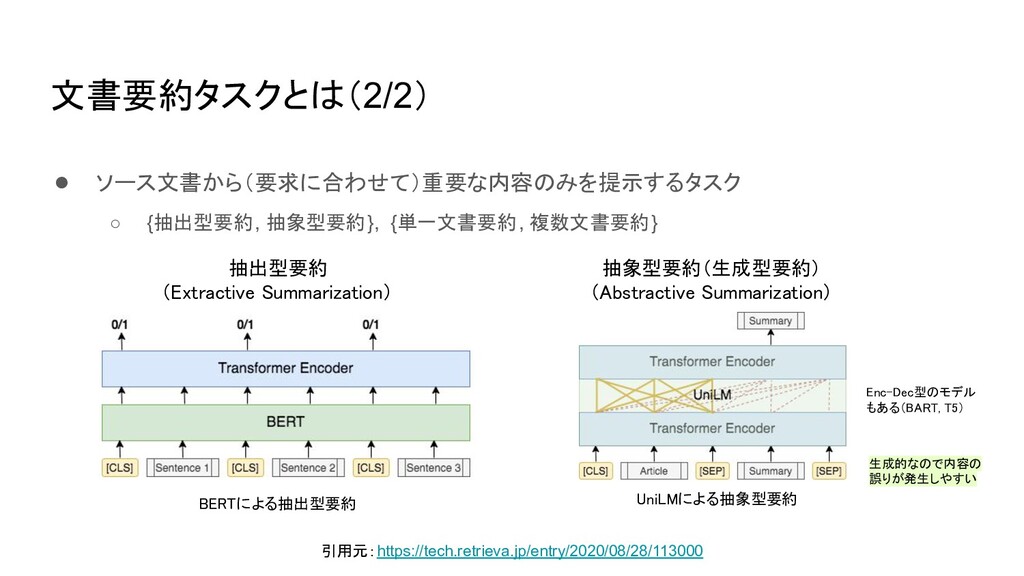
【紹介する論文】
・"Enhancing Factual Consistency of Abstractive Summarization"
・"GSum: A General Framework for Guided Neural Abstractive Summarization"
・"Annotating and Modeling Fine-grained Factuality in Summarization"
◦ GSum: A General Framework for Guided Neural Abstractive Summarization 2) 生成要約が事実と異なるかを判定するタスク (Factuality identification) ◦ Annotating and Modeling Fine-grained Factuality in Summarization
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}