Dask - Pythonic way of parallelizing scientific computation
Dask provides pythonic implementation for doing scalable and parallel scientific computation. It also facilitates orchestrating of jobs and parallel execution for them.
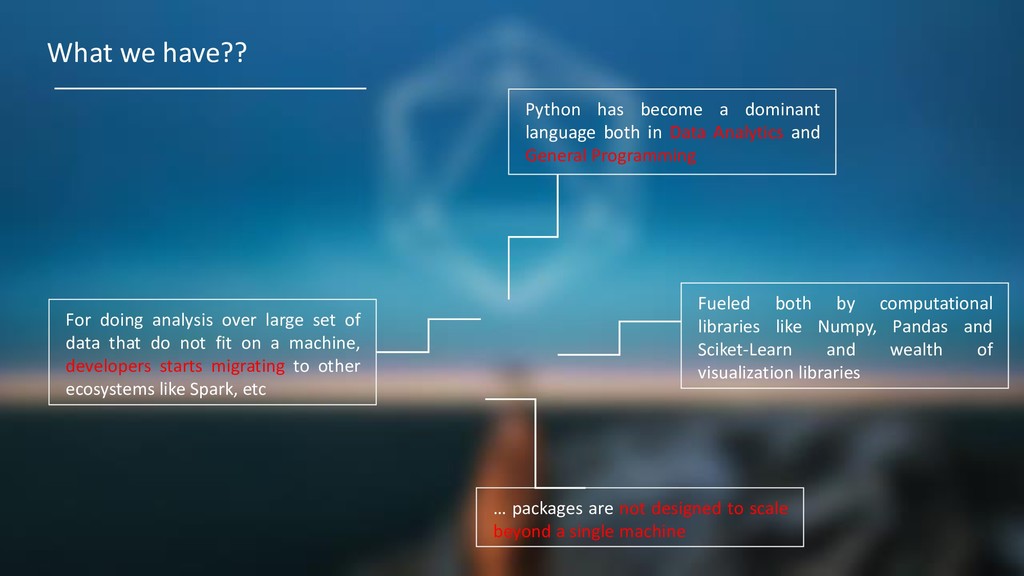
in Data Analytics and General Programming Fueled both by computational libraries like Numpy, Pandas and Sciket-Learn and wealth of visualization libraries … packages are not designed to scale beyond a single machine For doing analysis over large set of data that do not fit on a machine, developers starts migrating to other ecosystems like Spark, etc
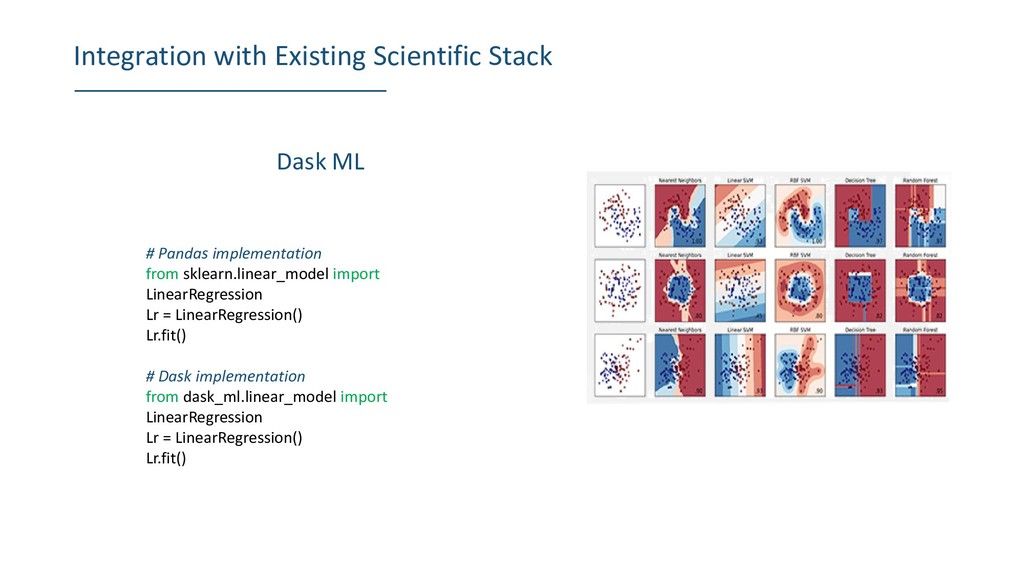
from sklearn.linear_model import LinearRegression Lr = LinearRegression() Lr.fit() # Dask implementation from dask_ml.linear_model import LinearRegression Lr = LinearRegression() Lr.fit()
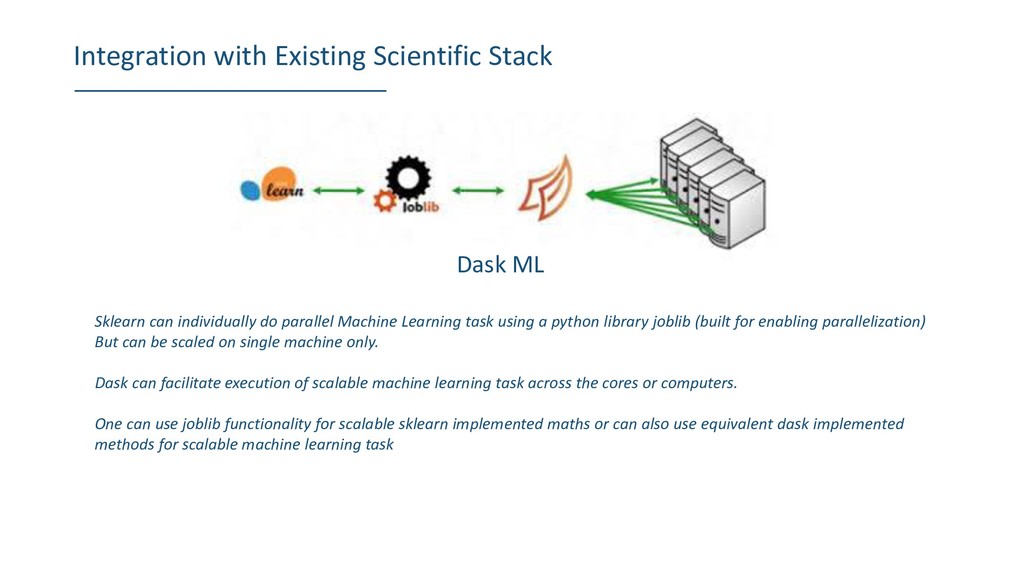
do parallel Machine Learning task using a python library joblib (built for enabling parallelization) But can be scaled on single machine only. Dask can facilitate execution of scalable machine learning task across the cores or computers. One can use joblib functionality for scalable sklearn implemented maths or can also use equivalent dask implemented methods for scalable machine learning task
laptop Dask runs on thousand-machine clusters to process hundreds of terabytes of data efficiently Can be Deployed in-house, on cloud or on HPC super-computer Supports authentication and encryption using TLS/SSL certificates Resilient, can handle failure of work nodes gracefully Can take advantage of new-node added-on-fly
