Foursquare has grown from a simple check-in application to one that can tell you the best place to grab a burger. Along the way we've also become the best source of local data for apps like Instagram and Pinterest. I'll talk about the general architecture, storage systems and development practices that we've created to handle the ever increasing volume and complexity. Foursquare started out as a PHP MySQL app running on a single virtual server. Early on we switched to Scala and Mongo and have recently been aggressively splitting a monolithic application into multiple services while maintaining a single code base. I'll talk about the somewhat unique approach we've taken in our service oriented architecture. I'll also go over how we run Mongo and the additional storage systems we're running for more specialized tasks like search, key-value lookups, and offline tasks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
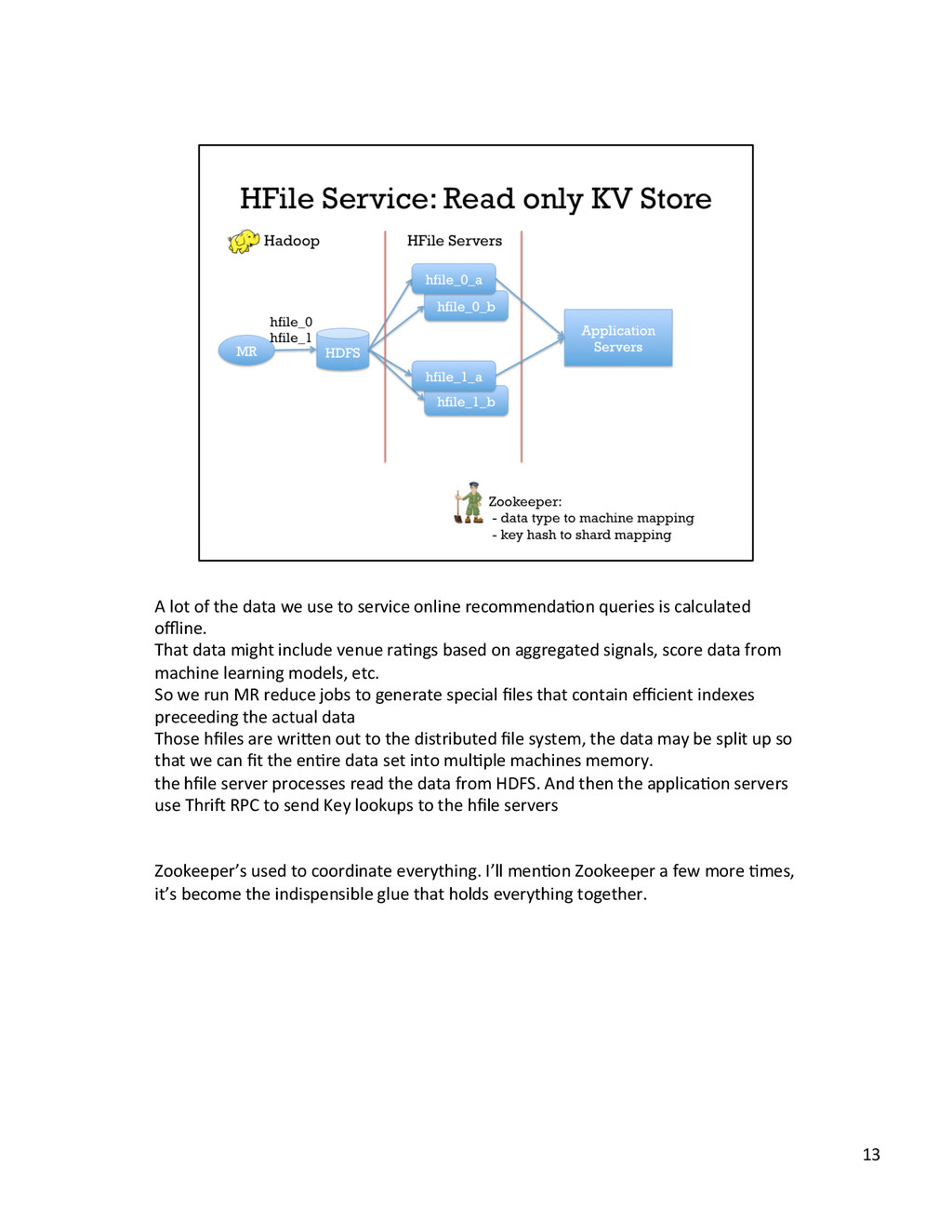{kind=link}
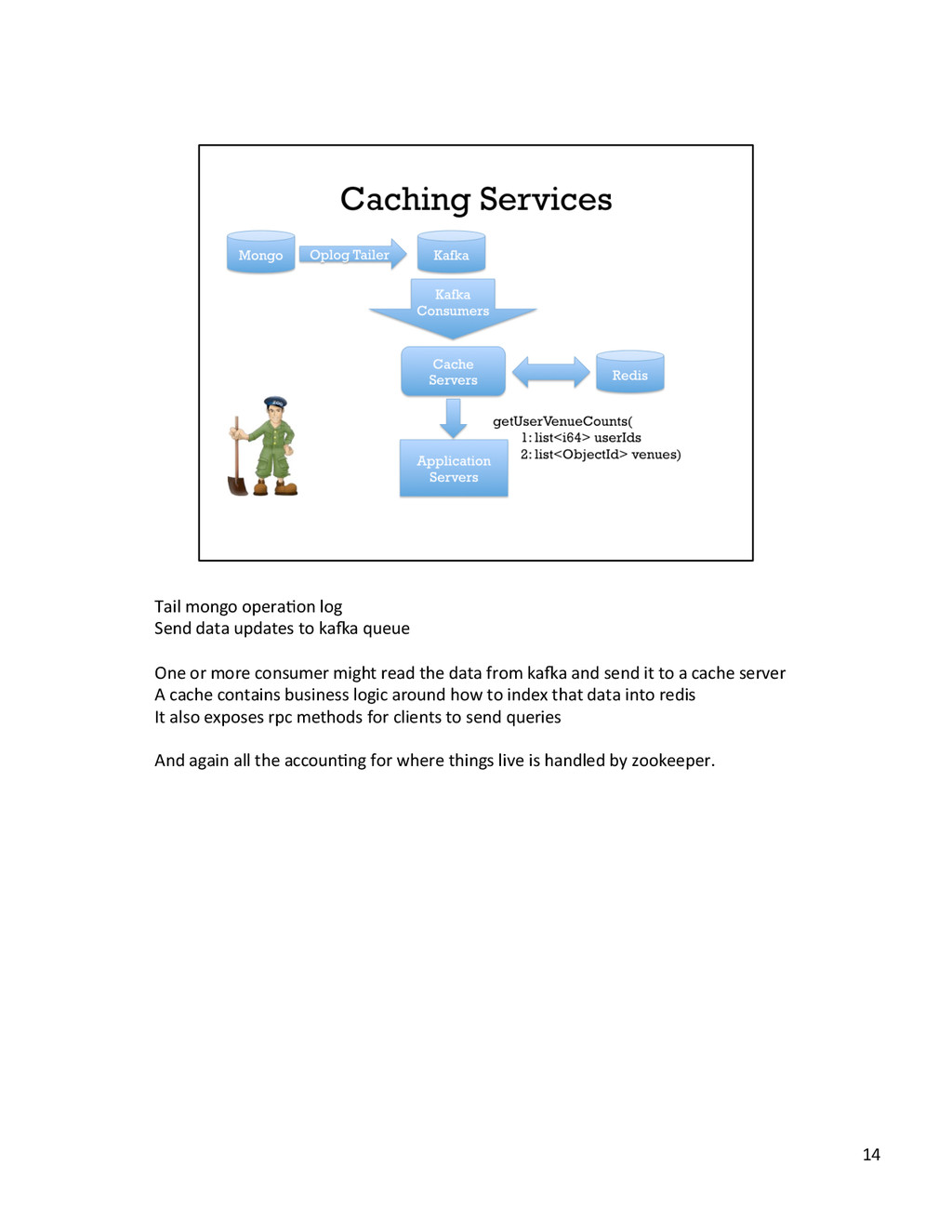{kind=link}
{kind=link}
{kind=link}
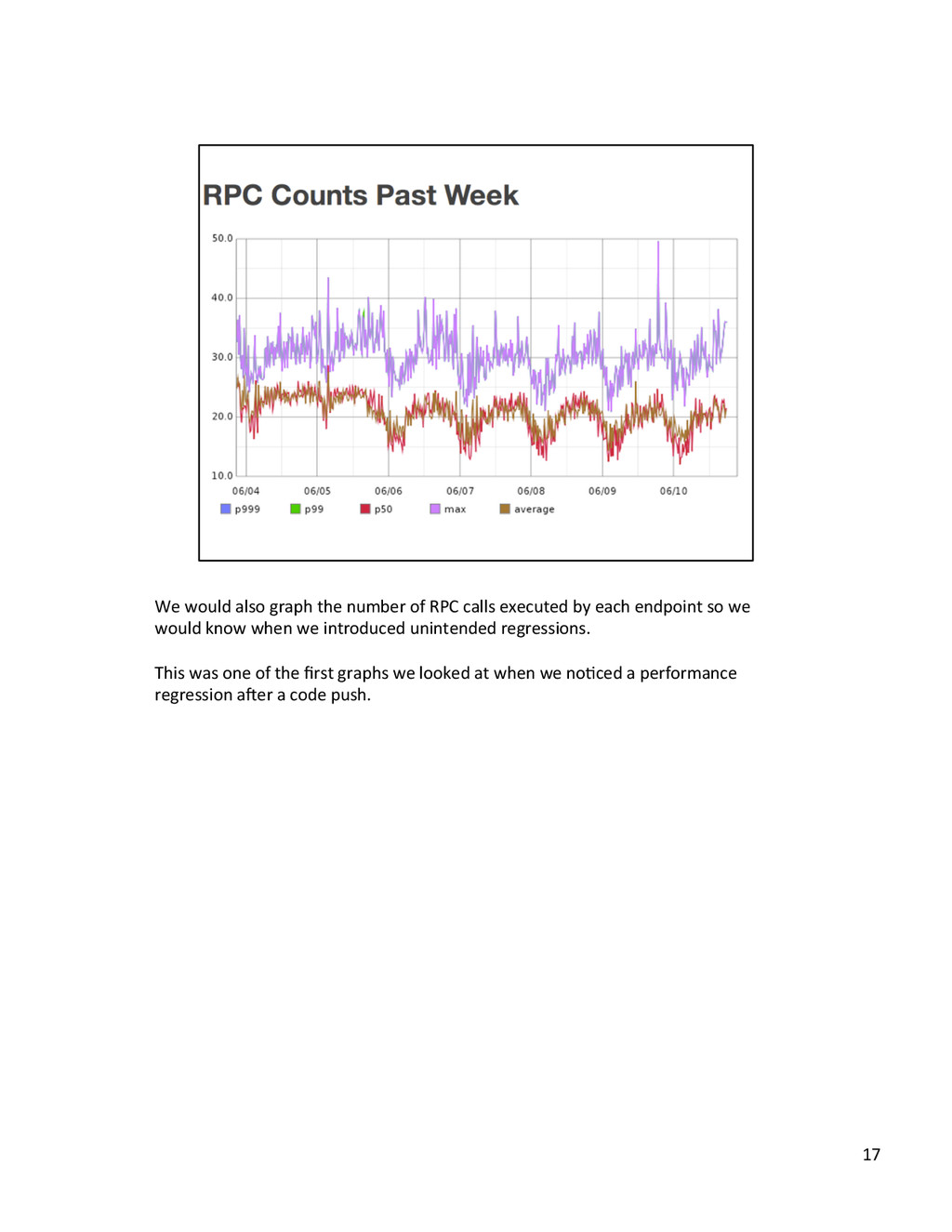{kind=link}
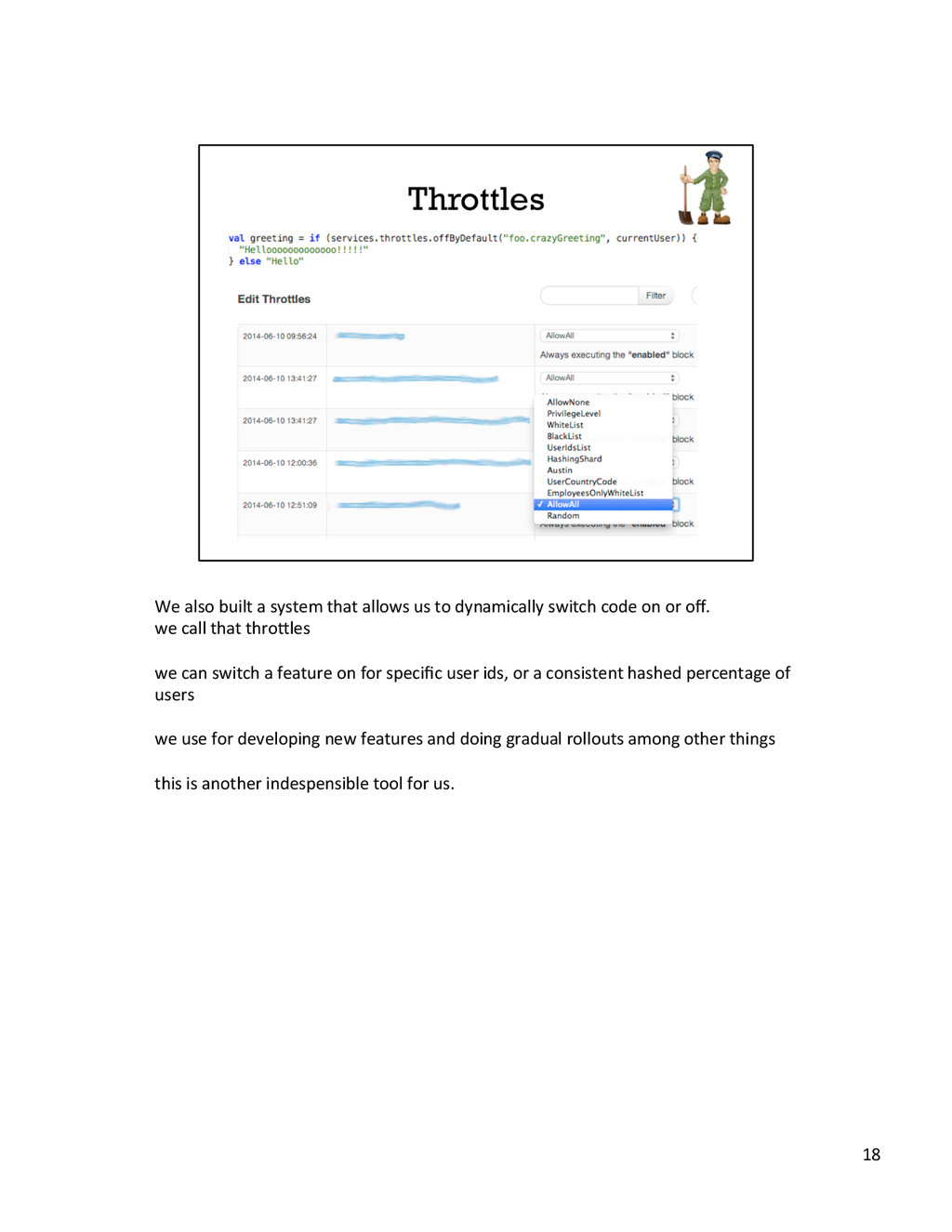{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}