DBObject dbobj = BasicDBObjectBuilder.start() .add("key1","value1") .add("key2","value2").get(); c.insert(dbobj); Meanwhile in world of Java, they insert documents Friday, October 19, 12
BasicDBObject( "$sum", 1 ))); DBObject group = new BasicDBObject( ); group.put("_id", "$name" ); group.put( "docsPerName", new BasicDBObject( "$sum", 1 )); group.put( "countPerName", new BasicDBObject( "$sum", "$count" )); AggregationOutput out = c.aggregate(new BasicDBObject( "$project", projFields ), new BasicDBObject( "$group", group)); Meanwhile in world of Java, they use atomic modifiers Friday, October 19, 12
LogFactory.getLog( WordCount.class ); public static class TokenizerMapper extends Mapper<Object, BSONObject, Text, IntWritable> { private final static IntWritable one = new IntWritable( 1 ); private final Text word = new Text(); public void map( Object key, BSONObject value, Context context ) throws IOException, InterruptedException{ final StringTokenizer itr = new StringTokenizer( value.get( "x" ).toString() ); while ( itr.hasMoreTokens() ){ word.set( itr.nextToken() ); context.write( word, one ); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private final IntWritable result = new IntWritable(); public void reduce( Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException{ int sum = 0; for ( final IntWritable val : values ){ sum += val.get(); } result.set( sum ); context.write( key, result ); } } Meanwhile in world of Java, they even use hadoop (spooky!). public static void main( String[] args ) throws Exception{ final Configuration conf = new Configuration(); MongoConfigUtil.setInputURI( conf, "mongodb://localhost/test.in" ); MongoConfigUtil.setOutputURI( conf, "mongodb://localhost/test.out" ); System.out.println( "Conf: " + conf ); final Job job = new Job( conf, "word count" ); job.setJarByClass( WordCount.class ); job.setMapperClass( TokenizerMapper.class ); job.setCombinerClass( IntSumReducer.class ); job.setReducerClass( IntSumReducer.class ); job.setOutputKeyClass( Text.class ); job.setOutputValueClass( IntWritable.class ); job.setInputFormatClass( MongoInputFormat.class ); job.setOutputFormatClass( MongoOutputFormat.class ); System.exit( job.waitForCompletion( true ) ? 0 : 1 ); } } Friday, October 19, 12
