a set of tokens, model the probability of a sentence by computing the probability of token tk given the history (t1, t2, t3, . . . . . . ., tk-1 ) Cost function
a set of tokens, model the probability of a sentence by computing the probability of token tk given the input (tk + 1, tk + 2, tk + 3, . . . . . . ., tN ) Cost function
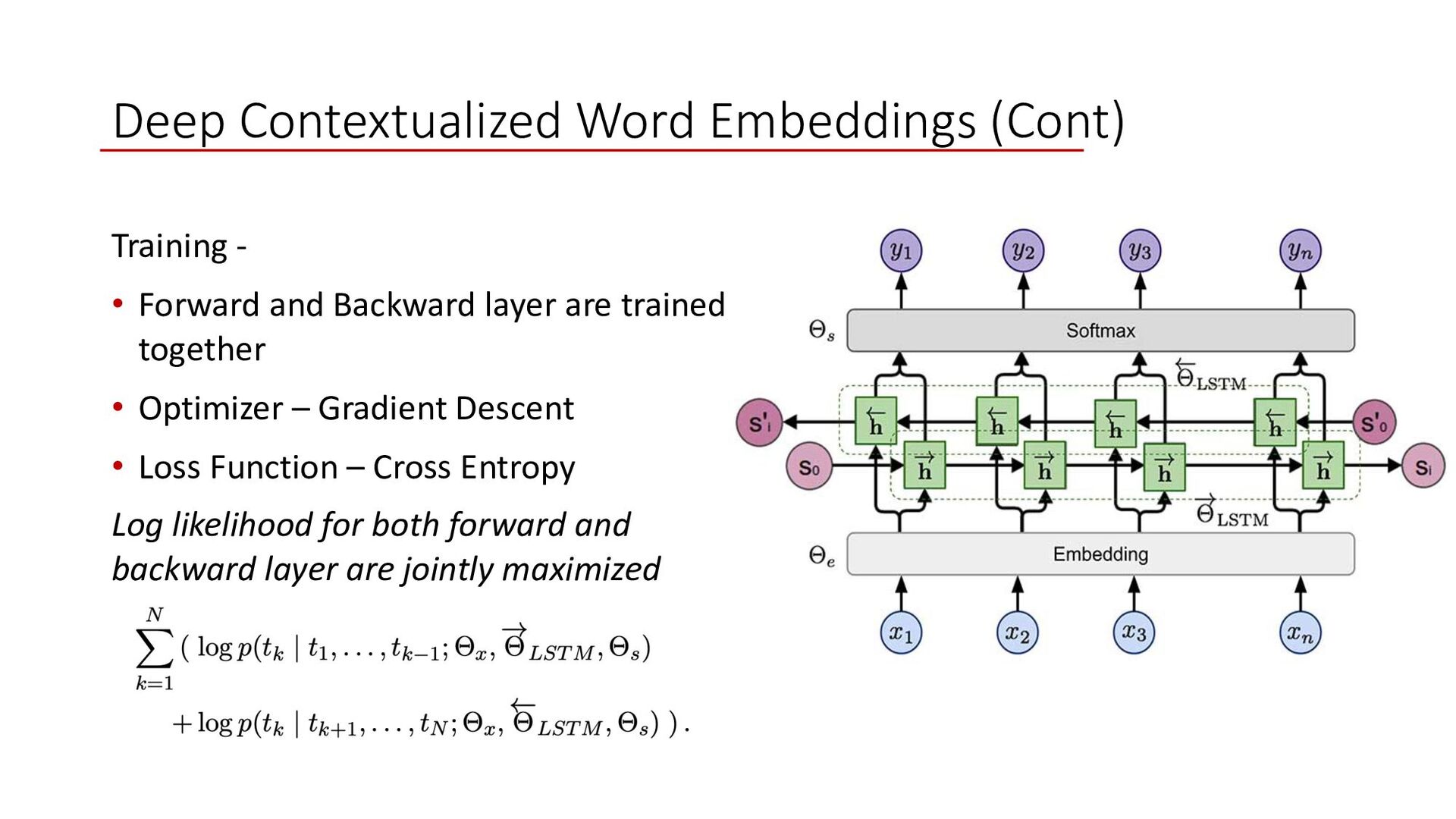
