what a consensus is all about. Get everyone to agree about a resource / thing Make decisions through a formal process Delay and analyse to gain harmony or else retry Establish a shared opinion
what a consensus is all about. Get everyone to agree about a resource / thing Make decisions through a formal process Delay and analyse to gain harmony or else retry Establish a shared opinion The resulting consensus doesn't have to be unanimous. This person here is clearly unhappy but has consented to the majority
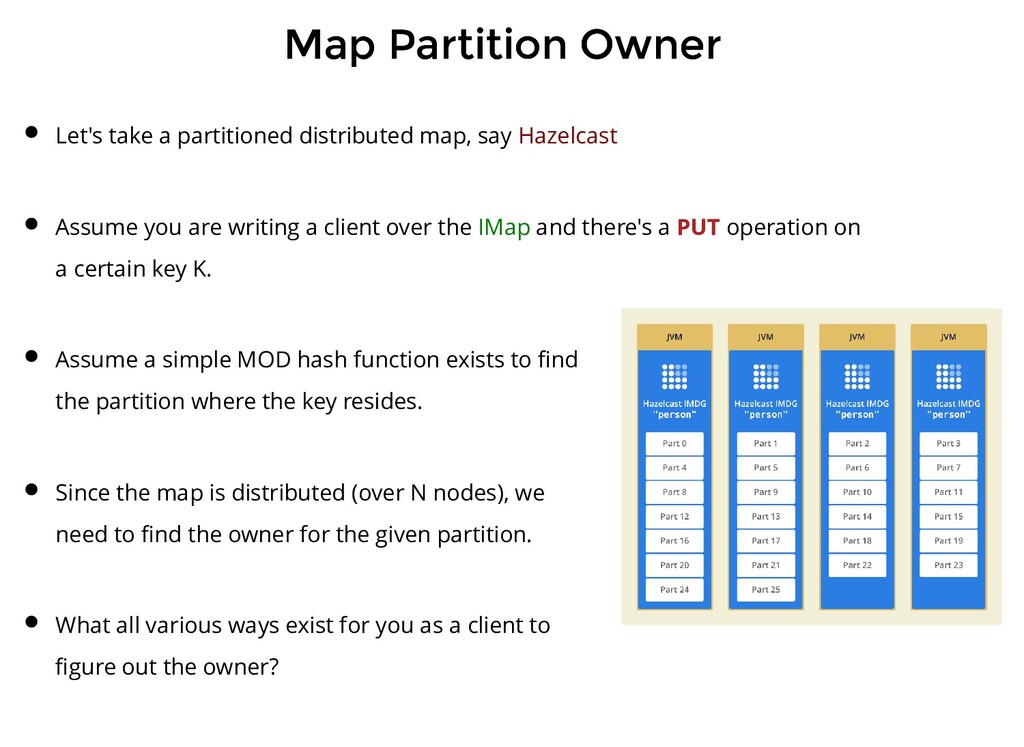
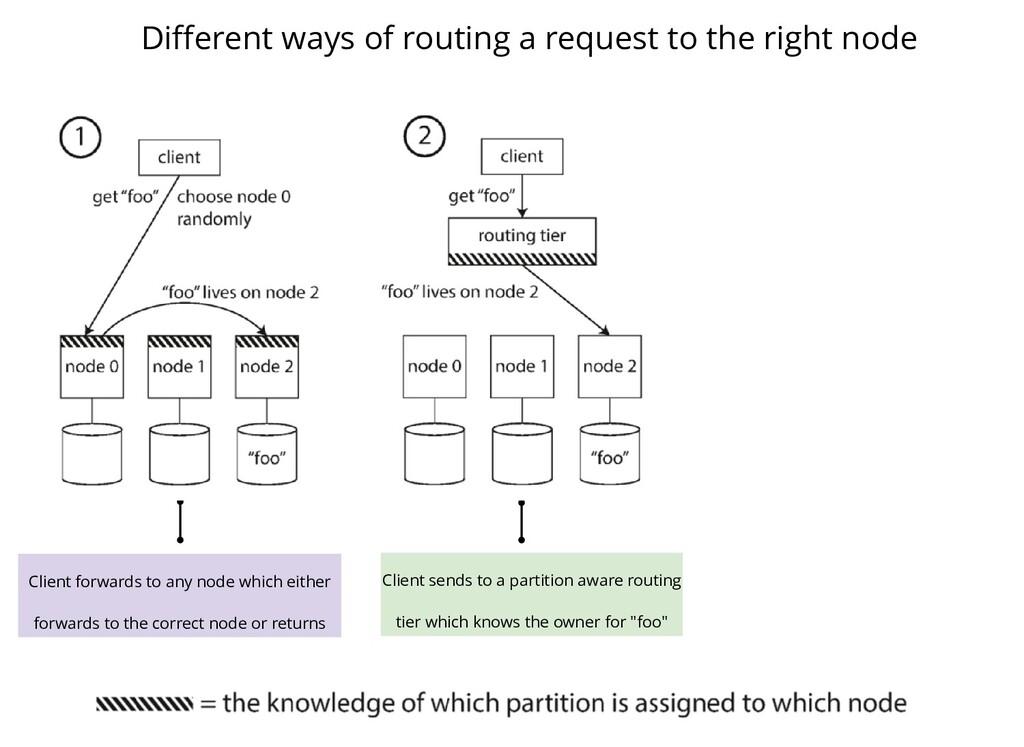
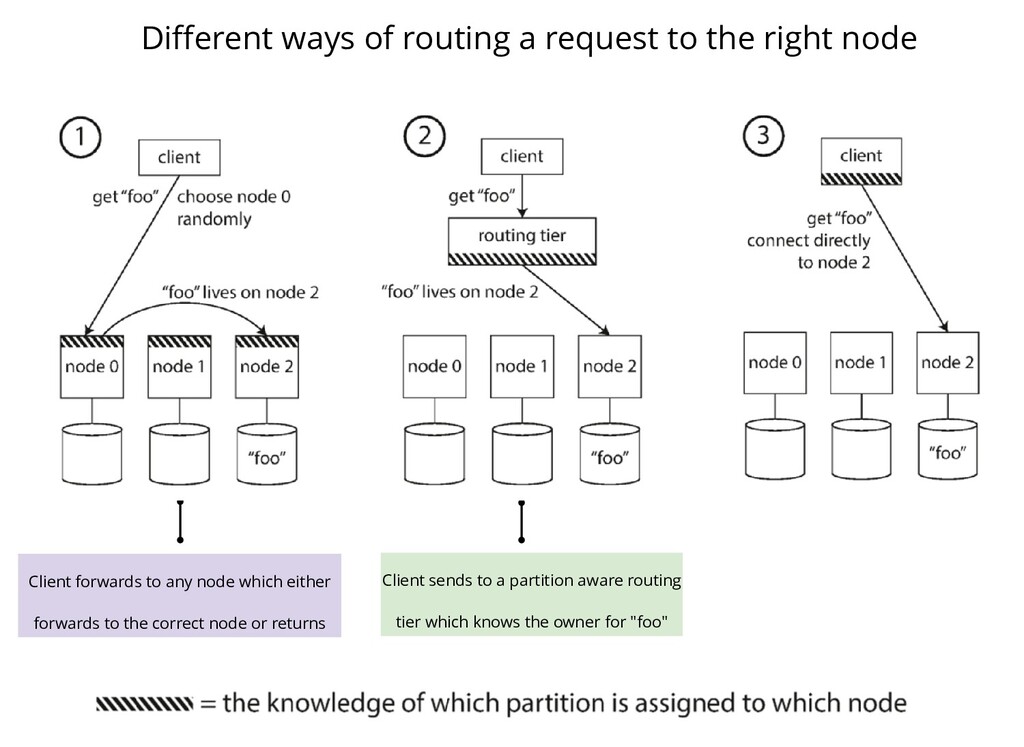
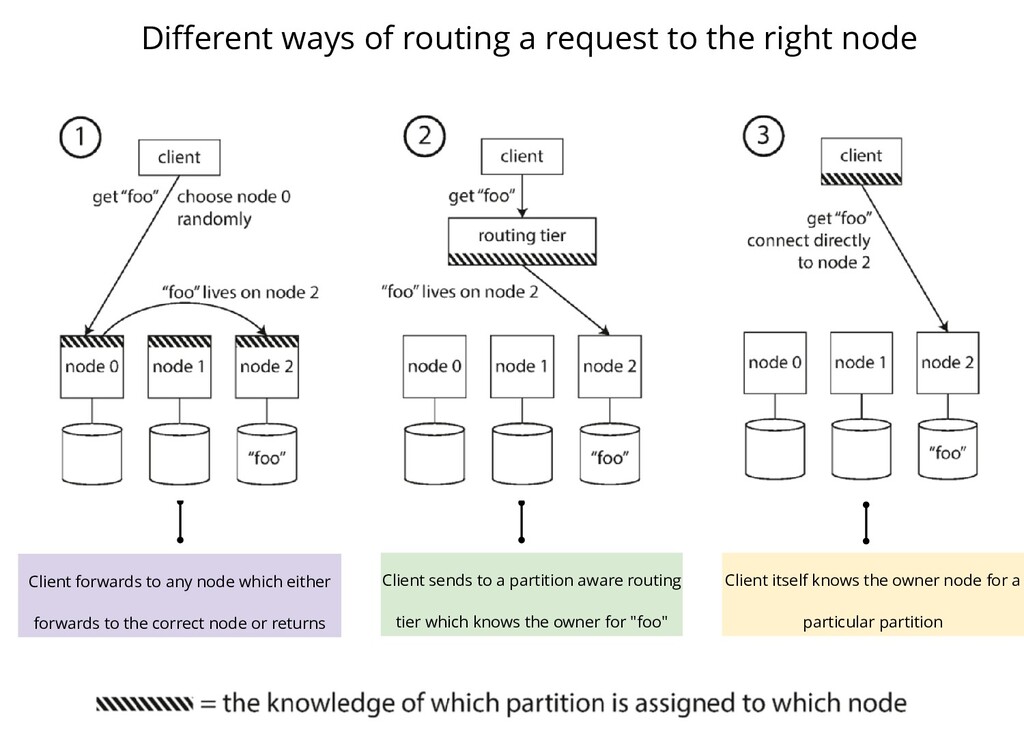
distributed map, say Hazelcast Assume you are writing a client over the IMap and there's a PUT operation on a certain key K. Assume a simple MOD hash function exists to find the partition where the key resides. Since the map is distributed (over N nodes), we need to find the owner for the given partition. What all various ways exist for you as a client to figure out the owner?
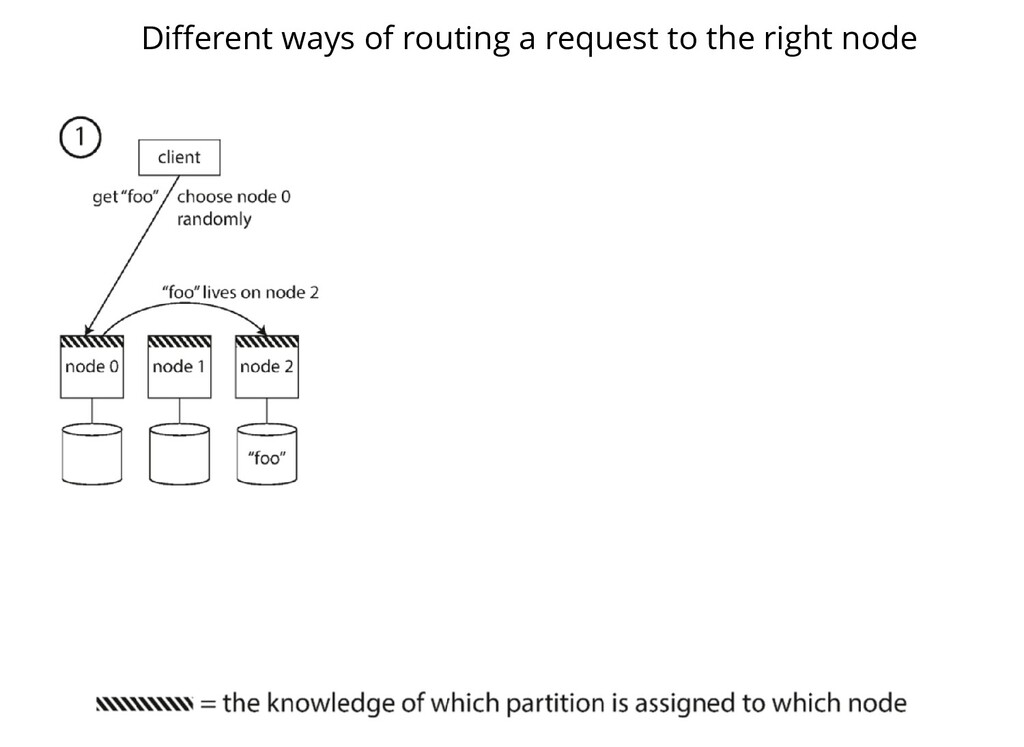
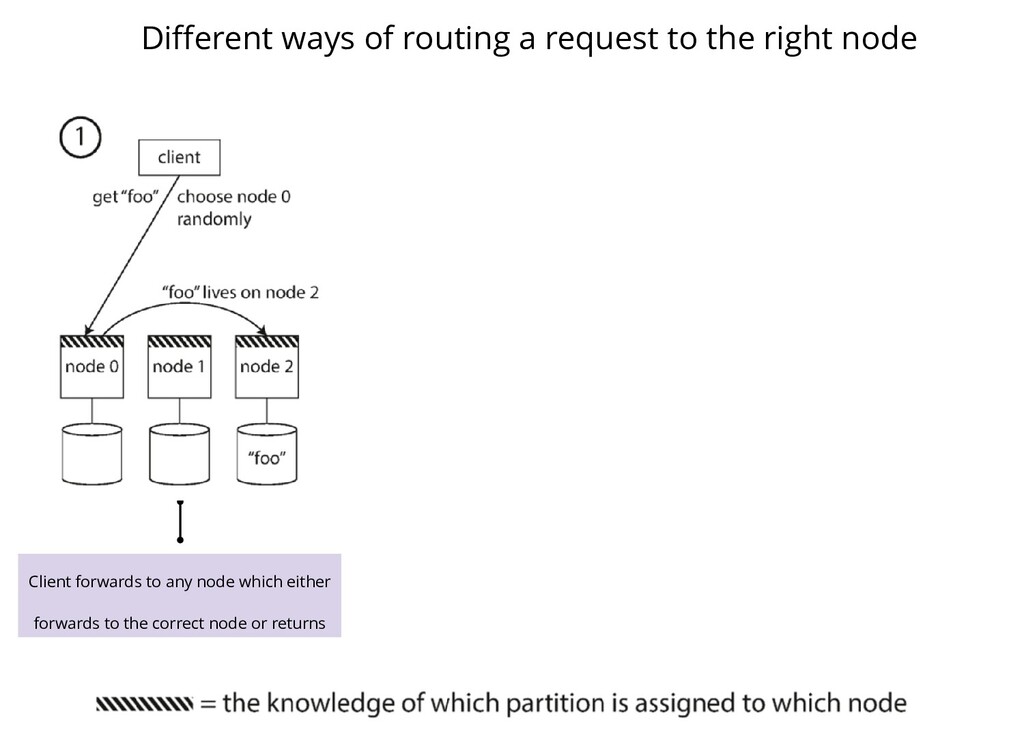
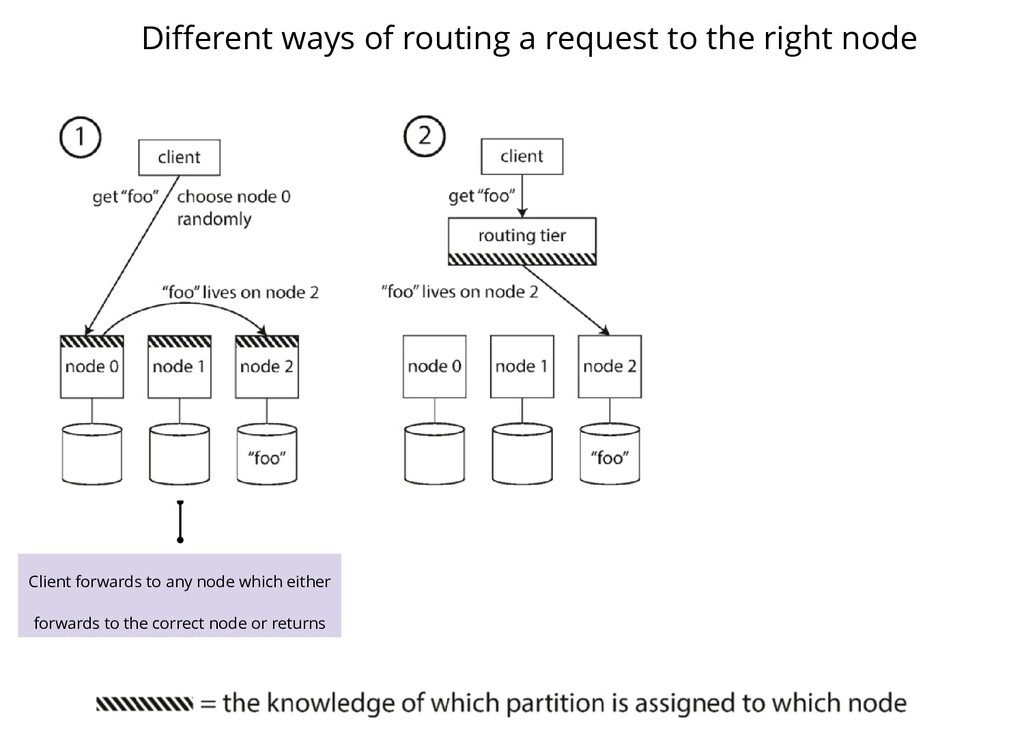
Client forwards to any node which either forwards to the correct node or returns Client sends to a partition aware routing tier which knows the owner for "foo"
Client forwards to any node which either forwards to the correct node or returns Client sends to a partition aware routing tier which knows the owner for "foo"
Client forwards to any node which either forwards to the correct node or returns Client sends to a partition aware routing tier which knows the owner for "foo" Client itself knows the owner node for a particular partition
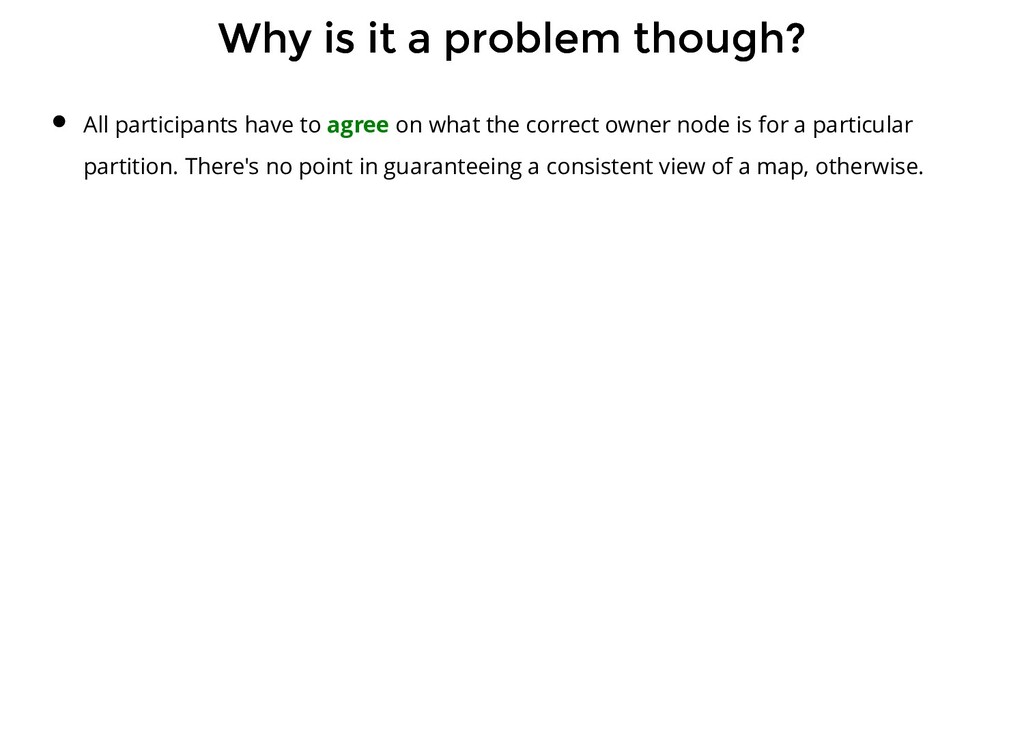
problem though? All participants have to agree on what the correct owner node is for a particular partition. There's no point in guaranteeing a consistent view of a map, otherwise.
problem though? All participants have to agree on what the correct owner node is for a particular partition. There's no point in guaranteeing a consistent view of a map, otherwise. Regardless of whether this information lies with the routing tier, nodes or the client, we need some sort of a coordination here.
problem though? All participants have to agree on what the correct owner node is for a particular partition. There's no point in guaranteeing a consistent view of a map, otherwise. Regardless of whether this information lies with the routing tier, nodes or the client, we need some sort of a coordination here. Distributed consensus is a hard problem. Easy to reason about but unfathomably hard to implement. There are a lot of edge cases to handle
problem though? All participants have to agree on what the correct owner node is for a particular partition. There's no point in guaranteeing a consistent view of a map, otherwise. Regardless of whether this information lies with the routing tier, nodes or the client, we need some sort of a coordination here. Distributed consensus is a hard problem. Easy to reason about but unfathomably hard to implement. There are a lot of edge cases to handle Many such distributed systems rely on an external service provider that gives strong coordination and consensus guarantees on the cluster metadata
