Also, are you caches, search index, and all denormalizations consistent at all times? Is EVERYTHING you do is happening with user watching it? Y U NO? Tuesday, April 16, 13
data is growing • Demand in scalable services is growing • Application backends get larger • Data loss and corruption is unacceptable • Variety of data is growing World expectations Tuesday, April 16, 13
you use • Lack of tool knowledge will bite you • Not knowing your numbers makes your choices blind • Eventual consistency is eventual • Conflict resolution strategies matter • Picking a nosql data store will require you to write more backend code World expectations Tuesday, April 16, 13
Reducing system complexity • Avoiding data loss (accepting writes) • Storing data in a meaningful way • Prepare data for reading Challenges Tuesday, April 16, 13
What can be shown immediately, what can wait (think: dashboards vs shopping carts) • How to build backend that’ll make sure it all is ticking • Learn how your clustered client works • Know your potential problems with consistency Things to ponder upon before joining nosql camp Tuesday, April 16, 13
possible to reconstruct your data • write increments (changes) • reconstruct final views from history • for the data that doesn’t tolerate inconsistency, make sure to use appropriate DSs • avoid single point of failure at all costs Possibilities Tuesday, April 16, 13
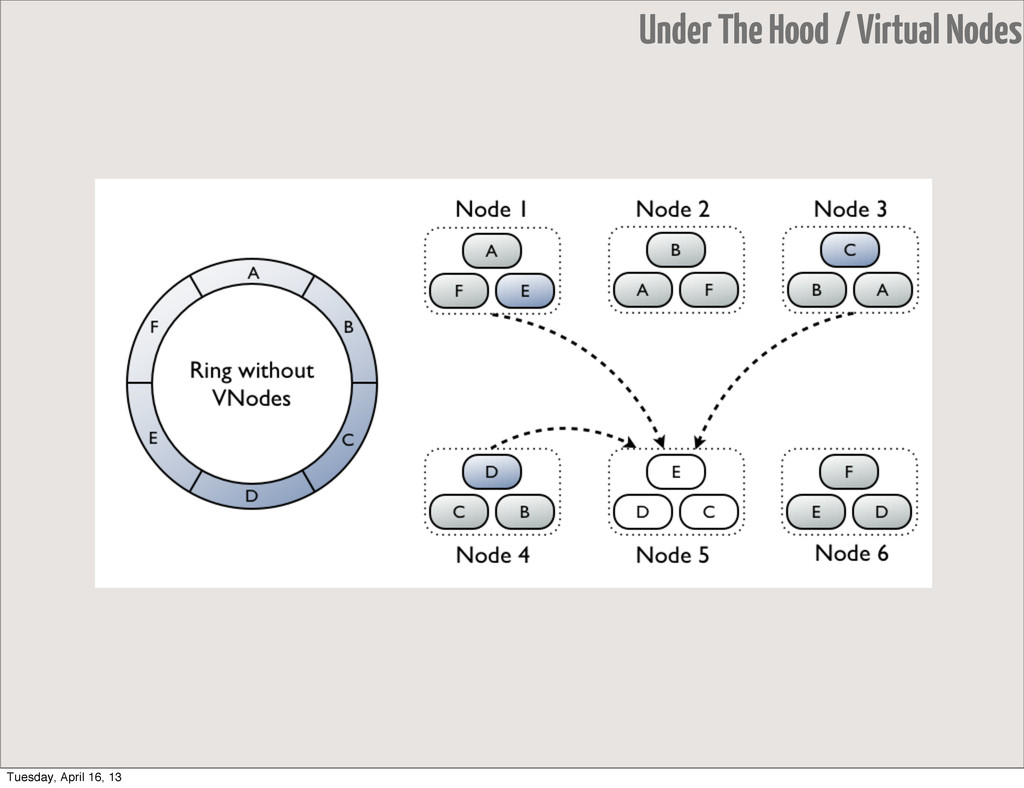
growth of nodes amount, minimal amount of data is affected • Murmur3, Random (consistent hashing) • Ordered Partitioner • allows ordered scans by partition key • difficult load balancing • hotspots because of sequential writes Under The Hood / Paritioners Tuesday, April 16, 13
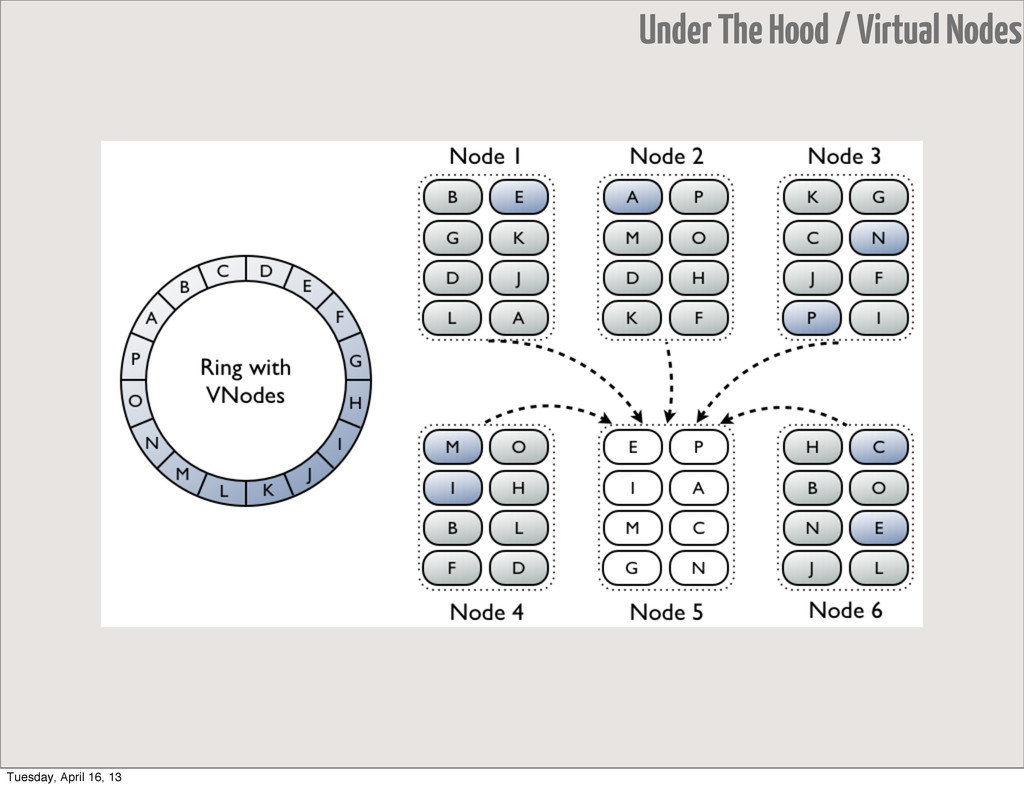
small range, which reduces load • does not require token generation and assignment • helps to avoid rebalancing • rebuilding dead node is faster, since data is copied from more nodes • major improvements for heterogenous cluster Under The Hood / VNodes Tuesday, April 16, 13
is `periodic` • move commitlog to differnt drive (to reduce contention with SSTable) • configure commitlog size • smaller will improve replay time • flush infrequently-updated CFs to disk • (slight) chance of lost written data, if all replicas go down during sync timeout period • check `batch` instead, to sync before ack'ing write Under The Hood / CommitLog Tuesday, April 16, 13
read optimization • reads (potentially) require to combine row fragments from multiple SSTables and unflushed memtables Under The Hood / SSTable Tuesday, April 16, 13
SSTables • discards tombstones, reclaims space • refreshes index of SSTable (changed addresses) Under The Hood / SSTable / Compaction Tuesday, April 16, 13