/ vars • transactional memory access yes, with retries • no user locks, no deadlocks • mutation through pure function • coordinated • readers can read value at any point in time STM?.. Friday, October 19, 12
• powerful expressive query DSL • support for MongoDB 2.0+ features • has next to no performance overhead • well maintained • well documented Monger Friday, October 19, 12
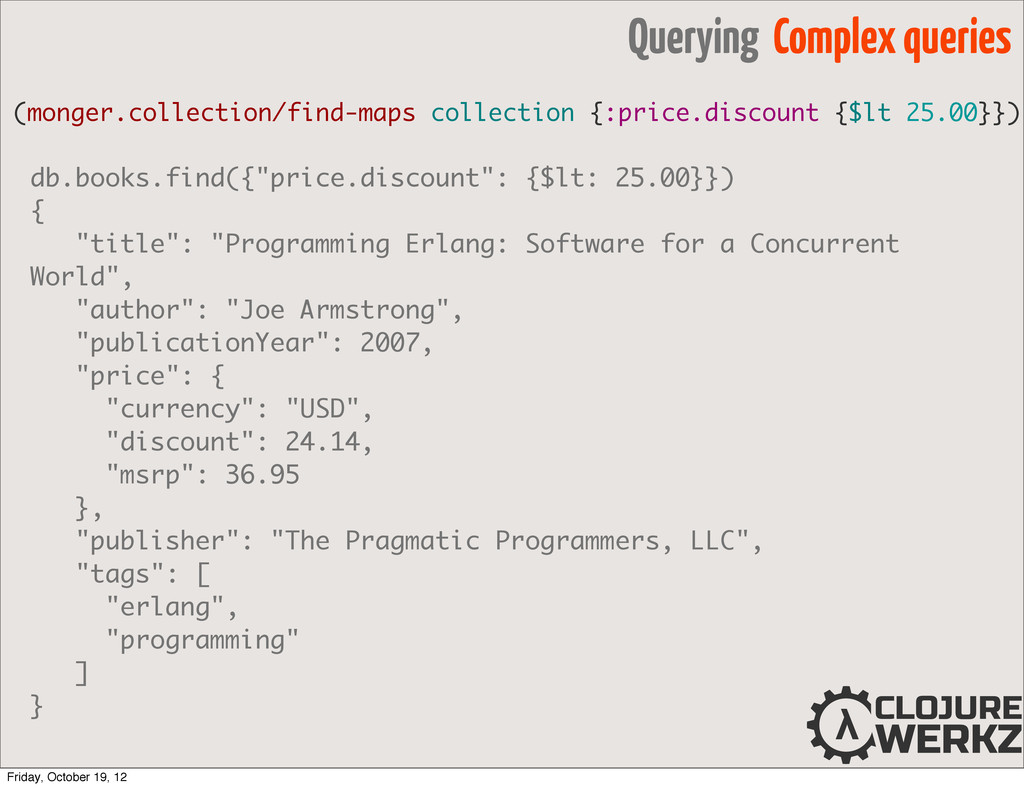
is greater than 10 (mgcol/find collection {:users {$gt 10}}) •$gt "greater than" comparator •$gte "greater than or equals" comparator •$gt "less than" comparator •$lte "less than or equals" comparator •$all matches all values in the array Friday, October 19, 12
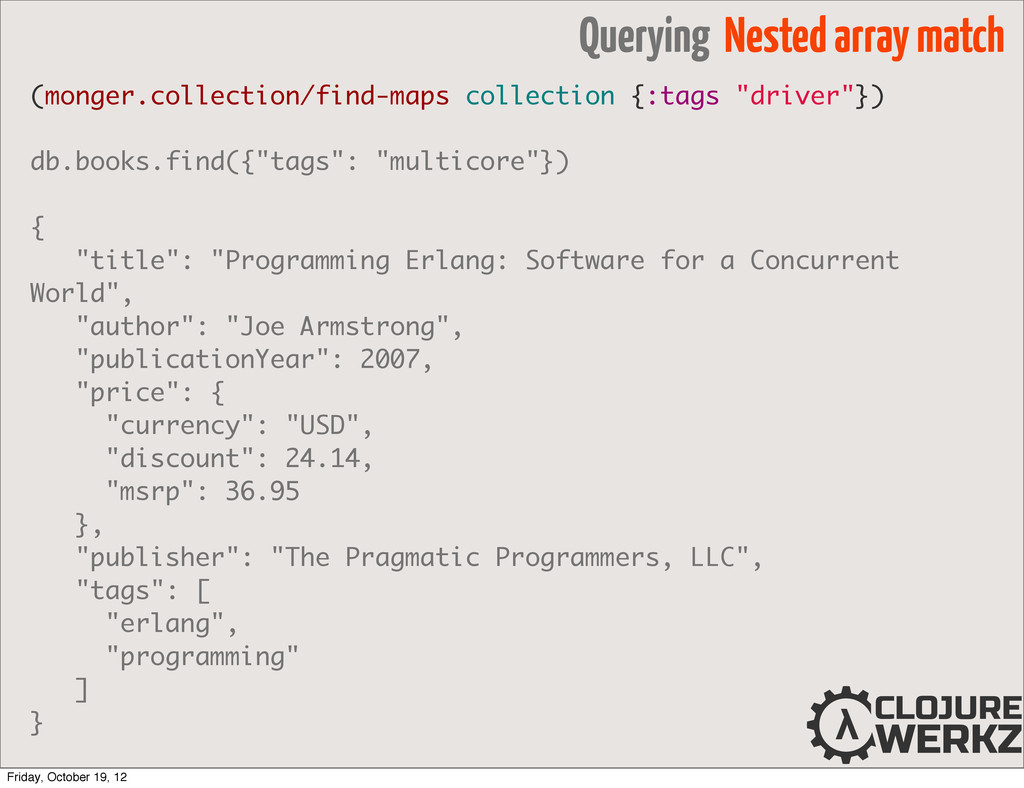
field matches all elements ;; of the given array (mgcol/find-maps collection {:tags {$all [ "functional" "object-oriented" ]}}) • $in analogous to the SQL IN modifier • $nin “not in set” Friday, October 19, 12
for the given value (monger.collection/update "scores" { :_id user-id } { :score 10 } }) $set ;; sets field (or set of fields) to value (monger.collection/update "things" { :_id oid } { $set { :weight 20.5 } }) $unset ;; $unset deletes a given field (monger.collection/update "things" { :_id oid } { $unset { :weight 1 } }) $rename ;; renames a given field (monger.collection/update "things" { :_id oid } { $rename { :old_field_name "new_field_name" } }) Friday, October 19, 12
(mgcol/update "docs" { :_id oid } { $push { :tags "modifiers" } }) $pushAll ;; appends each value in value_array to field (mgcol/update coll { :_id oid } { $pushAll { :tags ["mongodb" "docs"] } }) $addToSet ;; adds value to the set (go figure) (mgcol/update coll { :_id oid } { $addToSet { :tags "modifiers" } }) And many many more... Friday, October 19, 12