problem though? All participants have to agree on what the correct owner node is for a particular partition. There's no point in guaranteeing a consistent view of a map, otherwise. Regardless of whether this information lies with the routing tier, nodes or the client, we need some sort of a coordination here. Distributed consensus is a hard problem. Easy to reason about but unfathomably hard to implement. There are a lot of edge cases to handle Many such distributed systems rely on an external service provider that gives strong coordination and consensus guarantees on the cluster metadata Our favourite system enters to help us here. Wait for it....
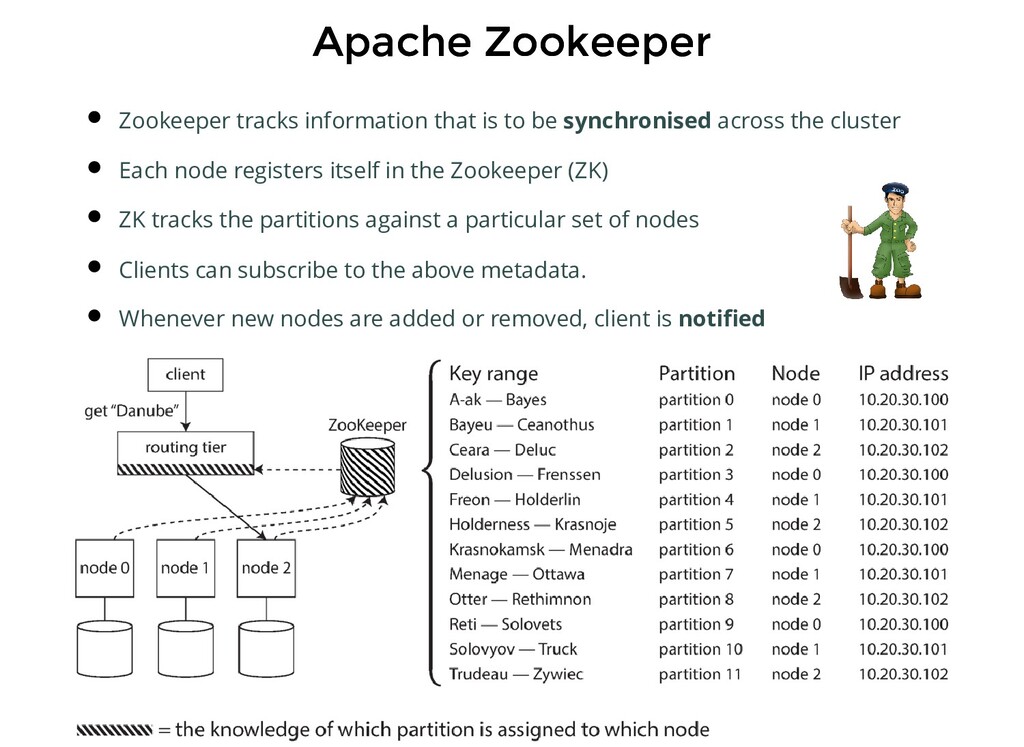
be synchronised across the cluster Each node registers itself in the Zookeeper (ZK) ZK tracks the partitions against a particular set of nodes Clients can subscribe to the above metadata. Whenever new nodes are added or removed, client is notified
is the key to solving at least the following problems in computer science: Total order broadcast Used in ZAB : Zookeeper Atomic Broadcast Atomic Commit (Databases) Fulfilling A and C in ACID properties
is the key to solving at least the following problems in computer science: Total order broadcast Used in ZAB : Zookeeper Atomic Broadcast Atomic Commit (Databases) Fulfilling A and C in ACID properties Terminating reliable broadcasts Sending messages to a list of processes, say in multiplayer gaming
is the key to solving at least the following problems in computer science: Total order broadcast Used in ZAB : Zookeeper Atomic Broadcast Atomic Commit (Databases) Fulfilling A and C in ACID properties Terminating reliable broadcasts Sending messages to a list of processes, say in multiplayer gaming Dynamic group membership Who is the master? Which workers are available? What task is assigned to the worker?
is the key to solving at least the following problems in computer science: Total order broadcast Used in ZAB : Zookeeper Atomic Broadcast Atomic Commit (Databases) Fulfilling A and C in ACID properties Terminating reliable broadcasts Sending messages to a list of processes, say in multiplayer gaming Dynamic group membership Who is the master? Which workers are available? What task is assigned to the worker? Stronger shared stored models Like how a concurrent hashmap helps concurrent threads to reach an agreement
Safety Never returns an incorrect result despite Network partitions and delays Packet loss, duplications and reorder Fault Tolerant System is available and fully functional in case of failure of nodes.
Safety Never returns an incorrect result despite Network partitions and delays Packet loss, duplications and reorder Fault Tolerant System is available and fully functional in case of failure of nodes. Correctness Performance is not impacted by minority of slow nodes. Does not depend on consistency of time for correctness.
Safety Never returns an incorrect result despite Network partitions and delays Packet loss, duplications and reorder Fault Tolerant System is available and fully functional in case of failure of nodes. Correctness Performance is not impacted by minority of slow nodes. Does not depend on consistency of time for correctness. Real World Core algorithm should be understandable and intuitive. The internal workings should seem obvious. Implementation shouldn't require a major overhaul in existing arch.
