Decisions • Sub Second aggregate queries • Real time analytics dashboard • Live queries for uniques • Instant exploratory analytics Technology powering the Data Platform Performance & Scale Considerations Opportunity for new Apps Monitoring Provisioning & deployment Future Plan Demo Biswajit Das Data Team @biswajit @branch.io Muwon Lum Infra Team @muwon @branch.io
Lack of instant access to aggregate data • Gathering unique impressions time consuming • No single pane of glass to view all data • Ad Hoc query requires pre-aggregation Instant access to information at scale was a problem
possible user queries. • Range scans on event data. • Pre-computing all permutations of all ad-hoc queries can lead to a result sets that grow exponentially with the number of columns of a data sets and can require hours of pre-processing time.
• Several hundred terabytes raw data indexed . • Typical complex datasource with 30 dimension and 2 metrics • Real time indexer with ~30k events per second to peak 50k • Hourly bucketed data to support different timezones • Sustained 2B + events day • Thousands of queries per second for online dashboard applications • Serving 11 million query every day
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
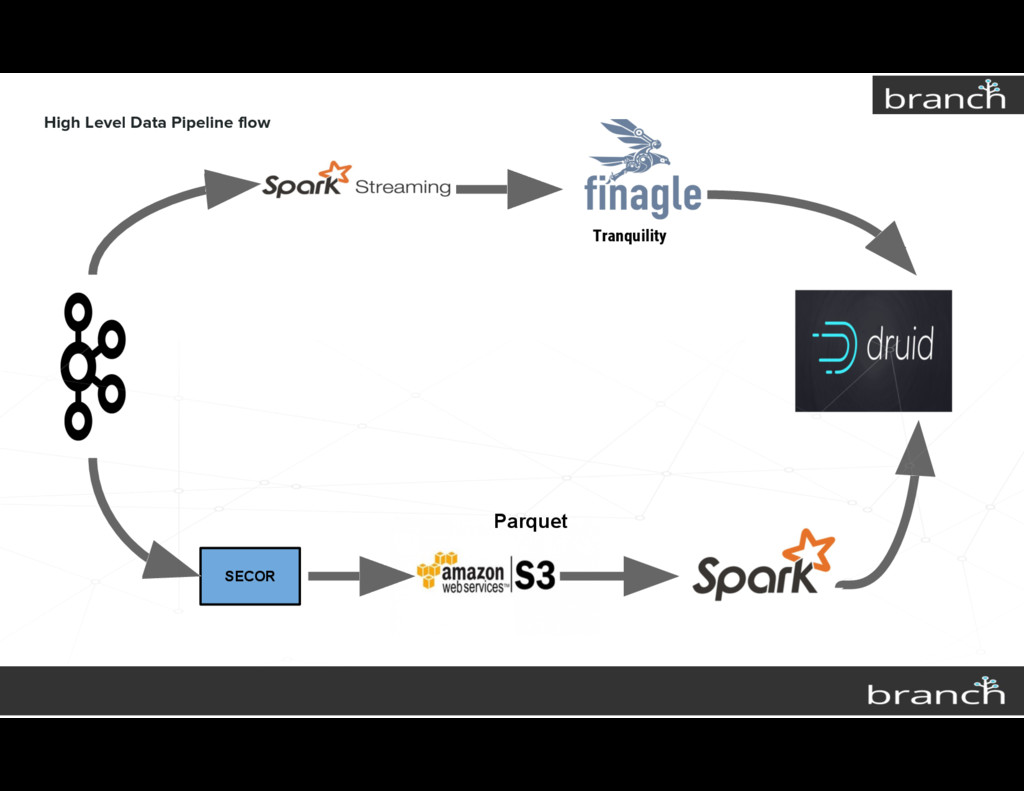{kind=link}
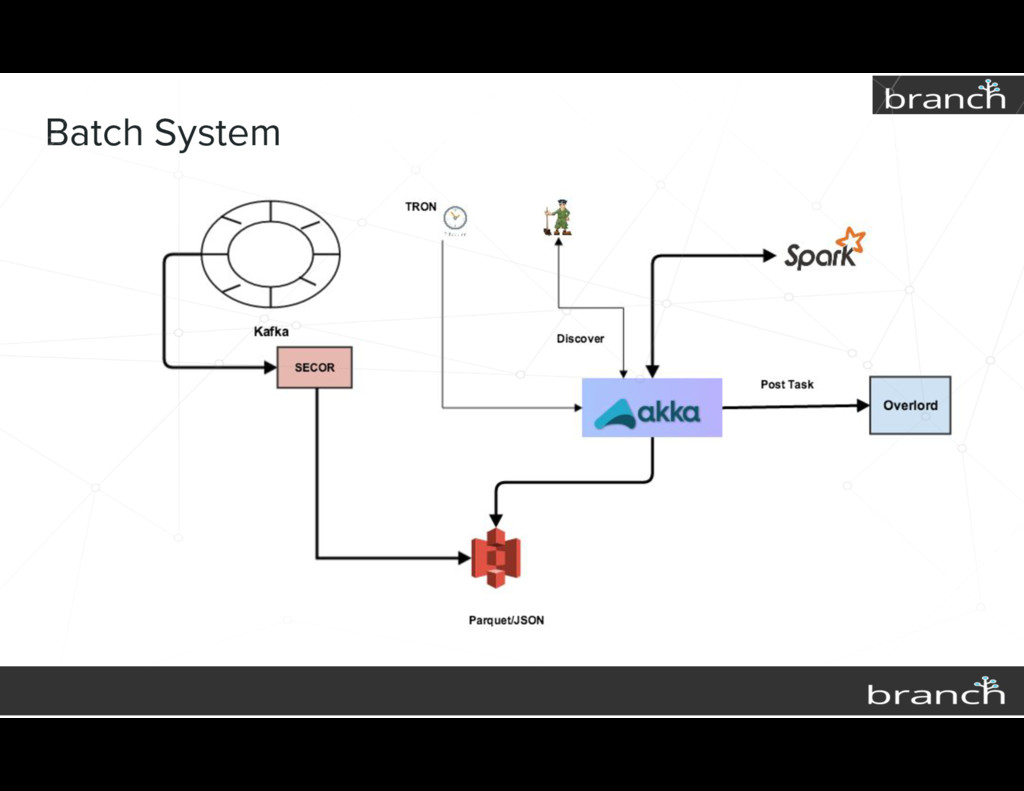{kind=link}
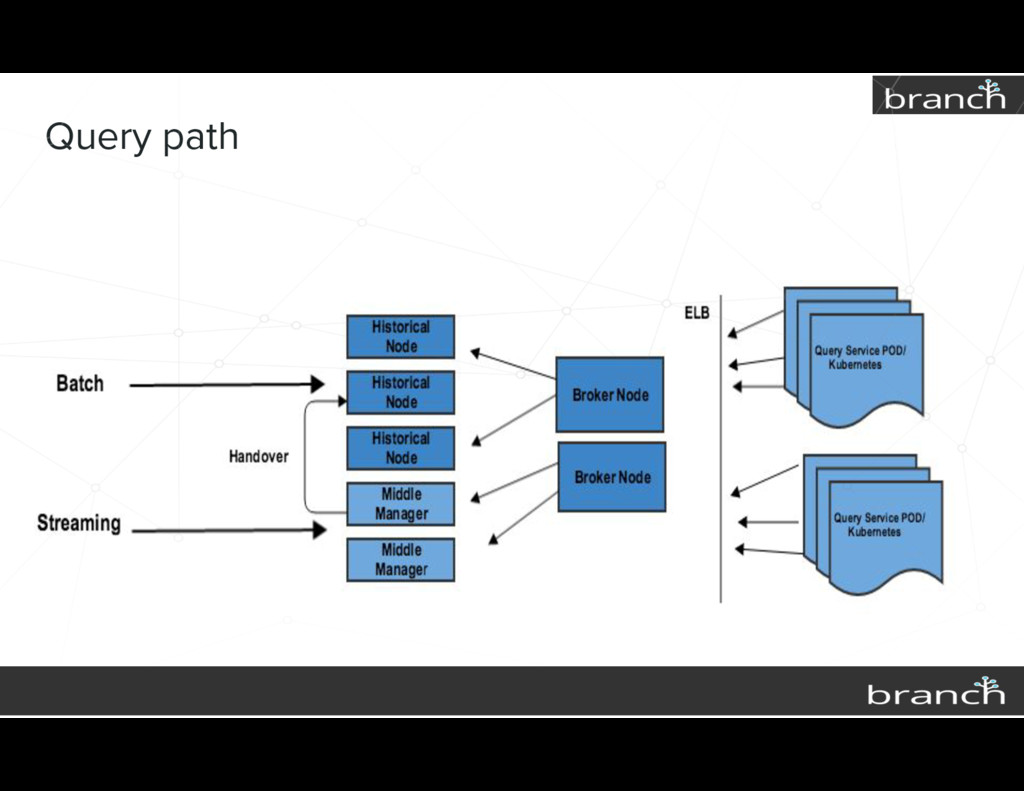{kind=link}
{kind=link}
{kind=link}
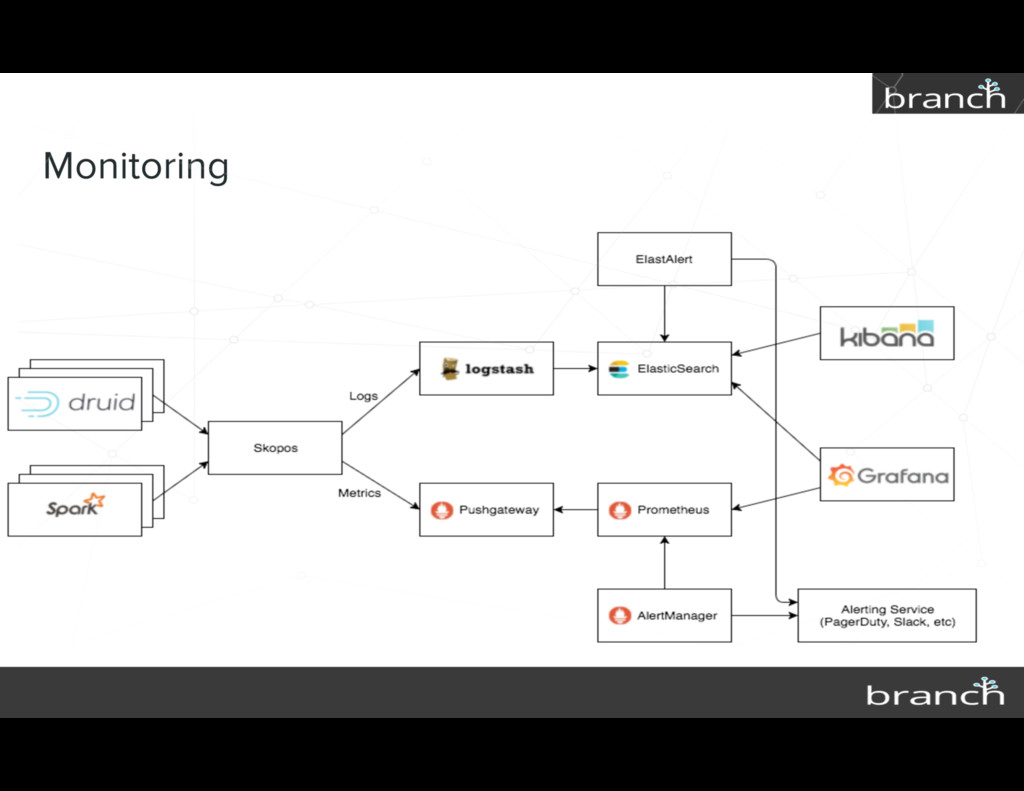{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}