Small: sizes are of the form 2k 1 , 5·2k 4 , 3·2k 2 , 7·2k 4 . (For example, 8, 10, 12, 14.) (These admit fast calculation of bin numbers.) Medium: prime numbers of cache lines: 5, 7, 11, 13, 17, 23, . . . cache lines. (Simply search for bin numbers.) To avoid fragmentation, use “pages” of 64 objects. These large “pages” are called folios. Large: page allocated plus a random offset. Huge: allocated via mmap plus a random offet. Aligned allocations have their own bins.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
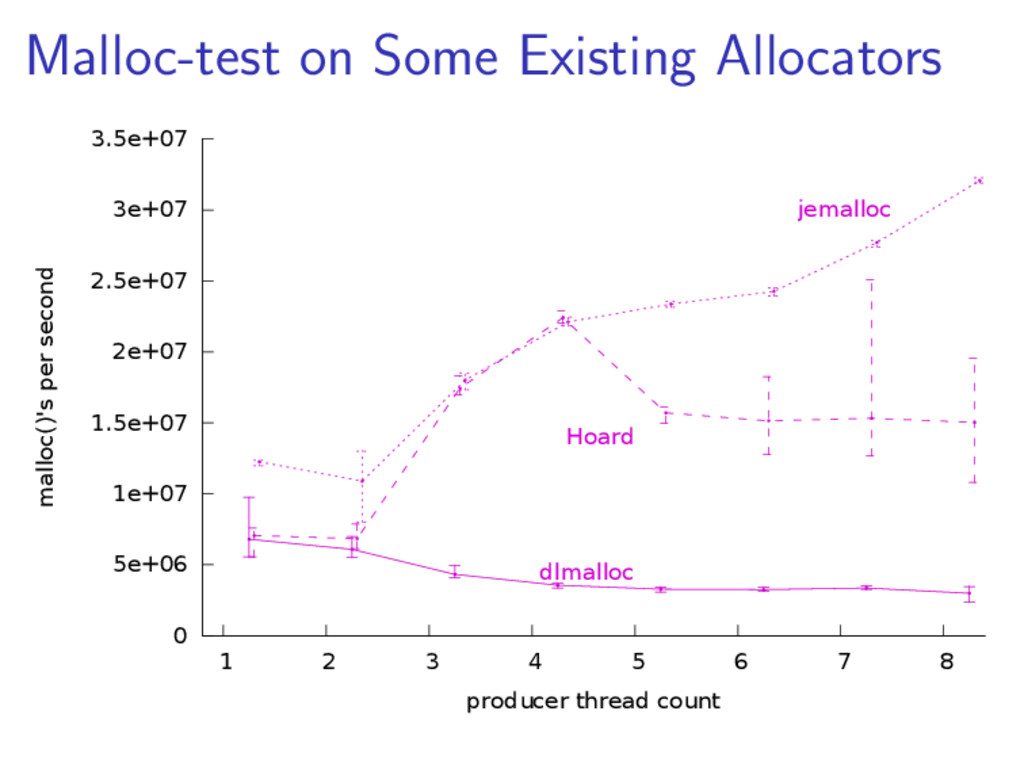{kind=link}
{kind=link}
{kind=link}
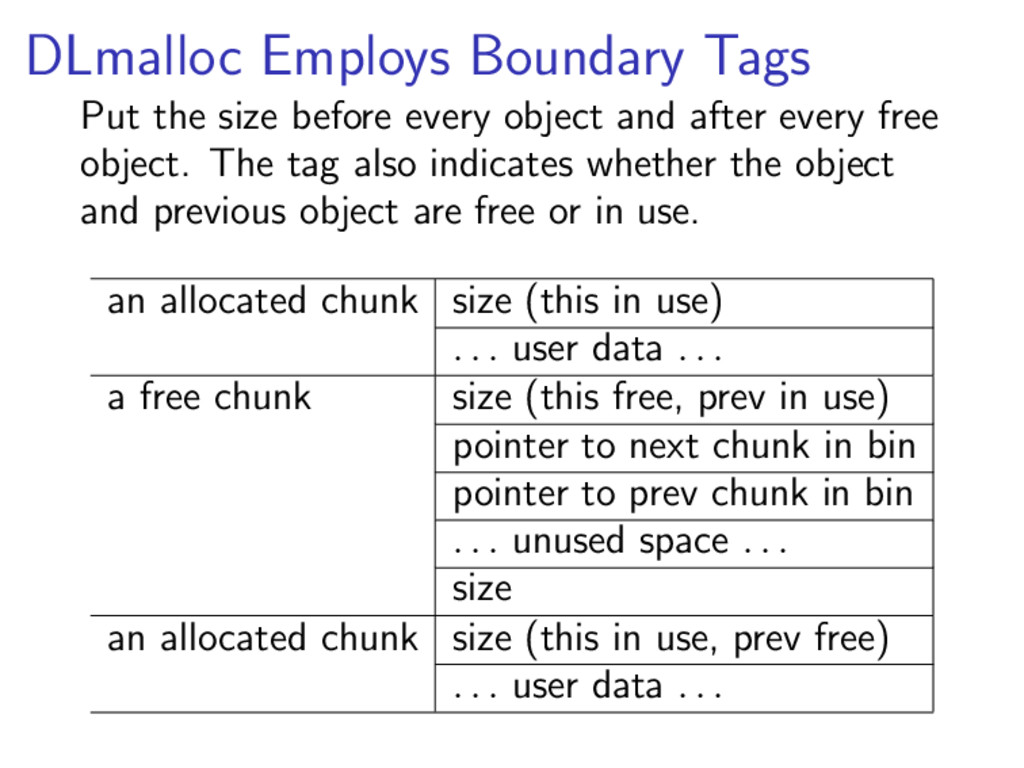{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
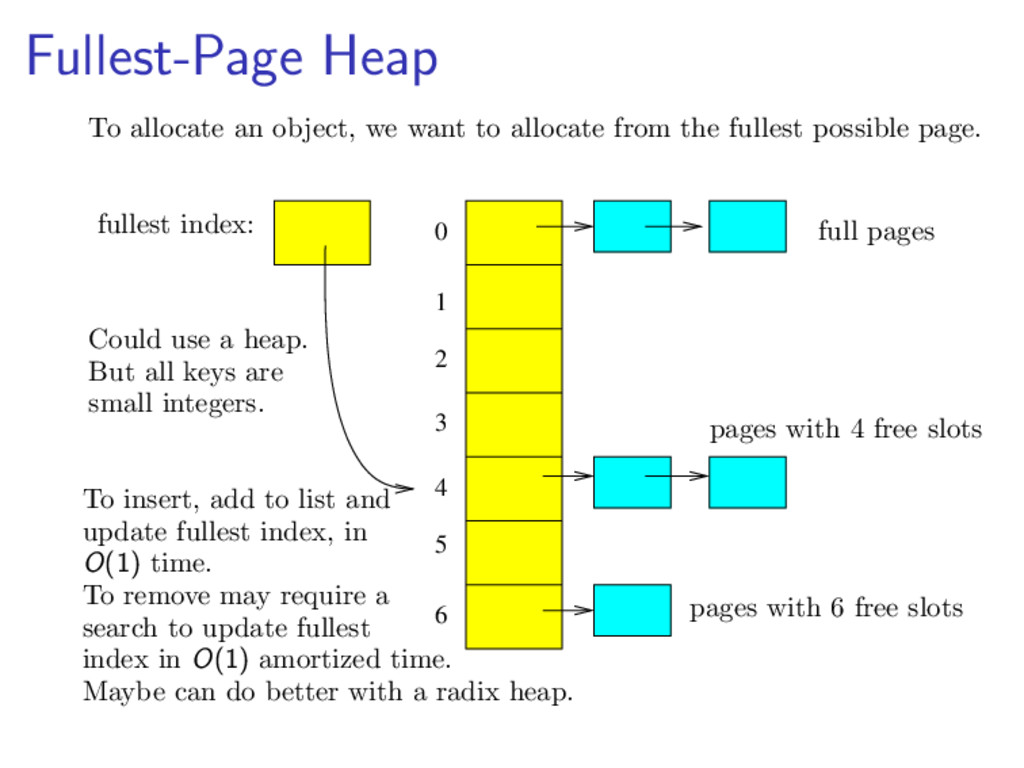{kind=link}
{kind=link}
{kind=link}
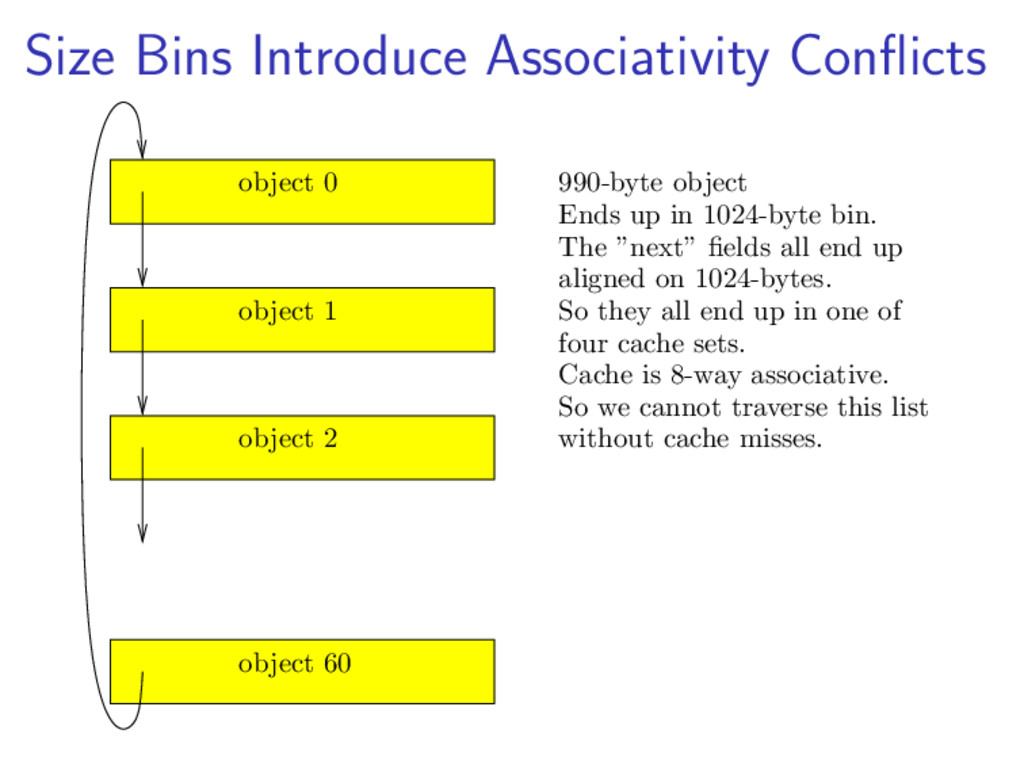{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}