ケモメトリックス
データセットの定義
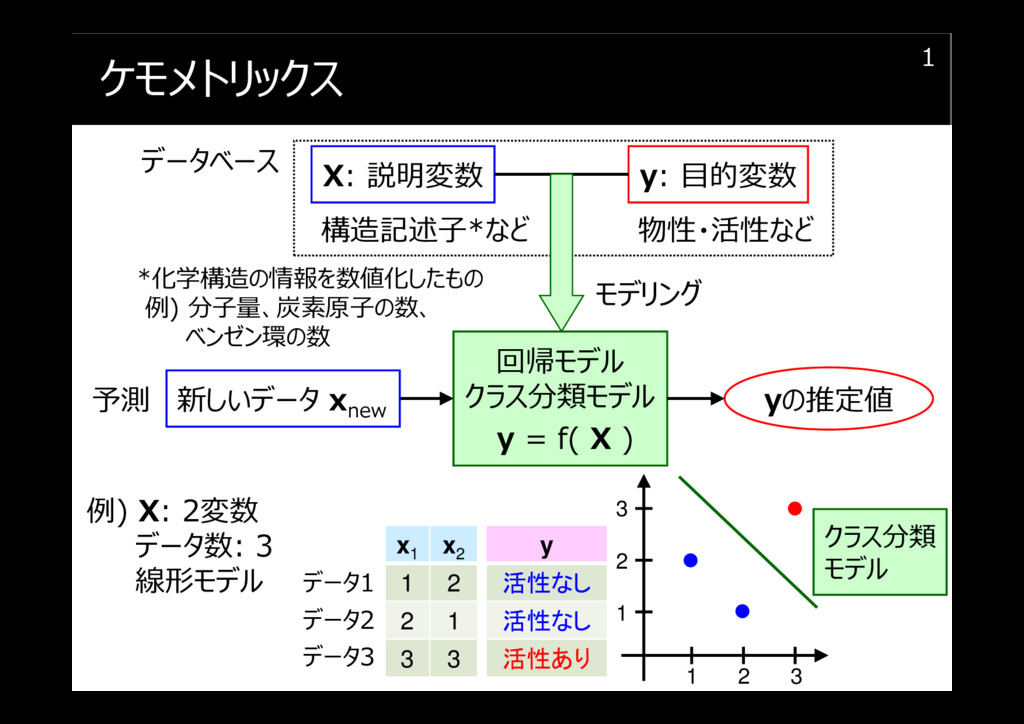
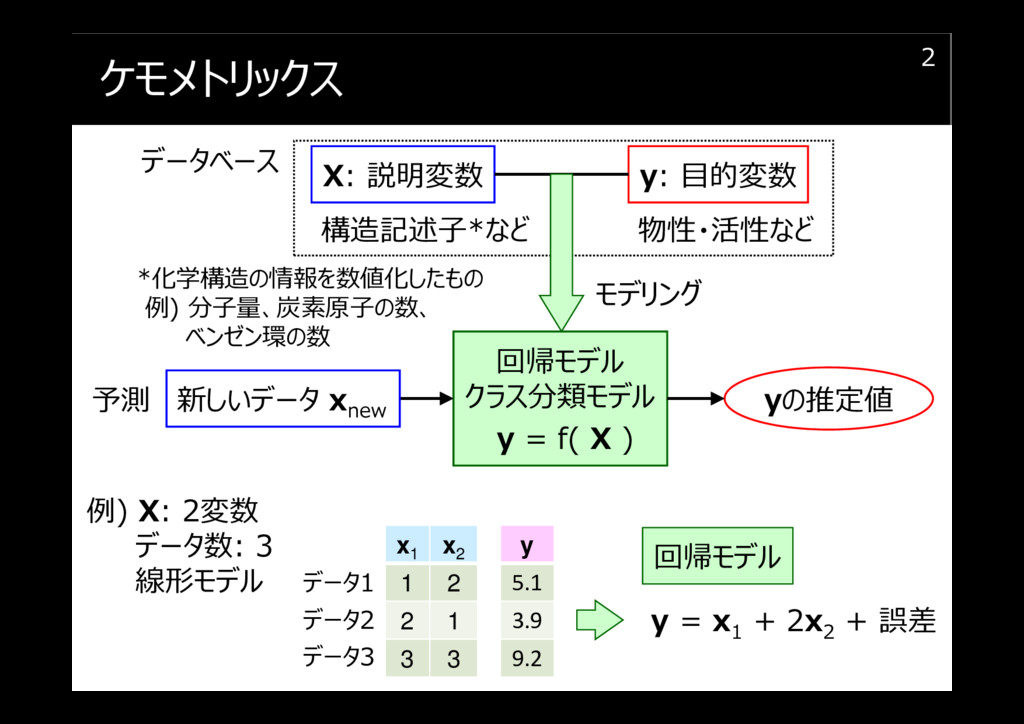
内容 1/2
内容 2/2
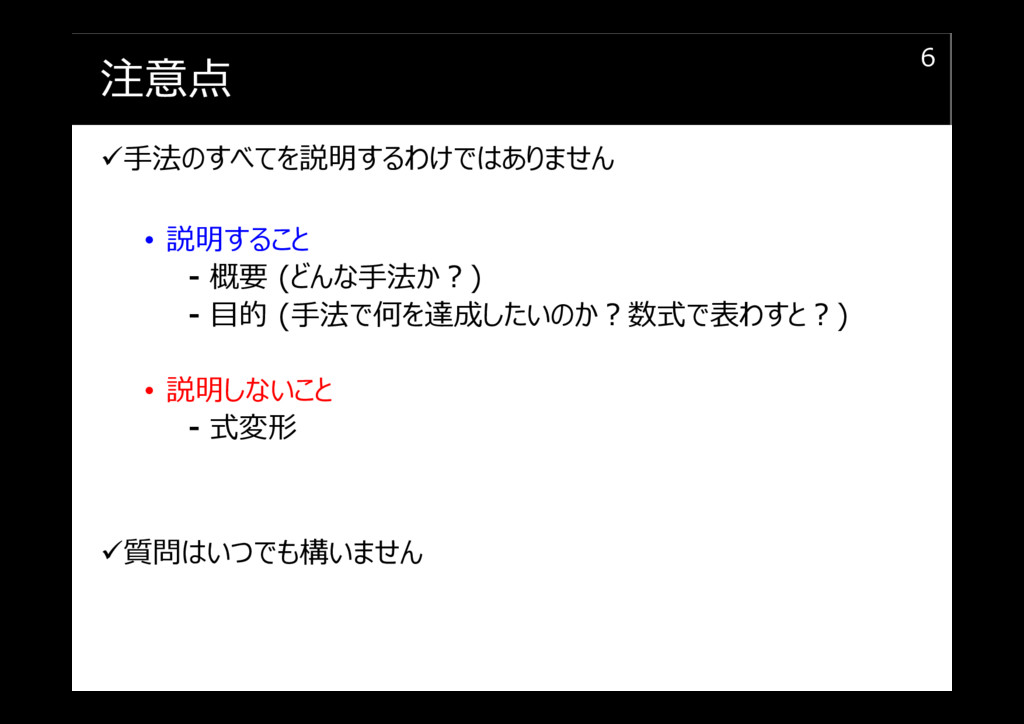
注意点
どうしてデータの前処理をするの?