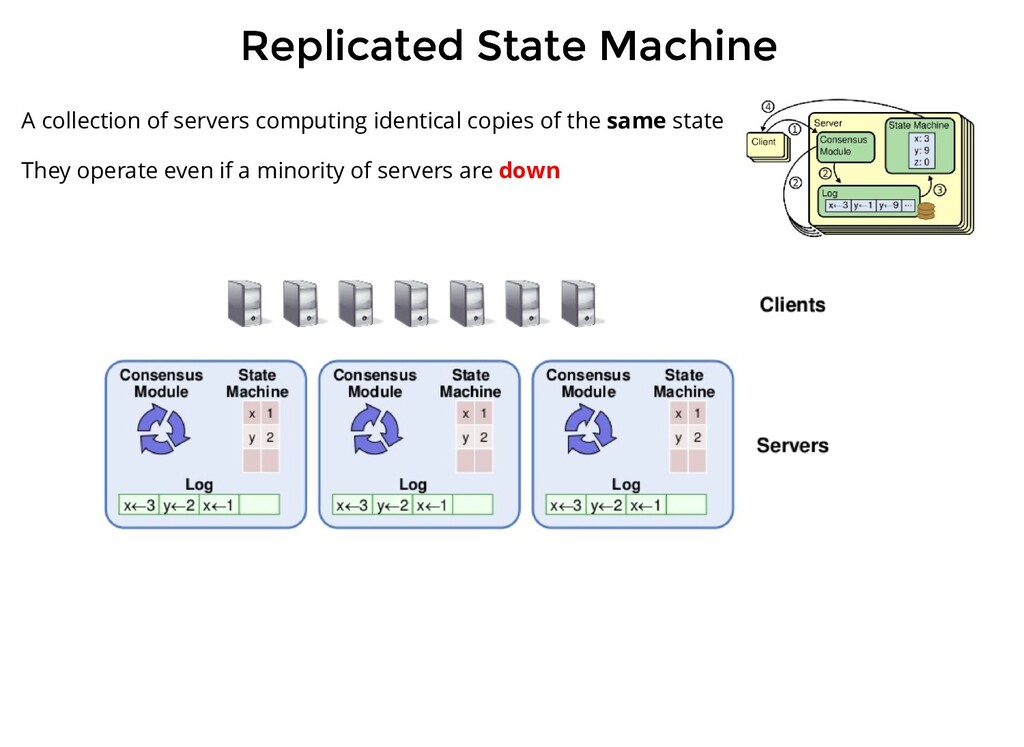
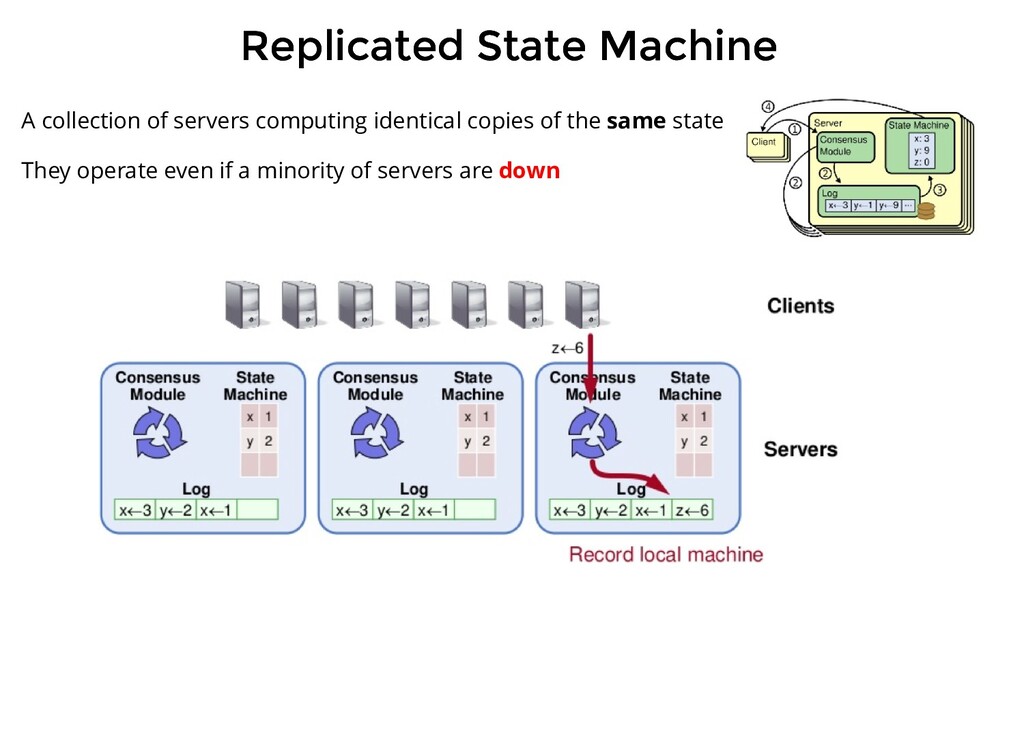
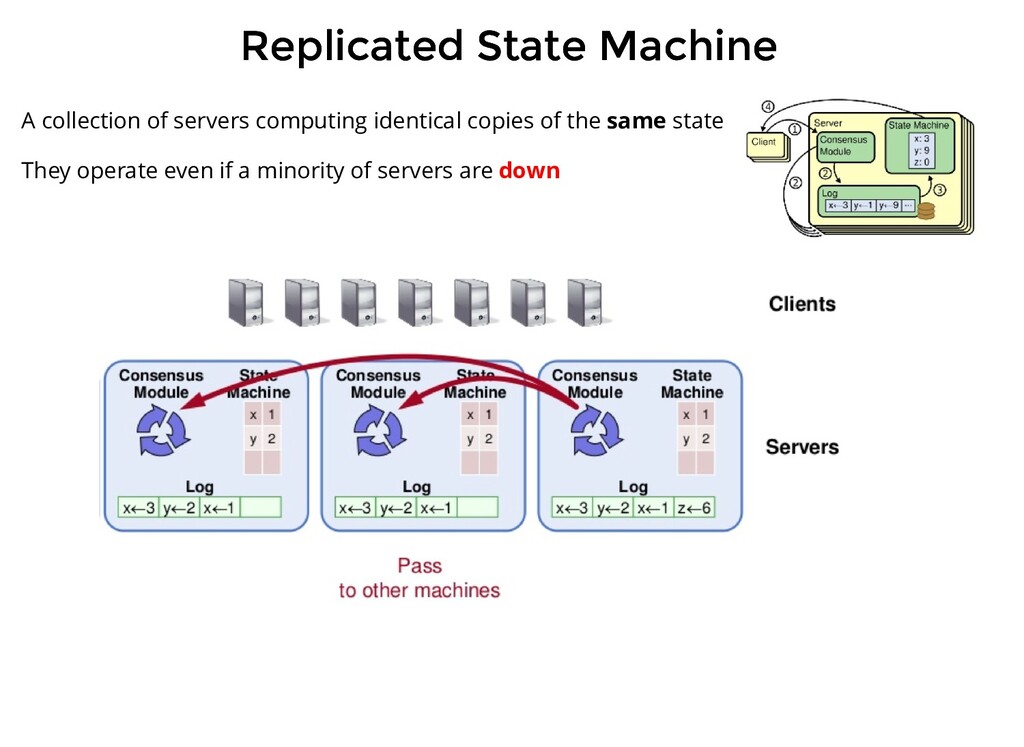
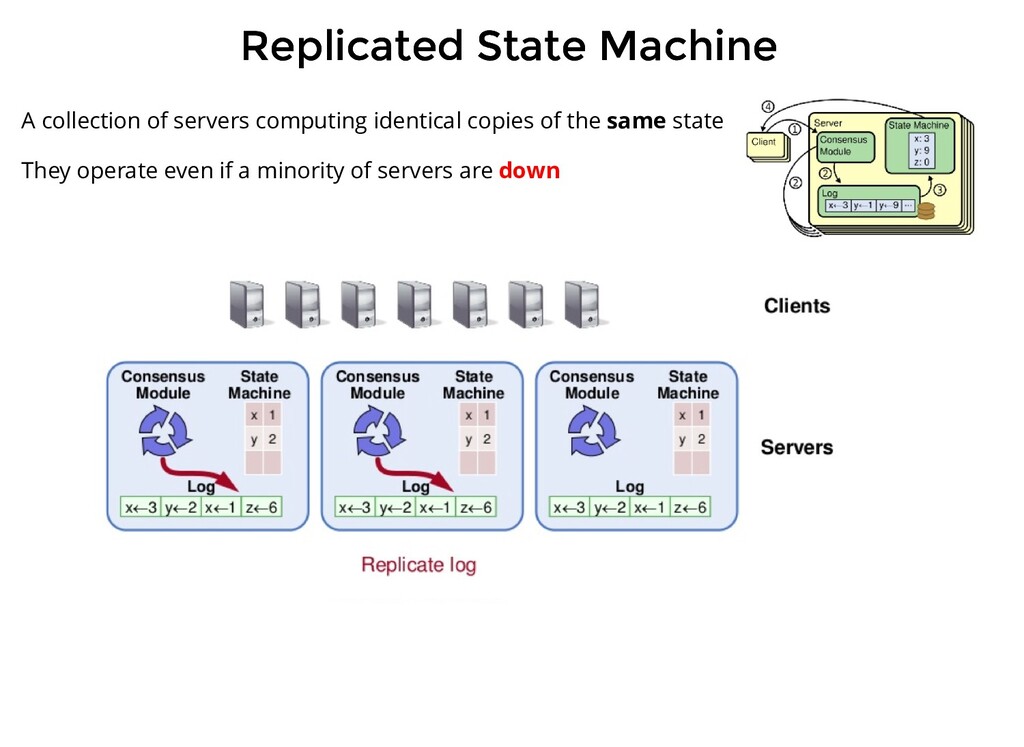
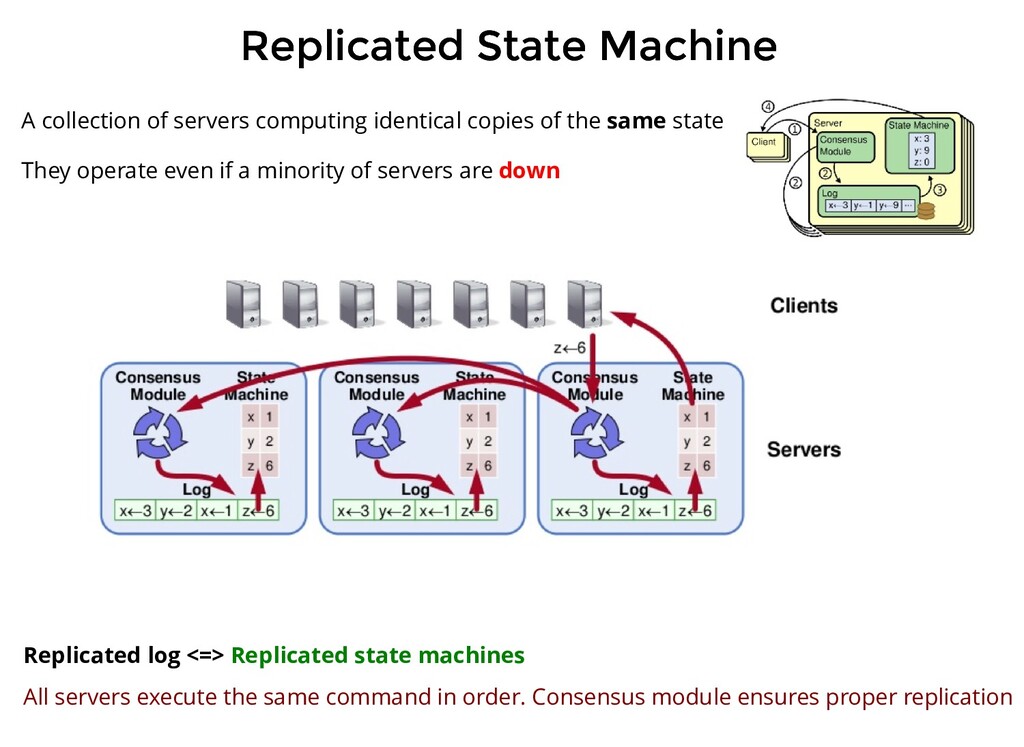
computing identical copies of the same state They operate even if a minority of servers are down Replicated log <=> Replicated state machines All servers execute the same command in order. Consensus module ensures proper replication
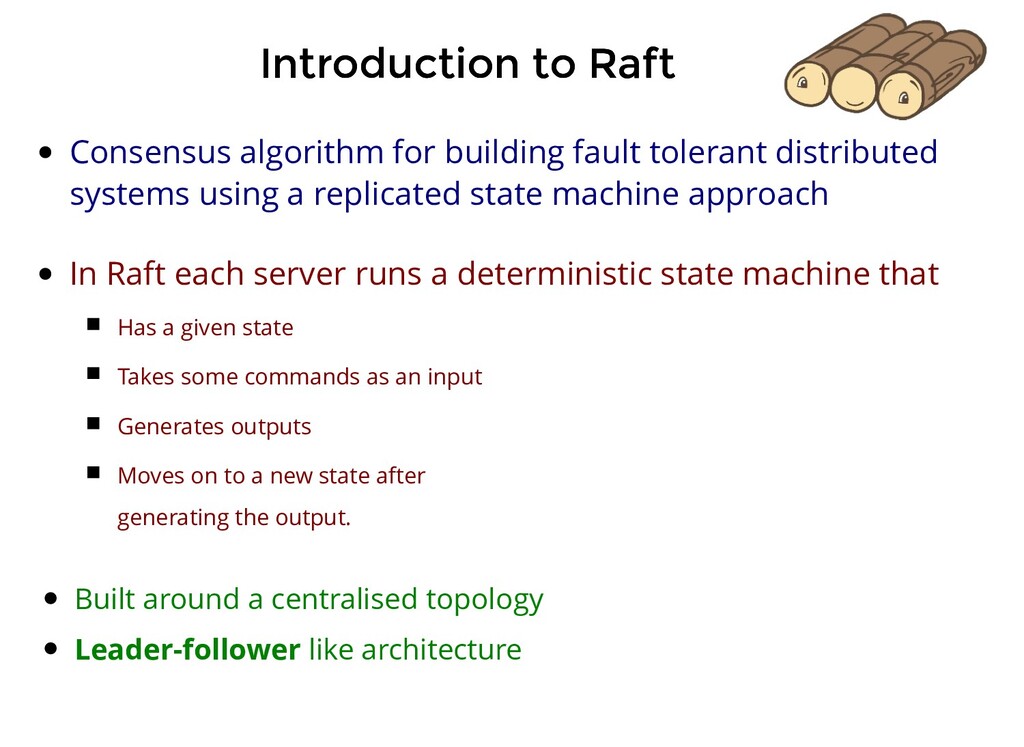
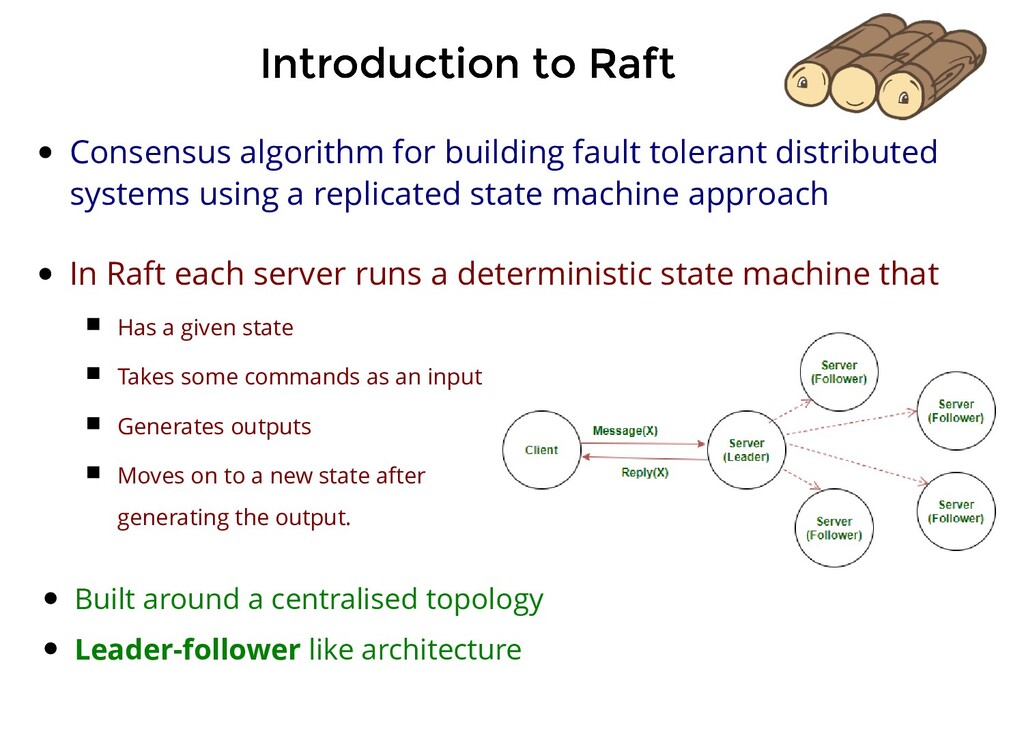
fault tolerant distributed systems using a replicated state machine approach In Raft each server runs a deterministic state machine that Has a given state Takes some commands as an input Generates outputs Moves on to a new state after generating the output.
