Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Database Integration to Improve Accessibility t...
Search
Tazro Inutano Ohta
July 04, 2014
Science
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Database Integration to Improve Accessibility to Public High-throughput Sequencing Data
A Presentation at National Institute of Genetics, Japan Retreat 2014
Tazro Inutano Ohta
July 04, 2014
More Decks by Tazro Inutano Ohta
See All by Tazro Inutano Ohta
Yevis: System to support building a workflow registry with automated quality control
inutano
0
160
Standardization of biological sample information database
inutano
0
110
Describe data analysis workflow with workflow languages
inutano
5
6.2k
Container virtualization technologies and workflow languages improve portability and reproducibility of data analysis environment
inutano
3
380
次世代シーケンサーによるメタゲノム解析:桜の花びらに付着した環境DNAを解析する
inutano
0
130
Workflows that run everywhere and where to run them
inutano
0
200
The Sequence Read Archive search system to make use of public high-throughput sequencing data
inutano
0
330
Improve portability of bioinformatics software across HPC and cloud infrastructures
inutano
1
150
Container, Cloud, and HPC
inutano
0
200
Other Decks in Science
See All in Science
Wet Active Matter
rajeshrinet
0
120
Snowflake HCLS Meet Upヘルスケアユーザー会紹介
ktatsuya
0
100
データベース06: SQL (3/3) 副問い合わせ
trycycle
PRO
1
1k
AIを用いた PID制御で部屋 の温度制御をしてみた
nearme_tech
PRO
0
180
大黒市で発生した大規模インシデント の ポストモーテムから読み解く、 記憶媒体消去の大切さ
shucho0103
0
210
東北地方における過去20年間の降水量の変化
naokimuroki
1
340
ハミルトン・ヤコビ方程式の解の性質と物理的意味
enakai00
0
810
Conwayの法則を"ちゃんと"使うために — 原典でConwayは何を言っていたのか
bonotake
9
5.6k
Endel Tulvingとエピソード記憶
rmaruy
0
150
AkarengaLT vol.40
hashimoto_kei
0
110
生成AIと司法書士の未来.pdf
tagtag
PRO
0
140
Non-Gaussian, nonlinear causal discovery with hidden variables and application
sshimizu2006
0
160
Featured
See All Featured
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
240
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Making Projects Easy
brettharned
120
6.7k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Why Our Code Smells
bkeepers
PRO
340
58k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Transcript
Database Integration to Improve Accessibility to High-Throughput Seq Data
TAZRO OHTA @inutano
None
What do you imagine with a term “Database”?
None
None
None
Knowledge Scientific data Experimental data
Knowledge base Database Raw Data repository
Knowledge base Database Raw Data repository
What kind of data? Next-generation is already out there…
We all need Raw data repo for NGS
We’ve already seen WHY WE NEED
None
Reproducibility is what makes science fair.