you connect to may be a coordinator • coordinator determines nodes responsible for the key • responsible nodes are sorted by proximity Under The Hood / Read Path / On Coordinator Tuesday, April 16, 13
not false negatives • determine if SSTable contains the key • avoiding additional disk seeks • uses index to locate data fast • data is returned to client Under The Hood / Read Path / On the node / BOOM filters Tuesday, April 16, 13
first written to CommitLog • then, data is written to Memtable • if there's not enough nodes to receive a write • coordinator takes a hinted write Under The Hood / Write Path Tuesday, April 16, 13
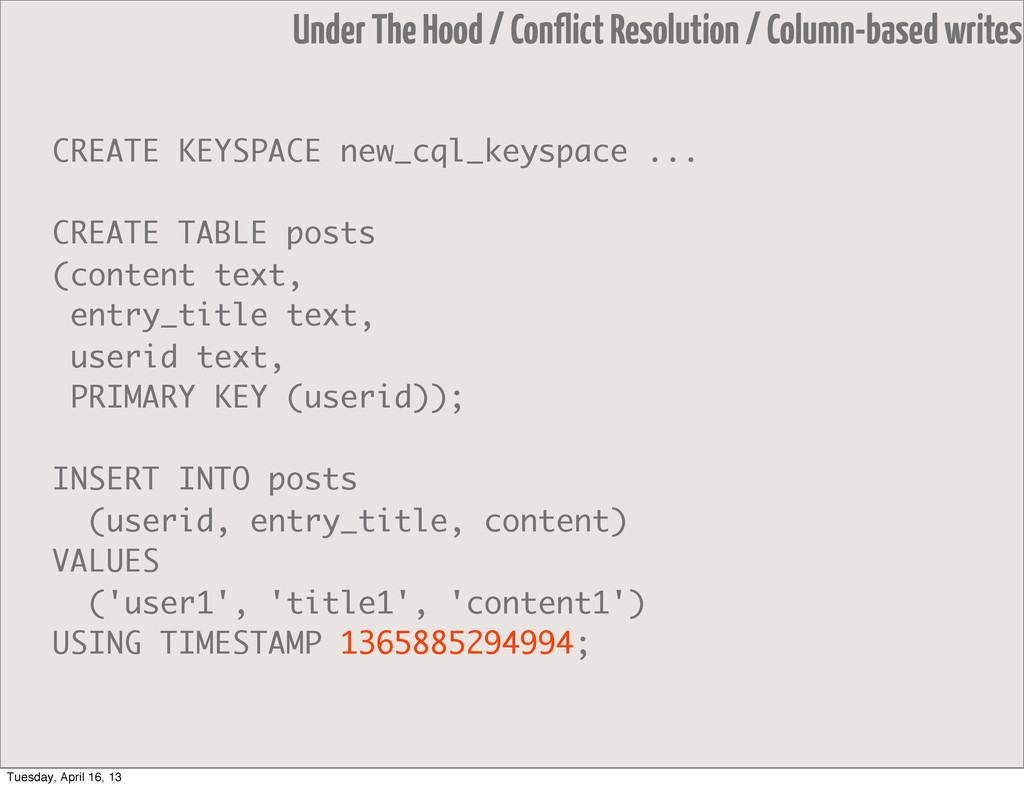
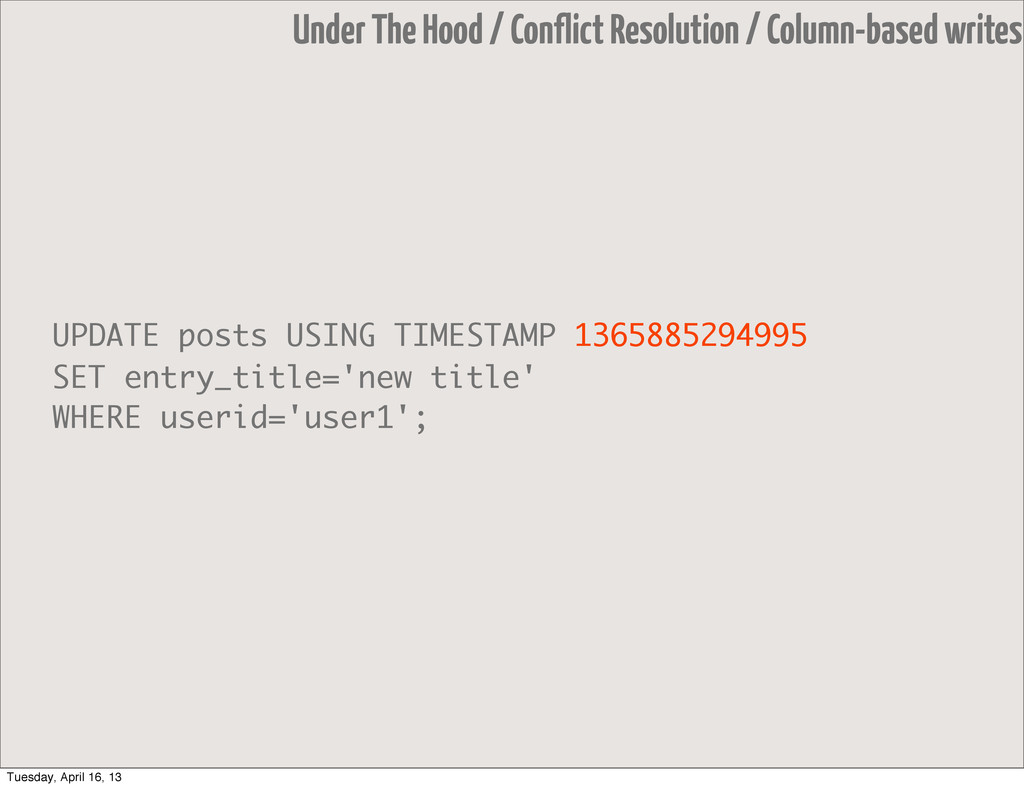
• Yeah, it's timestamp-based • Grab yourself some ntp • or a TAAS (timestamp as a service) • but keep in mind that... • writes are column-based, not row-based Under The Hood / Conflict Resolution Tuesday, April 16, 13
column • allows wide range of queries • Compound primary keys • key itself consists of 2 values • Clustering order • allows on-disk sorting of columns My favorite C* features / Keys Tuesday, April 16, 13
