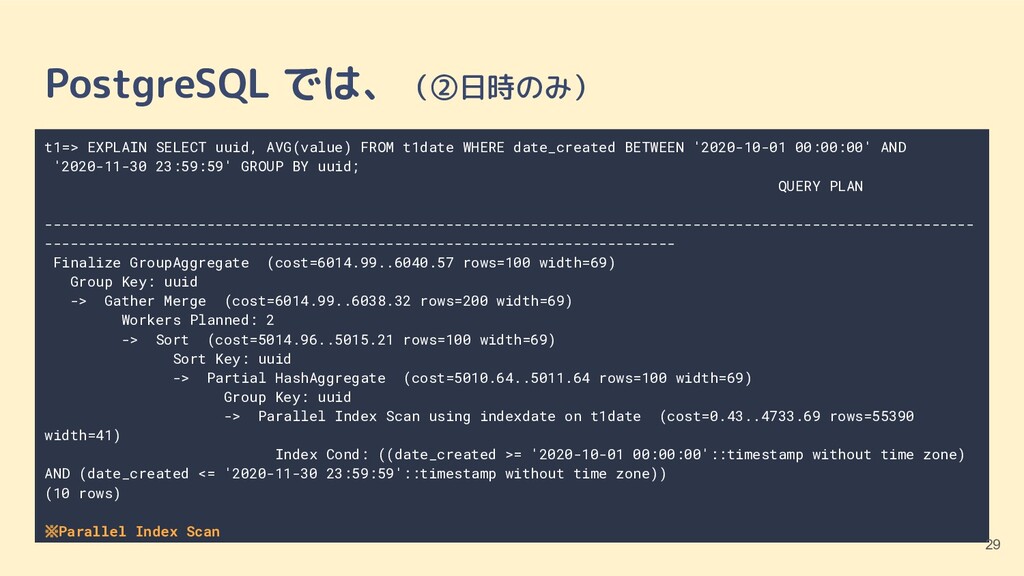
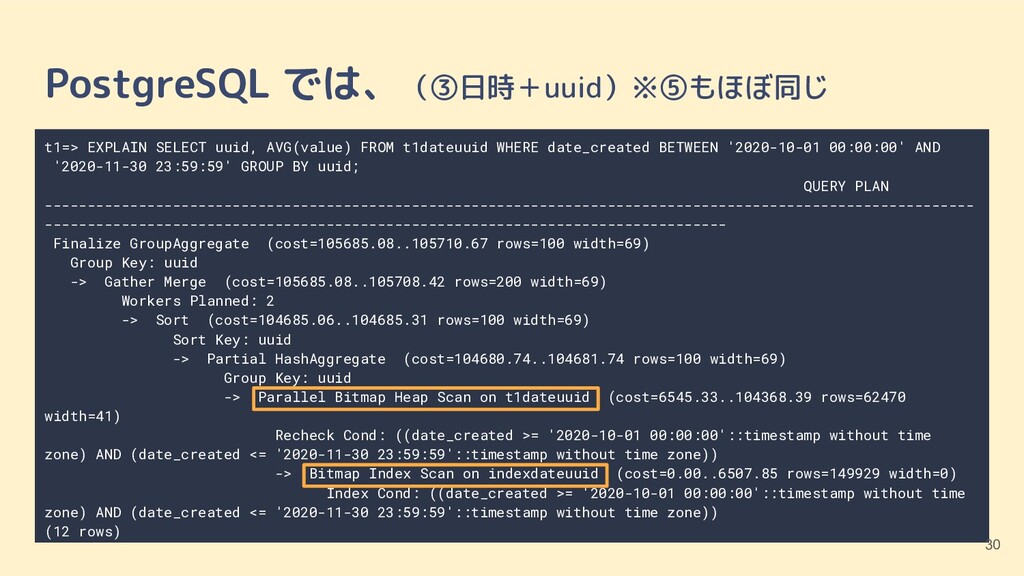
VARCHAR(40) NOT NULL, date_created timestamp NOT NULL, value int); ②日付(date_created)のみ CREATE TABLE t1date (id int PRIMARY KEY, uuid VARCHAR(40) NOT NULL, date_created timestamp NOT NULL, value int); CREATE INDEX indexdate ON t1date (date_created); ③日付(date_created)+uuid CREATE TABLE t1dateuuid (id int PRIMARY KEY, uuid VARCHAR(40) NOT NULL, date_created timestamp NOT NULL, value int); CREATE