On the Druid project, our goal is to build the engine that powers your analytics applications. Apps like interactive dashboards, slice-and-dice tools, and real-time monitoring systems, all need to respond quickly in order to be effective. This talk is about three of the virtues that keep analytic apps running smoothly. (And they're not that weird, we promise!)
In this talk, we'll discuss:
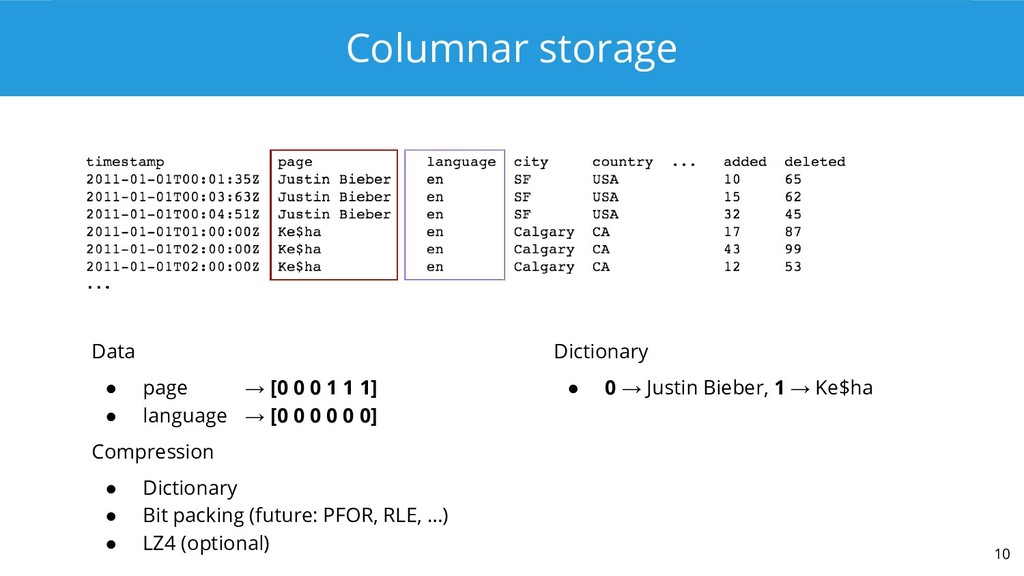
1. The virtue of brevity: it's best known as the soul of wit, but is also your gateway to the performance-improving benefits of compression.
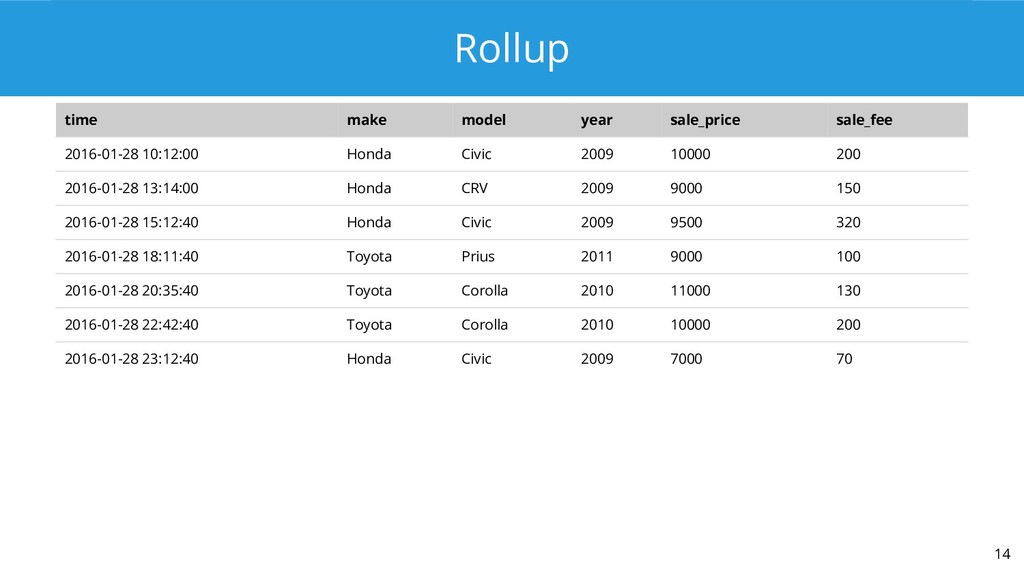
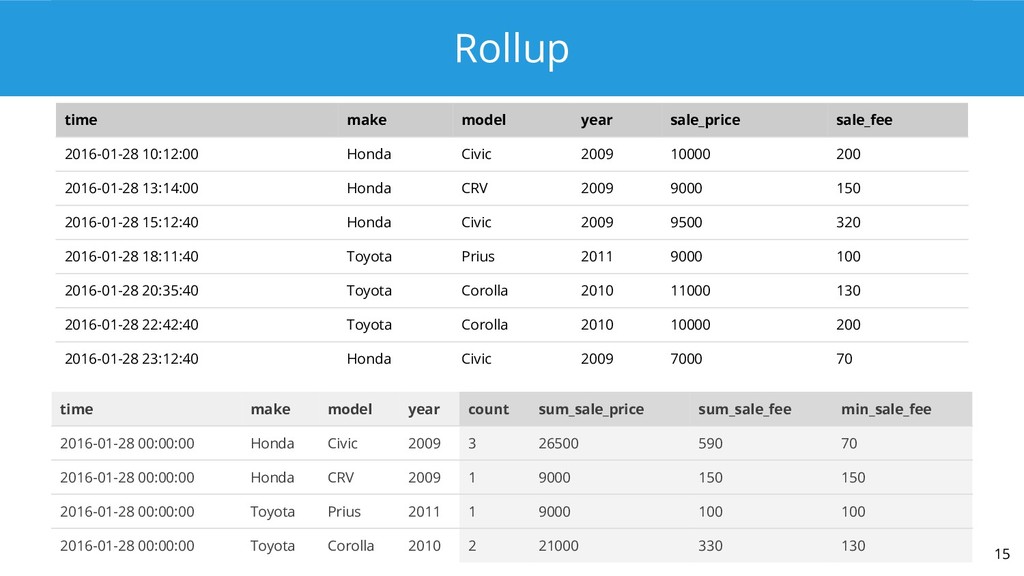
2. The virtue of foresight: thinking ahead and storing rollups of your data saves work at query time.
3. The virtue of flexibility: sketches and approximate algorithms can get you results fast, cheap, and 98% right.
![Gian Merlino [email protected] Three weird tips for high performance analytics](https://files.speakerdeck.com/presentations/1b53ecb7fd584efc8d5a7c4a8ea1fd25/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Indexing 11 Query • Justin Bieber OR Ke$ha → [111111]](https://files.speakerdeck.com/presentations/1b53ecb7fd584efc8d5a7c4a8ea1fd25/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}