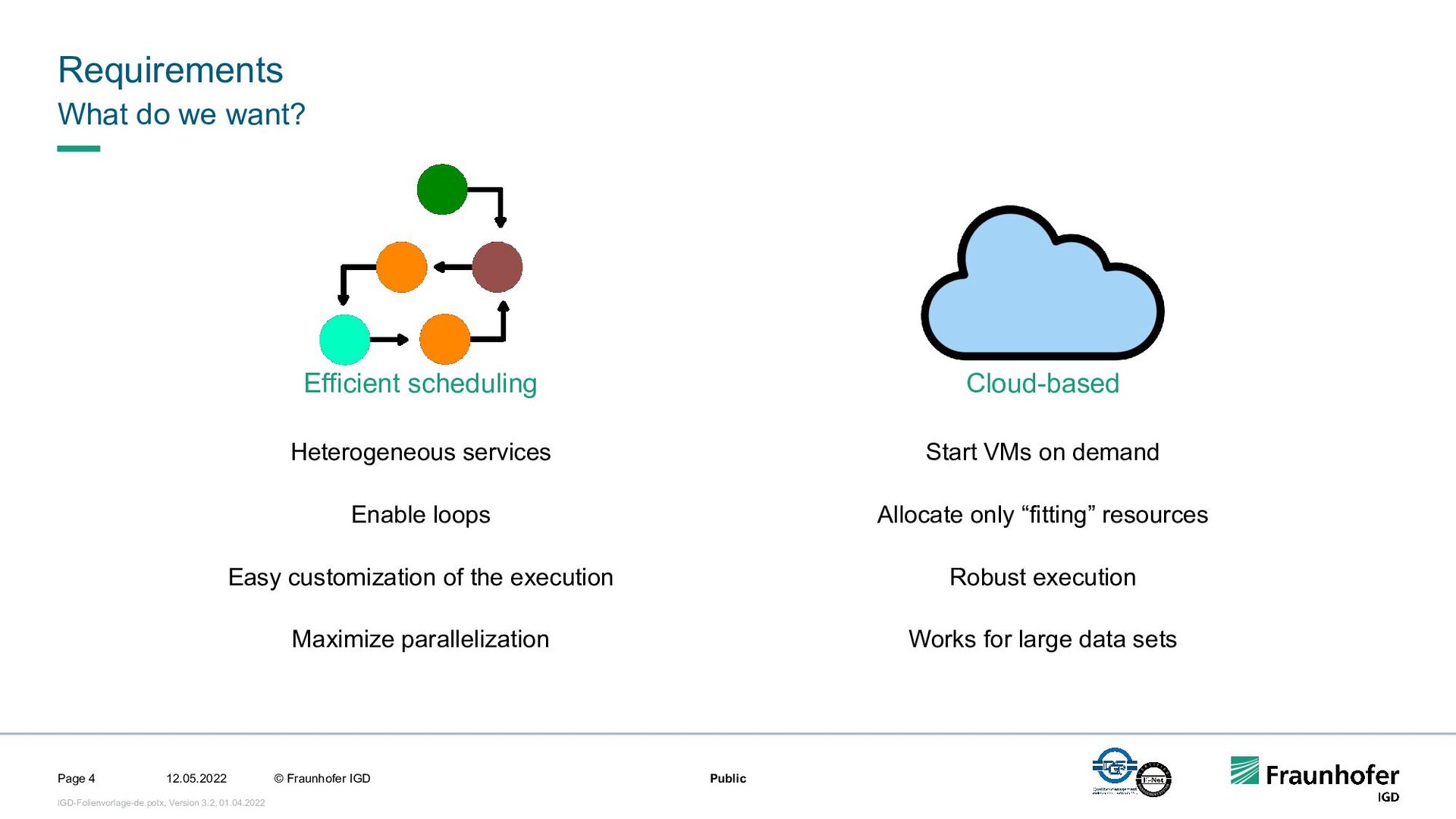
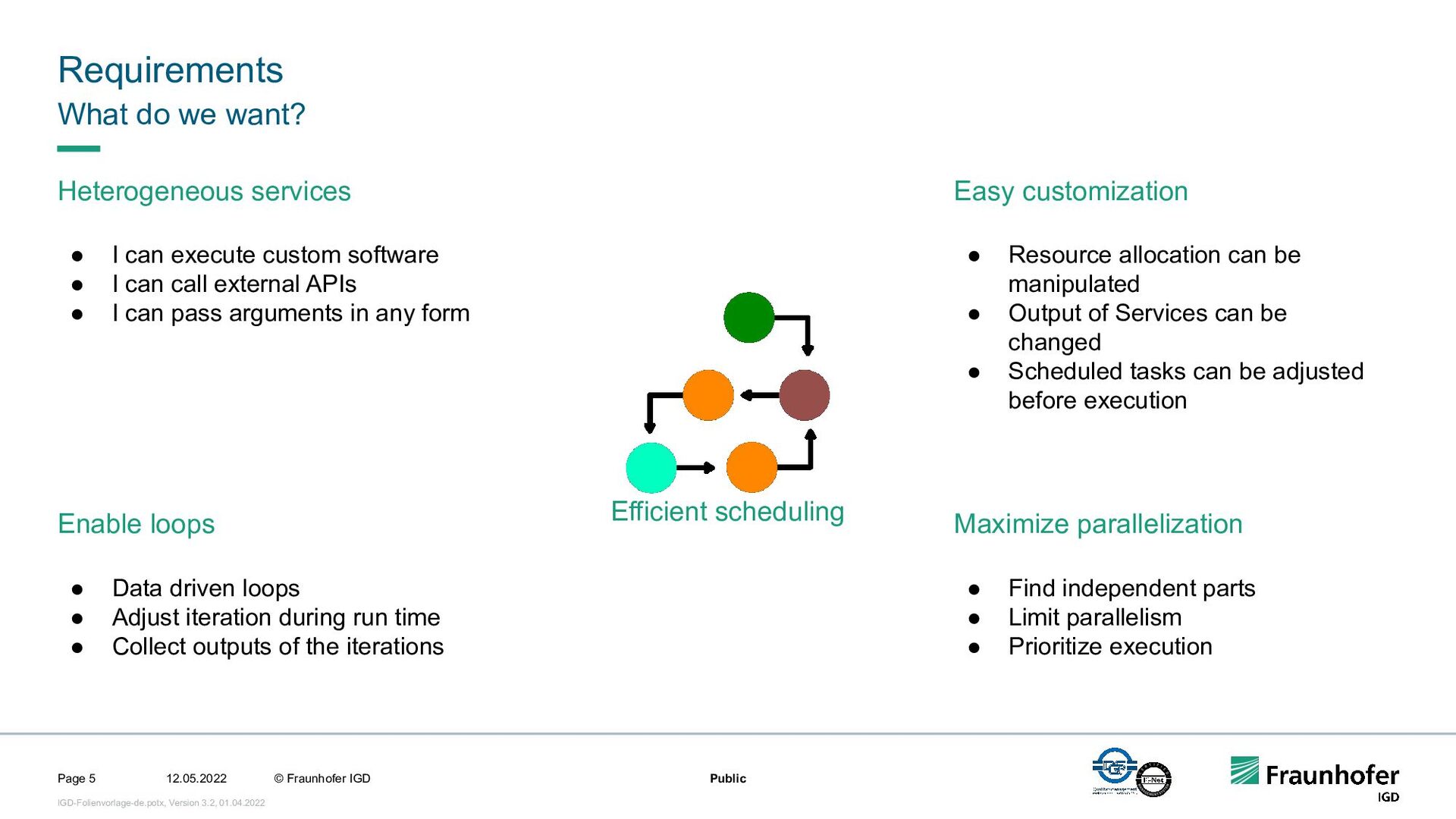
Scientific workflows are often used. However, depending on the specific use case, there are different requirements for the underlying system. For example, end users may want to monitor the execution in a user interface and intervene in the running process if necessary. On the other hand, there are many processes in the field of Big Data where a high level of automation is desired. The workflow management system should execute a workflow as efficiently as possible in the cloud and be able to react on its own. This requires a sufficiently powerful language for the workflows and flexible scheduling of the individual tasks.
