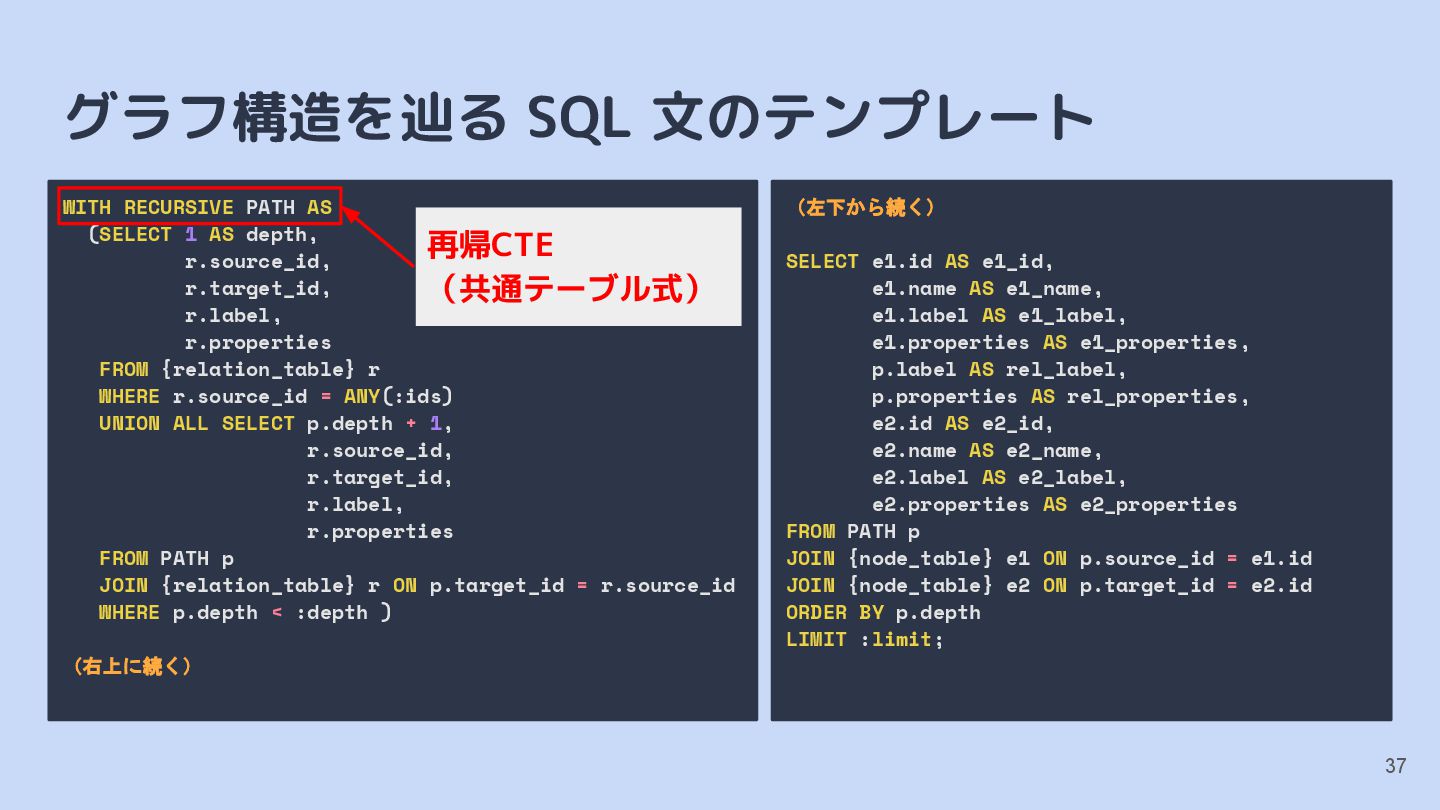
AS depth, r.source_id, r.target_id, r.label, r.properties FROM {relation_table} r WHERE r.source_id = ANY(:ids) UNION ALL SELECT p.depth + 1, r.source_id, r.target_id, r.label, r.properties FROM PATH p JOIN {relation_table} r ON p.target_id = r.source_id WHERE p.depth < :depth ) (右上に続く) (左下から続く) SELECT e1.id AS e1_id, e1.name AS e1_name, e1.label AS e1_label, e1.properties AS e1_properties, p.label AS rel_label, p.properties AS rel_properties, e2.id AS e2_id, e2.name AS e2_name, e2.label AS e2_label, e2.properties AS e2_properties FROM PATH p JOIN {node_table} e1 ON p.source_id = e1.id JOIN {node_table} e2 ON p.target_id = e2.id ORDER BY p.depth LIMIT :limit; 再帰CTE (共通テーブル式)
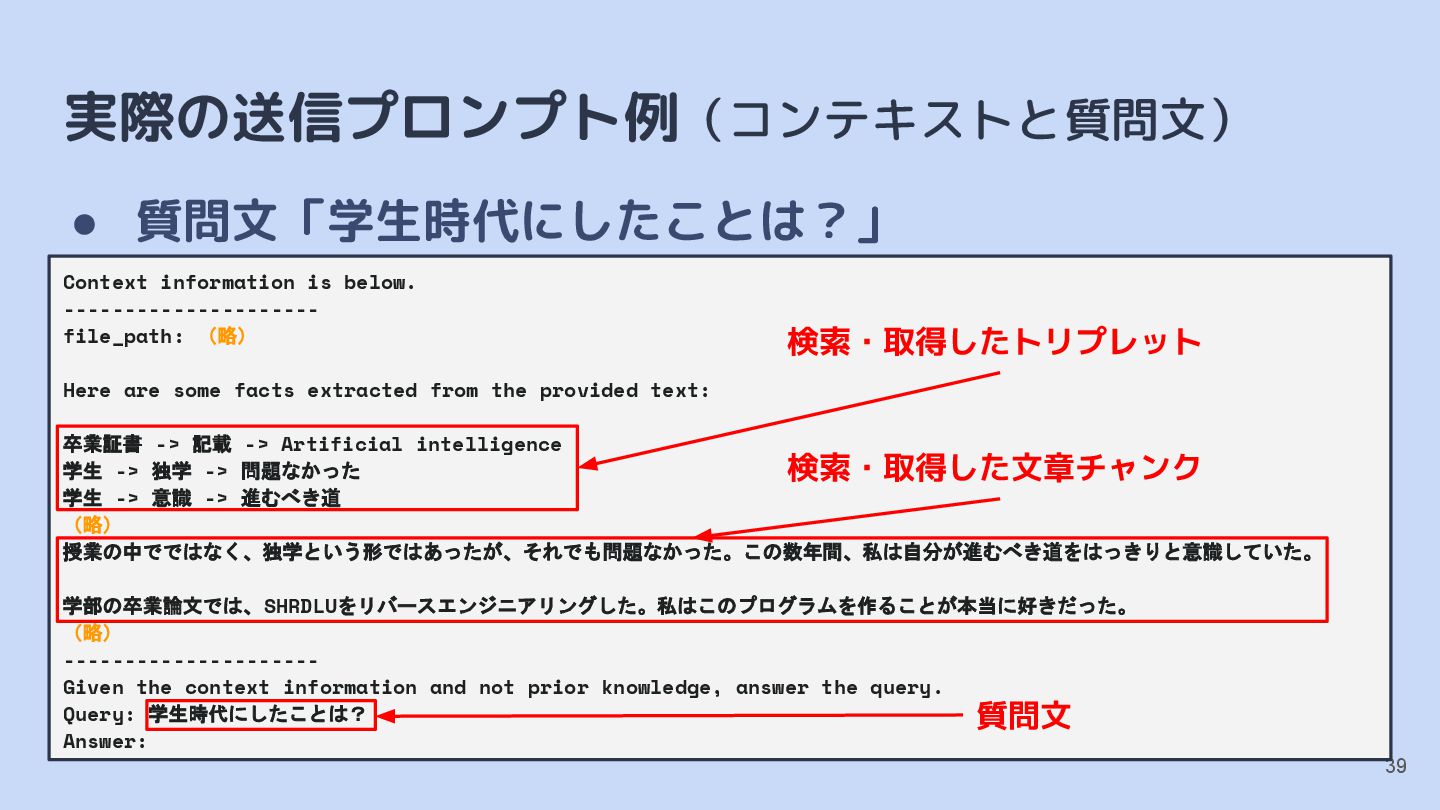
(略) Here are some facts extracted from the provided text: 卒業証書 -> 記載 -> Artificial intelligence 