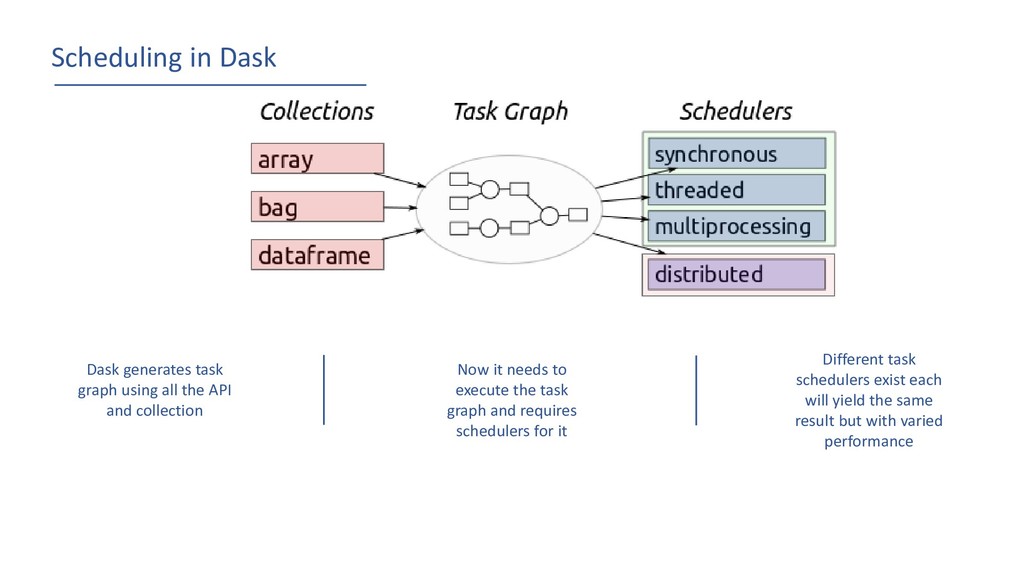
API and collection Now it needs to execute the task graph and requires schedulers for it Different task schedulers exist each will yield the same result but with varied performance
Single machine scheduler: This scheduler provides basic features on a local process or thread pool. This scheduler was made first and is the default. It is simple and cheap to use. It can only be used on a single machine and does not scale. Low Overhead : ~100us / task Concise : 1000 LOC Distributed scheduler: This scheduler is more sophisticated, offers more features, but also requires a bit more effort to set up. It can run locally or distributed across a cluster. Less Concise : 5000 LOC HDFS Aware Data Local : Move Computation to correct worker
market?? Map Pros : Easy to install Lightweight Cons : Data Interchange cost Not able to handle complex computations Big Data Collection Pros : Large set of operation Scales nicely on cluster Cons : Heavyweight and JVM focused Not able to handle complex computations Task Schedulers (Luigi, Airflow) Pros : Handles Arbitrarily complex task Python Native Cons : No interworker storage and Long Latency
Python Distribution framework at PyCon 2017 • Matthew Rocklin Blog • Analytics Vidya • Talk on Scalable Machine Learning with Dask at SciPy 2018 by Augspurger & Grisel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}