Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
kntn02
Search
hikalium
January 14, 2017
Programming
0
150
kntn02
https://github.com/hikalium/kntn02
hikalium
January 14, 2017
Tweet
Share
Other Decks in Programming
See All in Programming
Fragmented Architectures
denyspoltorak
0
150
Automatic Grammar Agreementと Markdown Extended Attributes について
kishikawakatsumi
0
180
Vibe Coding - AI 驅動的軟體開發
mickyp100
0
170
フロントエンド開発の勘所 -複数事業を経験して見えた判断軸の違い-
heimusu
7
2.8k
CSC307 Lecture 02
javiergs
PRO
1
780
フルサイクルエンジニアリングをAI Agentで全自動化したい 〜構想と現在地〜
kamina_zzz
0
400
Honoを使ったリモートMCPサーバでAIツールとの連携を加速させる!
tosuri13
1
180
360° Signals in Angular: Signal Forms with SignalStore & Resources @ngLondon 01/2026
manfredsteyer
PRO
0
120
AI時代の認知負荷との向き合い方
optfit
0
160
The Past, Present, and Future of Enterprise Java
ivargrimstad
0
550
例外処理とどう使い分ける?Result型を使ったエラー設計 #burikaigi
kajitack
16
6k
AI Schema Enrichment for your Oracle AI Database
thatjeffsmith
0
270
Featured
See All Featured
The Curious Case for Waylosing
cassininazir
0
230
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
120
Making Projects Easy
brettharned
120
6.6k
Product Roadmaps are Hard
iamctodd
PRO
55
12k
How To Stay Up To Date on Web Technology
chriscoyier
791
250k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
0
250
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
64
The Mindset for Success: Future Career Progression
greggifford
PRO
0
240
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
60
42k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
130
Building Adaptive Systems
keathley
44
2.9k
The Curse of the Amulet
leimatthew05
1
8.4k
Transcript
None
目次 ・手法の検討 ・実装の詳細 ・結果 ・まとめ
手法の検討
