Druid is an emerging standard in the data infrastructure world, designed for high-performance slice-and-dice analytics (“OLAP”-style) on large data sets. This talk is for you if you’re interested in learning more about pushing Druid’s analytical performance to the limit. Perhaps you’re already running Druid and are looking to speed up your deployment, or perhaps you aren’t familiar with Druid and are interested in learning the basics. Some of the tips in this talk are Druid-specific, but many of them will apply to any operational analytics technology stack.
The most important contributor to a fast analytical setup is getting the data model right. The talk will center around various choices you can make to prepare your data to get best possible query performance.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
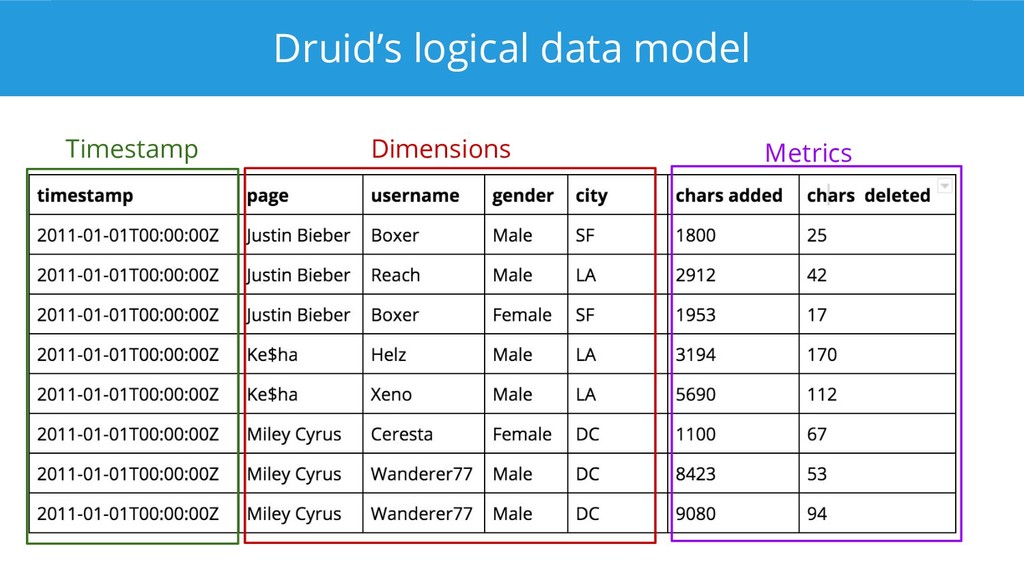{kind=link}
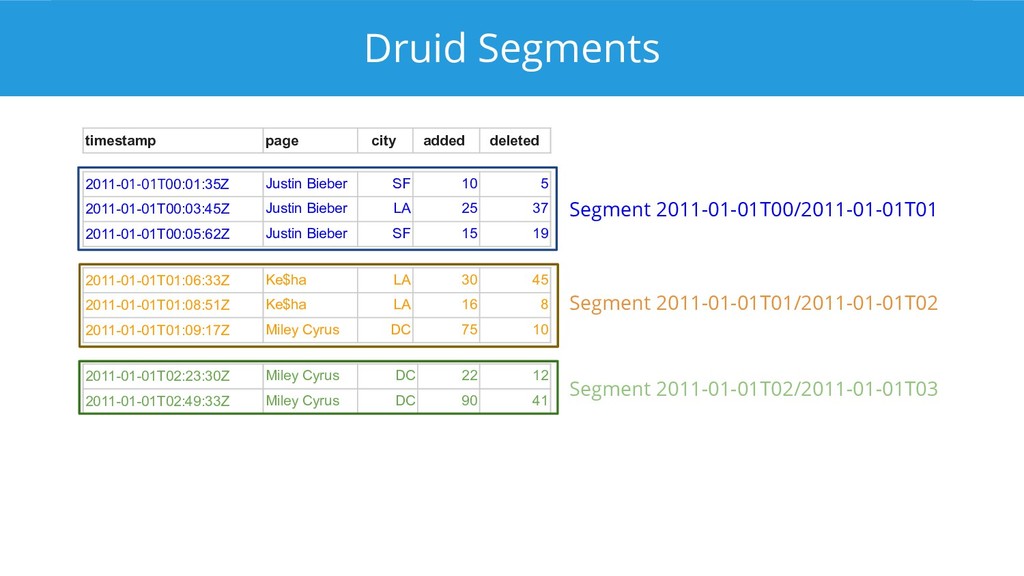{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}