2 things required for data repository is…
1: Reliability Data should be archived correctly, with explicit metadata
2: Accessibility Data should be able to be accessed by anyone, without special trick
1: Reliability needs curation Data should be archived correctly, with
explicit metadata 2: Accessibility needs good interface Data should be able to be accessed by anyone, without special trick
1: Reliability needs curation Data should be archived correctly, with
explicit metadata 2: Accessibility needs good interface Data should be able to be accessed by anyone, without special trick
1: Reliability needs curation Data should be archived correctly, with
explicit metadata 2: Accessibility needs good interface Data should be able to be accessed by anyone, without special trick
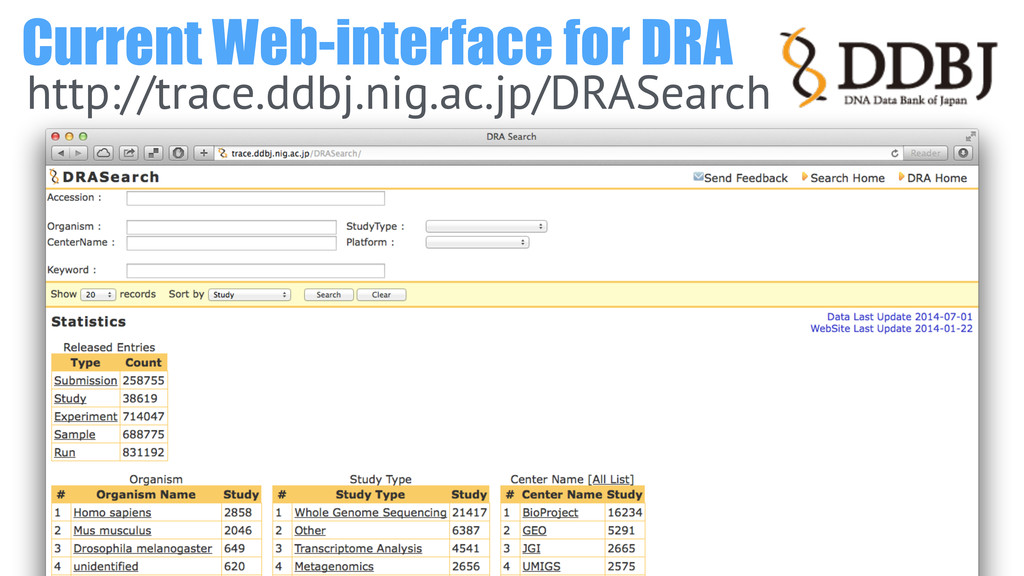
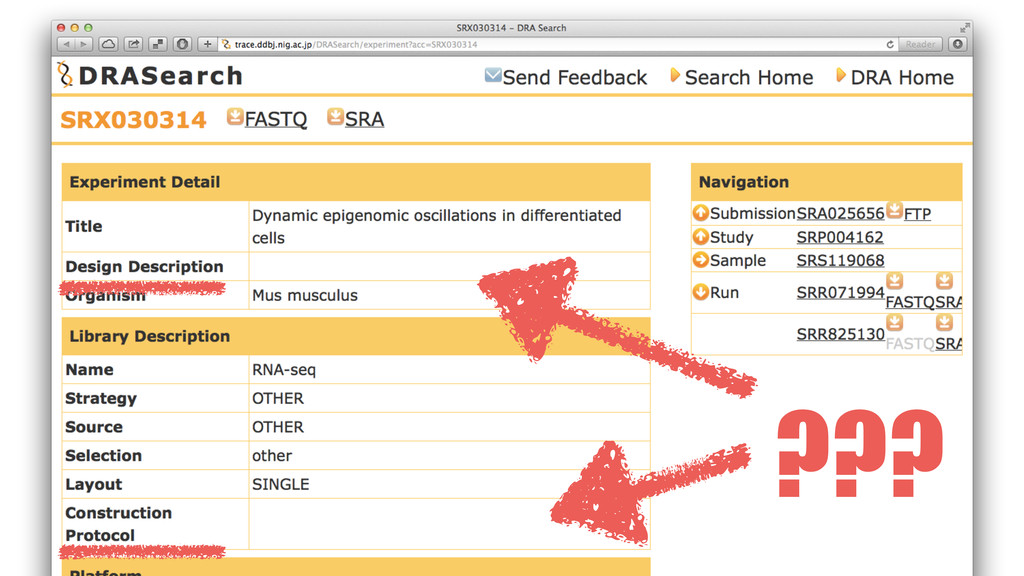
Current Web-interface for DRA http://trace.ddbj.nig.ac.jp/DRASearch
Good: Simple, Fast, and no bugs (!) Challenge: Lack of
metadata caused “NOT FOUND”
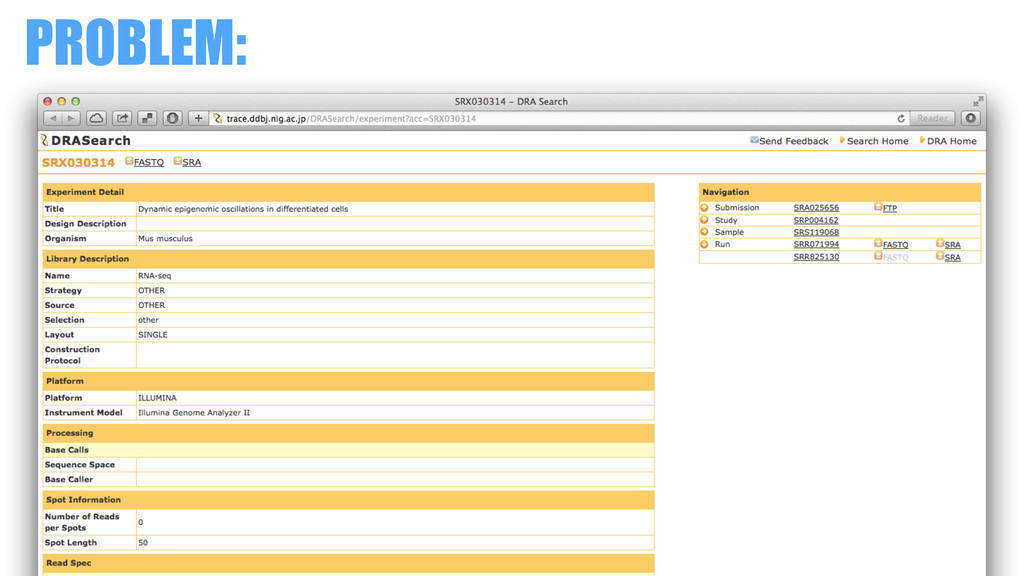
PROBLEM:
???
DRASearch can NOT find Data without metadata …but they definitely
exist in the repo.
Too many to ask submitters; then we implemented a system
to make metadata rich enough
2 sources into DRA DDBJ Read Archive
Publications can have details of seq process, Seq Read Quality
can be a source of data quality. DDBJ Read Archive PubMed PMC Extracted Read Quality
And then: integration enables to implement Efficient Data Search
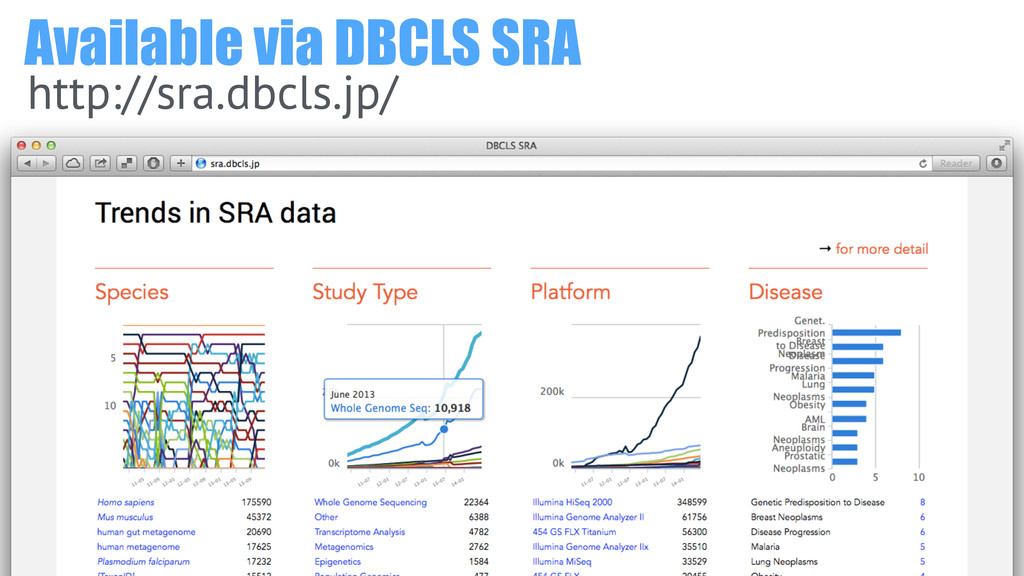
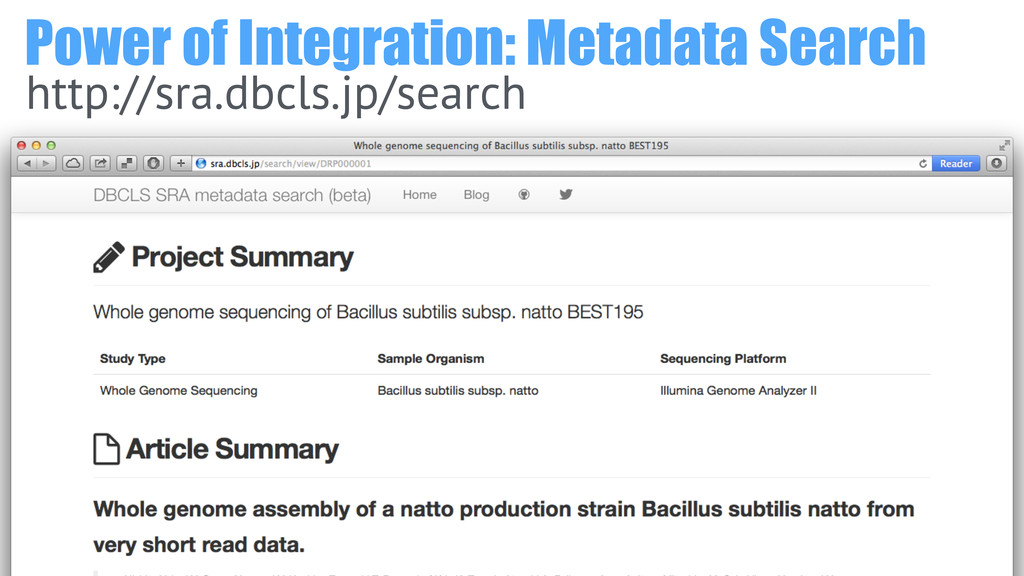
