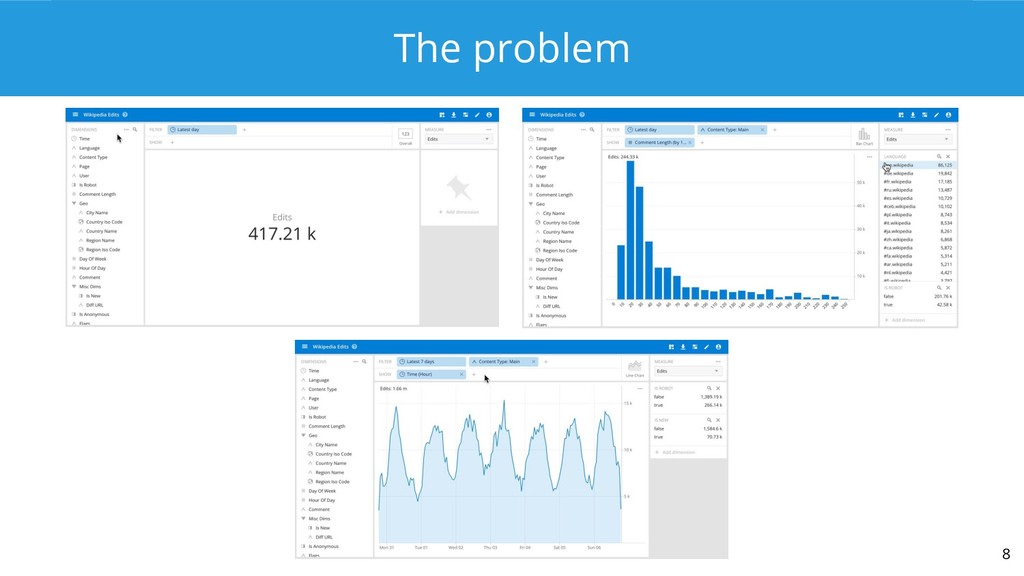
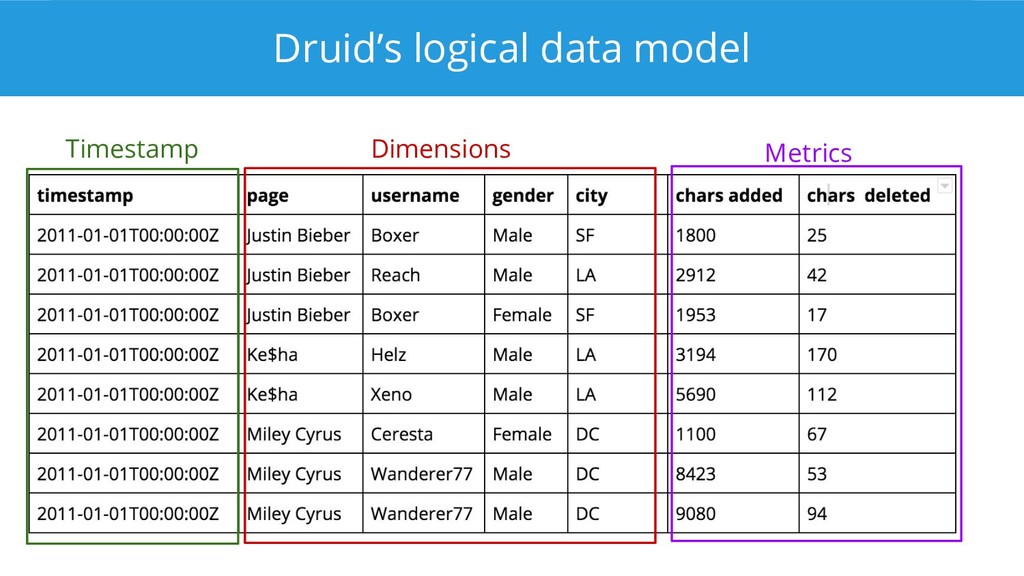
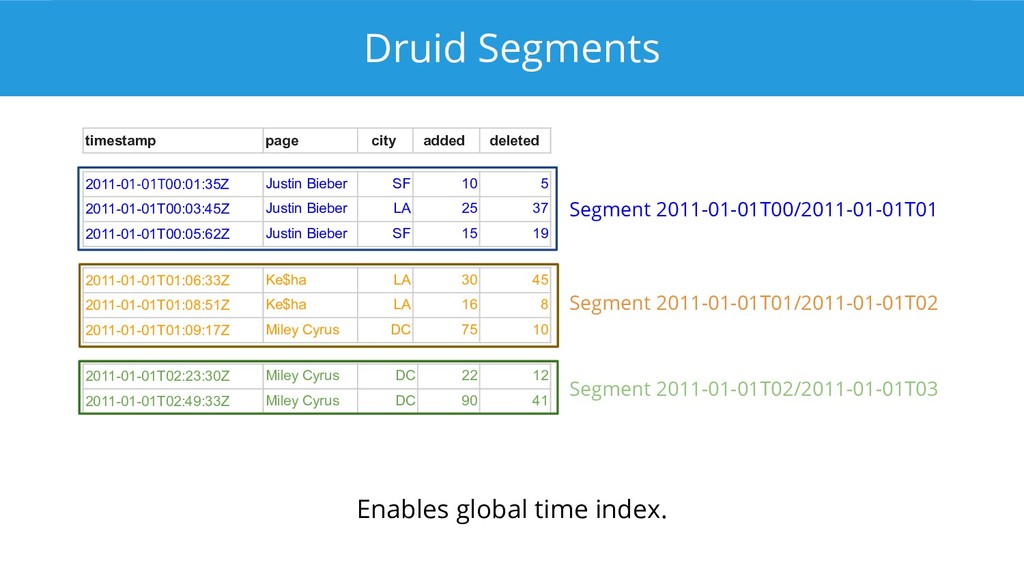
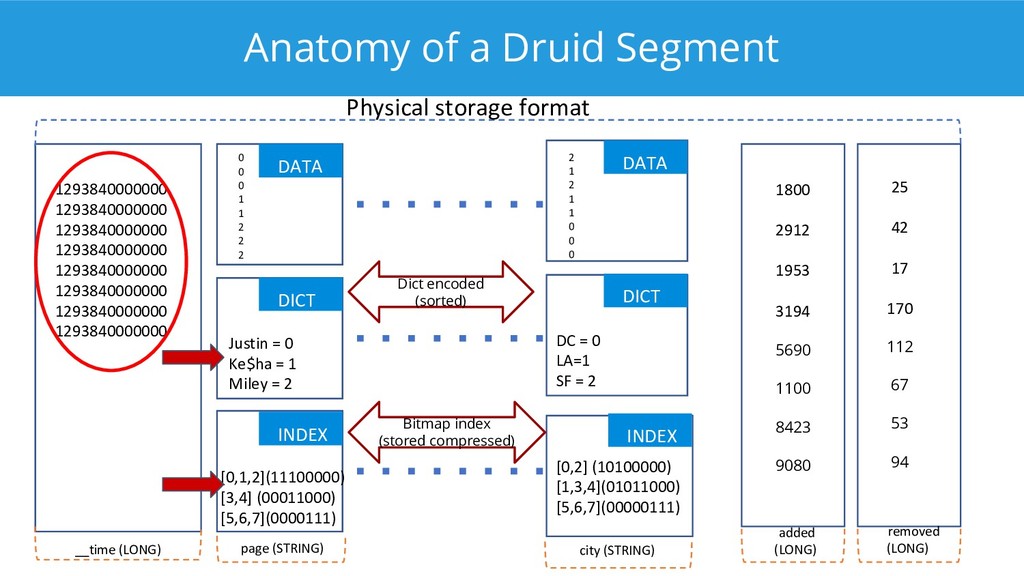
Apache Druid is a modern analytical database that implements a memory-mappable storage format, indexes, compression, late tuple materialization, and a query engine that can operate directly on compressed data. There is a patch out to add vectorized processing as well, which we can expect to see show up in a future release. This talk goes into detail on how Druid's query processing layer works and how each component contributes to achieving top performance for analytical queries.
