suitable free region, possibly breaking it in two. Freeing requires merging adjacent free regions. To run fast, the data structure gets more complex. To run in a multithreaded environment, the DLmalloc protects its data structures with a lock. DLmalloc [Lea 87] uses boundary tags is slow, and for multithreaded code, it’s even slower. DLmalloc is the standard allocator in Linux and has changed little in 28 years. Modern allocators use other data structures.
{kind=link}
{kind=link}
{kind=link}
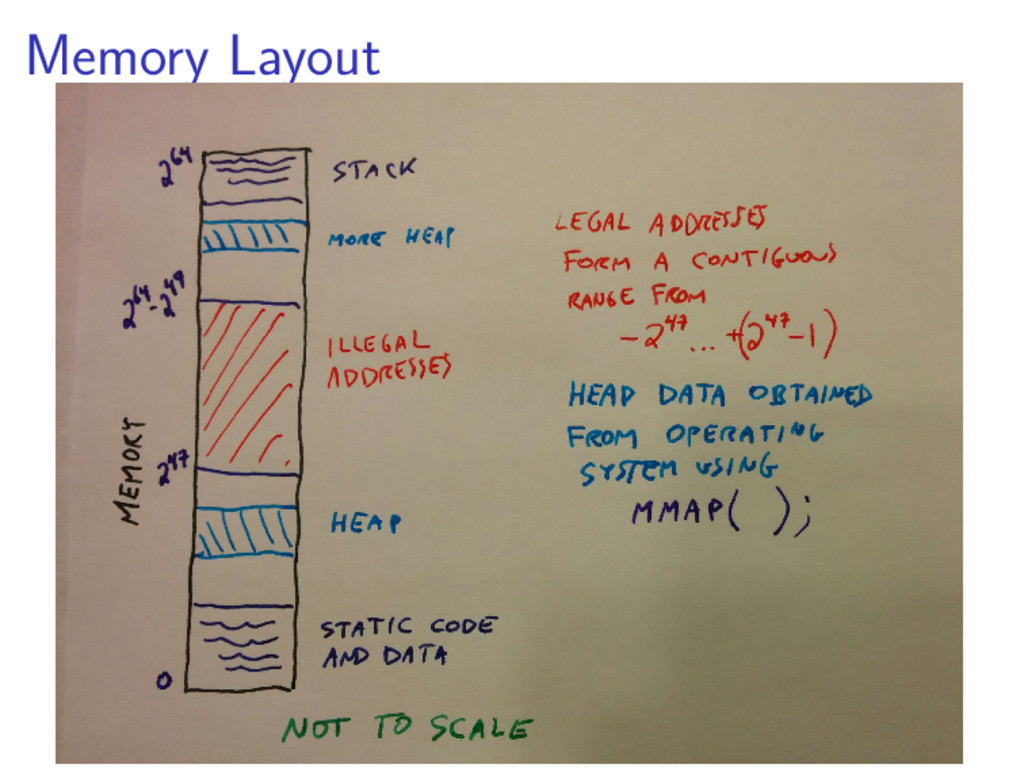{kind=link}
![Boundary Tags [Knuth 73]](https://files.speakerdeck.com/presentations/1dc7bfe336474da48d202eccc849f87e/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![The Problem with Thread Caches The malloc-test workload [LeverBo00]. queue](https://files.speakerdeck.com/presentations/1dc7bfe336474da48d202eccc849f87e/slide_8.jpg){kind=link}
![Useful Allocators Limit Space Hoard [BergerMcBl00] provides a competitive space](https://files.speakerdeck.com/presentations/1dc7bfe336474da48d202eccc849f87e/slide_9.jpg){kind=link}
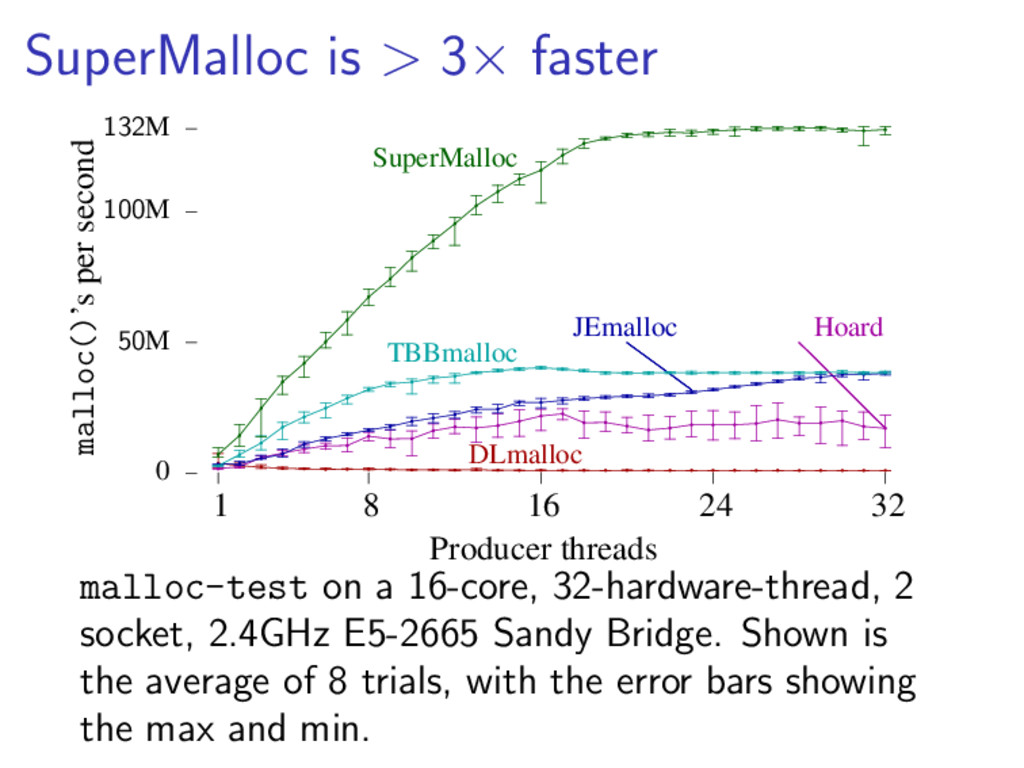{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}