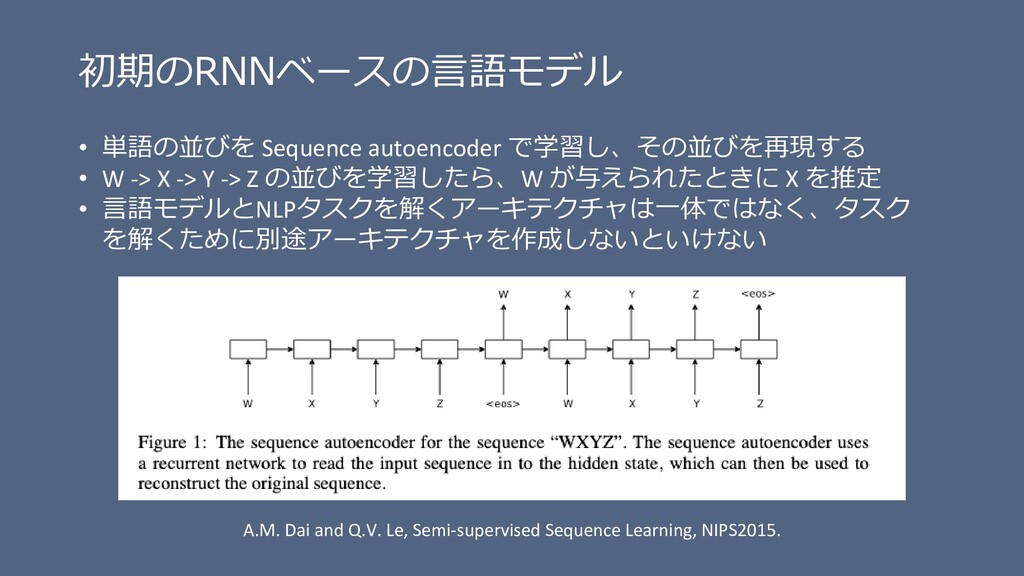
-> Y -> Z の並びを学習したら、W が与えられたときに X を推定 • 言語モデルとNLPタスクを解くアーキテクチャは一体ではなく、タスク を解くために別途アーキテクチャを作成しないといけない A.M. Dai and Q.V. Le, Semi-supervised Sequence Learning, NIPS2015.
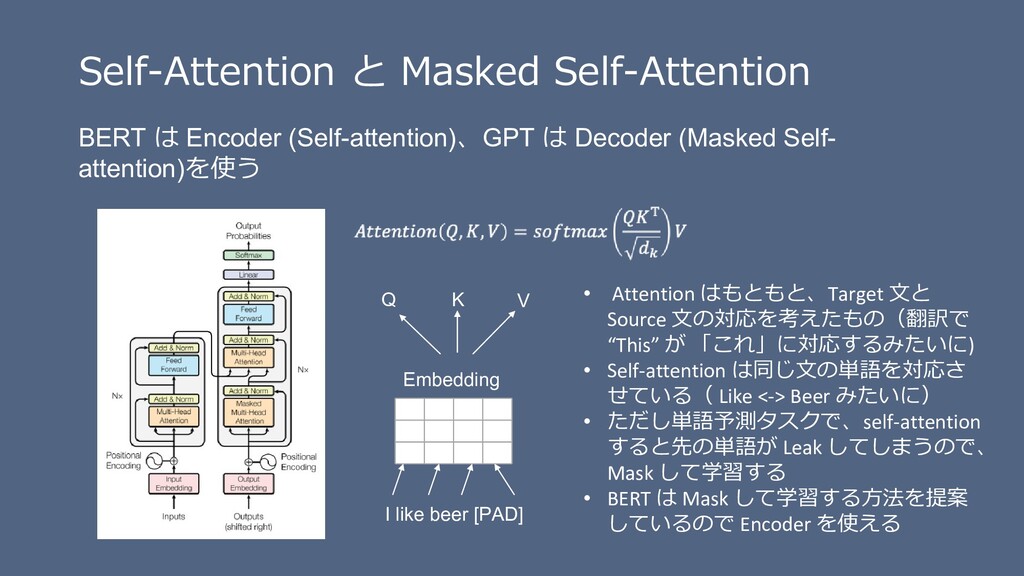
測も加味したモデル (Bidirectional) • 実用上優れた点として、様々なタス クを扱えるよう、入出力の表現を工 夫している (右図は入出力例) • 実際にタスクを解くためには、その タスクのデータを集めて fine-tuning しないといけない J. Devlin, et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019. https://www.aclweb.org/anthology/N19-1423/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}