The maturation and development of open source technologies has made it easier than ever for companies to derive insights from vast quantities of data. In this talk, we will cover how data analytic stacks have evolved from data warehouses, to data lakes, and to more modern stream-oriented analytic stacks. We will also discuss building such a stack using Apache Kafka and Apache Druid.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
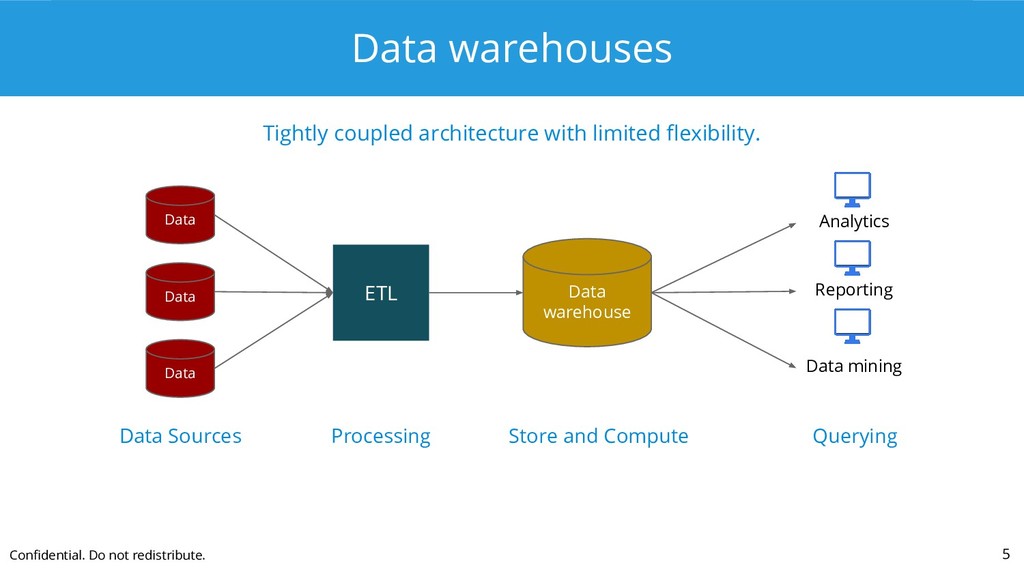{kind=link}
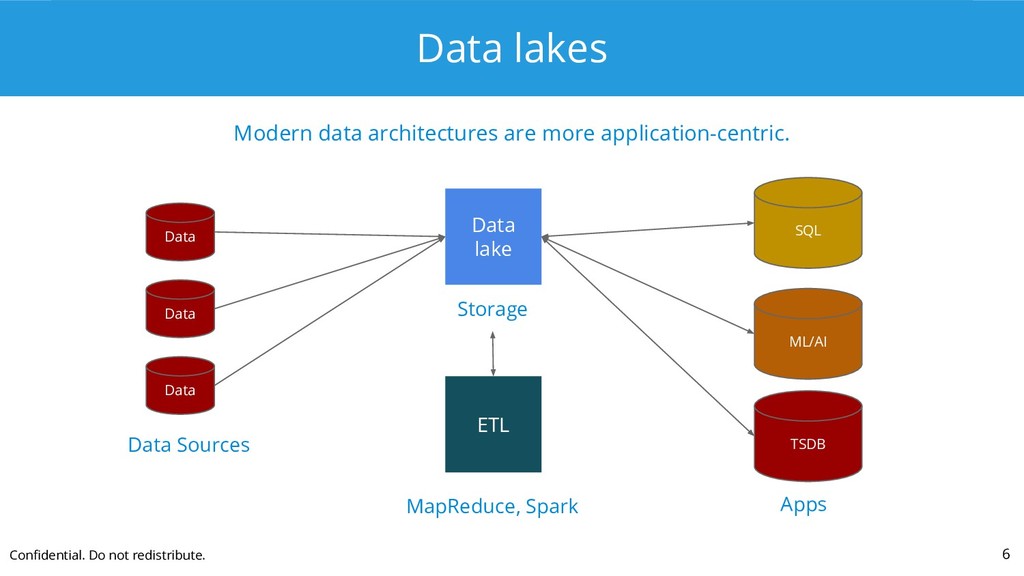{kind=link}
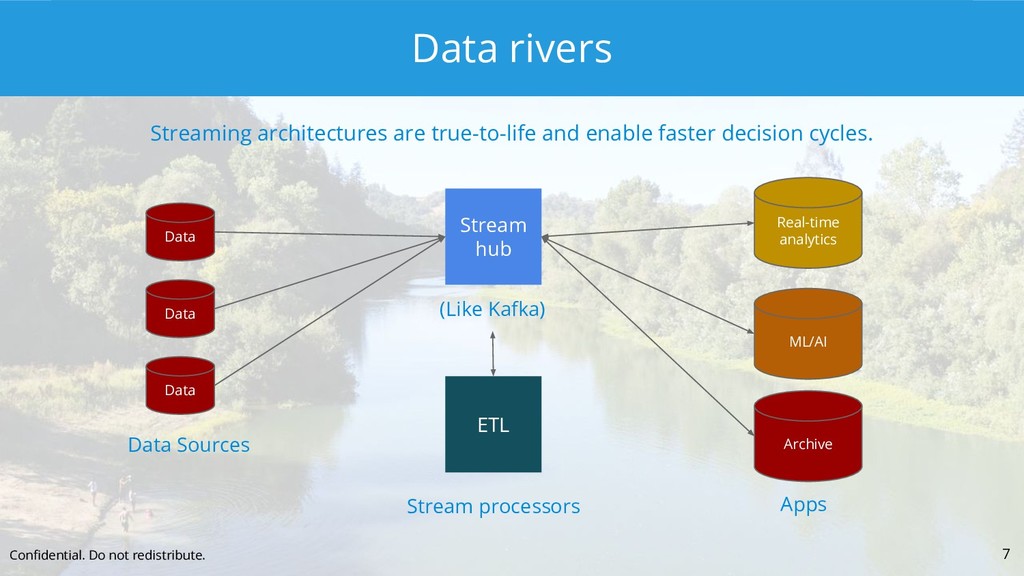{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}