オートスケーリング (標準化)
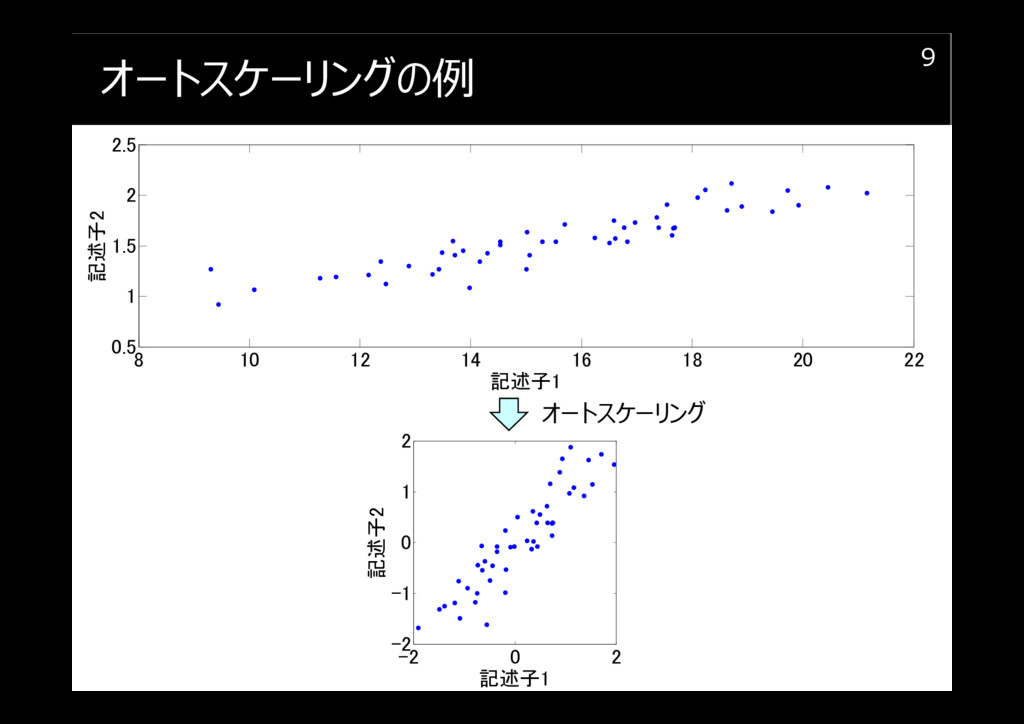
オートスケーリングの例
センタリング
スケーリング
モデル検証用(テスト)データのオートスケーリング
分散が0の変数の削除
同じ値を多くもつ変数の削除
注意点
相関係数の高い変数の組の1つの削除
しきい値は?どちらを消す?
注意
内容 1/2
入門編の復習
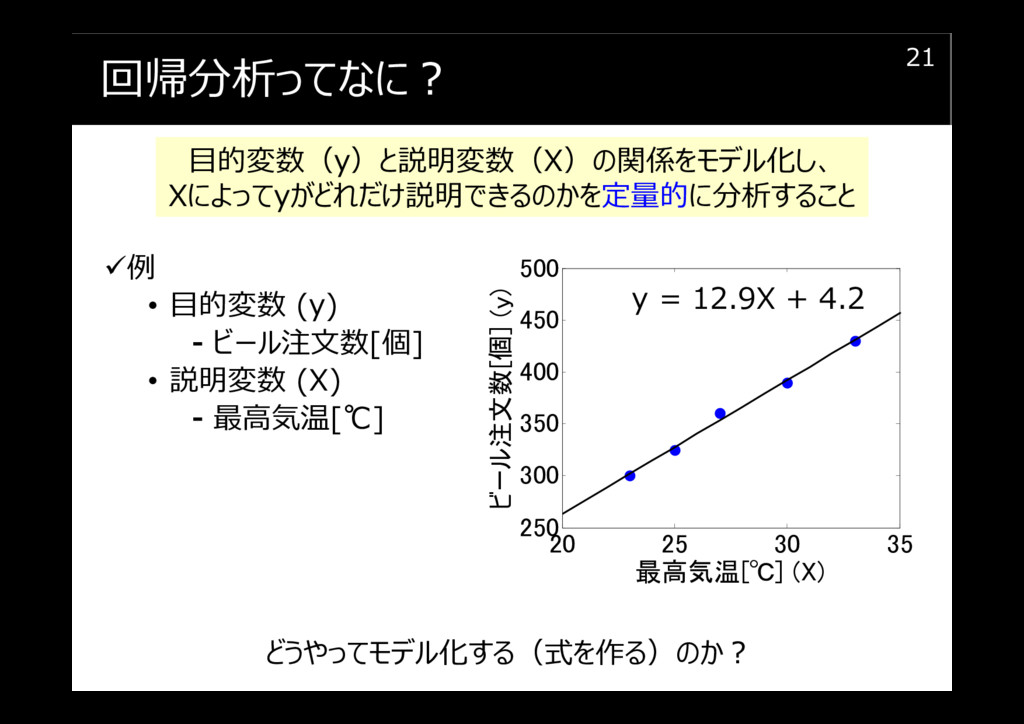
回帰分析ってなに?
最小二乗法による線形重回帰分析
最小二乗法による重回帰分析
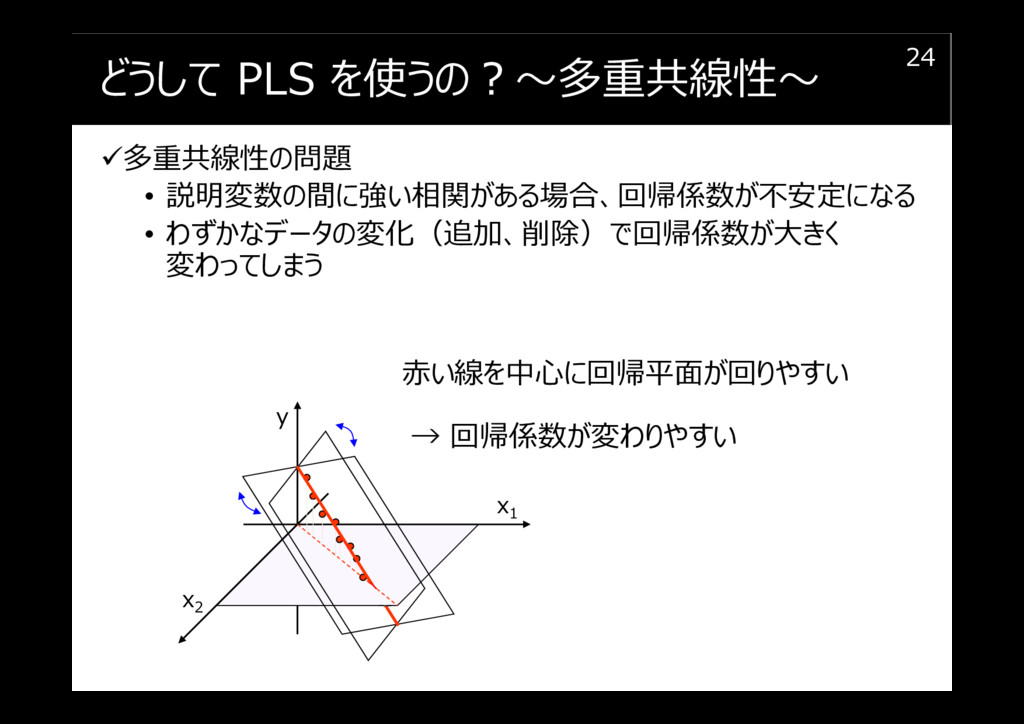
どうして PLS を使うの?~多重共線性~
PLS とは?