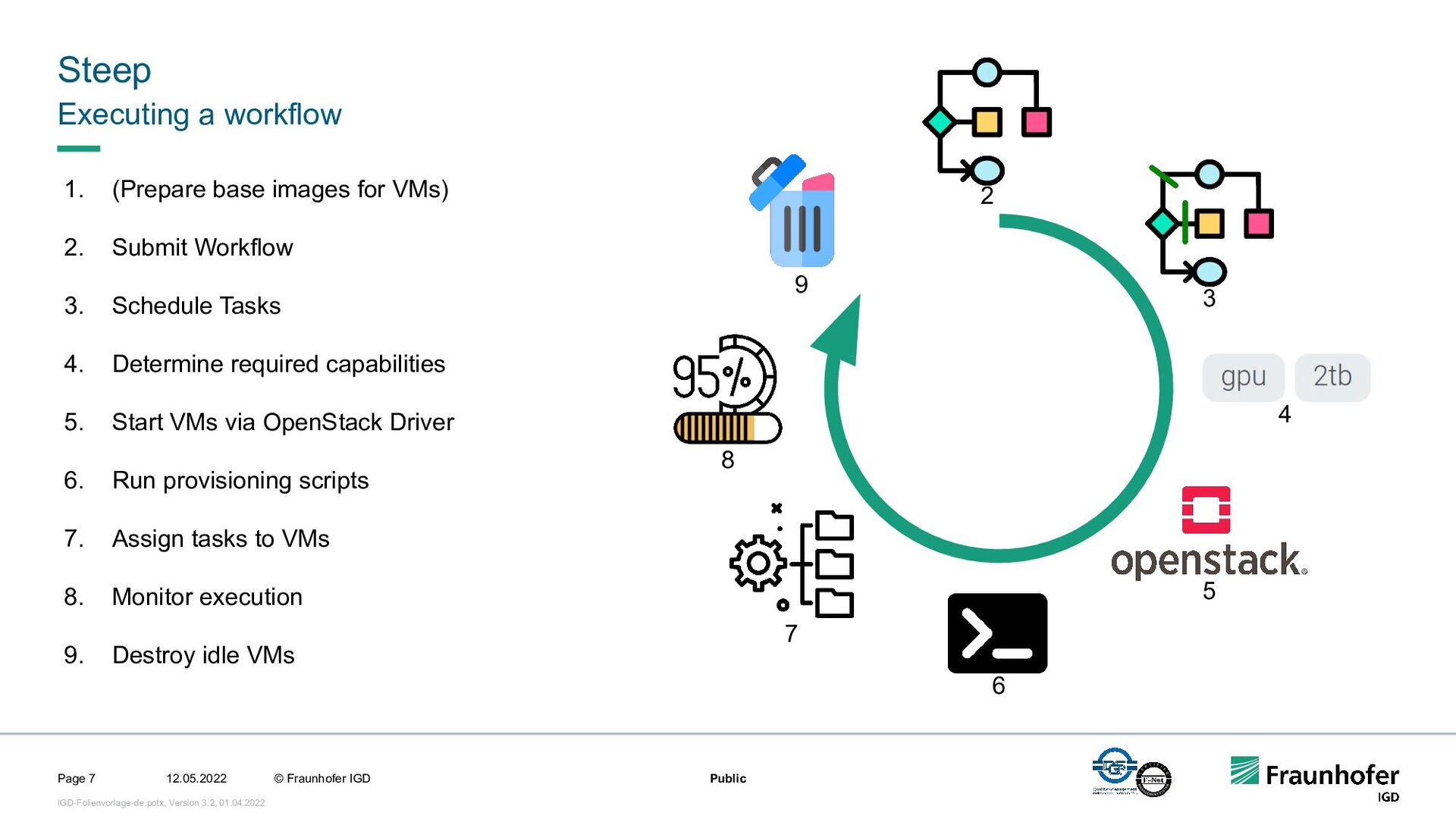
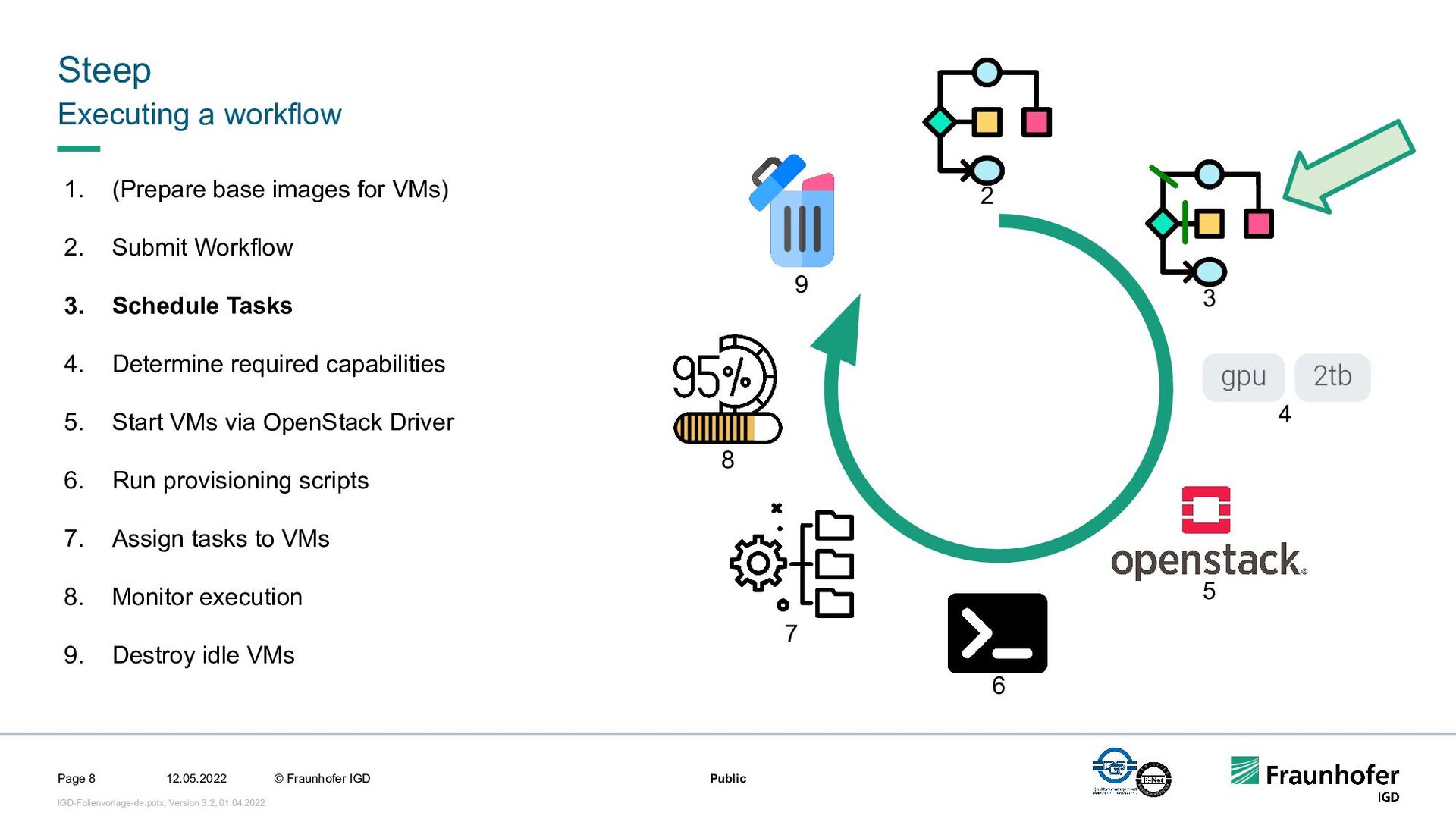
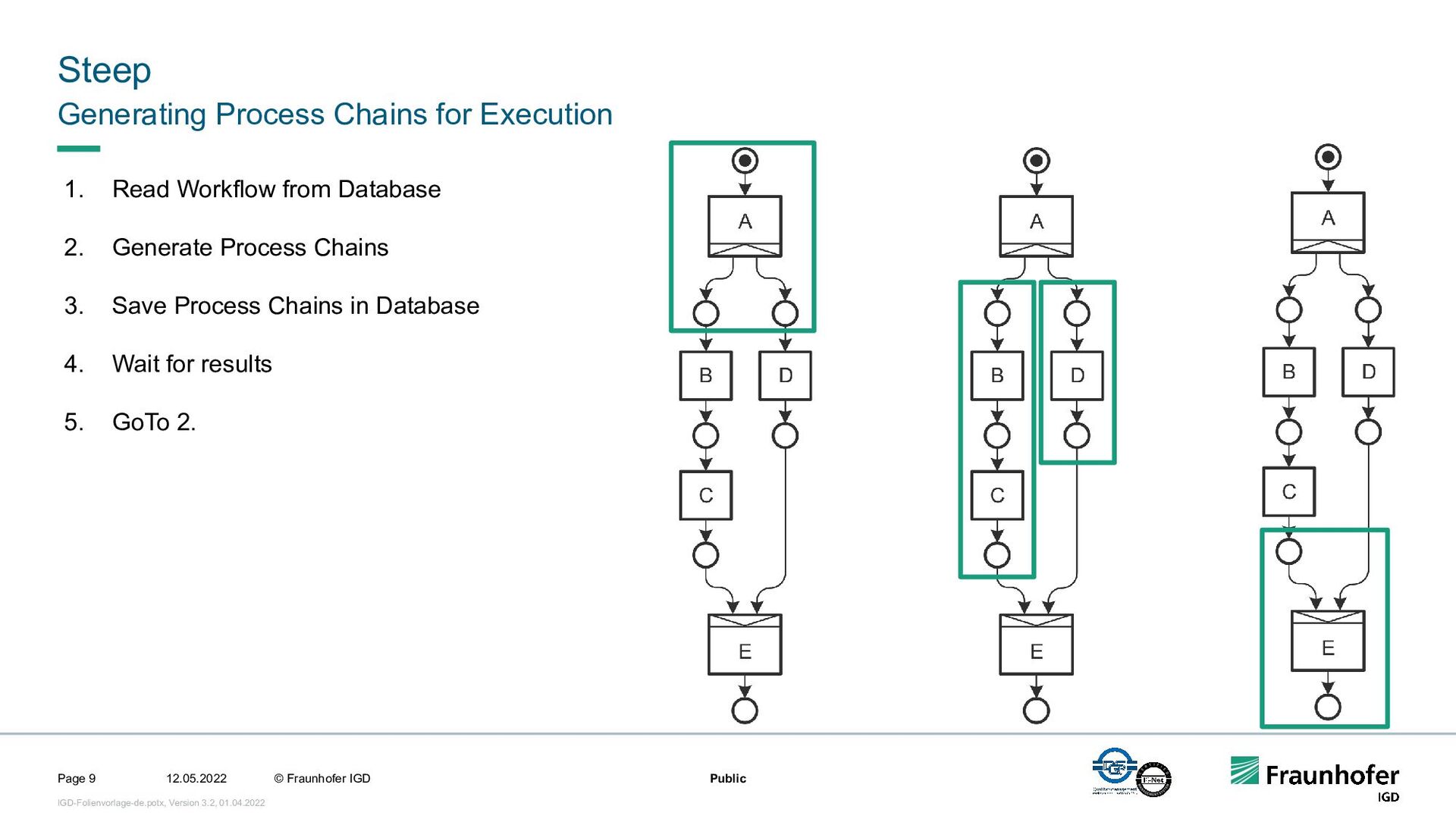
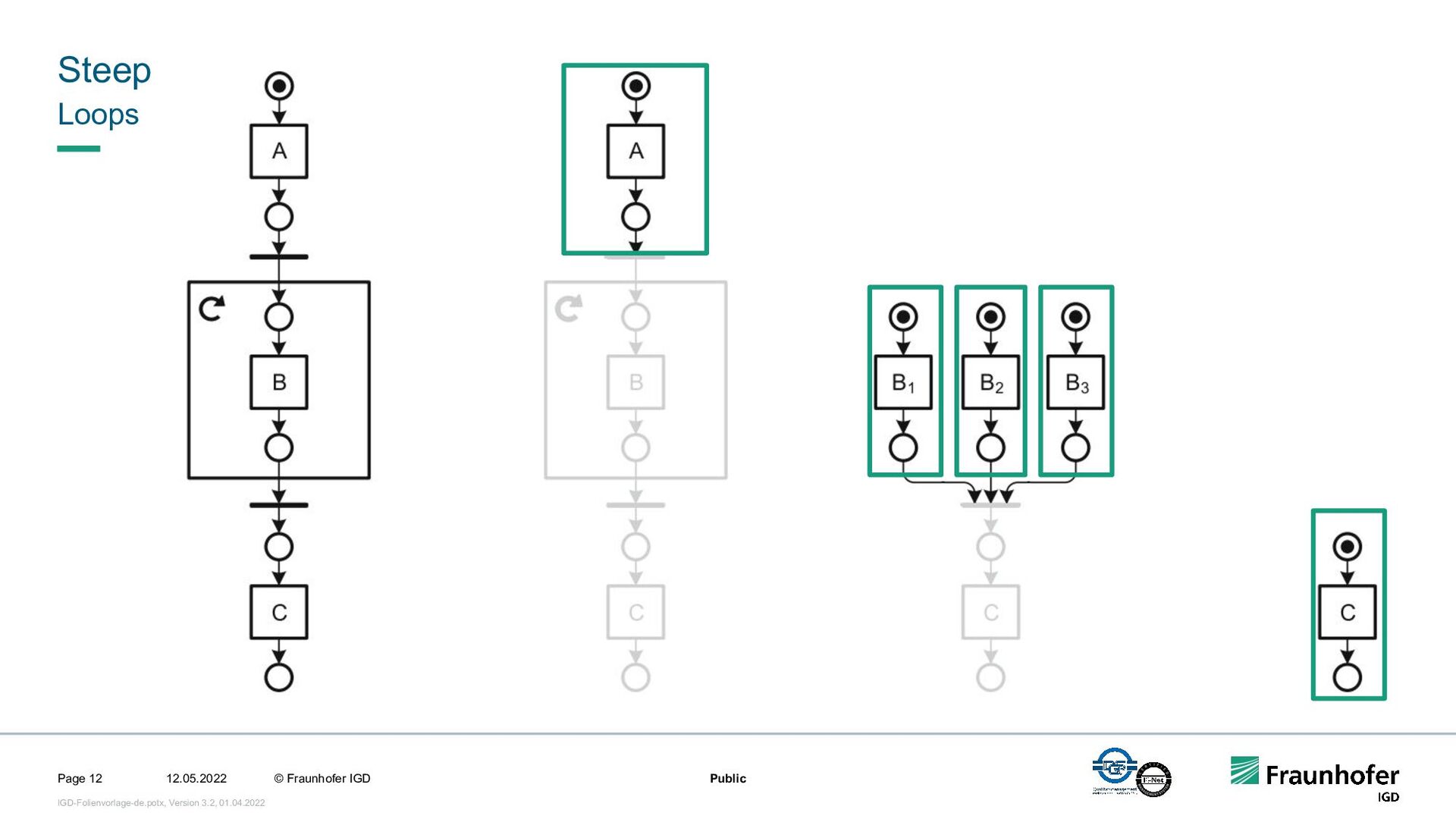
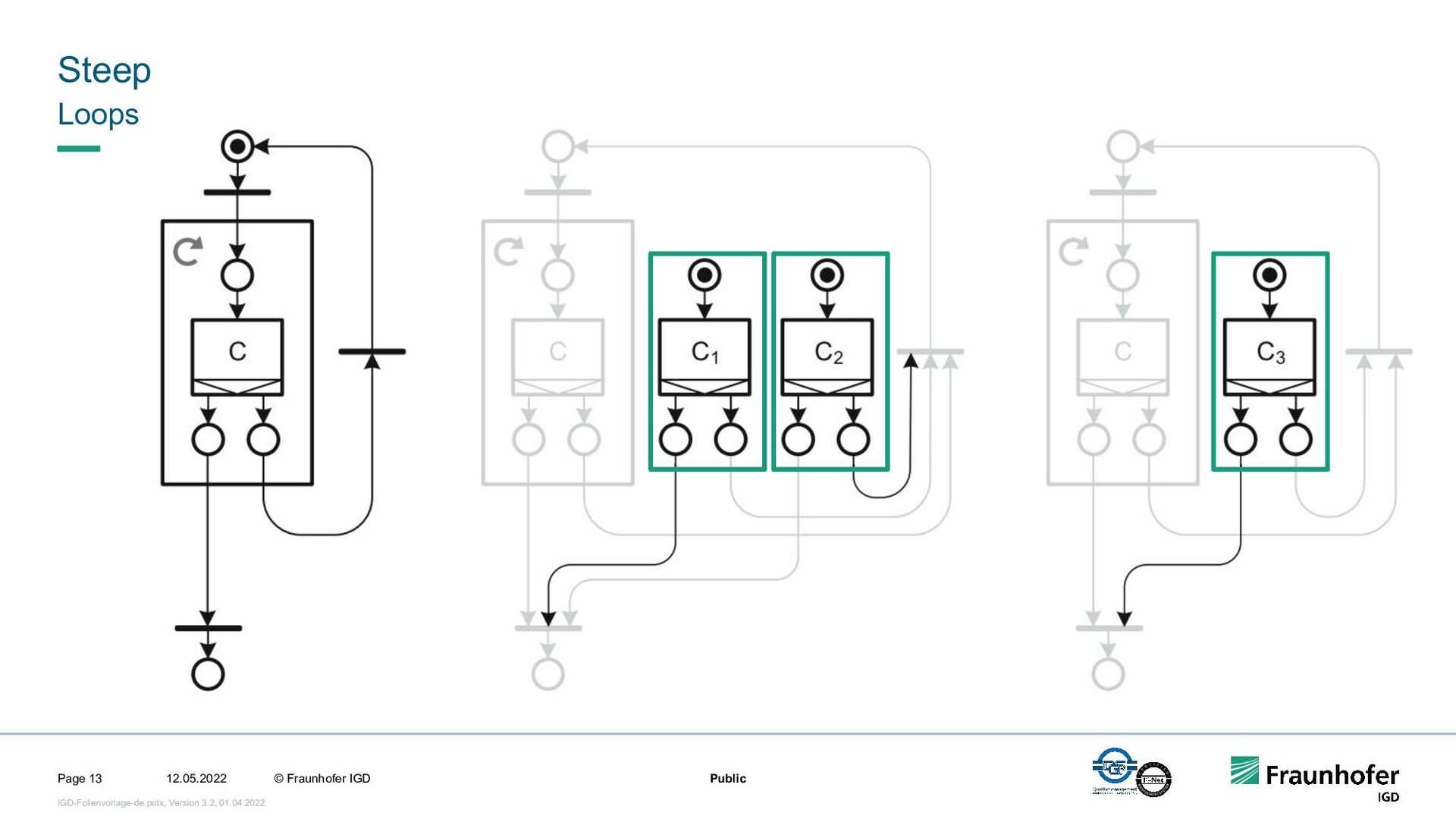
