社内の論文読み会にて発表した論文です。
元論文はこちらです。
https://aclanthology.org/2021.acl-long.9/
Mention Flags (MF): Constraining Transformer-based Text Generators
Yufei Wang, Ian Wood, Stephen Wan, Mark Dras, Mark Johnson
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)
{kind=link}
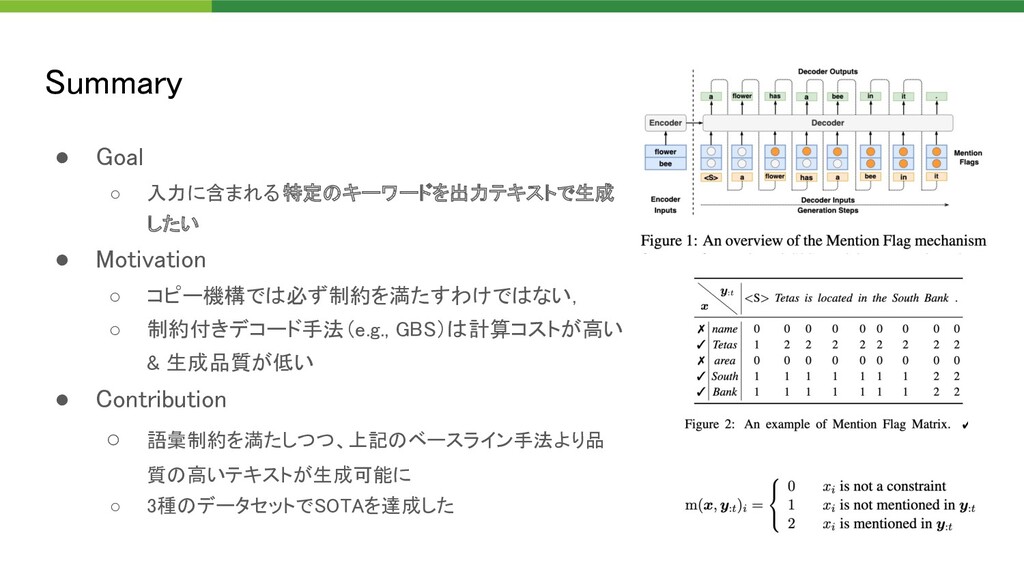{kind=link}
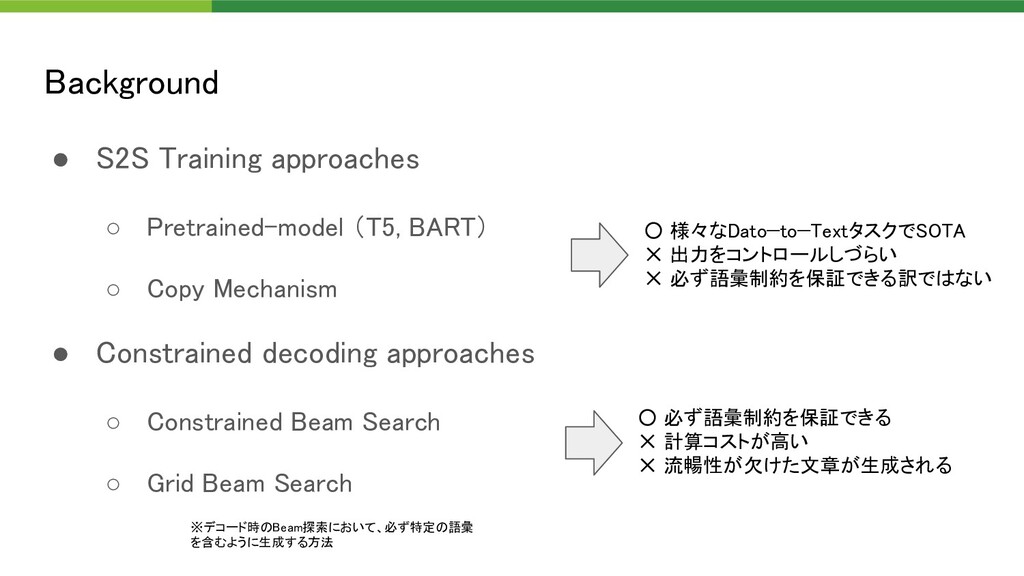{kind=link}
{kind=link}
{kind=link}
{kind=link}
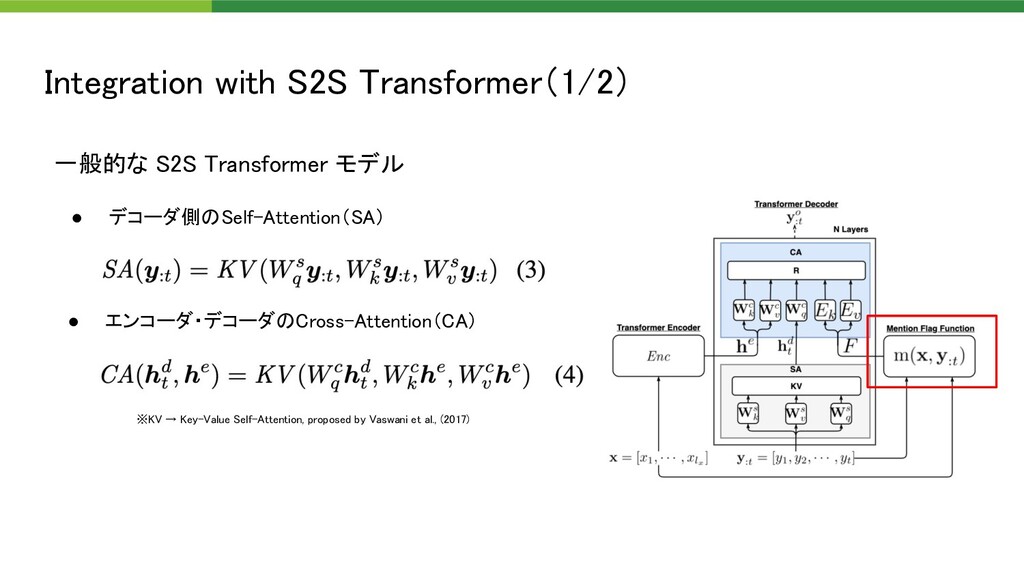{kind=link}
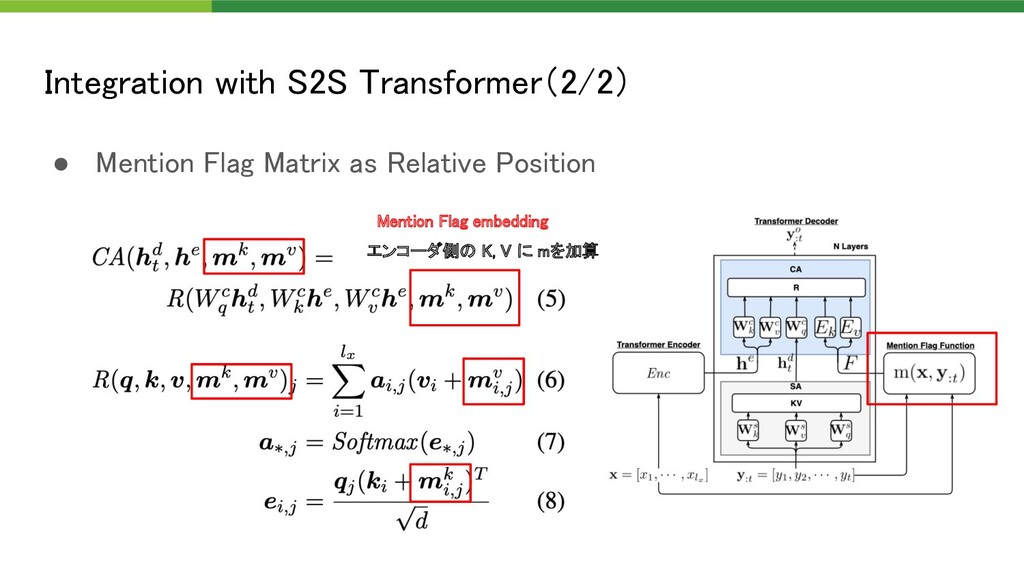{kind=link}
{kind=link}