学生 -> 独学 -> 問題なかった 学生 -> 意識 -> 進むべき道 (略) 授業の中でではなく、独学という形ではあったが、それでも問題なかった。この数年間、私は自分が進むべき道をはっきりと意識していた。 学部の卒業論文では、SHRDLUをリバースエンジニアリングした。私はこのプログラムを作ることが本当に好きだった。 (略) --------------------- Given the context information and not prior knowledge, answer the query. Query: 学生時代にしたことは? Answer: 検索・取得したトリプレット 検索・取得した文章チャンク 質問文
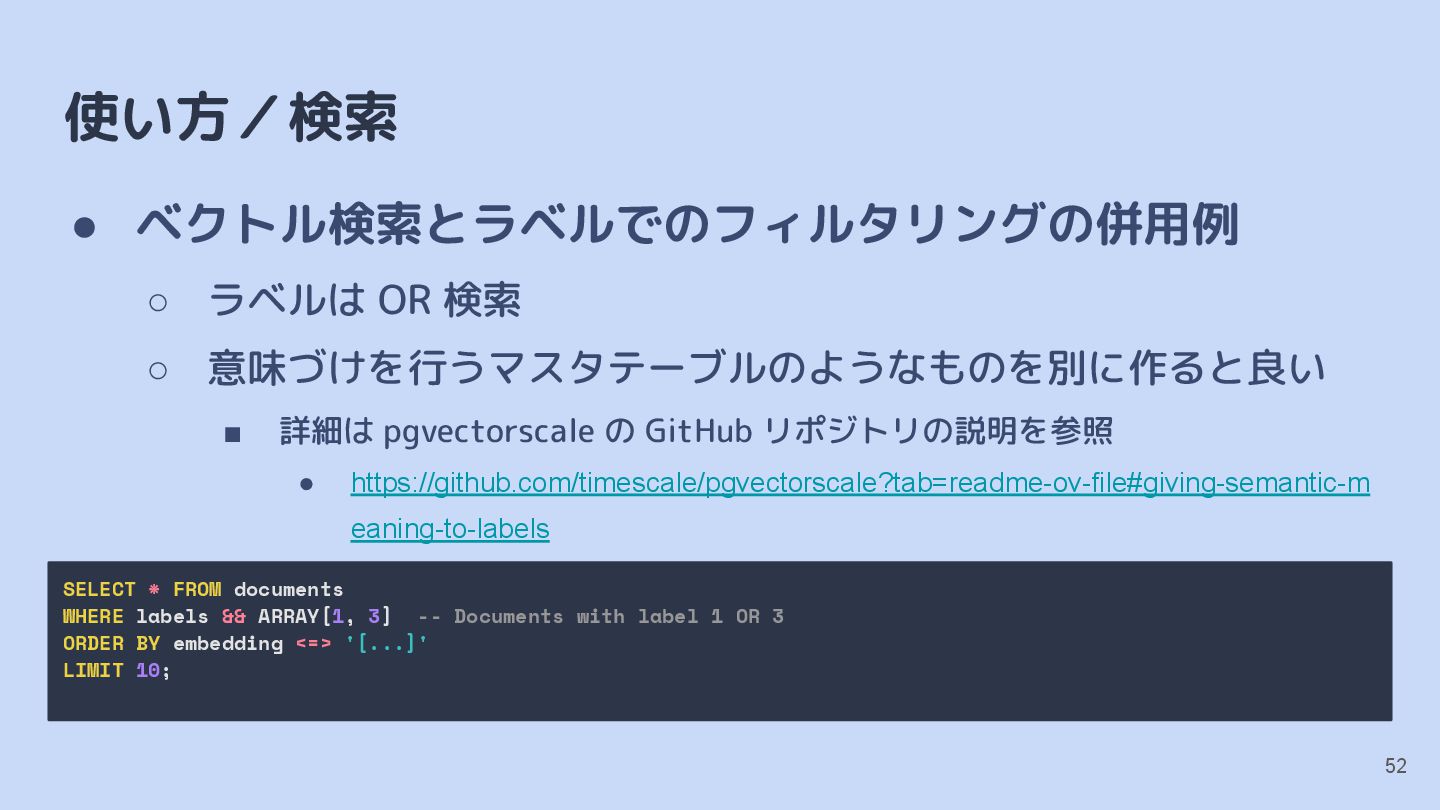
TABLE documents ( id SERIAL PRIMARY KEY, embedding VECTOR(1536), labels SMALLINT[], -- Array of category labels status TEXT, created_at TIMESTAMPTZ ); CREATE INDEX ON documents USING diskann (embedding vector_cosine_ops, labels);