fault tolerant distributed systems using a replicated state machine approach In Raft each server runs a deterministic state machine that Has a given state Takes some commands as an input Generates outputs Moves on to a new state after generating the output. Built around a centralised topology Leader-follower like architecture
fault tolerant distributed systems using a replicated state machine approach In Raft each server runs a deterministic state machine that Has a given state Takes some commands as an input Generates outputs Moves on to a new state after generating the output. Built around a centralised topology Leader-follower like architecture
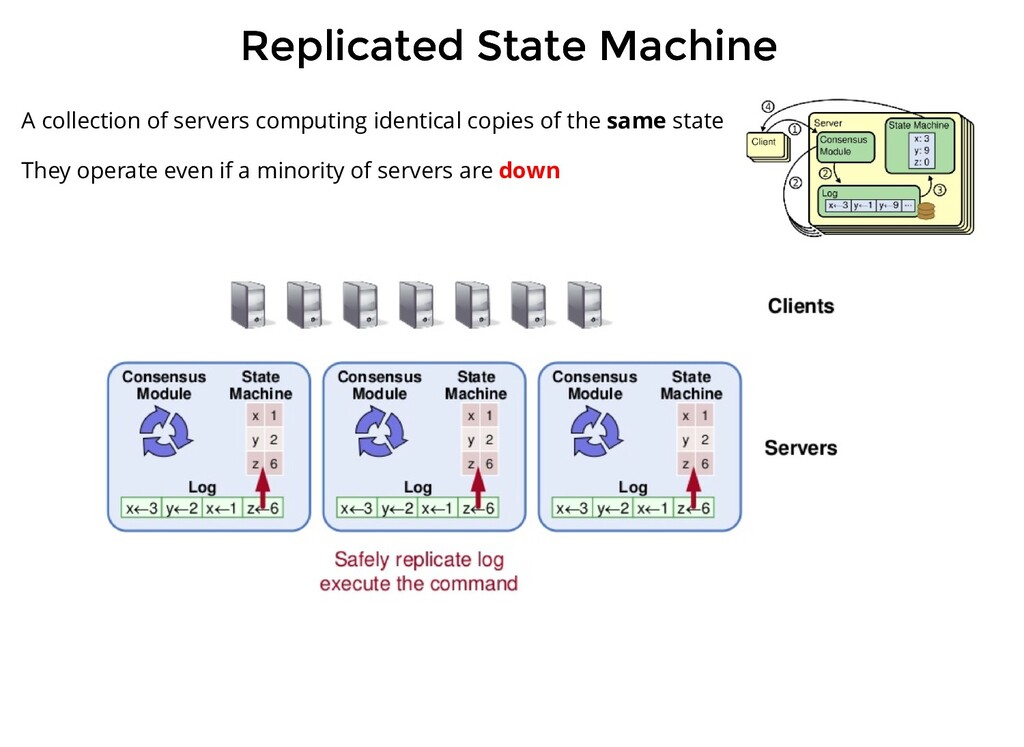
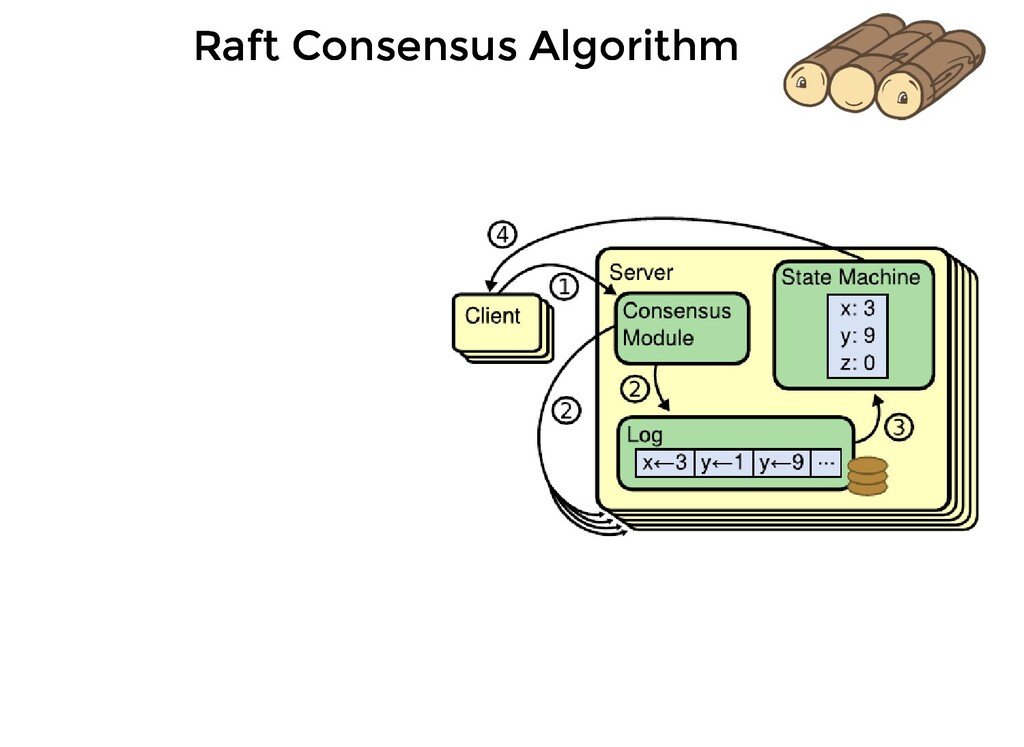
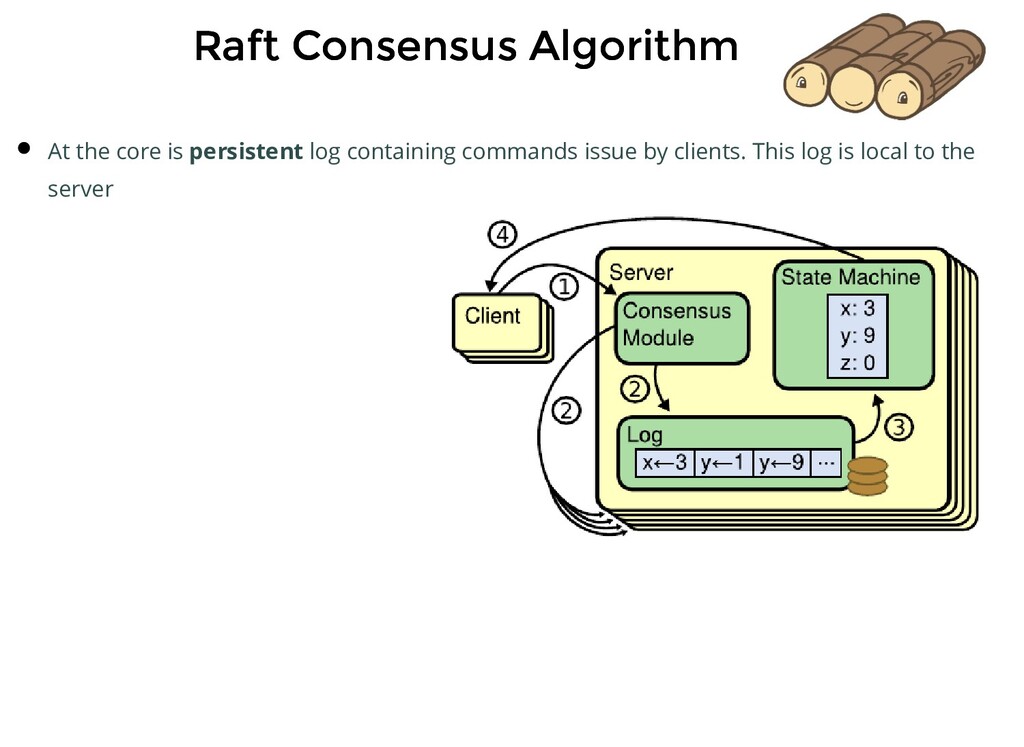
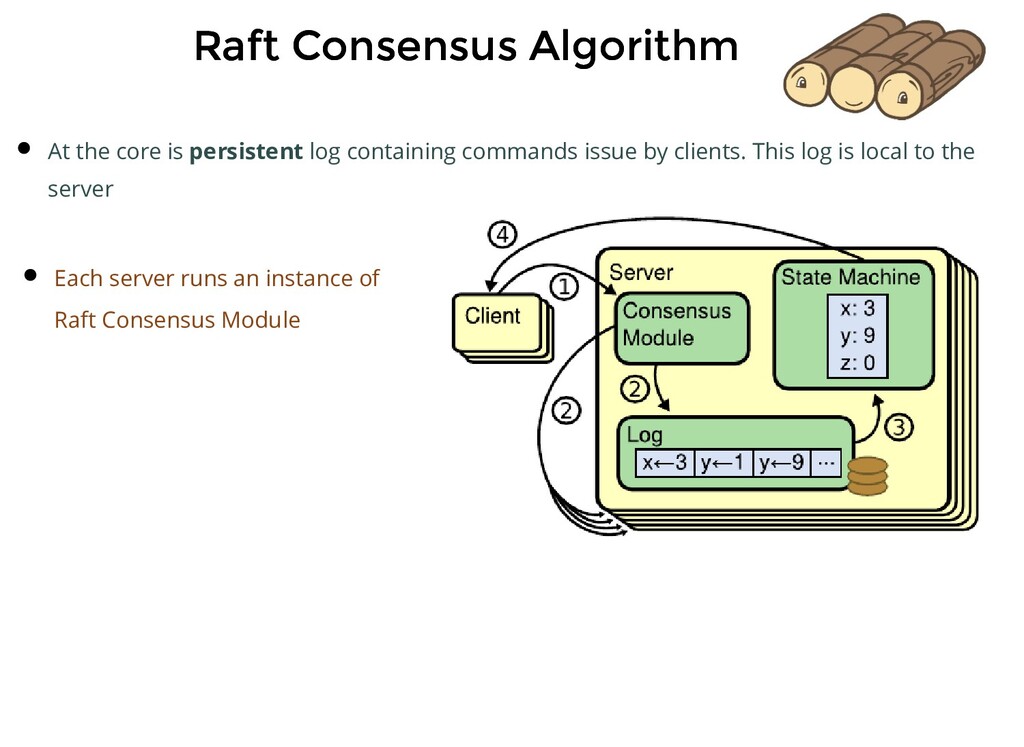
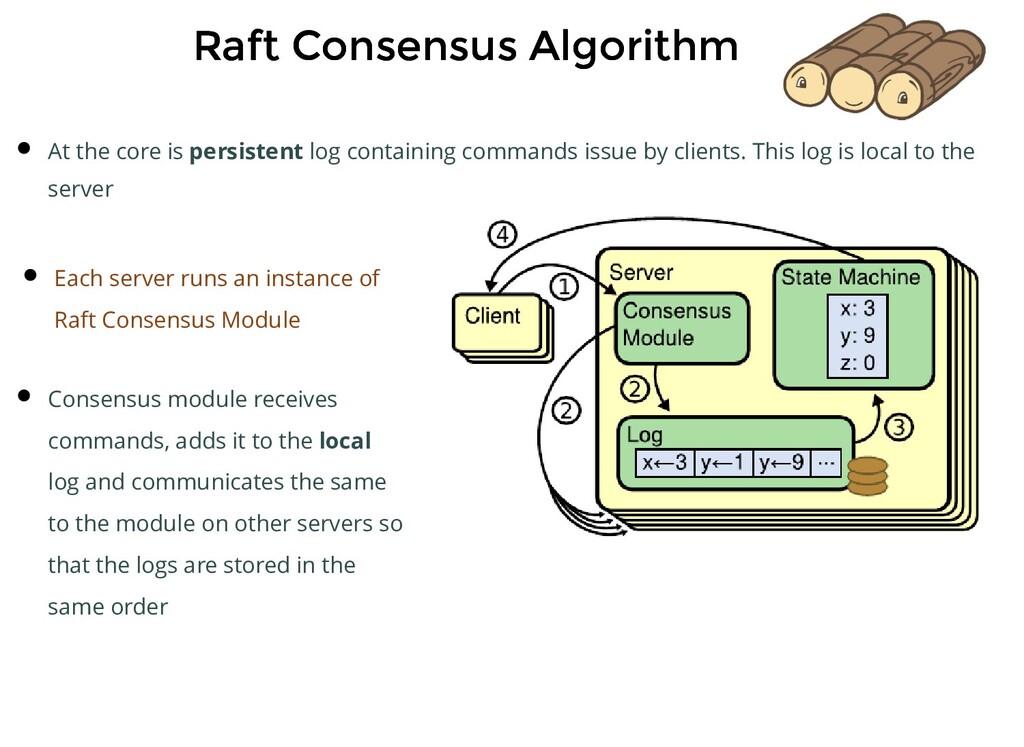
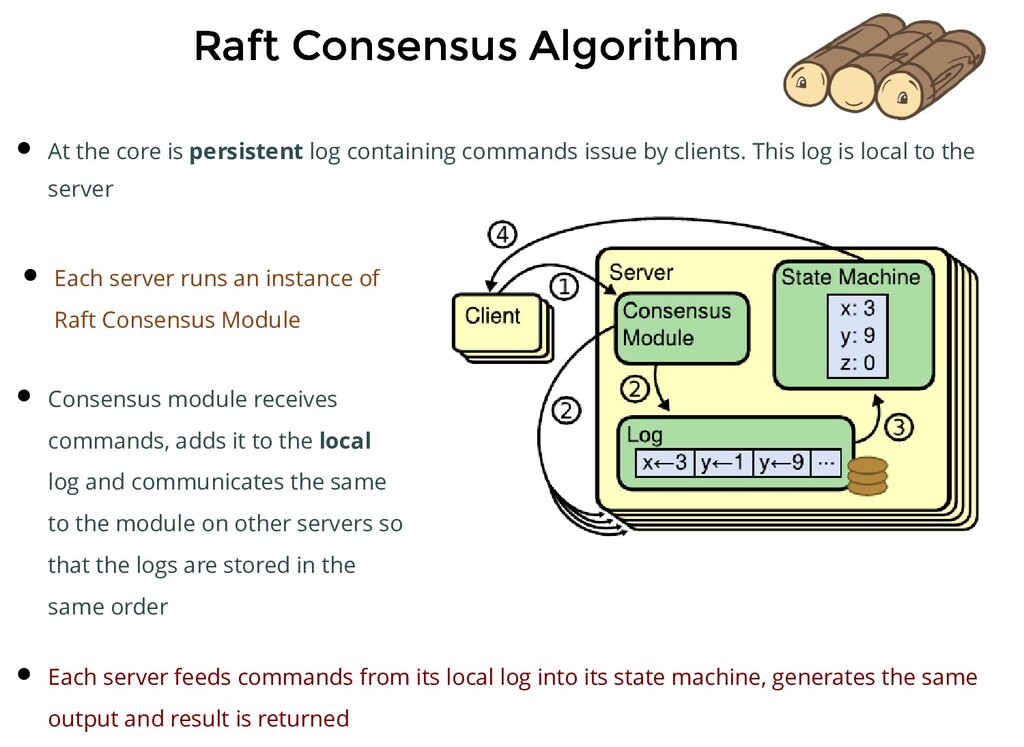
persistent log containing commands issue by clients. This log is local to the server Each server runs an instance of Raft Consensus Module Consensus module receives commands, adds it to the local log and communicates the same to the module on other servers so that the logs are stored in the same order
persistent log containing commands issue by clients. This log is local to the server Each server runs an instance of Raft Consensus Module Consensus module receives commands, adds it to the local log and communicates the same to the module on other servers so that the logs are stored in the same order Each server feeds commands from its local log into its state machine, generates the same output and result is returned
problems in general? problems in general? Problem decomposition Break the original problem into sub-problems Try to solve and conquer them individually Minimise the state space Handle multiple problems with a single mechanism Eliminate special cases Maximise coherence Minimise non determinism
one leader per term Heartbeats and timeouts to detect crashes and elect new leader Randomized voting to avoid split votes. Log Replication Leader accepts commands from clients and appends to its log Leaders replicates its log to other servers forcing them to agree Overwrite log consistencies using consistency checks
one leader per term Heartbeats and timeouts to detect crashes and elect new leader Randomized voting to avoid split votes. Log Replication Leader accepts commands from clients and appends to its log Leaders replicates its log to other servers forcing them to agree Overwrite log consistencies using consistency checks Safety Only servers with up to date logs can become leader New leaders will discard any uncommitted entries A leader is always correct
one leader per term Heartbeats and timeouts to detect crashes and elect new leader Randomized voting to avoid split votes. Log Replication Leader accepts commands from clients and appends to its log Leaders replicates its log to other servers forcing them to agree Overwrite log consistencies using consistency checks Safety Only servers with up to date logs can become leader New leaders will discard any uncommitted entries A leader is always correct
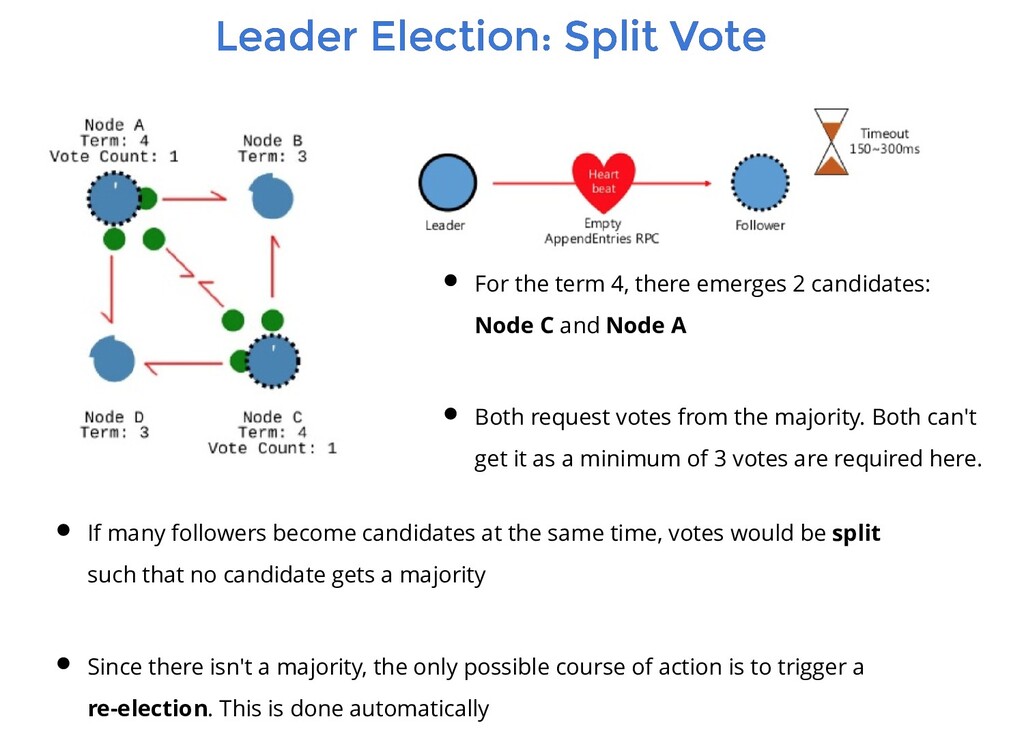
followers become candidates at the same time, votes would be split such that no candidate gets a majority Since there isn't a majority, the only possible course of action is to trigger a re-election. This is done automatically For the term 4, there emerges 2 candidates: Node C and Node A Both request votes from the majority. Both can't get it as a minimum of 3 votes are required here.
