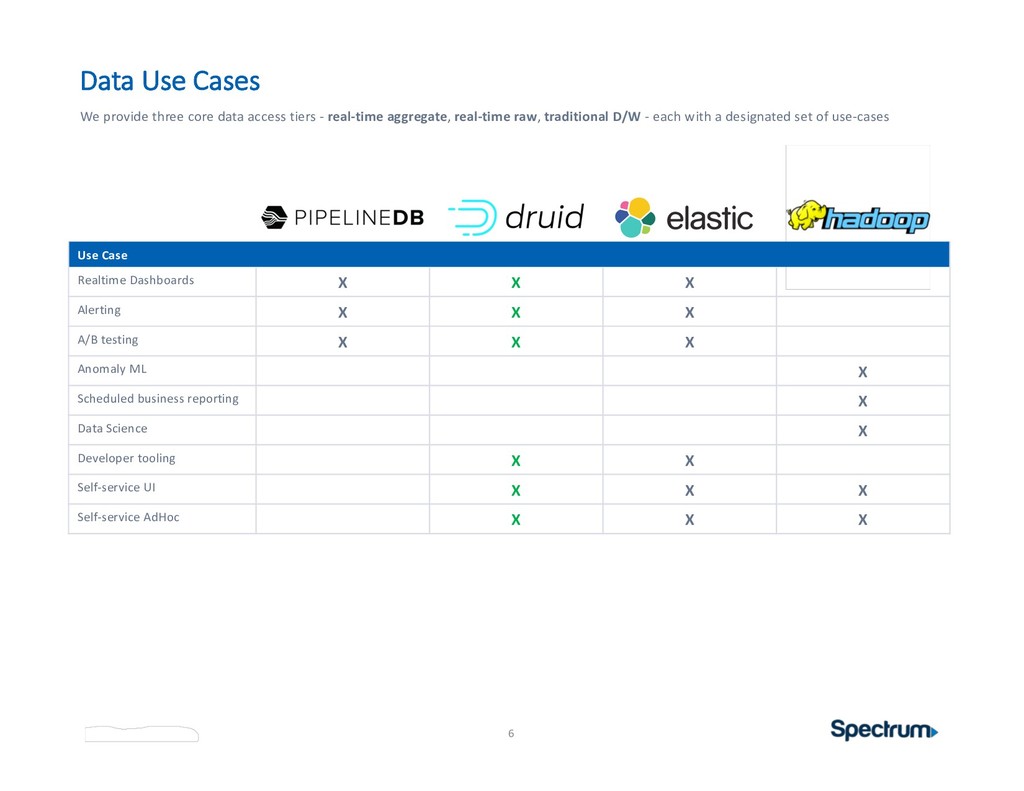
tiers - real-time aggregate, real-time raw, traditional D/W - each with a designated set of use-cases Use Case Realtime Dashboards X X X Alerting X X X A/B testing X X X Anomaly ML X Scheduled business reporting X Data Science X Developer tooling X X Self-service UI X X X Self-service AdHoc X X X
Ingestion Depends On • Ingest broken down into tasks • Ingest must keep up at peak • Maintain task buffer for ingest spec changes In our case • 20 tasks per source (5m and 1h) • 40 total ingest tasks • 40 buffer tasks for ingest changes • 80 tasks for current load
rows • Replication • Retention In our case • 20M rows / hour • 2x replication • 300GB/day for 5 minute ingest • 180GB/day for 1 hour ingest • 100TB for 90 days + 1 year 17 Self-service data availability and storage requirements Storage
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}