data generated by smart machines in their customer-facing sales, billing, and service workflows. And by 2018, 6 billion “Things” will request support. 6 Billion Things Source: Gartner
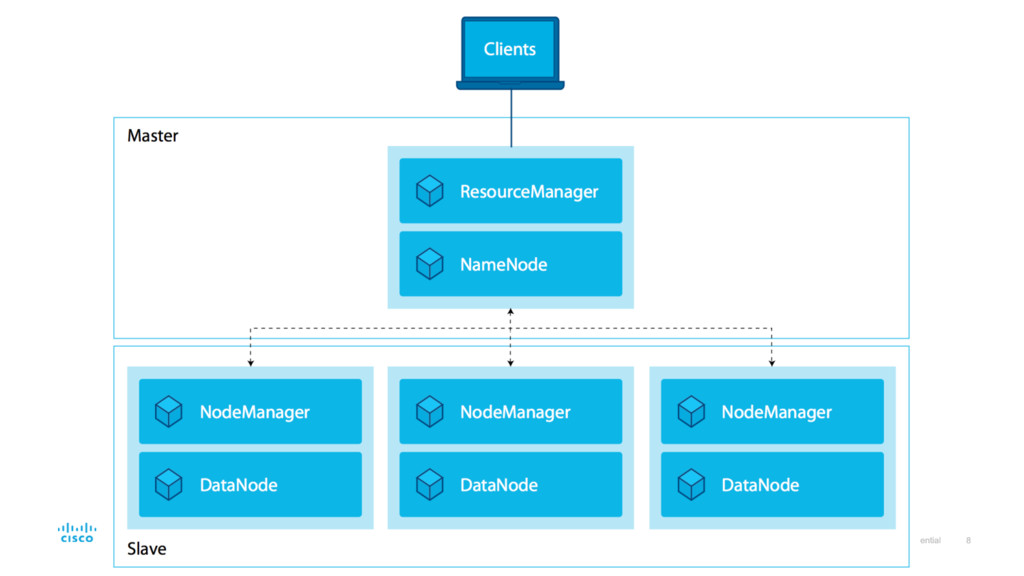
vast amounts of data (MapReduce, HBase, HDFS) • Yahoo! and Google are its biggest contributors • Attributes: • Scalable: Store and process petabytes of data • Economical: Processes across clusters of commonly available servers • Efficient: Processes in parallel on the nodes where the data is located • Reliable: Maintains multiple copies of the data • Highly available: Automatically redeploys computing tasks on failures What Is Hadoop?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}