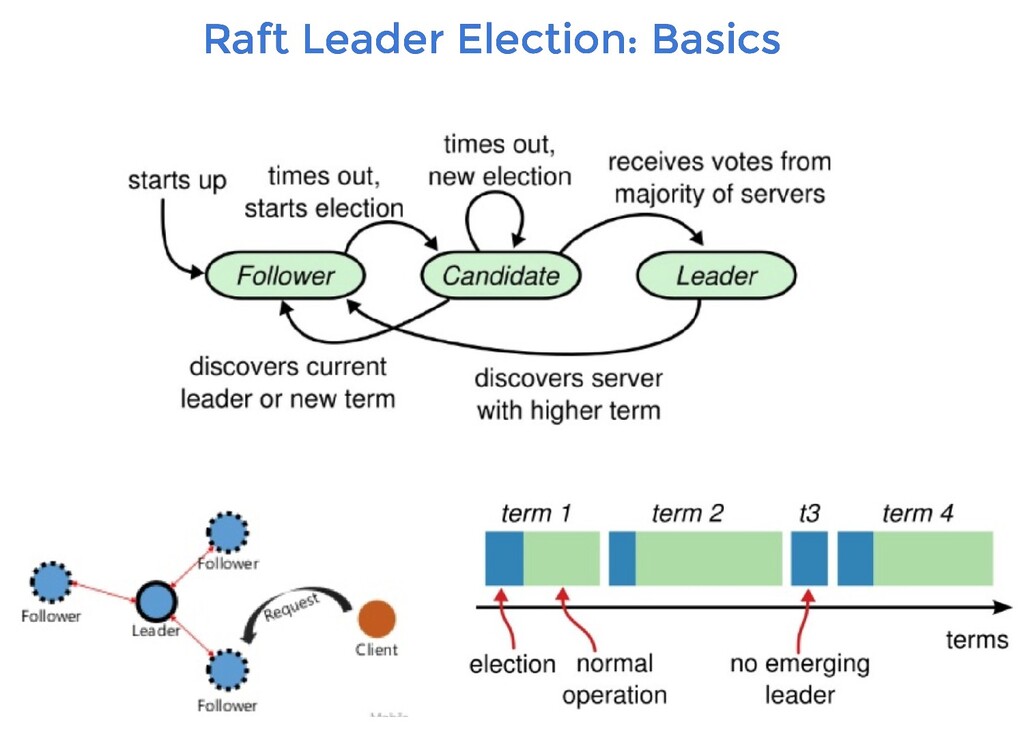
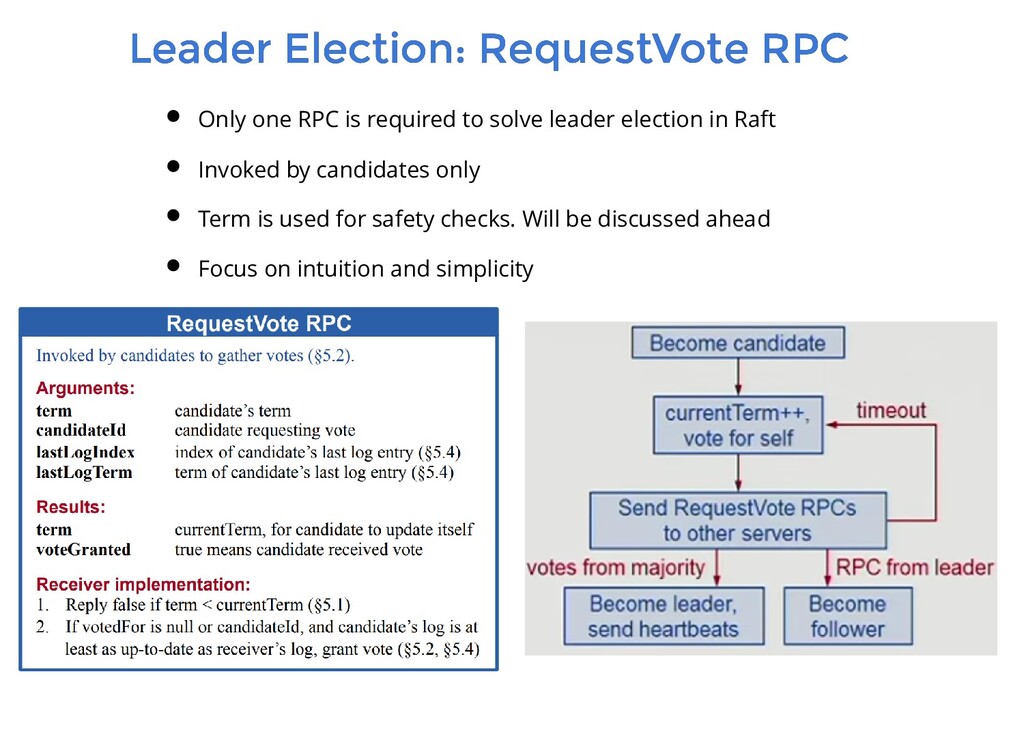
RPC is required to solve leader election in Raft Invoked by candidates only Term is used for safety checks. Will be discussed ahead Focus on intuition and simplicity
there can be at most 1 leader The ongoing latest term number is exchanged between the servers. The term number is encapsulated as part of requests sent by the leader to follower nodes. A node rejects any request received with an old term number. A server will vote for at most one candidate for the particular term. This will be done on first-come-first-served basis. Once a candidate wins, it establishes its authority over other follower nodes by broadcasting a message to all other nodes. This will let everyone know who the new leader is. A server will give its vote to at most one candidate (if it hasn't voted for itself) of course. This information will be persisted to disk as well.
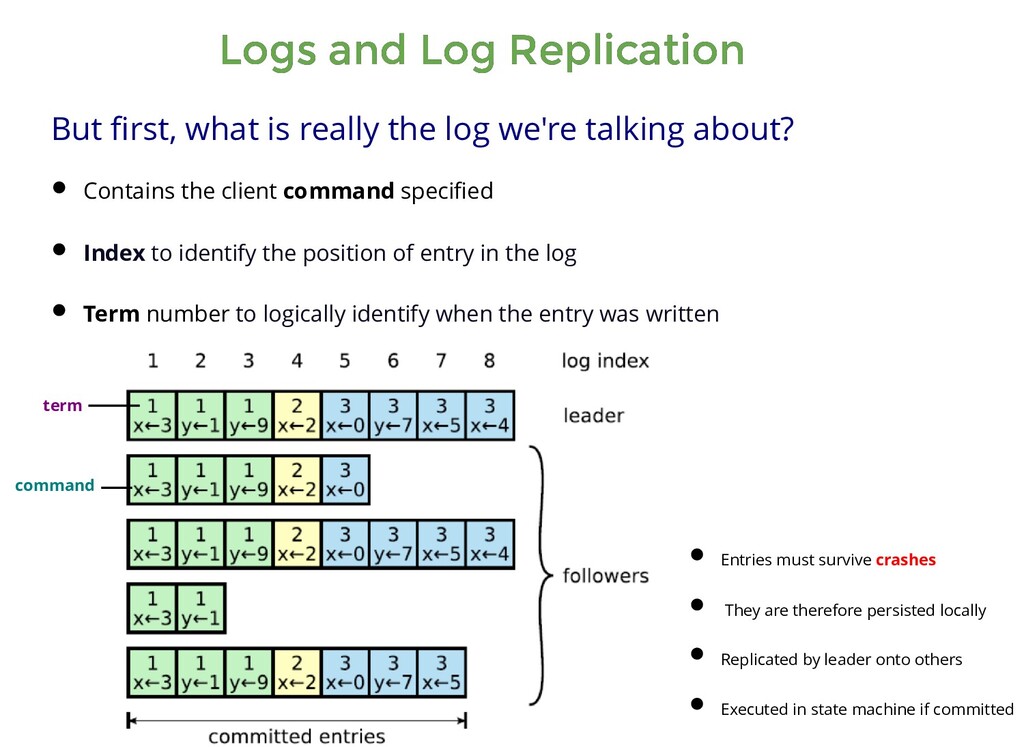
client command specified Index to identify the position of entry in the log Term number to logically identify when the entry was written But first, what is really the log we're talking about? Entries must survive crashes They are therefore persisted locally Replicated by leader onto others Executed in state machine if committed command term
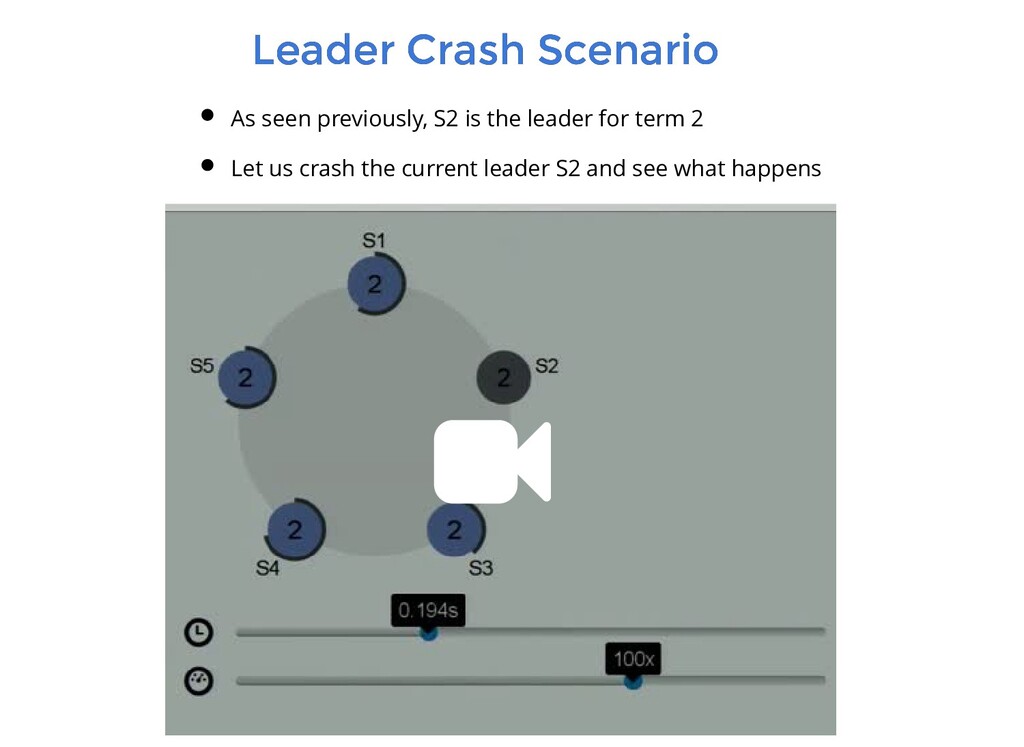
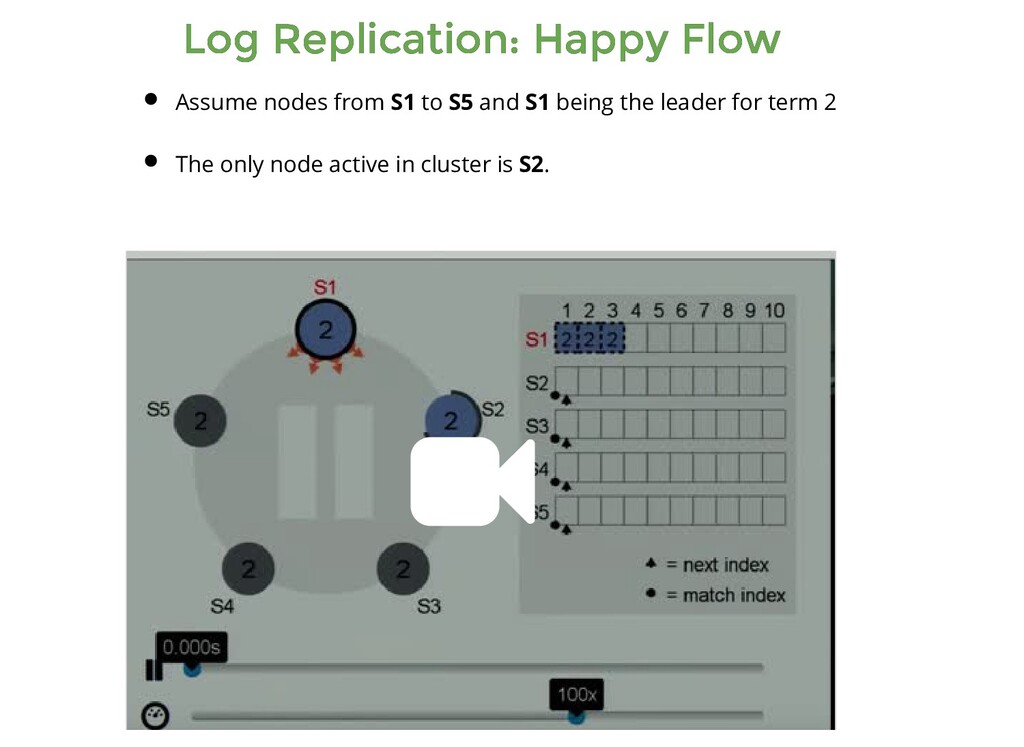
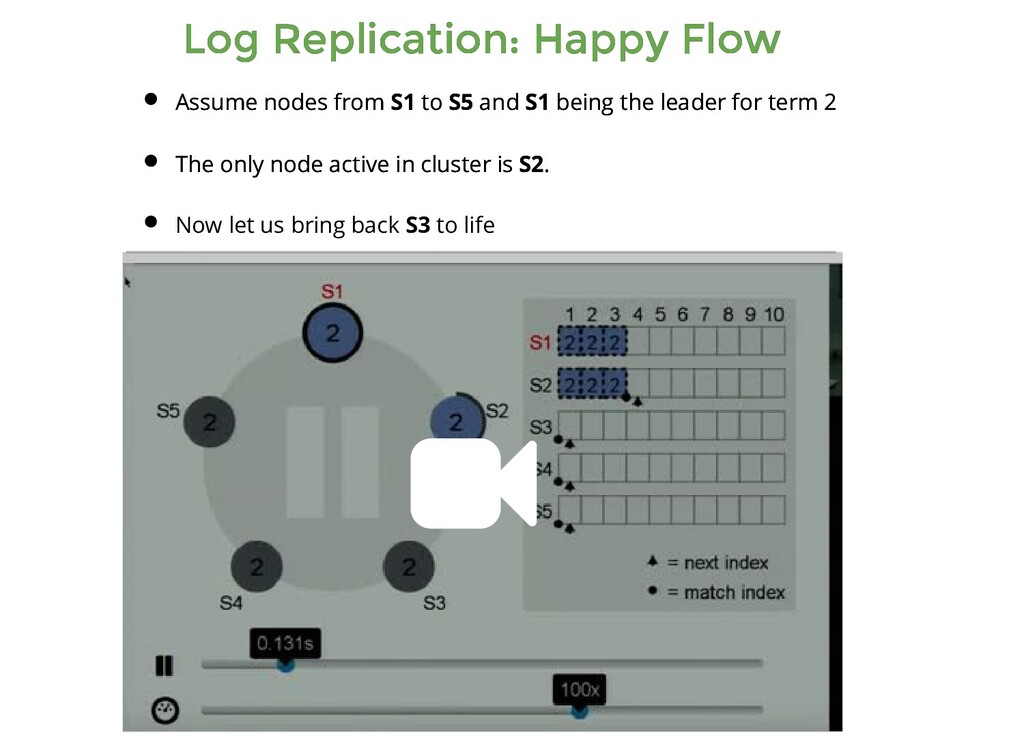
from S1 to S5 and S1 being the leader for term 2 The only node active in cluster is S2. Assume nodes from S1 to S5 and S1 being the leader for term 2 The only node active in cluster is S2. Now let us bring back S3 to life
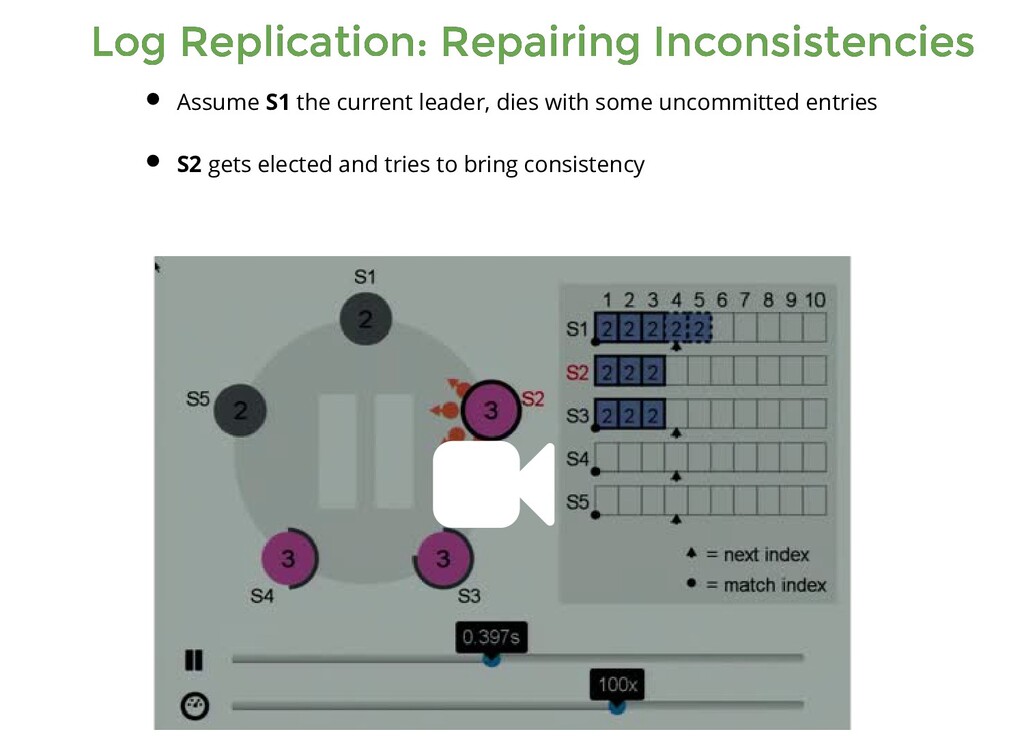
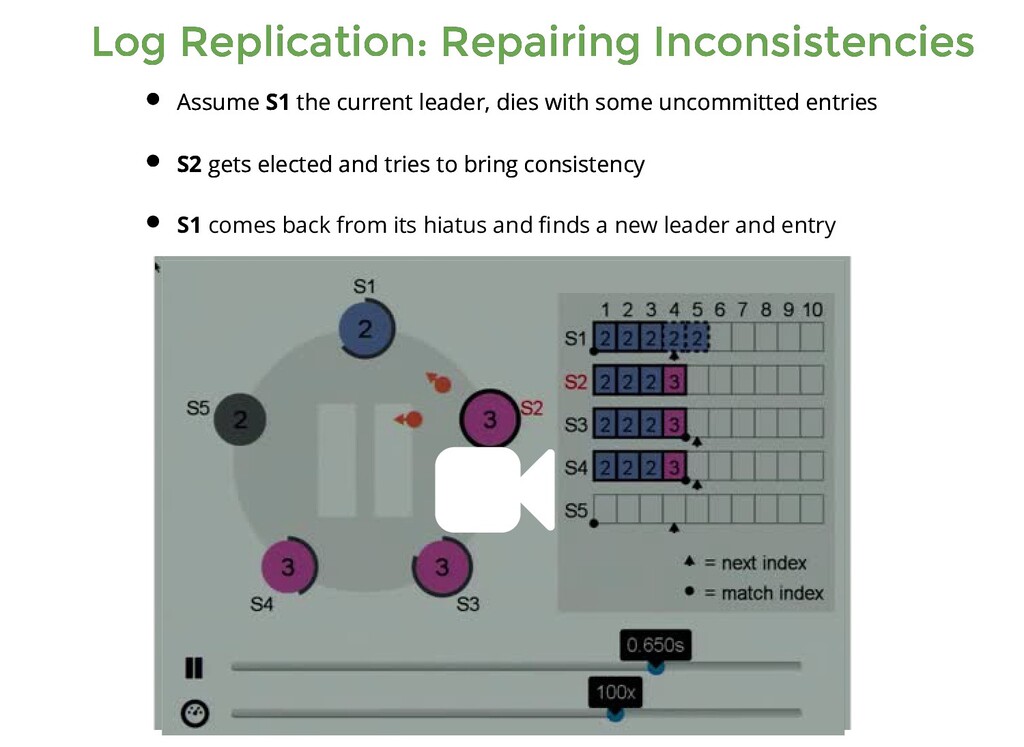
the current leader, dies with some uncommitted entries S2 gets elected and tries to bring consistency Assume S1 the current leader, dies with some uncommitted entries S2 gets elected and tries to bring consistency S1 comes back from its hiatus and finds a new leader and entry
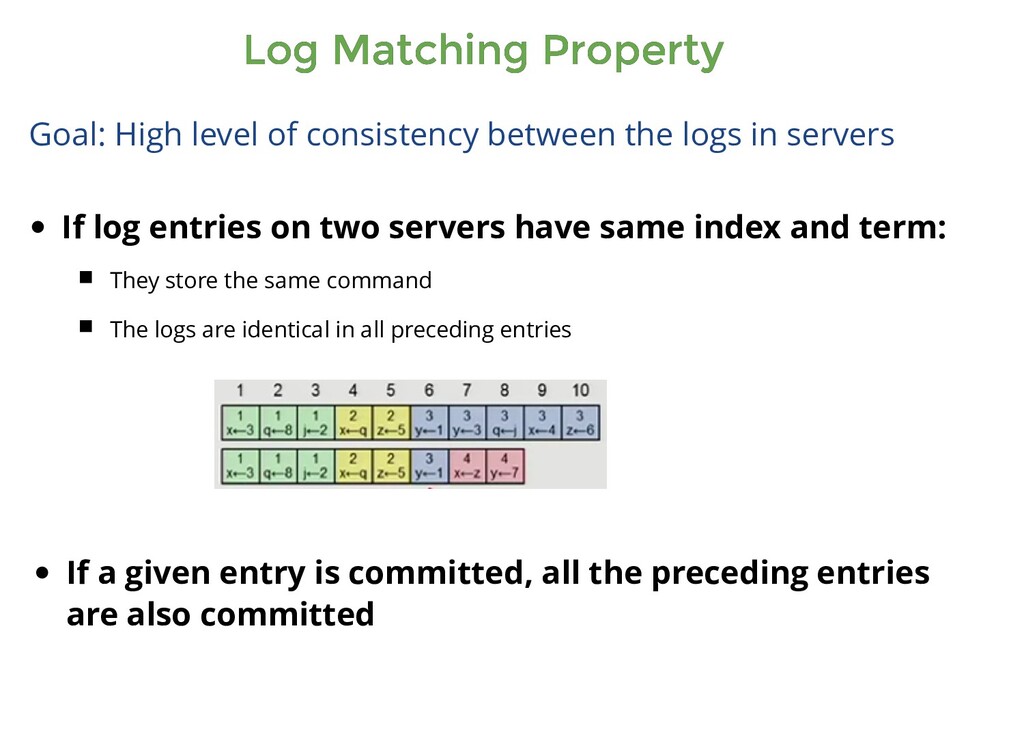
consistency between the logs in servers If log entries on two servers have same index and term: They store the same command The logs are identical in all preceding entries If a given entry is committed, all the preceding entries are also committed
consistency between the logs in servers If log entries on two servers have same index and term: They store the same command The logs are identical in all preceding entries If a given entry is committed, all the preceding entries are also committed
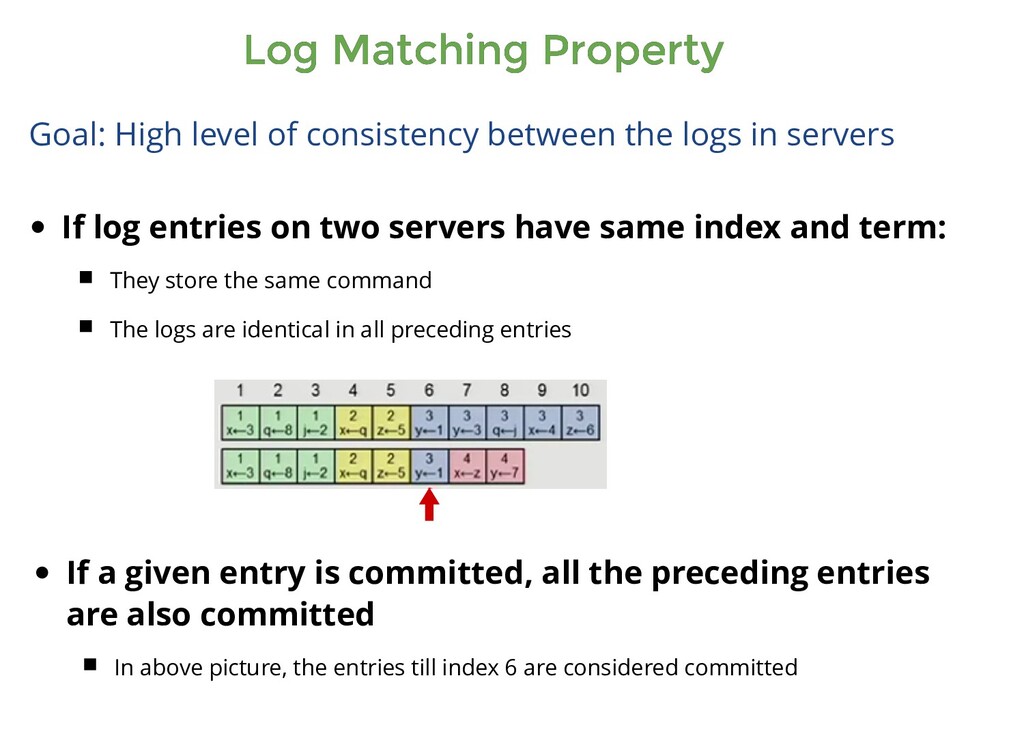
consistency between the logs in servers If log entries on two servers have same index and term: They store the same command The logs are identical in all preceding entries If a given entry is committed, all the preceding entries are also committed In above picture, the entries till index 6 are considered committed
AppendEntries RPC include <index, term> of preceding entry Follower must contain matching entry, otherwise it rejects the request Leader then has to retry with a lower index until match
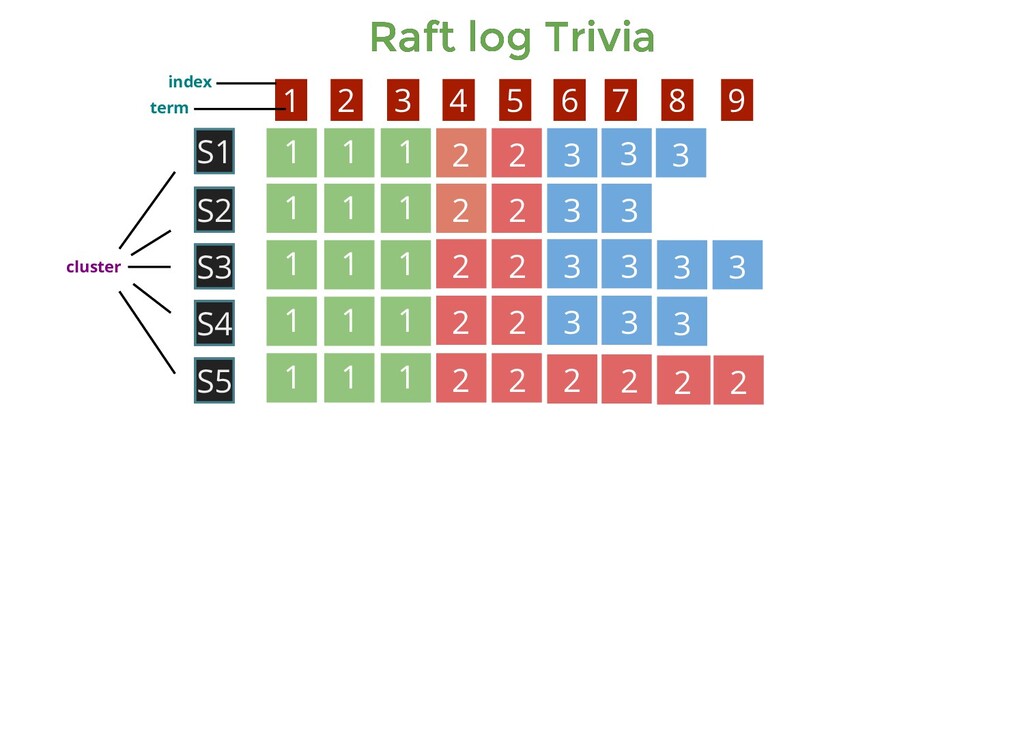
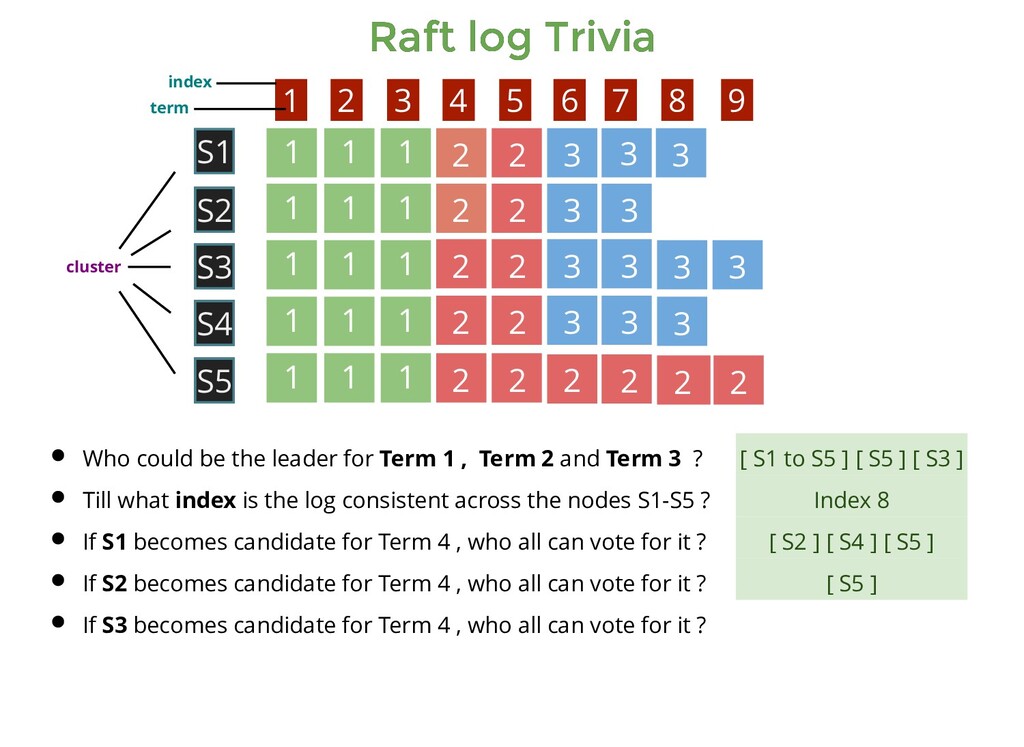
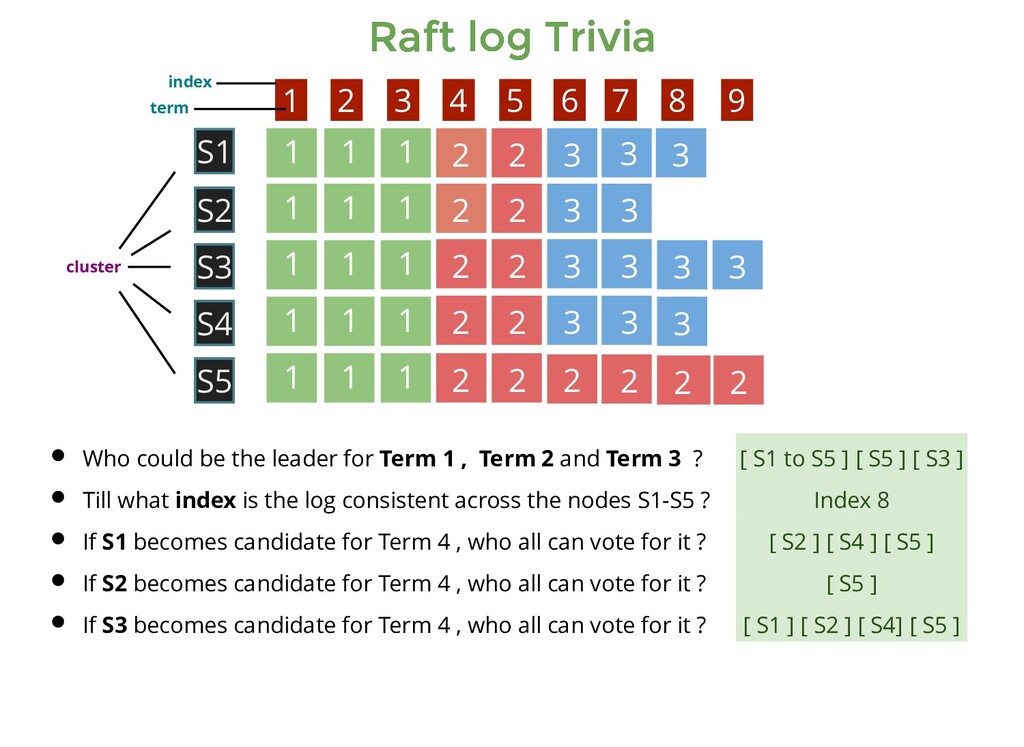
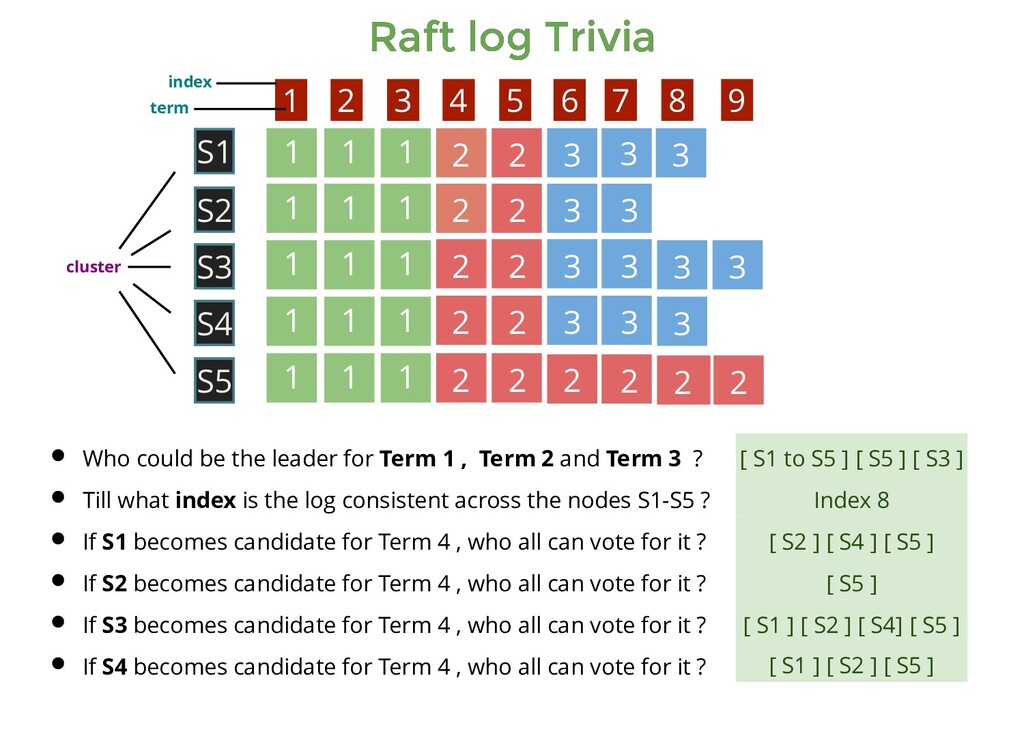
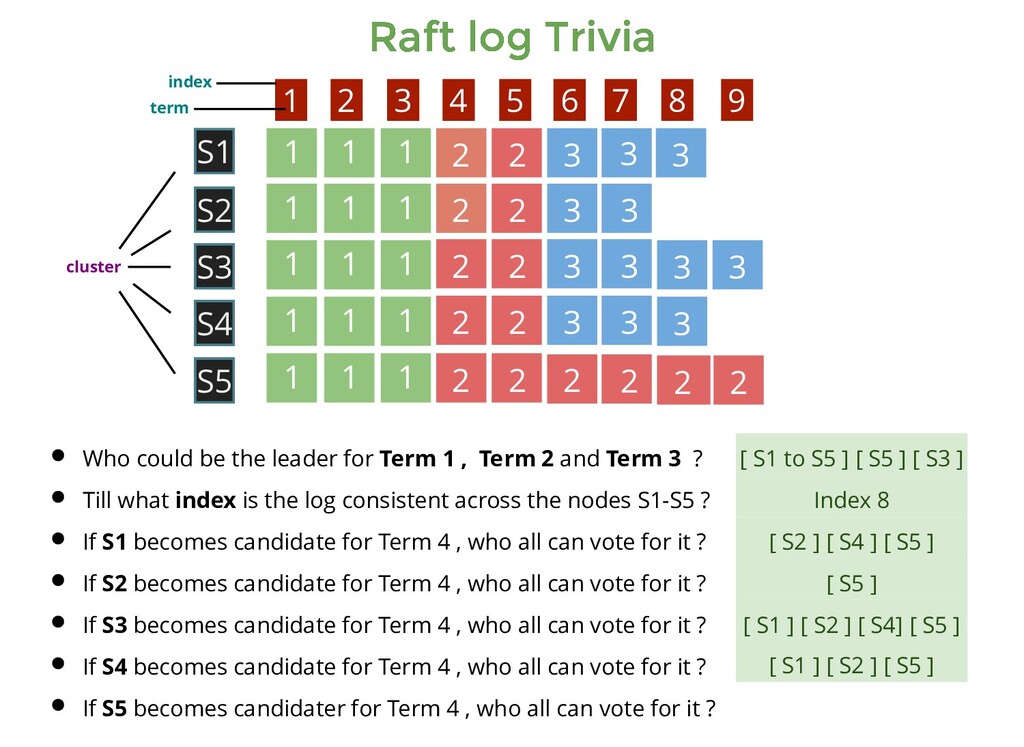
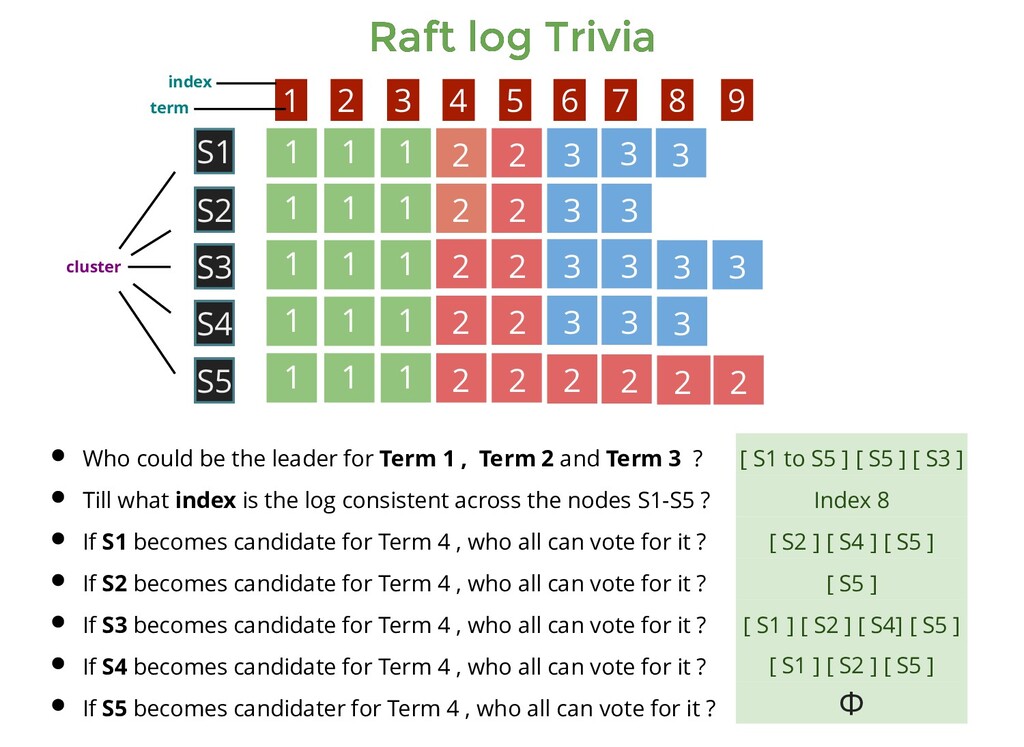