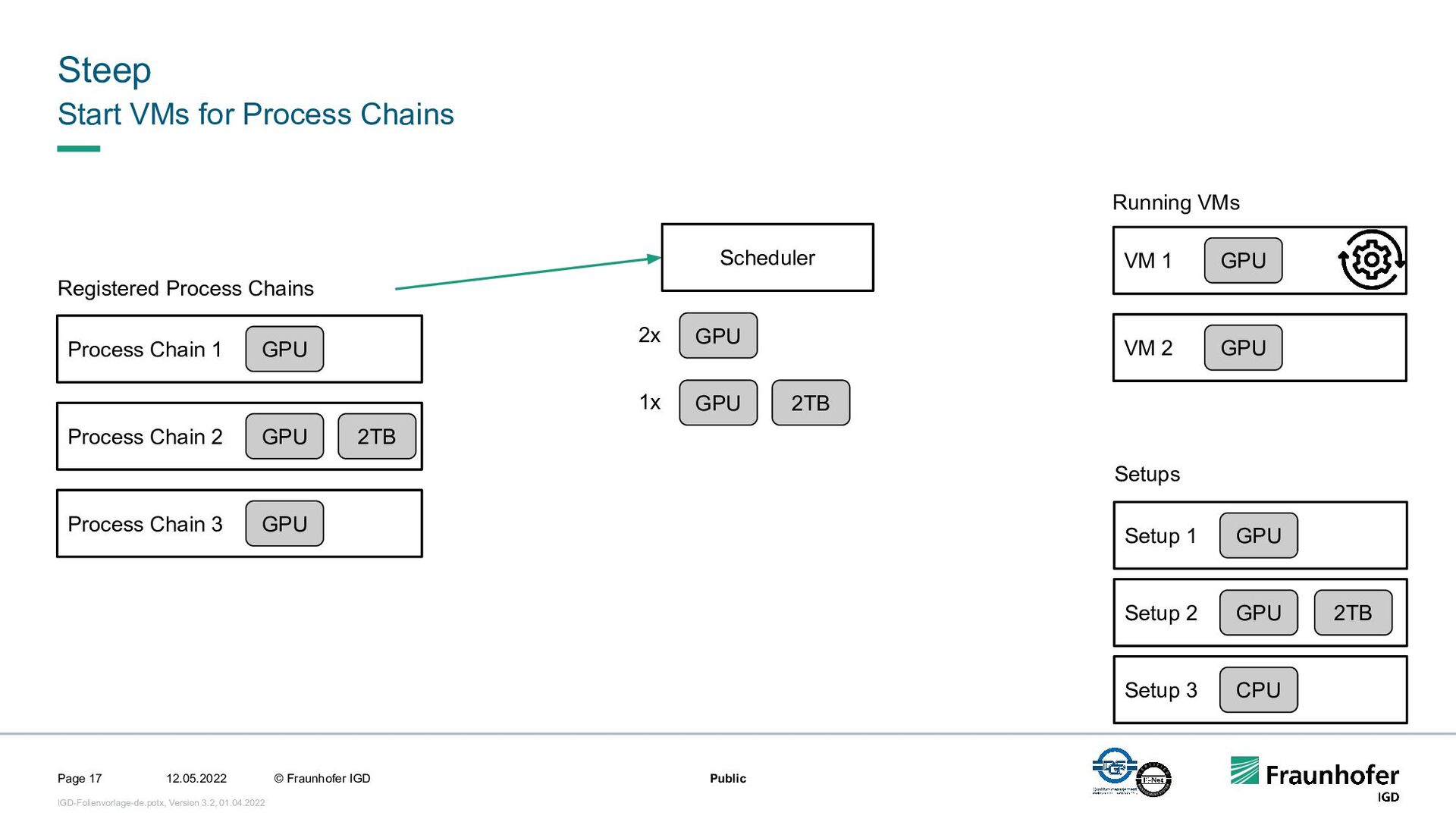
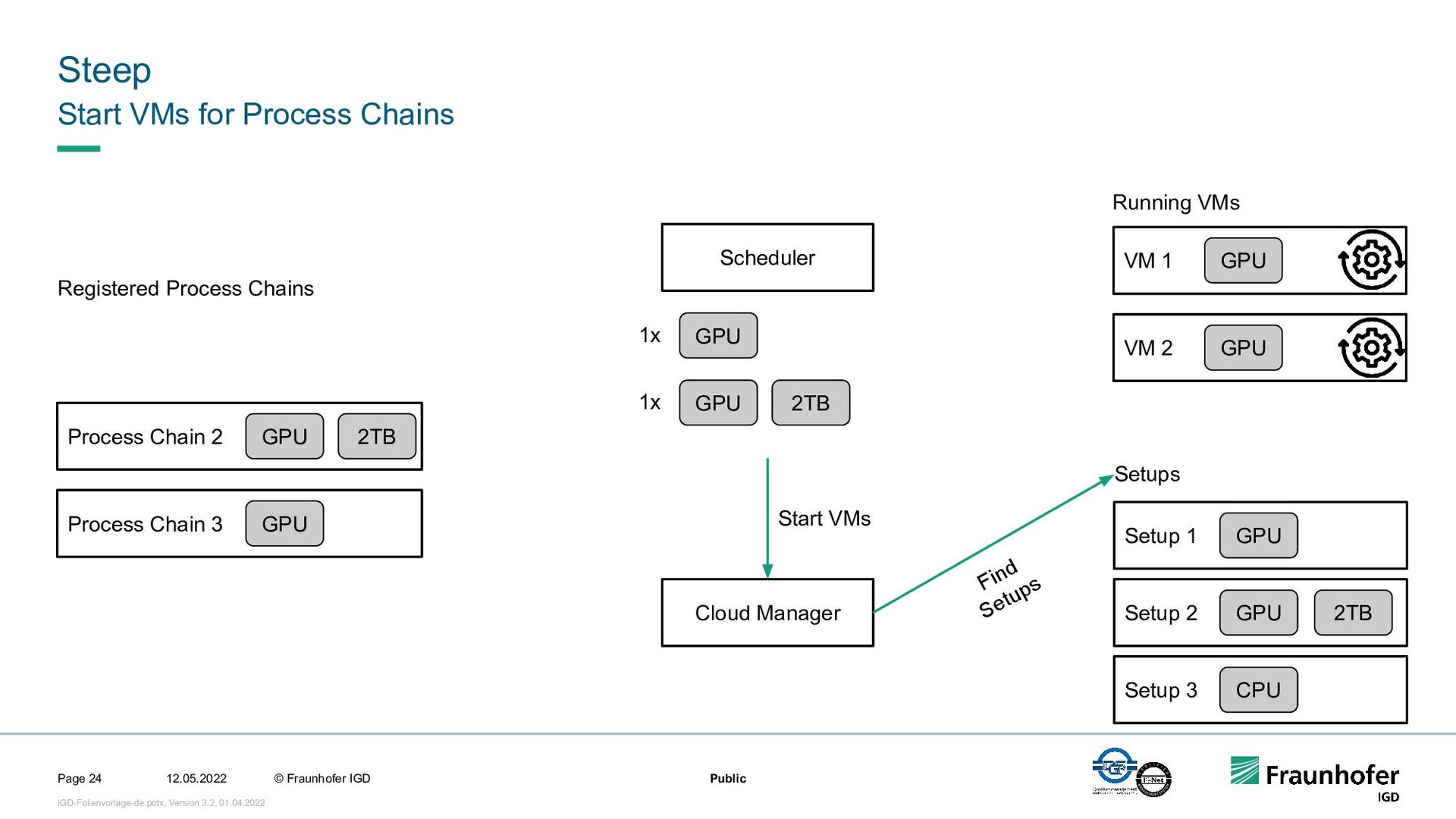
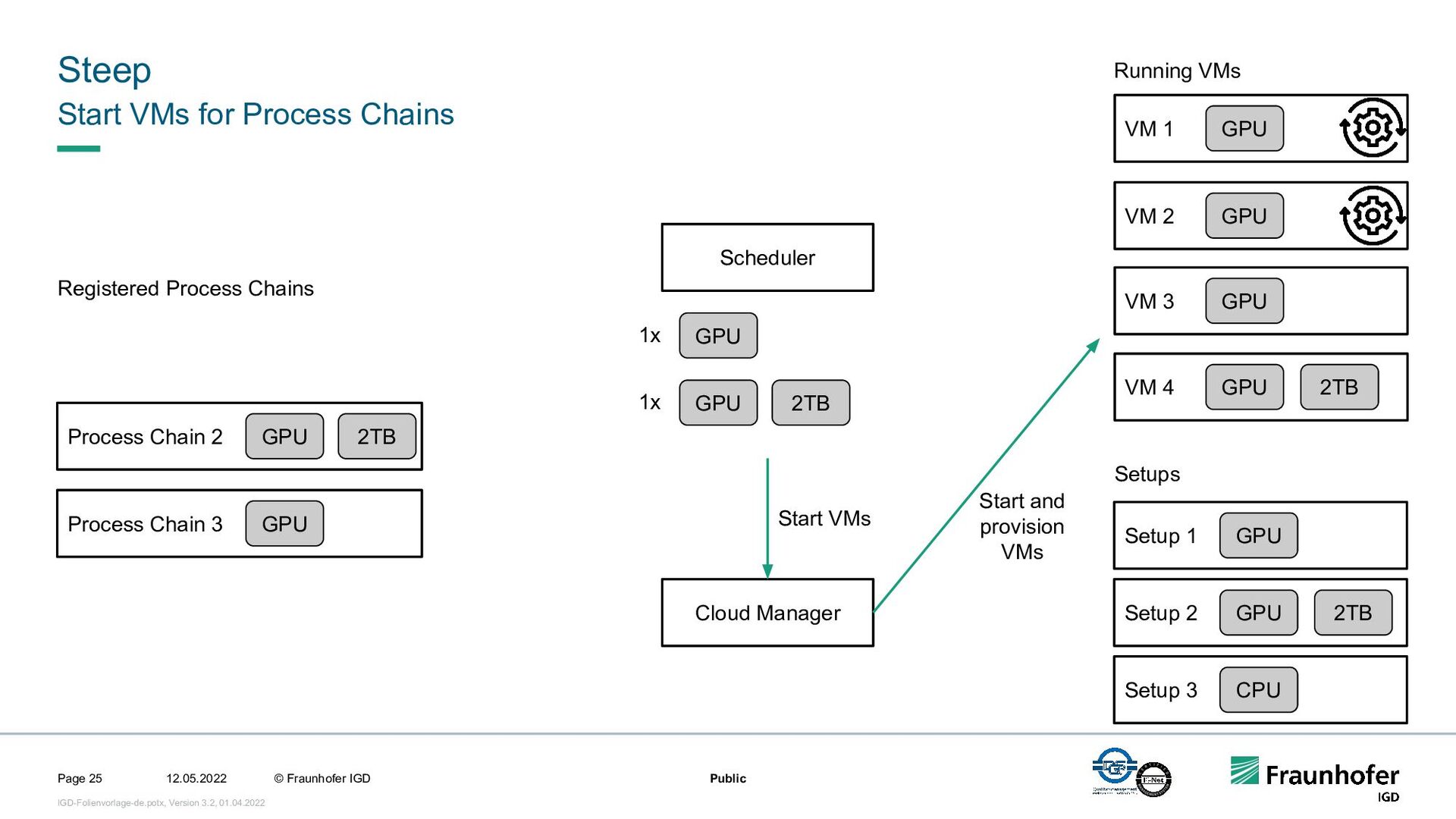
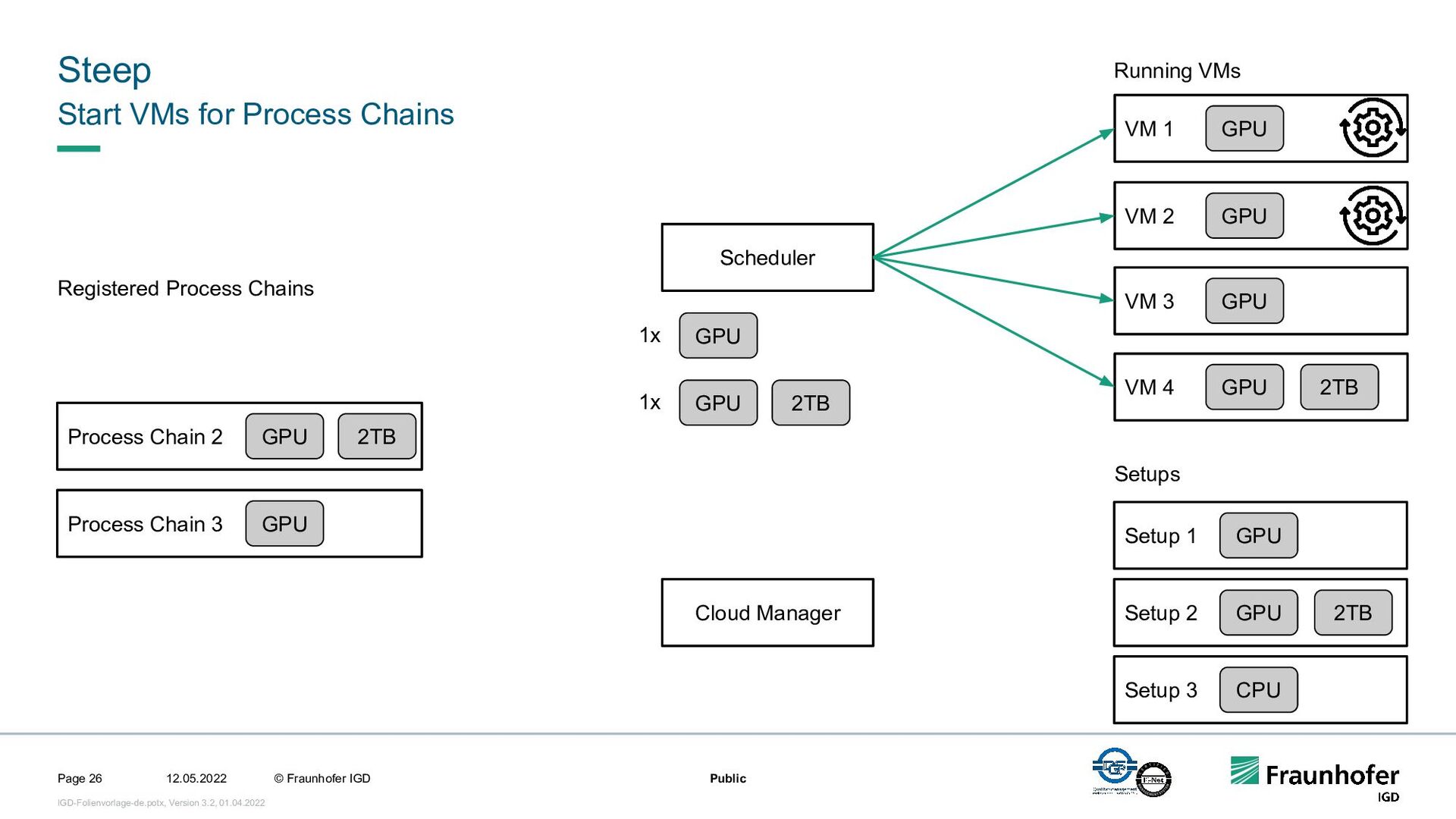
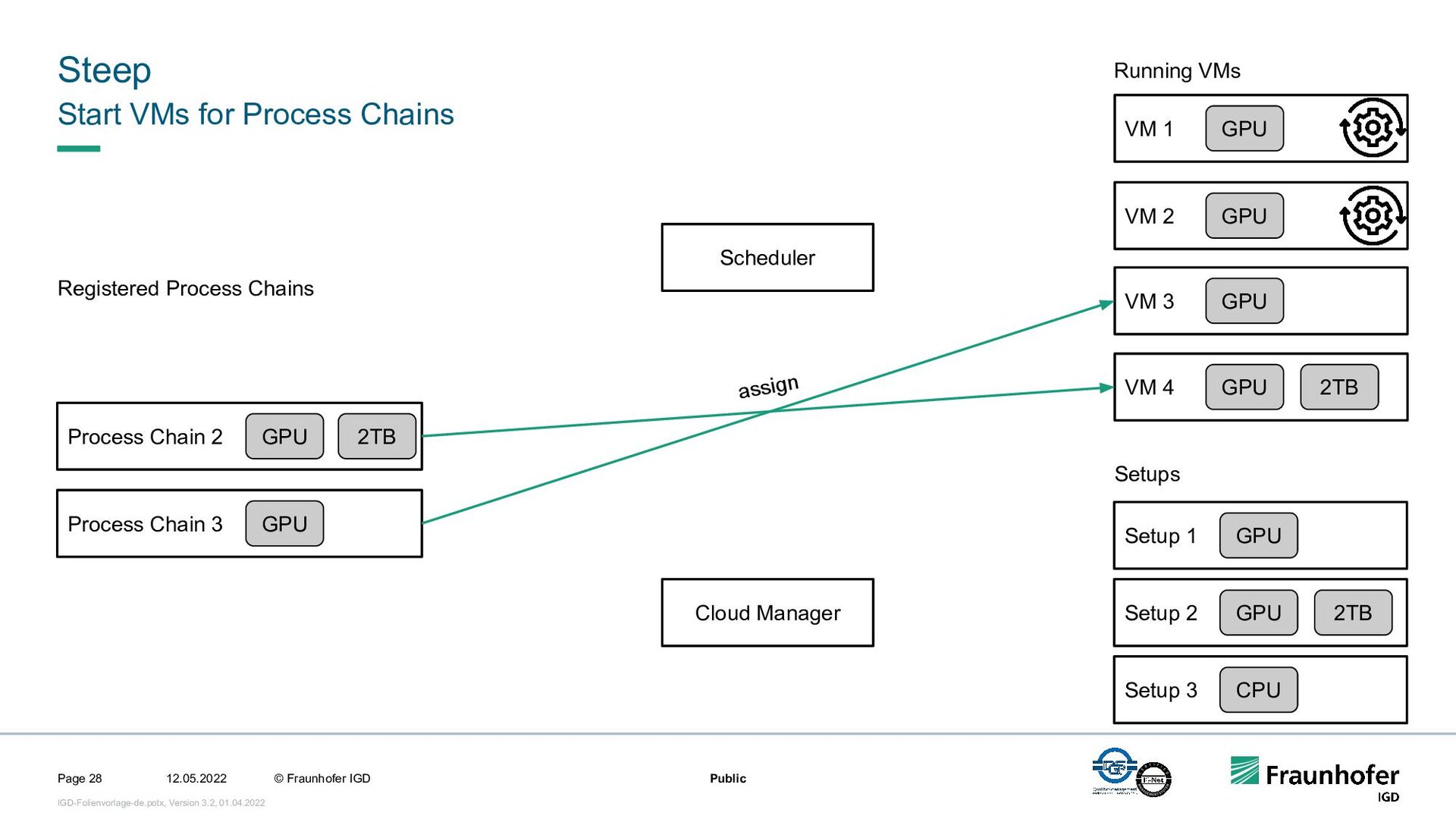
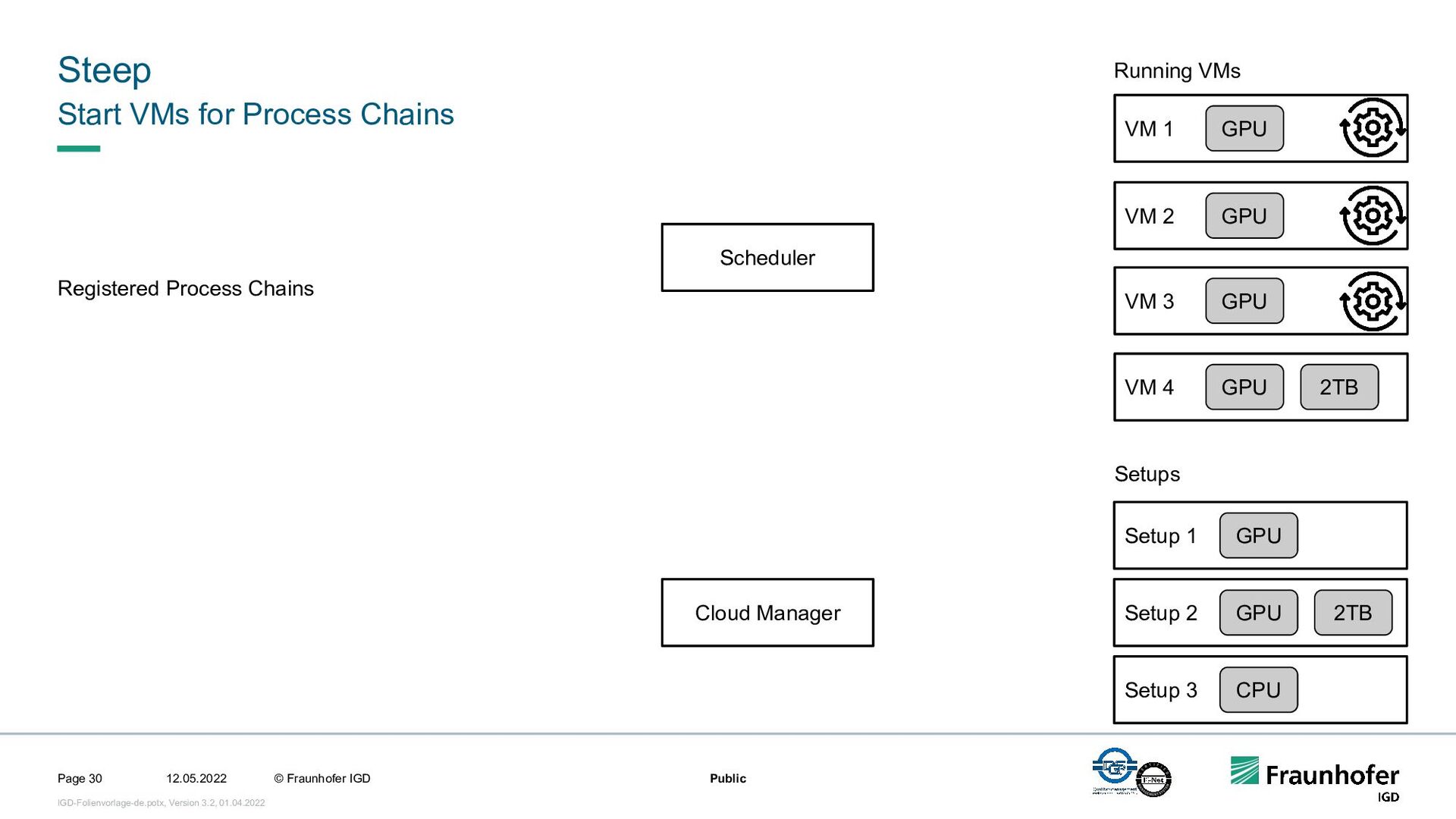