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
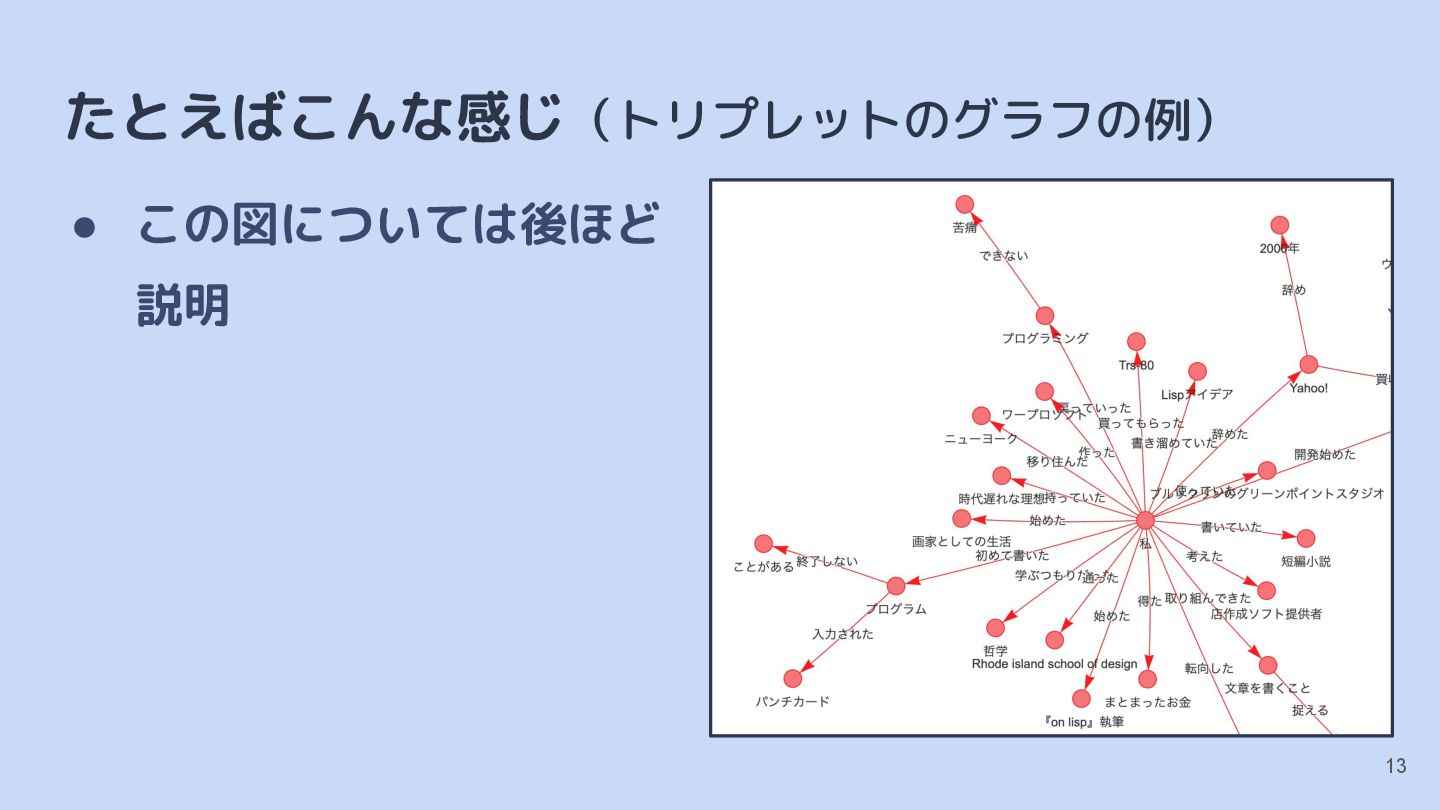{kind=link}
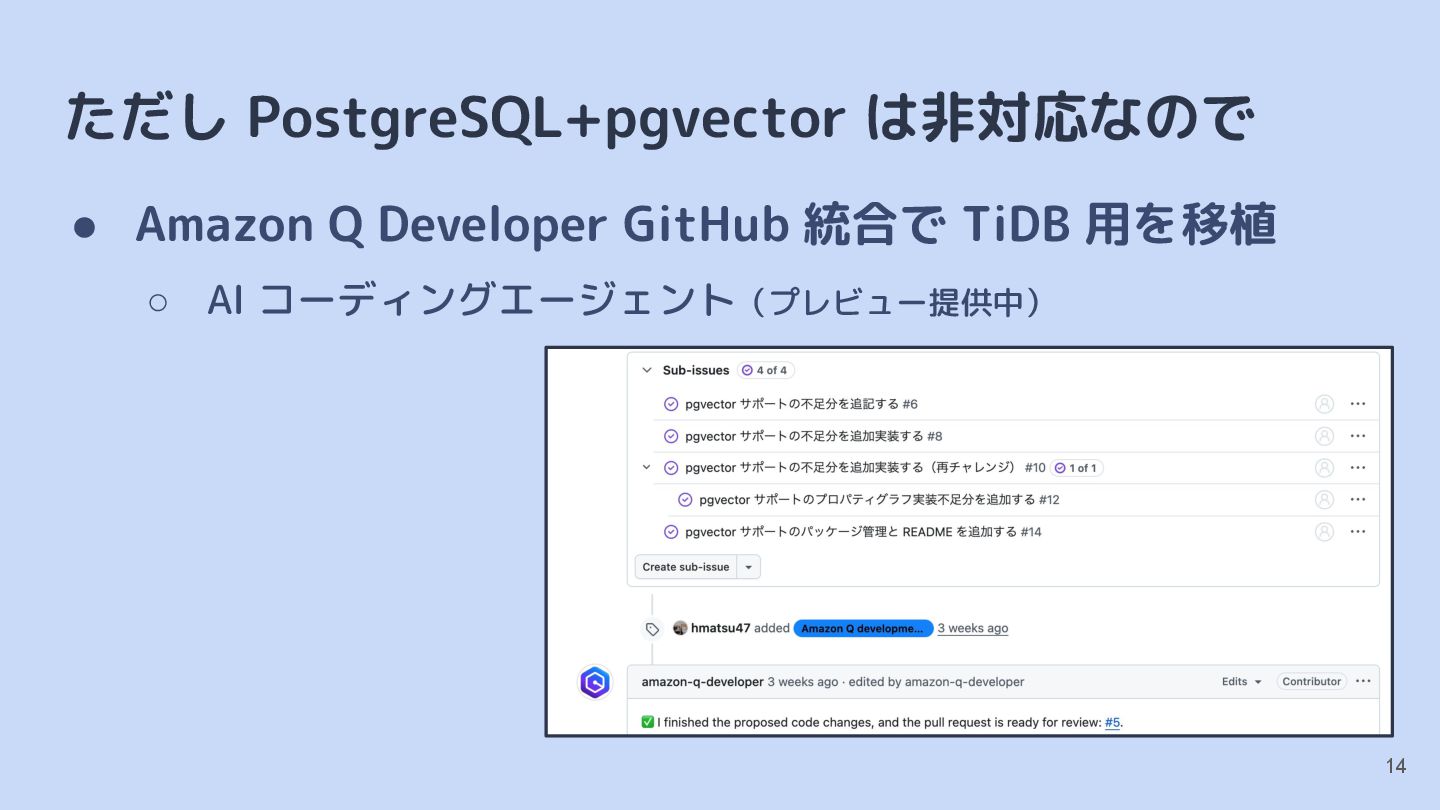{kind=link}
{kind=link}
{kind=link}
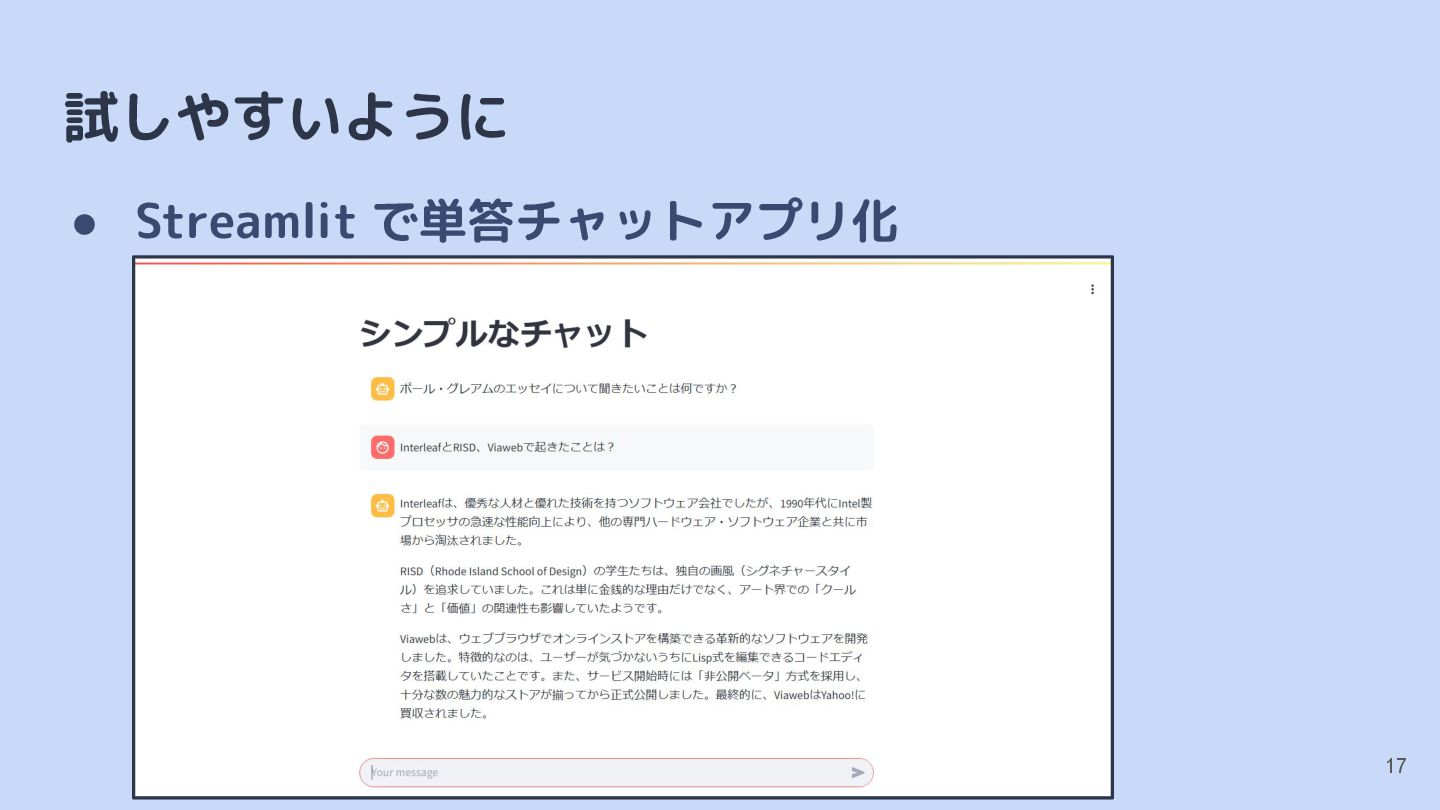{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