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? [ S1 to S5 ] [ S5 ] [ S3 ] cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? If S1 becomes candidate for Term 4 , who all can vote for it ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? If S1 becomes candidate for Term 4 , who all can vote for it ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 [ S2 ] [ S4 ] [ S5 ] cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? If S1 becomes candidate for Term 4 , who all can vote for it ? If S2 becomes candidate for Term 4 , who all can vote for it ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 [ S2 ] [ S4 ] [ S5 ] cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? If S1 becomes candidate for Term 4 , who all can vote for it ? If S2 becomes candidate for Term 4 , who all can vote for it ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 [ S2 ] [ S4 ] [ S5 ] [ S5 ] cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? If S1 becomes candidate for Term 4 , who all can vote for it ? If S2 becomes candidate for Term 4 , who all can vote for it ? If S3 becomes candidate for Term 4 , who all can vote for it ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 [ S2 ] [ S4 ] [ S5 ] [ S5 ] cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? If S1 becomes candidate for Term 4 , who all can vote for it ? If S2 becomes candidate for Term 4 , who all can vote for it ? If S3 becomes candidate for Term 4 , who all can vote for it ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 [ S2 ] [ S4 ] [ S5 ] [ S5 ] [ S1 ] [ S2 ] [ S4] [ S5 ] cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? If S1 becomes candidate for Term 4 , who all can vote for it ? If S2 becomes candidate for Term 4 , who all can vote for it ? If S3 becomes candidate for Term 4 , who all can vote for it ? If S4 becomes candidate for Term 4 , who all can vote for it ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 [ S2 ] [ S4 ] [ S5 ] [ S5 ] [ S1 ] [ S2 ] [ S4] [ S5 ] cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? If S1 becomes candidate for Term 4 , who all can vote for it ? If S2 becomes candidate for Term 4 , who all can vote for it ? If S3 becomes candidate for Term 4 , who all can vote for it ? If S4 becomes candidate for Term 4 , who all can vote for it ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 [ S2 ] [ S4 ] [ S5 ] [ S5 ] [ S1 ] [ S2 ] [ S4] [ S5 ] [ S1 ] [ S2 ] [ S5 ] cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? If S1 becomes candidate for Term 4 , who all can vote for it ? If S2 becomes candidate for Term 4 , who all can vote for it ? If S3 becomes candidate for Term 4 , who all can vote for it ? If S4 becomes candidate for Term 4 , who all can vote for it ? If S5 becomes candidater for Term 4 , who all can vote for it ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 [ S2 ] [ S4 ] [ S5 ] [ S5 ] [ S1 ] [ S2 ] [ S4] [ S5 ] [ S1 ] [ S2 ] [ S5 ] cluster index term
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 1 1 1 2 2 3 3 3 S1 S5 S3 S4 S2 1 2 3 4 5 6 7 8 9 Who could be the leader for Term 1 , Term 2 and Term 3 ? Till what index is the log consistent across the nodes S1-S5 ? If S1 becomes candidate for Term 4 , who all can vote for it ? If S2 becomes candidate for Term 4 , who all can vote for it ? If S3 becomes candidate for Term 4 , who all can vote for it ? If S4 becomes candidate for Term 4 , who all can vote for it ? If S5 becomes candidater for Term 4 , who all can vote for it ? [ S1 to S5 ] [ S5 ] [ S3 ] Index 8 [ S2 ] [ S4 ] [ S5 ] [ S5 ] [ S1 ] [ S2 ] [ S4] [ S5 ] [ S1 ] [ S2 ] [ S5 ] Φ cluster index term