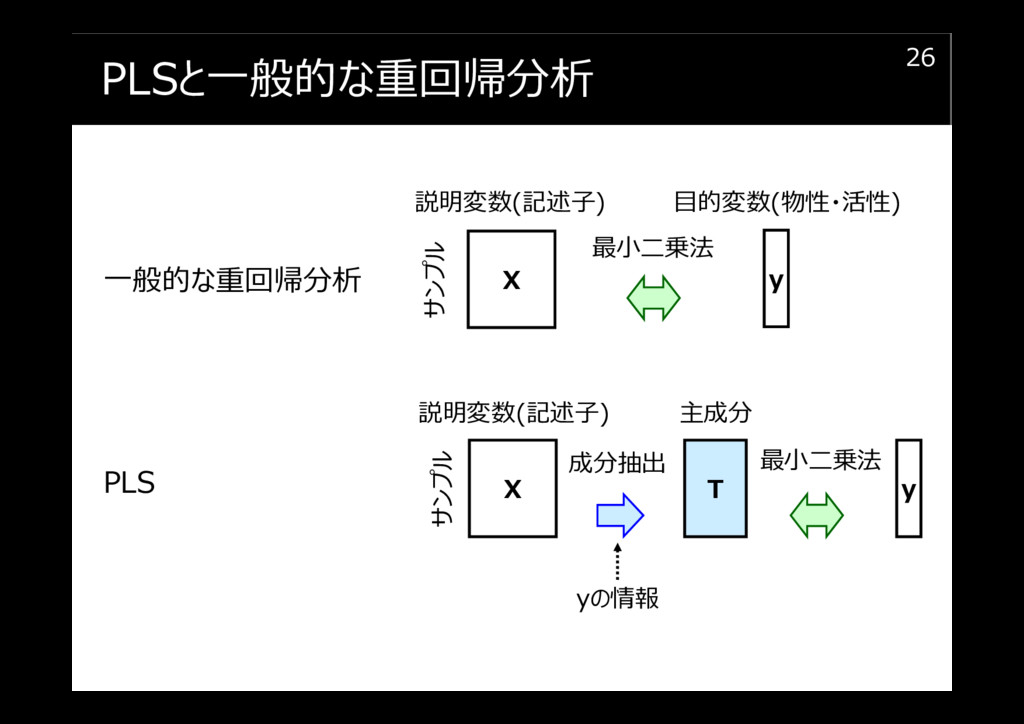
PLSと一般的な重回帰分析
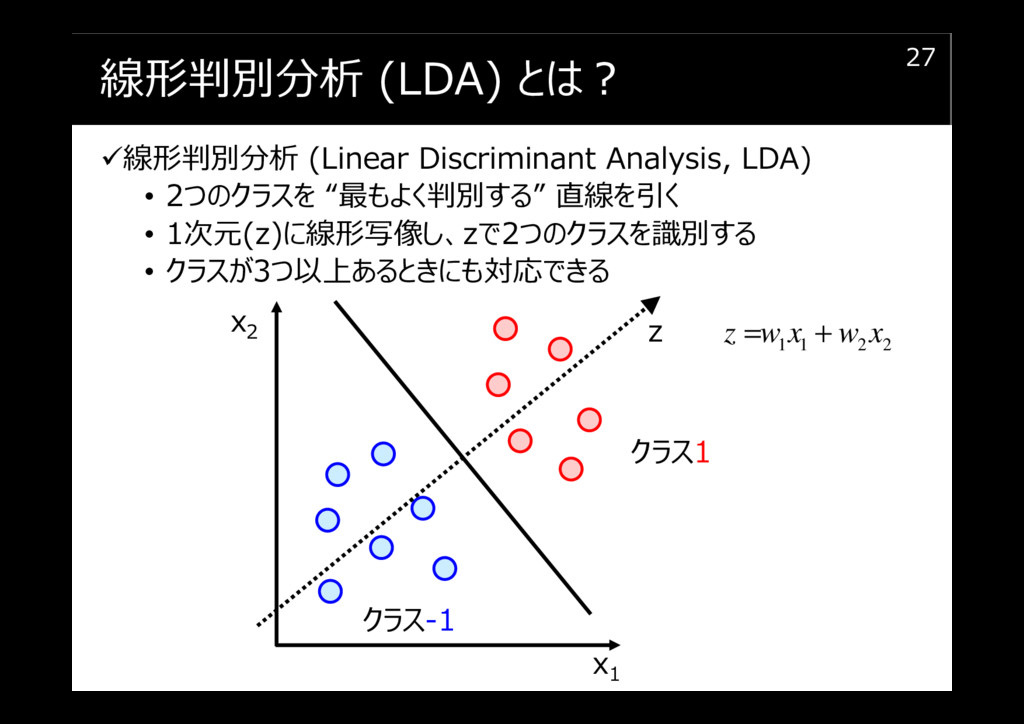
線形判別分析 (LDA) とは?
“最もよく判別する” とは?
重み w の求め方
サポートベクターマシン (SVM) とは?
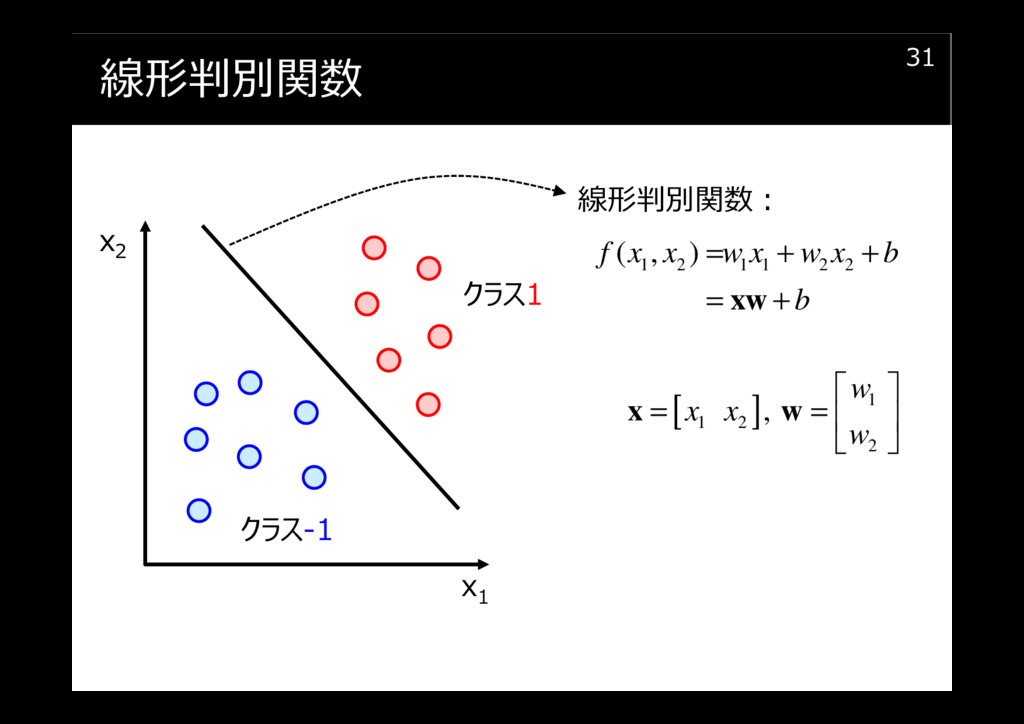
線形判別関数
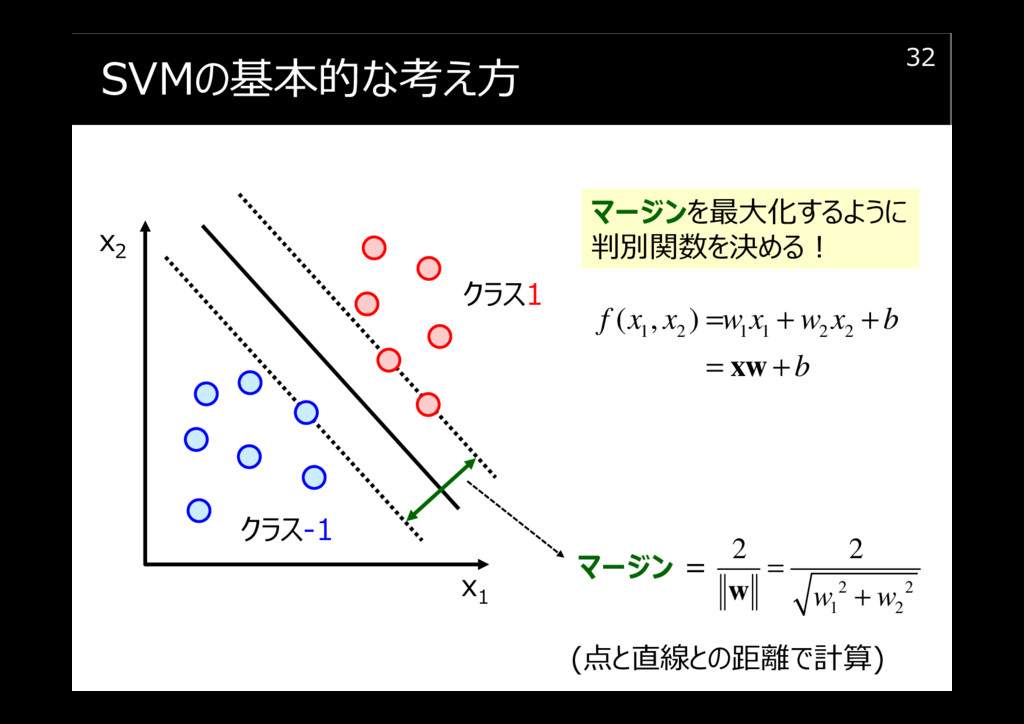
SVMの基本的な考え方
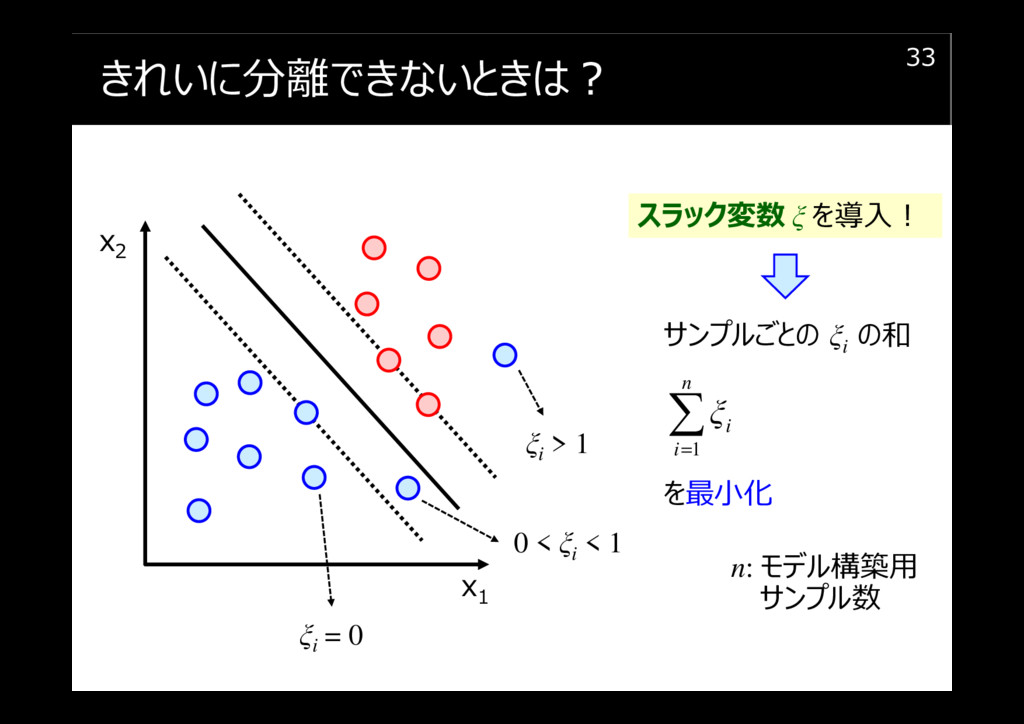
きれいに分離できないときは?
