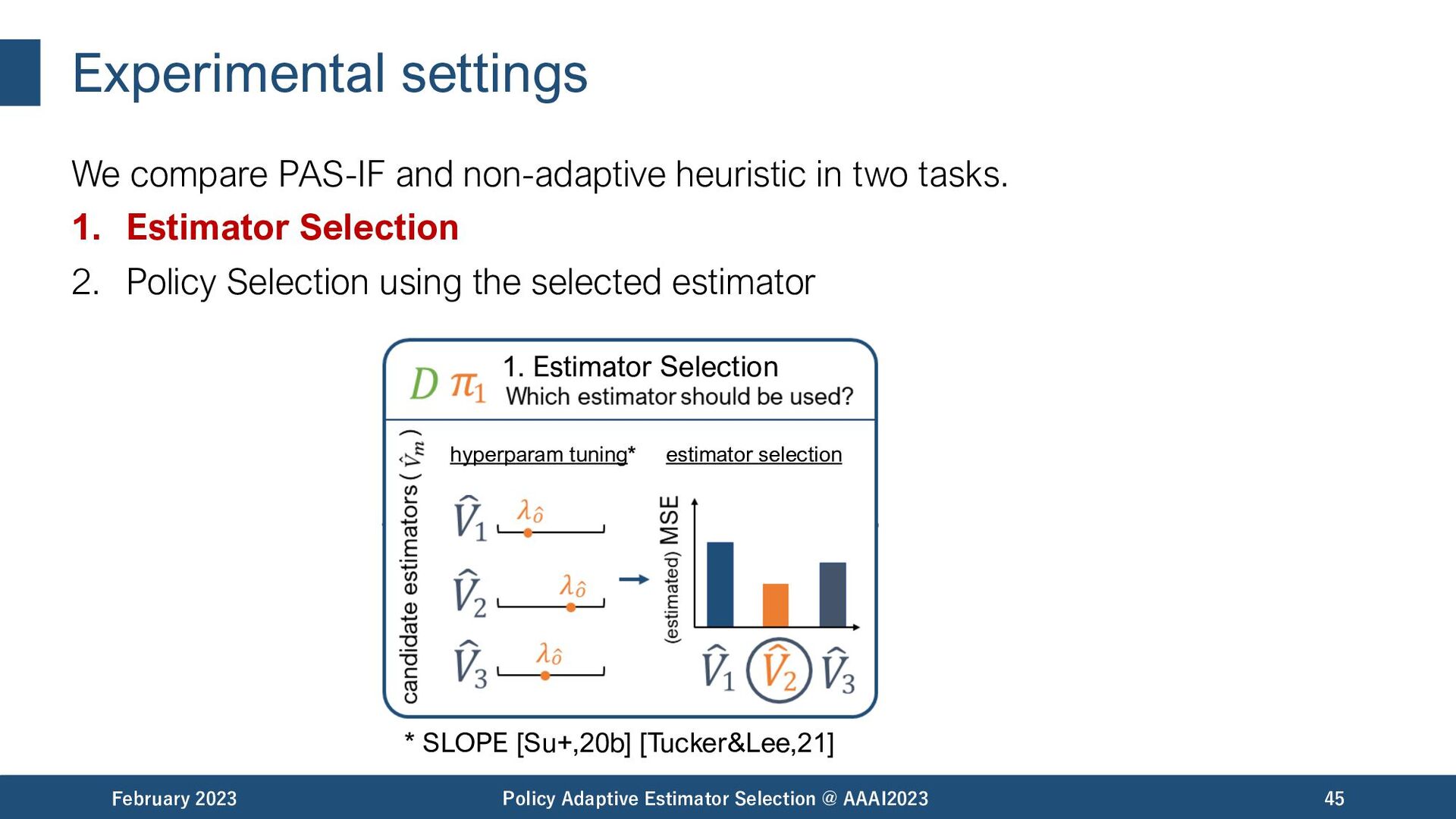
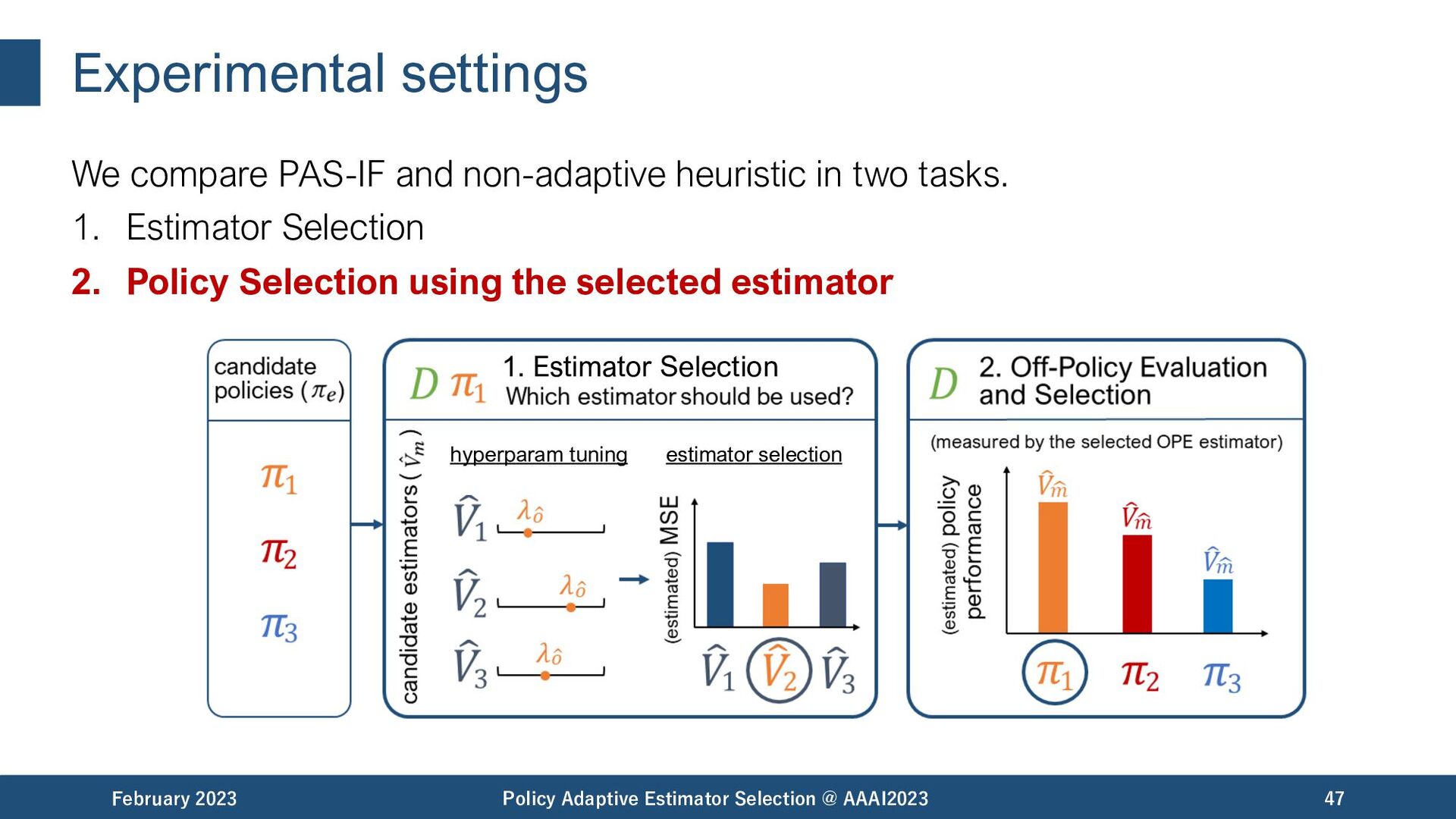
Selection @ AAAI2023 19 𝜋𝑏 among the best among the worst Estimator Selection is important! but.. The best estimator can be different under different situations.