critical in Raft to elect and maintain a steady leader over time, in order to have a perfect availability of the cluster. Stability is ensured by respecting the timing requirement of the algorithm
critical in Raft to elect and maintain a steady leader over time, in order to have a perfect availability of the cluster. Stability is ensured by respecting the timing requirement of the algorithm broadcastTime << electionTimeout << MTBF
critical in Raft to elect and maintain a steady leader over time, in order to have a perfect availability of the cluster. Stability is ensured by respecting the timing requirement of the algorithm broadcastTime << electionTimeout << MTBF broadcastTime is the average time it takes a server to send request to every server in the cluster and receive responses. It is relative to the infrastructure. Typically 0.5 - 20 ms
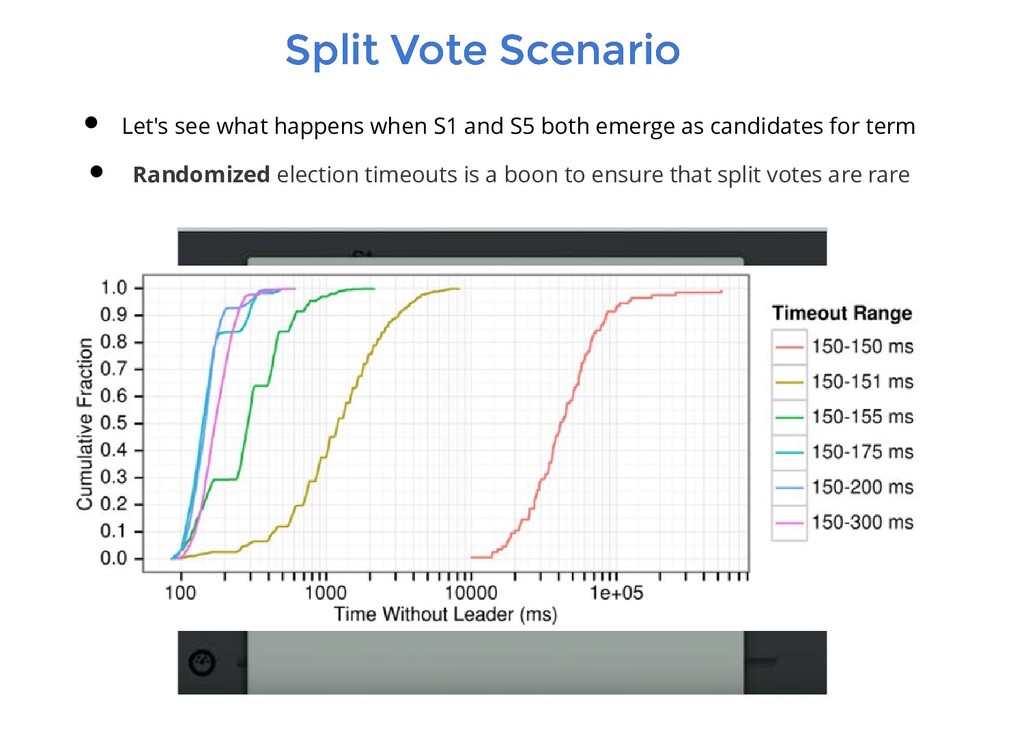
critical in Raft to elect and maintain a steady leader over time, in order to have a perfect availability of the cluster. Stability is ensured by respecting the timing requirement of the algorithm broadcastTime << electionTimeout << MTBF broadcastTime is the average time it takes a server to send request to every server in the cluster and receive responses. It is relative to the infrastructure. Typically 0.5 - 20 ms electionTimeout is the configurable time post which a election triggers. Typically 150-300ms A good measure is around ~10x the mean network latency
critical in Raft to elect and maintain a steady leader over time, in order to have a perfect availability of the cluster. Stability is ensured by respecting the timing requirement of the algorithm broadcastTime << electionTimeout << MTBF broadcastTime is the average time it takes a server to send request to every server in the cluster and receive responses. It is relative to the infrastructure. Typically 0.5 - 20 ms electionTimeout is the configurable time post which a election triggers. Typically 150-300ms A good measure is around ~10x the mean network latency MTBF (Mean Time Between Failures) is the average time between failures for a server
A leader never overwrites or delete entries rather appends Leader append only Only one leader will be elected per election term If two logs contain an entry with same index and term, they are consistent. and their logs are identical in all entries up to the index Log Matching If a log entry is committed in a term then that entry will be present in the logs of leaders for all higher numbered terms. Leader completeness If a server has applied a log at a particular index in its state machine, no other server will apply a different log to that index State machine safety
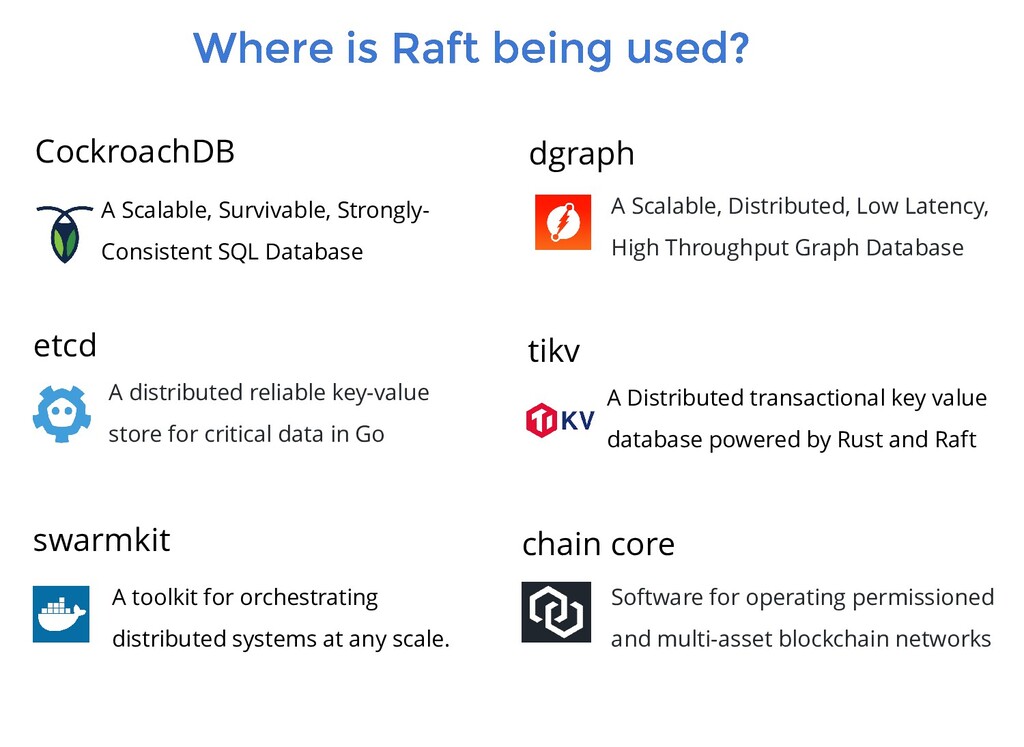
CockroachDB A Scalable, Survivable, Strongly- Consistent SQL Database dgraph A Scalable, Distributed, Low Latency, High Throughput Graph Database etcd A distributed reliable key-value store for critical data in Go tikv A Distributed transactional key value database powered by Rust and Raft swarmkit A toolkit for orchestrating distributed systems at any scale. chain core Software for operating permissioned and multi-asset blockchain networks