2つの項を一緒に最小化
線形判別関数
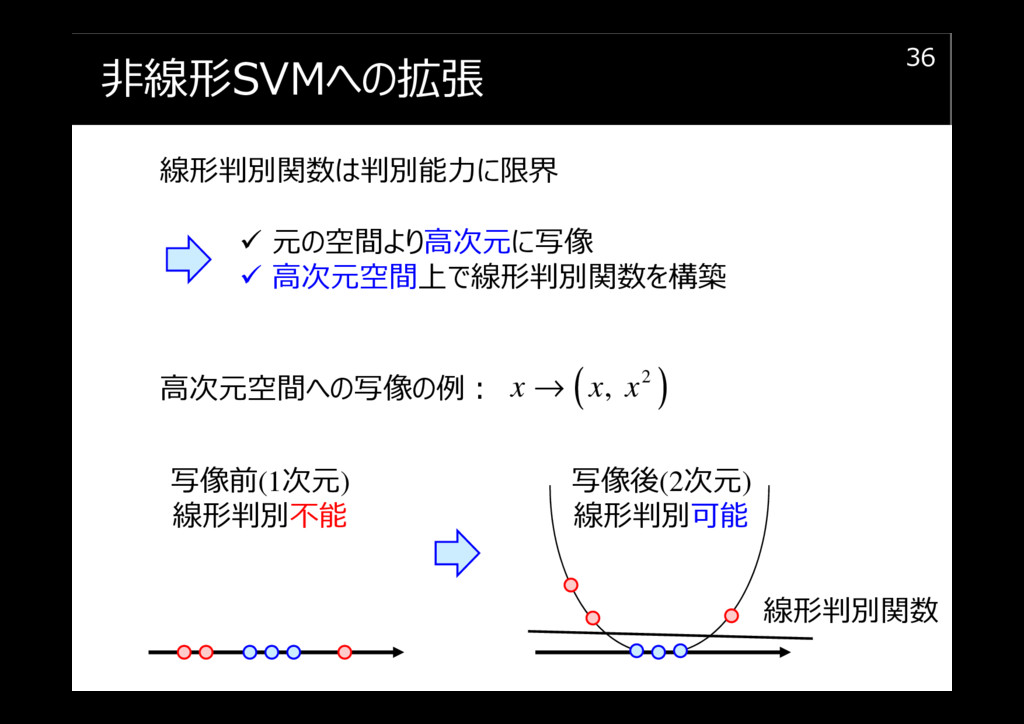
非線形SVMへの拡張
カーネルトリック
カーネル関数の例
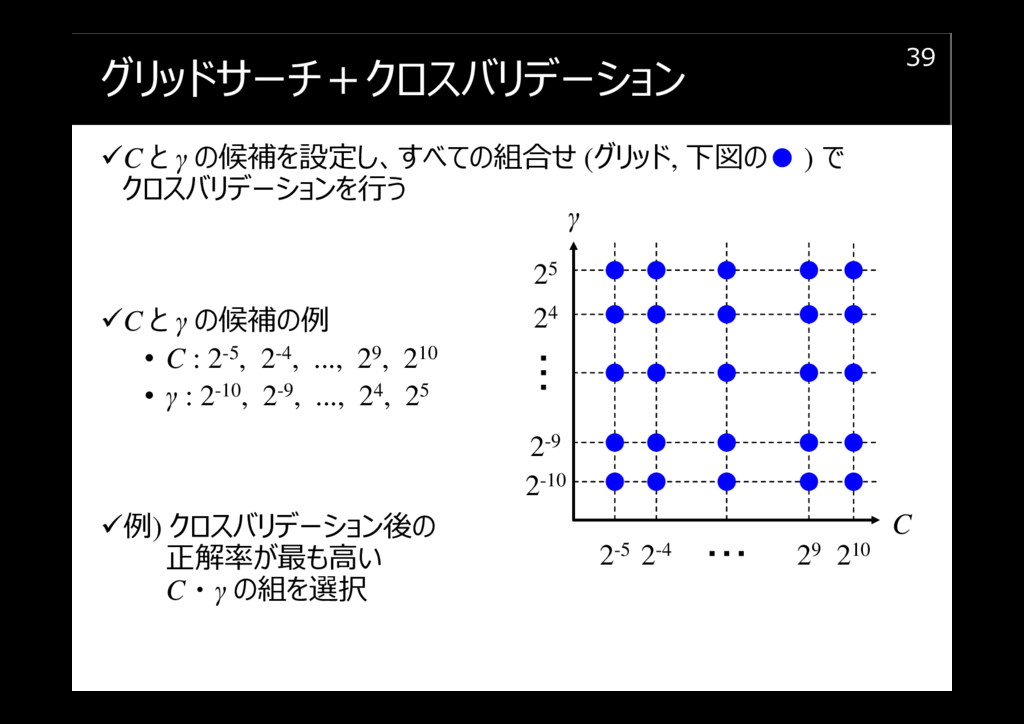
グリッドサーチ+クロスバリデーション
内容 1/2
“良い”回帰モデル・クラス分類モデルとは何か?
データセットの呼び方
比較指標
回帰分析 決定係数 r2
回帰分析 RMSE
回帰分析 MAE
クラス分類 混同行列・正解率・精度・検出率
クラス分類 Kappa係数
モデルの評価・比較 ハイパーパラメータの決定
どのようなハイパーパラメータを用いるか?