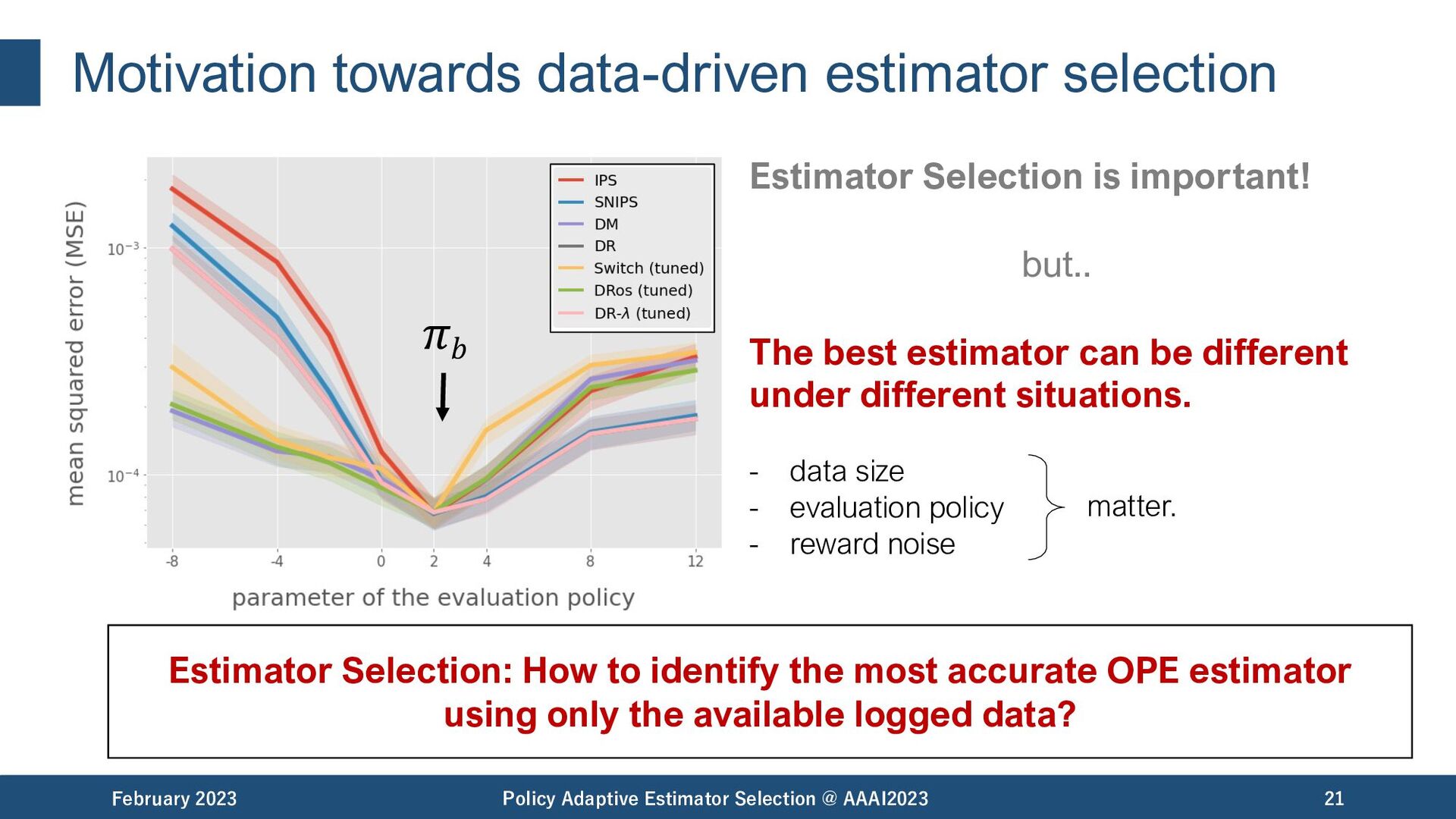
Selection @ AAAI2023 20 𝜋𝑏 among the best among the worst Estimator Selection is important! but.. The best estimator can be different under different situations. - data size - evaluation policy - reward noise matter.
