* Abstract:
Life doesn’t happen in batch mode which is why application engineers and data architects need to closely cooperate to get the best out of streaming platforms like Apache Kafka and NoSQL data stores such as MongoDB. This session explores ways and means to integrate both worlds in a streaming fashion.
* Description:
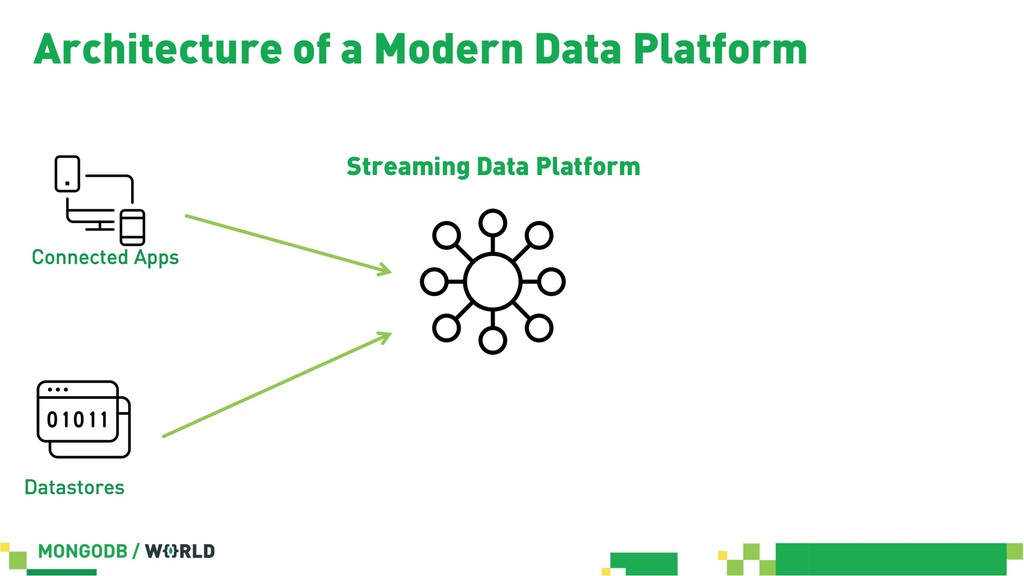
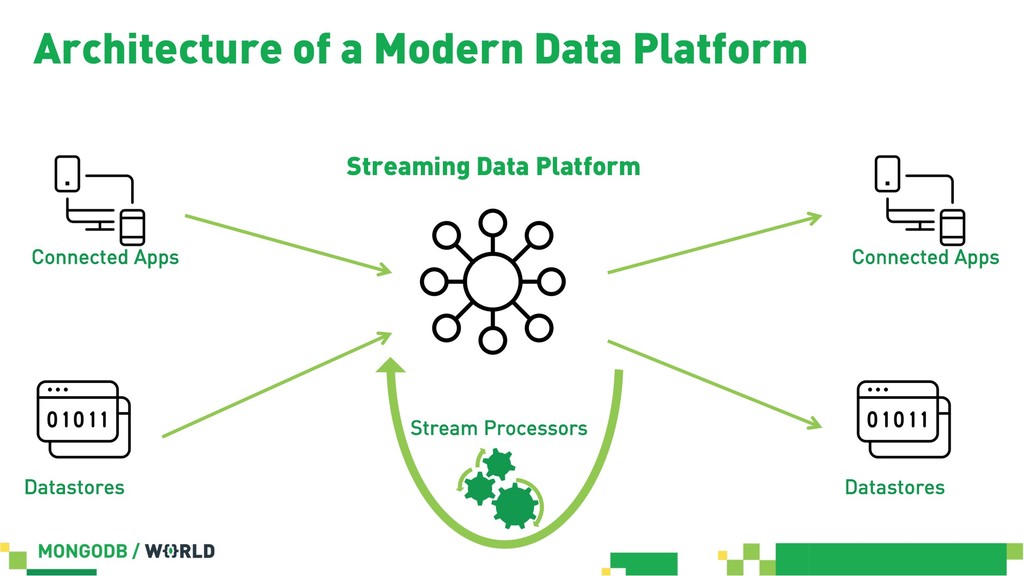
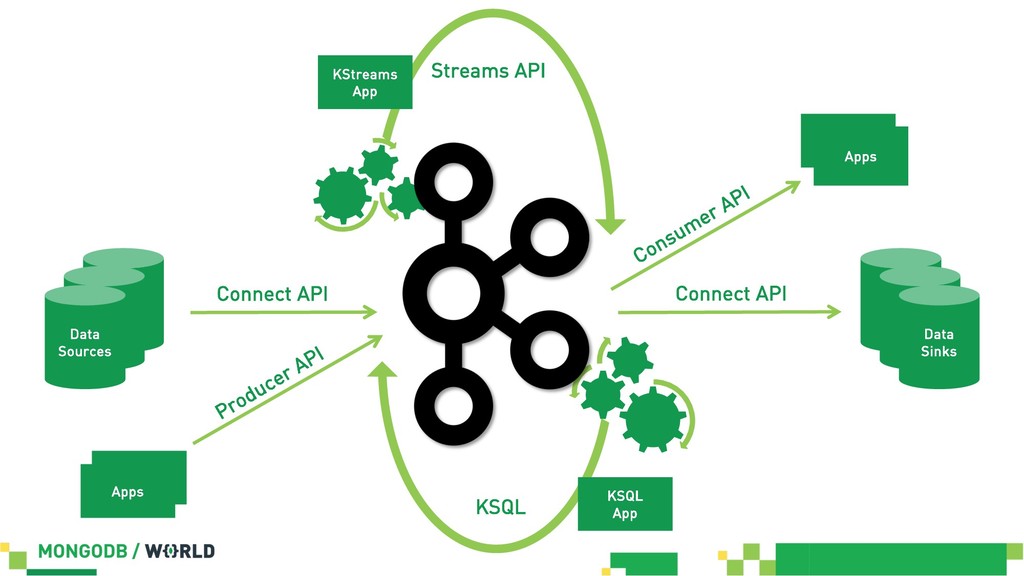
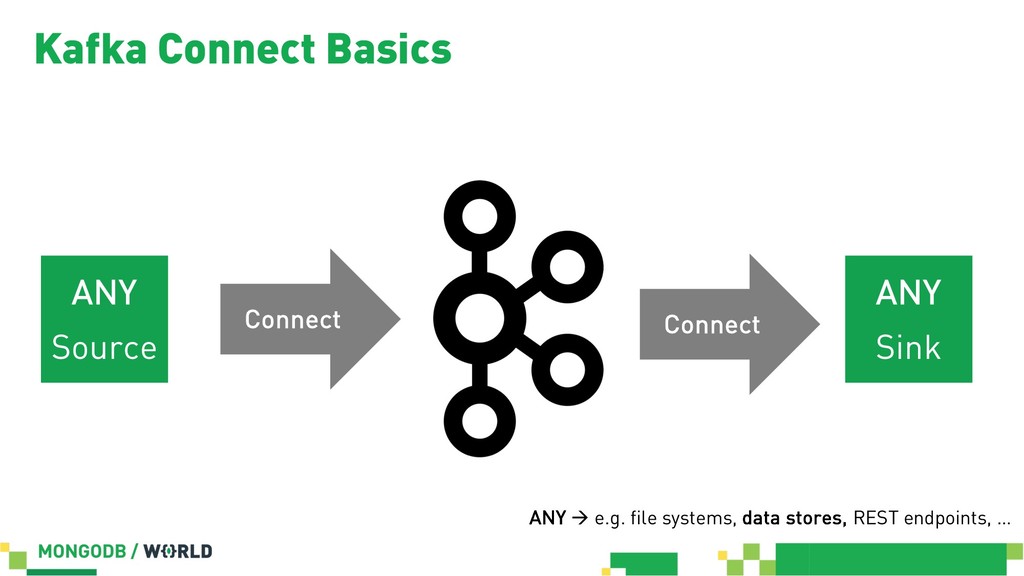
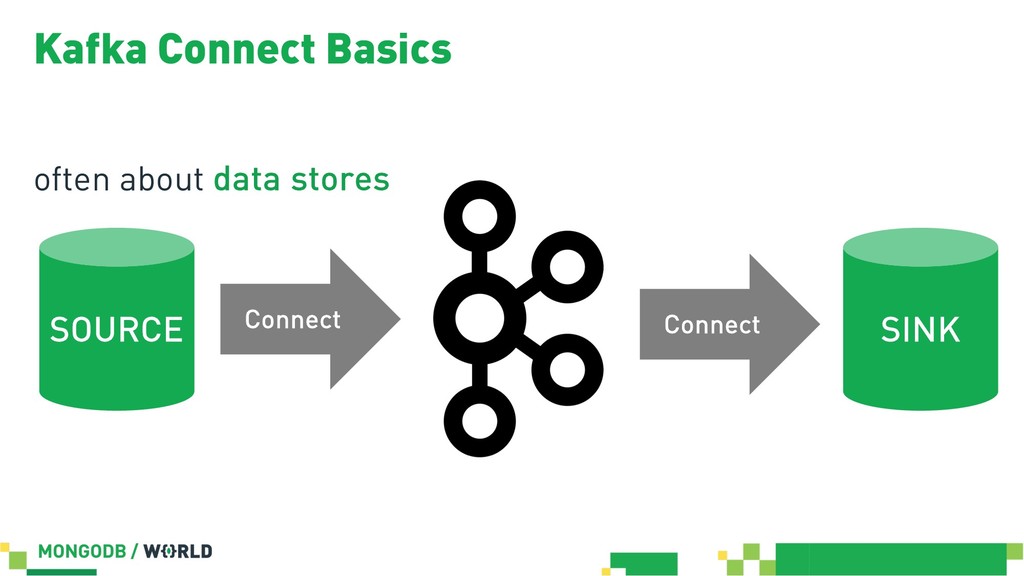
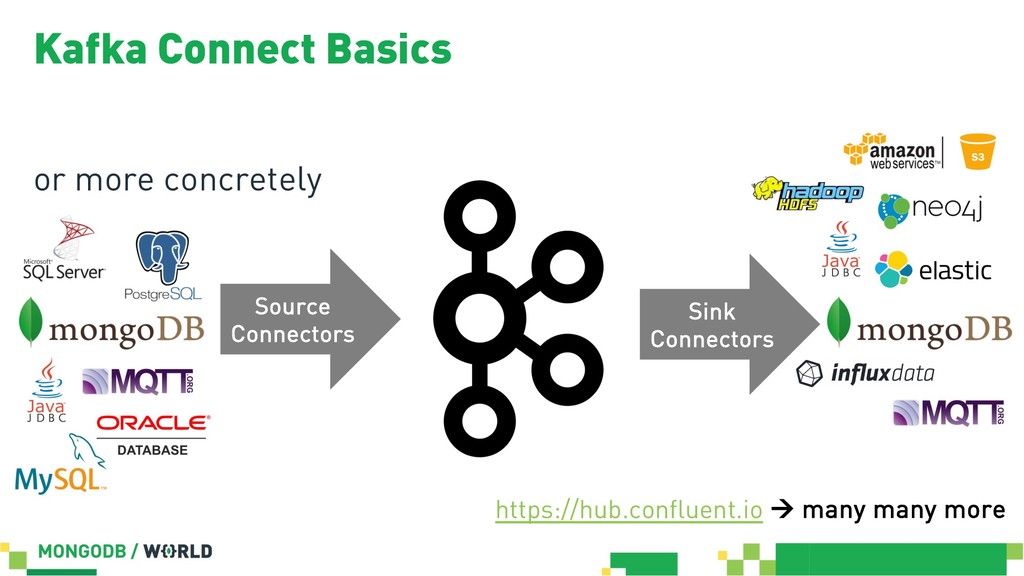