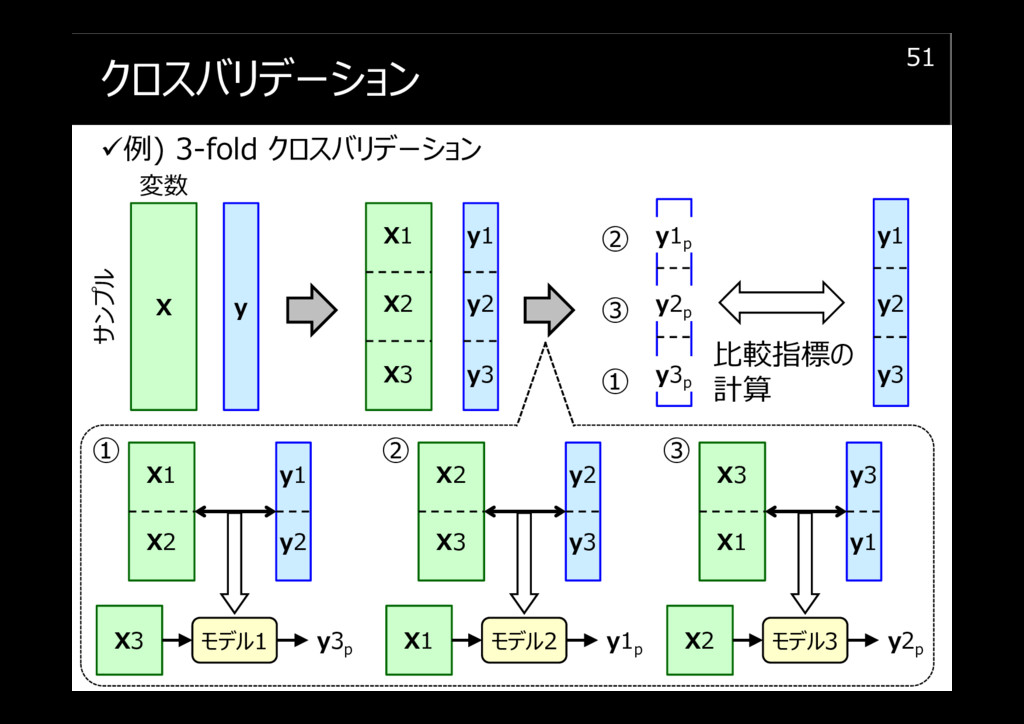
クロスバリデーション
クロスバリデーションの補足
どのようにデータセットを分けるか?
Y-randomization (Yランダマイゼイション)
内容 1/2
決定木 (Decision Tree, DT) とは?
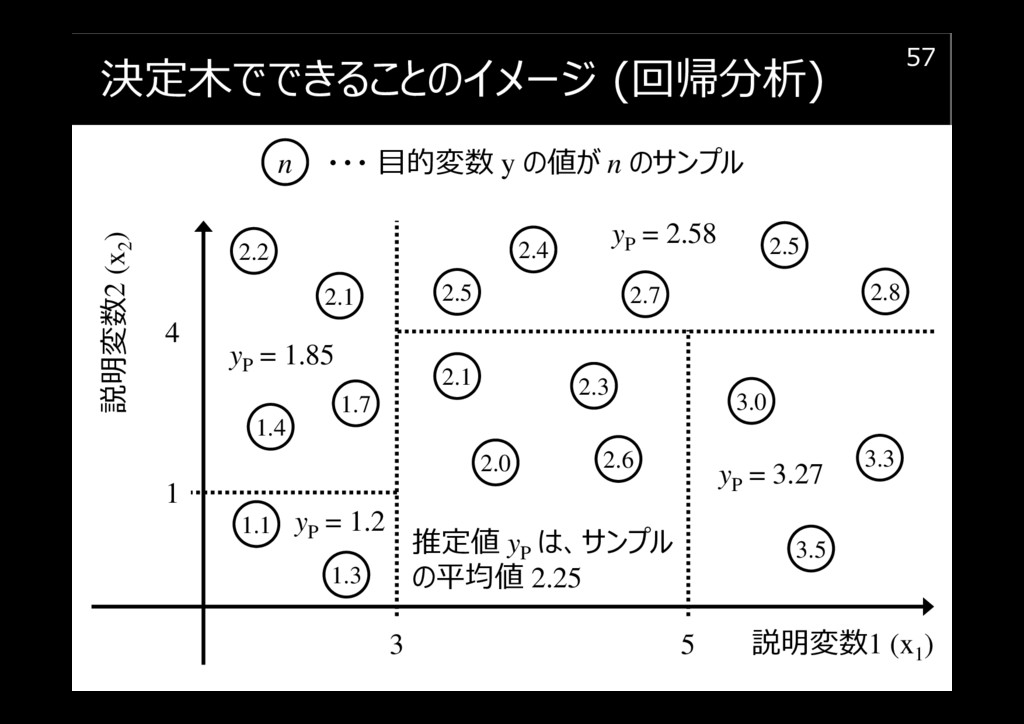
決定木でできることのイメージ (回帰分析)
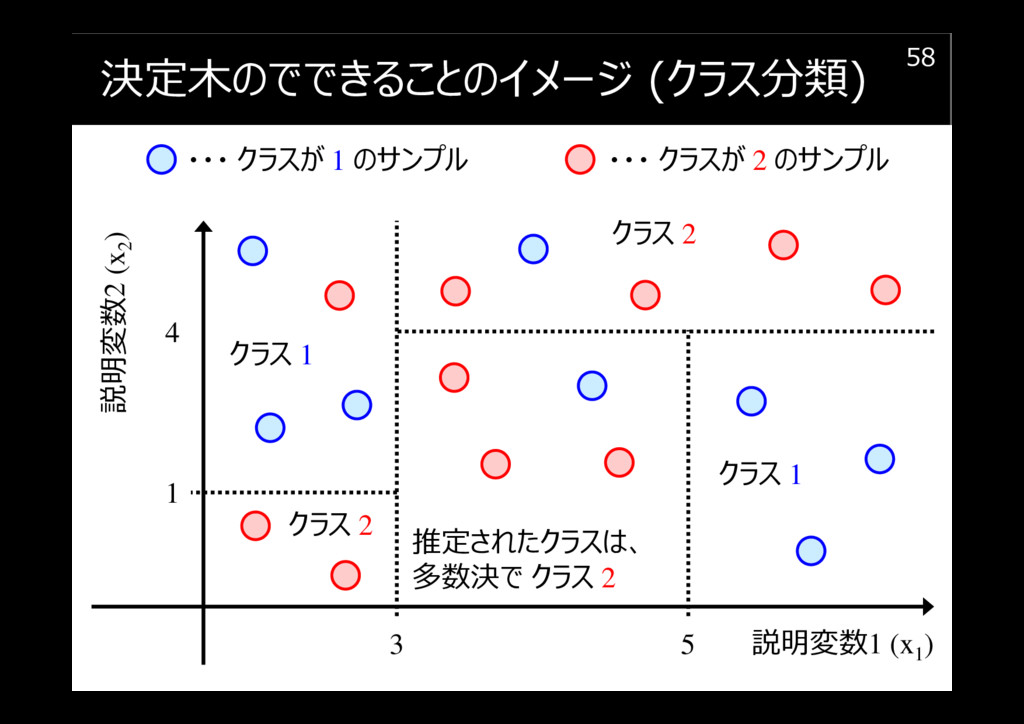
決定木のでできることのイメージ (クラス分類)