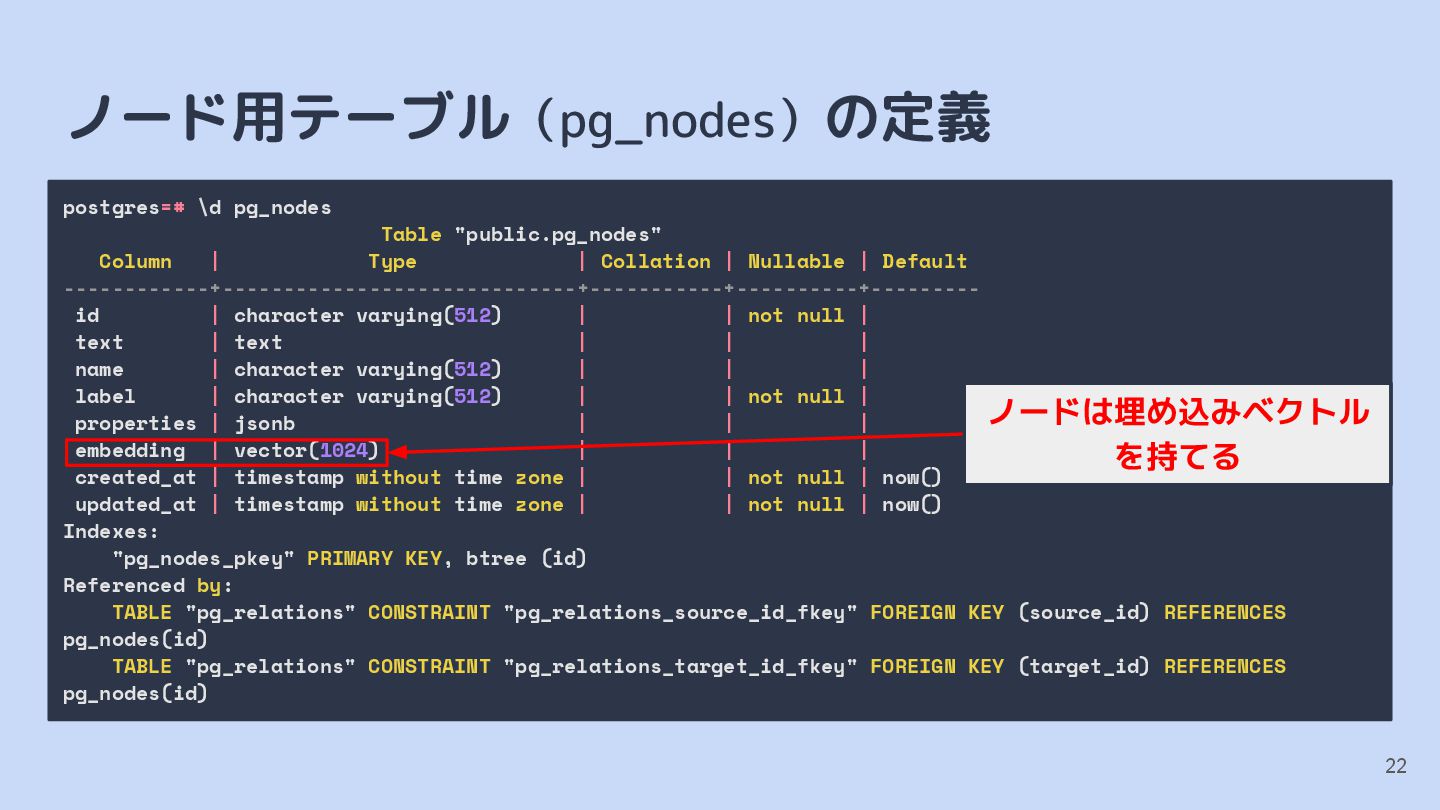{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
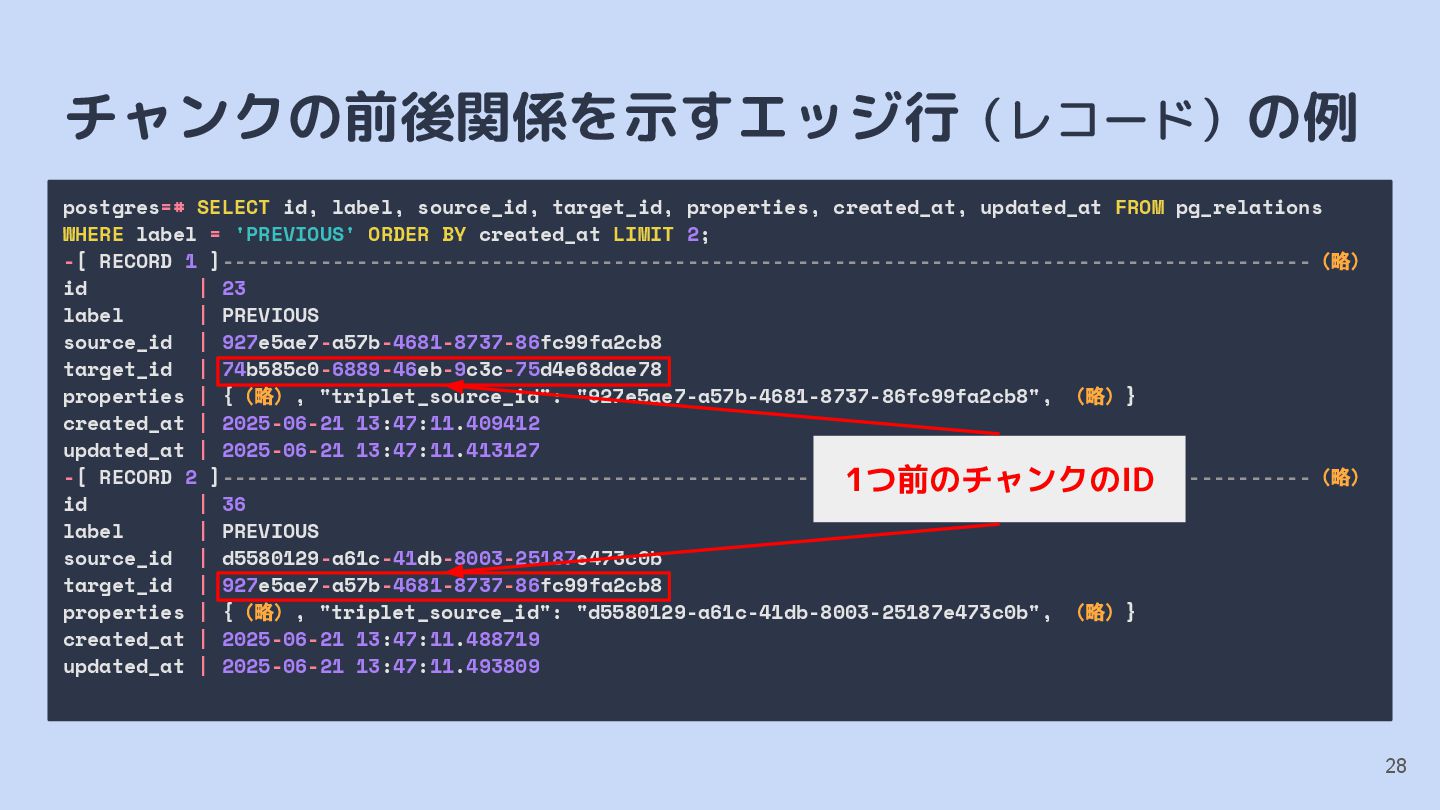{kind=link}
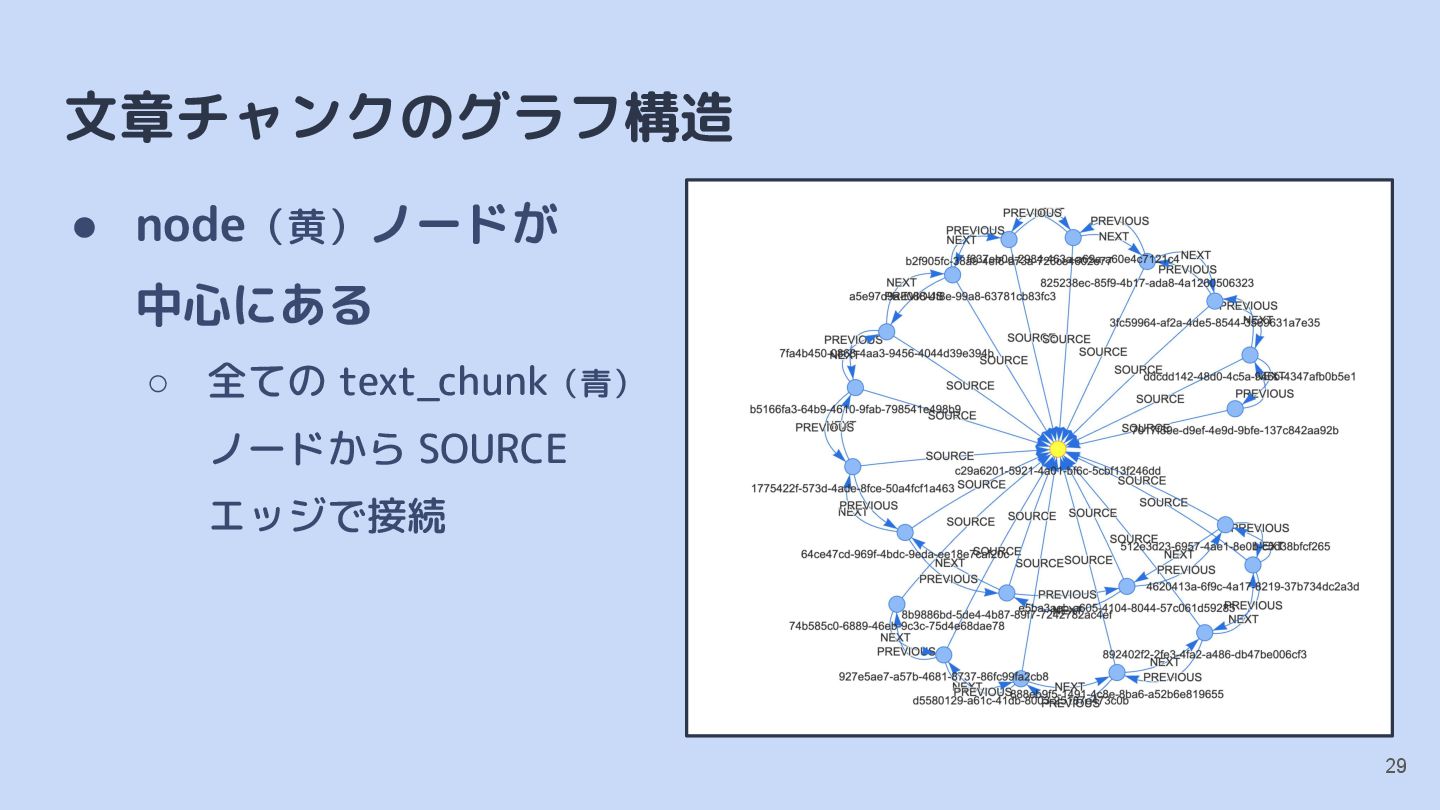{kind=link}
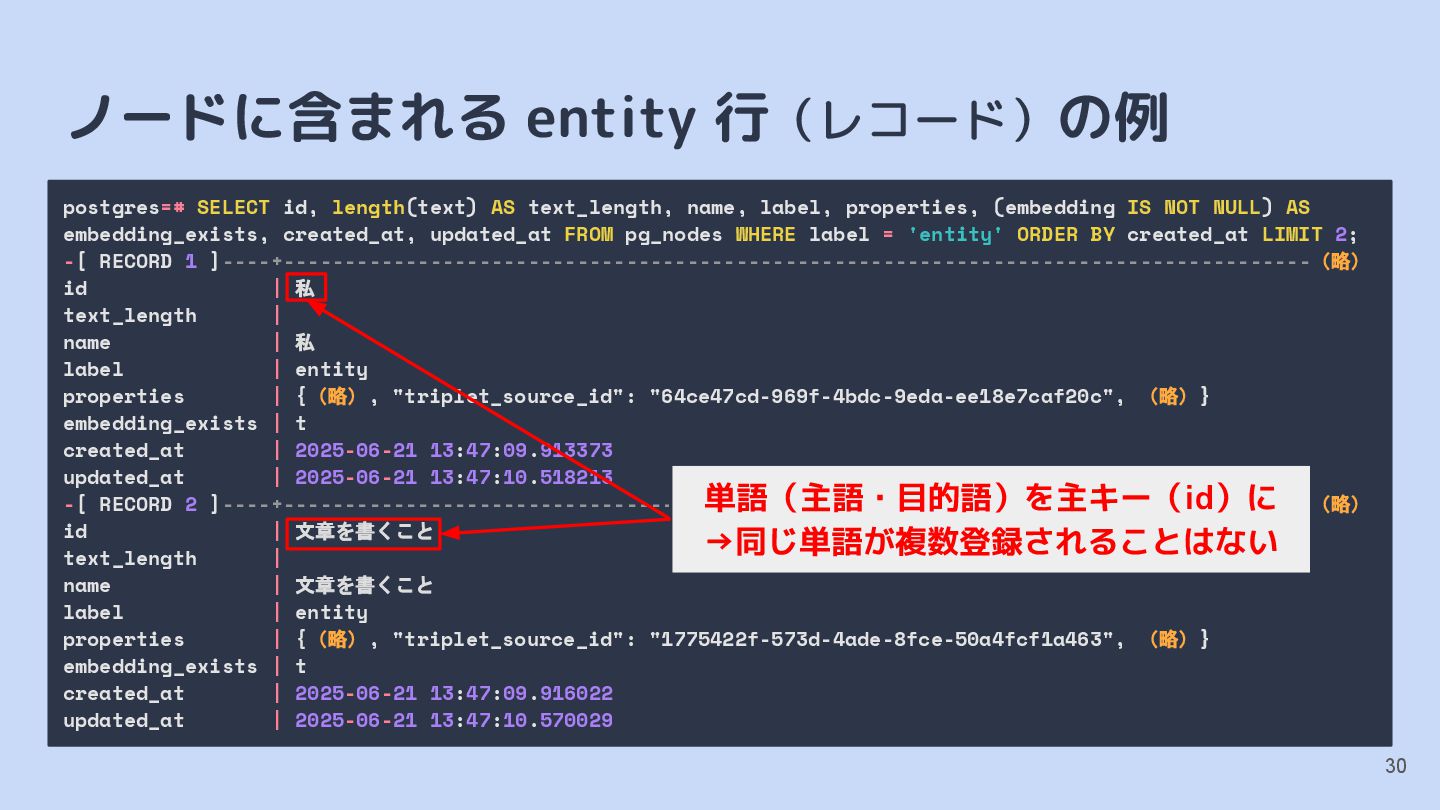{kind=link}
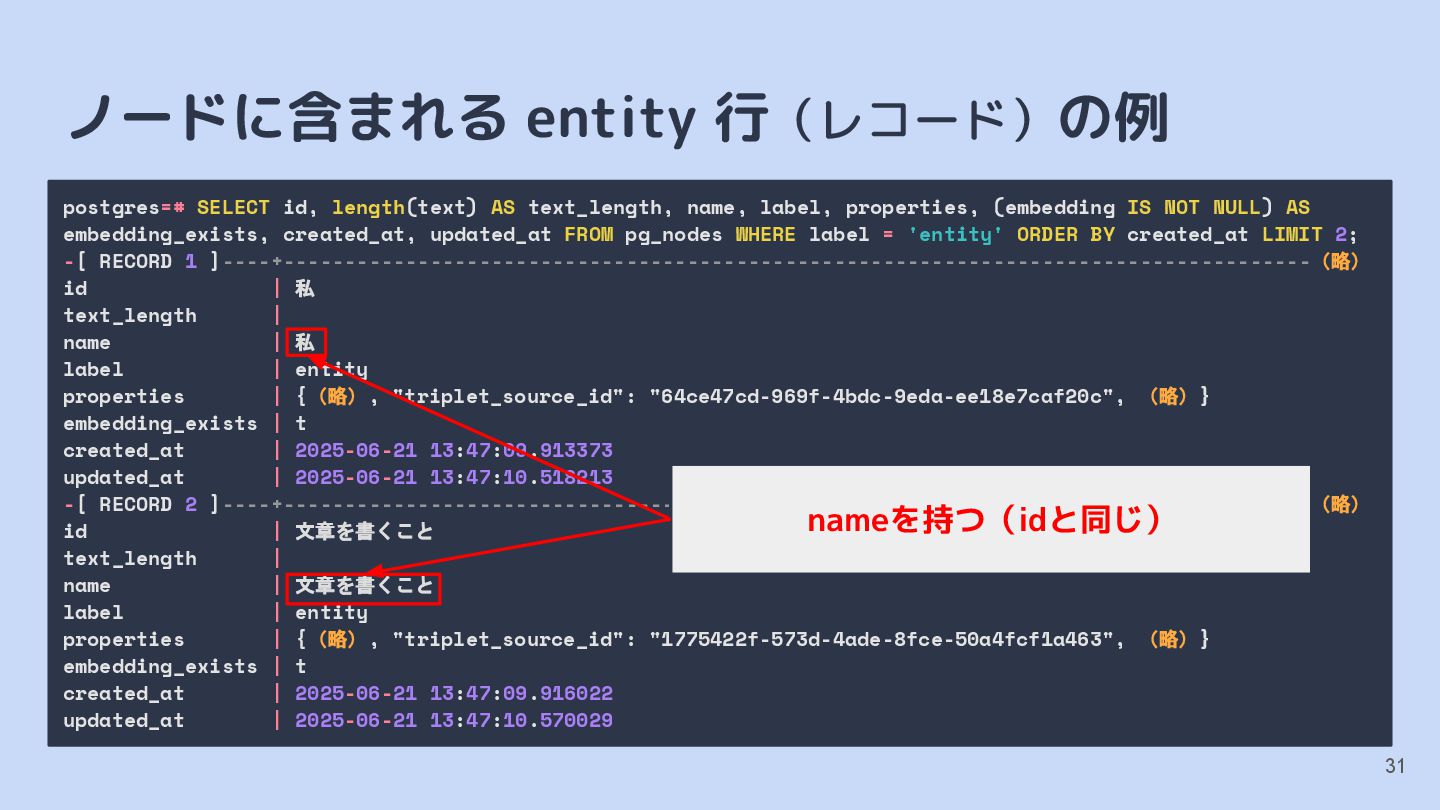{kind=link}