Selection @ AAAI2023 21 𝜋𝑏 Estimator Selection: How to identify the most accurate OPE estimator using only the available logged data? Estimator Selection is important! but.. The best estimator can be different under different situations. - data size - evaluation policy - reward noise matter.
data from previous A/B tests. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 29 ※ 𝑆 is a set of random states for bootstrapping. pseudo-evaluation policy OPE estimate on-policy policy value
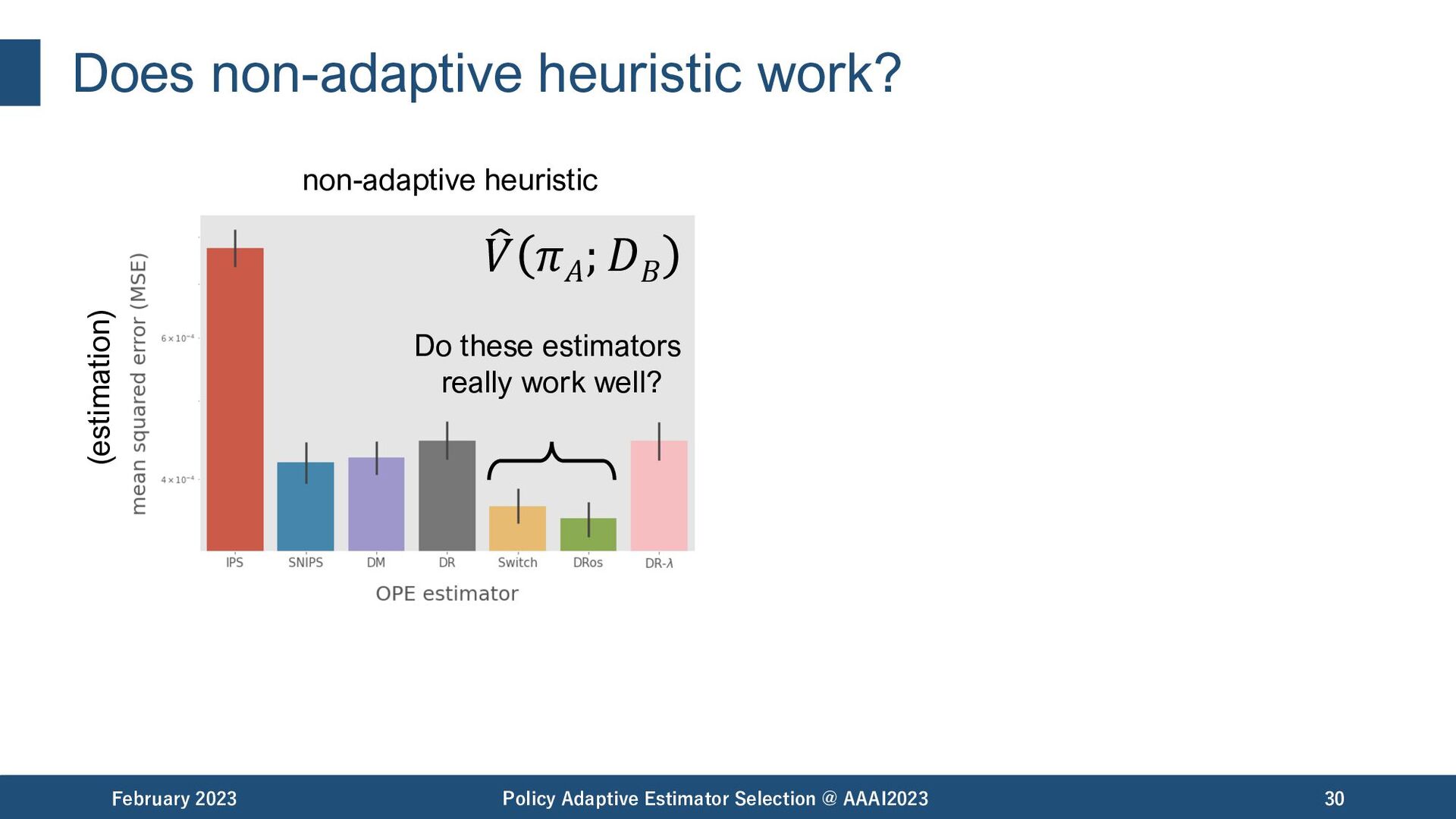
