We introduce 10 challenges in this workshop and welcome all attendance to try, solve, discuss and share the idea how to take a look for each issue and what's the way to fix it.
All issues in this workshop mainly focus on the Kubernetes basic concept, not a specific K8s application (istio...etc), help people to understand more K8s concept which may be ignored in their learning path.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
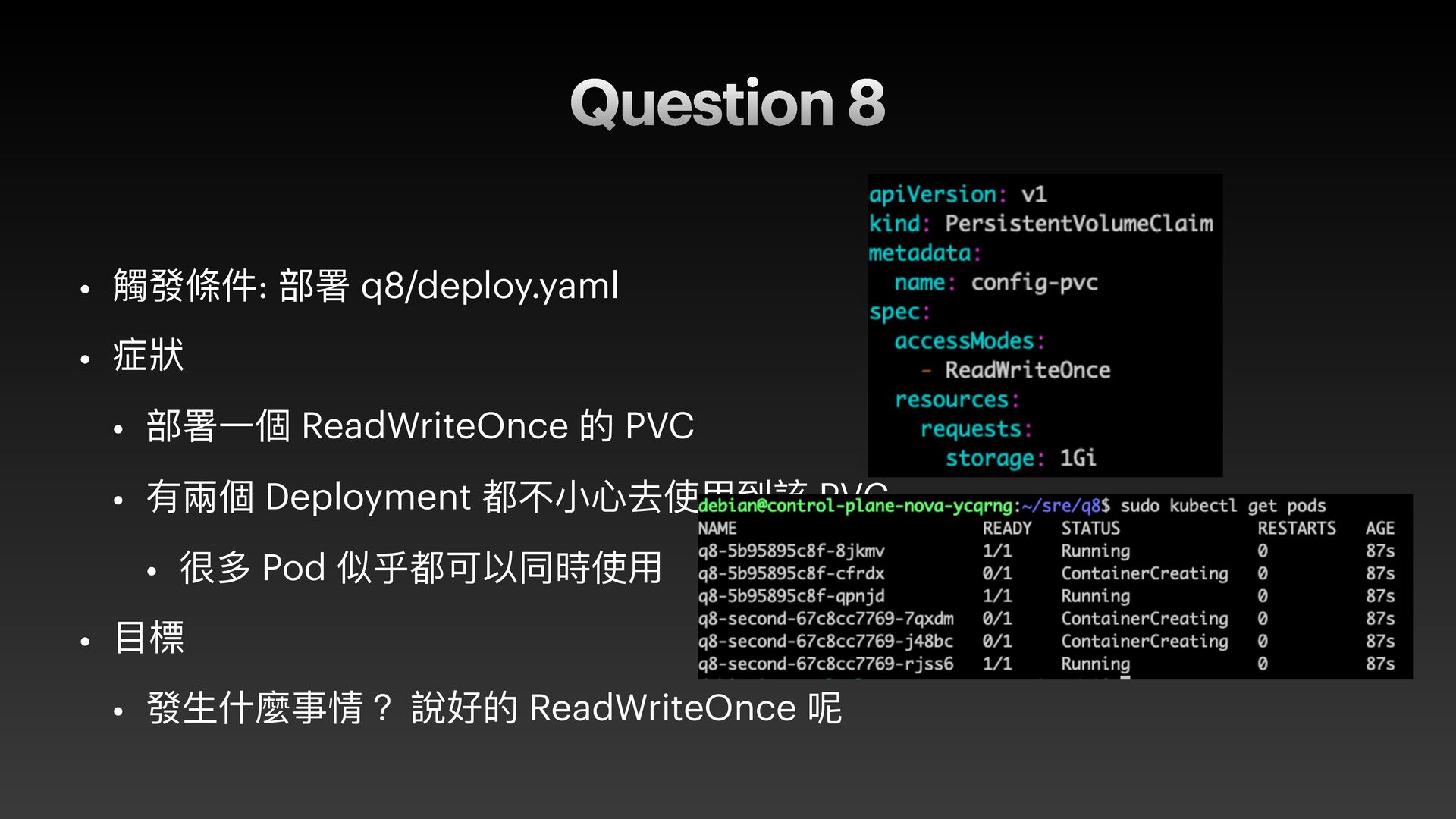{kind=link}