元のデータは一体…? ・ある「モデル」で生成されている → 誰かのDNA配列? 画像データ? → モデルを推定できるだろうか?
正解データrefの視覚化
法則はなさそうに見える ・目で見るのは限界がある ・周期性を見つけたい → フーリエ変換!
ランダム 正解データ 視覚化したデータのフーリエ変換像 ランダムなデータと正解データは異なる!
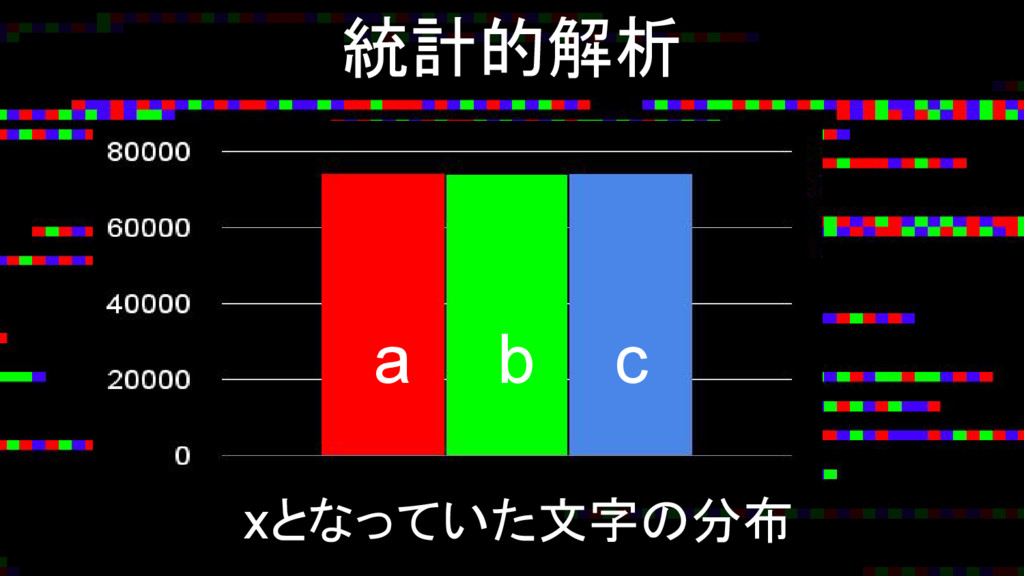
統計的解析 xとなっていた文字の分布 a b c
統計的解析 正解文字列中の3-gram 分布 同じ文字が連続しない場合 (12パターン) 同じ文字が2連続する場合 (12パターン) 同じ文字が3連続する場合(3パターン)
統計的解析からわかること 同じ文字が連続して出現する可能性は低い 連続しない: 79.0% 2文字連続: 19.8% 3文字連続: 1.2%
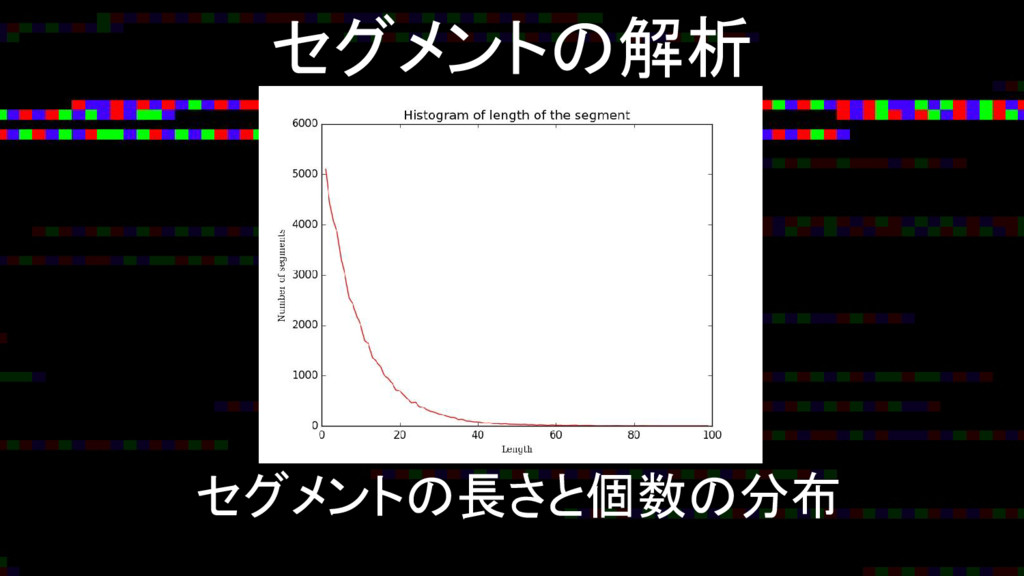
セグメントの解析 セグメントの長さと個数の分布
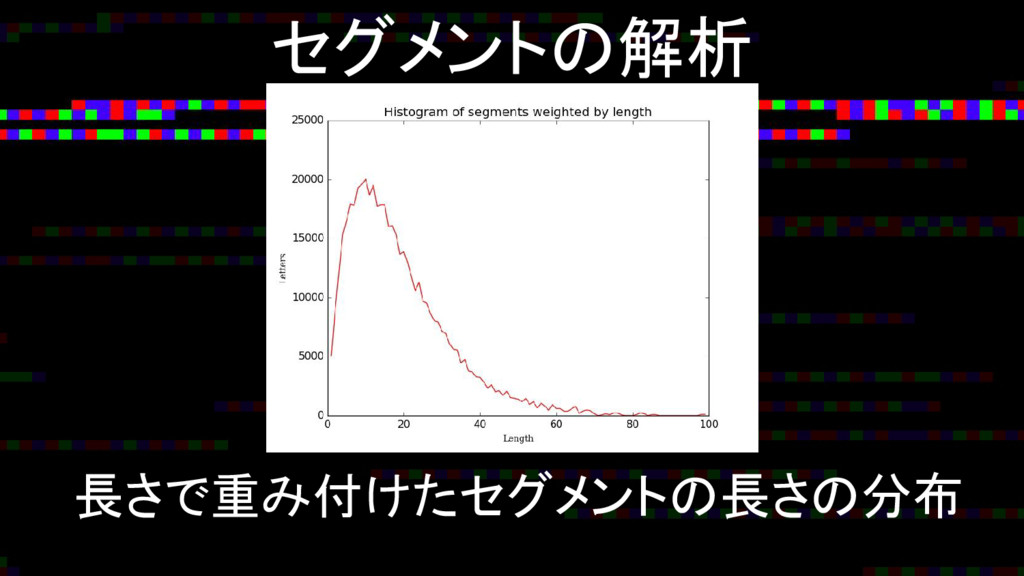
セグメントの解析 長さで重み付けたセグメントの長さの分布
そもそも精度100%は可能か 不可能 1文字のセグメント:1700個ほどある 生成モデルも不明 (実は機械学習も試したがダメだった)
2種類の手法の組み合わせ 1. 確実に修復 → 修復した箇所は100%正解 2. 確率的に修復 → 誤った修復をする可能性あり
実装の詳細 〜確実に修復〜
確実に修復 利用可能な情報:2種類 T' = 虫食いデータ Segment = 切れ端 → 全部つなげると元の文書になる
セグメントの配置決定 T'とセグメント情報を利用 → 挿入可能offsetをリストアップ xを無視した完全一致をとる 挿入可能offsetが一つしかないSegment → そこに配置するしかない = 決定!
セグメントの配置決定 セグメントを配置 → 配置可能箇所が減少する可能性 セグメントは重複しないため → 他のセグメントが決定可能になるかも → これ以上決定できなくなるまで反復
セグメントの解析結果 25文字以下のセグメント → ほぼ確定不可能 35文字以上のセグメント → ほぼ確定できる
セグメント配置の高速化 毎回検索していては遅すぎる! → 配置可能ofsのテーブルを 最初に生成 そのテーブル生成も遅い! → prefixツリーをその前に生成 → テーブル生成を10秒に短縮
実装の詳細 〜確率的修復〜
1: もっともらしいoffsetに配置 セグメントの配置先範囲に含まれる… ・多くのa,b,cで一致しているoffset かつ ・a,b,cの数が一定以上のoffset に優先的に配置する
2: 長いセグメントから配置 長いセグメントほど置ける場所は少ない → 正解の可能性が高い と考える →長いセグメントで上書きしていく (確定的に配置された部分は上書きしない)
結果
None
入力データT'の視覚化
確実に修復されたセグメント 全体の14.5%程度
さらに確率的修復をした結果
正解データと比較
テストデータにおける実績 test1 83.46% test2 83.50% test3 83.32% test4 83.68% test5
83.42%
テストデータにおける実績 だいたい30秒以下 on 1.3 GHz Intel Core i5 (きっと計測環境はもっと速いはず…!)
まとめ
まとめ 速度と精度のトレードオフはよくとれた しかし 精度はそこまで上がらなかった → 決定的なモデルではなくて 確率的モデル?
Contributors
Source Code https://github.com/hikalium/kntn02
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}