conversion • implement a single function (to-db-object) for multiple different types • Runtime will get the type and call the corresponding method for you. • Recurse into keys/values by simply calling to-db-object. • don’t have to know what type of the object is given _now_, simply implement for all possible. • allows extension by library user by simply implementing the protocol Clojure Way Making Monger Conversion Protocols Friday, October 19, 12
define constants on the fly • extensible (you can add as many defoperator’s as you want) • easy to change impl (change protocol at one place) • actually allows you to get your DSL closer to the domain Clojure Way Making Monger Query Operators Macros Friday, October 19, 12
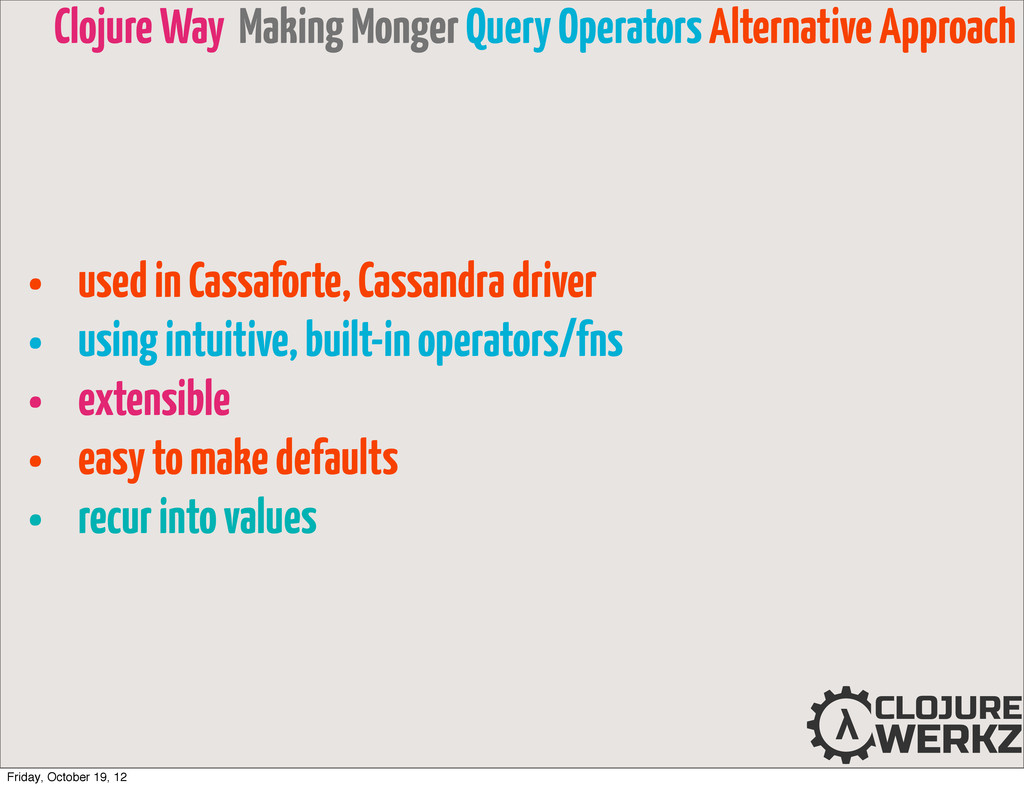
operators/fns • extensible • easy to make defaults • recur into values Clojure Way Making Monger Query Operators Alternative Approach Friday, October 19, 12
have thread-local dynamic vars • people don’t have to pass/carry connection around • easy defaults (set dynamic by alter-var-root) • easy to understand Clojure Way Making Monger Multiple Connections Bindings Friday, October 19, 12
create DSL that’s close to your domain • specify collection just once • use thrush (->) operator to pass collection to all parts of ~@body • easy to understand • DSL methods that will be evaluated later (find/fields...) return hashes • hashes are destructured in :keys of exec function Clojure Way Making Monger Query DSL Macro/thrush Friday, October 19, 12
many operations at once as you want, as they will be very readable (and also composable) • DSL is very extensible, since you can write your own arbitrary functions that return hashes, so you can write (find-person-by- gender :male). Paginate is one of examples Clojure Way Making Monger Query DSL Macro/thrush Friday, October 19, 12
about server errors, only network) • Very (very) high virtual memory usage (yeah, right, let’s just use “repairDatabase”) • Repairs require lot of disk space (quantity of disk space that’s equal to size of your db, so when running into trouble, use --repairpath) • The rest I won’t mention in the talk Facts you probably won’t hear on Mongo Conferences Friday, October 19, 12
