Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Cassandra for Data Analytics Backends
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
αλεx π
September 24, 2015
Research
460
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Cassandra for Data Analytics Backends
αλεx π
September 24, 2015
More Decks by αλεx π
See All by αλεx π
Scalable Time Series With Cassandra
ifesdjeen
1
420
Bayesian Inference is known to make machines biased
ifesdjeen
2
400
Stream Processing and Functional Programming
ifesdjeen
1
790
PolyConf 2015 - Rocking the Time Series boat with C, Haskell and ClojureScript
ifesdjeen
0
520
Clojure - A Sweetspot for Analytics
ifesdjeen
8
2.1k
Going Off Heap
ifesdjeen
3
1.9k
Always be learning
ifesdjeen
1
190
Learn Yourself Emacs For Great Good workshop slides
ifesdjeen
3
350
What Reading 5 Papers can yield for your Business
ifesdjeen
0
390
Other Decks in Research
See All in Research
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
130
Language and AI
ayaniwa
0
170
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
550
コーディングエージェントとABNを再考
hf149
2
760
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
220
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
140
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
250
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
120
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
300
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
1.5k
NLP colloquium: AI Safety Survey
kanekomasahiro
0
840
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
660
Featured
See All Featured
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Designing for humans not robots
tammielis
254
26k
Designing for Timeless Needs
cassininazir
1
320
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
Faster Mobile Websites
deanohume
310
32k
Visualization
eitanlees
152
17k
Un-Boring Meetings
codingconduct
0
340
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
410
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Transcript
@ifesdjeen
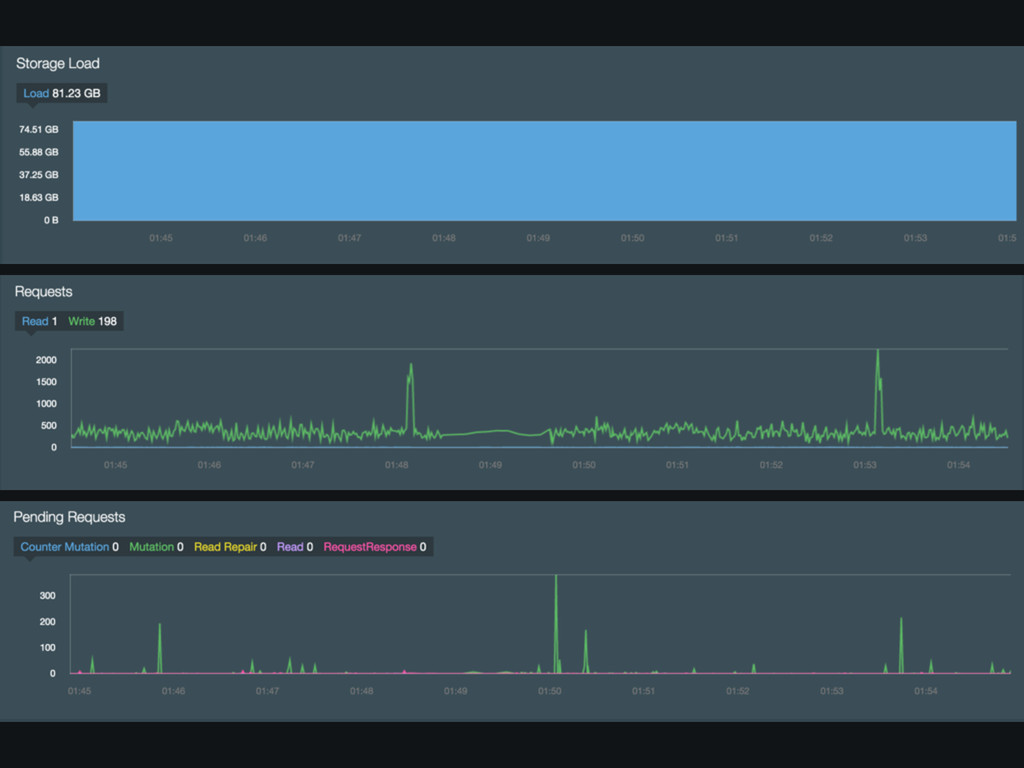
Cassandra Monitoring
None
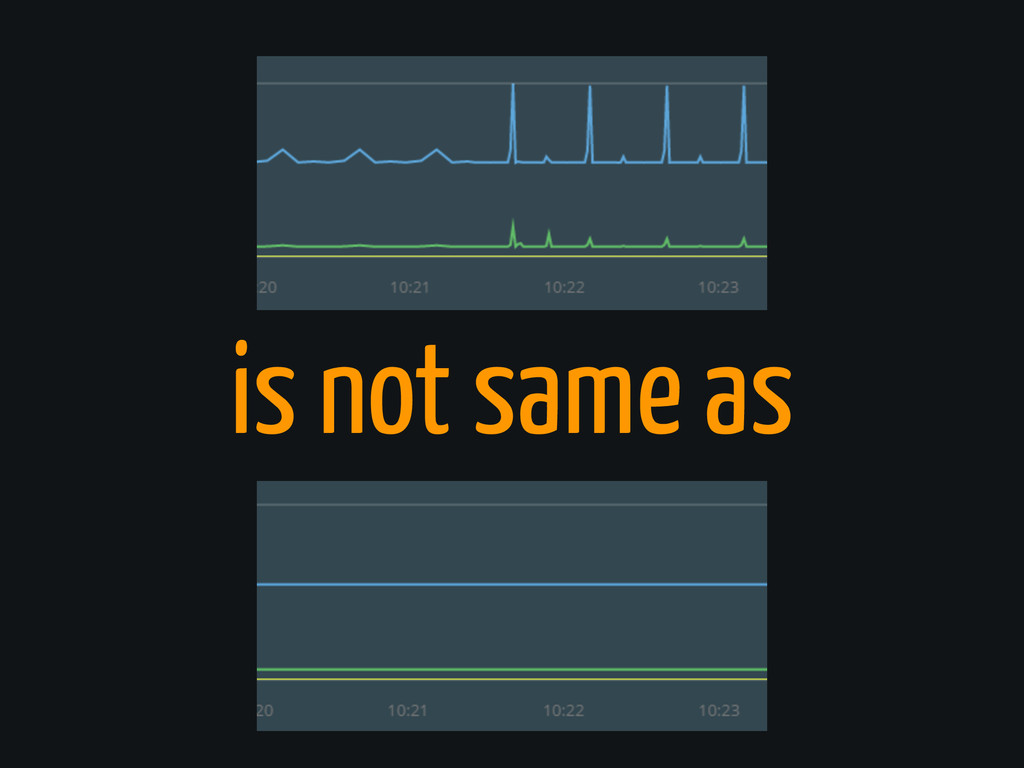
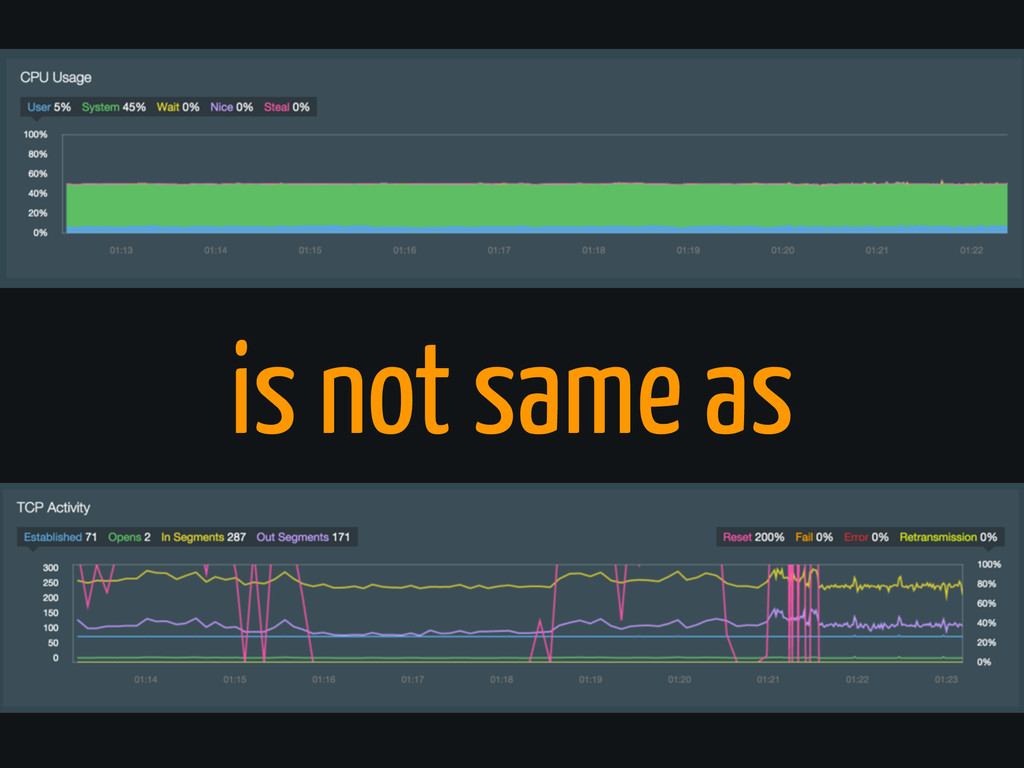
Precision
is not same as
Semantics
is not same as
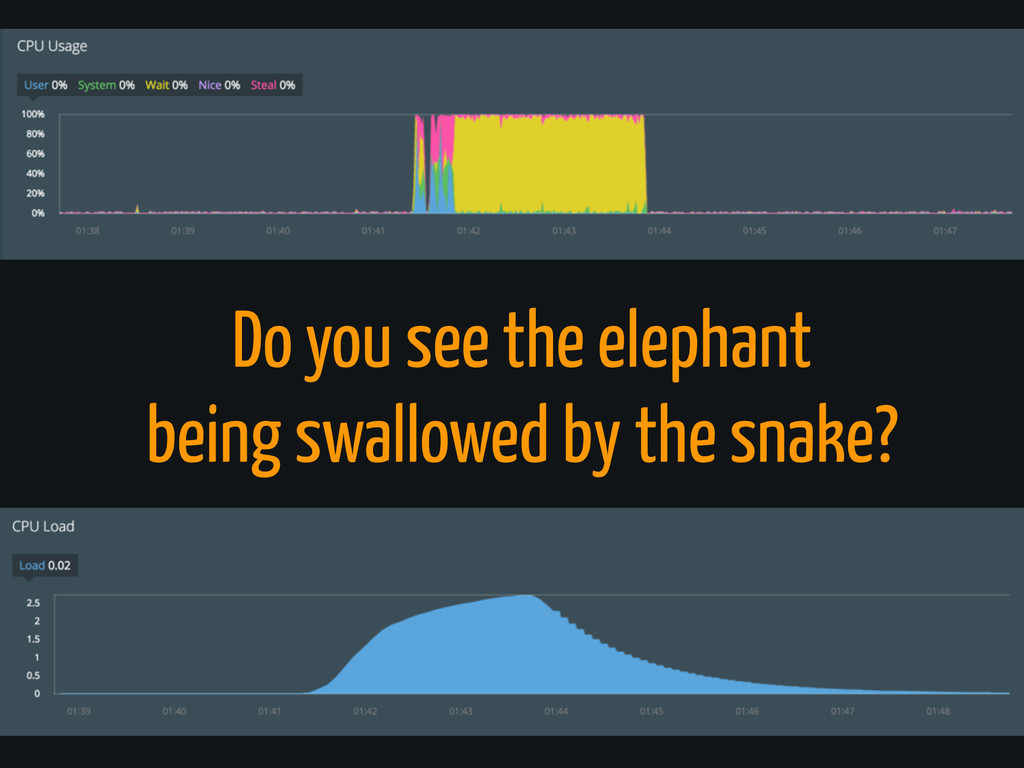
Anomaly detection
Do you see the elephant being swallowed by the snake?
