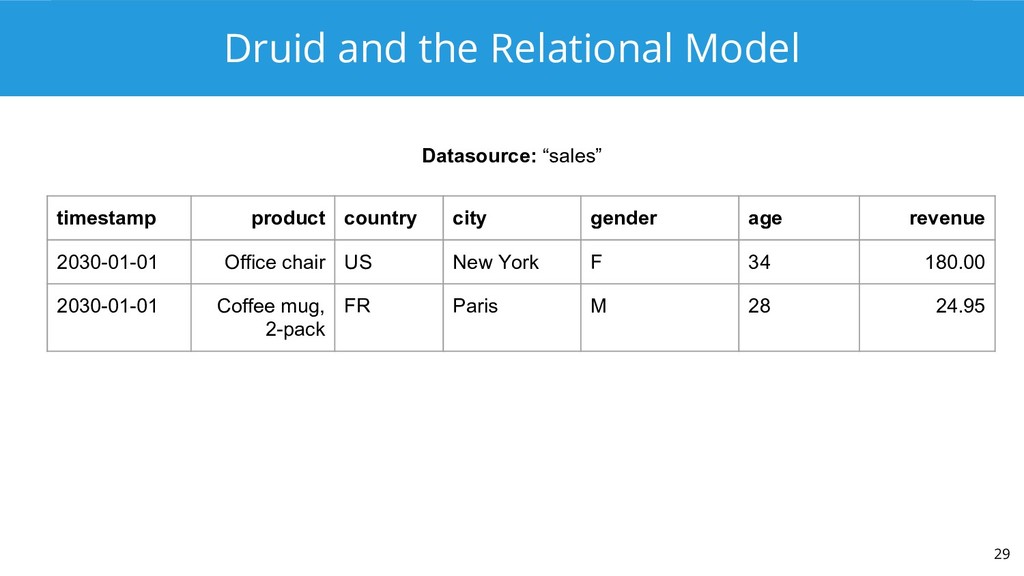
Druid is an analytics-focused, distributed, scale-out data store. Existing Druid clusters have scaled to petabytes of data and trillions of events, ingesting millions of events every second. Up until version 0.10, Druid could only be queried in a JSON-based language that many users found unfamiliar.
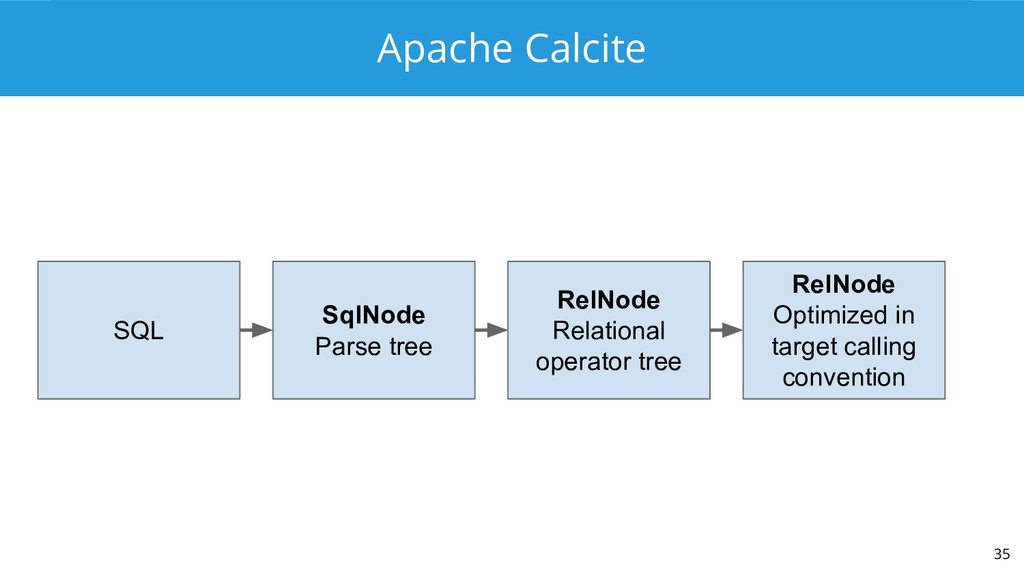
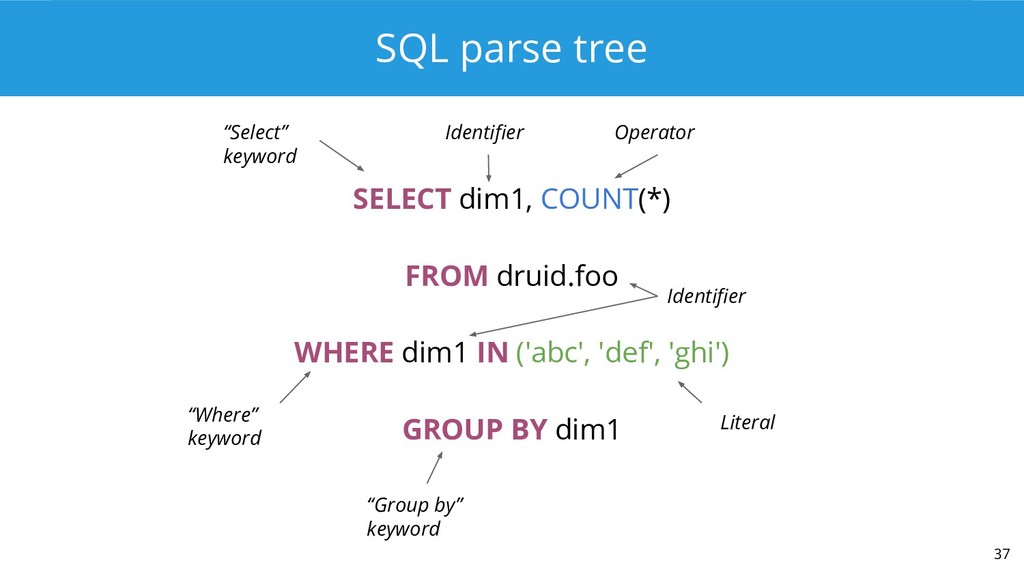
