Talk delivered at Open Data Science Conference, San Francisco, November 2015
This version includes speaker notes.
As more and more applications are being deployed in the cloud, developers are learning how to best design software for this new type of system. These Cloud Native applications are single-purpose, stateless and easily scalable. This contrasts with traditional approaches which created large, monolithic, and fragile systems. What can data scientists learn from these new approaches, and how can we make sure our models are easily deployed in this kind of system? In this talk I will discuss the principles of cloud native design, how they apply to data science driven applications and how data scientists can get started using open source cloud native platforms.
{kind=link}
{kind=link}
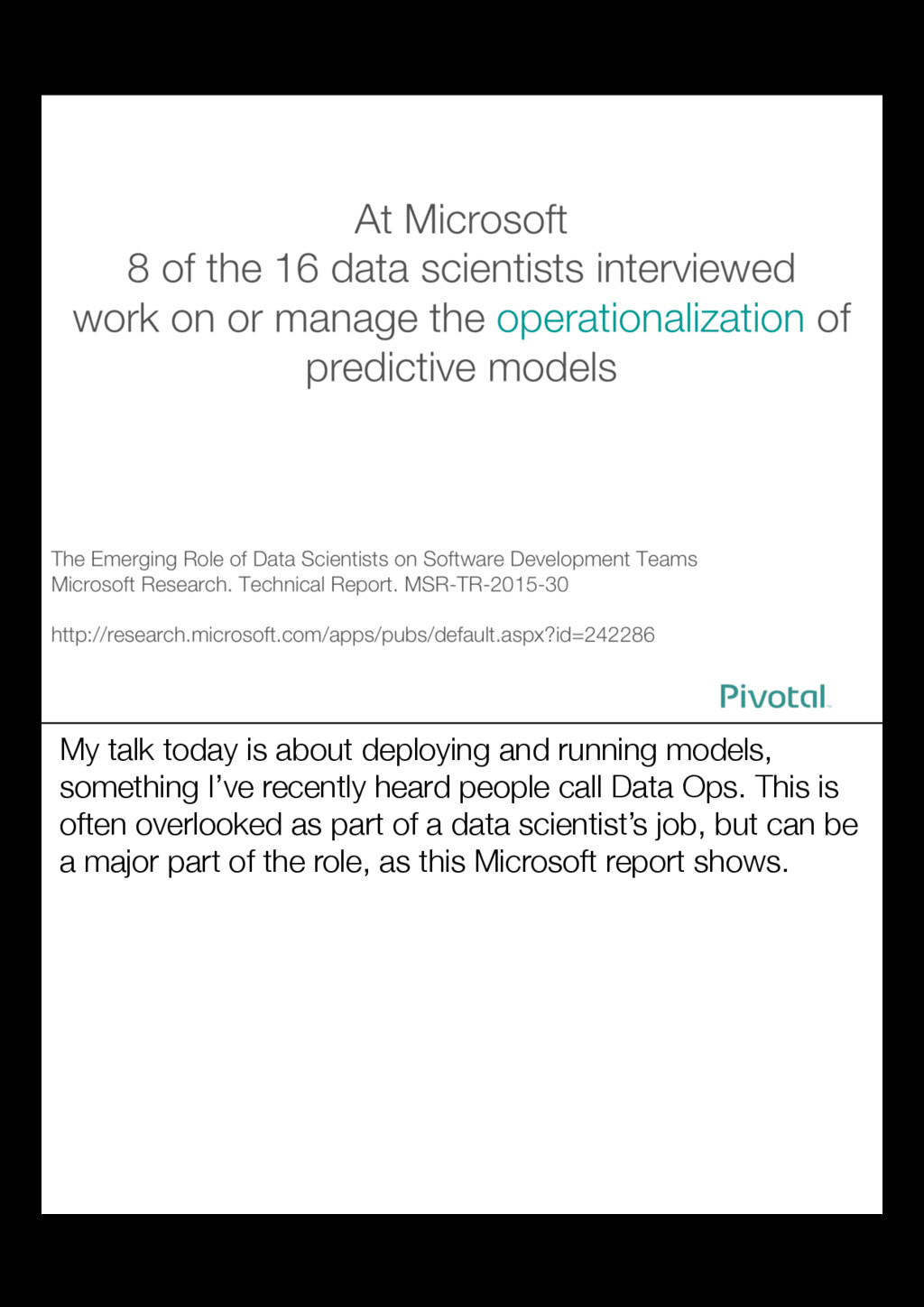{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
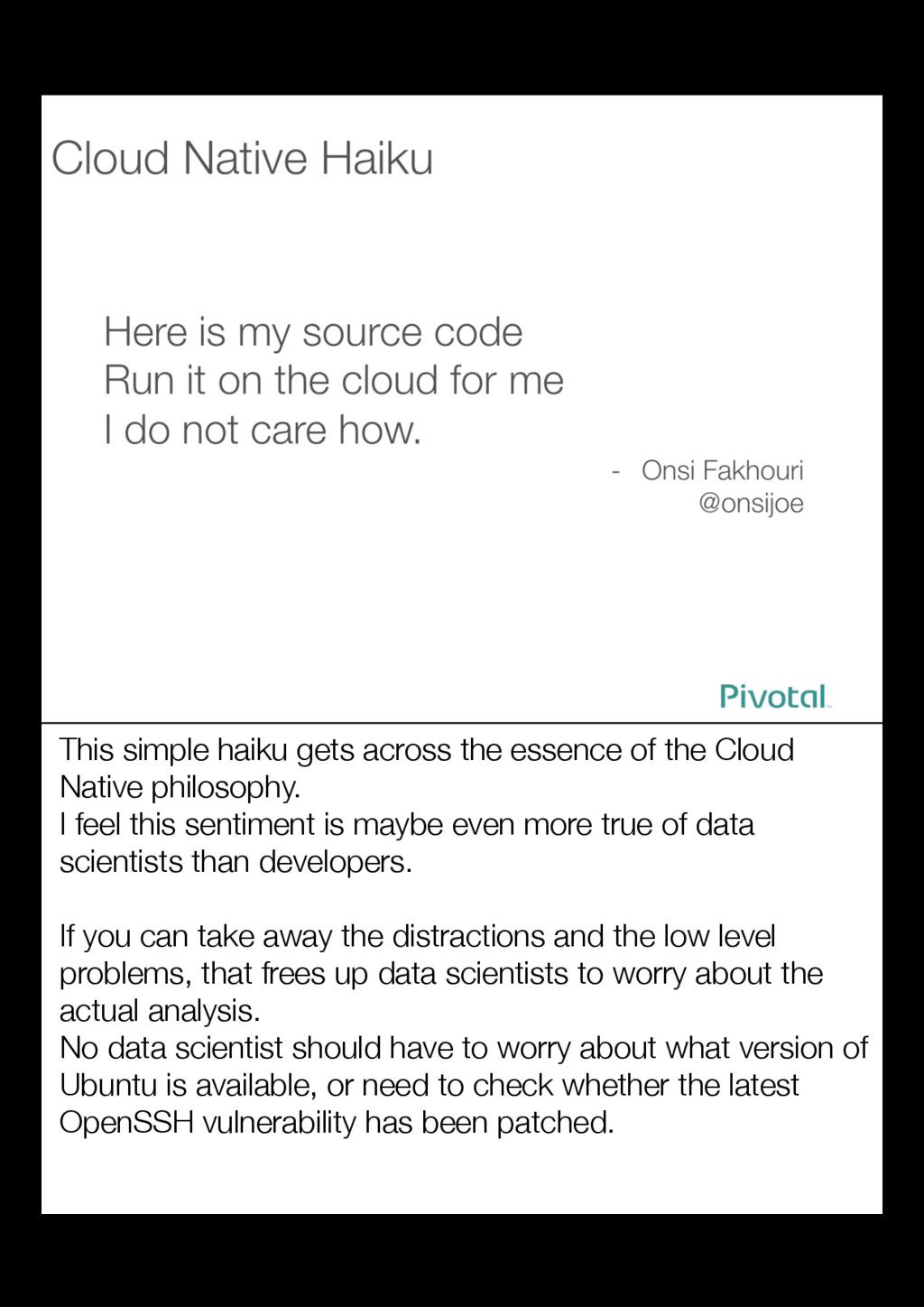{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
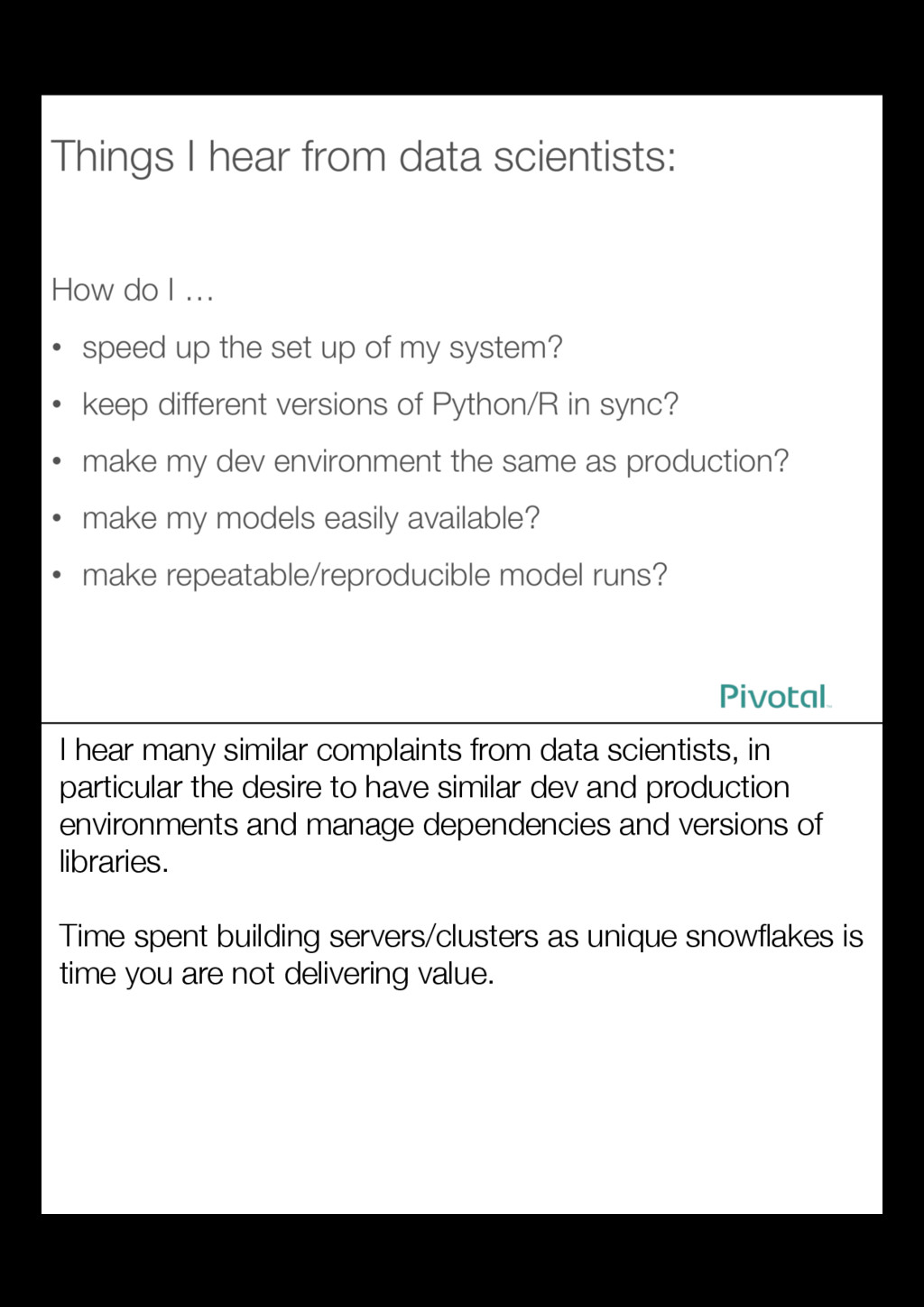{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}