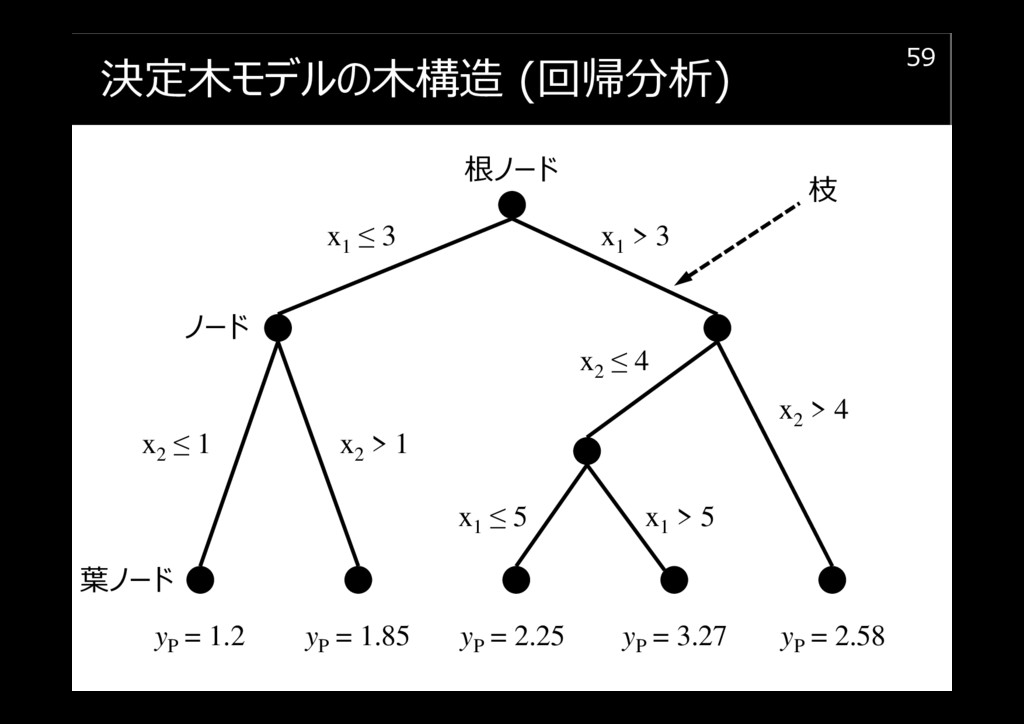
決定木モデルの木構造 (回帰分析)
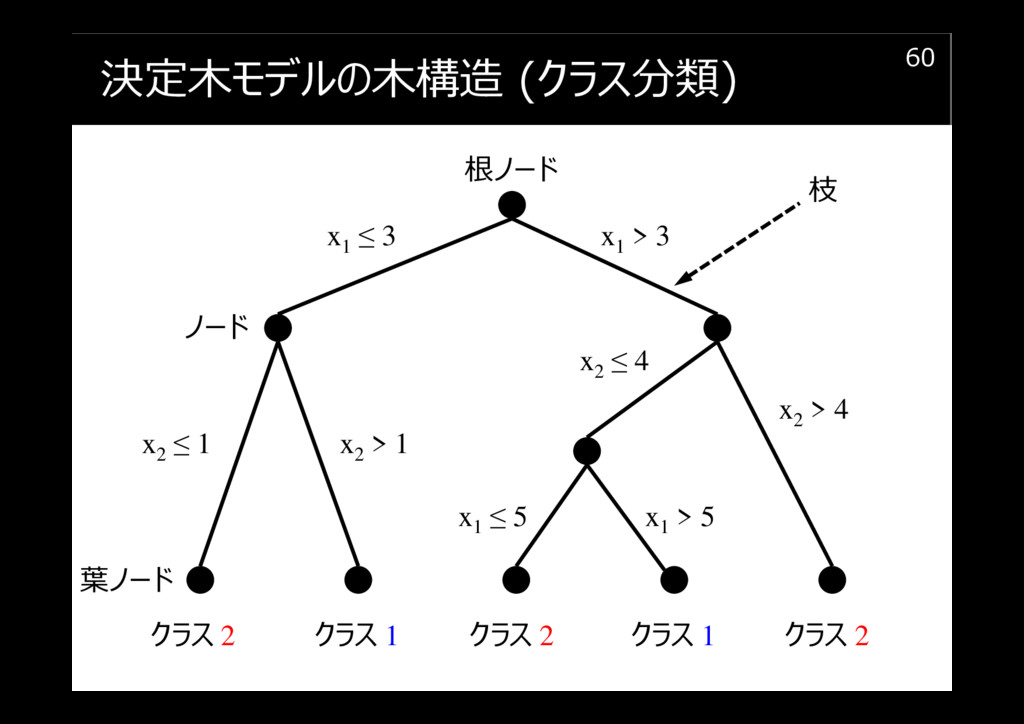
決定木モデルの木構造 (クラス分類)
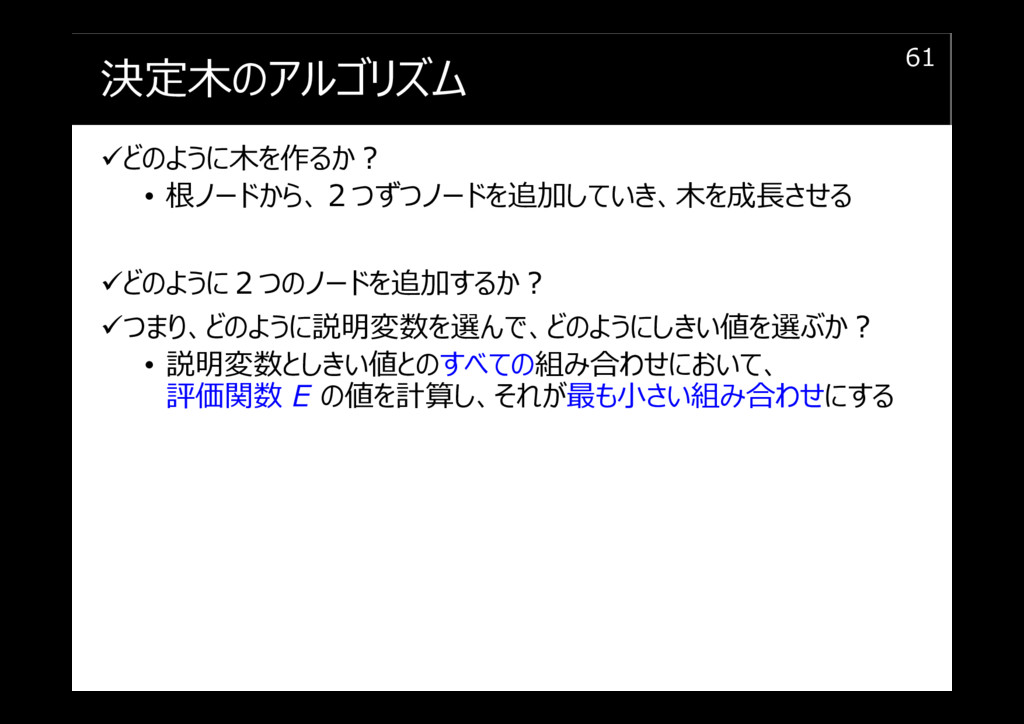
決定木のアルゴリズム
回帰分析における評価関数 E
クラス分類における評価関数 E
いつ木の成長を止めるか?
内容 1/2
Random Forest (RF) とは?
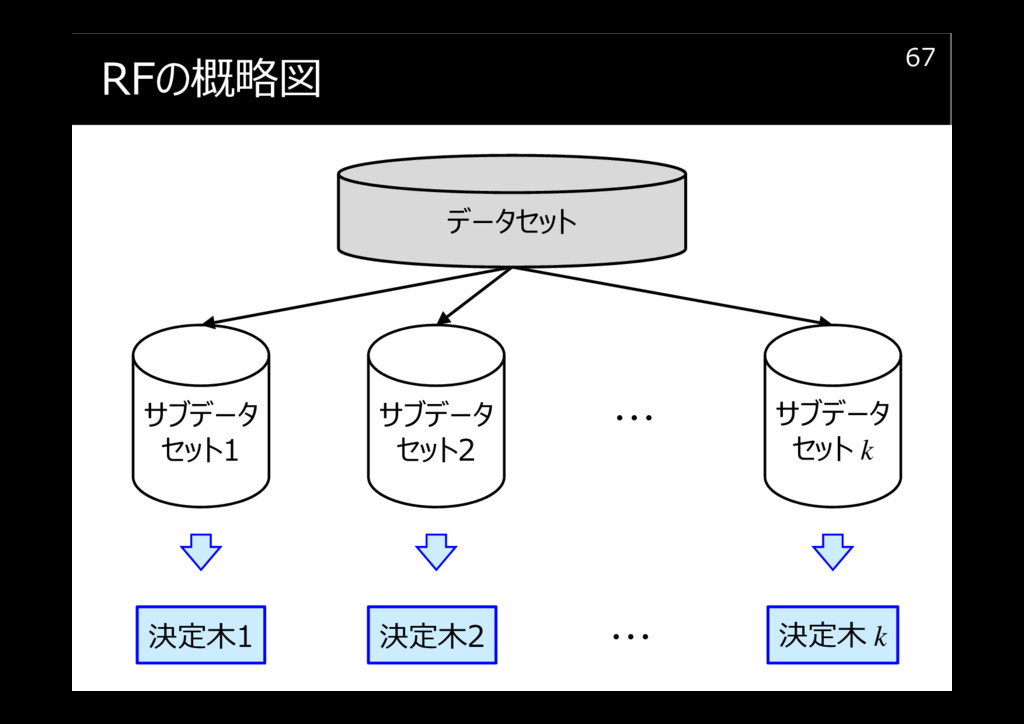
RFの概略図
どのようにサブデータセットを作るか?