INDEX indexdateuuid ON t1dateuuid (date_created, uuid); テスト用のテーブル(1/2) 16
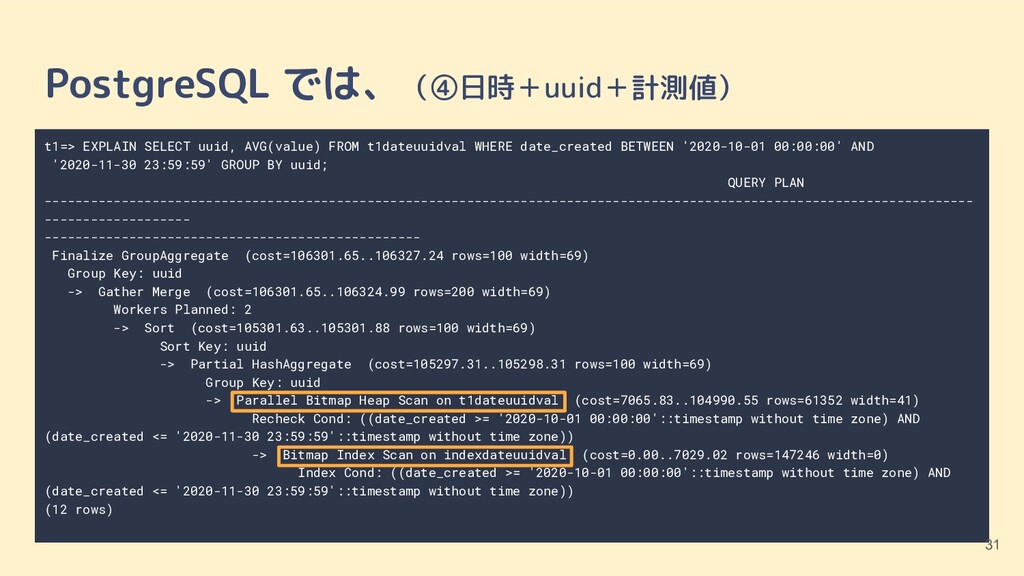
NOT NULL, date_created timestamp NOT NULL, value int); CREATE INDEX indexdateuuidval ON t1dateuuidval (date_created, uuid, value); ⑤日付(date_created)+計測値(value) CREATE TABLE t1dateval (id int PRIMARY KEY, uuid VARCHAR(40) NOT NULL, date_created timestamp NOT NULL, value int); CREATE INDEX indexdateval ON t1dateval (date_created, uuid, value); ⑥uuid のみ CREATE