{kind=link}
{kind=link}
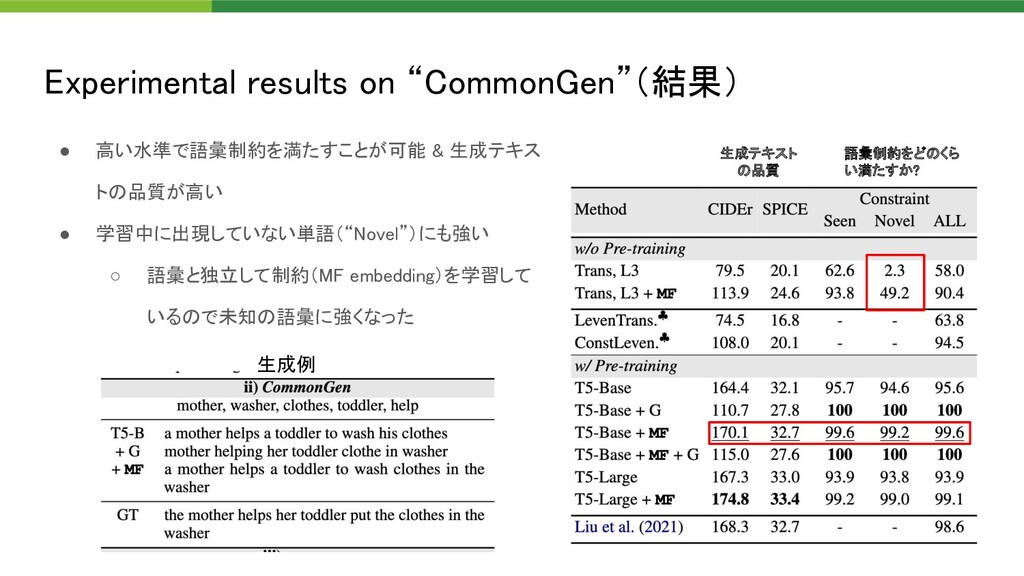{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
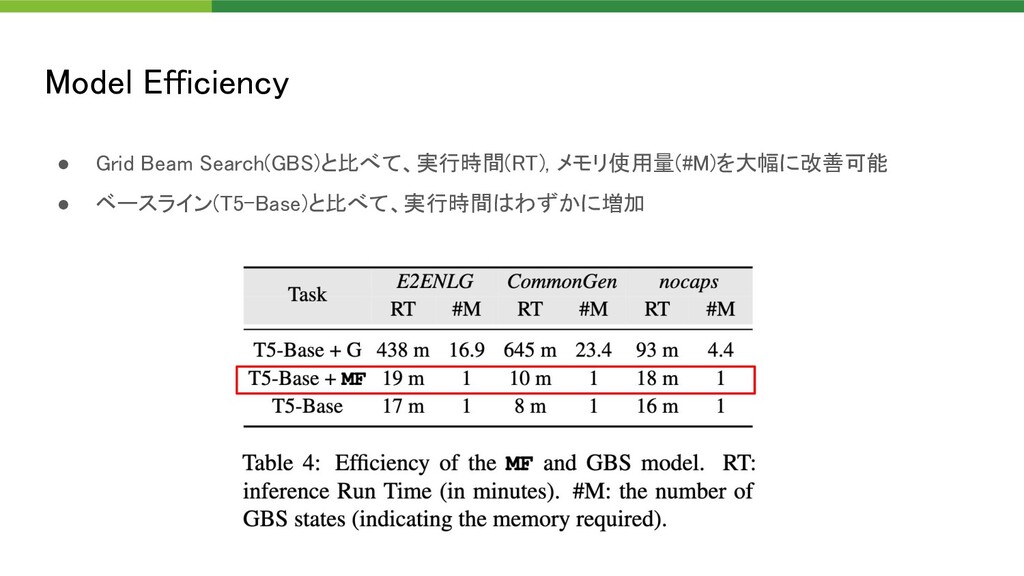{kind=link}
{kind=link}
{kind=link}
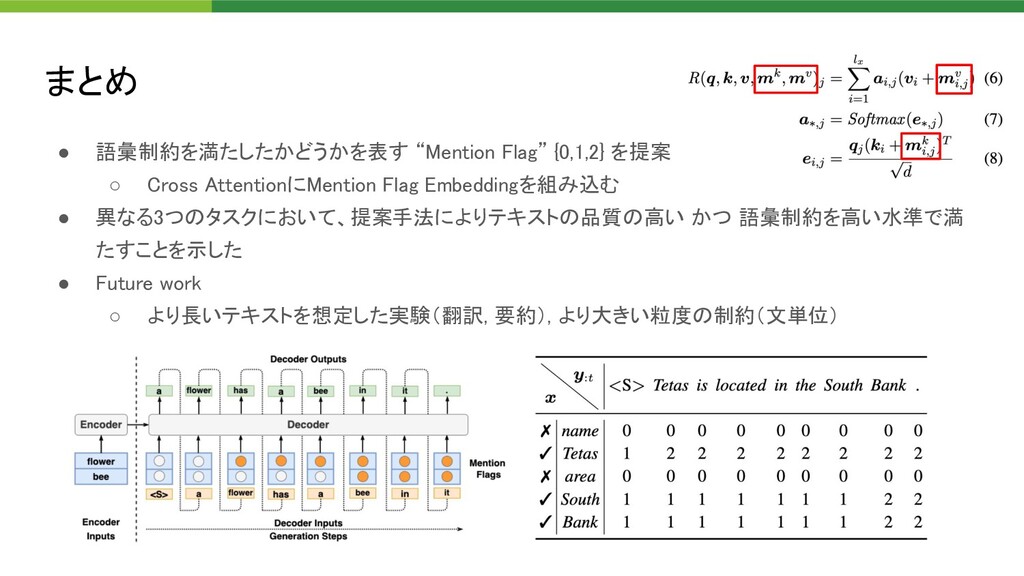{kind=link}
{kind=link}