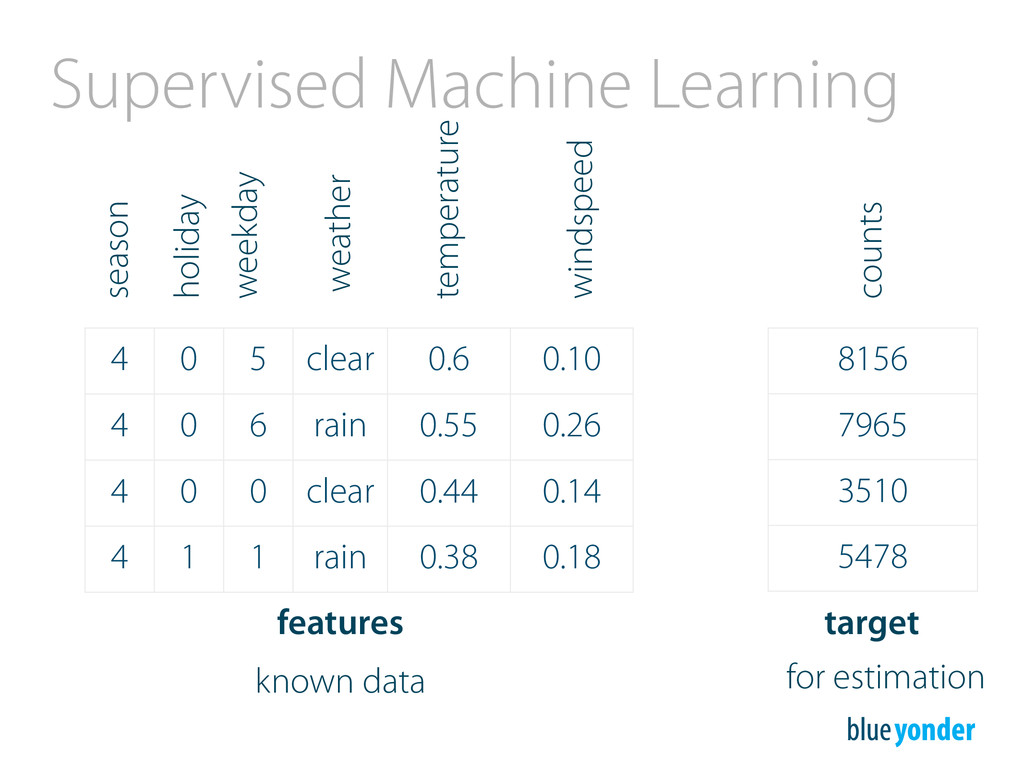
estimator using X, y est.predict(X) → y estimate target from feature-data We train the model using feature & known target values, we estimate the based on feature values only.
/= np.std(x, axis=0) For some estimators, we need to scale each feature to mean µ=0 and standard deviation σ=1 But what about missing values? Suppose we have NaN values in x
[ nan, 18. ], [ 9.8, 31. ]]) array([[ 1. , 0.78406256], [ 0. , -1.41131261], [-1. , 0.62725005]]) Results to: This works for the fit, but how do we prepare for the predict?
], [ nan, 18. ], [ 9.8, 31. ]]) scaler = NaNGuessingScaler() Xt = scaler.fit_transform(X) np.testing.assert_allclose(np.std(Xt, axis=0), [1., 1.]) … The standard deviation is determined, before missing values are corrected to the mean. Rather have one transformer impute missing values and one transformer do the scaling Conclusion: !
to estimators. • Think in small, testable units • Have your complete trained model in a serialisable object. Conclusions Outlook • Composition of transformers for feature construction (FeatureUnion) • Composition of estimators (GridSearchCV, etc.)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Test array([[ nan, 0.78406256], [ nan, -1.41131261], [ nan, 0.62725005]])](https://files.speakerdeck.com/presentations/c95ab01cff4e443781dca033fd1337cc/slide_6.jpg){kind=link}
{kind=link}
![How does this transform our data? array([[ 15.7, 32. ],](https://files.speakerdeck.com/presentations/c95ab01cff4e443781dca033fd1337cc/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}