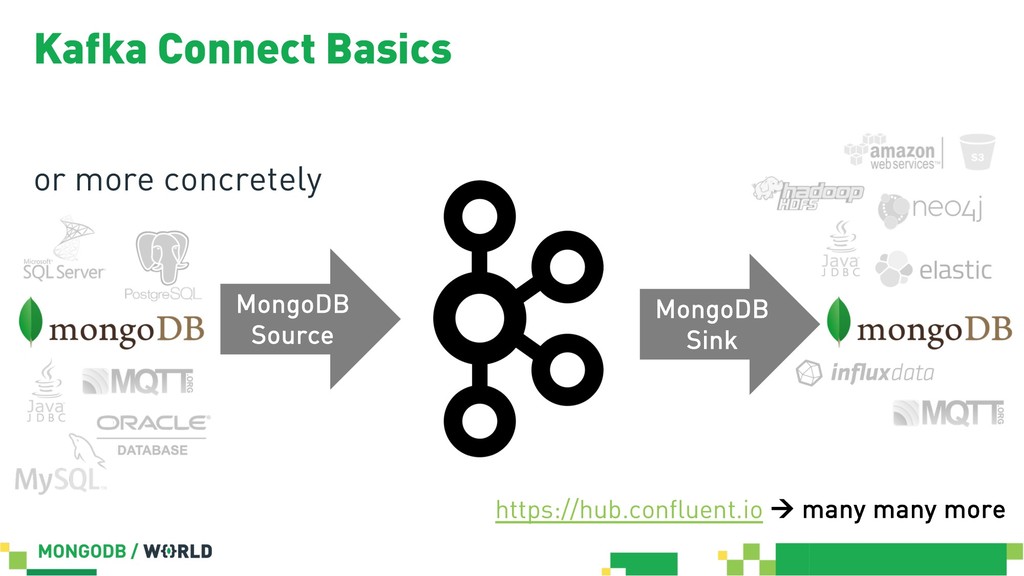
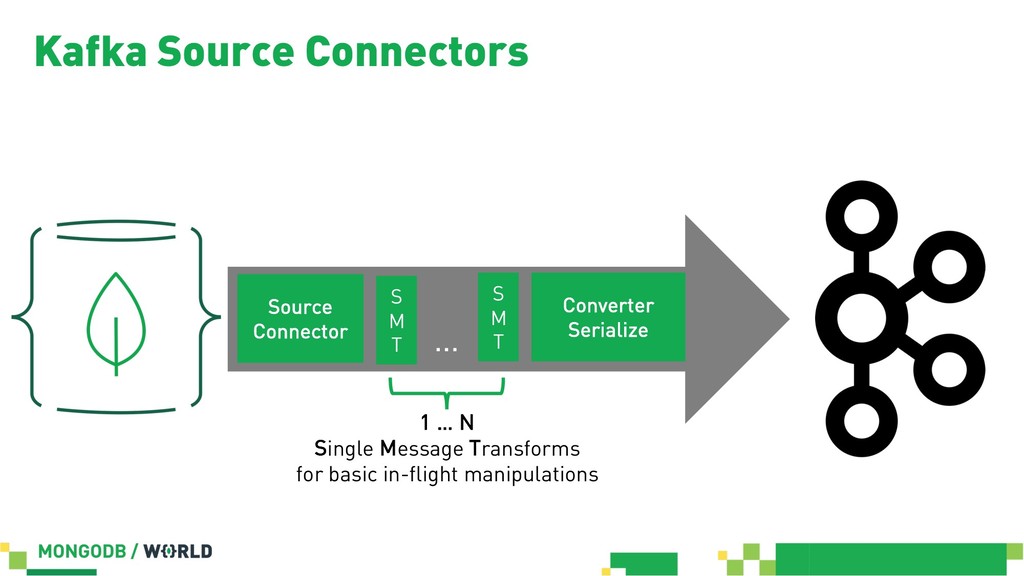
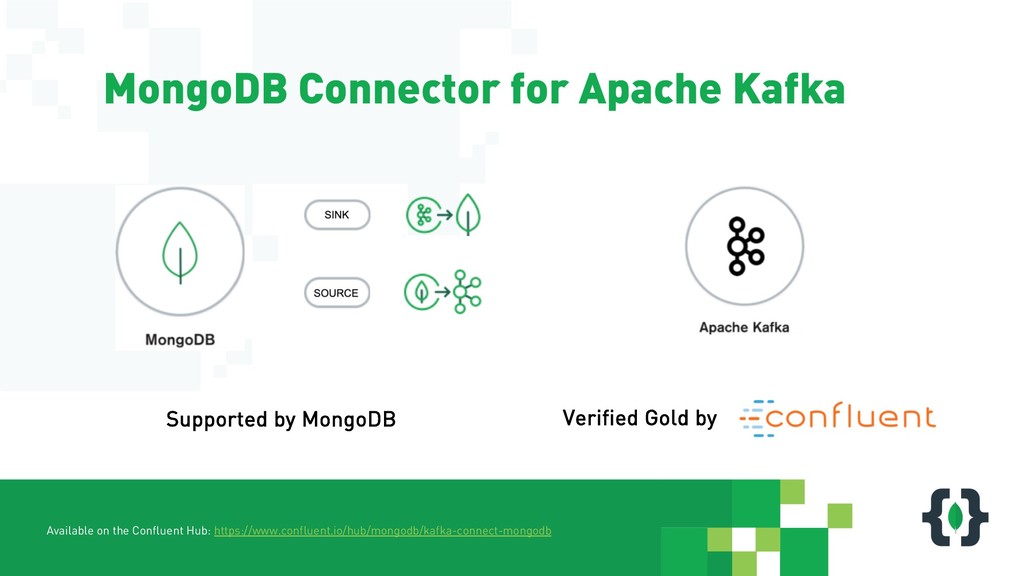
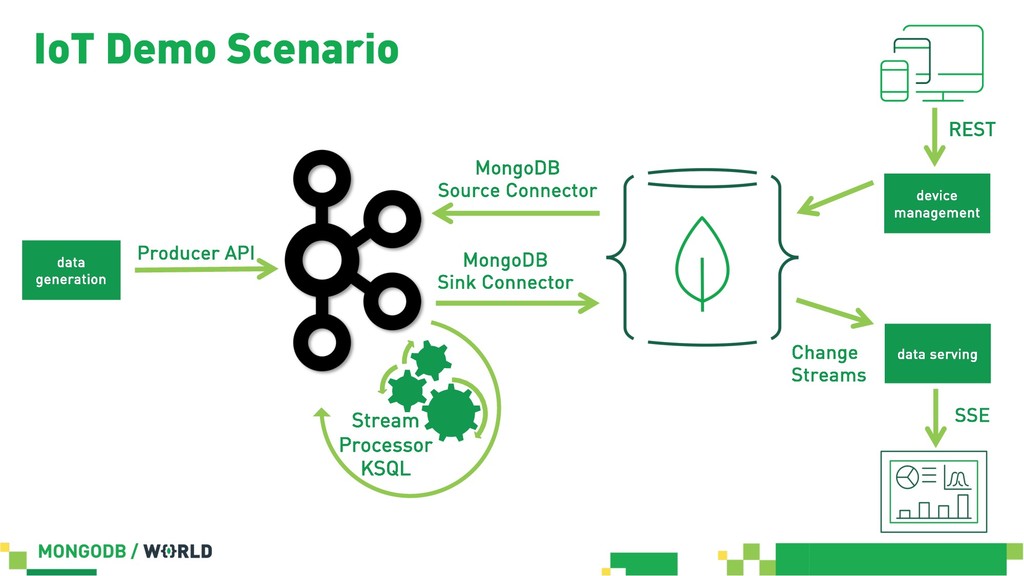
Without doubt stream processing is a big deal these days and oftentimes we find Apache Kafka as the central nervous system of company-wide data architectures. However, many real-world uses cases simply need an operational data store which is flexible, robust and scalable enough to live up to diverse application-related requirements and challenges. This session discusses different options in order to build solid data integration pipelines between MongoDB and Apache Kafka. The focus lies on configuration-based data in motion scenarios leveraging the Kafka Connect framework in order to lay out streaming ETL pipeline examples without writing a single line of code.