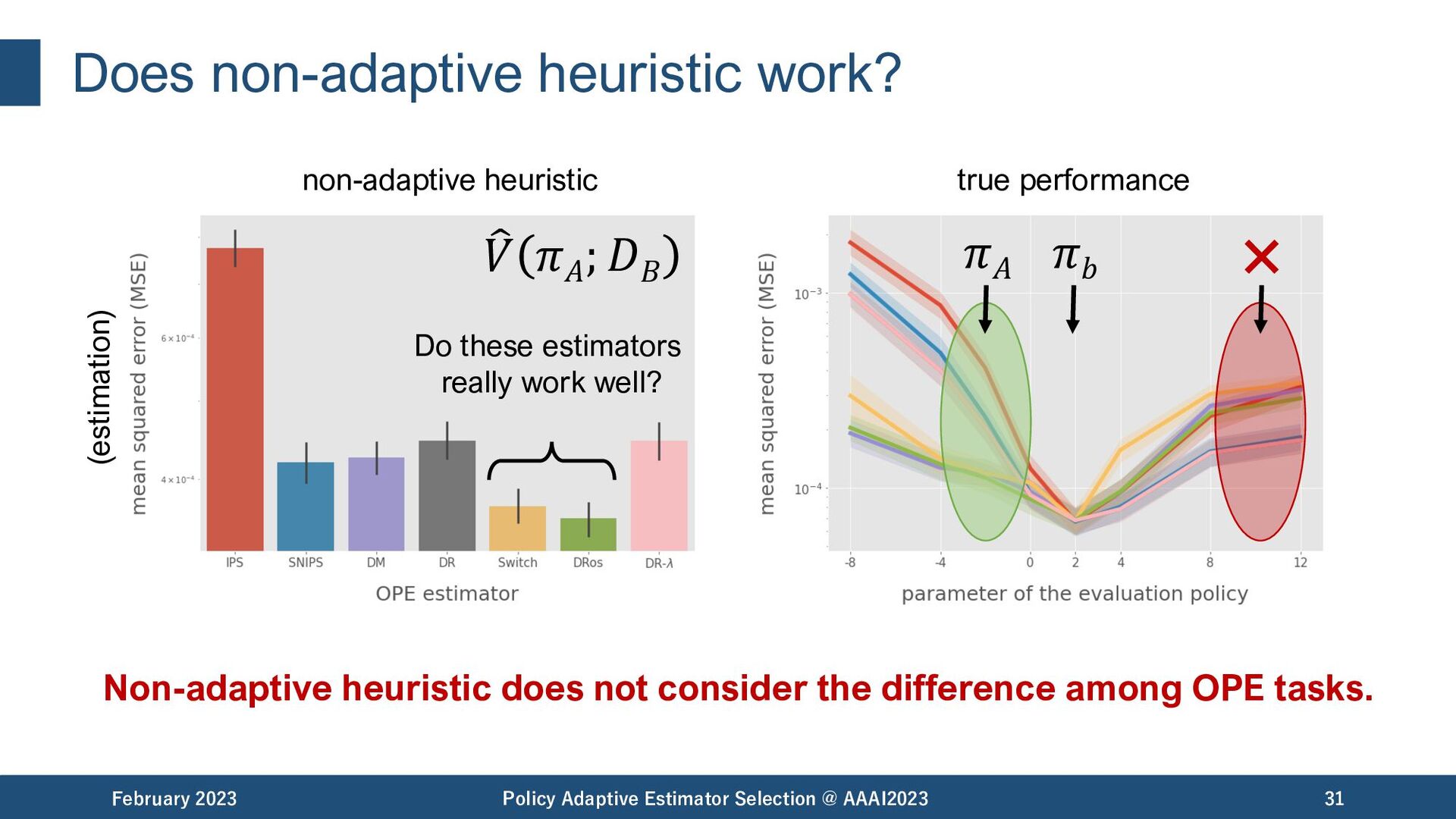
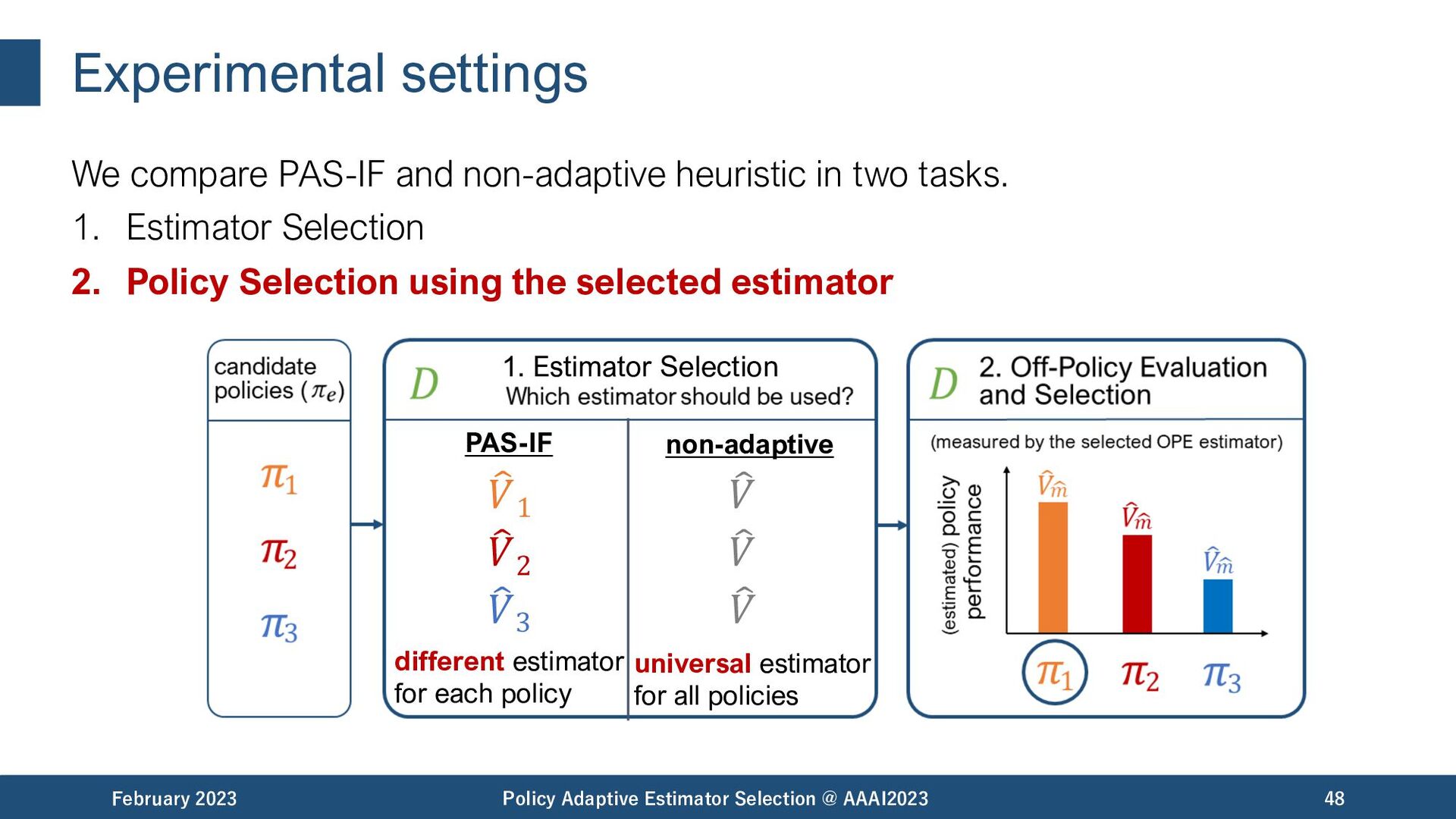
@ AAAI2023 31 𝜋𝑏 𝜋𝐴 Do these estimators really work well? non-adaptive heuristic true performance Non-adaptive heuristic does not consider the difference among OPE tasks. (estimation) " 𝑉 𝜋𝐴 ; 𝐷𝐵
@ AAAI2023 32 𝜋𝑏 𝜋𝐴 Do these estimators really work well? non-adaptive heuristic true performance Non-adaptive heuristic does not consider the difference among OPE tasks. (estimation) " 𝑉 𝜋𝐴 ; 𝐷𝐵 How to choose OPE estimators adaptively to the given OPE task (e.g., evaluation policy)?