Enter Apache Calcite. It includes an industry-standard SQL parser, validator, and JDBC driver, as well as a cost-based relational optimizer. Calcite bills itself as “the foundation for your next high-performance database” and is used by Hive, Drill, and a variety of other projects. Druid uses Calcite to power Druid SQL, a standards-based query API that vaults Druid out of the NoSQL world and into the SQL world.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
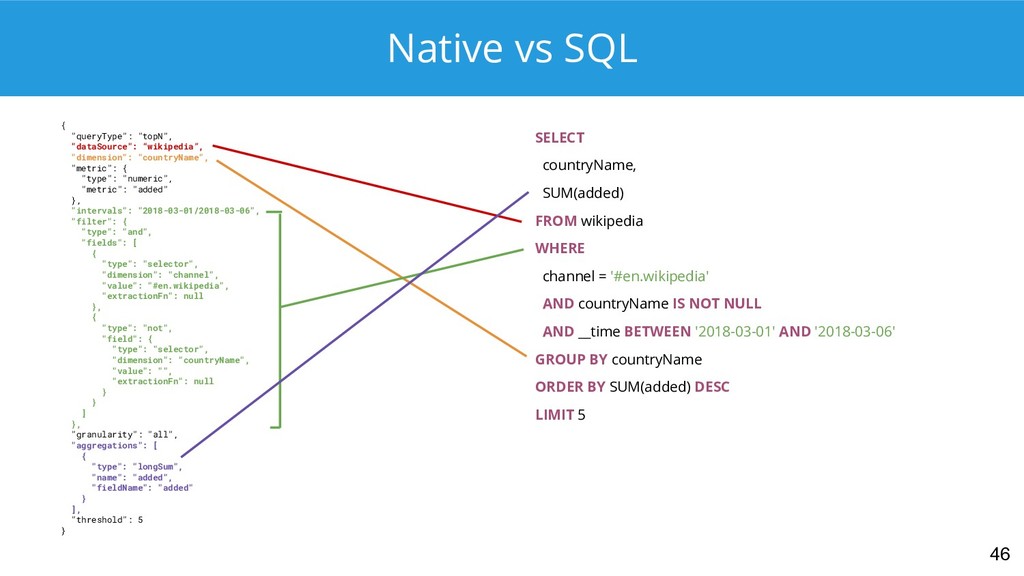{kind=link}
{kind=link}