TABLE t1uuid (id int PRIMARY KEY, uuid VARCHAR(40) NOT NULL, date_created timestamp NOT NULL, value int); CREATE INDEX indexuuid ON t1dateuuidval (uuid); テスト用のテーブル(2/2) 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
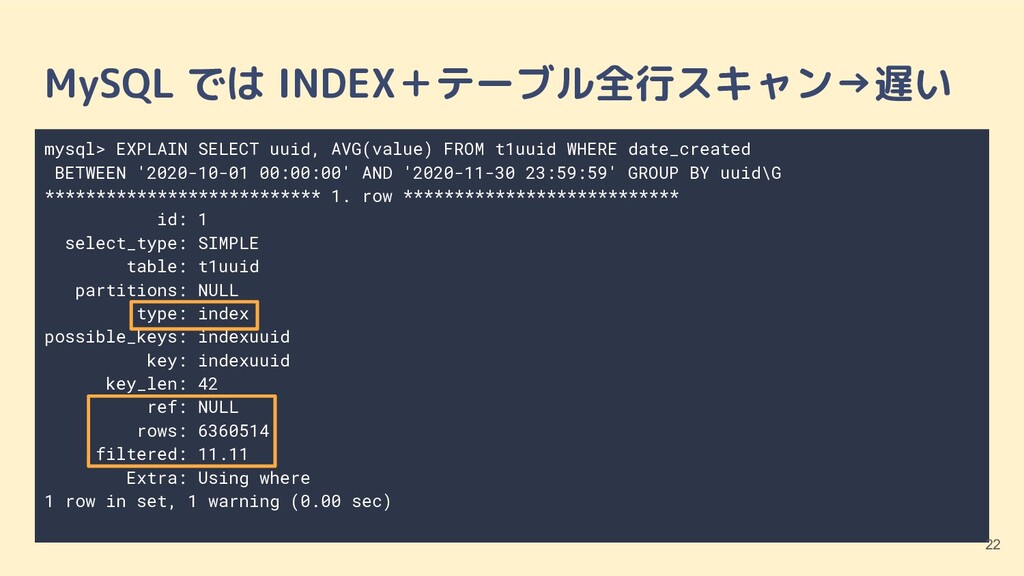{kind=link}
{kind=link}
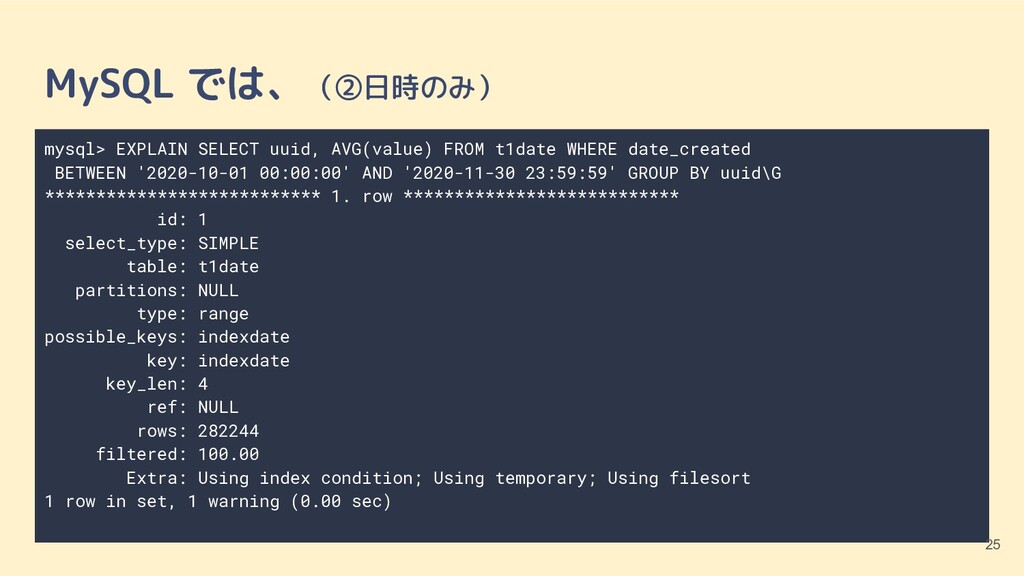
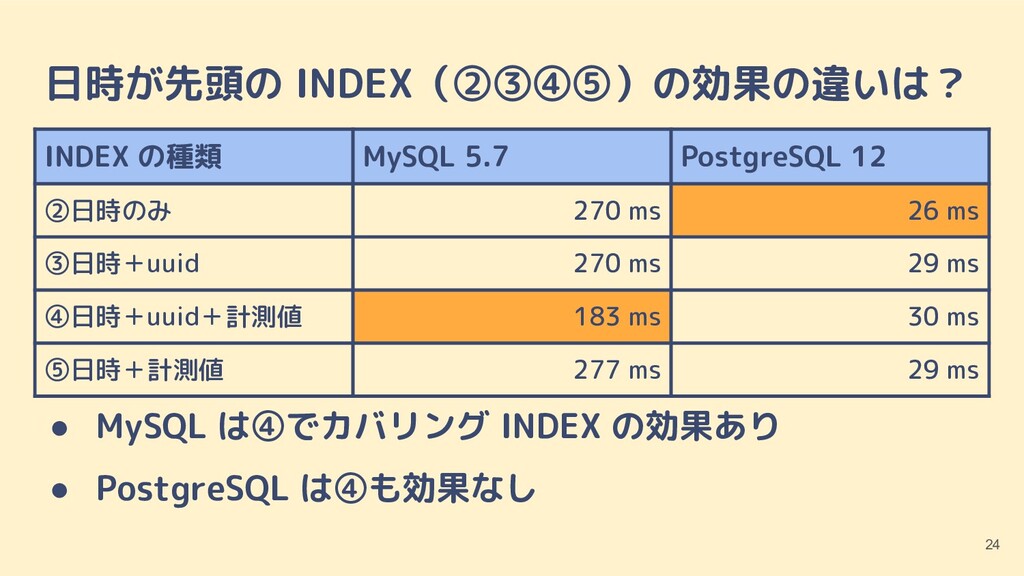{kind=link}
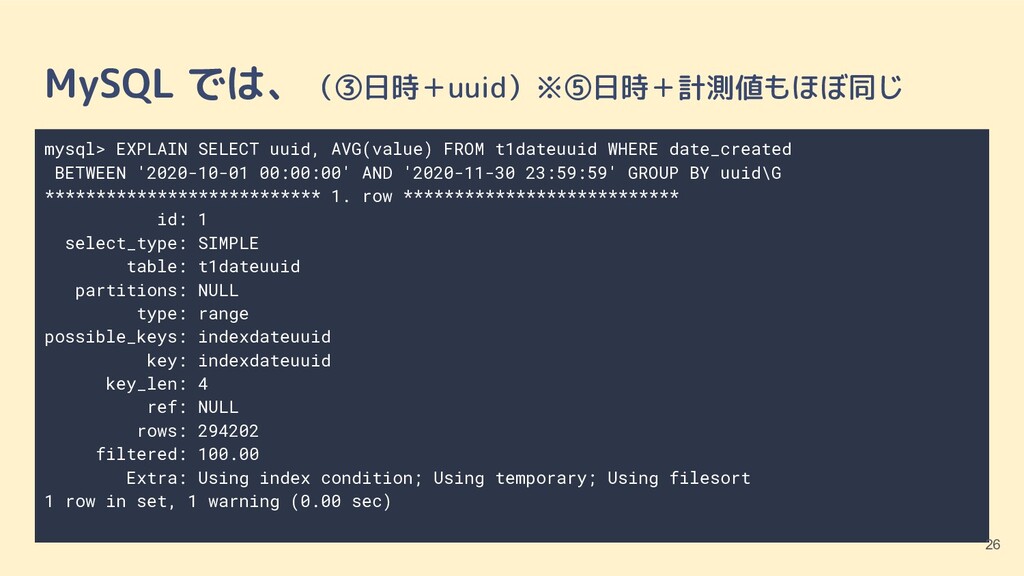
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}