partition key • determines node placement • rest is clustering columns • insert,update,delete ops for same partition key are atomic and isolated • values that share partition key are stored on same node(s) My favorite C* features / Keys Tuesday, April 16, 13
key are performed atomically and in isolation • Supports only Update, Insert and Delete My favorite C* features / Batch Operations Tuesday, April 16, 13
Binary CQL protocol, new possibilities • Internals became way more powerful with 1.2 • Ease of use/development • Still some work to do (Hadoop integration is still on Thrift) My favorite C* features / Conclusions Tuesday, April 16, 13
• Have a powerful backend to conform to the store • Determine best caching strategy • Use windowed operations (EEP) for pre- aggregation, instead of believing realtime ad-hoc myth My favorite C* features / Conclusions Tuesday, April 16, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![get posts[user1]; => (column=content, value=636f6e74656e7431, timestamp=1365885294994) => (column=entry_title, value=7469746c6531, timestamp=1365885294994)](https://files.speakerdeck.com/presentations/36cdc0c088ff013012ae22000a1cbfb9/slide_55.jpg){kind=link}
{kind=link}
![get posts[user1]; => (column=content, value=636f6e74656e7431, timestamp=1365885294994) ;; OLD => (column=entry_title,](https://files.speakerdeck.com/presentations/36cdc0c088ff013012ae22000a1cbfb9/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}