* Video Recording: pending...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
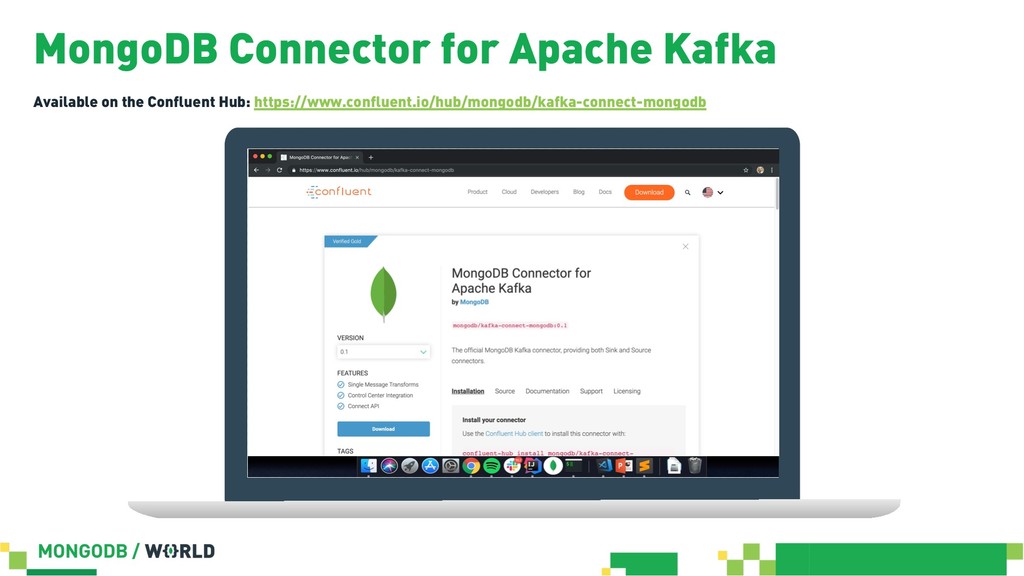{kind=link}
{kind=link}
{kind=link}
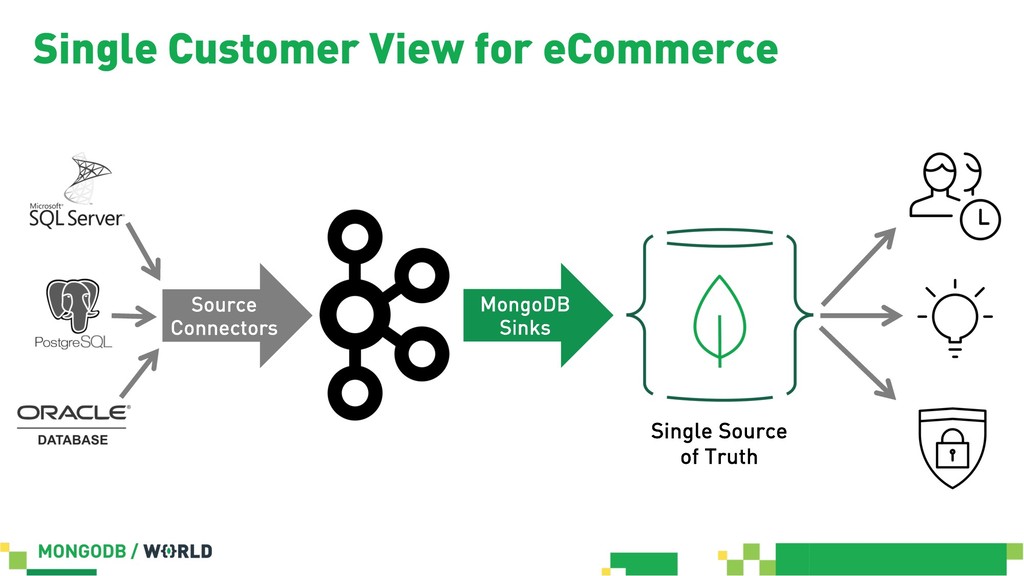{kind=link}