Log replication and Safety A node can be in one of three states: Follower, Candidate or Leader Every node starts as a Follower and transitions to candidate state after election timeout
Log replication and Safety A node can be in one of three states: Follower, Candidate or Leader Every node starts as a Follower and transitions to candidate state after election timeout A Candidate will vote for itself and send RequestVote RPCs to all the other nodes
Log replication and Safety A node can be in one of three states: Follower, Candidate or Leader Every node starts as a Follower and transitions to candidate state after election timeout A Candidate will vote for itself and send RequestVote RPCs to all the other nodes If it gets votes from the majority of the nodes, it becomes the new Leader
Log replication and Safety A node can be in one of three states: Follower, Candidate or Leader Every node starts as a Follower and transitions to candidate state after election timeout A Candidate will vote for itself and send RequestVote RPCs to all the other nodes If it gets votes from the majority of the nodes, it becomes the new Leader The leader is the only node responsible for managing the log. Followers just add new entries to their logs in response to the leader AppendEntries RPC
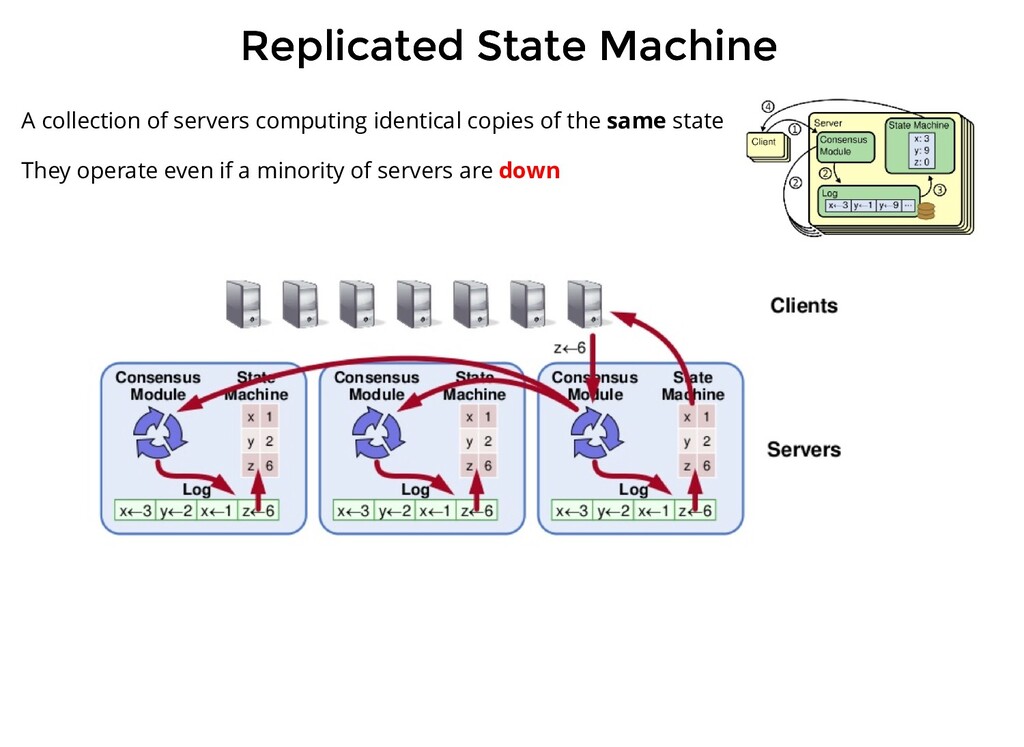
from the client, it first saves this uncommitted message in its log, then sends it to every follower When it gets a successful response from the majority of nodes, the command is committed and the client gets a confirmation.
from the client, it first saves this uncommitted message in its log, then sends it to every follower When it gets a successful response from the majority of nodes, the command is committed and the client gets a confirmation. In the next AppendEntries RPC sent to the follower (that can be a new entry or just a heartbeat), the follower also commits the message
from the client, it first saves this uncommitted message in its log, then sends it to every follower When it gets a successful response from the majority of nodes, the command is committed and the client gets a confirmation. In the next AppendEntries RPC sent to the follower (that can be a new entry or just a heartbeat), the follower also commits the message The AppendEntries RPC implements a consistency check, to guarantee its local log is consistent with the leader's log.
from the client, it first saves this uncommitted message in its log, then sends it to every follower When it gets a successful response from the majority of nodes, the command is committed and the client gets a confirmation. In the next AppendEntries RPC sent to the follower (that can be a new entry or just a heartbeat), the follower also commits the message The AppendEntries RPC implements a consistency check, to guarantee its local log is consistent with the leader's log. A follower will grant its vote to a candidate that has a log at least as up to date as its own
the first place to start Read about cluster membership in Raft You can now read about ZAB protocol in Zookeeper Raft in even simpler terms Sample implementations of the Raft, particularly in Java ZK logs should make even more sense now Dive into Paxos and compare the models for yourself. Raft paper Visualize
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}