a couple of weeks before the conf) Works in production (on rather small, ~15gb datasets) https://github.com/ifesdjeen/cascading-mongodb Cascading-Mongodb tap Friday, October 19, 12
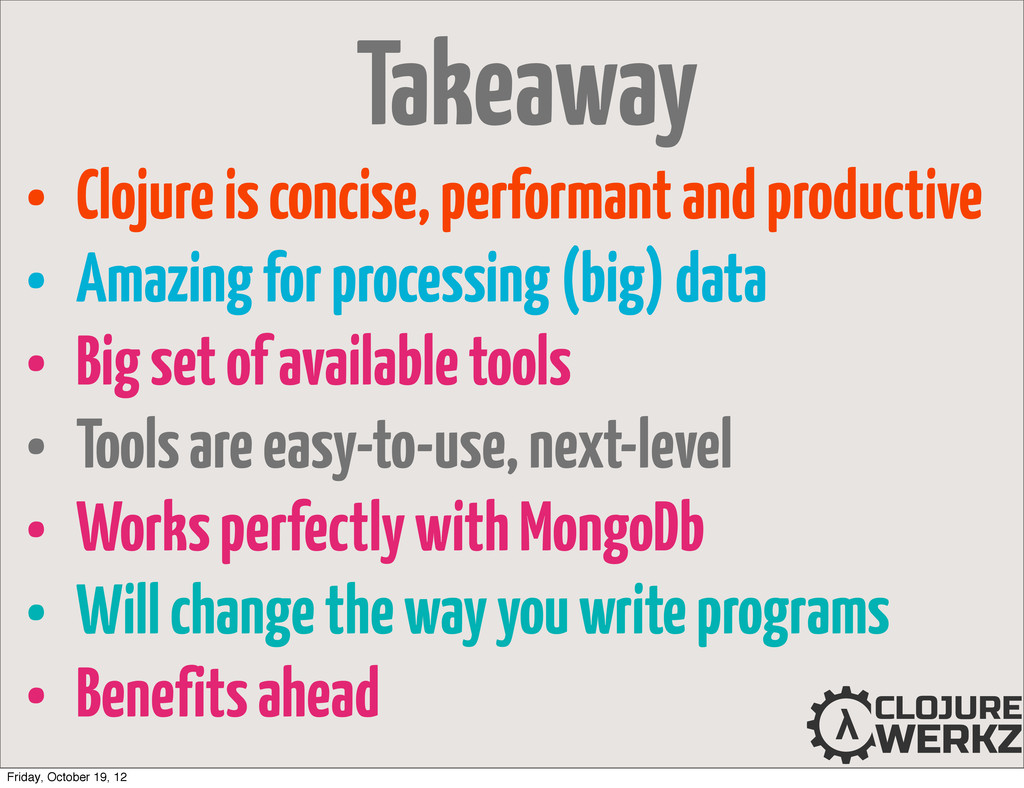
processing (big) data • Big set of available tools • Tools are easy-to-use, next-level • Works perfectly with MongoDb • Will change the way you write programs • Benefits ahead Takeaway Friday, October 19, 12
upsides • Get away from db-js map/reduce timely • Evaluate upsides of new tech • Use tools that make your team more productive • Evaluate incidental complexity Takeaway Friday, October 19, 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![first-class functions (def hello (fn [] "Hello world")) just in](https://files.speakerdeck.com/presentations/508123325b45fd0002026bef/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Primitives, array/vector [ "value1" "value2" "value3" ] [ "value1", "value2",](https://files.speakerdeck.com/presentations/508123325b45fd0002026bef/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Clojure Way Making Monger Conversion (defprotocol ConvertToDBObject (^com.mongodb.DBObject to-db-object [input]))](https://files.speakerdeck.com/presentations/508123325b45fd0002026bef/slide_76.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Cascalog (<- [?count] (in _) (c/count ?count)) Remember that spooky](https://files.speakerdeck.com/presentations/508123325b45fd0002026bef/slide_96.jpg){kind=link}
{kind=link}
![Cascalog (?<- (stdout) [?person ?age] (age ?person ?age) (= ?person](https://files.speakerdeck.com/presentations/508123325b45fd0002026bef/slide_98.jpg){kind=link}
![Cascalog (?<- (stdout) [?person ?count] (follows ?person _) (c/count ?count))](https://files.speakerdeck.com/presentations/508123325b45fd0002026bef/slide_99.jpg){kind=link}
![Cascalog (<- output [!date ?md5 !count] (input ?type ?hostname ?received_at](https://files.speakerdeck.com/presentations/508123325b45fd0002026bef/slide_100.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}