Agenda
Ad-hoc queries
Aggregations Fast
Machine Learning
parallel queries Step 1
+---------------+---------------+ | timestamp | sequenceId | +---------------+---------------+
Used to avoid timestamp resolution collisions To ensure sub-resolution order
Snapshot the data on overflow or timeout Ensures idempotence Sequence ID
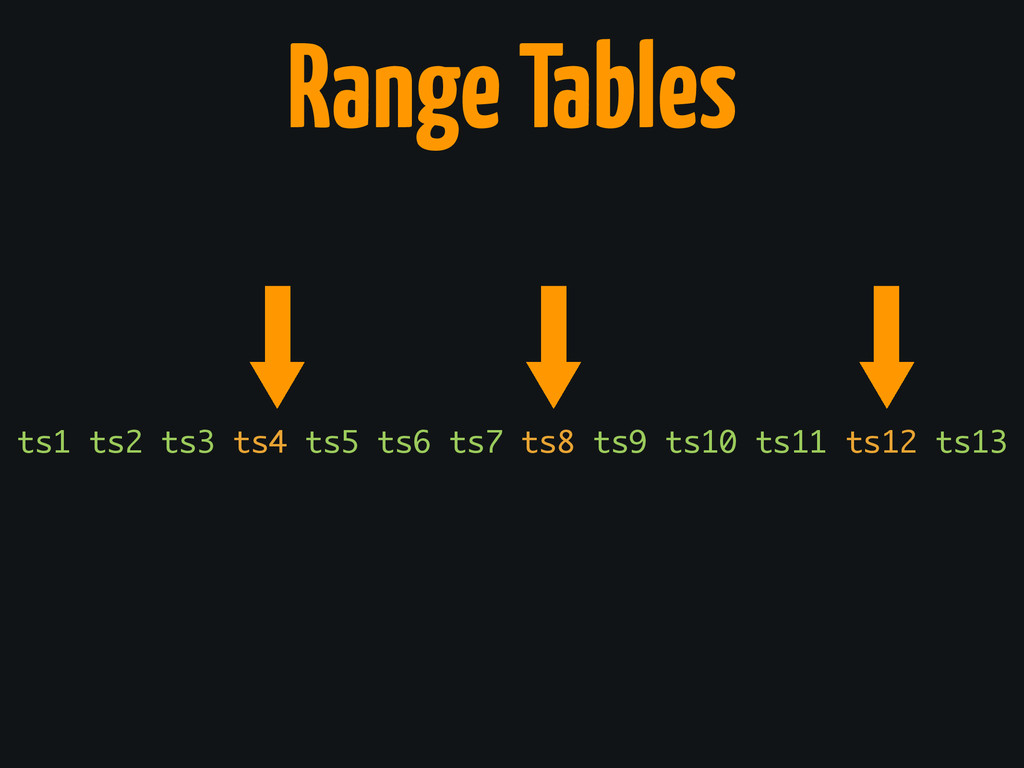
Fighting Dispersion
ts1 ts2 ts3 ts4 ts5 ts6 ts7 ts8 ts9 ts10
ts11 ts12 ts13 Range Tables
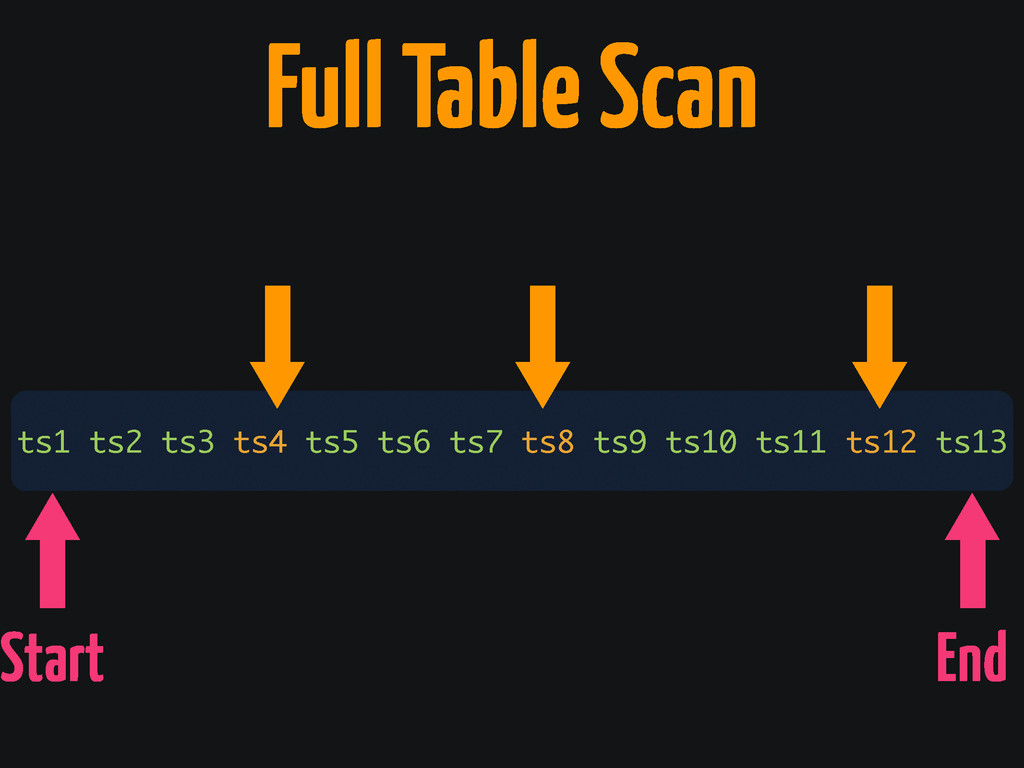
Full Table Scan ts1 ts2 ts3 ts4 ts5 ts6 ts7
ts8 ts9 ts10 ts11 ts12 ts13 Start End
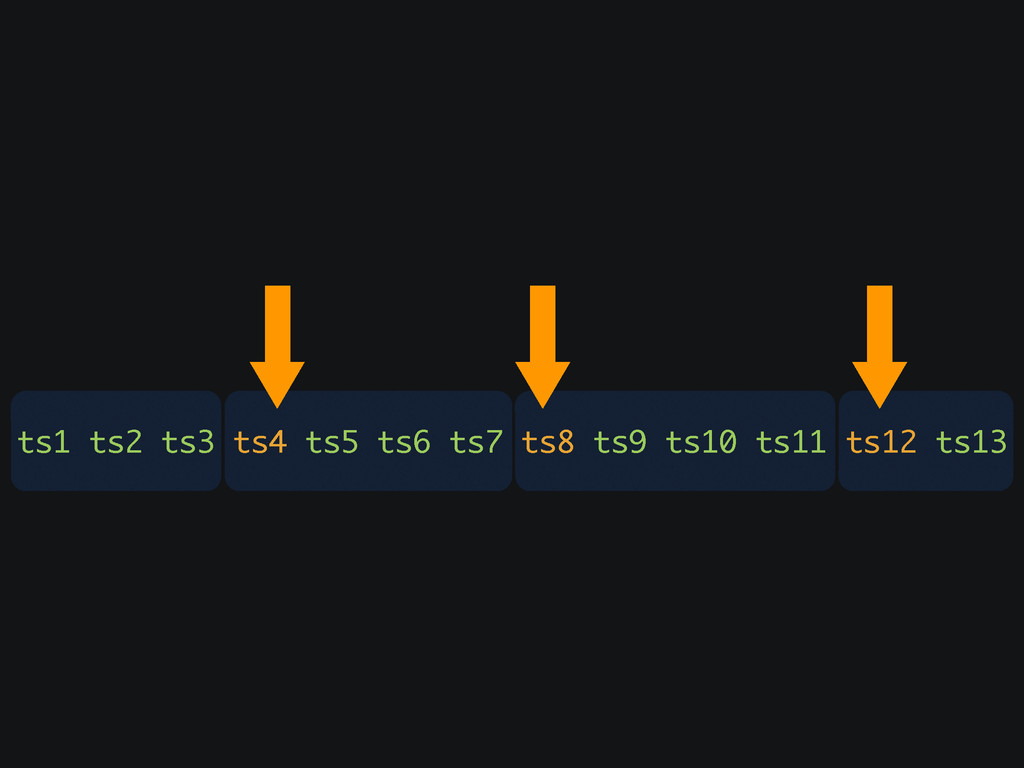
ts1 ts2 ts3 ts4 ts5 ts6 ts7 ts8 ts9 ts10
ts11 ts12 ts13
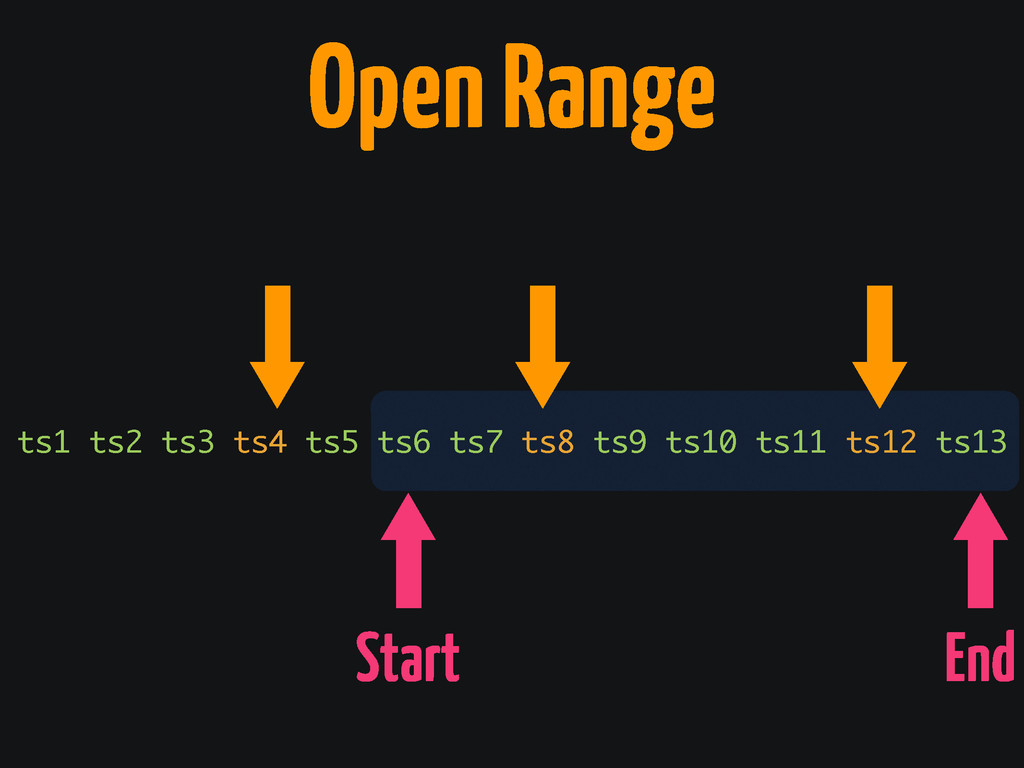
Open Range Start End ts1 ts2 ts3 ts4 ts5 ts6
ts7 ts8 ts9 ts10 ts11 ts12 ts13
ts1 ts2 ts3 ts4 ts5 ts6 ts7 ts8 ts9 ts10
ts11 ts12 ts13
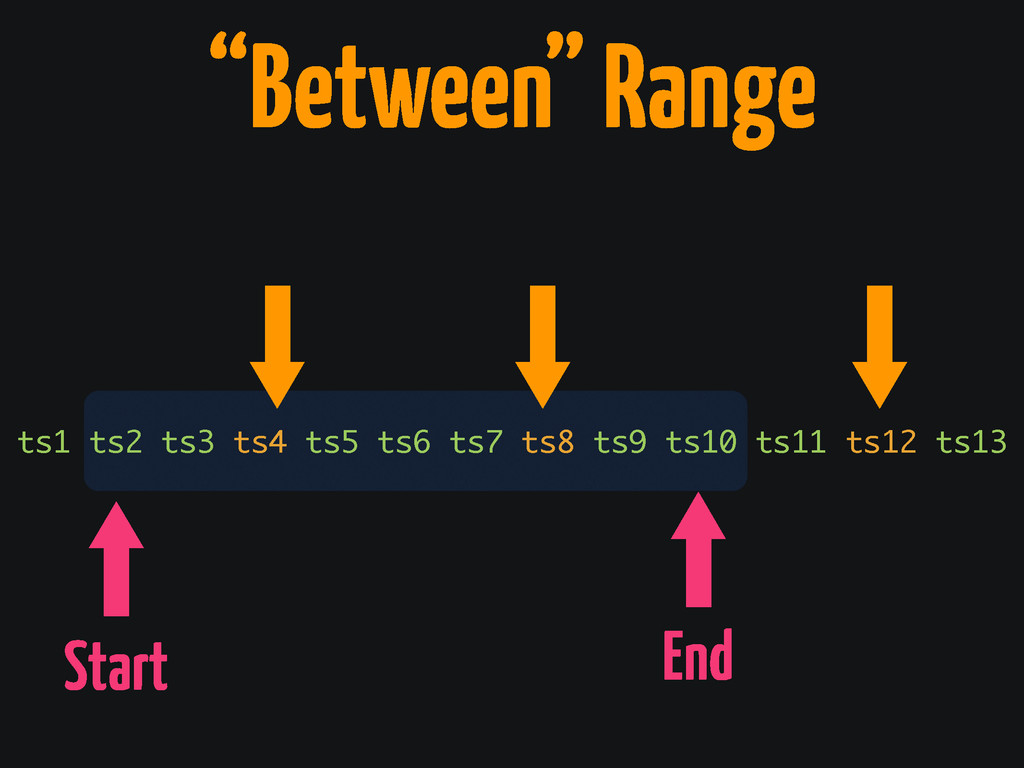