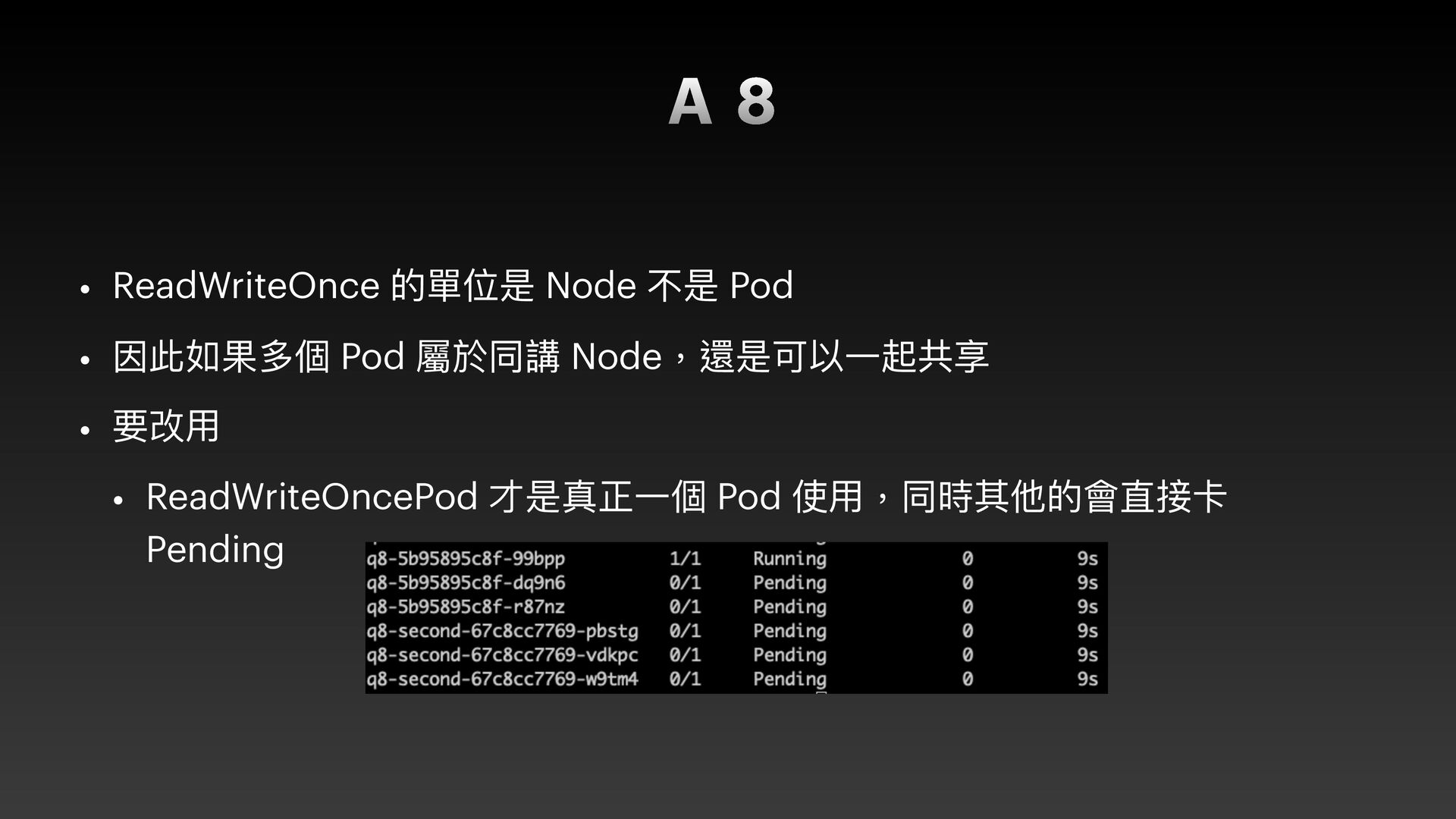{kind=link}
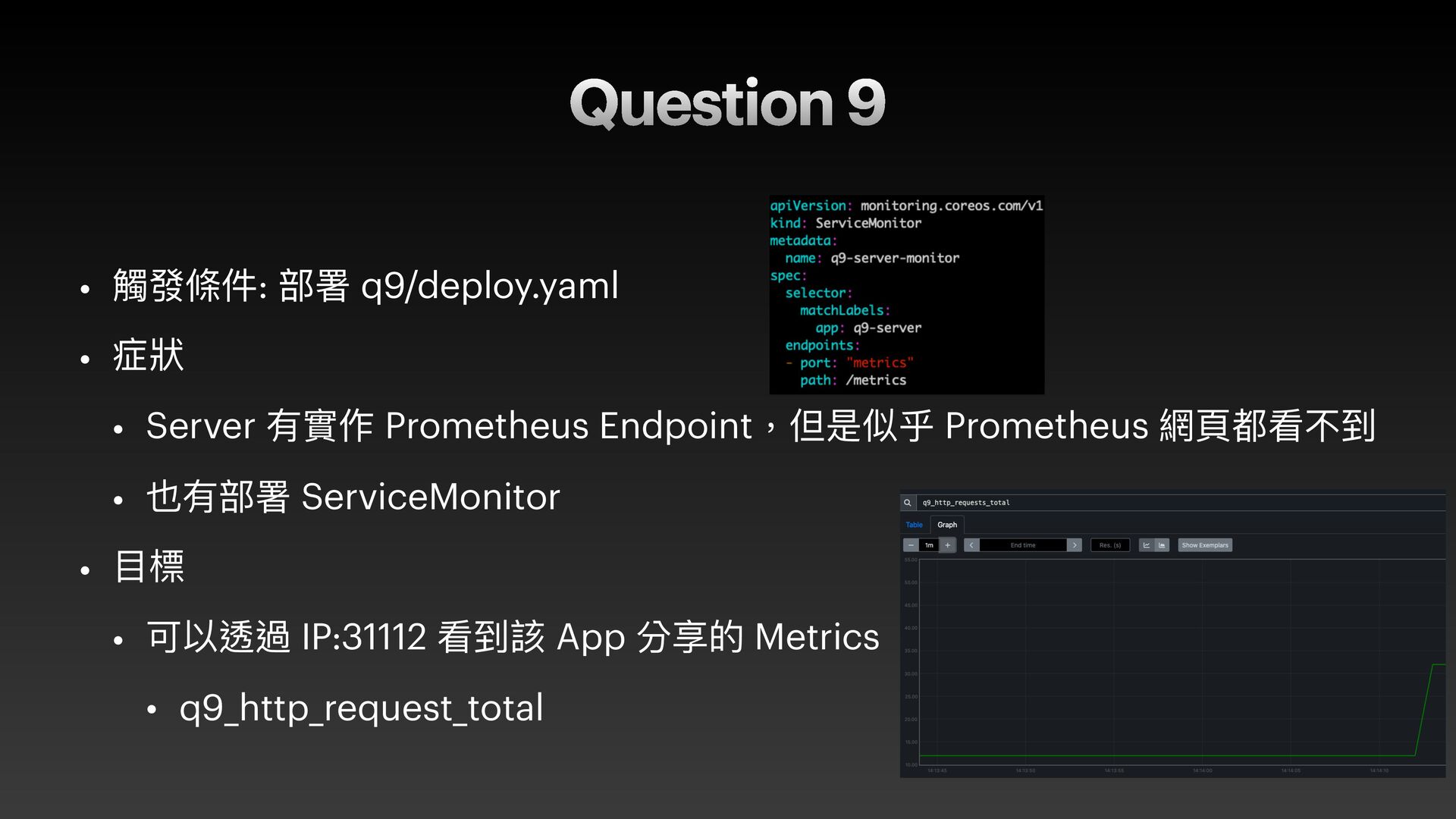{kind=link}
{kind=link}
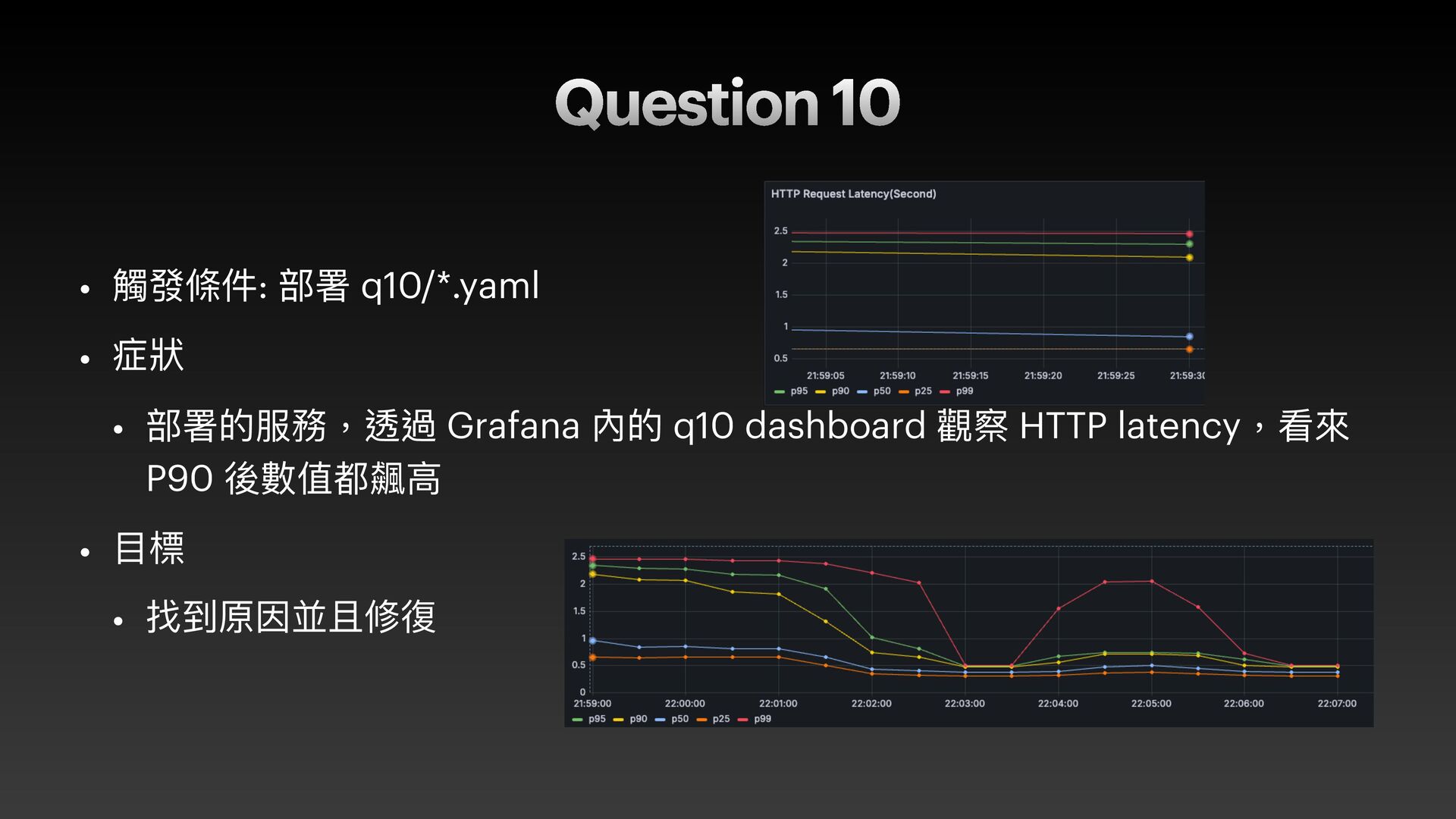{kind=link}
{kind=link}