![Inside Apache Druid Designed for Performance Gian Merlino [email protected]](https://files.speakerdeck.com/presentations/b85fd42f5e994d73893fa468932cbc63/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
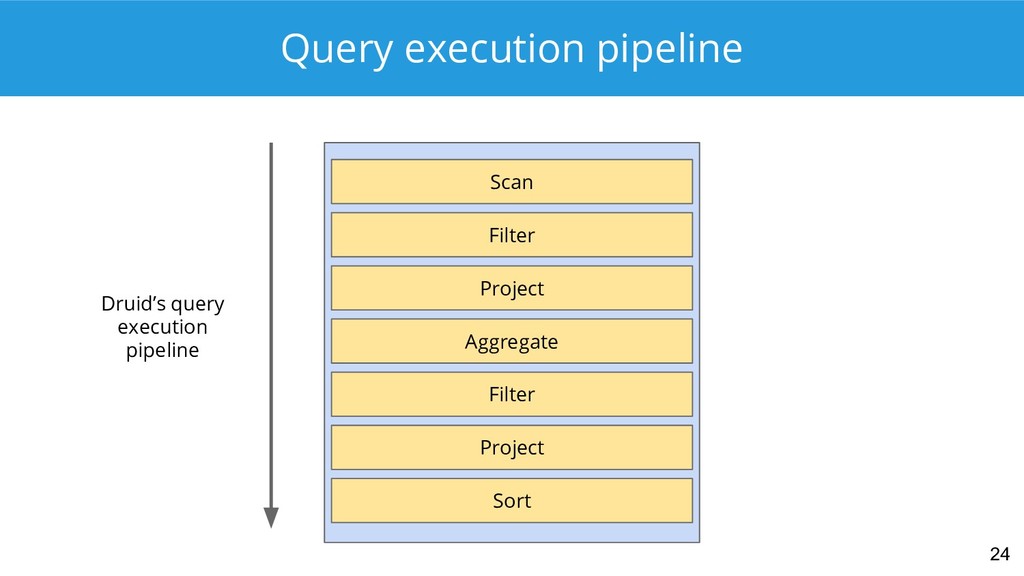{kind=link}
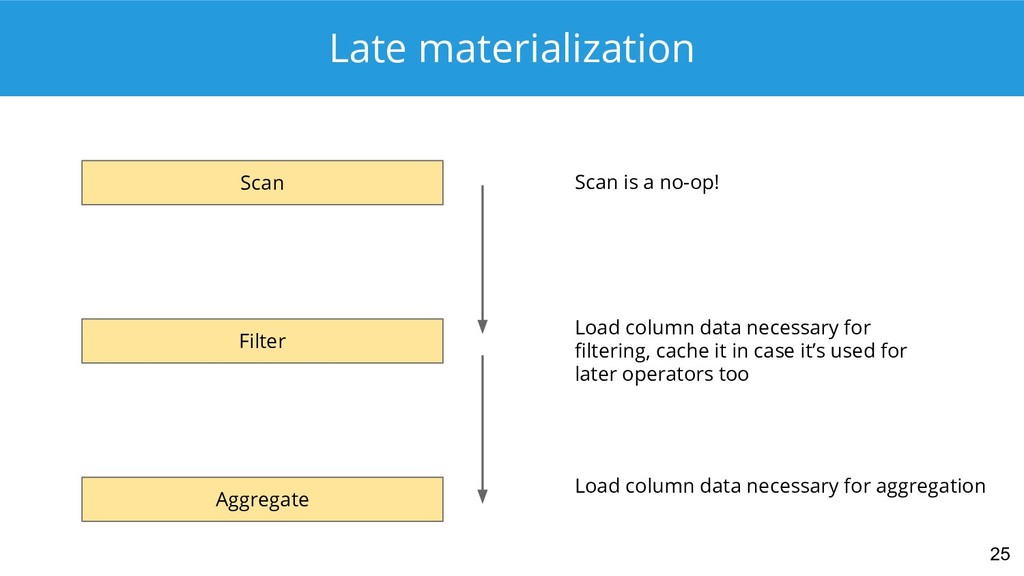{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
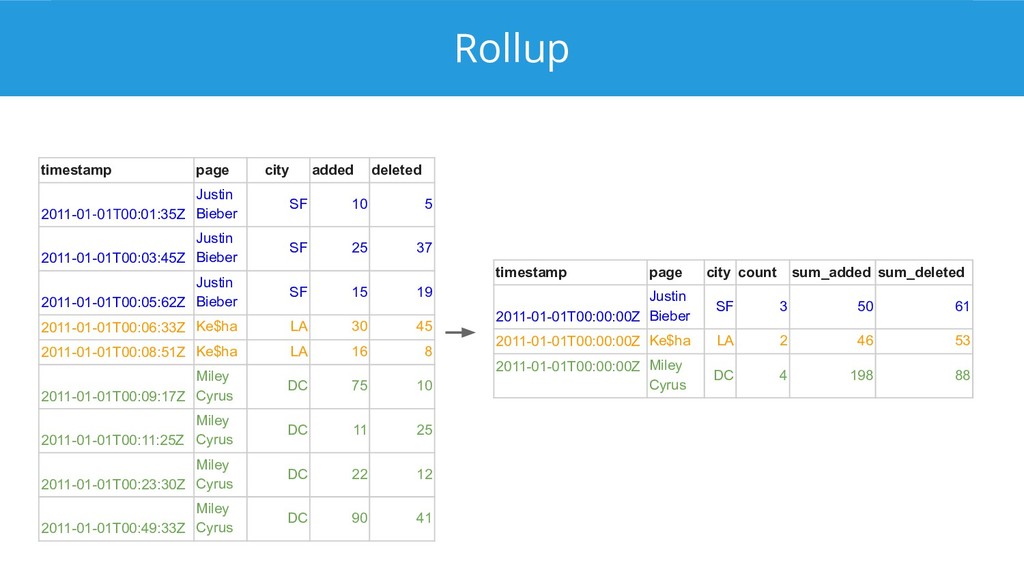{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}