Backward layer are trained together • Optimizer – Gradient Descent • Loss Function – Cross Entropy Log likelihood for both forward and backward layer are jointly maximized
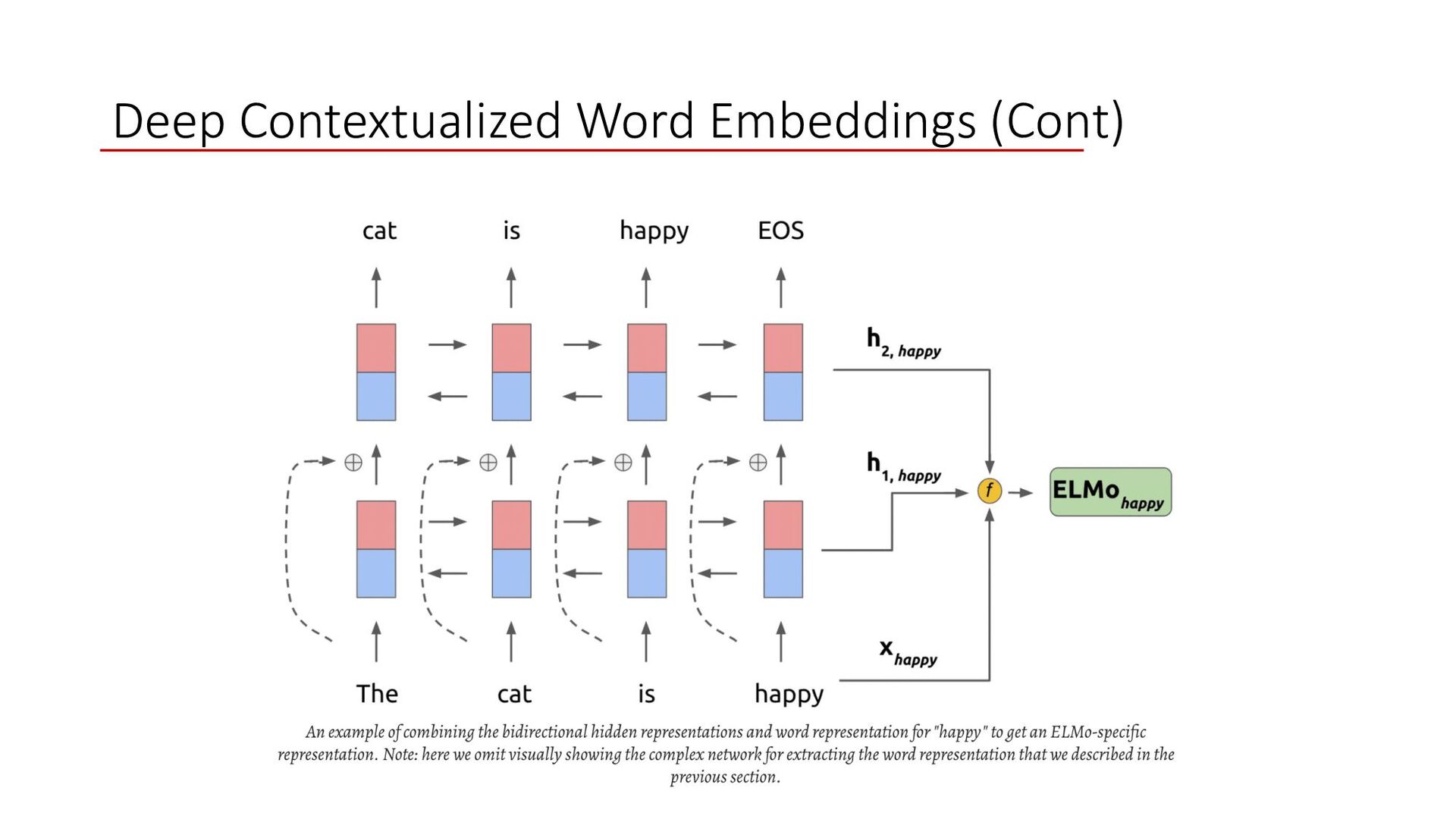
lower - level representation in some weighted fashion • Results in Deep context - rich embeddings • What if we can combine the representation with respect to task? How about creating task specific deep contextual embeddings?