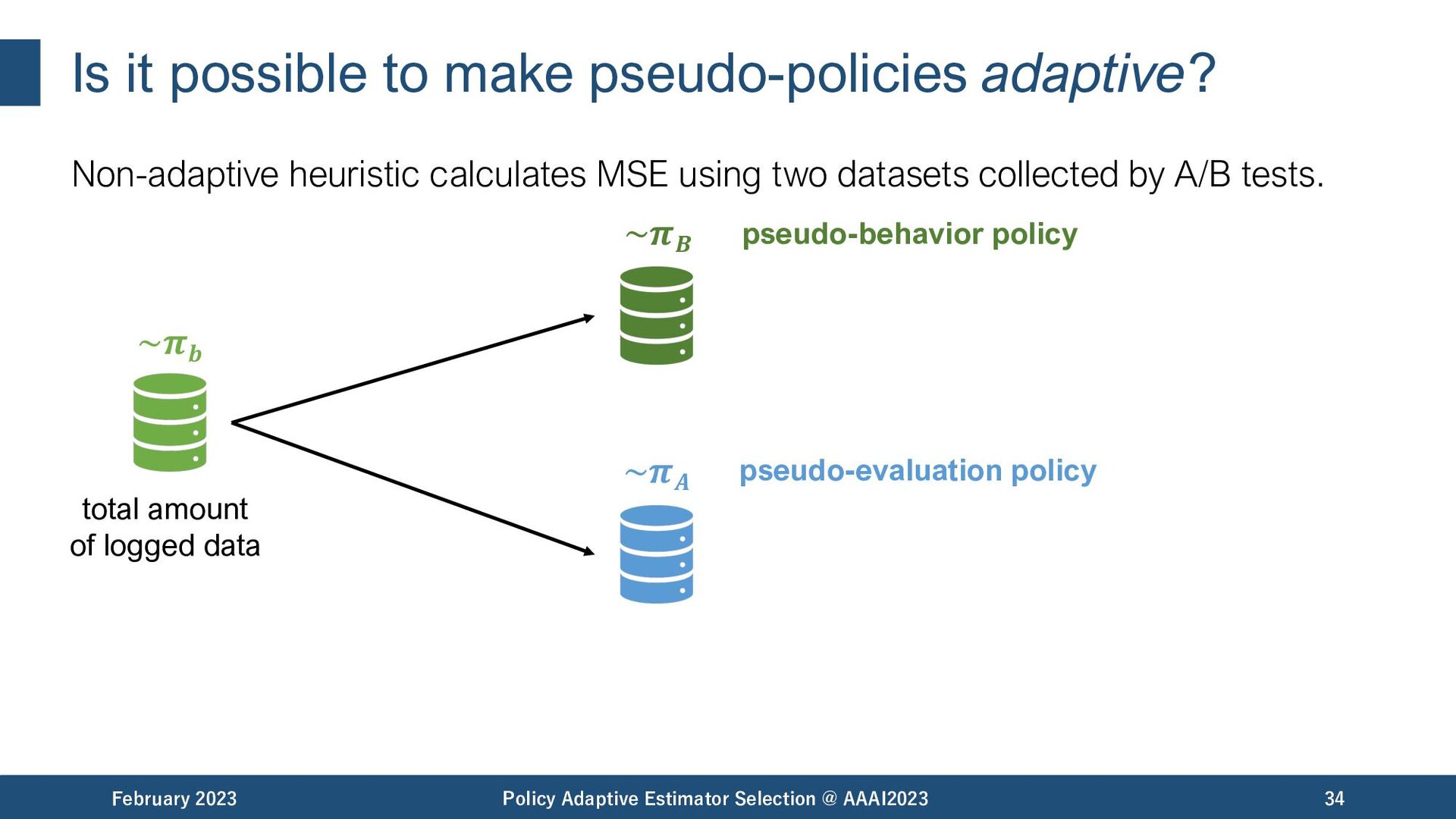
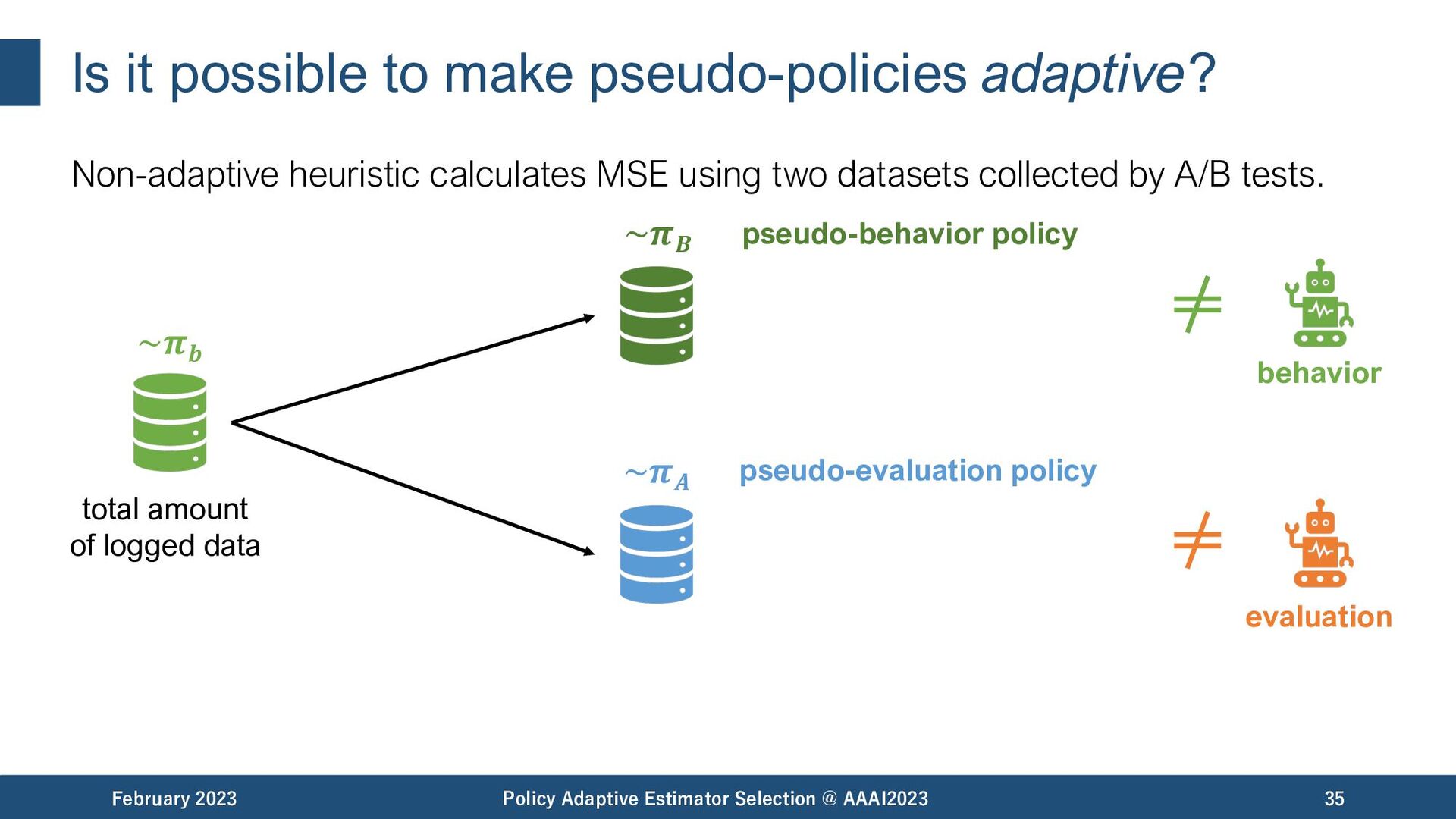
MSE using two datasets collected by A/B tests. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 34 ~𝝅𝒃 ~𝝅𝑩 ~𝝅𝑨 pseudo-behavior policy total amount of logged data pseudo-evaluation policy
MSE using two datasets collected by A/B tests. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 35 ~𝝅𝒃 ~𝝅𝑩 ~𝝅𝑨 pseudo-behavior policy total amount of logged data pseudo-evaluation policy behavior evaluation
MSE using two datasets collected by A/B tests. We aim to split the logged datasets adaptive to the given OPE task. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 36 ~𝝅𝒃 ~𝝅𝑩 ~𝝅𝑨 pseudo-behavior policy pseudo-evaluation policy ~$ 𝝅𝒃 ~$ 𝝅𝒆 total amount of logged data
function . February 2023 Policy Adaptive Estimator Selection @ AAAI2023 37 ~𝝅𝒃 pseudo-behavior policy total amount of logged data pseudo-evaluation policy ~$ 𝝅𝒃 ~$ 𝝅𝒆
function . February 2023 Policy Adaptive Estimator Selection @ AAAI2023 38 ~𝝅𝒃 pseudo-behavior policy total amount of logged data pseudo-evaluation policy ~$ 𝝅𝒃 ~$ 𝝅𝒆
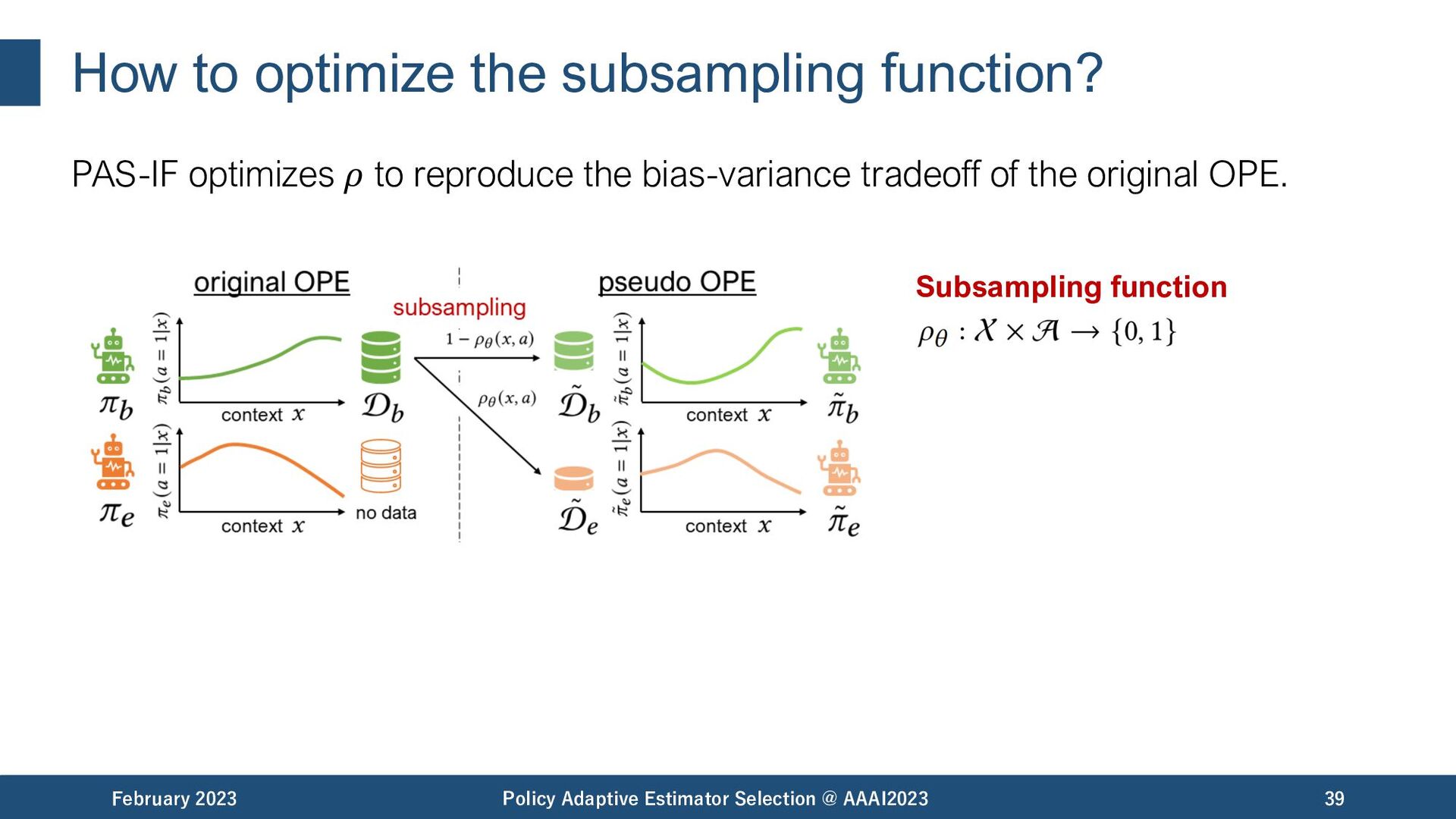
reproduce the bias-variance tradeoff of the original OPE. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 41 Objective of importance fitting: Subsampling function