“Between” Range ts1 ts2 ts3 ts4 ts5 ts6 ts7 ts8
ts9 ts10 ts11 ts12 ts13 Start End
ts1 ts2 ts3 ts4 ts5 ts6 ts7 ts8 ts9 ts10
ts11 ts12 ts13
(rich query API) Step 2 add some algebra
None
Stream Fusion for rich ad-hoc queries
What is even Stream Fusion
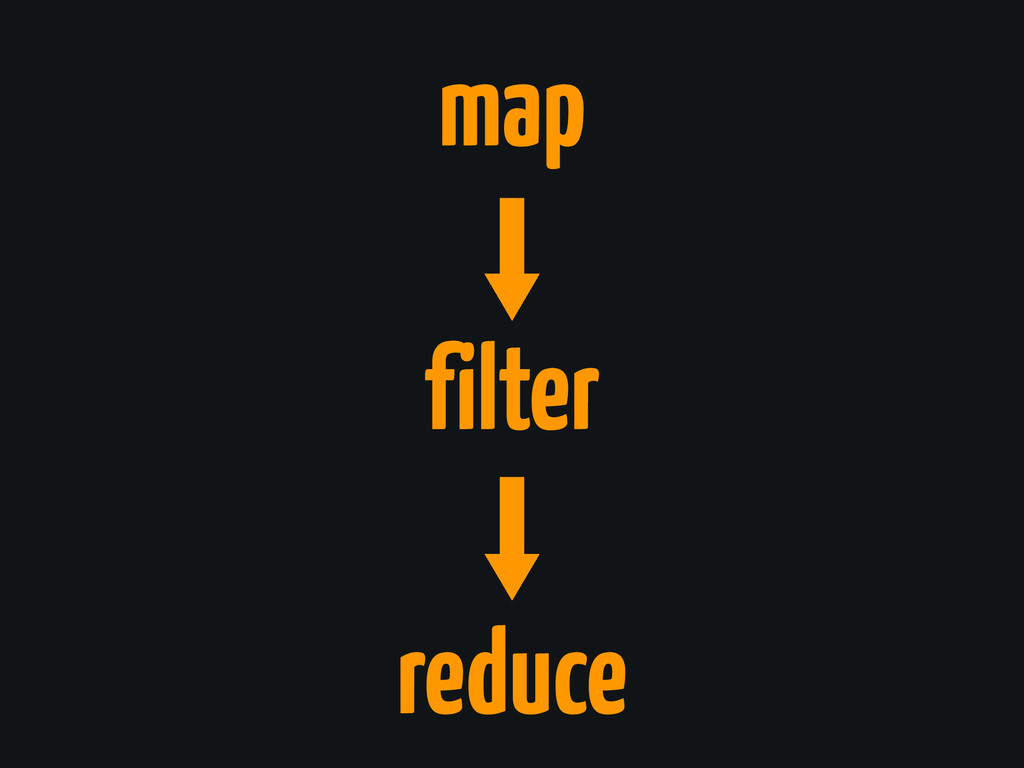
map filter reduce
single step mapFilterReduce
data Step data cursor = Yield data !cursor | Skip
!cursor | Done data Stream data = ∃s. Stream (cursor → Step data cursor) cursor
Stream Beginning: reading from the DB
map Yield data cursor → Yield (f cursor) cursor Skip
cursor → Skip cursor Done → Done maps :: (a → b) → Stream a → Stream b
filter Yield data cursor | p data → Yield data
cursor | otherwise → Skip cursor Skip cursor → Skip cursor Done → Done filters :: (a → Bool) → Stream a → Stream a
reduce/fold Yield x cursor → loop (f data x) cursor