{kind=link}
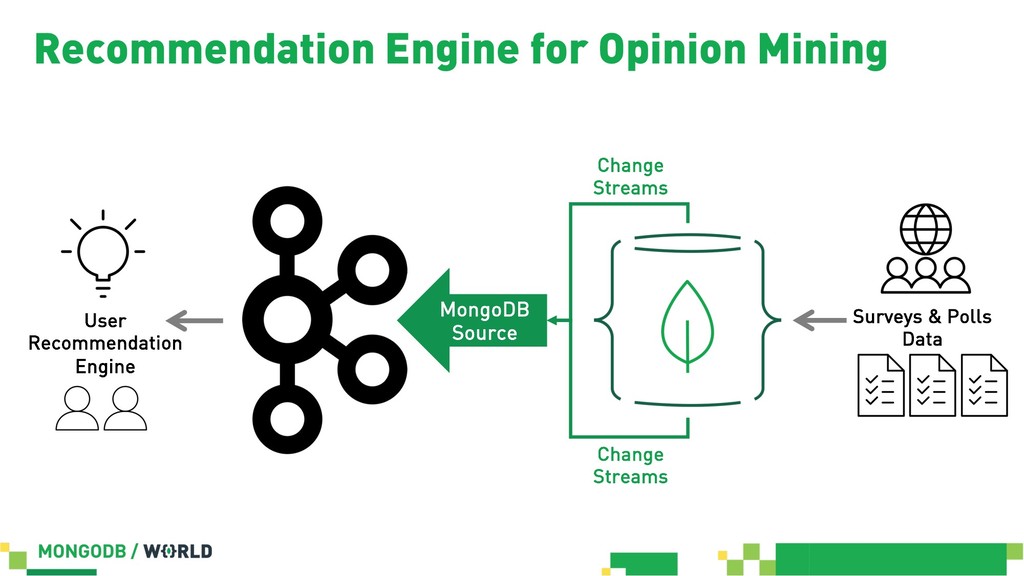{kind=link}
{kind=link}
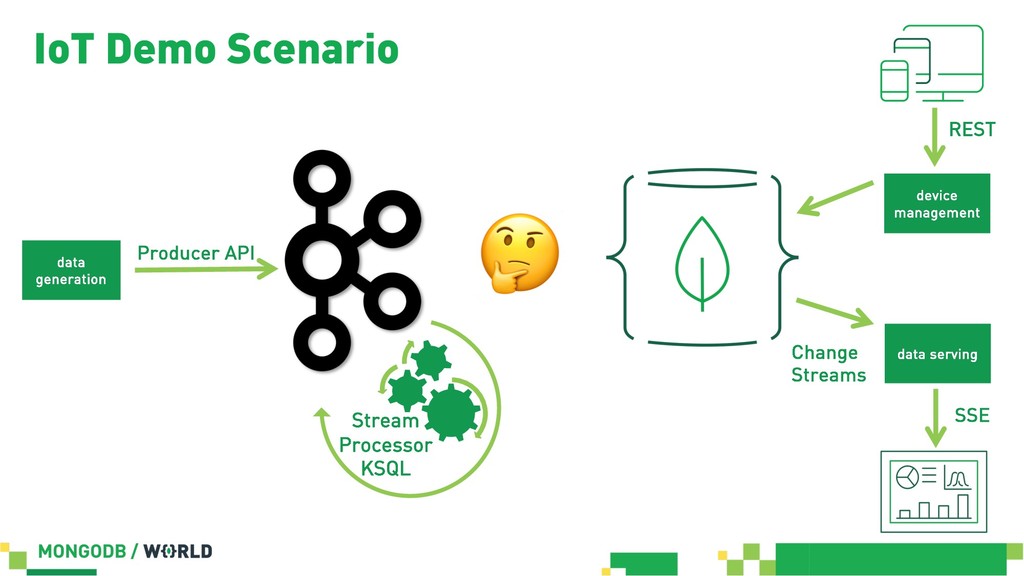{kind=link}
{kind=link}
{kind=link}
{kind=link}