February 2023 Policy Adaptive Estimator Selection @ AAAI2023 42 Data Driven -> by splitting the logged data into pseudo datasets Adaptive -> by optimizing subsampling function to simulate the distribution shift of the original OPE task Accurate Estimator Selection! . ->
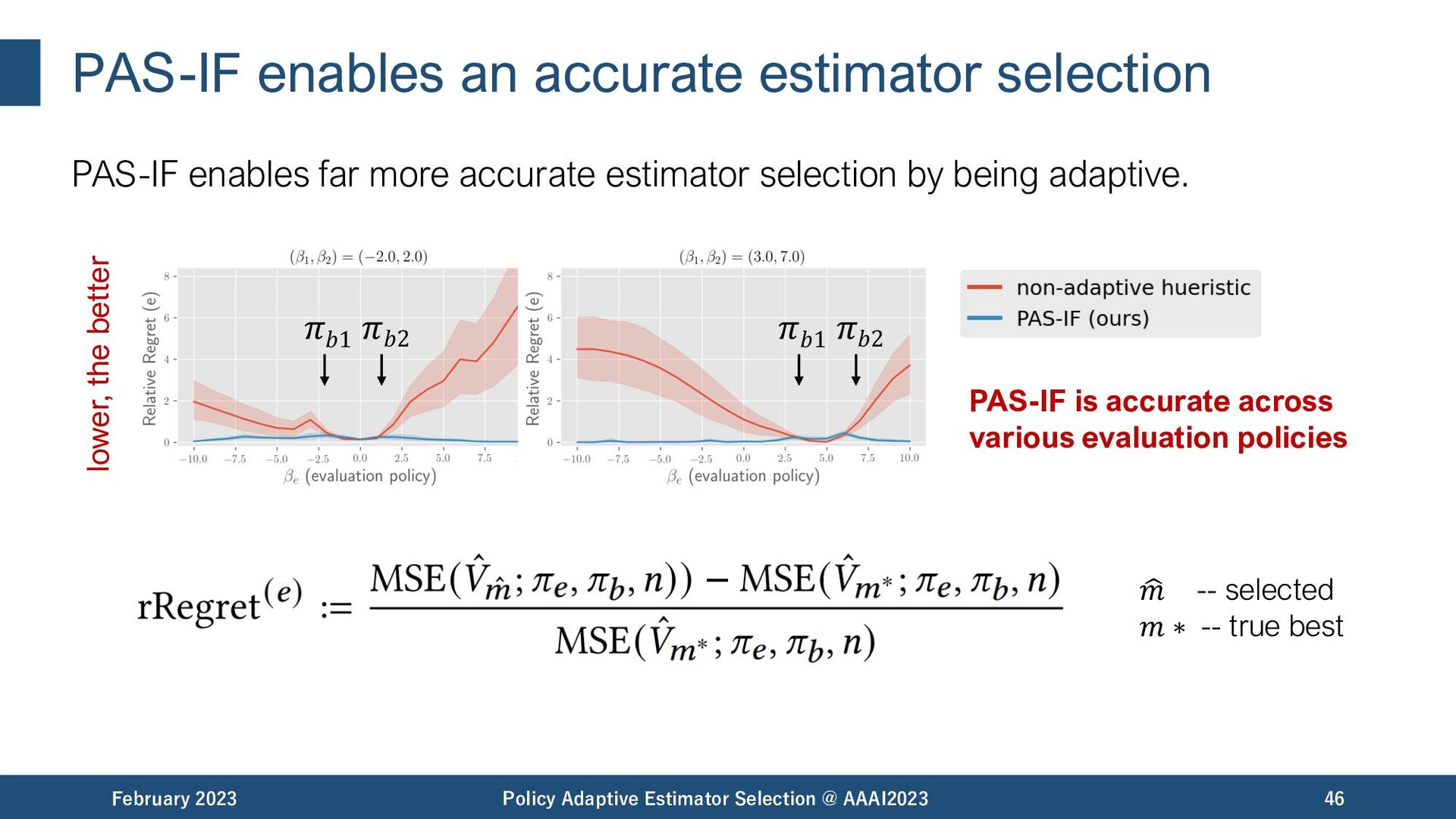
accurate estimator selection by being adaptive. February 2023 Policy Adaptive Estimator Selection @ AAAI2023 46 PAS-IF is accurate across various evaluation policies lower, the better 𝜋𝑏1 𝜋𝑏2 𝜋𝑏1 𝜋𝑏2 " 𝑚 -- selected 𝑚 ∗ -- true best
favorable result in the policy selection task. PAS-IF can identify better policies among many candidates by using different (appropriate) estimator for each policy! February 2023 Policy Adaptive Estimator Selection @ AAAI2023 49 lower, the better % 𝜋 -- selected 𝜋 ∗ -- true best
OPE. • Non-adaptive heuristic fails to be adaptive to the given OPE task. • PAS-IF enables an adaptive and accurate estimator selection by subsampling and optimizing the pseudo OPE datasets. PAS-IF will help identify an accurate OPE estimator in practice! February 2023 Policy Adaptive Estimator Selection @ AAAI2023 50
𝜌𝜃 via gradient decent. To maintain the similar data size with the original OPE task, PAS-IF also imposes the regularization on the data size. We tune 𝜆 so that . February 2023 Policy Adaptive Estimator Selection @ AAAI2023 53