Skip cursor → loop data cursor Done → z foldls :: (Monoid acc) => (acc → a → acc) → acc → Stream a → acc
Append class Monoid a where mempty :: a mappend ::
a -> a -> a -- ^ Identity of 'mappend' -- ^ An associative operation
class (Monoid intermediate) => Aggregate intermediate end where combine ::
intermediate -> end Combine
data Count = Count Int instance Monoid Count where mempty
= Count 0 mappend (Count a) (Count b) = Count $ a + b instance Aggregate Count Int where combine (Count a) = a Count Example
add some ML Step 3
Storing Models
Support Vector Machines
Hyperplane α·x - φ = 1
[ α1 α1 α1 ...αn ] ρ
Option 1: list<double>
CREATE TABLE support_vectors( path varchar, alpha list<double>, phi int, PRIMARY
KEY(path))
Problems High deserialisation overhead Need to add PK specifiers for
multiple SVs
Alternative: blob & byte buffers
Vector Representation
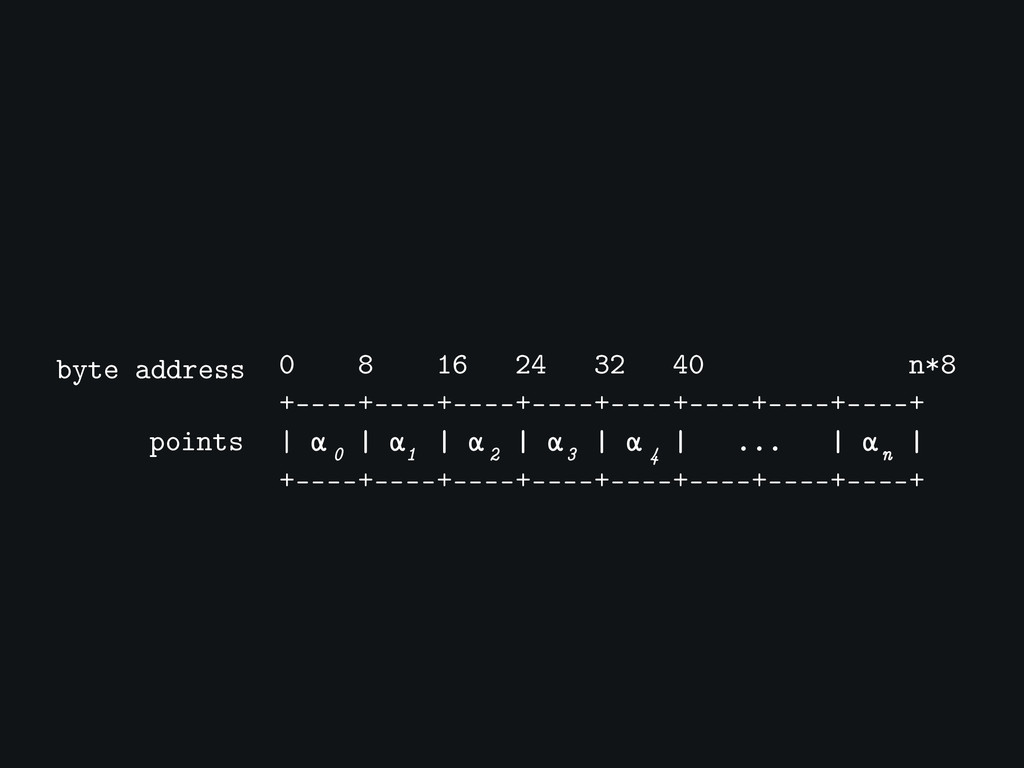