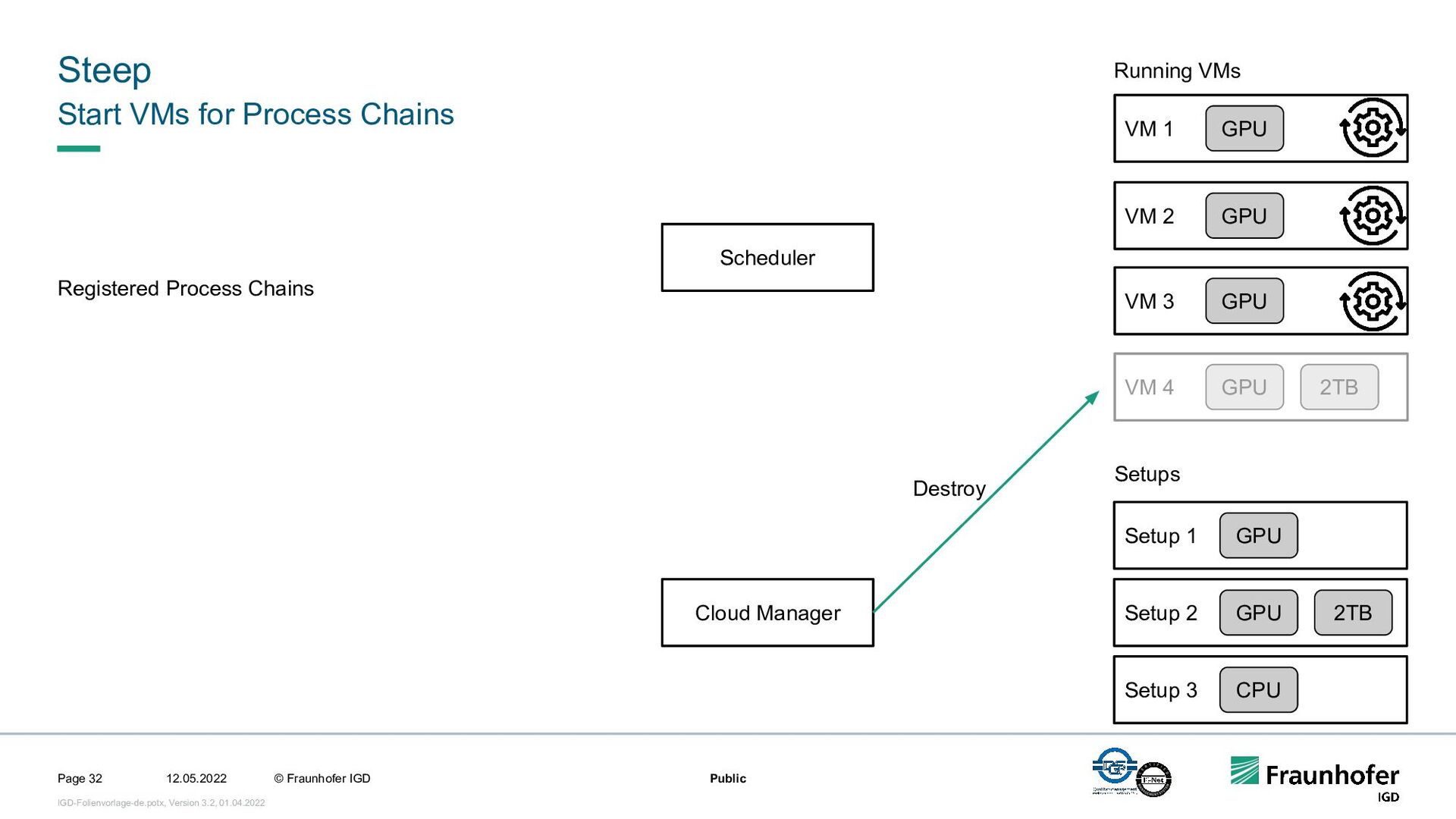
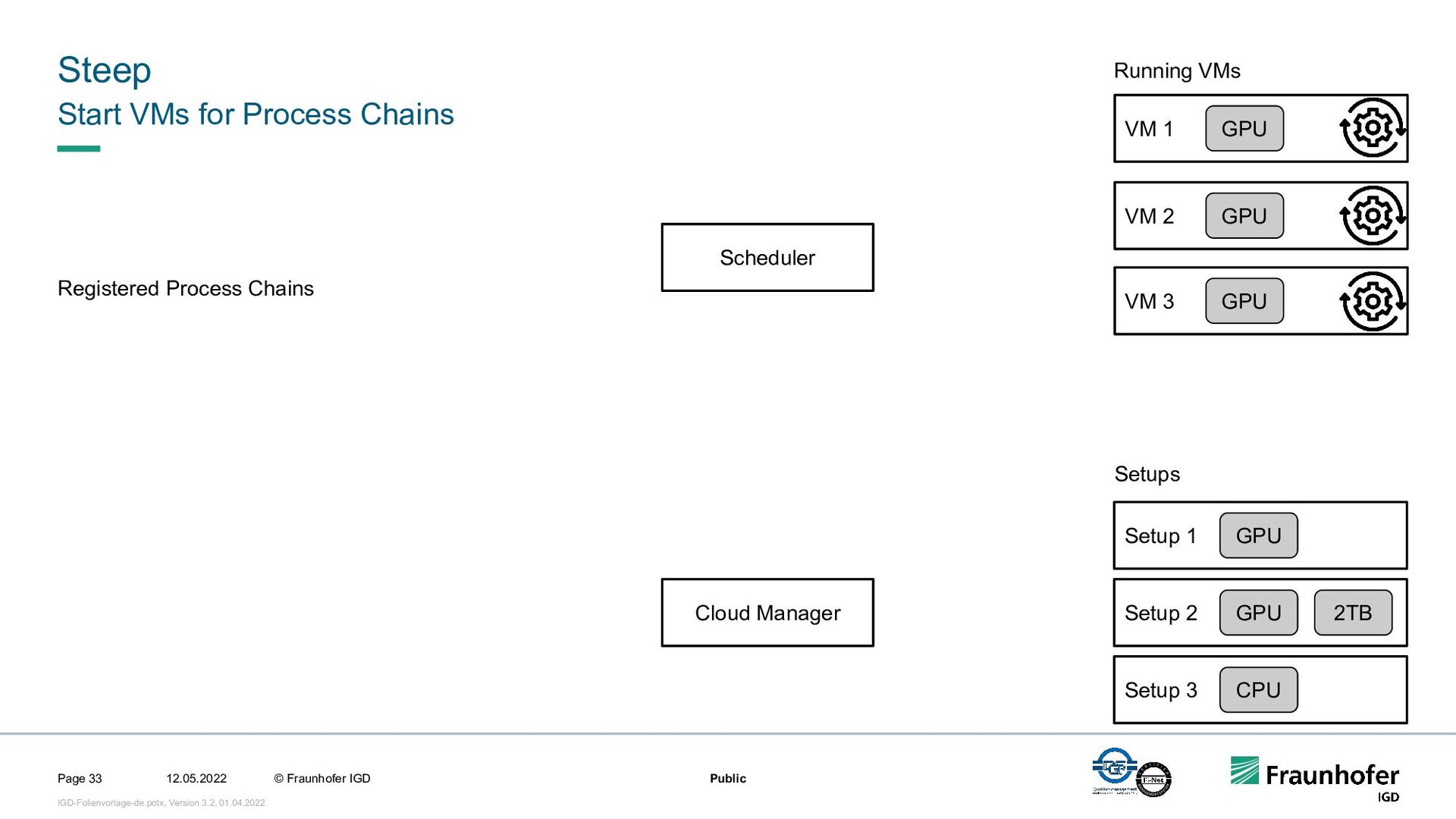
In this talk, we focus on the second case. We will show how we implemented efficient and automated execution of workflows in the cloud using the workflow management system Steep. We will start with the challenges of cloud-based execution. For a given workflow, appropriate hardware must be allocated, and in case of network problems, the system must continue to ensure robust execution. Afterwards we present our scheduling system. It decomposes the workflow into several parts and tries to achieve the highest possible parallelization. If a workflow contains loops, their iteration count will be determined at runtime. This enables workflows like iterative optimization up to a certain threshold or generic workflows for different data sets.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact — Hendrik M. Würz GEO Department [email protected] Fraunhofer IGD](https://files.speakerdeck.com/presentations/229b96ba5a954a2d8ea16145e3b3b729/slide_35.jpg){kind=link}
{kind=link}