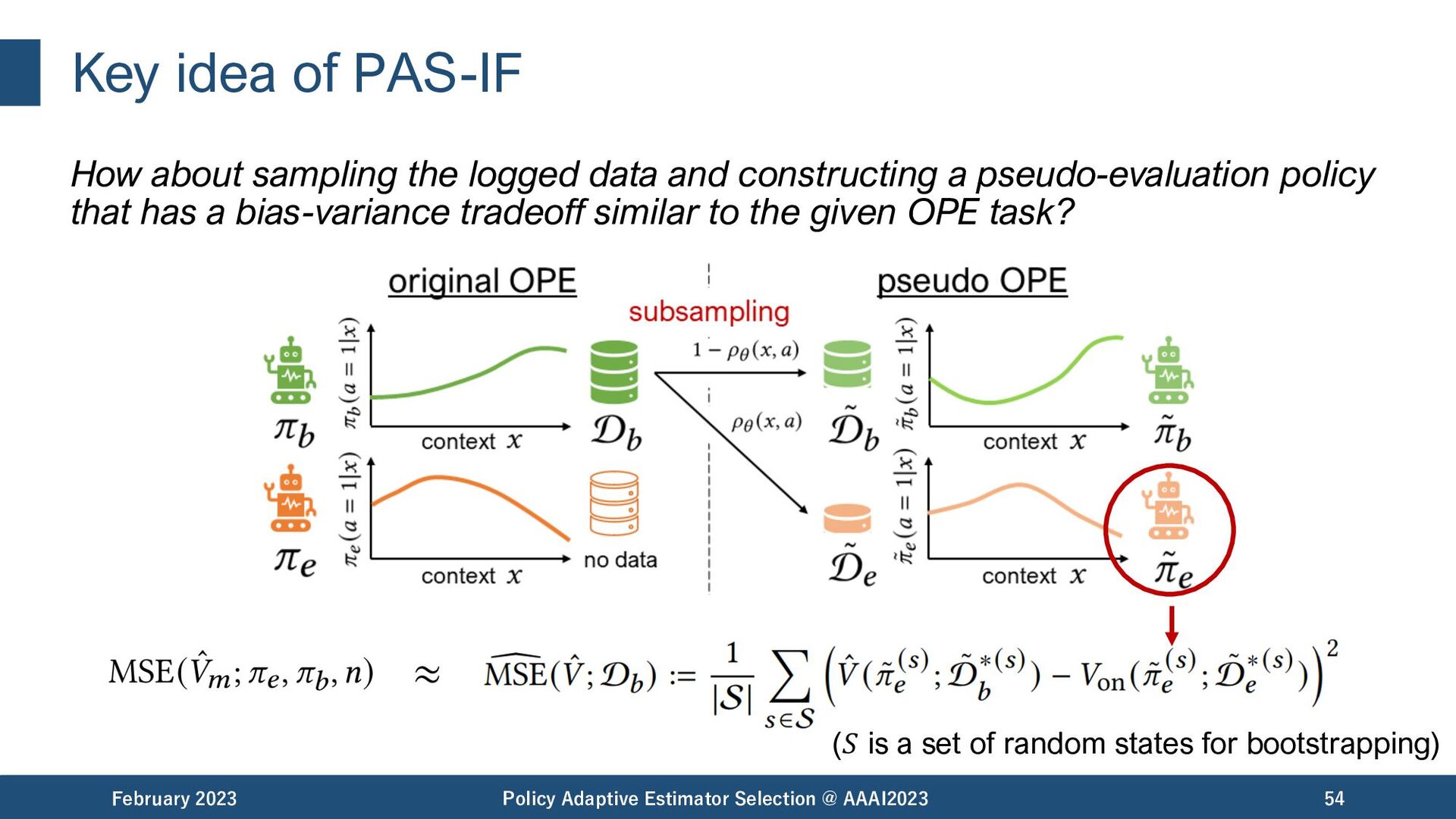
and constructing a pseudo-evaluation policy that has a bias-variance tradeoff similar to the given OPE task? February 2023 Policy Adaptive Estimator Selection @ AAAI2023 54 (𝑆 is a set of random states for bootstrapping)
Tree for Learning with Partial Labels.” KDD, 2009. [Precup+,00] Doina Precup, Richard S. Sutton, and Satinder Singh. “Eligibility Traces for Off-Policy Policy Evaluation.” ICML, 2000. https://scholarworks.umass.edu/cgi/viewcontent.cgi?article=1079&context=cs_facult y_pubs [Strehl+,10] Alex Strehl, John Langford, Sham Kakade, and Lihong Li. “Learning from Logged Implicit Exploration Data.” NeurIPS, 2010. https://arxiv.org/abs/1003.0120 [Dudík+,14] Miroslav Dudík, Dumitru Erhan, John Langford, and Lihong Li. “Doubly Robust Policy Evaluation and Optimization.” ICML, 2011. https://arxiv.org/abs/1503.02834 February 2023 Policy Adaptive Estimator Selection @ AAAI2023 56
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Baseline – non-adaptive heuristic [Saito+,21a] [Saito+,21b] Suppose we have logged](https://files.speakerdeck.com/presentations/5d10b9df16614f63bce48c160868889a/slide_25.jpg){kind=link}