0 8 16 24 32 40 n*8 +----+----+----+----+----+----+----+----+ | α
| α | α | α | α | ... | α | +----+----+----+----+----+----+----+----+ byte address points 1 2 3 4 0 n
Matrix Representation
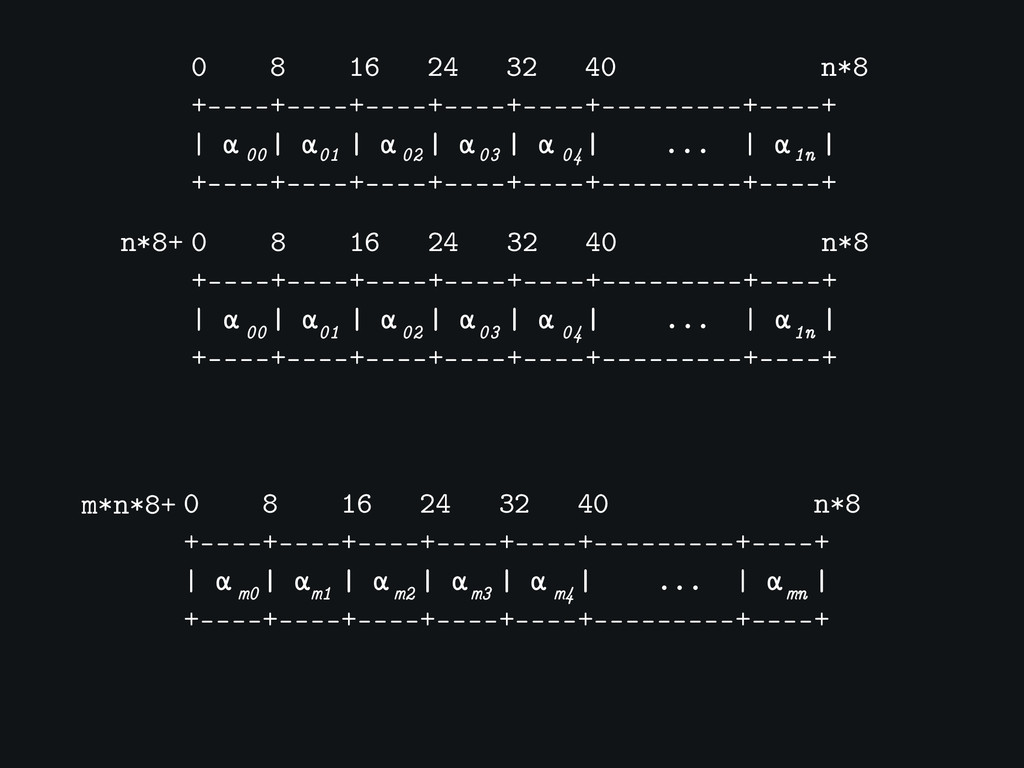
0 8 16 24 32 40 n*8 +----+----+----+----+----+---------+----+ | α
| α | α | α | α | ... | α | +----+----+----+----+----+---------+----+ 01 02 03 04 00 1n n*8+ 0 8 16 24 32 40 n*8 +----+----+----+----+----+---------+----+ | α | α | α | α | α | ... | α | +----+----+----+----+----+---------+----+ 01 02 03 04 00 1n m*n*8+ 0 8 16 24 32 40 n*8 +----+----+----+----+----+---------+----+ | α | α | α | α | α | ... | α | +----+----+----+----+----+---------+----+ m1 m2 m3 m4 m0 mn
Advantages No serialisation overhead Fast relative access Easy to go
multi-dimensional Easy to implement atomic in-memory operations
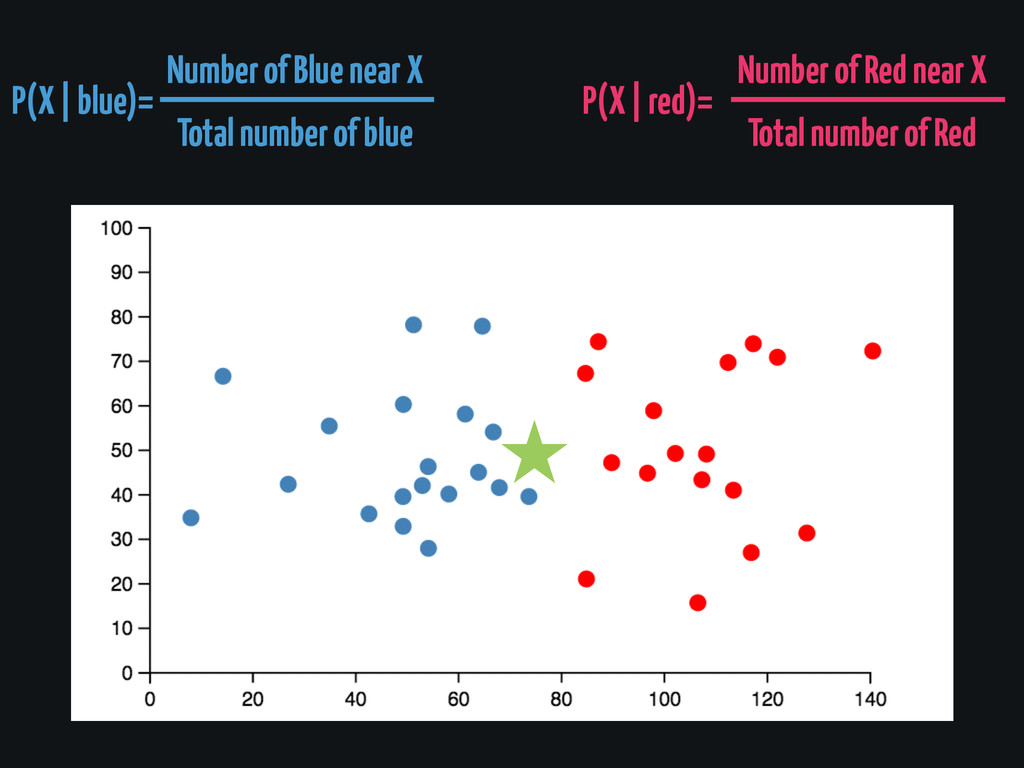