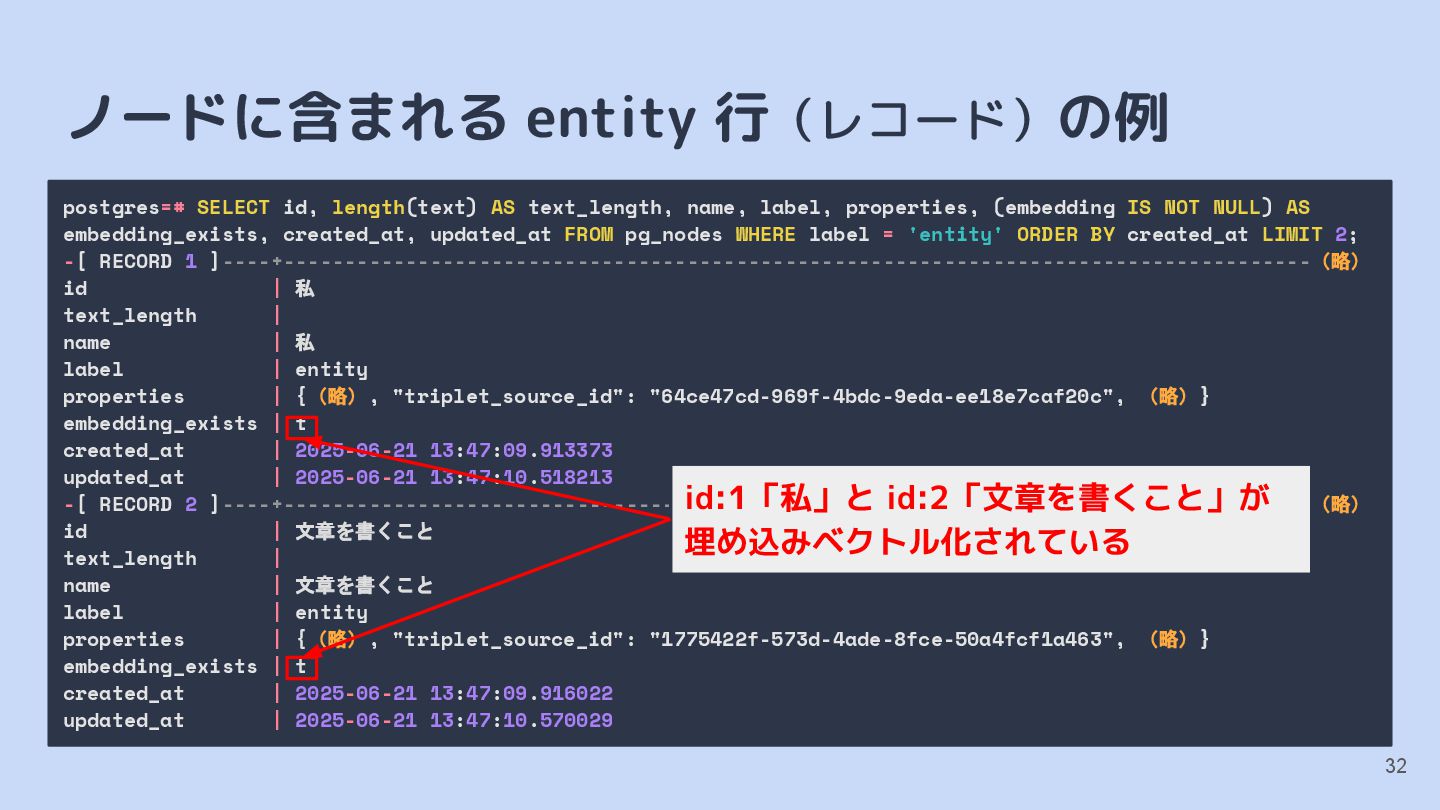{kind=link}
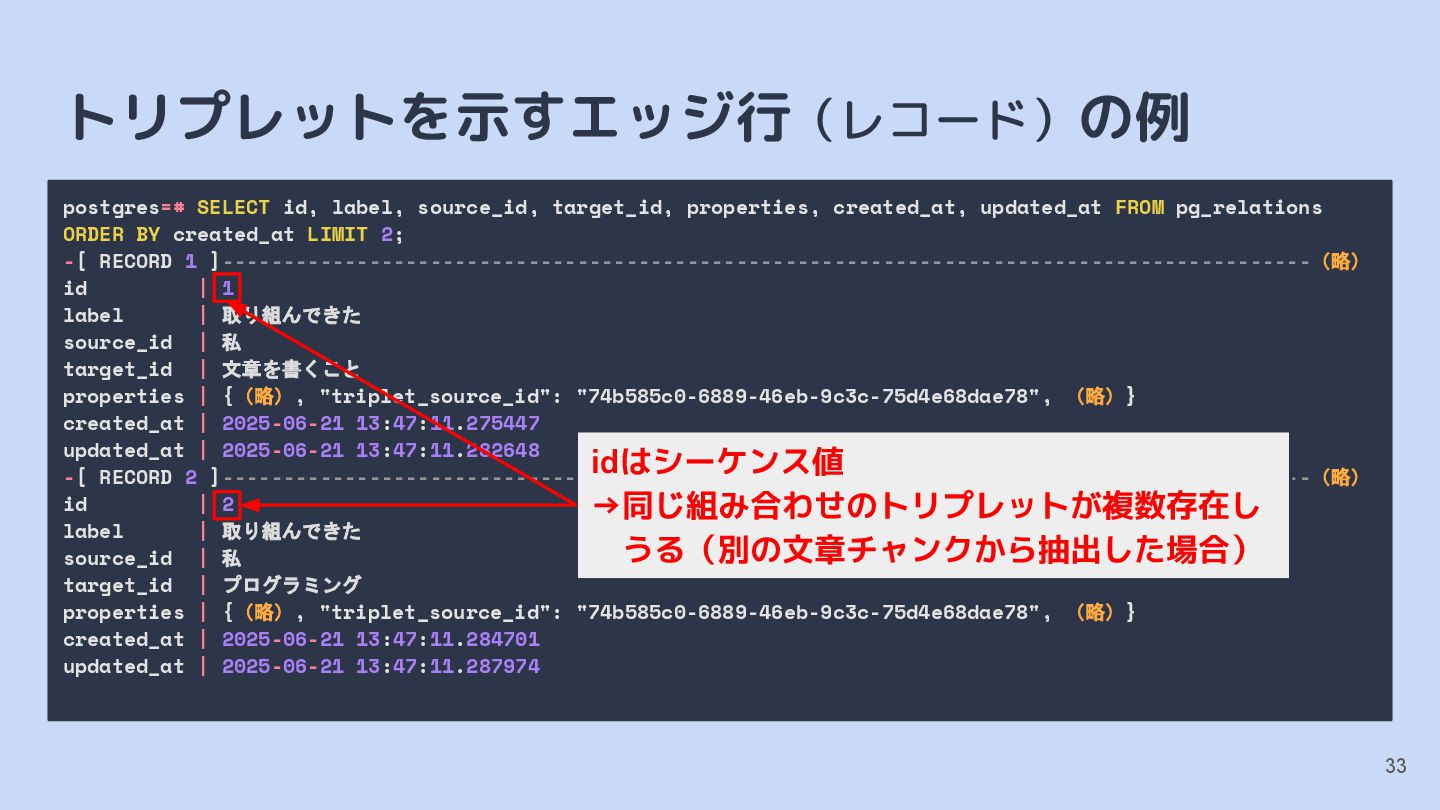{kind=link}
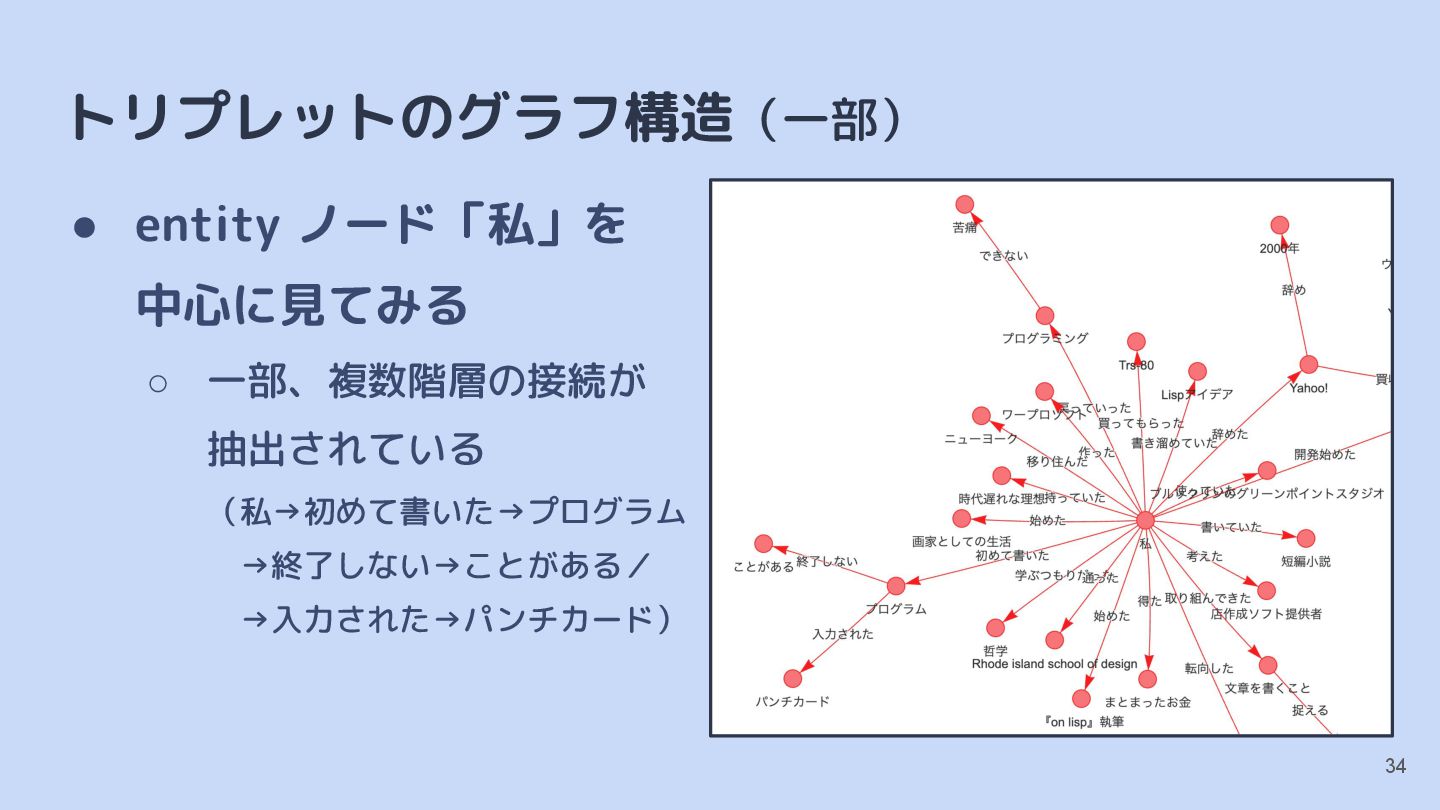{kind=link}
{kind=link}
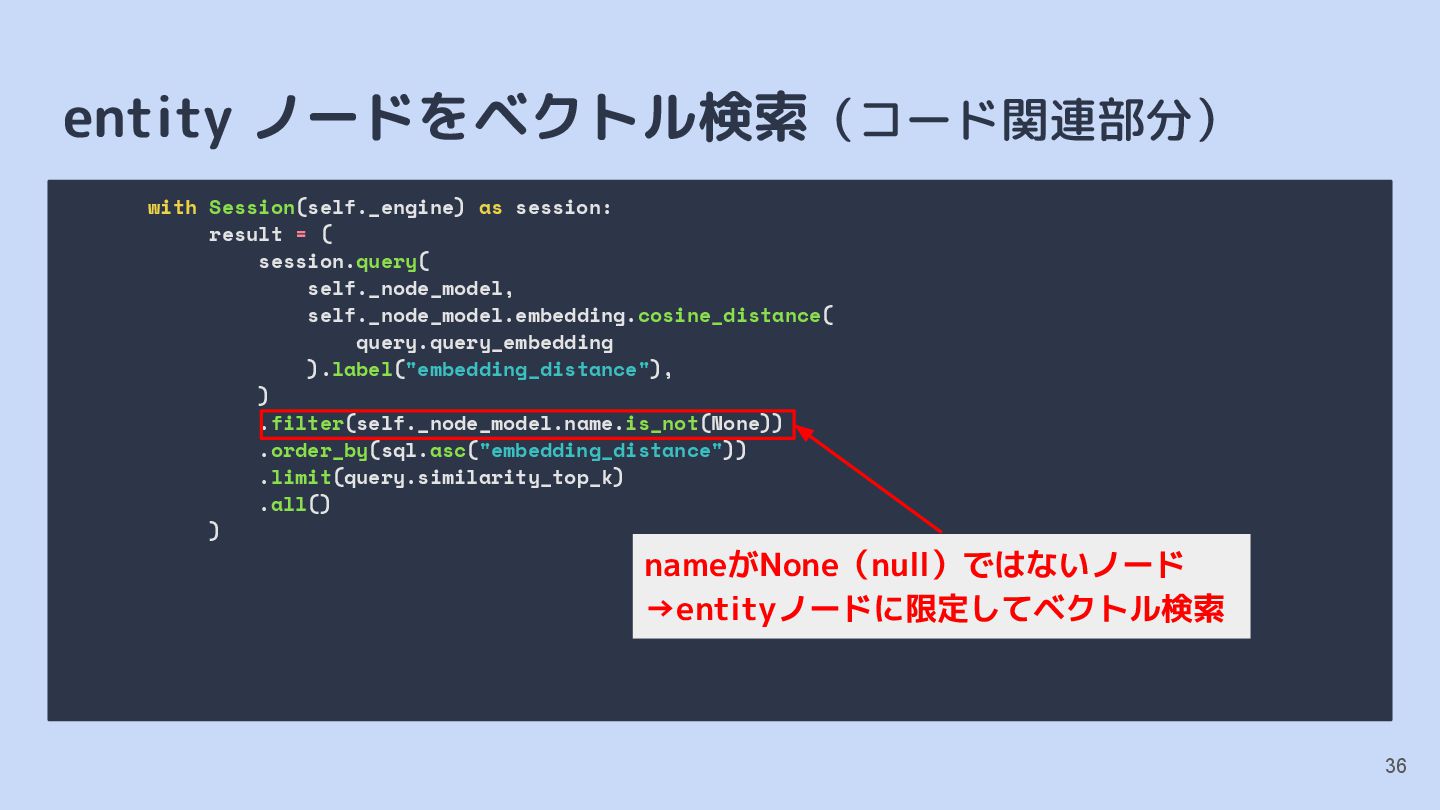{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}