, 5·2k 4 , 3·2k 2 , 7·2k 4 . The numbers are 8, 10, 12, 14, 16, 20, 24, 28, 32, 40, 48, 56, 64, 80, 96, 112, 128, 160, 192, 224, 256, and 320. These admit fast calculation of bin numbers via bit hacks. Technically, some of these are bad alignments: DLmalloc provides 8-byte aligned data, and programmers may expect it. Probably need to remove 10, 12, 14, 20, and 28.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Modern Allocators Employ Thread Caches __thread LinkedList *cache[N_SIZE_CLASSES]; void *alloc(size_t](https://files.speakerdeck.com/presentations/2da7e9457dbd4aac93461eedfe3a95dc/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
![Recent Allocators Also Improved Space Hoard [BergerMcBl00] provided the first](https://files.speakerdeck.com/presentations/2da7e9457dbd4aac93461eedfe3a95dc/slide_7.jpg){kind=link}
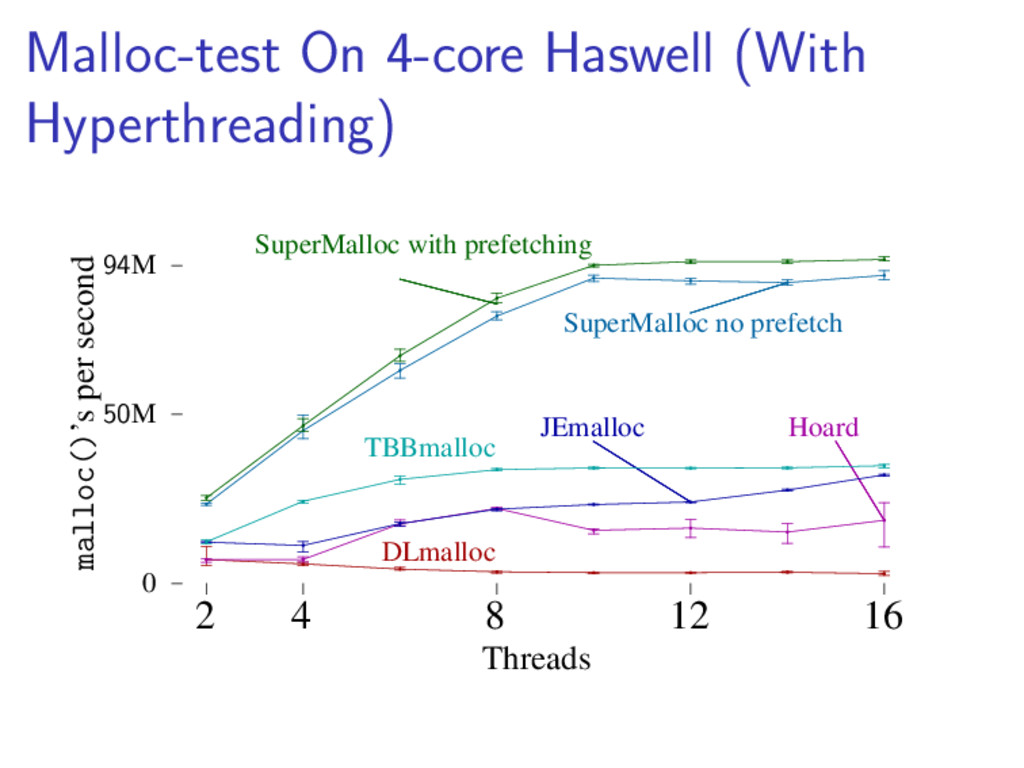{kind=link}
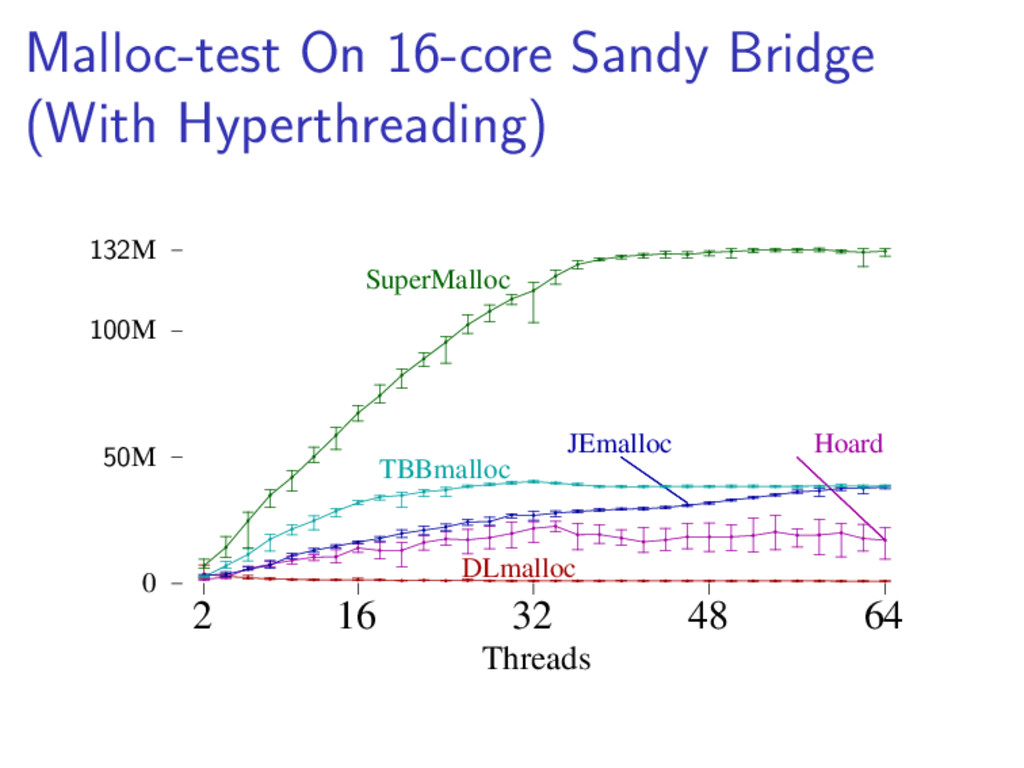{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
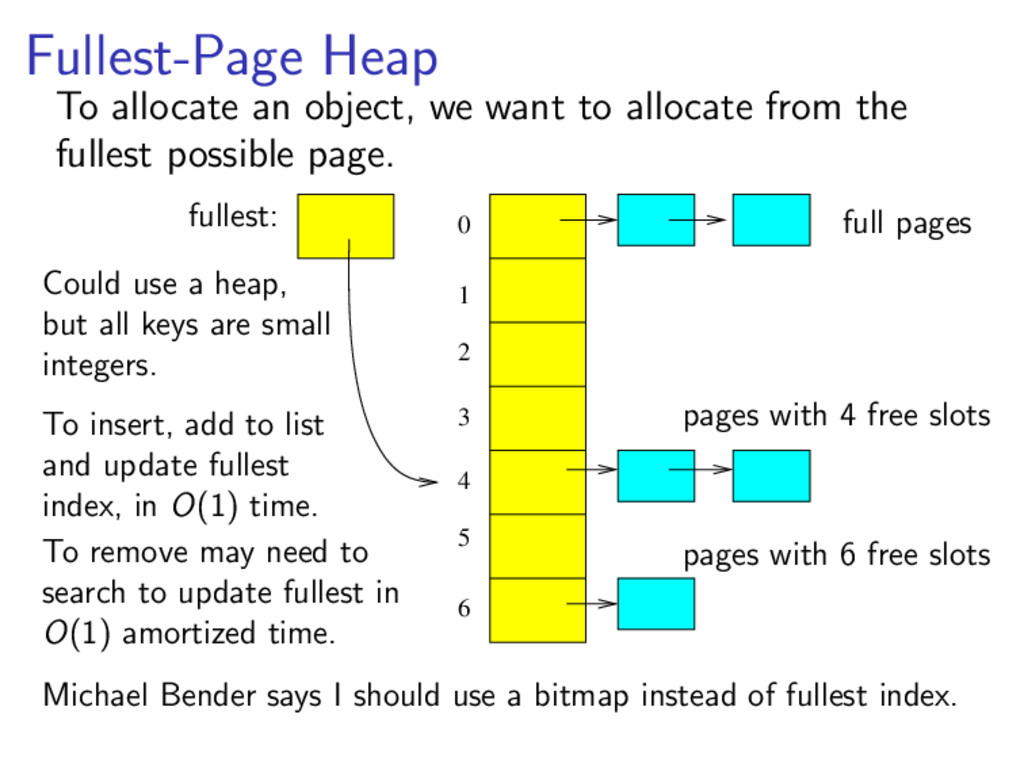{kind=link}
{kind=link}
{kind=link}
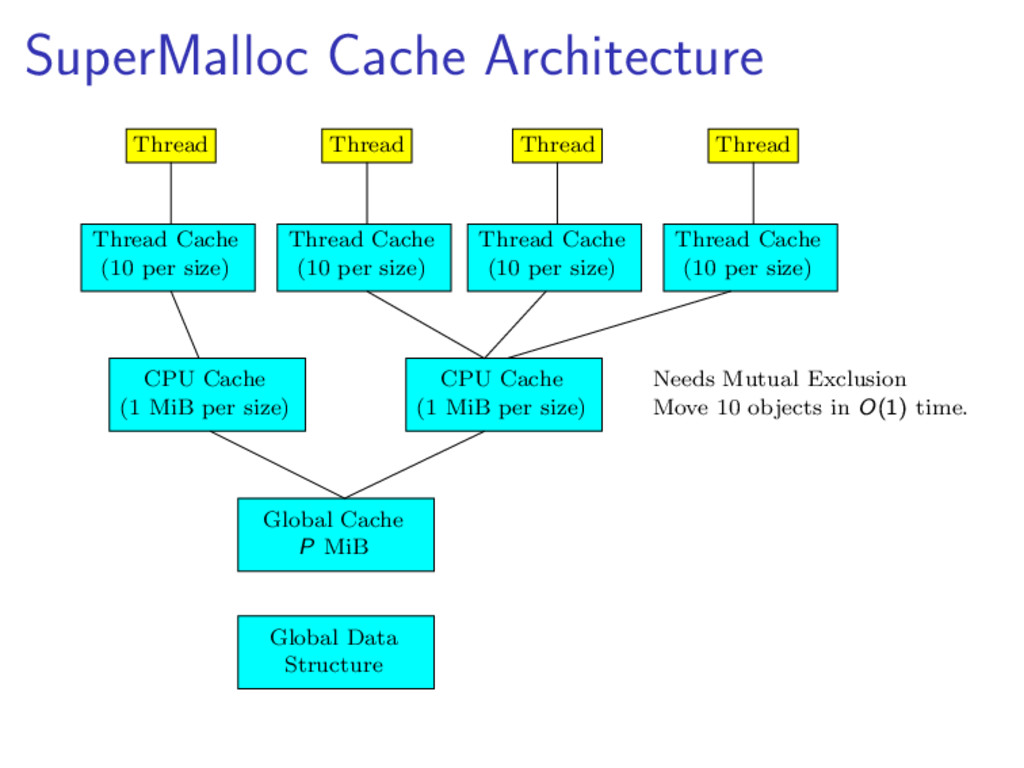{kind=link}
{kind=link}
{kind=link}
{kind=link}
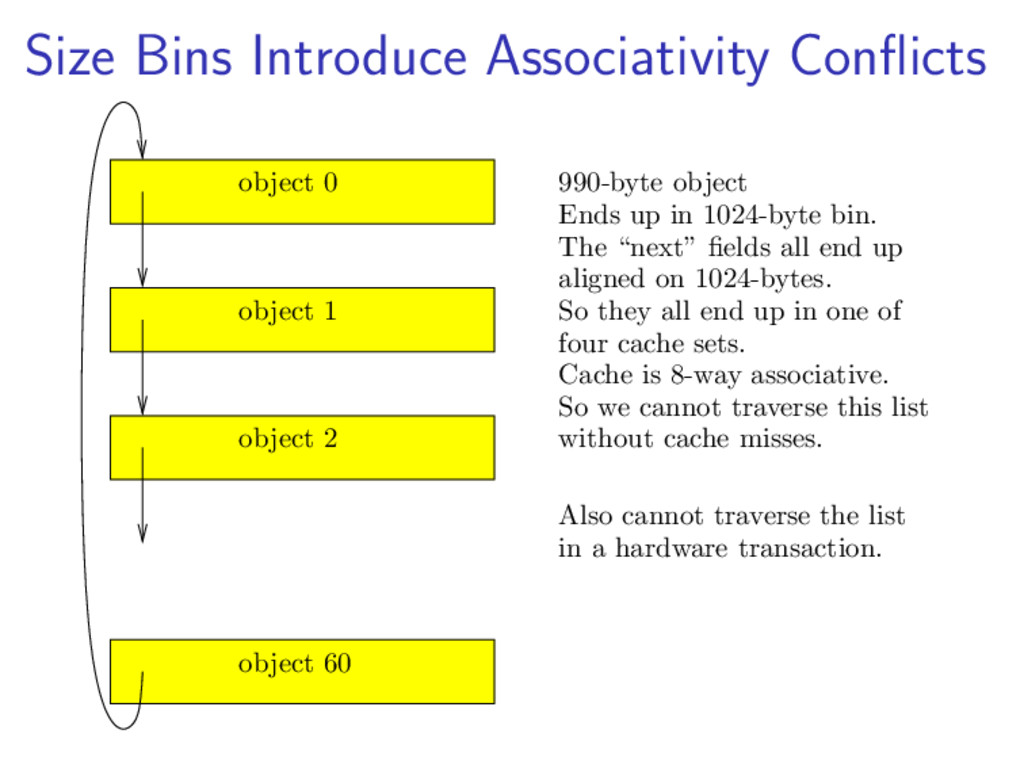{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}