- level neurons capture local properties such as morphological structuring, syntax related aspects. Can be useful to deal with dependency parsing, POS tagging, etc. • High – level neurons capture context dependent aspects. Can be used on tasks such as word sense disambiguation, etc What if we expose both and combine both to represent a deep contextual representation of words?
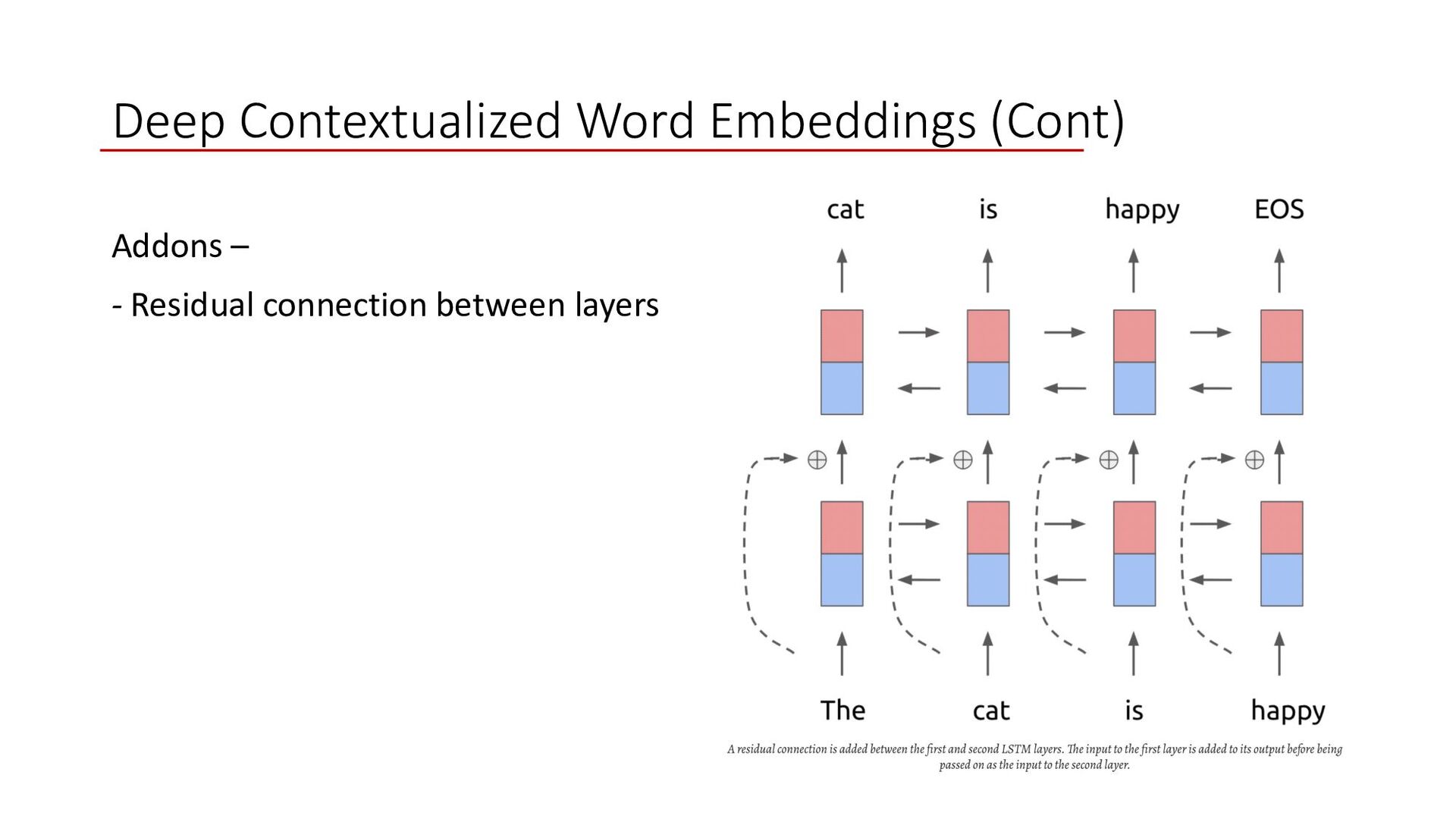
