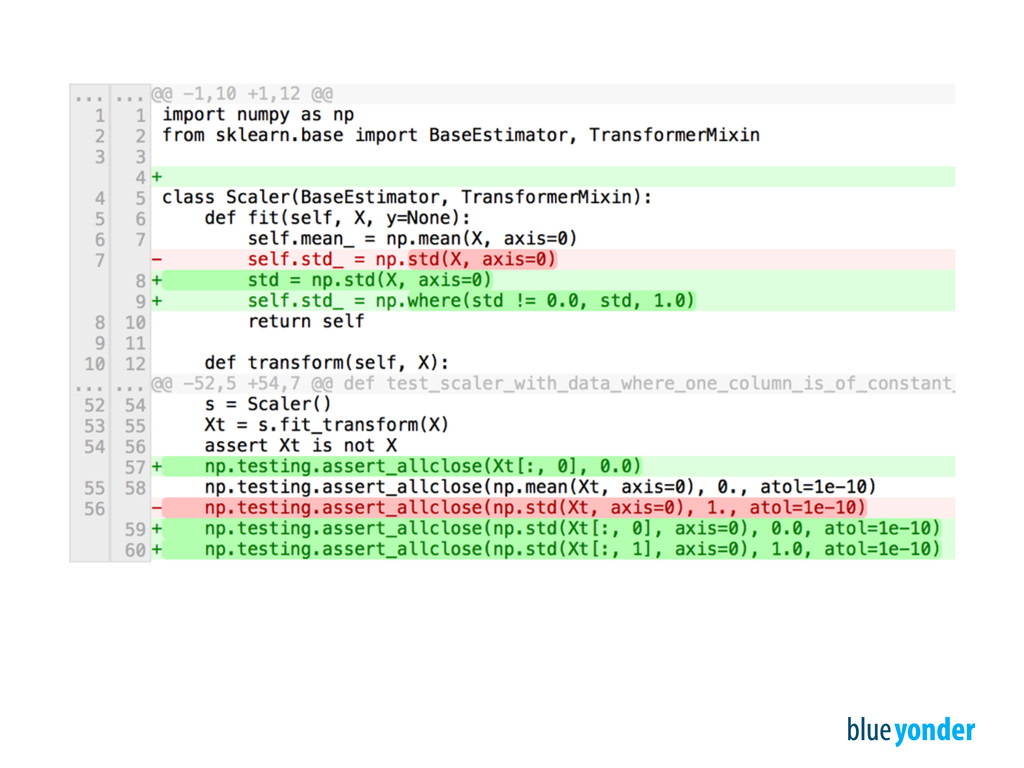
sklearn.base import BaseEstimator, TransformerMixin class Scaler(BaseEstimator, TransformerMixin): def fit(self, X, y=None): self.mean_ = np.mean(X, axis=0) self.std_ = np.std(X, axis=0) return self def transform(self, X): X = np.asarray(X, dtype=np.float).copy() X -= self.mean_ X /= self.std_ return X def test_scaler_noop(): X = np.c_[[-1, 1]] s = Scaler() Xt = s.fit_transform(X) assert Xt is not X np.testing.assert_allclose(Xt, np.c_[[-1, 1]]) np.testing.assert_allclose(np.mean(Xt, axis=0), 0., atol=1e-10) np.testing.assert_allclose(np.std(Xt, axis=0), 1., atol=1e-10) def test_scaler_simple(): X = np.c_[np.arange(10.), np.arange(10.)] s = Scaler() Xt = s.fit_transform(X) assert Xt is not X np.testing.assert_allclose(np.mean(Xt, axis=0), 0., atol=1e-10) np.testing.assert_allclose(np.std(Xt, axis=0), 1., atol=1e-10) def test_scaler_with_data_where_one_column_is_of_constant_value(): X = np.c_[np.ones(10.), np.arange(10.)] s = Scaler() Xt = s.fit_transform(X) assert Xt is not X np.testing.assert_allclose(np.mean(Xt, axis=0), 0., atol=1e-10) np.testing.assert_allclose(np.std(Xt, axis=0), 1., atol=1e-10)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
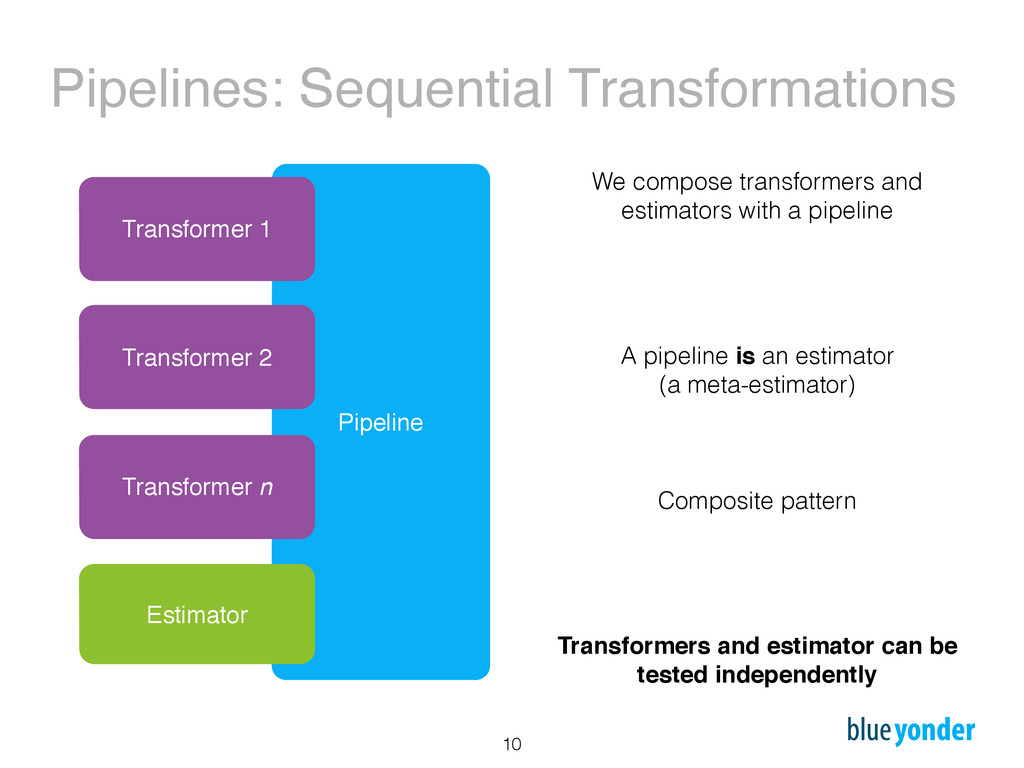
![Example pipe = Pipeline([('pca', PCA(n_components=20)), ('scaler', StandardScaler()), ('svc', LinearSVC())]) pipe.fit(X_train,](https://files.speakerdeck.com/presentations/dff5fa6243cd4a95b044fa607b4e02d3/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}