サブデータセットの数・説明変数の数はどうする?
どのように推定結果を統合するか?
Out-Of-Bag (OOB)
OOBを用いた説明変数 (記述子) の重要度
内容 1/2
RR・LASSO・EN とは?
OLS・RR・LASSO・EN・SVR
OLS・RR・LASSO・EN・SVRの共通点
OLS・RR・LASSO・EN・SVRの違い 1/2
OLS・RR・LASSO・EN・SVRの違い 2/2
回帰係数の求め方
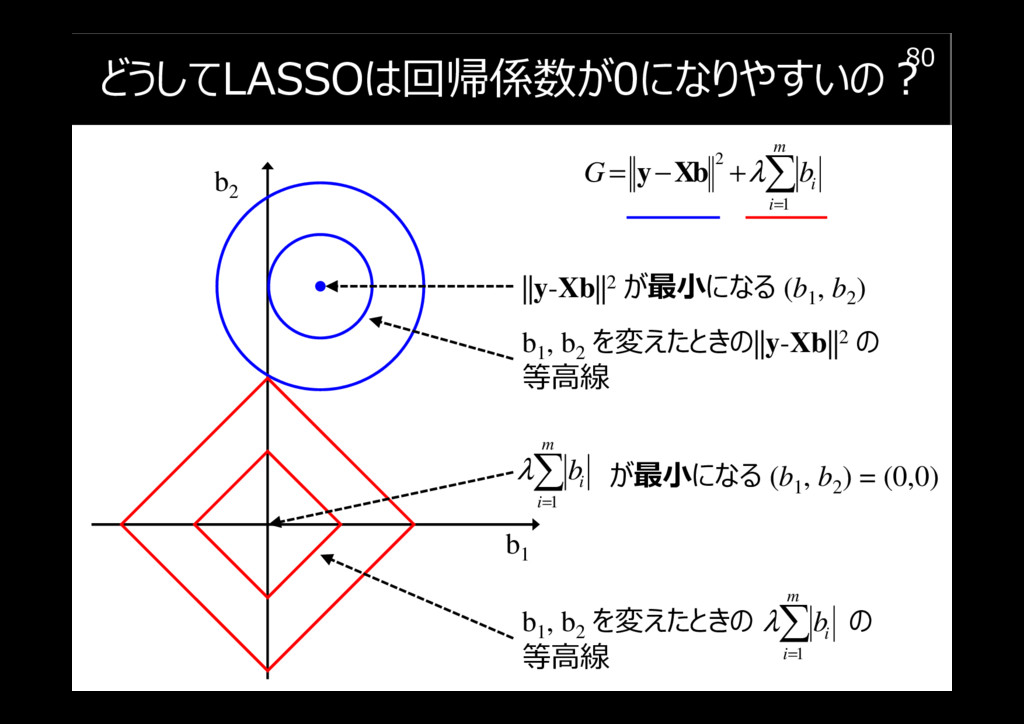
どうしてLASSOは回帰係数が0になりやすいの?
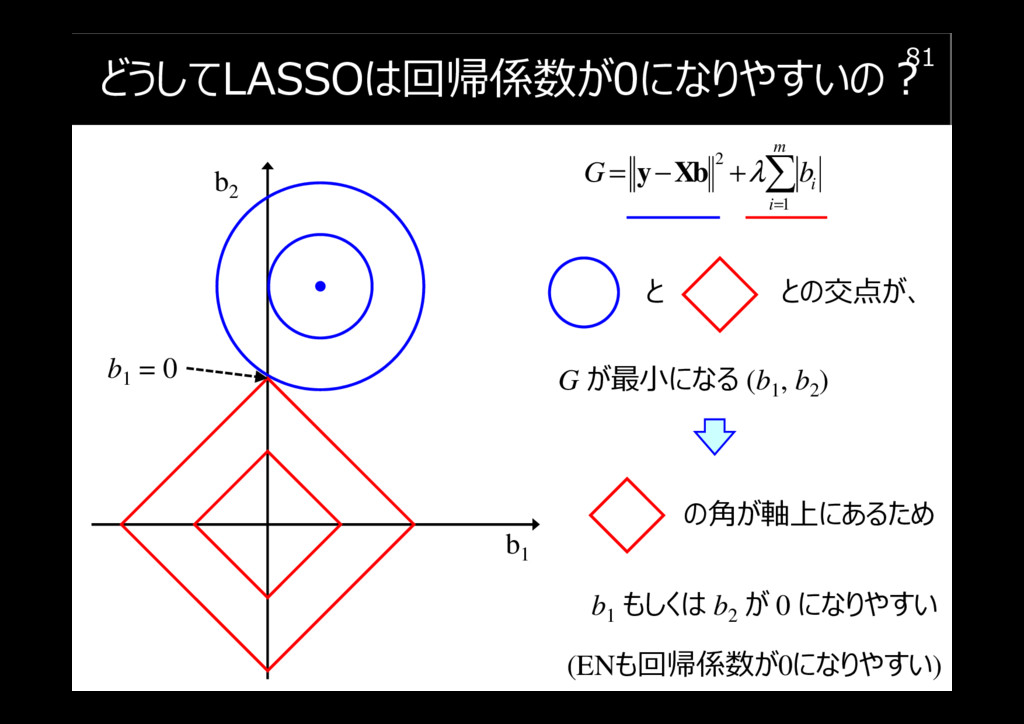
どうしてLASSOは回帰係数が0になりやすいの?
重み λ, α の決め方
内容 1/2
サポートベクター回帰 (SVR) とは?
基本的にSVRは線形の回帰分析手法
回帰係数 b
非線形の回帰モデルへ
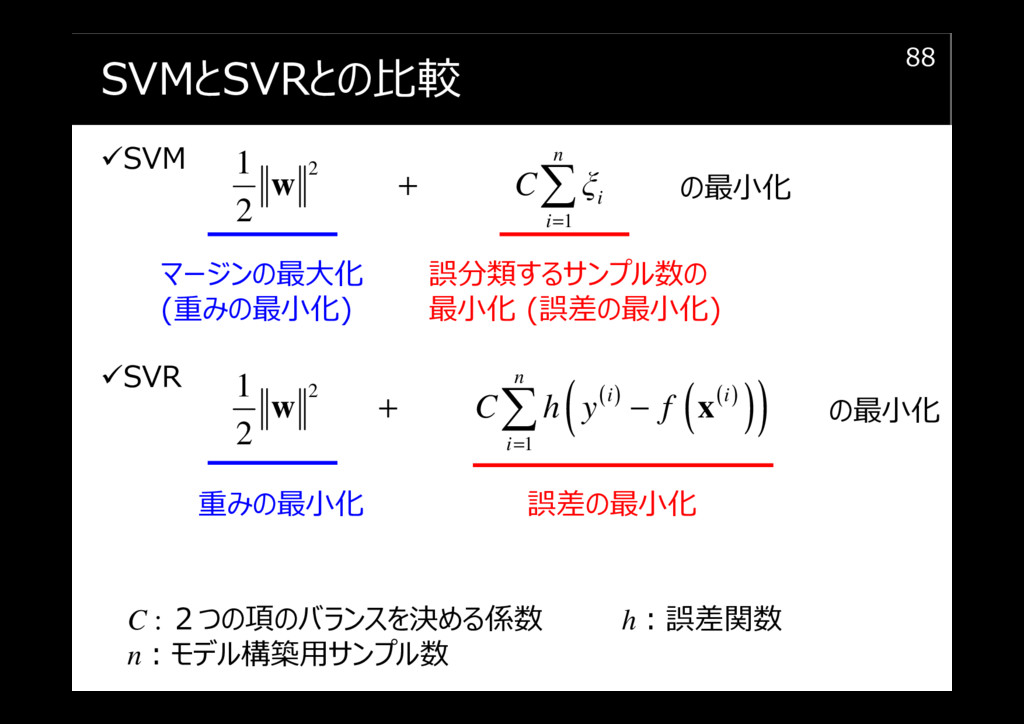
SVMとSVRとの比較
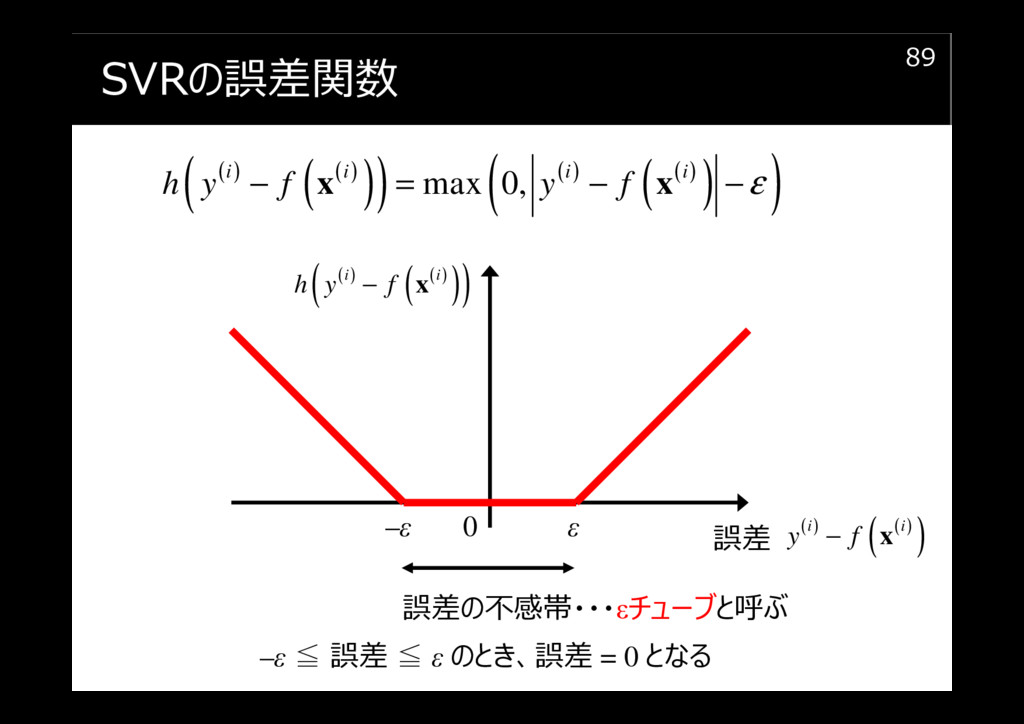
SVRの誤差関数
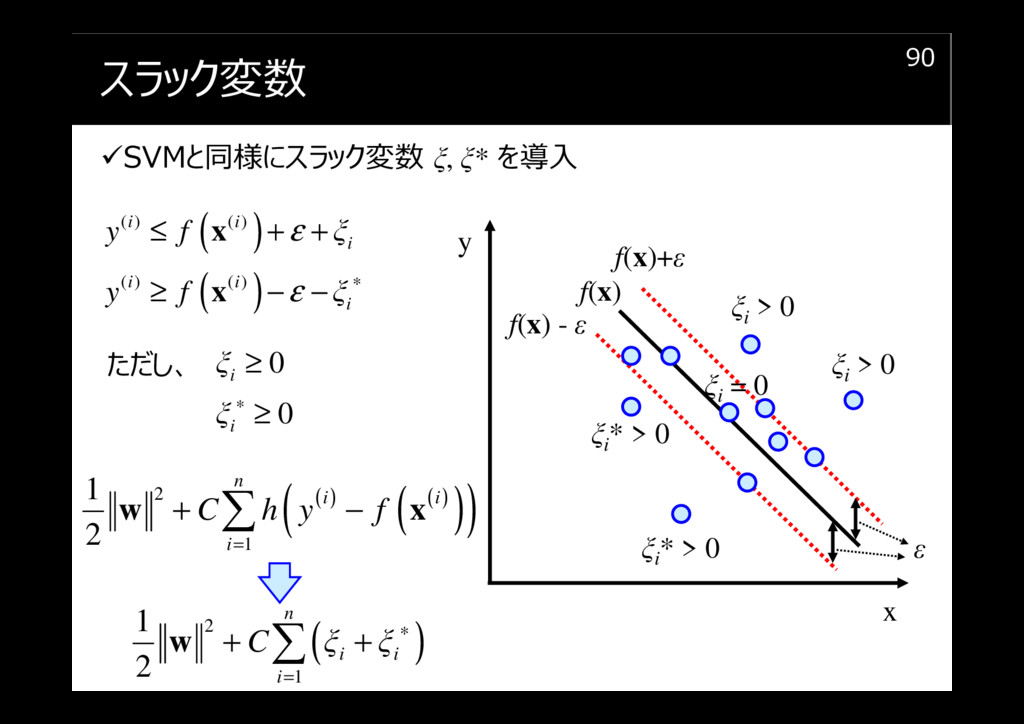
スラック変数
RR・LASSO・EN との関係
Lagrangeの未定乗数法
偏微分して0
G の変形
カーネル関数の例
α を求める
二次計画問題
SVRの回帰式
サポートベクターとは
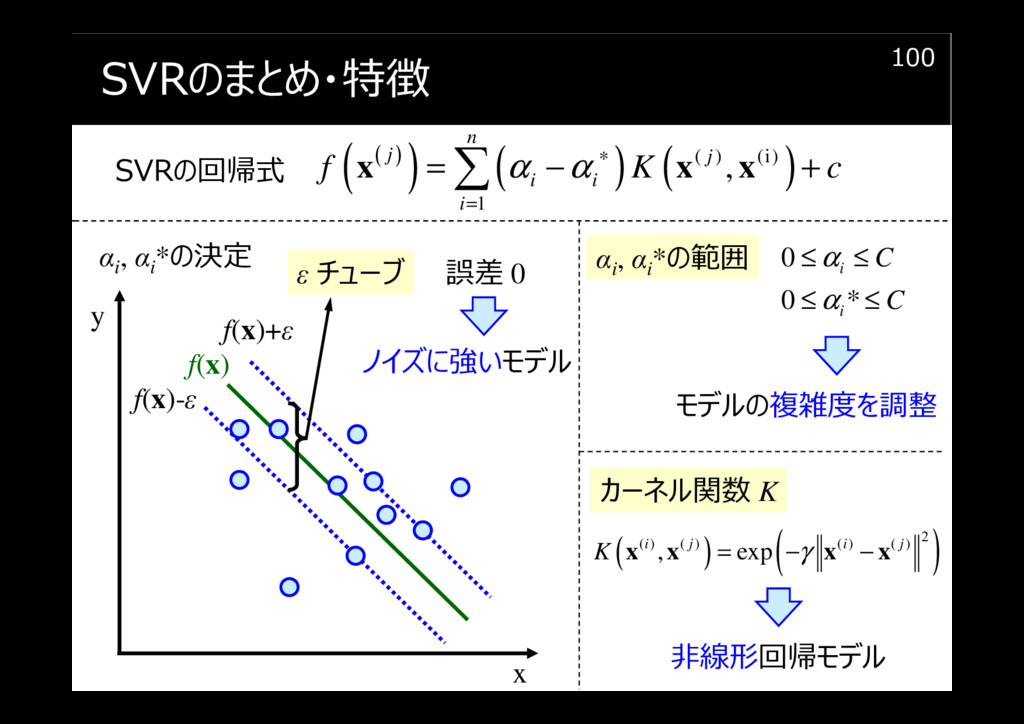
SVRのまとめ・特徴
C, ε, γ の決め方
内容 2/2
Stepwise (ステップワイズ) 法とは?
Stepwise法の種類
どのように説明変数を増やすか?
評価指標 (最小二乗法による重回帰分析用) 1/2
評価指標 (最小二乗法による重回帰分析用) 2/2
評価指標 (任意の回帰分析手法で使える)
どのように説明変数を減らすか?
減らすときだけで使える手法
どのように説明変数を増やすか減らすかするか?
scikit-learn を使う方へ 1/2
scikit-learn を使う方へ 2/2
参考資料
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![入門編の復習 回帰分析 • 最⼩二乗法による重回帰分析 [1,2,4] • Partial Least Squares (PLS)](https://files.speakerdeck.com/presentations/d44e3a42e2fe4516b2657014696ba4fe/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考資料 最⼩二乗法による重回帰分析 [1,2,4] Partial Least Squares (PLS) [1,2,3] 線形判別分析 (Linear](https://files.speakerdeck.com/presentations/d44e3a42e2fe4516b2657014696ba4fe/slide_114.jpg){kind=link}