Available via DBCLS SRA http://sra.dbcls.jp/
Available via DBCLS SRA http://sra.dbcls.jp/
Available via DBCLS SRA http://sra.dbcls.jp/
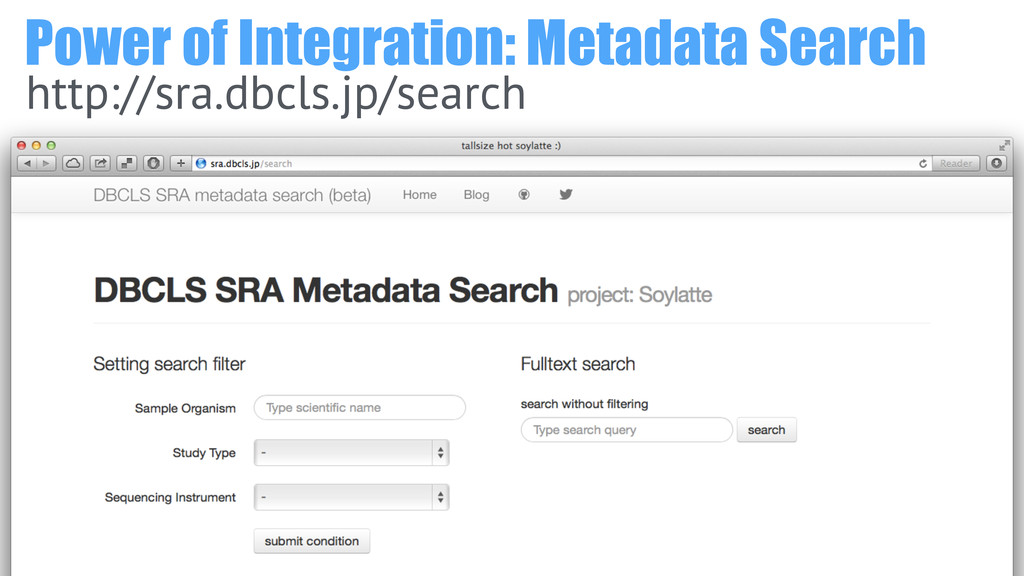
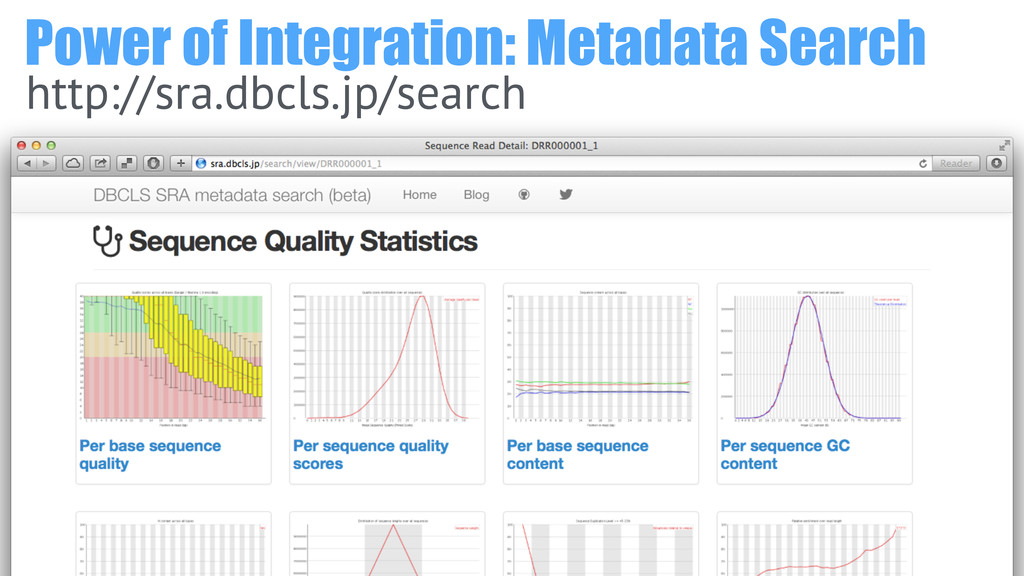
Power of Integration: Metadata Search http://sra.dbcls.jp/search
Power of Integration: Metadata Search http://sra.dbcls.jp/search
Power of Integration: Metadata Search http://sra.dbcls.jp/search
83% seq reads satisfied average quality over 30 0.03% of
seq reads fall into over 50% N content
1: Reliability from paper/data qual more description brings more proof.
2: Accessibility from text-search Search included publication brings flexibility.
2.20% of submitted projects has at least one publication 4429
/ 201558 PROBLEM:
NIH Data sharing Guideline http://www.niaid.nih.gov/LabsAndResources/resources/dmid/Pages/data.aspx
NIH Data sharing Guideline http://www.niaid.nih.gov/LabsAndResources/resources/dmid/Pages/data.aspx
What is Next-step to carry on?
1: Beyond Raw Data Archive is going to handle alignment
data. 2: Analysis Reproducibility Public repo for analysis pipeline is required.
1: Beyond Raw Data Archive is going to handle alignment
data. 2: Analysis Reproducibility Public repo for analysis pipeline is required.
Database is for Biologists not for developers.
Thank you!
[email protected]
http://speakerdeck.com/inutano
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! [email protected] http://speakerdeck.com/inutano](https://files.speakerdeck.com/presentations/f3da4e80e58a01319ec90ab05acaf620/slide_44.jpg){kind=link}