![Baseline – non-adaptive heuristic [Saito+,21a] [Saito+,21b] Suppose we have logged](https://files.speakerdeck.com/presentations/5d10b9df16614f63bce48c160868889a/slide_26.jpg){kind=link}
![Baseline – non-adaptive heuristic [Saito+,21a] [Saito+,21b] Suppose we have logged](https://files.speakerdeck.com/presentations/5d10b9df16614f63bce48c160868889a/slide_27.jpg){kind=link}
![Baseline – non-adaptive heuristic [Saito+,21a] [Saito+,21b] Suppose we have logged](https://files.speakerdeck.com/presentations/5d10b9df16614f63bce48c160868889a/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References (1/4) [Beygelzimer&Langford,00] Alina Beygelzimer and John Langford. “The Offset](https://files.speakerdeck.com/presentations/5d10b9df16614f63bce48c160868889a/slide_55.jpg){kind=link}
![References (2/4) [Swaminathan&Joachims,15] Adith Swaminathan and Thorsten Joachims. “The Self-](https://files.speakerdeck.com/presentations/5d10b9df16614f63bce48c160868889a/slide_56.jpg){kind=link}
![References (3/4) [Su+,20a] Yi Su, Maria Dimakopoulou, Akshay Krishnamurthy, and](https://files.speakerdeck.com/presentations/5d10b9df16614f63bce48c160868889a/slide_57.jpg){kind=link}
![References (4/4) [Saito+,21a] Yuta Saito, Shunsuke Aihara, Megumi Matsutani, and](https://files.speakerdeck.com/presentations/5d10b9df16614f63bce48c160868889a/slide_58.jpg){kind=link}