Bayesian Classifiers
P(X | blue)= Number of Blue near X Total number
of blue P(X | red)= Number of Red near X Total number of Red
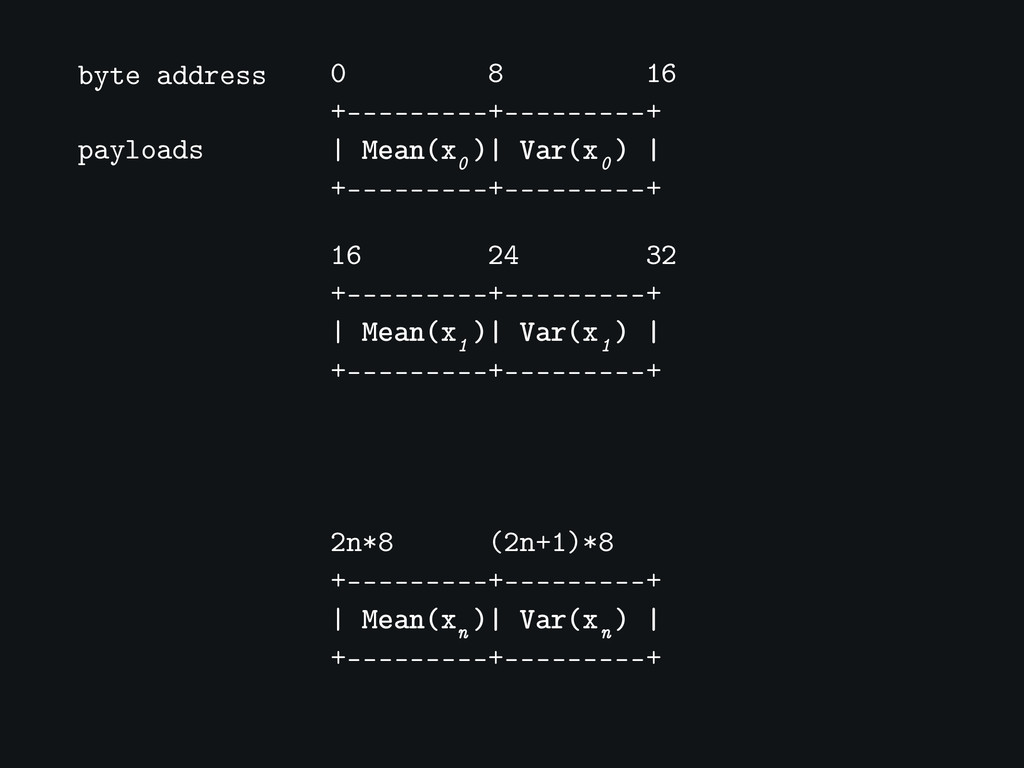
[[Mean(x1), Var(x1)] [Mean(x2), Var(x3)] ... [Mean(xn), Var(xn)]]
0 8 16 +---------+---------+ | Mean(x )| Var(x ) |
+---------+---------+ 0 0 16 24 32 +---------+---------+ | Mean(x )| Var(x ) | +---------+---------+ 1 1 2n*8 (2n+1)*8 +---------+---------+ | Mean(x )| Var(x ) | +---------+---------+ n n byte address payloads
make it rocket-fast Step 4
Approximate Data Structures
Bloom Filters are basically long arrays / vectors
BitSet
0 8 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | +---+---+---+---+---+---+---+---+ 8 16 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | +---+---+---+---+---+---+---+---+ 16 24 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | +---+---+---+---+---+---+---+---+ 24 32 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | +---+---+---+---+---+---+---+---+ bit address
Advantages 64 bits per 8-byte Long Easy to represent by
the long-array using offsets, bit shifts and masks Easy to implement atomic in-memory operations
Count-min sketches are basically int matrices
Histograms are basically long vectors
Conclusions Ad-hoc queries Parallelism Lightweight DSs representation Optimisations and good
API fits
@ifesdjeen
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[ α1 α1 α1 ...αn ] ρ](https://files.speakerdeck.com/presentations/48f0d2a8595d49a78d29eb8e2b49165e/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[[Mean(x1), Var(x1)] [Mean(x2), Var(x3)] ... [Mean(xn), Var(xn)]]](https://files.speakerdeck.com/presentations/48f0d2a8595d49a78d29eb8e2b49165e/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}