{kind=link}
{kind=link}
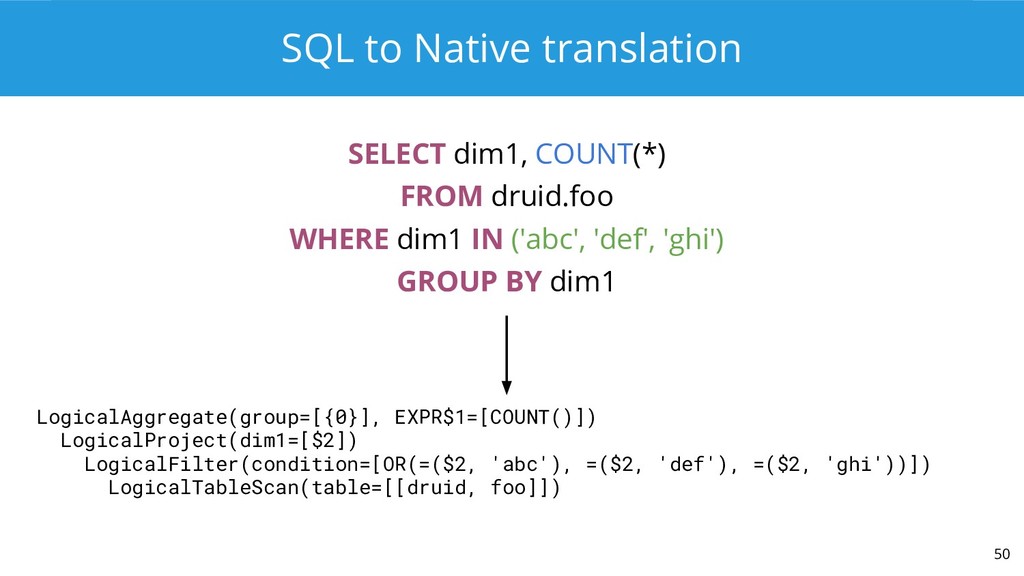{kind=link}
![SQL to Native translation 51 PartialDruidQuery Scan(table=[[druid, foo]]) Filter(condition=[OR(=($2, 'abc'),](https://files.speakerdeck.com/presentations/155659a837b046bba229af08daec5a13/slide_50.jpg){kind=link}
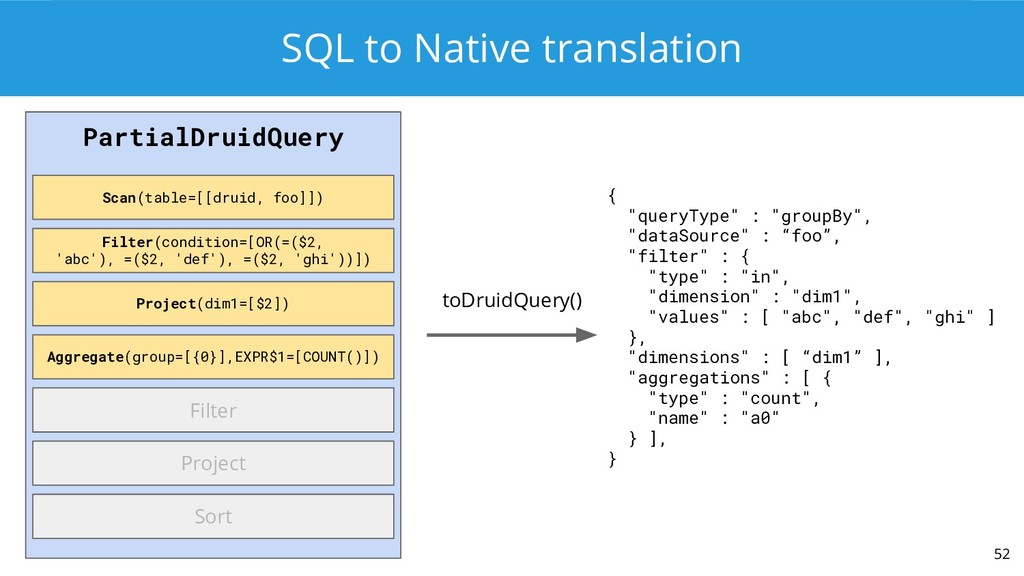{kind=link}
{kind=link}
{kind=link}
{kind=link}
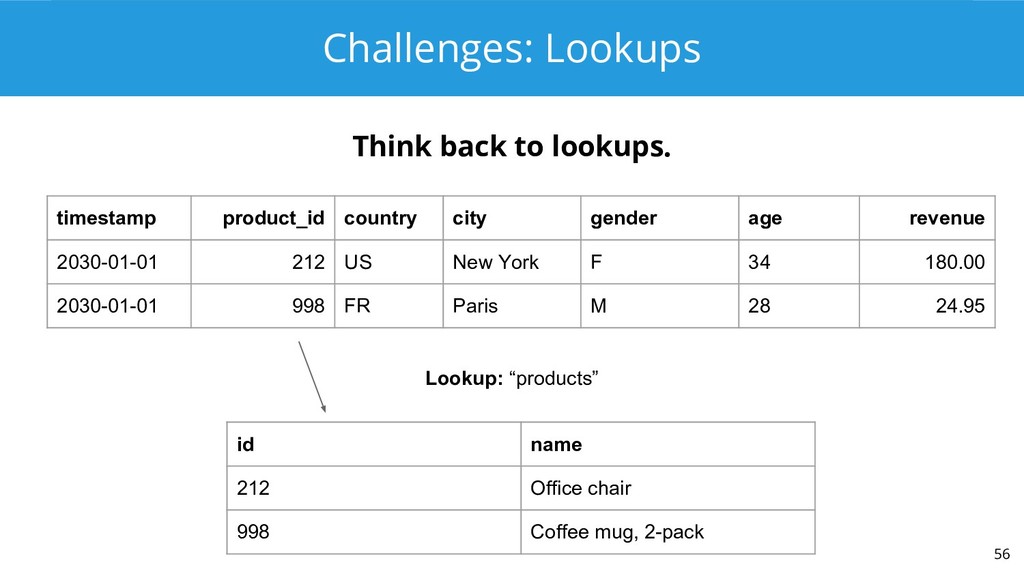{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}