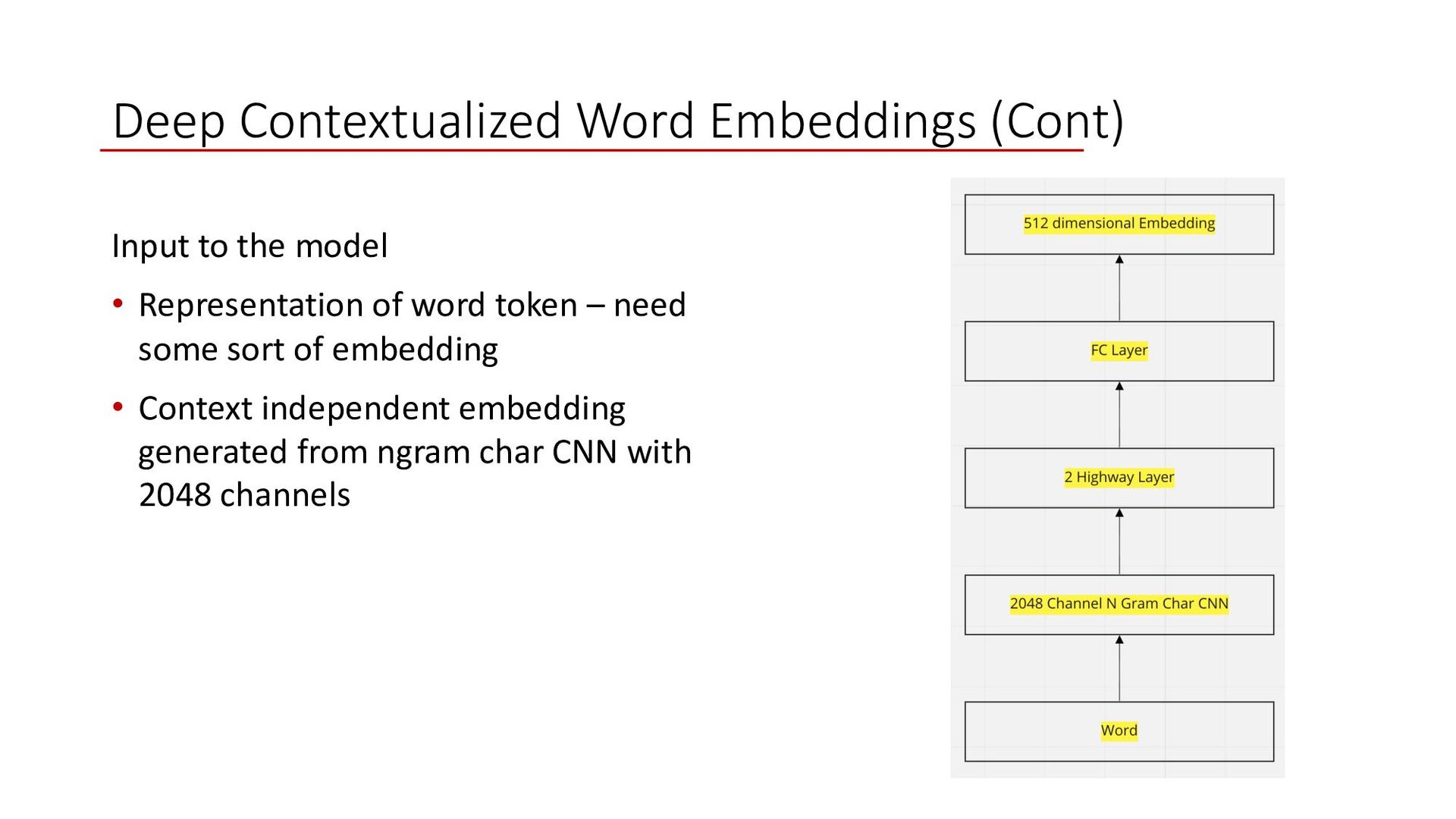
projection ØResidual connection between the first and second layer ØTask independent word representation with 2048 n gram char CNN model ØTie weight for forward and backward layer together, jointly maximize the log likelihood ØWeighted representation from all layers followed by a scaler
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}